【實戰場景】記一次UAT jvm故障排查經歷
- 開篇詞:
- 干貨篇:
- 1.查看系統資源使用情況
- 2.將十進制進程號轉成十六進制
- 3.使用jstack工具監視進程的垃圾回收情況
- 4.輸出指定線程的堆內存信息
- 5.觀察日志
- 6.本地環境復現
- 總結篇:
- 我是杰叔叔,一名滬漂的碼農,下期再會!
開篇詞:
故障背景是客服中心通話歷史分表4季度,單表200w+,查詢一年的數據量,大分頁(查詢第20w頁的10條數據)查詢多次,tomcat卡死,一段時間后,后臺其他定時任務,kafaka消費線程恢復正常,tomcat web容器依舊高cpu,具卡無比。
干貨篇:
1.查看系統資源使用情況
top -H -p 49339
解釋:查看進程49339進程的實時系統資源使用情況,“-H”表示查看進程中所有線程資源占用情況; “-p”指用來指定具體進程號
2.將十進制進程號轉成十六進制
printf “%x \n” 49339
解釋:轉換的目的是讓這個線程ID能和jstack輸出的線程ID匹配上,因為jstack輸出的是十六進制的線程ID
3.使用jstack工具監視進程的垃圾回收情況
jstat -gc 49339 3 5
解釋:通過jstat工具查看jvm 垃圾回收情況,“-gc”指定要監視的內容為垃圾回收情況;“3”每隔三秒輸出一次監視結果;“5”一共輸出5次監視結果。
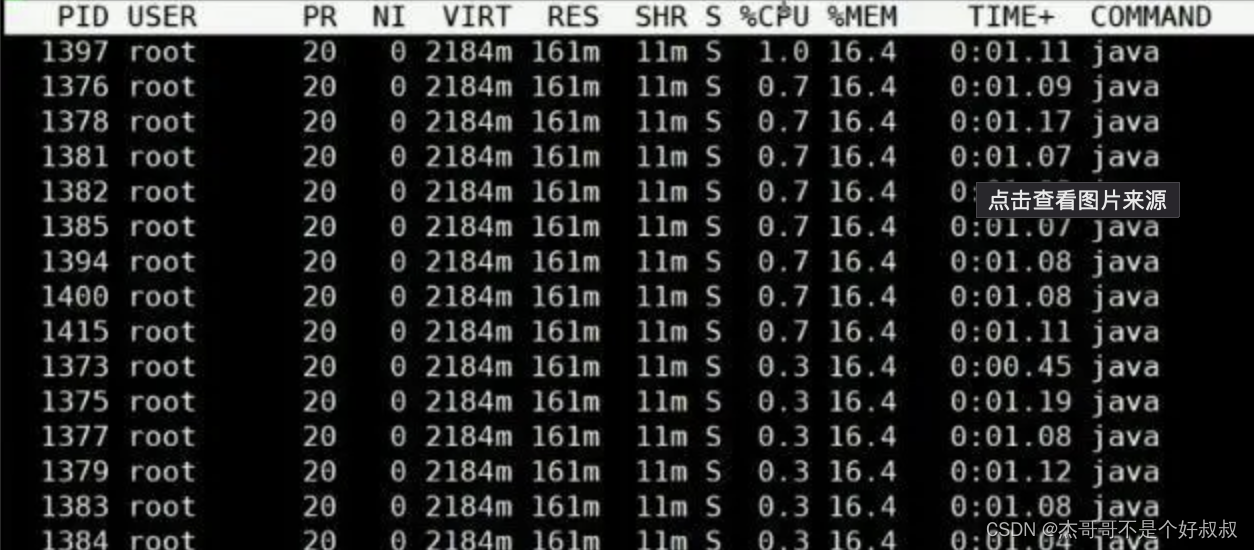
其中各參數代表的含義:
- S0C (Survivor space 0 capacity):第一個幸存區(Survivor space)的容量(以字節為單位)。幸存區用于存放垃圾收集后存活的對象。
- S1C (Survivor space 1 capacity):第二個幸存區的容量(以字節為單位)。在大多數 JVM 實現中,幸存區有兩個,用于在不同的垃圾收集周期之間切換。
- S0U (Survivor space 0 utilization):第一個幸存區當前已使用的空間大小(以字節為單位)。
- S1U (Survivor space 1 utilization):第二個幸存區當前已使用的空間大小(以字節為單位)。
- EC (Eden space capacity):Eden 區的容量(以字節為單位)。Eden 區是 Java 堆的一部分,用于存放新生成的對象。
- EU (Eden space utilization):Eden 區當前已使用的空間大小(以字節為單位)。
- OC (Old space capacity):老年代(Old Generation)的容量(以字節為單位)。老年代用于存放存活時間較長的對象。
- OU (Old space utilization):老年代當前已使用的空間大小(以字節為單位)。
