一、Redis
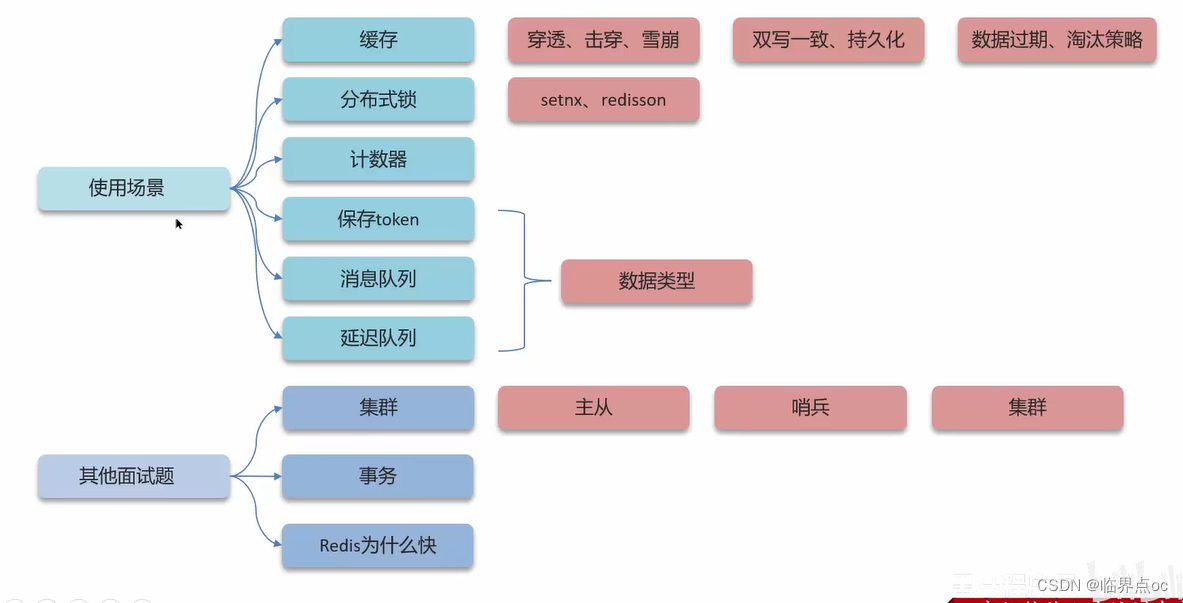
1. 使用場景
(1)Redis的數據持久化策略有哪些
RDB:全稱Redis Database Backup file(Redis數據備份文件),也被叫作Redis數據快照。簡單來說就是把內存中的所有數據都記錄到磁盤中。當Redis實例故障重啟后,從磁盤讀取快照文件,恢復數據。
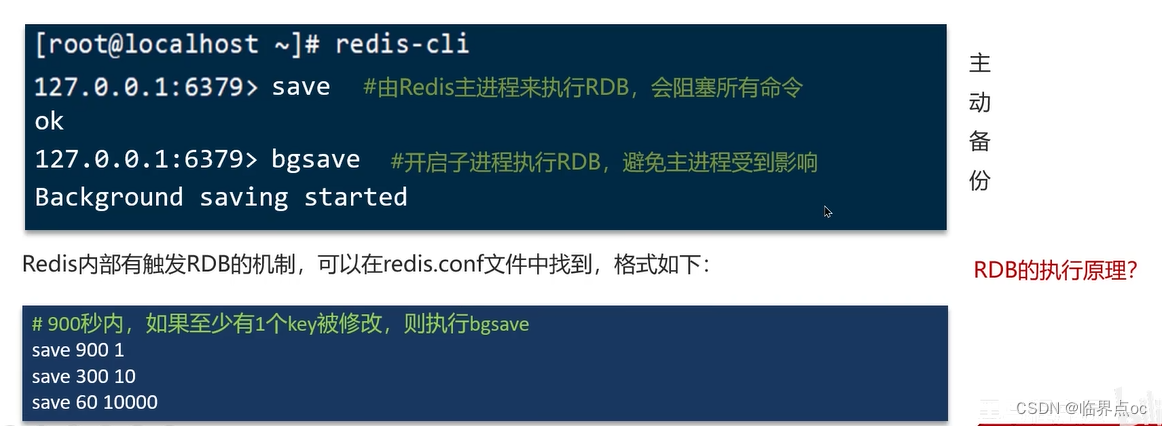
RDB的執行原理?
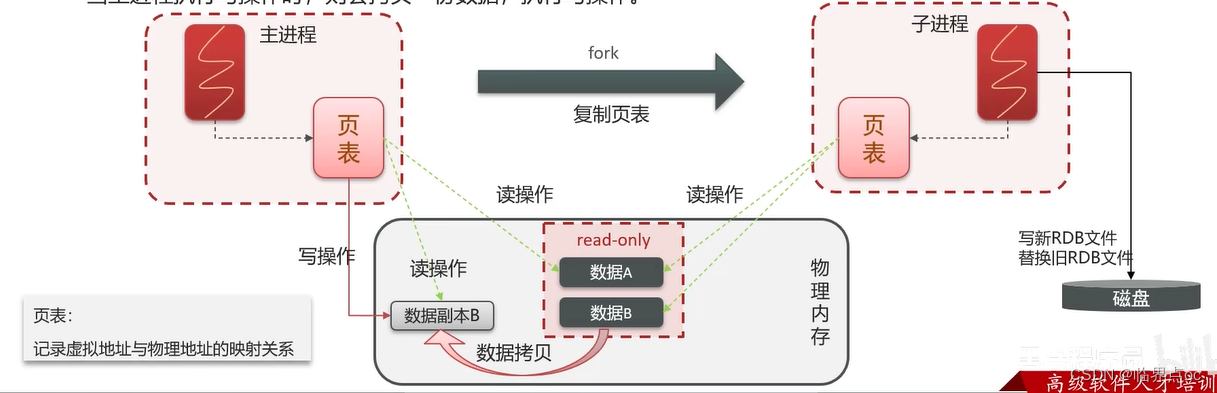
bgsave開始時會fork主進程得到子進程,子進程共享主進程的內存數據。完成fork后讀取內存數據并寫入RDB文件。fork采用的是copy-on-write技術:
當主進程執行讀操作時,訪問共享內存;
當主進程執行寫操作時,則會拷貝一份數據,執行寫操作。
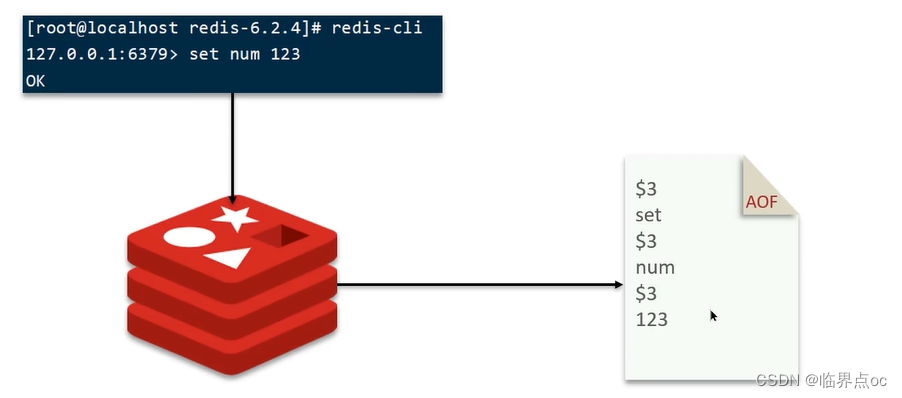
AOF
AOF全稱為Append Only File(追加文件)。Redis處理的每一個寫命令都會記錄在AOF文件,可以看做是命令日志文件。



(2)什么是緩存穿透,怎么解決
緩存穿透:查詢一個不存在的數據,mysql查詢不到數據也不會直接寫入緩存,就會導致每次請求都查數據庫
解決方案一:緩存空數據,查詢返回的數據為空,扔把這個空結果進行緩存。優點:簡單;缺點:消耗內存,可能會發生不一致的問題
解決方案二:布隆過濾器
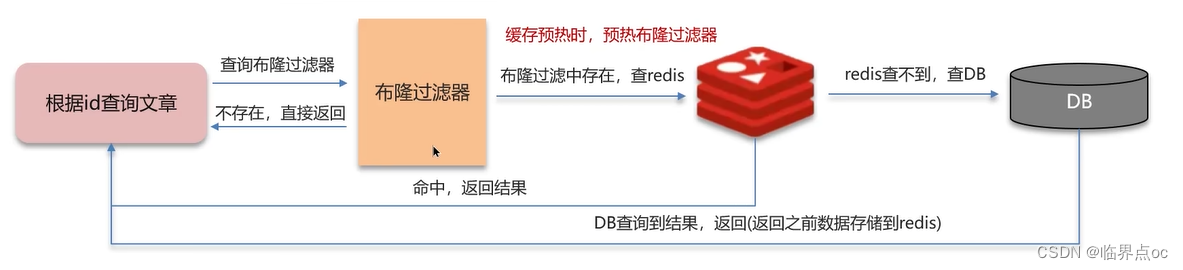

(3)什么是布隆過濾器
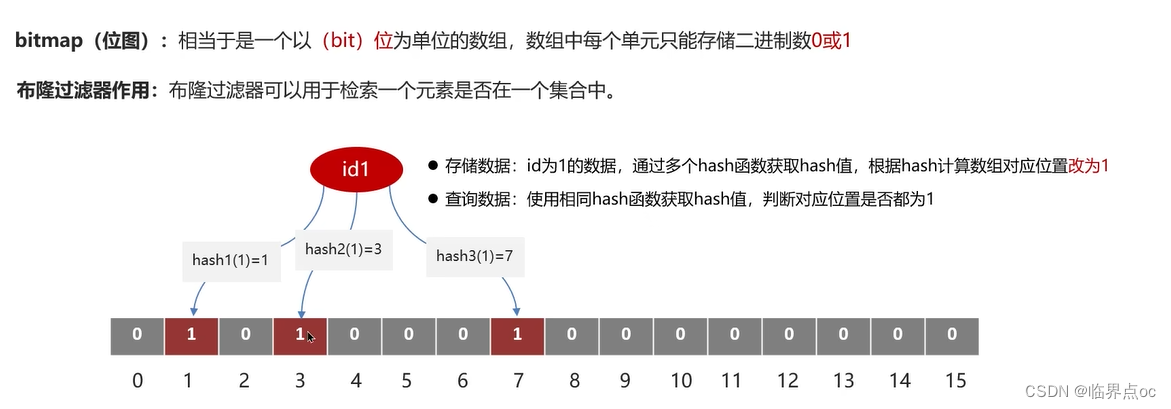
誤判率:數組越小誤判率越大,數組越大誤判率就越小,但是同時帶來了更多的內存消耗。
優點:內存占用較少,沒有多余key;缺點:實現復雜,存在誤判
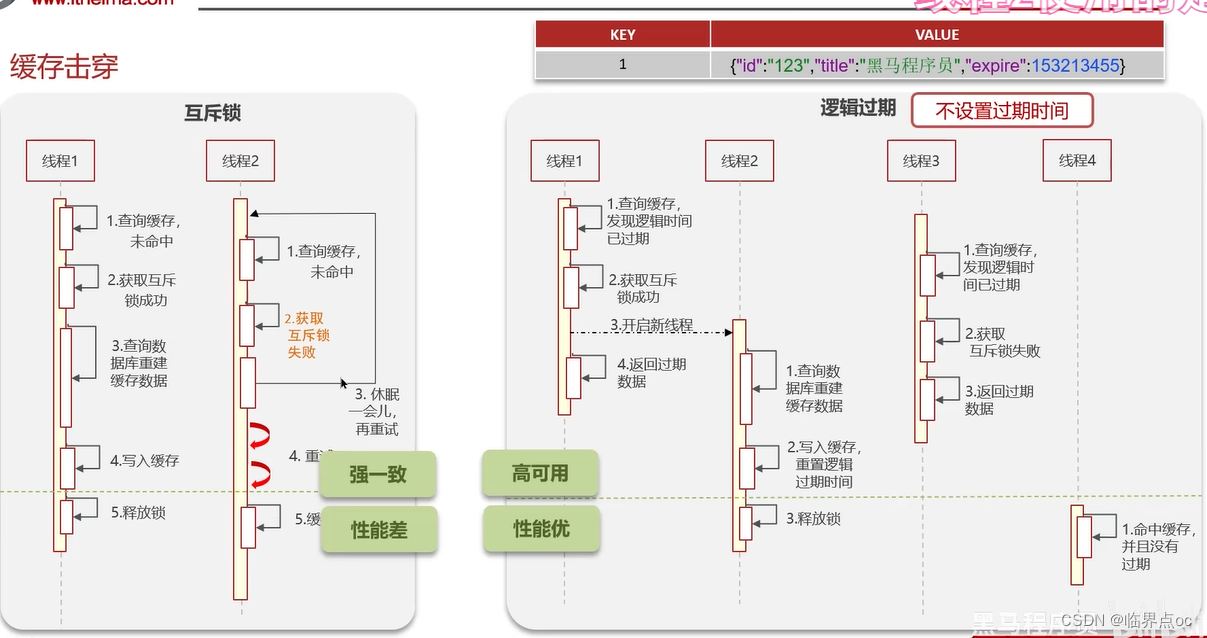
(4)什么是緩存擊穿,怎么解決
緩存擊穿:給某一個key設置了過期時間,當key過期的時候,恰好這個時間點對這個key有大量的并發請求過來,這些并發的請求可能會瞬間把DB壓垮

解決方案一:互斥鎖,強一致,性能差
解決方案二:邏輯過期,高可用,性能優,不能保證數據絕對一致
(5)什么是緩存雪崩,怎么解決
緩存雪崩實質同一時間段大量的緩存key同時失效或者Redis服務宕機,導致大量請求到達數據庫,帶來巨大壓力。


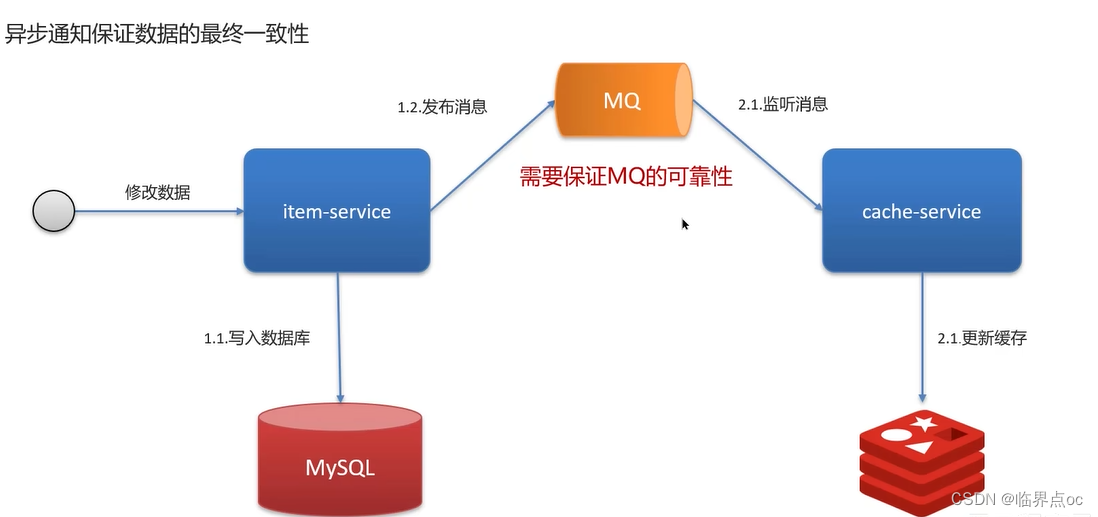
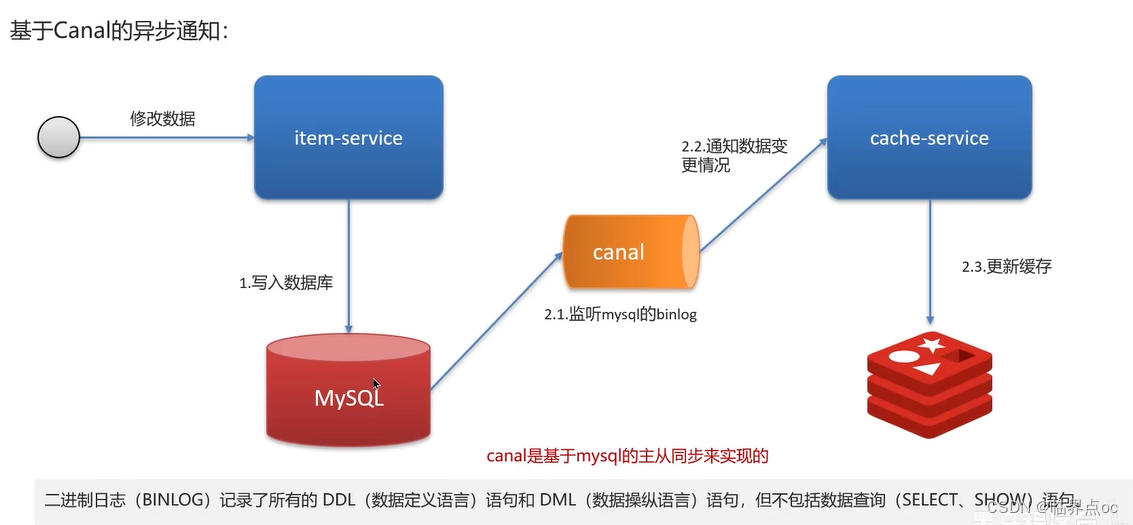
(6)redis雙寫一致性問題(redis作為緩存,mysql的數據如何與redis進行同步)
雙寫一致性:當修改了數據庫的數據也要同時更新緩存的數據,緩存和數據庫的數據要保持一致
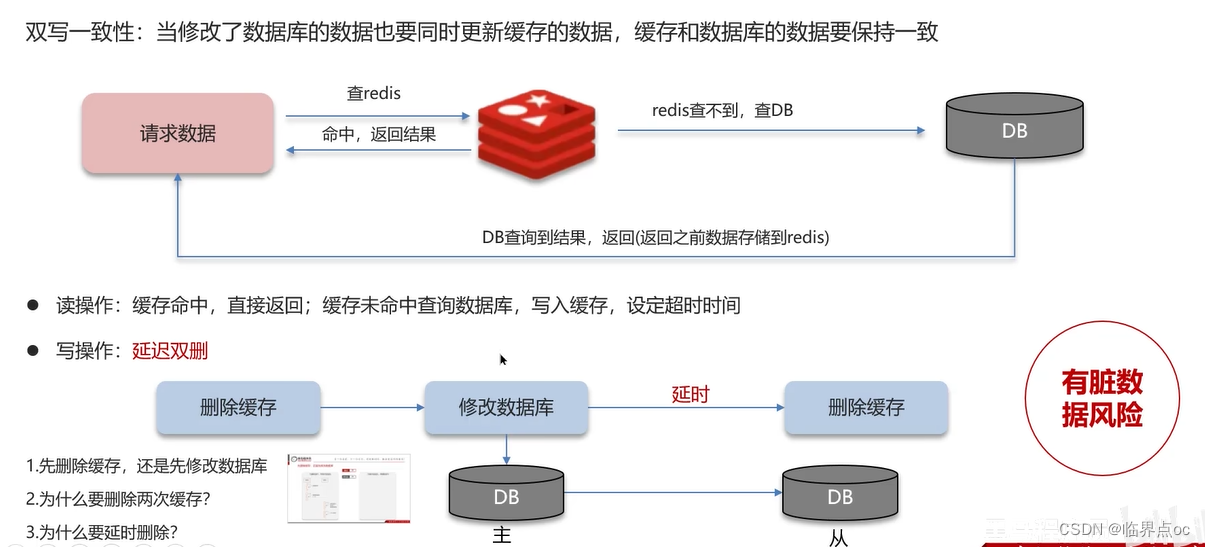
先刪除緩存,還是先修改數據庫?
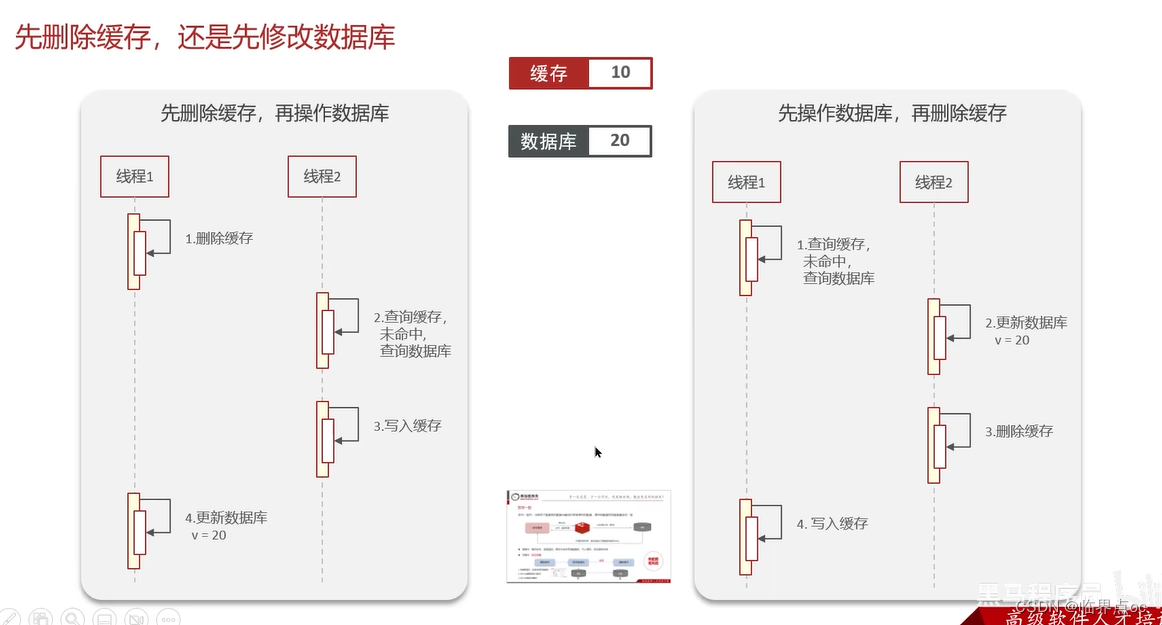
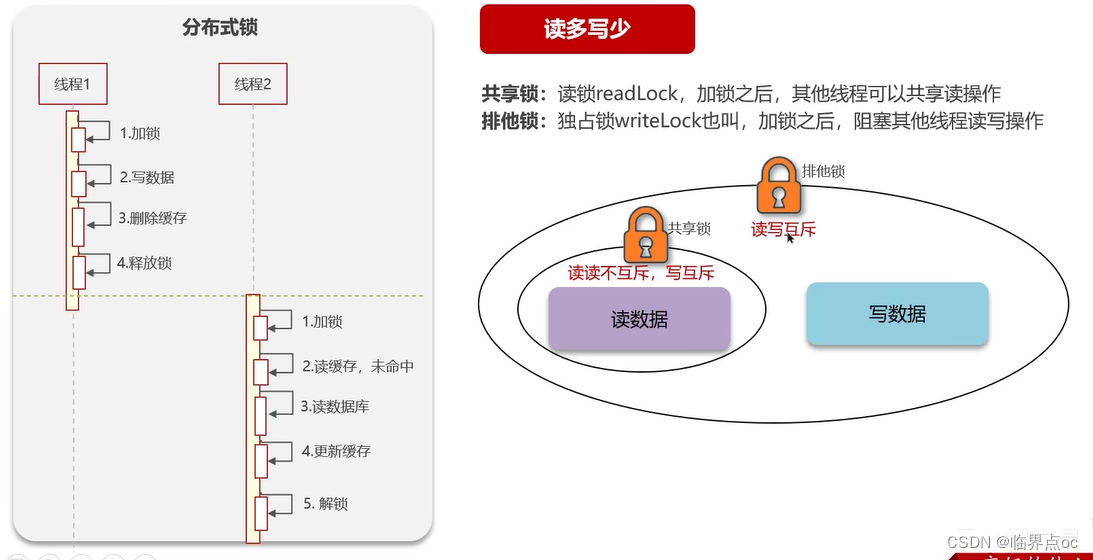

