TF-IDF
TF-IDF是TF(詞頻,Term Frequency)和IDF(逆文檔頻率,Inverse Document Frequency)的乘積。我們先來看他們分別是怎么計算的:
TF的計算有多種方式,常見的是
 除以文章總詞數是為了標準化
除以文章總詞數是為了標準化
IDF為:

如果一個詞越常見,那么分母就越大,逆文檔頻率就越小越接近0。分母之所以要加1,是為了避免分母為0(即所有文檔都不包含該詞)。log表示對得到的值取對數,求log是為了歸一化,保證IDF不會過大。
所以TF-IDF 的計算就是:
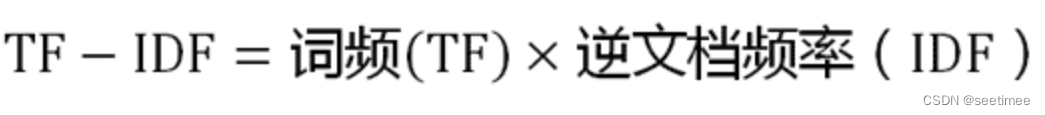

以下有幾個細節點的理解:
- IDF表征的是區分度、稀缺性,用以評估一個單詞在語料庫中的重要程度,一個詞在少數幾篇文檔中出現的次數越多,它的IDF值越高,如果這個詞在大多數文檔中都出現了,這個值就不大了。從公式也可以看出來,由于log函數是單增函數,當文檔總數固定時,包含該詞的文檔數越少,IDF值越大,稀缺性越強。背后的思想是某個詞或者短語在一篇文章中出現的頻率高(TF大),并且在其他文檔中很少出現(IDF也大),則認為該詞或短語具備很好的類別區分能力(TF-IDF就越大)。
- TF刻畫了詞語w對某篇文檔的重要性,IDF刻畫了w對整個文檔集的重要性。TF與IDF沒有必然聯系,TF低并不一定伴隨著IDF高。實際上我們可以看出來,IDF其實是給TF加了一個權重。
