概述
論文地址:https://arxiv.org/pdf/2402.13217.pdf
視頻是我們觀察世界的生動窗口,記錄了從日常瞬間到科學探索的各種體驗。在這個數字時代,視頻基礎模型(ViFM)有可能分析如此海量的信息并提取新的見解。迄今為止,視頻理解領域的研究確實取得了長足進步,但構建真正的基礎視頻模型,嫻熟地處理外觀和運動問題,仍是一個尚未實現的領域。
因此,本文提出了創新型通用視頻編碼器VideoPrism,旨在解決從視頻分類到定位、搜索、字幕和問題解答等所有視頻理解任務。通過廣泛的評估(包括計算機視覺數據集以及神經科學和生態學等科學學科),VideoPrism 以最小的適應度展示了最先進的性能。下圖是 VideoPrism 的概覽。

在 VideoPrism 的開發過程中,我們強調了預訓練數據的重要性。理想情況下,預訓練數據應該是來自世界各地的具有代表性的視頻樣本,但實際上,許多視頻并不附帶描述內容的文本,或者噪音非常大。因此,VideoPrism 通過收集 3,600 萬對高質量視頻和字幕以及 5.82 億個噪聲視頻片段,充分利用了這些數據。
建模從視頻和語言之間的意義對比學習開始。然后,它使用純視頻數據,結合全局和局部提煉、標記洗牌,并通過屏蔽視頻建模進一步改進。這種獨特的兩階段方法是 VideoPrism 在同時關注視頻外觀和運動的任務中的優勢所在。
通過在四大理解任務類別中進行廣泛評估,包括從網絡視頻、腳本表演到科學實驗的 33 種不同基準,證明了這種方法的有效性 VideoPrism 在其中 30 種基準中的表現優于現有的視頻基礎架構模型 (ViFM)。在其中 30 項基準測試中,VideoPrism 的表現遠遠超過了現有的視頻基礎架構模型(ViFM),證明了其卓越的性能。結果如下圖所示。
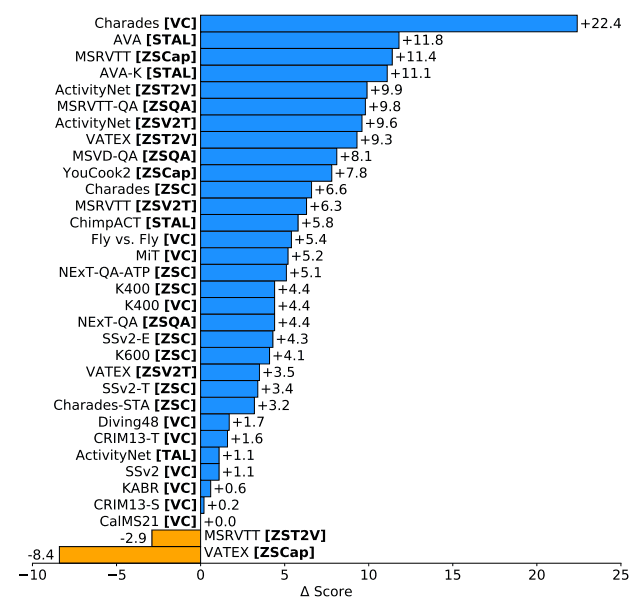
這表明 VideoPrism 具有 "非常 "好的概括能力。
技術
VideoPrism 采用創新的視頻理解方法。其核心是一個豐富的預訓練數據集,包含 3600 萬個片段。這些片段是從 3,600 萬個視頻中提取出來的,并配有高質量的人工字幕。此外,2.75 億個視頻中的 5.82 億個片段包含帶噪聲的平行文本。這種預訓練數據集在視頻基礎模型(ViFM)中是前所未有的,但與圖像基礎模型所用的數據相比仍然較少。為了填補這一空白,本文還收集了其他數據,包括 ASR、元數據和通過大規模多模態模型生成的噪聲文本。