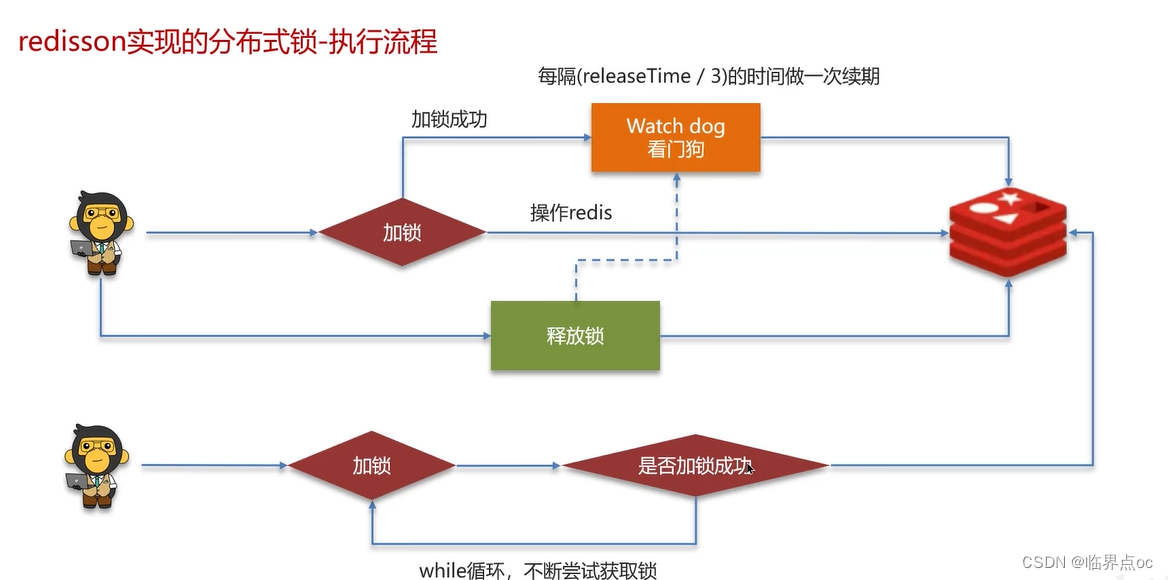
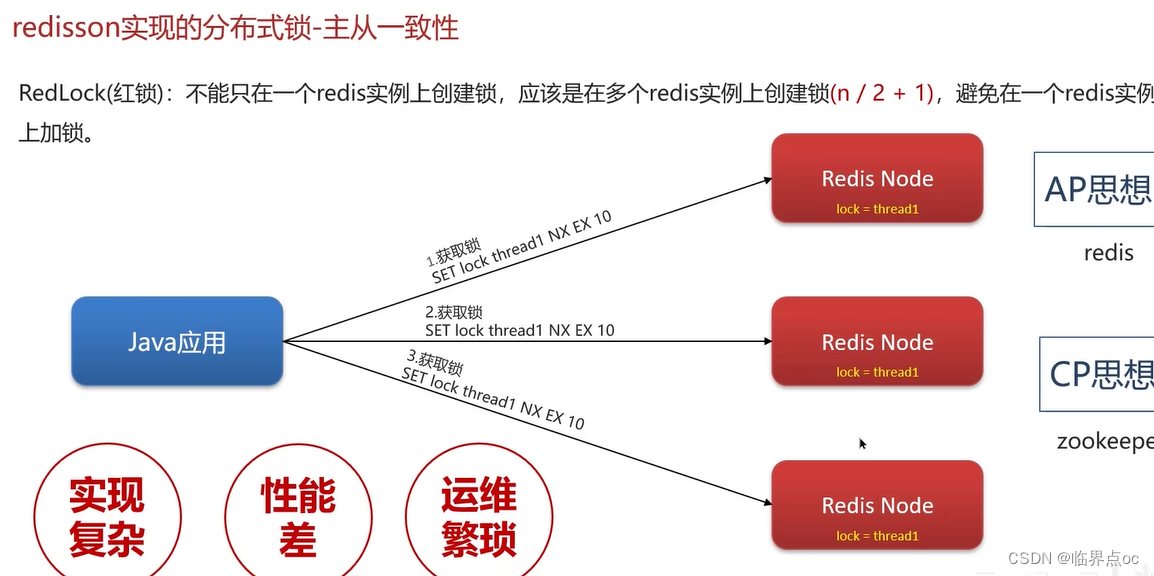
(7)Redis分布式鎖如何實現

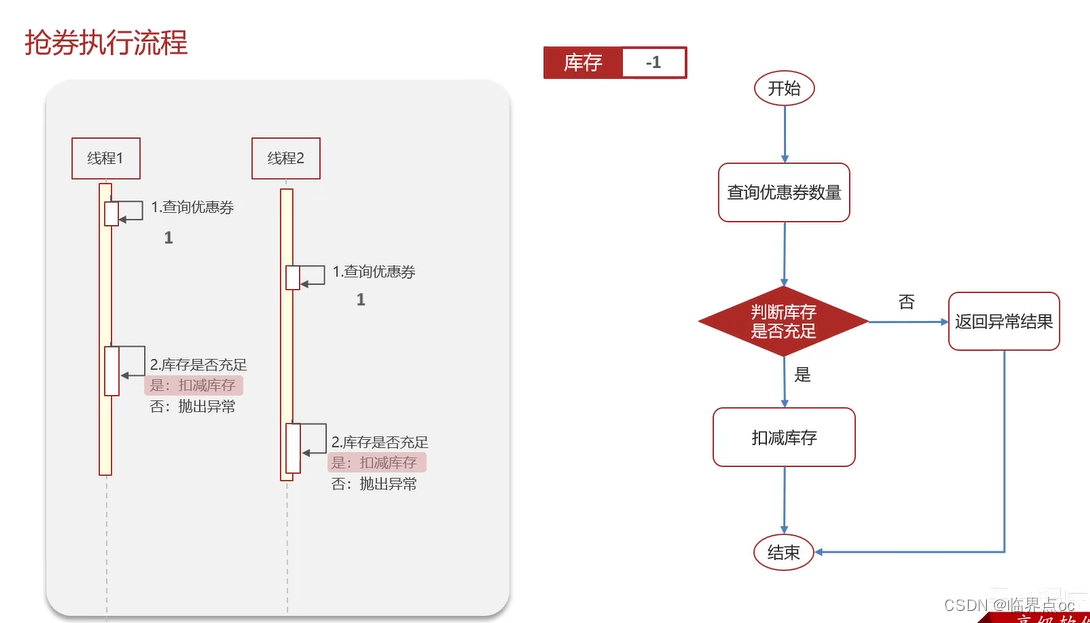
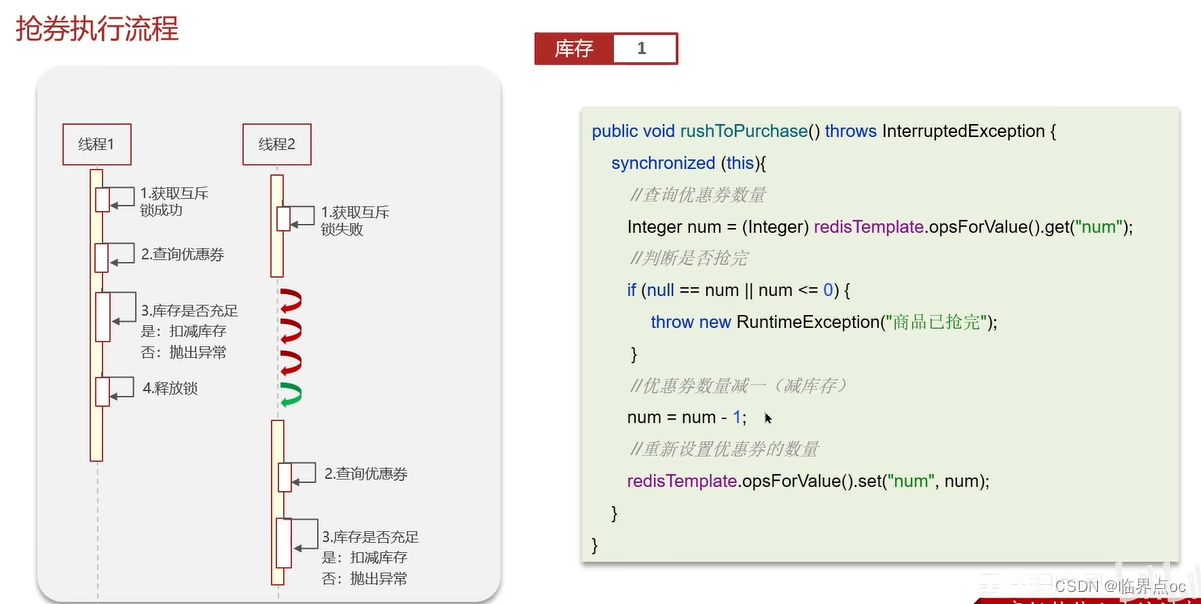
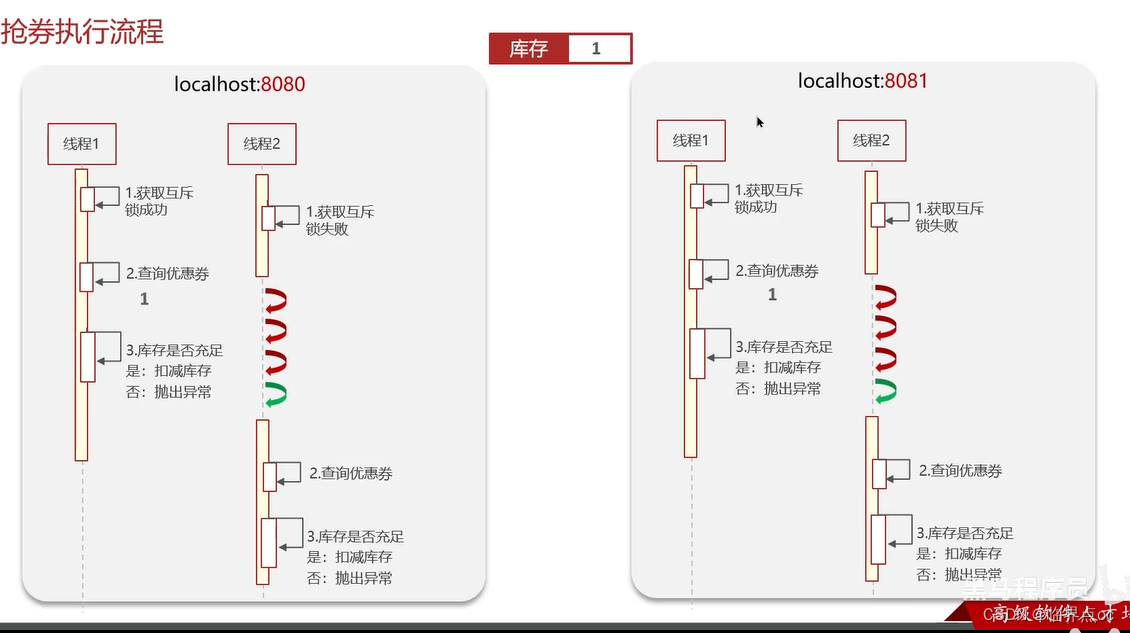
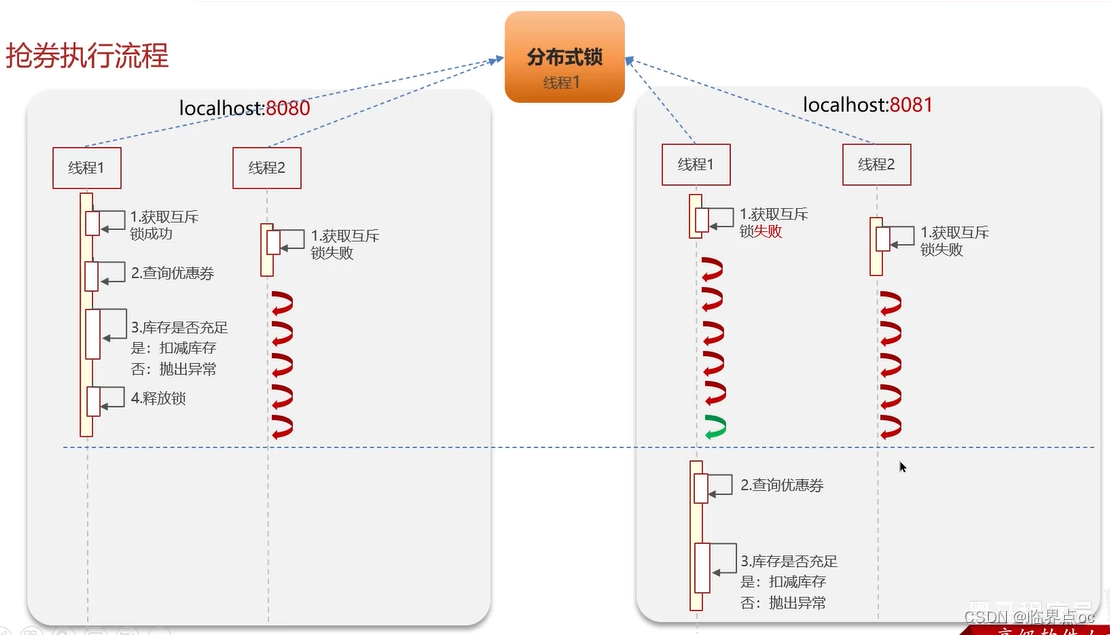
(8)Redis實現分布式鎖如何合理的控制鎖的有效時長




(9)Redis的數據過期策略有哪些
惰性刪除:設置key過期時間后,我們不去管它,當需要該key時,我們再檢查其是否過期,如果過期,我們就刪掉它,反之返回該key

優點:對CPU友好,只會在使用該key時才會進行過期檢查,對于很多用不到的key不用浪費時間進行過期檢查
缺點:對內存不友好,如果一個key已經過期,但是一直沒有使用,那么該key就會一直存在內存中,內存永遠不會釋放。
定期刪除:每隔一段時間,我們就會對一些key進行檢查,刪除里面過期的key(從一定數量的數據庫中取出一定數量的隨機key進行刪除,并刪除其中的過期key)。


(10)Redis的數據淘汰策略有哪些
數據的淘汰策略:當Redis中的內存不夠用時,此時再向Redis中添加新的key,那么Redis就會按照某一種規則將內存中的數據刪除掉,這種數據的刪除規則則被稱之為內存的淘汰策略。