優點與不足
TF-IDF算法的優點是簡單快速,結果比較符合實際情況。缺點是,單純以"詞頻"衡量一個詞的重要性,不夠全面,有時重要的詞可能出現次數并不多。這會導致TF-IDF法的精度并不是很高。而且,這種算法無法體現詞的位置信息,出現位置靠前的詞與出現位置靠后的詞,都被視為重要性相同,這是不正確的。(常用的一種解決方法是,對全文的第一段和每一段的第一句話,給予較大的權重。)同時TF-IDF沒有考慮詞頻上限的問題。
BM25
因為在TF-IDF 中去停用詞被認為是一種標準實踐,故TF-IDF沒有考慮詞頻上限的問題(因為高頻停用詞已經被移除了)。而在某些頻率較高的停用詞不被去除的情況下,停用詞的權重會被無意義地放大。比如文中提到的:
Elasticsearch 的?
standard?標準分析器(?string?字段默認使用)不會移除停用詞,因為盡管這些詞的重要性很低,但也不是毫無用處。這導致:在一個相當長的文檔中,像?the?和?and?這樣詞出現的數量會高得離譜,以致它們的權重被人為放大。
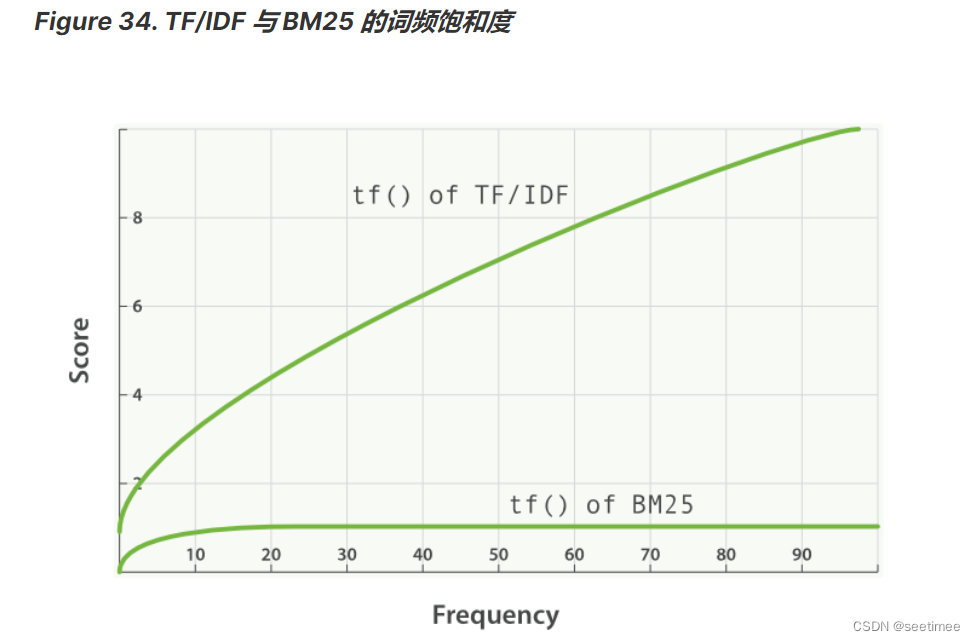
這就是所謂的詞頻飽和度,TF-IDF的詞頻飽和度是線性的,而BM25的詞頻飽和度是非線性的:
公式:
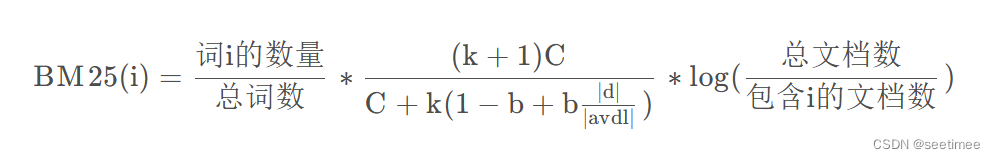
?C = tf = ,k > 0,