值得注意的是,在預訓練和后續訓練中都沒有使用評估基準的訓練集。這可以防止模型針對特定的評估基準進行過度優化。此外,預訓練語料庫與評估基準視頻是去重復的,以避免數據泄露。
在模型架構方面,VideoPrism 基于視覺轉換器(ViT),但同時考慮了空間和時間因素。這確保了在輸出標記序列中保留空間和時間維度,以支持需要細粒度特征的下游任務:VideoPrism-g 采用了擁有 10 億個參數的 ViT-giant 網絡,而較小的 ViT-Base 網絡則采用了更小的 ViT-Giant 網絡。VideoPrism-B 采用較小的 ViT-Base 網絡。
VideoPrism 采用獨特的兩階段方法,通過利用視頻和文本對以及純視頻數據來學習純視頻數據。由于大型預訓練數據集中的文本在某些視頻中通常會出現噪聲,因此 VideoPrism 專注于純視頻數據,以捕捉視頻的深層含義。
第一階段:在這一階段,對比學習用于使視頻編碼器與文本編碼器同步。這一過程根據視頻-文本對的相似性得分,通過最小化對稱交叉熵損失,從語言中引導視頻編碼器學習豐富的視覺語義。這一階段產生的模型為下一階段的學習提供了語義視頻嵌入。
第2 階段:第 1 階段中僅基于視覺文本數據的學習面臨著一個問題,即文本描述包含噪音,而且往往只捕捉外觀而非運動。第二階段的重點是從純視頻數據中學習外觀和運動信息。這里引入了一種新的標記洗牌方案以及全局和每個標記的蒸餾損失,作為對遮蔽視頻建模的改進。這樣,模型就能在保留語義知識的基礎上,根據遮蔽視頻學習預測第一階段的嵌入。
通過這種兩階段方法,VideoPrism 正在構建一個底層視頻編碼器,它可以更好地理解視頻并捕捉外觀和運動的語義。
試驗
對 VideoPrism 進行了評估,以證明其在各種以視頻為中心的理解任務中的性能和多功能性。這些任務分為四類:第一類是一般視頻理解。這包括分類和時空定位;第二類是零鏡頭視頻文本檢索;第三類是零鏡頭視頻字幕和質量保證;第四類是用于科學研究的計算機視覺;第四類是用于視頻分析的視頻理解。
在所有實驗中,VideoPrism 都被固定為視頻編碼器,只訓練特定任務所需的組件。這樣就可以評估 VideoPrism 的多功能性及其獨立于特定任務模型的能力。此外,VideoPrism 方法在視頻分析中特別有用,因為視頻編碼的成本可以分攤到多個任務中,因此很難進行昂貴的微調。
首先將其與視頻理解基準 VideoGLUE 中的先進模型進行比較。評估范圍包括以外觀為重點的動作識別(VC(A))、動作豐富的動作識別(VC(M))、多標簽視頻分類(VC(ML))、時間動作定位(TAL)、時間和空間動作定位(STAL)。這項研究使用了八個具有代表性的數據集,包括

從 ViT-B 到 ViT-g,隨著模型大小的增加,VideoPrism 的性能顯著提高。這意味著 VideoPrism 在單一編碼器中結合了對不同視頻源的魯棒性,如外觀和運動線索、空間和時間信息、網絡視頻和腳本性能。
然后,我們使用 MSRVTT、VATEX 和 ActivityNet 這三個關鍵基準來評估 VideoPrism 的零鏡頭視頻文本檢索性能。零鏡頭視頻分類任務也是對 Kinetics-400、Charades、SSv2-Temporal、SSv2-Events 和 NExT-QA 的 ATP-Hard 子集的挑戰。

作為一項重要成果,VideoPrism 在多項基準測試中創造了新的最佳記錄,并在特別具有挑戰性的數據集上取得了顯著改進,VideoPrism-B 的表現優于現有的大型模型。此外,與使用域內數據和其他模式預先訓練的模型相比,VideoPrism 的表現同樣出色,甚至更好。這些結果表明,VideoPrism 在零鏡頭搜索和分類任務中具有強大的泛化能力。