2. 面試題
(1)Redis集群有哪些方案
在Redis中中提供的集群方案總共有三種:
- 主從復制
- 哨兵模式
- 分片集群
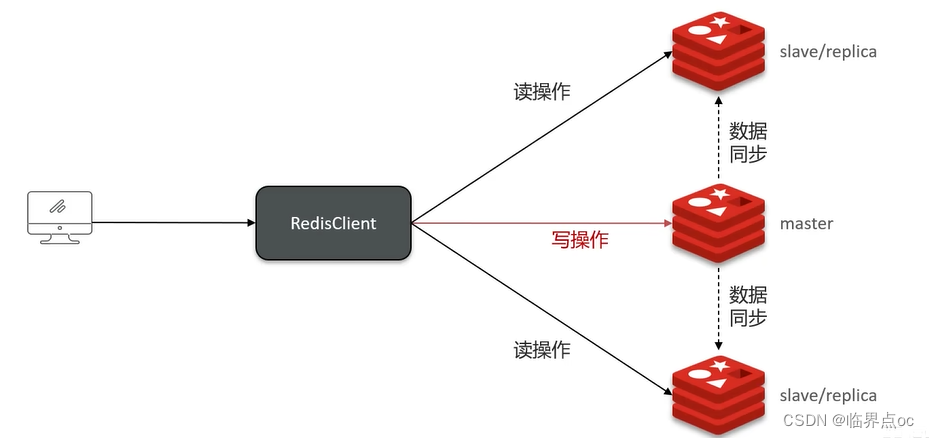
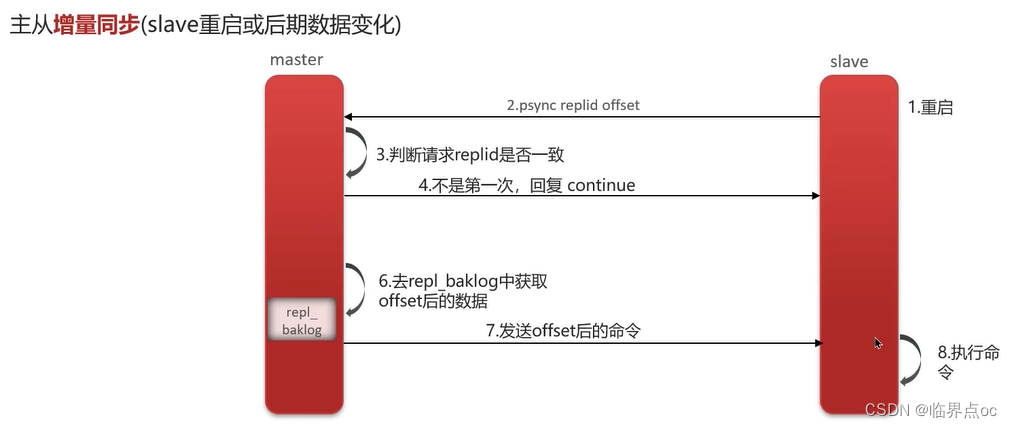
(2)什么是Redis主從同步
單結點Redis的并發能力是有上限的,要進一步提高Redis的并發能力,就需要搭建主從集群,實現讀寫分離。


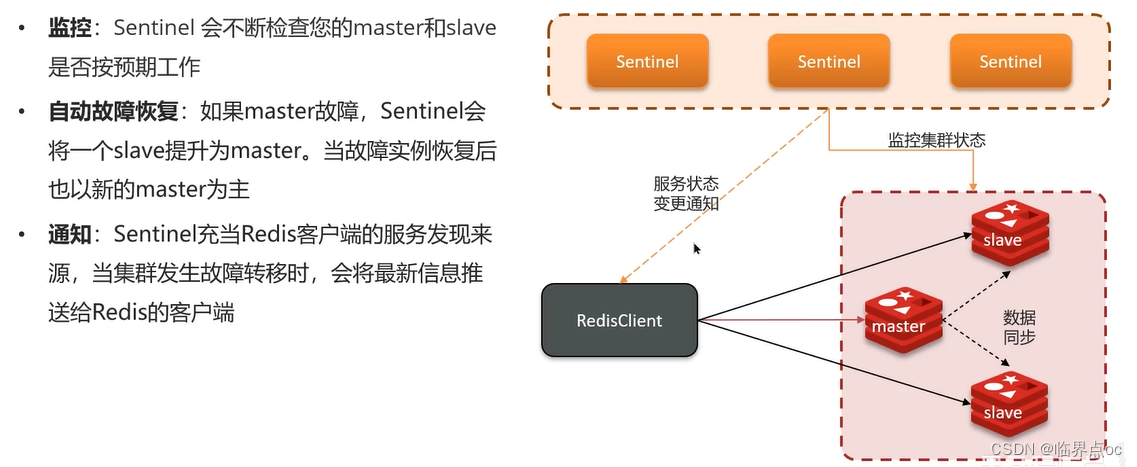
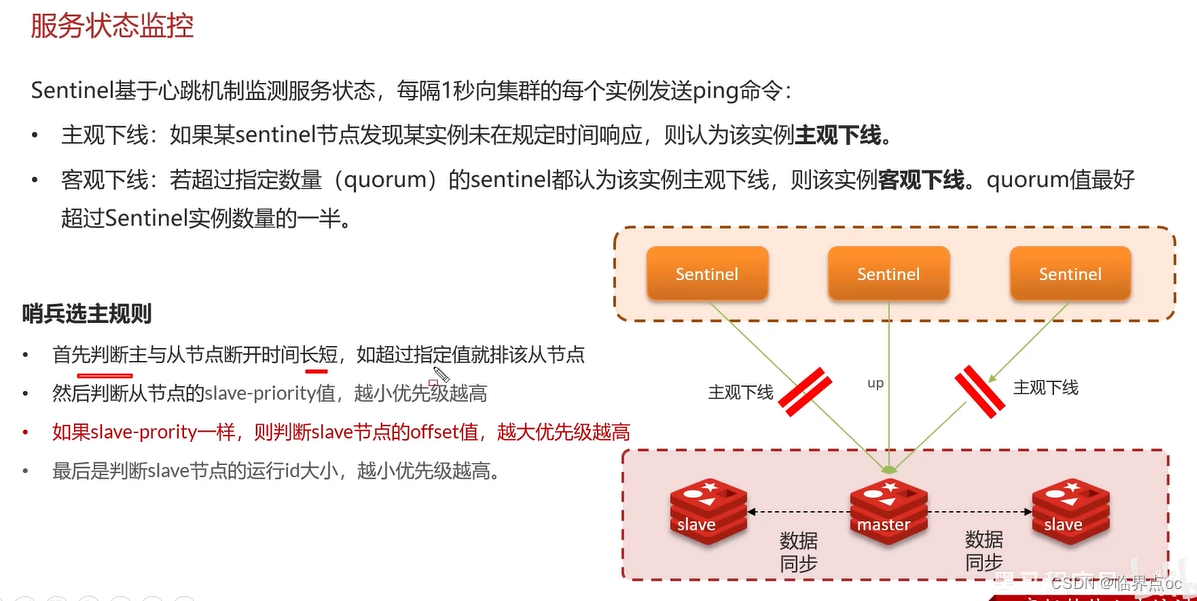
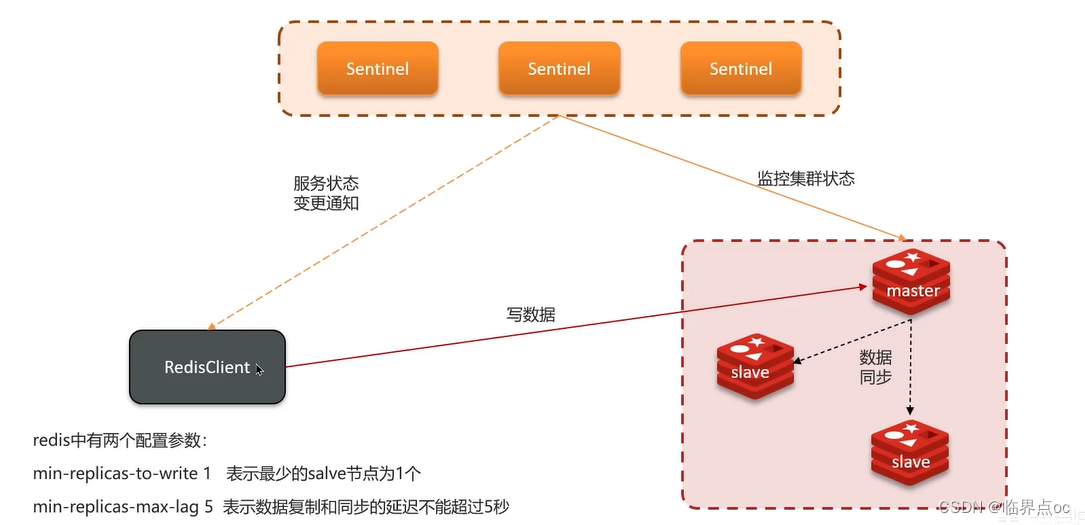
(3)哨兵的作用
Redis提供了哨兵(Sentinel)機制來實現主從集群的自動故障恢復。哨兵的結構和作用如下:
(4)Redis集群(哨兵模式)腦裂,該怎么解決?

(5)你們使用Redis是單點還是集群?哪種集群

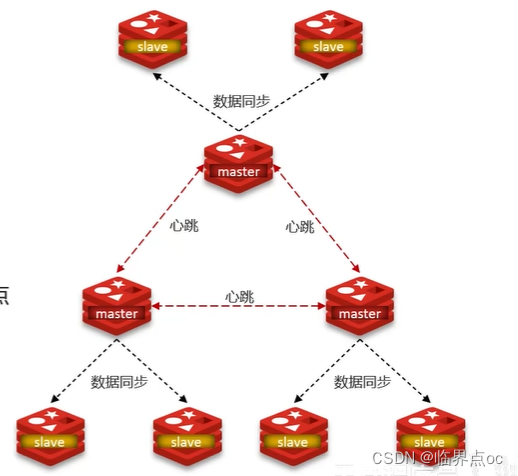
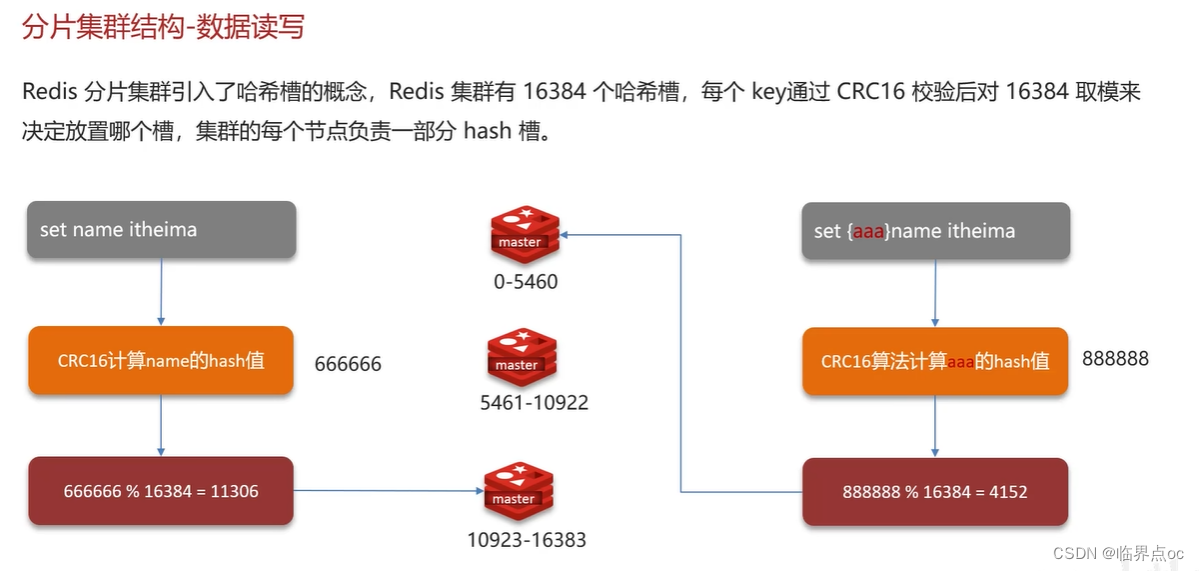
(6)Redis分片集群中數據是怎么存儲和讀取的
主從和哨兵可以解決高可用、高并發讀的問題。但是依然有兩個問題沒有解決:
- 海量數據存儲問題
- 高并發寫的問題
使用分片集群可以解決上述問題,分片集群特征:
- 集群中有多個master,每個master保存不同數據
- 每個master都可以有多個slave節點
- master之間通過ping監測彼此健康狀態
- 客戶端請求可以訪問集群任意節點,最終都會轉發到正確節點


(6)怎么保證Redis的高并發高可用
(7)你們用過Redis的事務嗎?事務的命令有哪些?
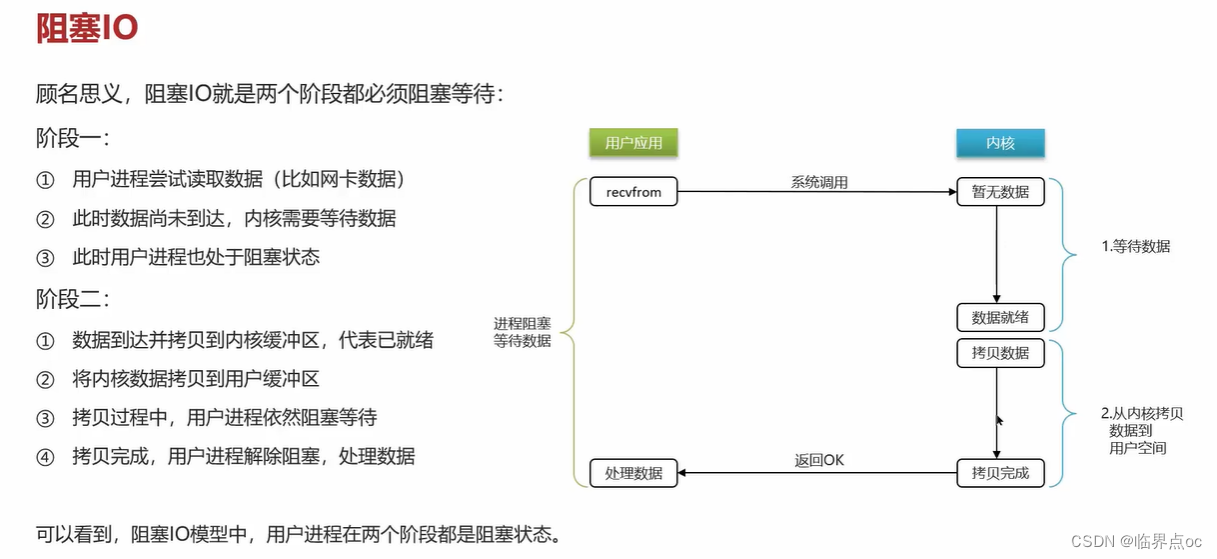
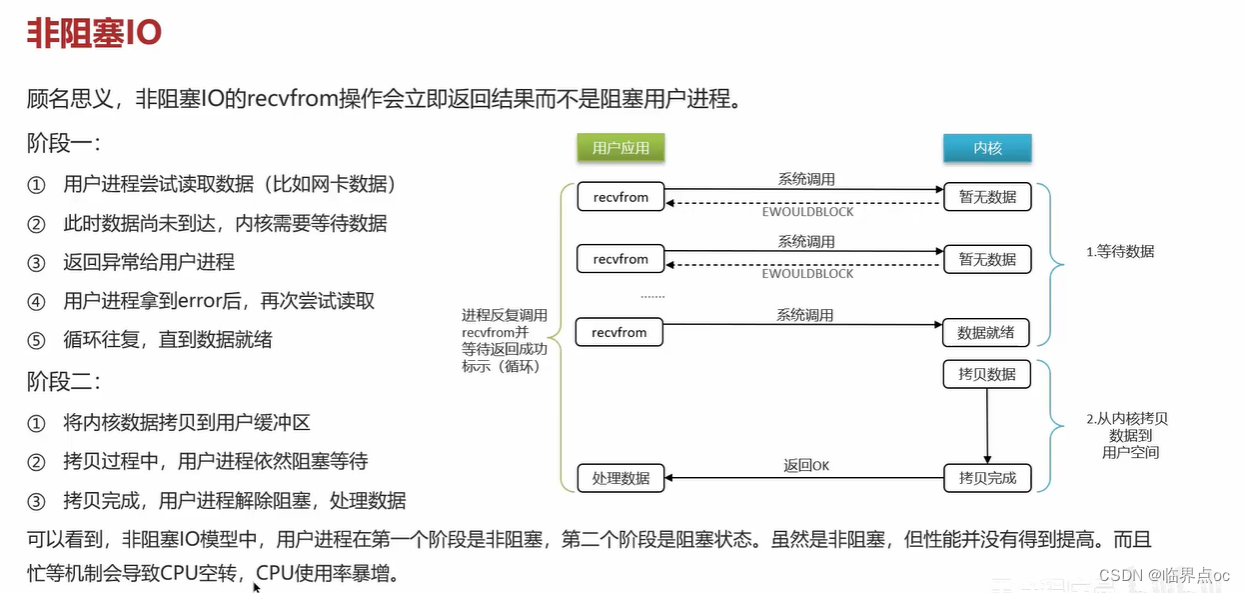
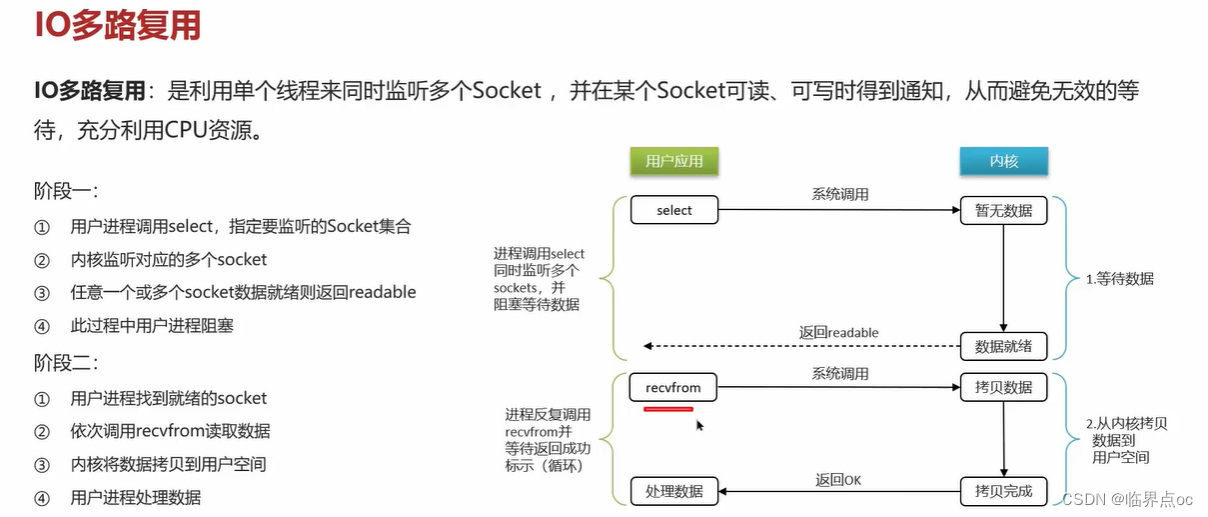
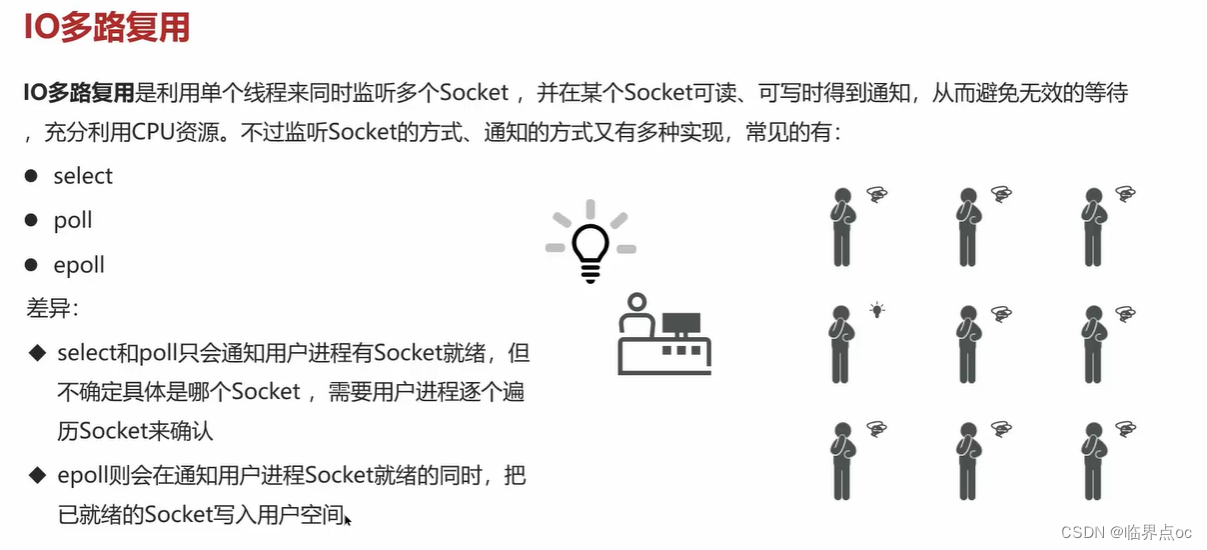
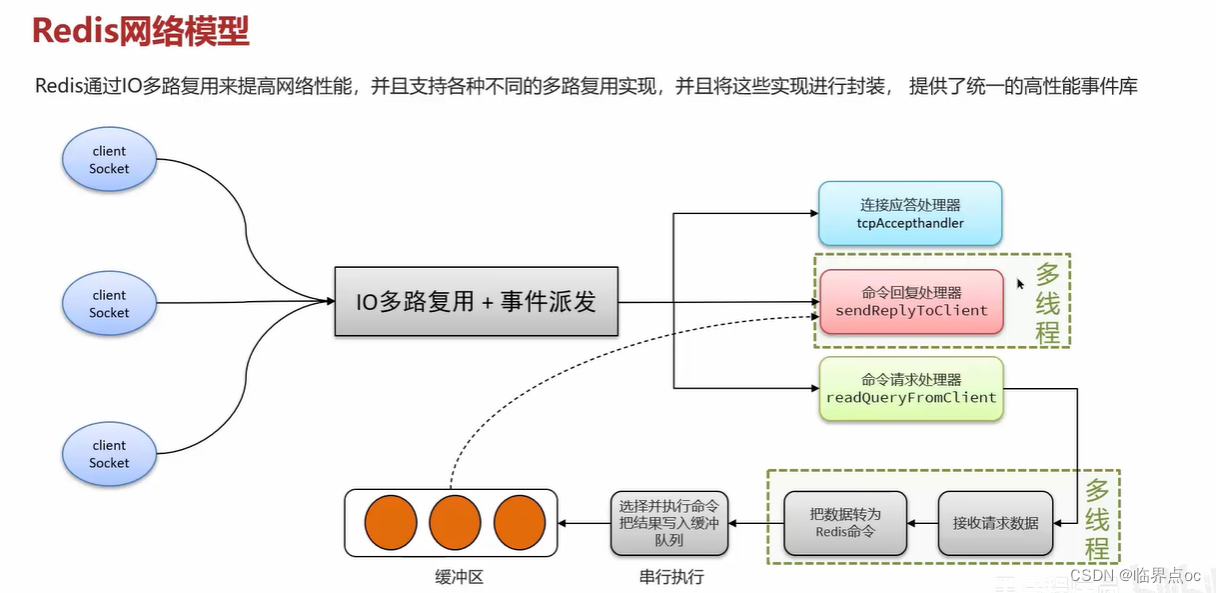
(8)Redis是單線程的,但是為什么還那么快?