,d為文檔的長度,
是文檔的平均長度
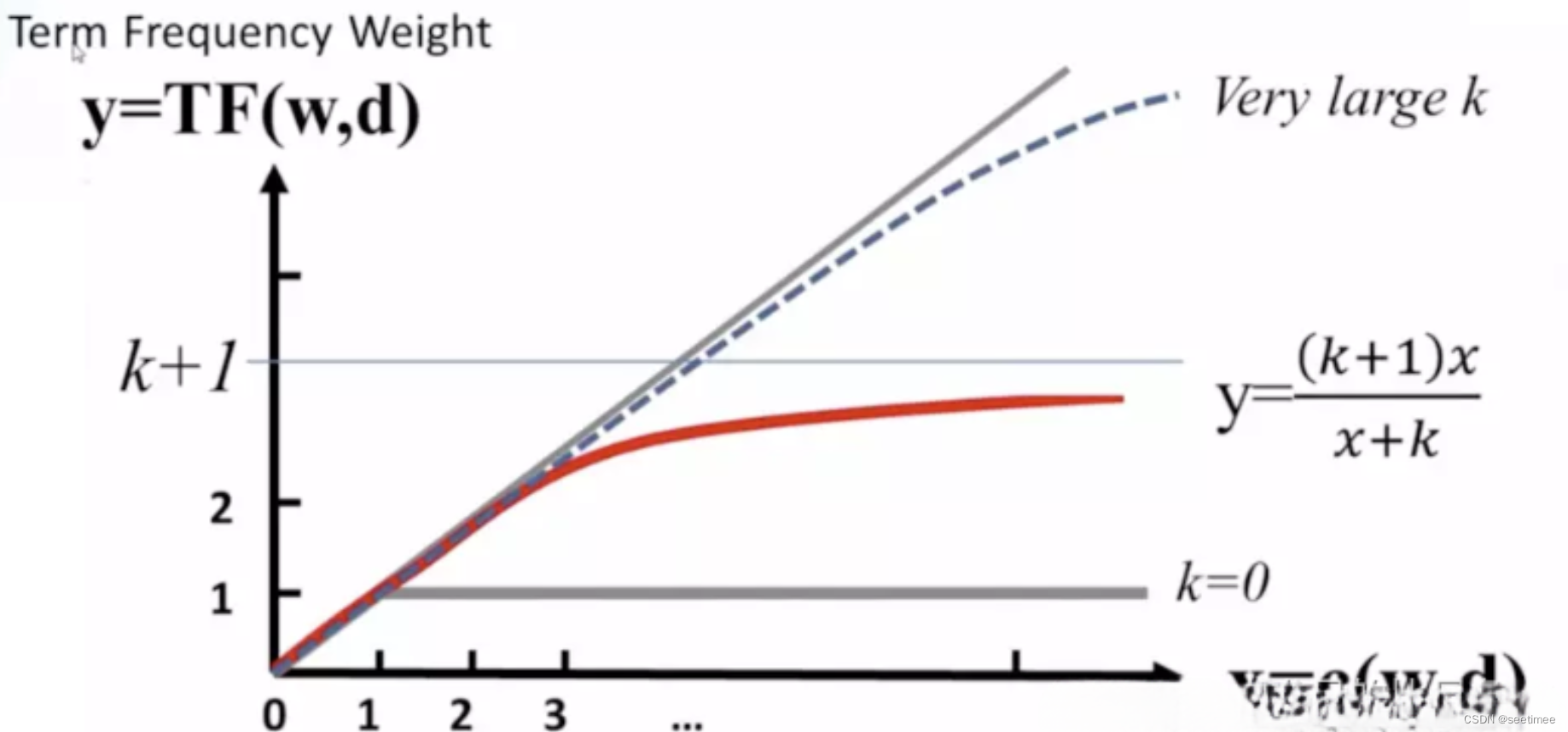
BM25和tfidf的計算結果很相似,唯一的區別在于中多了一項,這一項是用來對tf的結果進行的一種變換。把中的b看成0,那么此時項的結果為
,通過設置一個k,就能夠保證其最大值為1,達到限制tf過大的目的。
即:
?上下同除tf
k不變的情況下,上式隨著tf的增大而增大,上限為k + 1,但是增加的程度會變小,如下圖所示。在一個句子中,某個詞重要程度應該是隨著詞語的數量逐漸衰減的,所以中間項對詞頻進行了一定罰,隨著次數的增加,影響程度的增加會越來越小。通過設置k值,能夠保證其最大值為k + 1,k往往取值1.2。
其變化如下圖(無論k為多少,中間項的變化程度會隨著次數的增加,越來越小):
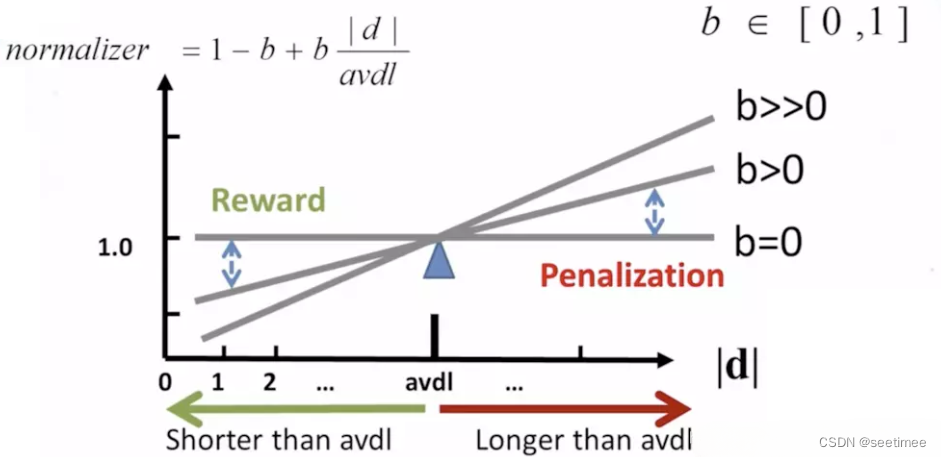
的作用是用來對文本的長度進行歸一化。
例如在考慮整個句子的 tdidf 的時候,如果句子的長度太短,那么計算的總的 tdidf 的值是要比長句子的 tdidf 的值要低的。所以可以考慮對句子的長度進行歸一化處理。
可以看到,當句子的長度越短, 的值是越小,作為分母的位置,會讓整個第二項越大,從而達到提高短文本句子的 BM25 的值的效果。當 b 的值為 0,可以禁用歸一化,b 往往取值 0.75。
?





)








】)