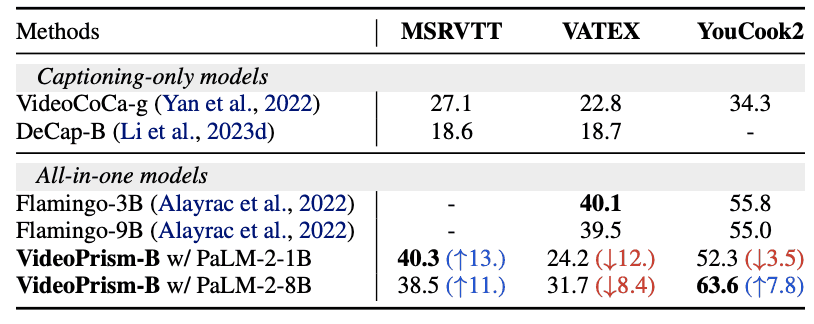
此外,MSRVTT、VATEX 和 YouCook2 等標準視頻封頂數據集以及 MSRVTT-QA、MSVD-QA 和 NExT-QA 等視頻質量保證基準被用于視頻封頂和質量保證任務,并在零鏡頭設置下進行性能 評估。評估。請注意,這些模型并未針對字幕和質量保證任務進行專門調整。
結果如下表所示。盡管結構簡單,適配器參數數量有限,但它仍具有競爭力,在除 VATEX 之外的大多數評估中都取得了優異成績。這表明,VideoPrism 編碼器在視頻到語言的生成任務中具有廣泛的通用能力。

現有的視頻分析基準主要側重于以人為中心的數據,而 VideoPrism 的功能及其在科學應用方面的潛力則是利用科學數據集對各種視頻集進行探索。分析涵蓋了廣泛的學科,包括行為研究、行為神經科學、認知科學和生態學。本研究首次嘗試將 ViFM 應用于科學數據集,結果表明 ViFM 的性能與專業模型相當,甚至更好。這
該分析包括在科學實驗中捕獲的標注了專業知識的大型視頻數據集,其中包括蒼蠅、小鼠、黑猩猩和肯尼亞野生動物。所有這些數據集都為行為視頻分類或時空動作定位進行了詳細注釋。其中,CRIM13 數據集分析的是籠子側面和上方視角的視頻。

結果表明,使用共享的凍結編碼器可以獲得等同于或優于專用于個別任務的特定領域模型的性能。尤其是在基本模型中,VideoPrism 的表現優于專家模型。此外,擴展模型可大幅提高所有數據集的性能。這些結果表明,ViFMs 有潛力在多個領域顯著加速視頻分析。
總結
本文介紹的 VideoPrism 是一種基本的視頻編碼器,可在視頻理解領域實現最先進的技術。它專注于數據和建模方法,建立了自己的大型預訓練數據集和有效提取視頻外觀和運動信息的預訓練策略。與其他模型相比,它在各種基準測試中取得了最佳性能,并顯示出極高的泛化能力。
視頻理解技術的進步有可能加速從科學研究到教育、機器人、醫療保健和內容推薦等領域的發展。這些技術有望促進科學發現、豐富學習體驗、增強安保和安全,并實現反應更靈敏的互動系統。
然而,在現實世界中使用這些模型之前,還必須采取措施防止潛在的偏見和濫用。當務之急是減少算法偏差、保護隱私并遵守負責任的研究規范。論文指出,必須繼續在社區內推動關于這些新發展的公開討論,以便以負責任的方式從這項技術中獲益。






—Vue 3自定義指令的藝術:實戰中的最佳實踐)







![[我靠升級逆襲成為大師]韓漫日漫無刪減完整版,免費在線觀看漫畫](http://pic.xiahunao.cn/[我靠升級逆襲成為大師]韓漫日漫無刪減完整版,免費在線觀看漫畫)

:Nuitka庫)