二、MySQL
1. SQL優化
(1)在MySQL,如何定位慢查詢?
- 聚合查詢
- 多表查詢
- 表數據量過大查詢
- 深度分頁查詢
表象:頁面加載過慢、接口壓測響應時間過長(超過1s)
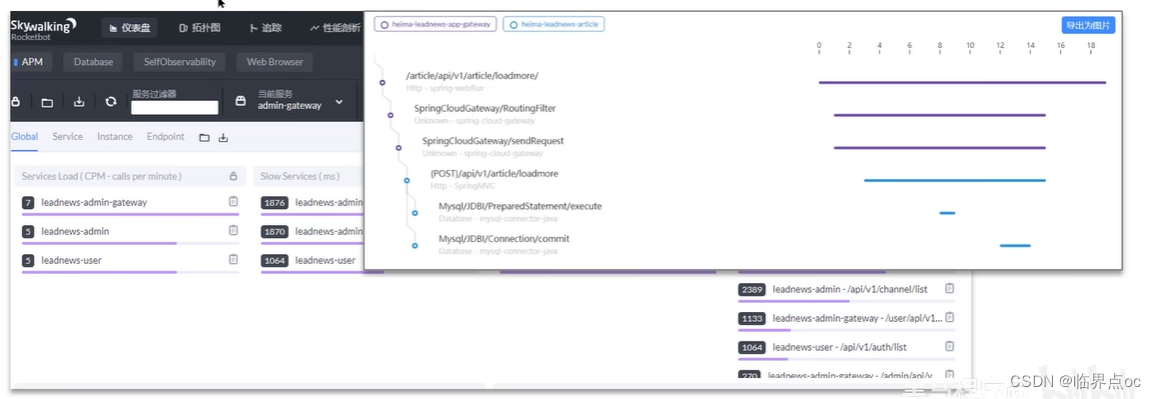
方案一:開源工具
- 調試工具:Arthas
- 運維工具:Prometheus、Skywalking
方案二:MySQL自帶慢日志
慢查詢日志記錄了所有執行時間超過指定參數(long_query_time,單位:秒,默認10秒)的所有SQL語句的日志。如果要開啟慢查詢日志,需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息:

配置完畢之后,通過以下命令重新啟動MySQL服務器進行測試,查看慢日志文件中記錄的信息:/var/lib/mysql/localhost-slow.log


(2)一個SQL語句執行很慢,如何分析
可以采用EXPLAIN或者DESC命令獲取MySQL如何執行SELECT語句的信息
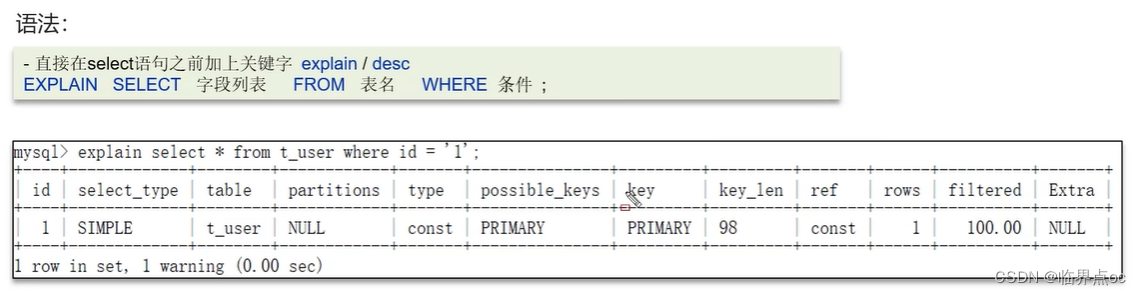



(3)了解過索引嗎?什么是索引?
索引(index)是幫助MySQL高效獲取數據的數據結構(有序)。在數據之外,數據庫系統還維護著滿足特定查找算法的數據結構(B+樹),這些數據結構以某種方式引用(指向)數據,這樣就可以在這些數據結構上實現高級查找算法,這種數據結構就是索引。


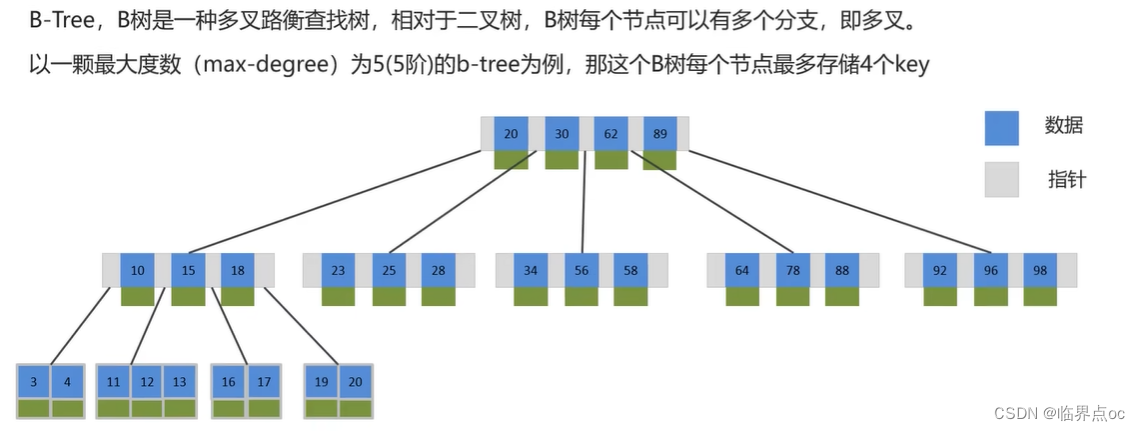
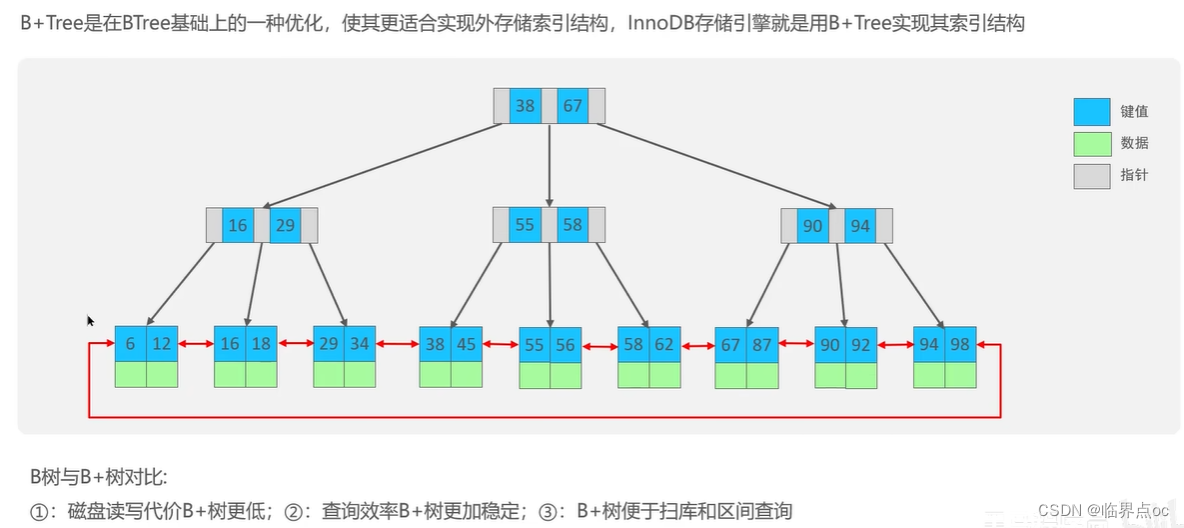


(4)什么是聚簇索引,什么是非聚簇索引?
什么是聚集索引,什么是二級索引(非聚集索引),什么是回表?
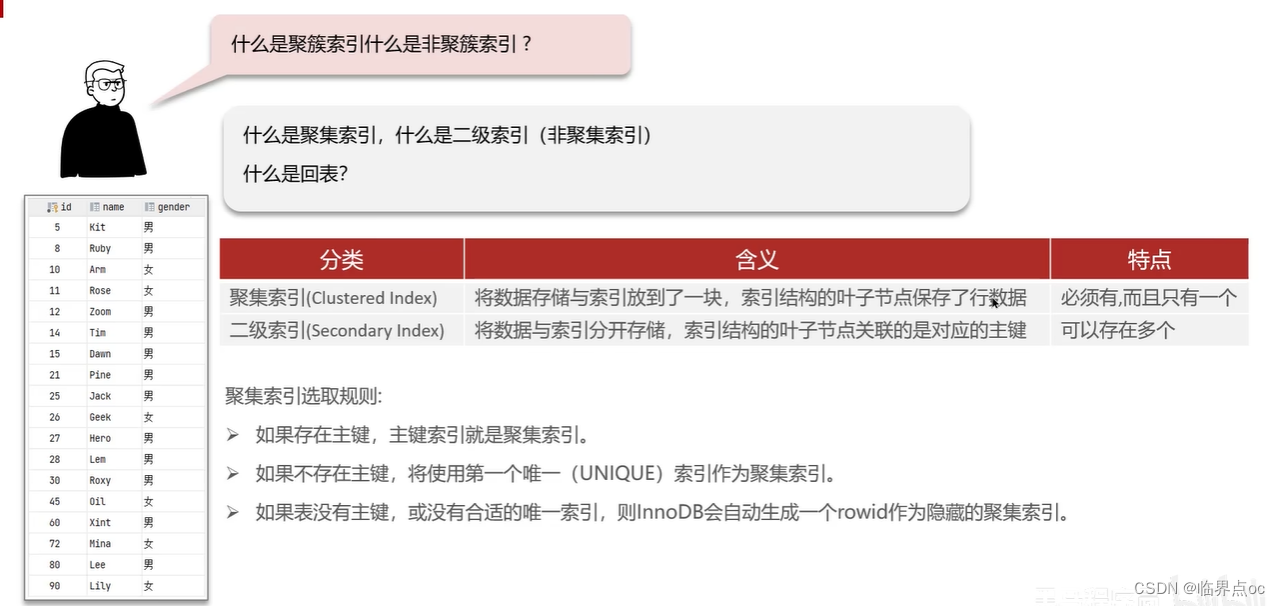
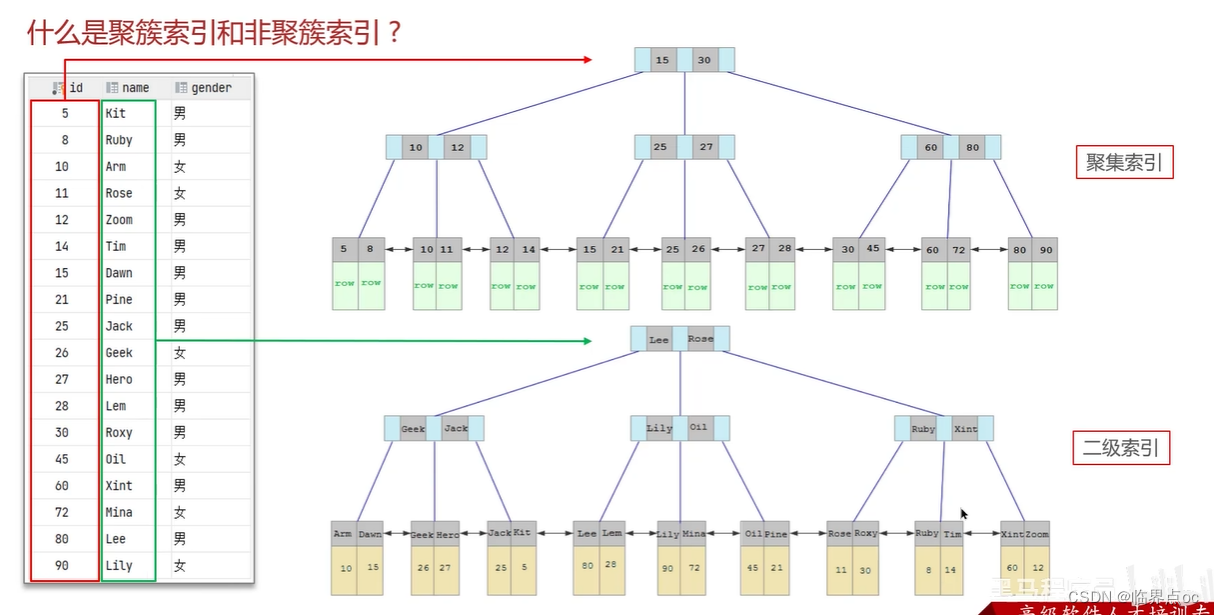
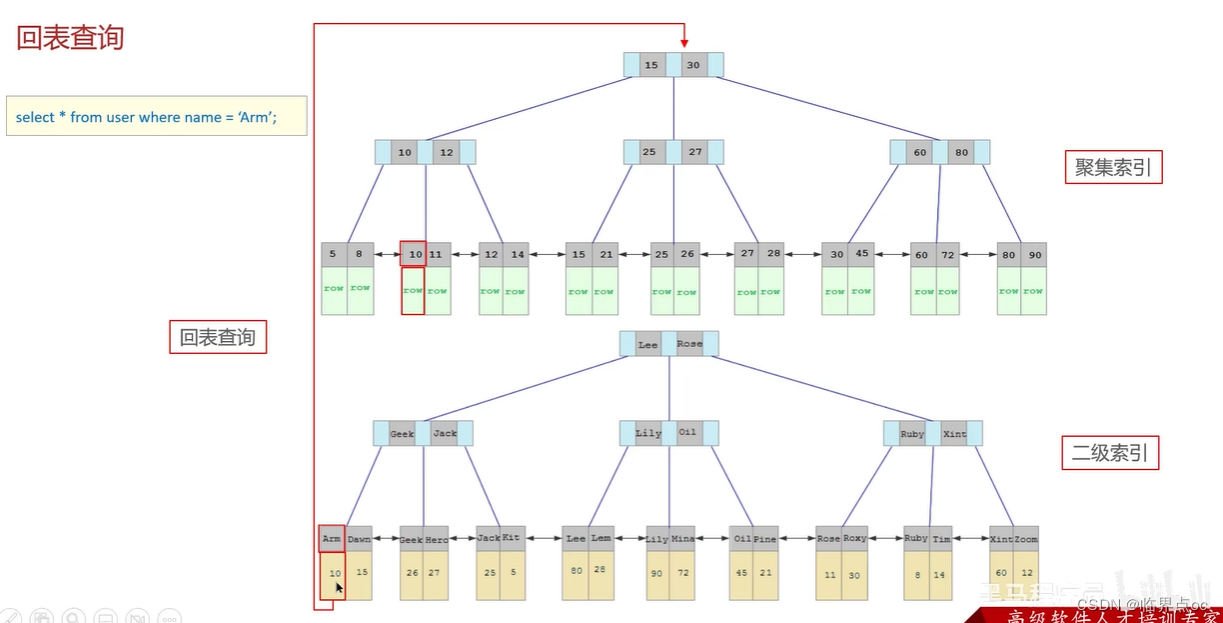
在二級索引中找到name字段對應的主鍵值,然后再根據主鍵值到聚集索引中查找對應行數據。


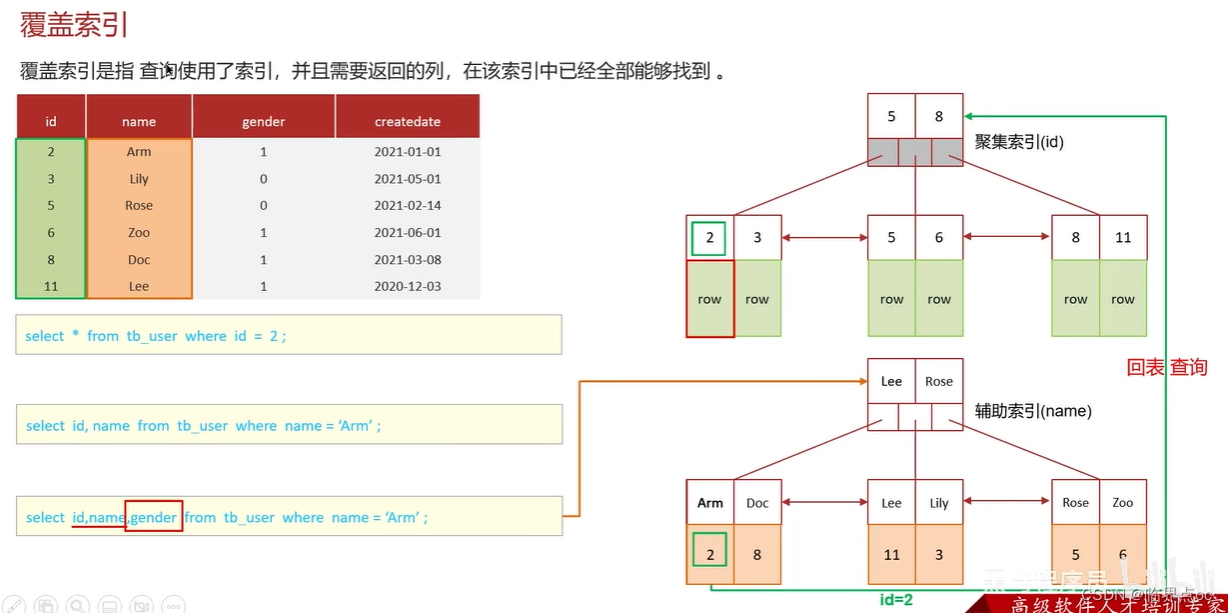
(5)什么是覆蓋索引?