- MC (Metaspace capacity):元空間(Metaspace,Java 8 引入以替代永久代)的容量(以字節為單位)。元空間用于存放類的元數據。
- MU (Metaspace utilization):元空間當前已使用的空間大小(以字節為單位)。
- CCSC (Compressed class space capacity):壓縮類空間(Java 8+ 中使用)的容量(以字節為單位)。這個空間用于存放類的元數據,但與元空間分開管理。
- CCSU (Compressed class space utilization):壓縮類空間當前已使用的空間大小(以字節為單位)。
- YGC (Young GC count):年輕代垃圾收集的次數。
- YGCT (Young GC time):年輕代垃圾收集所花費的總時間(以秒為單位)。
- FGC (Full GC count):完全垃圾收集(Full GC,也稱作老年代垃圾收集)的次數。
- FGCT (Full GC time):完全垃圾收集所花費的總時間(以秒為單位)。
- GCT (Total GC time):垃圾收集所花費的總時間(以秒為單位),包括年輕代和完全垃圾收集的時間。
請注意,具體的輸出參數可能會因 JVM 的版本和配置(如是否啟用了壓縮指針等)而有所不同。此外,對于 JDK 11 及更高版本,元空間(Metaspace)取代了永久代(PermGen space),因此相關的參數(如 PC 和 PU)在較新版本的 JVM 中不再出現。
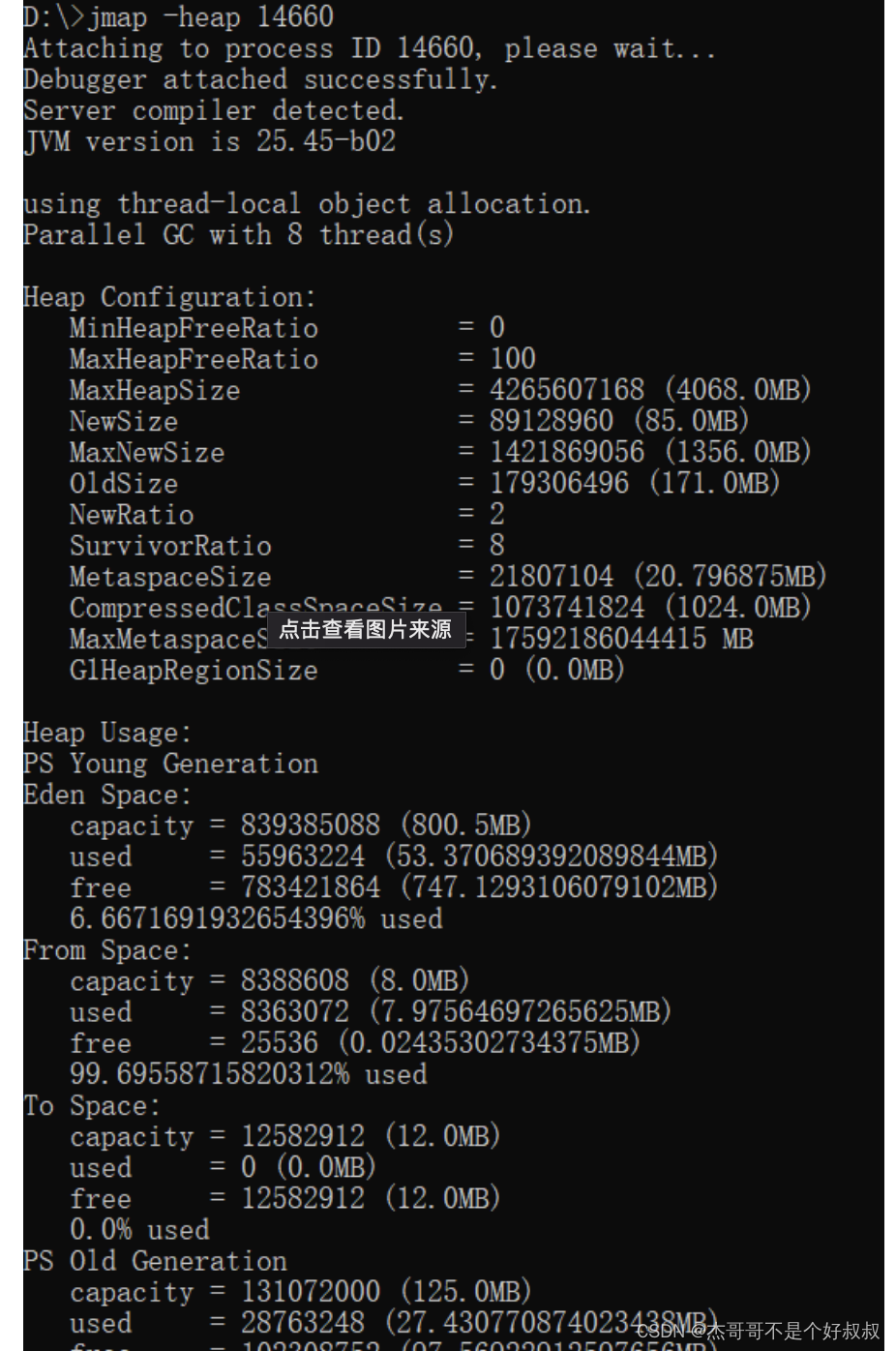
4.輸出指定線程的堆內存信息
jmap -heap 49339
解釋:輸出指定線程的堆內存信息
jstack -l 49339|grep c22a -A 20
解釋:時候用jstack工具來輸出java進程的線程堆棧信息,并查找包含字符串“c22a”的行,打印其后面的20行
“-l”:指定輸出java進程的線程ID;“-A 20”:打印匹配行及其后面的20行
5.觀察日志
發現kafka消費線程占用cpu較高,kafka consumer正常epollWait等待kafaka數據,無其他特別異常信息,暫時跳過
6.本地環境復現
更換jdbc連接池至druid,通過dashboard排查分表后的真實sql耗時,中等數據量時,由于分表的存在,limit 20w,20w+10會被重寫0,20W+10,以便跨表數據內存排序,數據量大,便造成了慢查詢,有可能導致OOM
總結篇:
以下是大致的排查JVM問題的思路:
- 初步觀察和監控
查看系統指標:使用系統監控工具(如Linux的top命令或Windows的任務管理器)查看CPU、內存和網絡IO等關鍵指標。