(6)MySQL超大分頁處理
在數據量比較大時,如果進行limit分頁查詢,在查詢時,越往后,分頁查詢效率越低。

優化思路:一般分頁查詢時,通過創建覆蓋索引能夠比較好地提高性能,可以通過覆蓋索引加子查詢形式進行優化。



(7)索引創建原則有哪些?
- 主鍵索引
- 唯一索引
- 根據業務創建的索引(復合索引)
①針對于數據量較大,且查詢比較頻繁的表建立索引 -> 單表超過10萬條數據(增加用戶體驗)
②針對于常作為查詢條件(where)、排序(order by)、分組(group by)操作的字段建立索引。
③盡量選擇區分度高的列作為索引,盡量建立唯一索引,區分度越高,使用索引的效率越高
④如果是字符串類型的字段,字段的長度較長,可以針對于字段的特點,建立前綴索引。
⑤盡量使用聯合索引,減少單列索引,查詢時,聯合索引很多時候可以覆蓋索引,節省存儲空間,避免回表,提高查詢效率。
⑥要控制索引的數量,索引并不是多多益善,索引越多,維護索引結構的代價也就越大,會影響增刪改的效率。
⑦如果索引列不能存儲NULL值,請在創建表時使用NOT NULL約束它。當優化器知道每列是否包含NULL值時,它可以更好地確定哪個索引最有效地用于查詢。

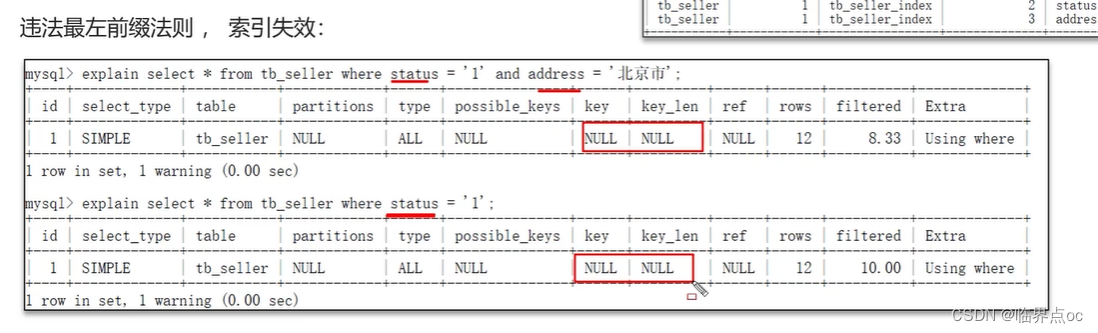
(8)什么情況下索引會失效?



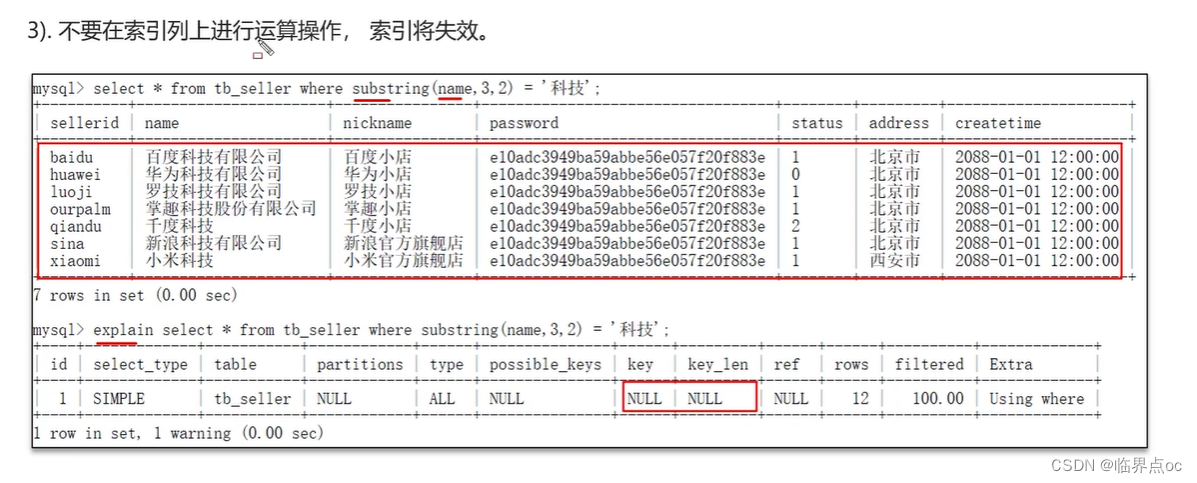

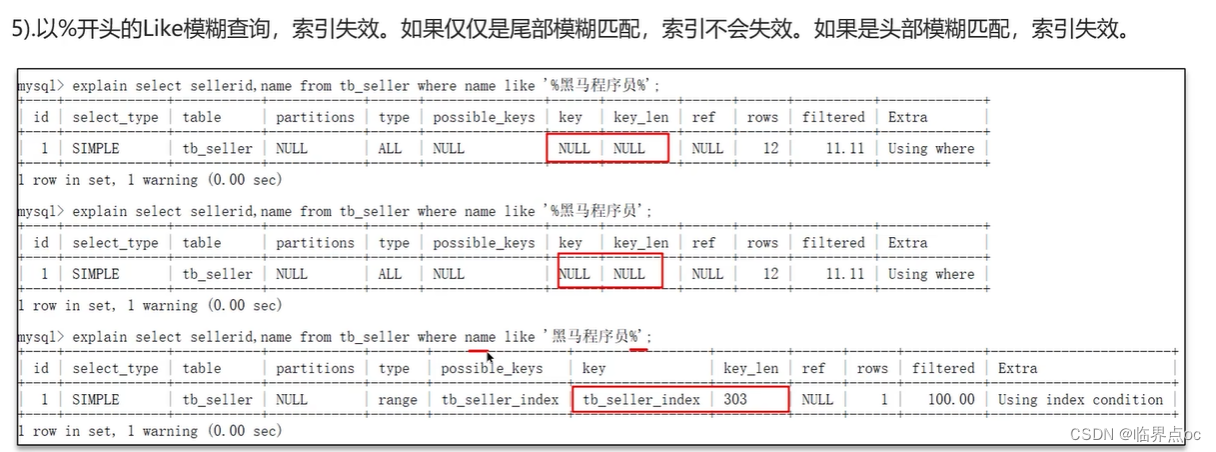


?(9)談談你對sql的優化經驗?
- 表的設計優化
- 索引優化
- SQL語句優化
- 主從復制、讀寫分離
- 分庫分表



2. 其他面試題
(1)事務的特性是什么?可以詳細說一下嗎?
事務是一組操作的集合,它是越高不可分割的工作單位,事務會把所有的操作作為一個整體一起向系統提交或撤銷操作請求,即這些操作要么成功,要么同時失敗。
ACID是什么?


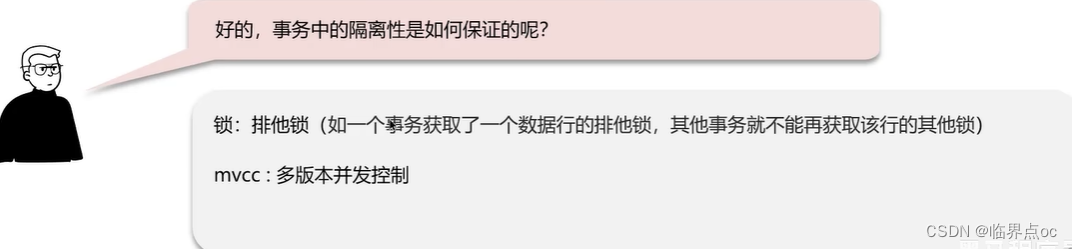
(2)并發事務帶來哪些問題?怎么解決這些問題呢?MySQL的默認隔離級別是?
并發事務問題:臟讀、不可重復讀、幻讀
隔離級別:讀未提交、讀已提交、可重復讀、串行化

解決方案:對事務進行隔離
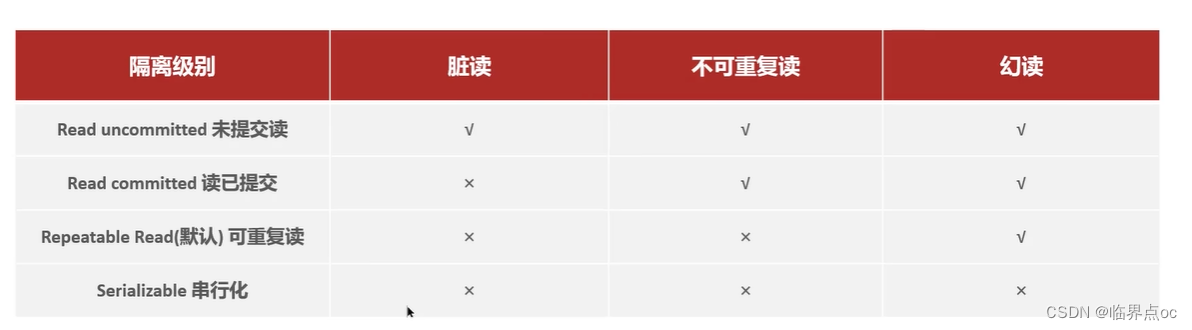
注意:事務隔離級別越高,數據越安全,但是性能越低。
MySQL默認的隔離級別是Repeatable Read(可重復讀)

(3)undo log和redo log的區別
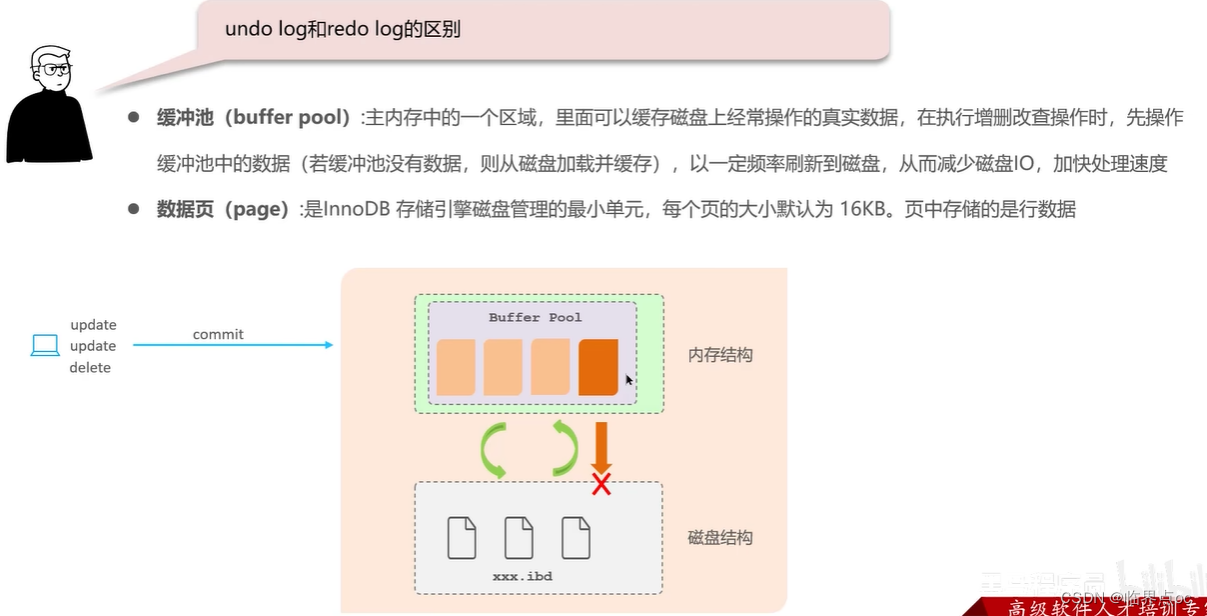
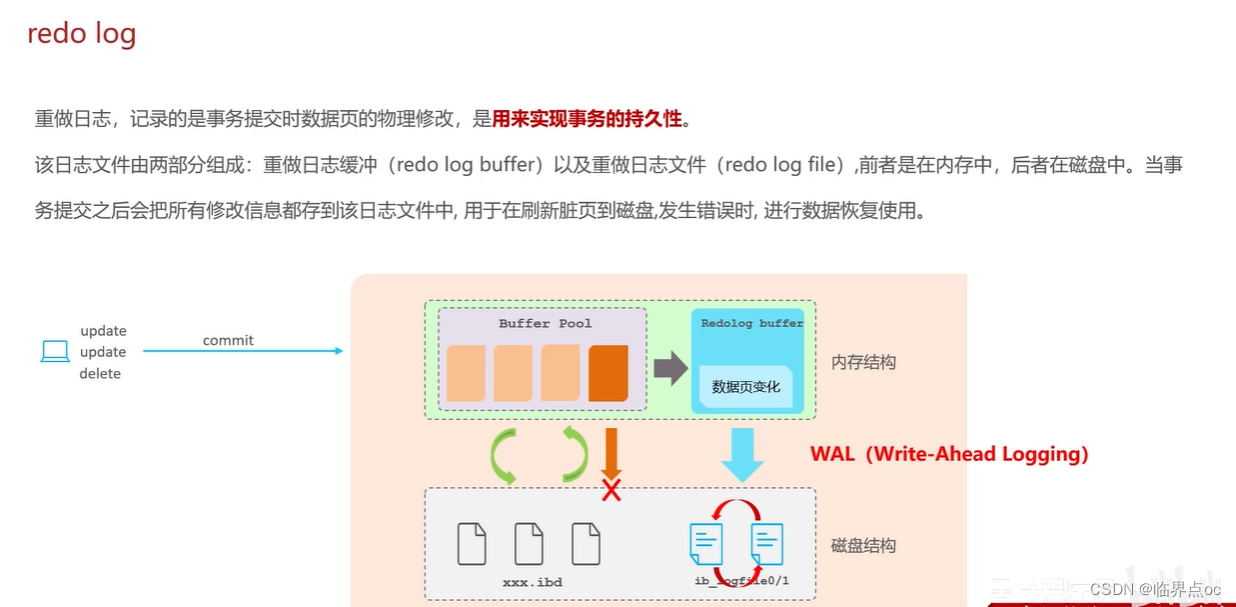

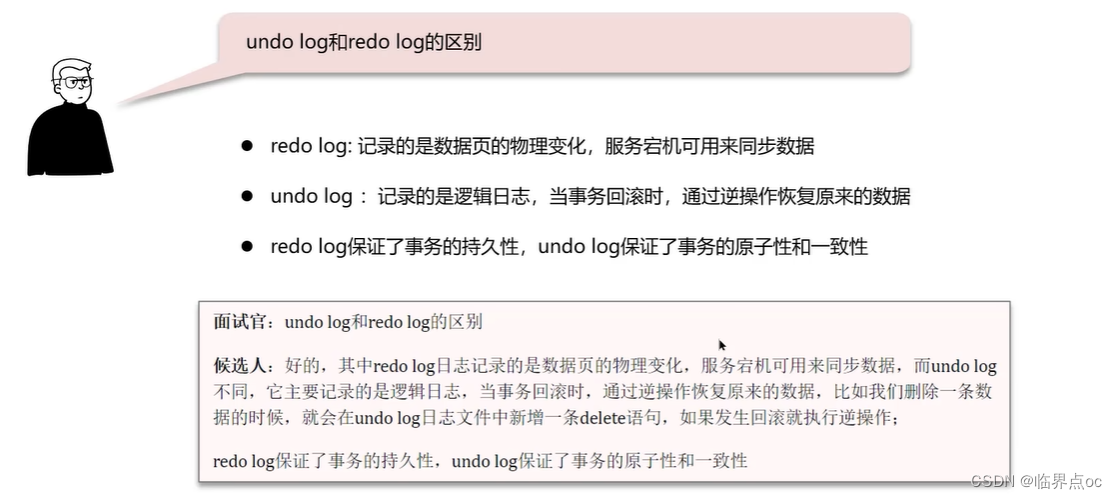
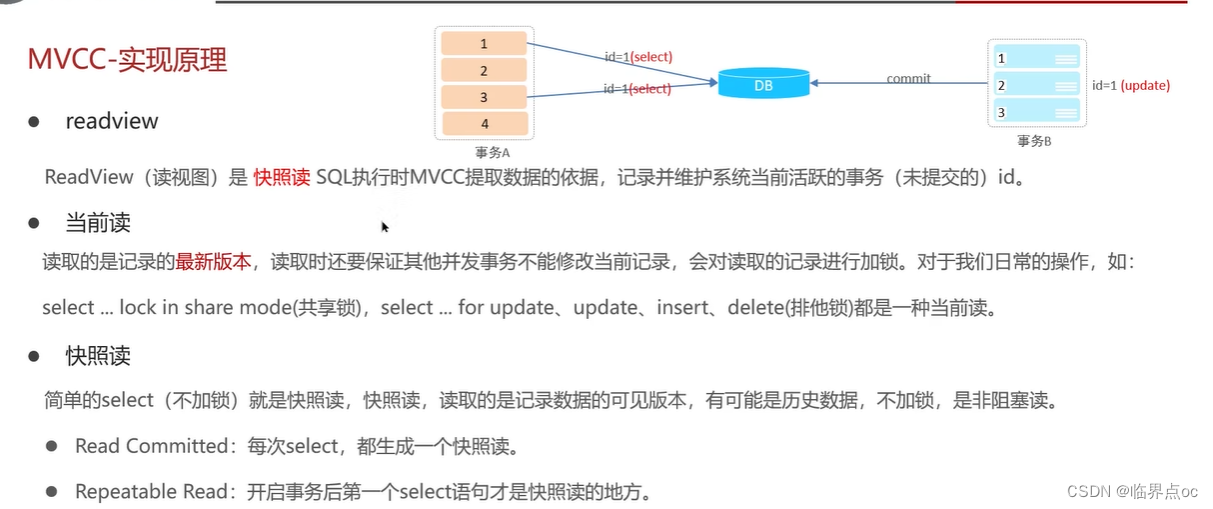
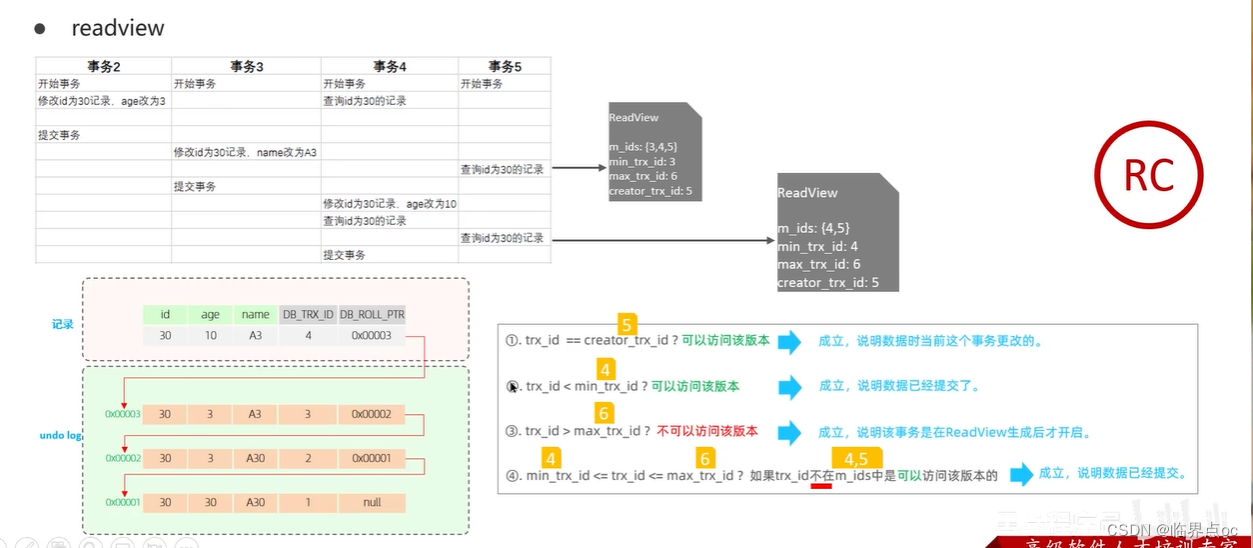
(4)解釋一下MVCC -> 事務隔離性
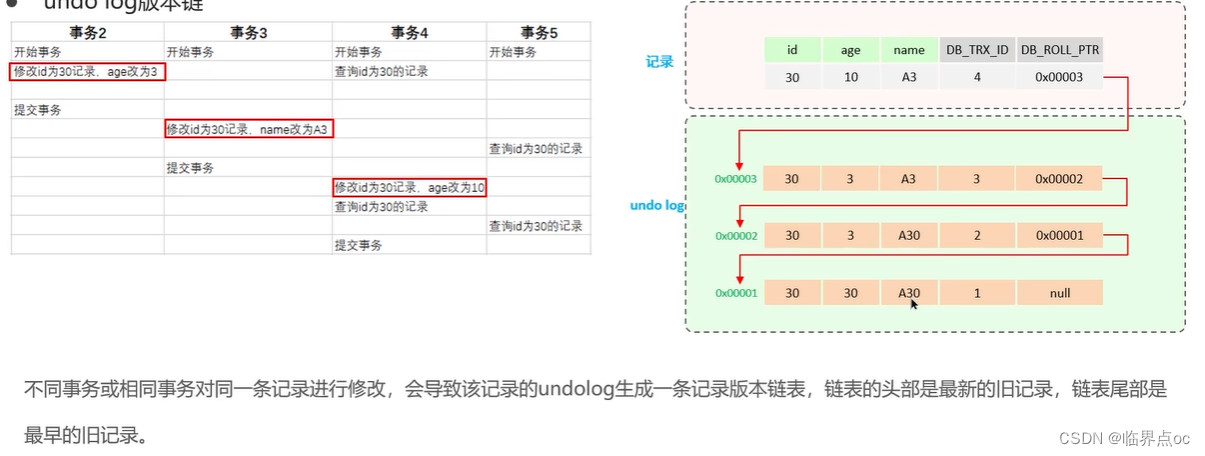
全稱Multi-Version Concurrency Control,多版本并行控制。指維護一個數據的多個版本,使得讀寫操作沒有沖突。MVCC的具體實現,主要依賴于數據庫記錄中的隱式字段、undo log日志、readView讀視圖。
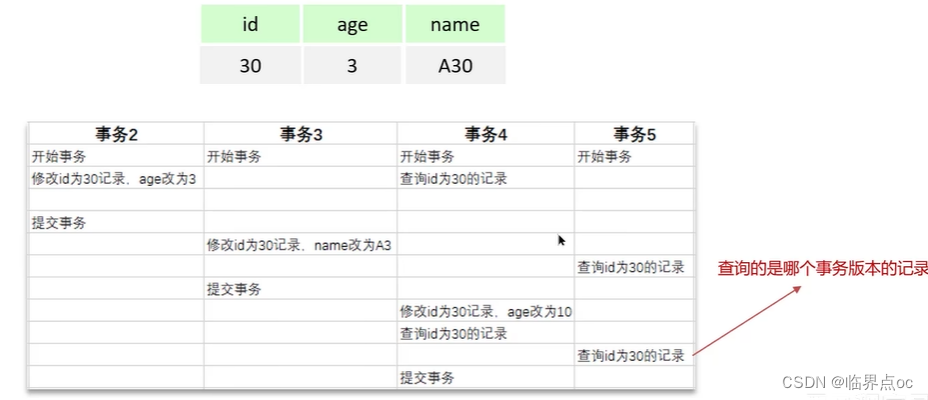
- 記錄中的隱藏字段

- undo log

- undo log版本鏈
- readview


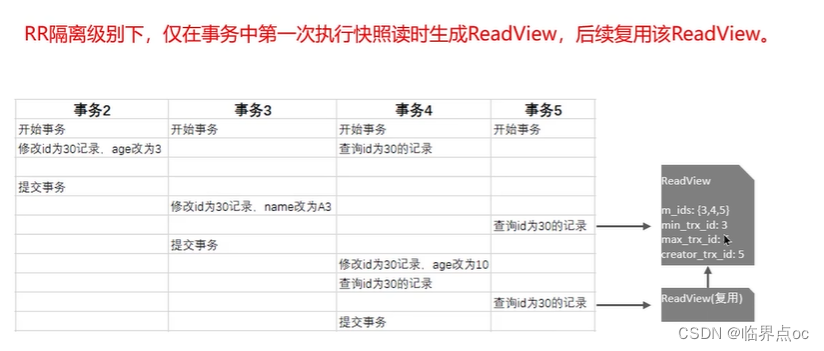


(5)MySQL主從同步原理
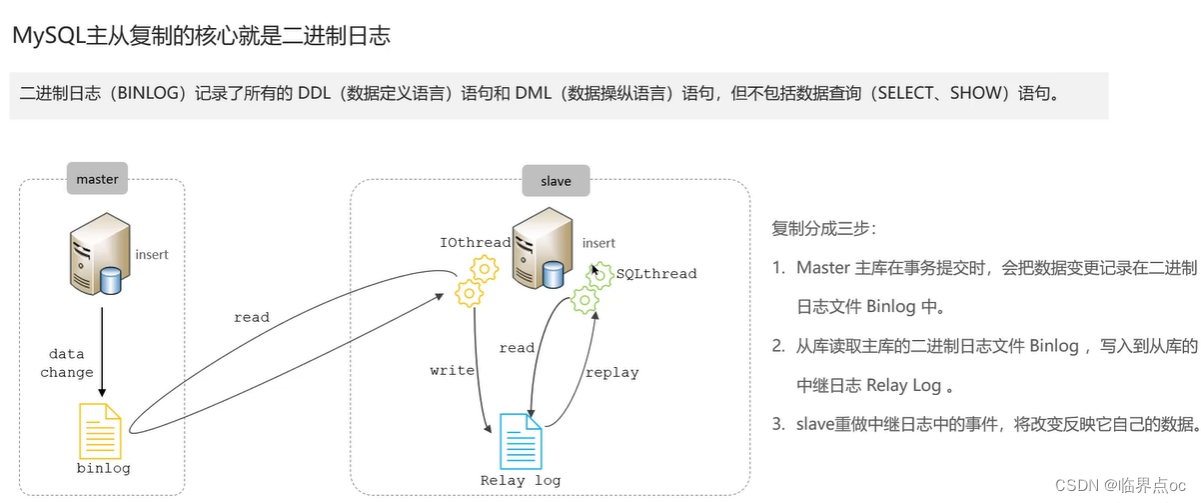

(6)你們項目用過分庫分表嗎?
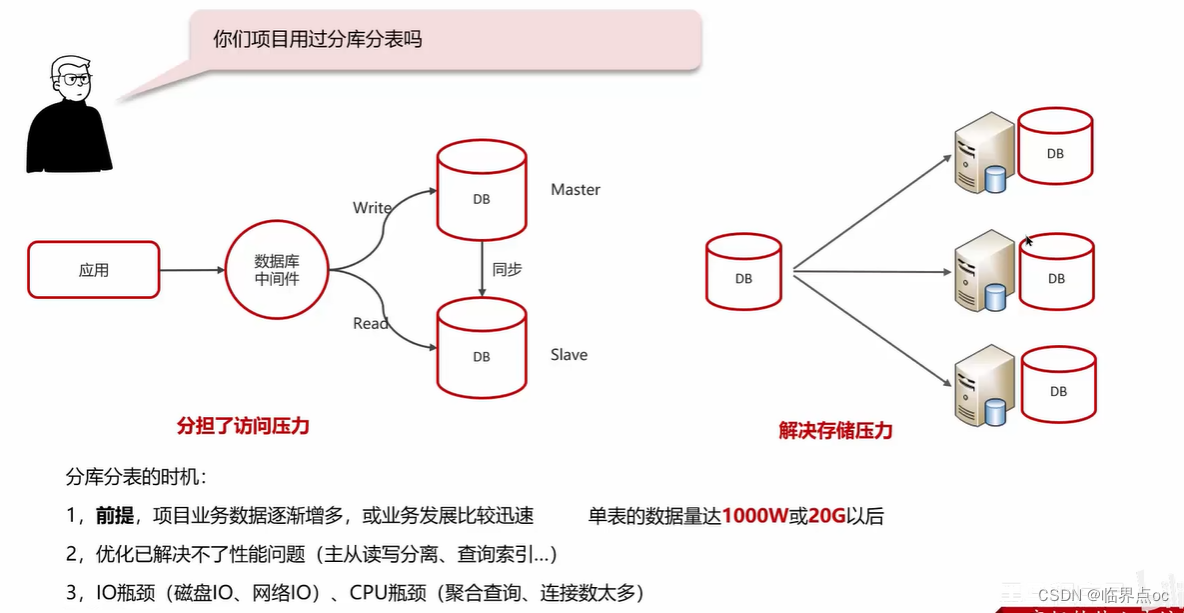
拆分策略:垂直拆分、水平拆分
垂直分庫:以表為依據,根據業務將不同表拆分到不同庫中。
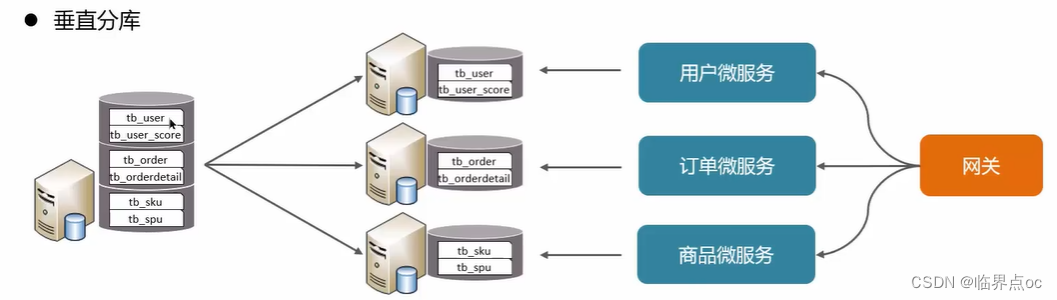
特點:
- ①按業務對數據分級管理、維護、監控、擴展
- ②在高并發下,提高磁盤IO和數據量連接數
垂直分表:以字段為依據,根據字段熟悉將不同字段拆分到不同表中。
拆分規則:
- 把不常用的字段單獨放到一張表
- 把text、blob等大字段拆分出來放在附表中
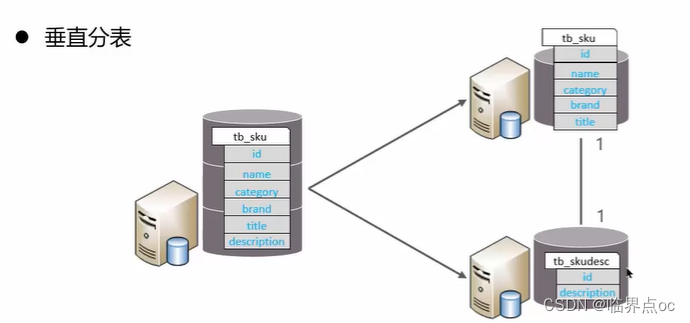
特點:①冷熱數據分離;②減少IO過渡爭搶,兩表互不影響
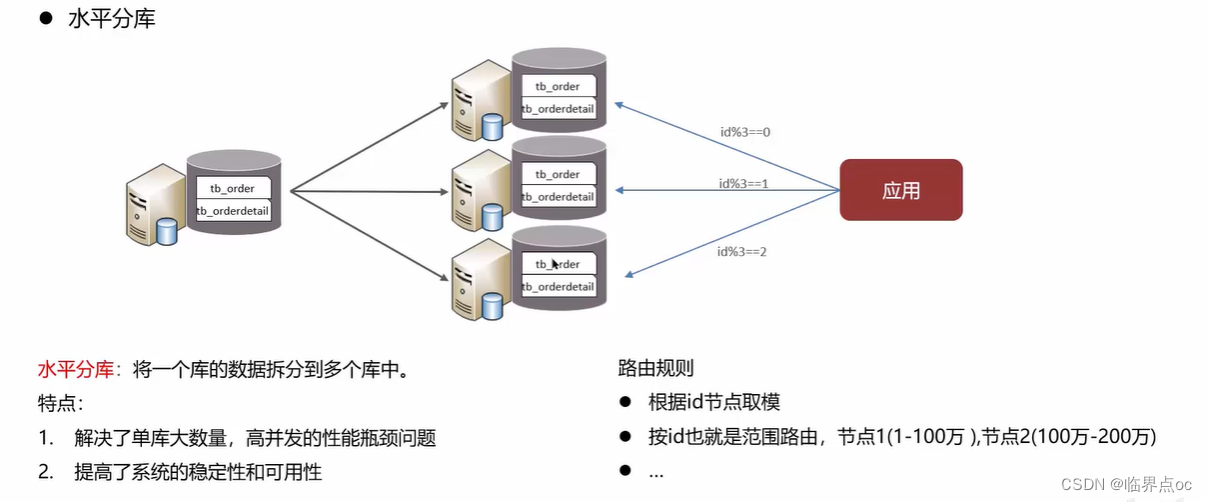
水平分庫:將一個庫的數據拆分到多個庫中。
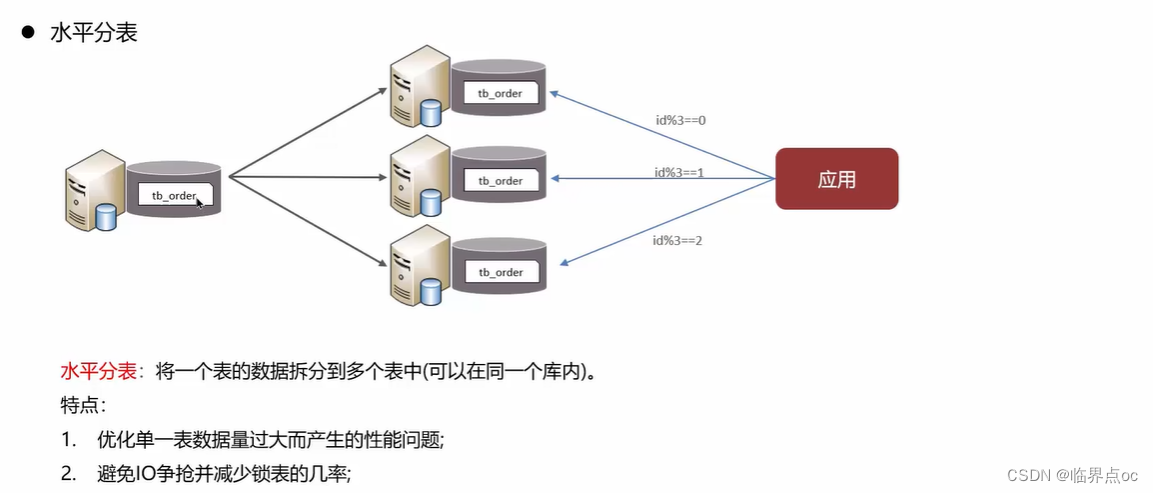
水平分表:將一個表的數據拆分到多個表中(可以在同一個庫內)。
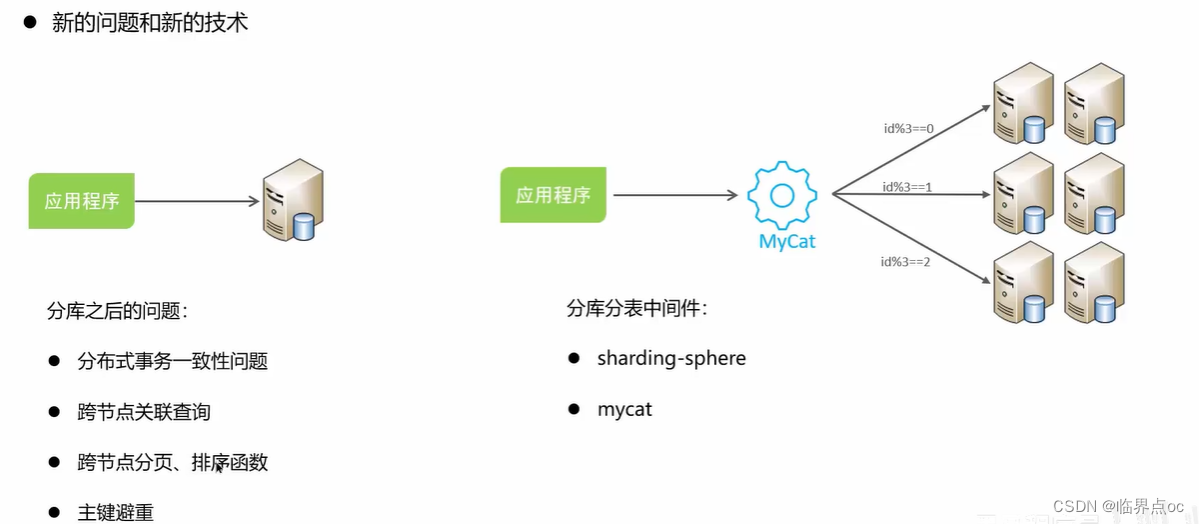