觀察JVM監控工具:使用JDK自帶的工具如jConsole、VisualVM或第三方工具(如Arthas)來遠程連接并監控JVM的內存使用趨勢、線程狀態、垃圾回收活動等。 - 確定問題類型
內存問題:觀察是否出現OutOfMemoryError(OOM)錯誤,或者內存使用量異常增長。
CPU問題:查看CPU使用率是否過高,特別是某個或某些Java線程的CPU占用率異常。
線程問題:檢查是否存在死鎖、線程饑餓或線程阻塞等問題。
垃圾回收問題:分析垃圾回收日志,查看垃圾回收的頻率、時間和類型,判斷是否存在頻繁的Full GC或GC時間過長等問題。 - 使用診斷工具
jstack:用于打印Java線程的堆棧跟蹤信息,幫助定位線程問題,如死鎖、線程阻塞等。
示例命令:jstack ,其中是Java進程的進程ID。
jmap:用于生成堆內存快照和查詢堆內存使用情況。
示例命令:jmap -heap 查看堆內存使用情況,jmap -dump:live,format=b,file=.hprof 生成堆內存快照。
jstat:用于監視JVM中類的加載、內存、垃圾收集、JIT編譯等運行時數據。
示例命令:jstat -gc 1000每1000毫秒打印一次GC信息。
jcmd(JDK 1.8+):集成了多個JDK診斷命令的功能,用于執行更復雜的診斷任務。
示例命令:jcmd Thread.print打印線程信息。 - 分析日志和堆內存快照
分析GC日志:通過GC日志分析垃圾回收的頻率、時間、類型和原因,判斷是否存在內存泄漏、堆內存設置不合理等問題。
分析堆內存快照:使用MAT(Memory Analyzer Tool)等內存分析工具分析堆內存快照,查找內存泄漏的源頭、大對象占用等。
查看應用程序日志:檢查應用程序日志以獲取更多關于錯誤和異常的上下文信息。 - 定位和解決問題
代碼優化:根據分析結果優化代碼,減少內存占用、避免內存泄漏、優化數據結構等。
JVM參數調整:調整JVM啟動參數,如堆內存大小(-Xms,-Xmx)、垃圾回收器類型(-XX:+UseG1GC)等,以改善JVM性能。
升級JDK版本:如果問題是由于JDK的已知bug引起的,考慮升級到更高版本的JDK。 - 驗證和監控
驗證修復:在開發或測試環境中驗證修復是否有效,確保問題得到解決。
持續監控:在問題解決后,持續監控系統性能,確保沒有新的問題出現。
通過以上步驟,可以系統地排查和解決JVM問題,提高系統的穩定性和性能。需要注意的是,排查JVM問題可能需要一定的經驗和耐心,因為問題可能由多種因素引起,需要綜合考慮各種信息來找到問題的根源。



)



)


![[ALSA]從零開始,使用ALSA驅動播放一個音頻](http://pic.xiahunao.cn/[ALSA]從零開始,使用ALSA驅動播放一個音頻)