三、Spring
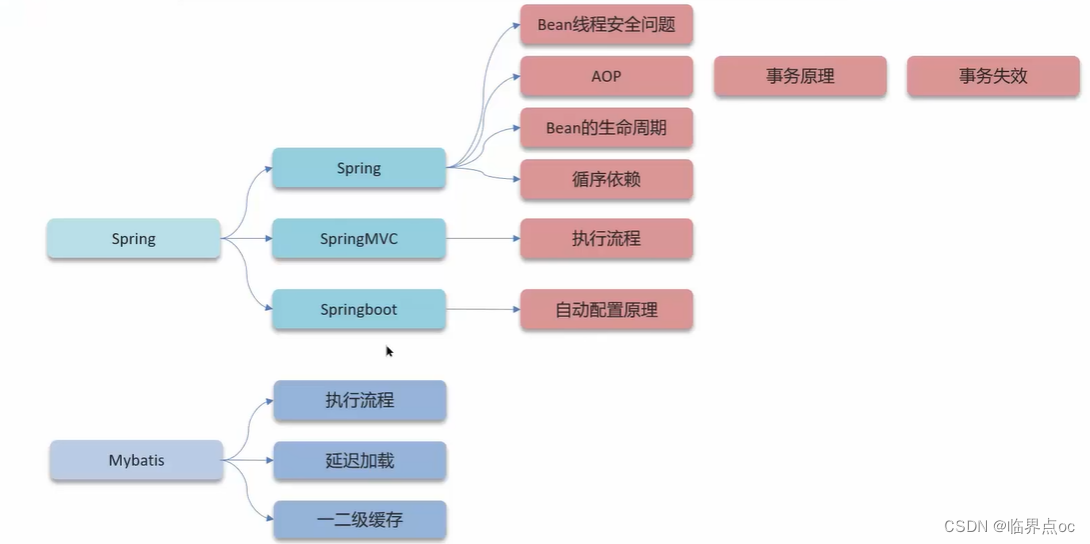
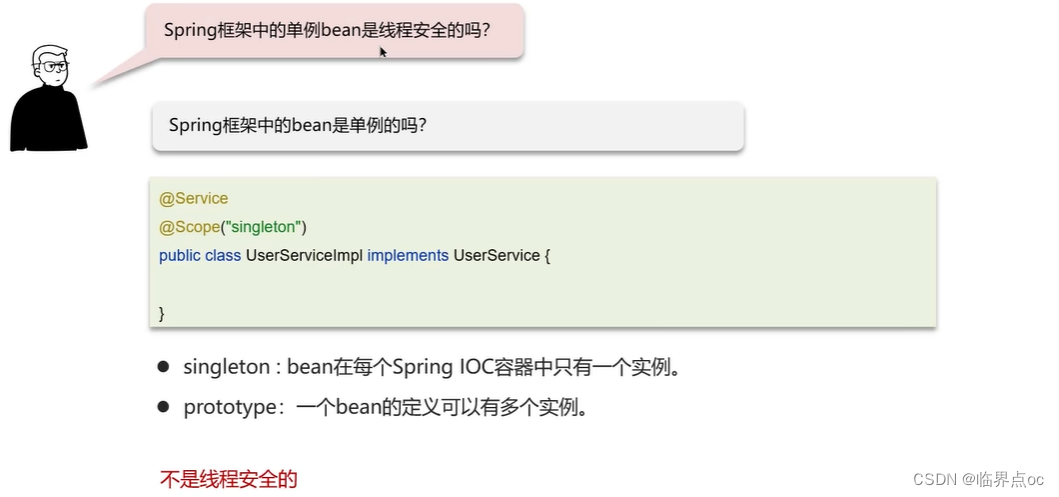
(1)Spring框架中的單例bean是線程安全的嗎?



(2)什么是AOP,你們項目中有沒有使用到AOP
AOP基礎-CSDN博客


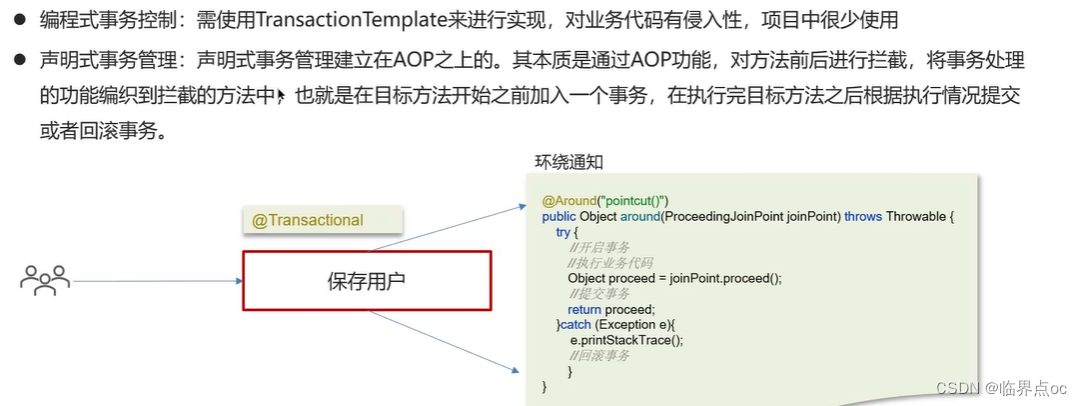
(3)Spring中的事務是如何實現的?
Spring支持編程式事務管理和聲明式事務管理兩種方式。
???????

(4)Spring中事務失效的場景有哪些?
情況一:異常捕獲處理
如果在一個事務方法內部捕獲了異常并對其進行了處理,Spring事務管理可能無法感知異常的發生,從而導致事務失效。事務通知只有捕捉到了目標拋出的異常,才能進行后續的回滾處理,如果目標自己處理掉異常,事務通知無法知悉。

情況二:拋出異常
如果拋出的異常不是繼承自RuntimeException,Spring默認不會回滾事務。所以,確保拋出的異常繼承自RuntimeException或聲明在方法簽名中。
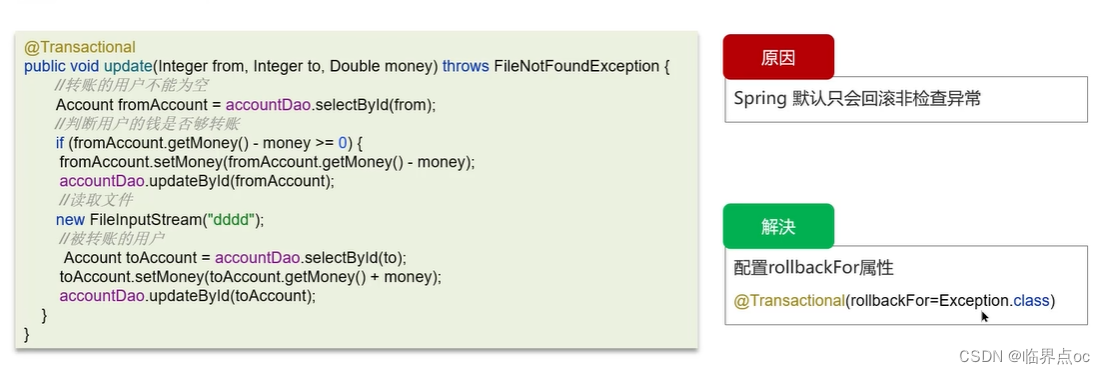
情況三:非public方法導致的事務失效

情況四:未使用代理對象
Spring的事務管理通常通過代理對象來實現事務的增強,如果直接調用一個帶有@Transactional注解的方法而不是通過代理對象調用,事務將不會生效。
情況五:編程式事務管理下,拋出異常未被捕獲
在基于編程式事務管理時,如果一個帶有@Transactional注解的方法內部發生但未被捕獲,在異常傳播至事務管理器時,可能導致事務無法回滾。
情況六:運行時異常未被聲明
只有在方法聲明的檢查異常(checked exception)被拋出時,Spring 事務管理器才會觸發事務回滾。如果拋出的是運行時異常,且未被顯式聲明在方法簽名中,可能會導致事務未能正確回滾。
情況七:嵌套調用問題
在嵌套調用的情況下,事務的傳播機制需要正確設置,否則可能導致外部事務失效或內部事務回滾不受控制。
情況八:多個事務注解嵌套使用
在某個方法上同時使用多個?@Transactional?注解,可能導致事務失效或者事務傳播不符合預期。

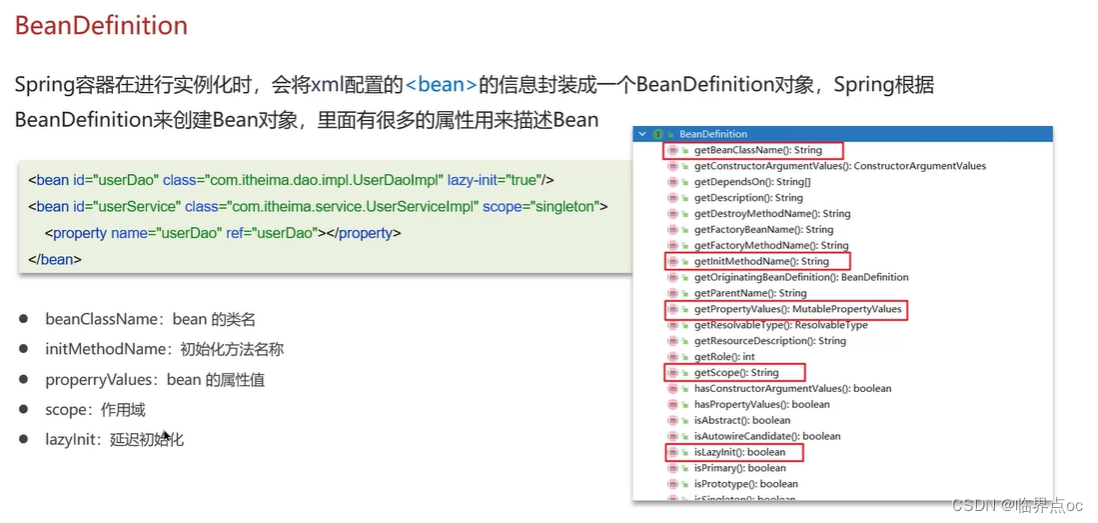
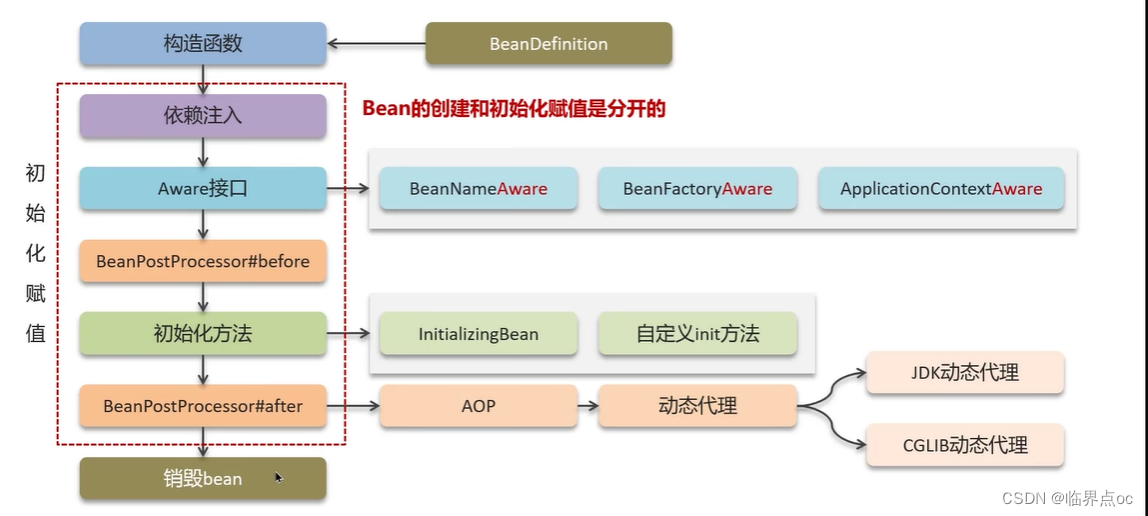
(5)Spring的bean的生命周期

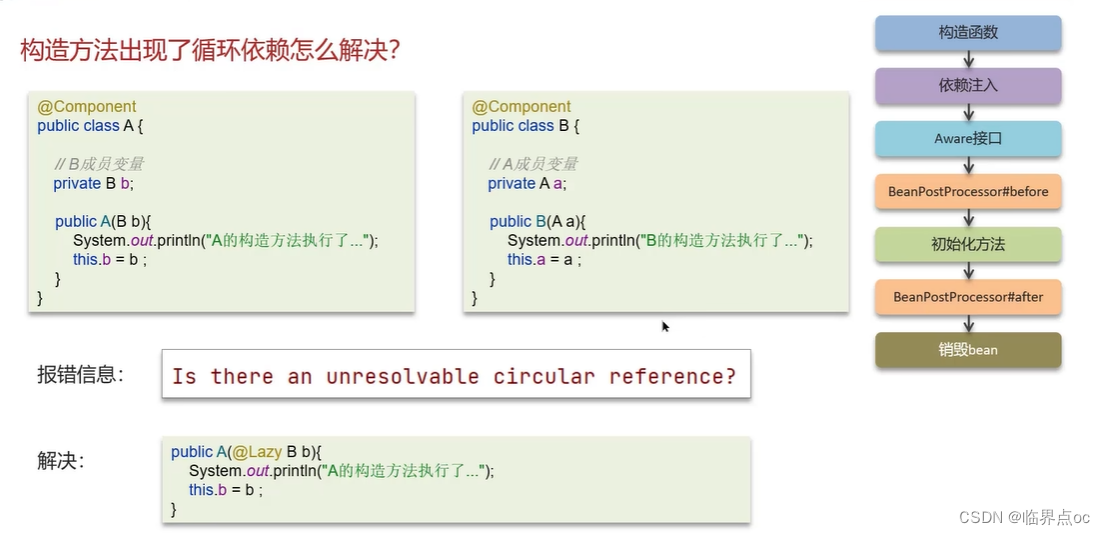
(6)Spring中的循環引用
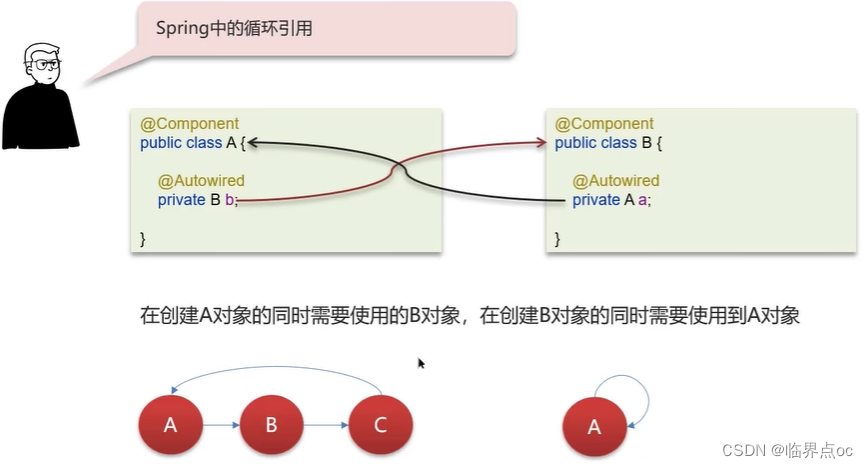
什么是Spring的循環依賴?
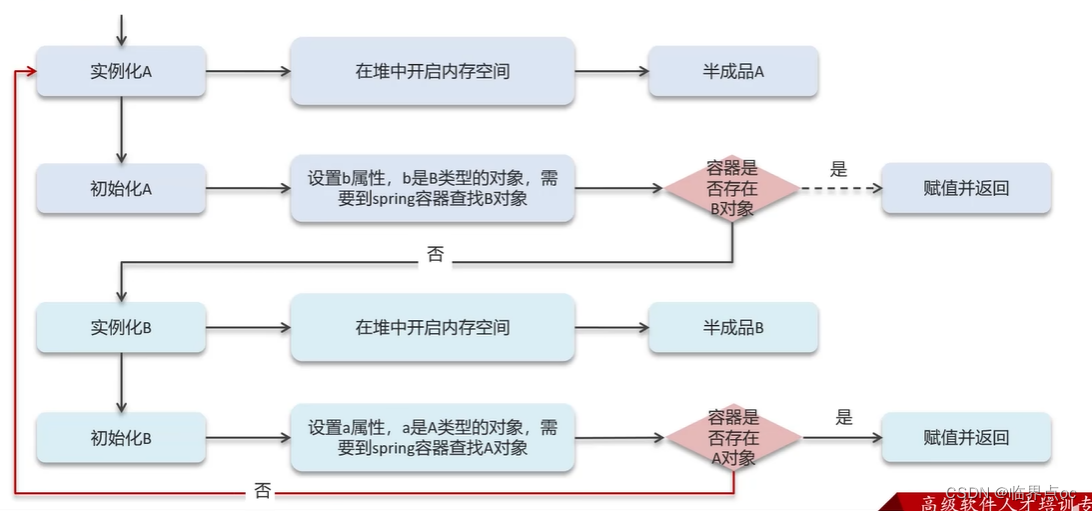
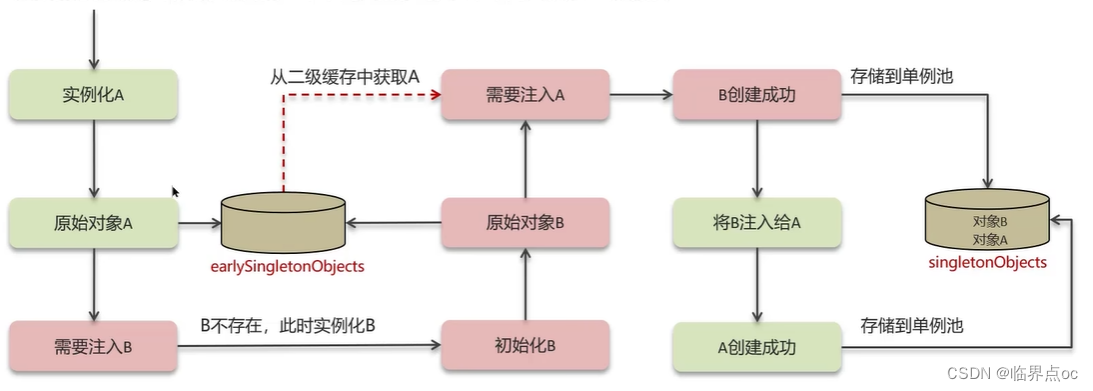
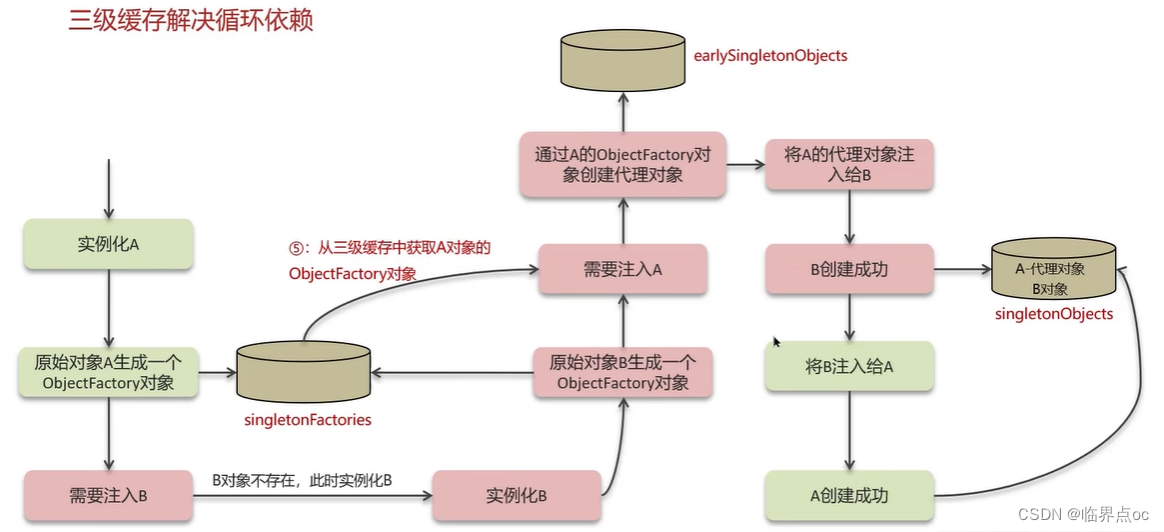
三級緩存解決循環依賴
Spring解決循環依賴是通過三級緩存,對應的三級緩存如下所示:

一級緩存作用:限制bean在beanFactory中只存一份,即實現singleton scope,解決不了循環依賴
如果要想打破循環依賴,就需要一個中間人的參與,這個中間人就是二級緩存


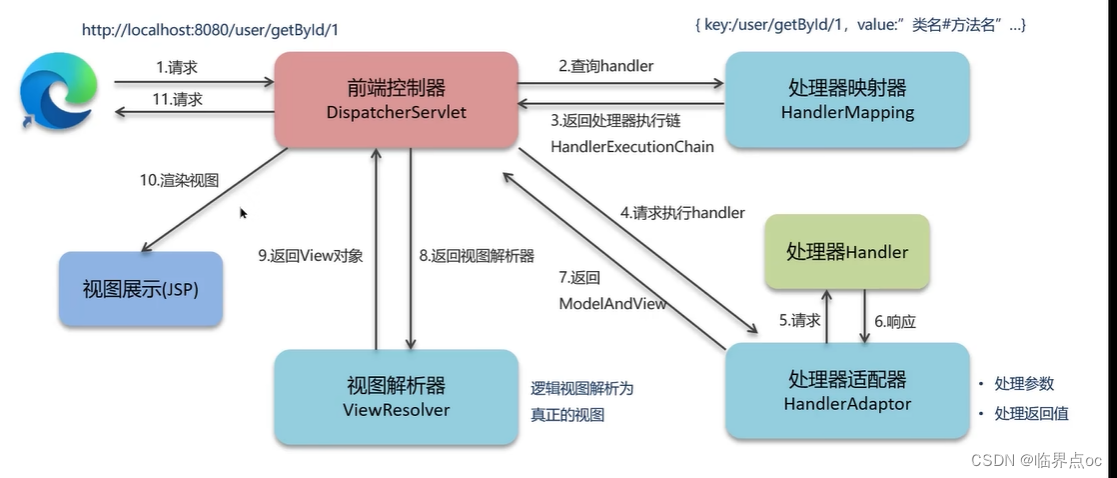
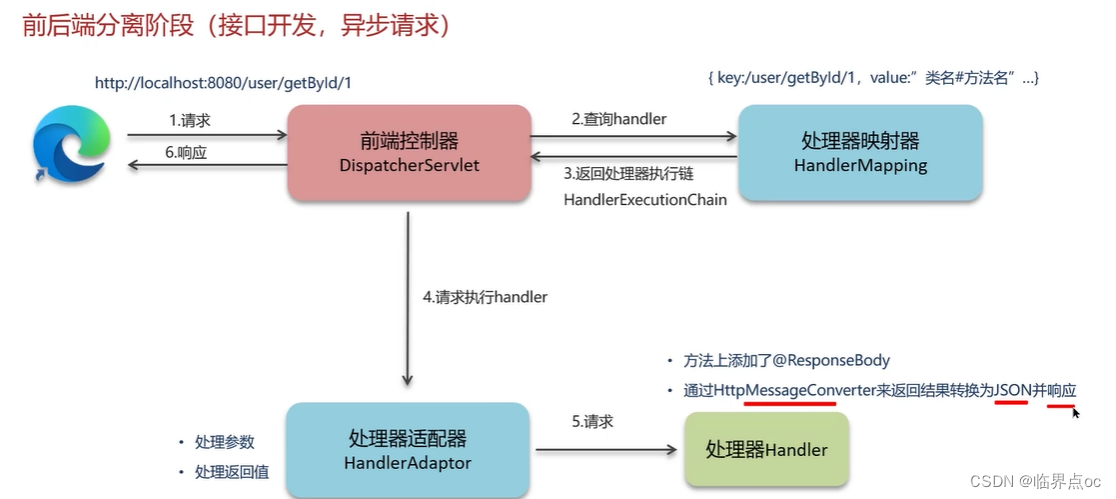
(7)SpringMVC的執行流程

視圖階段(JSP)


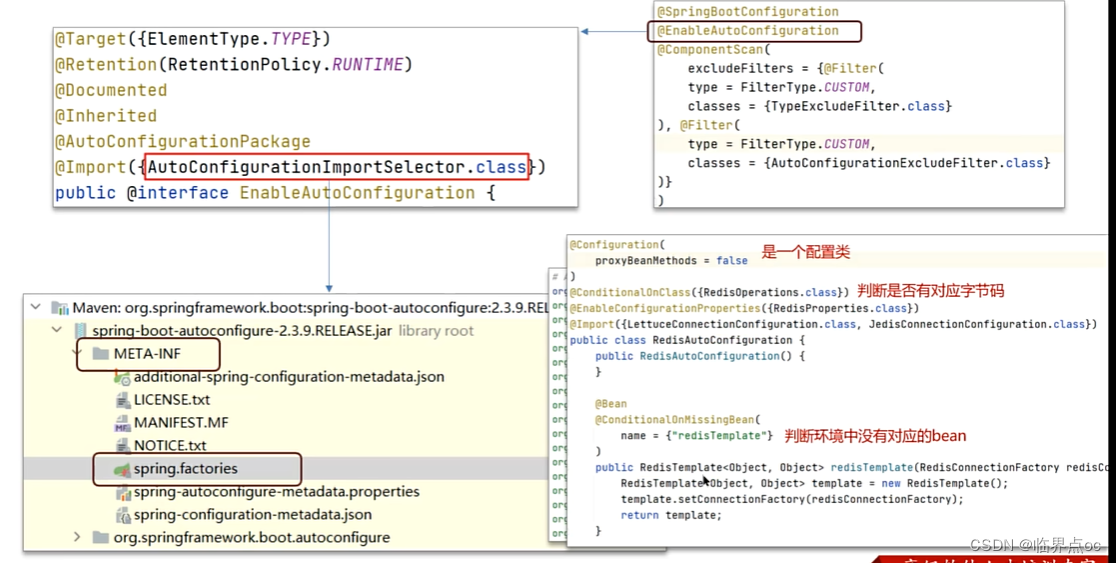
(8)SpringBoot的自動配置原理


(9)Spring框架常見注解(Spring、SpringBoot、SpringMVC)
Spring的常見注解有哪些?
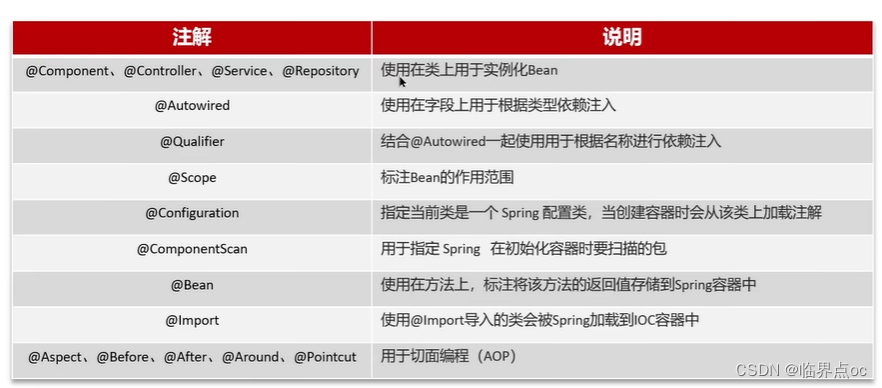
SpringMVC的常見注解有哪些?

SpringBoot常見注解有哪些?

?
四、MyBatis
?(1)MyBatis執行流程
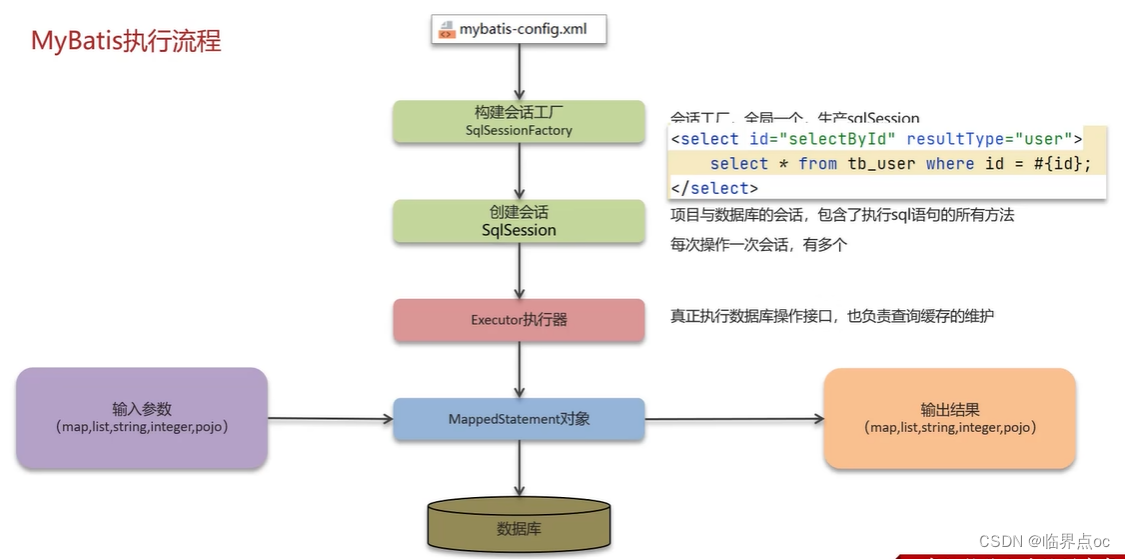

(2)MyBatis是否支持延遲加載?
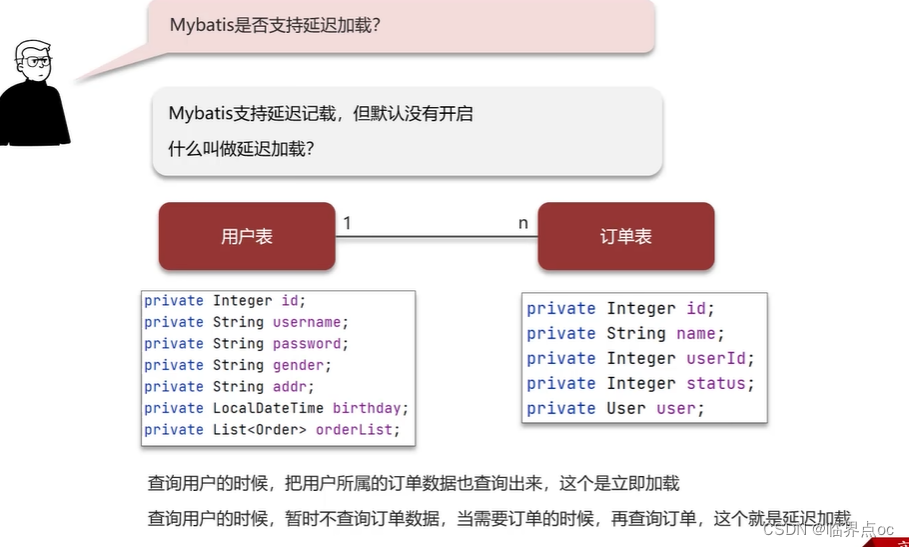
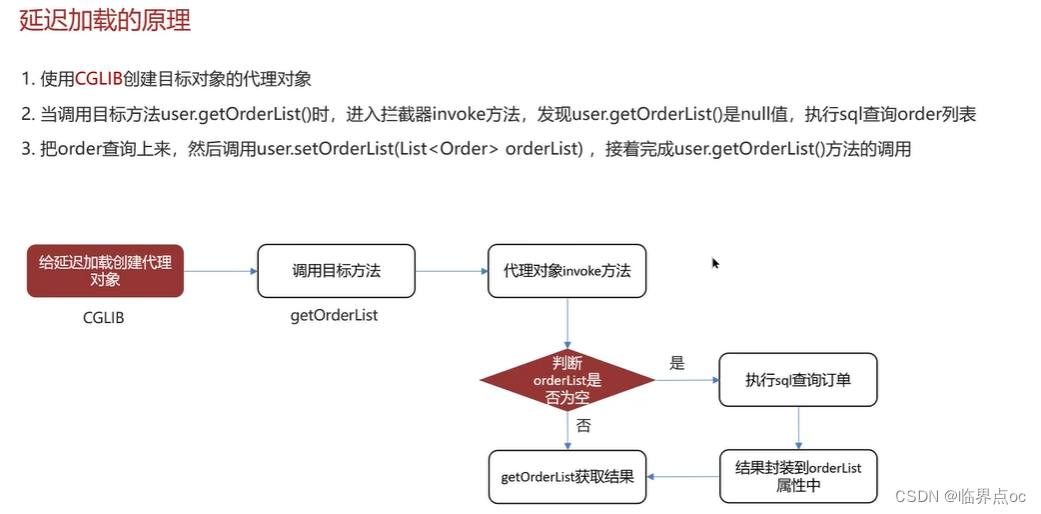

(3)MyBatis的一級、二級緩存用過嗎?
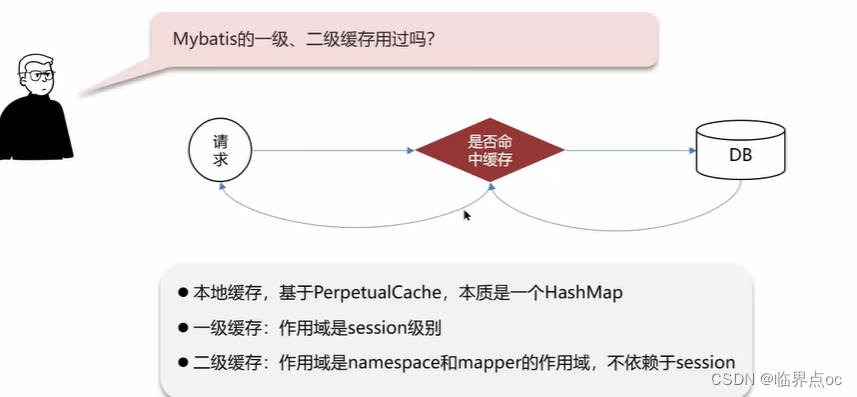
一級緩存
一級緩存:基于PerpetualCache的HashMap本地緩存,其存儲作用域為Session,當Session進行flush或close之后,該Session中的所有Cache就將清空,默認打開一級緩存。
二級緩存
二級緩存是基于namespace和mapper的作用域起作用的,不是依賴于SQL session,默認也是采用PerpetualCache,HashMap存儲

注意事項:
- 對于緩存數據更新機制,當某一個作用域(一級緩存Session/二級緩存Namespaces)進行了新增、刪除操作后,默認該作用域所有select中的緩存將被clear
- 二級緩存需要緩存的數據實現Serializable接口
- 只有會話提交或者關閉以后,一級緩存中的數據才會轉移到二級緩存中

五、SpringCloud
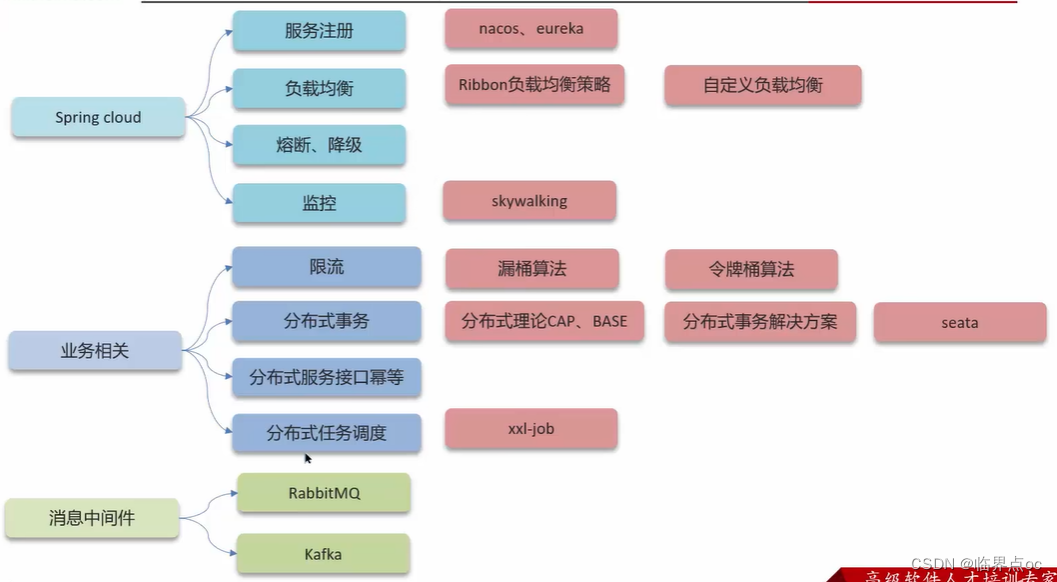
(1)Spring Cloud的5大組件有哪些?
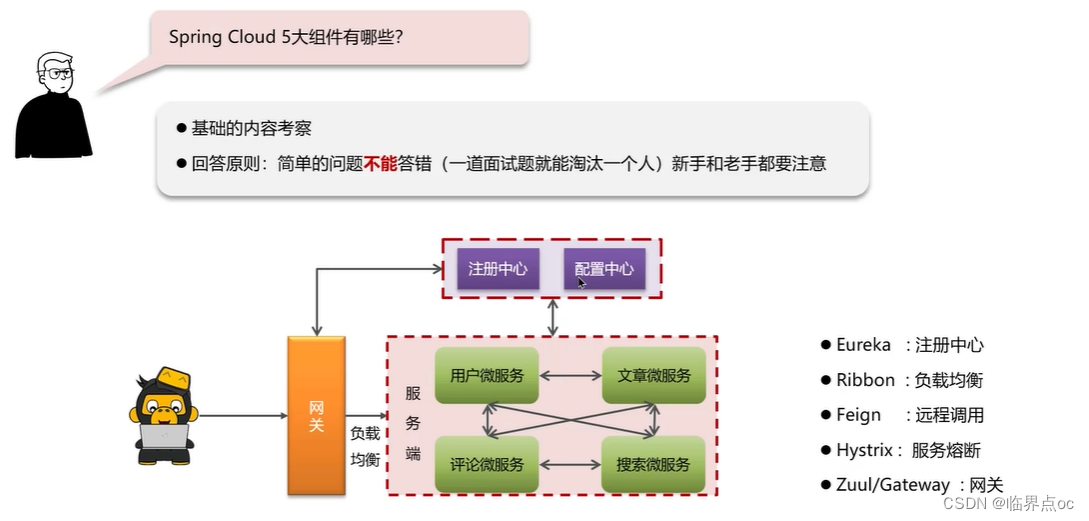
通常情況下:
Eureka/Nacos:注冊中心
Ribbon/SpringCloudLoadBalancer:負載均衡
Feign:遠程調用
Hystrix/Sentinel:服務熔斷
Zuul/Gateway:網關

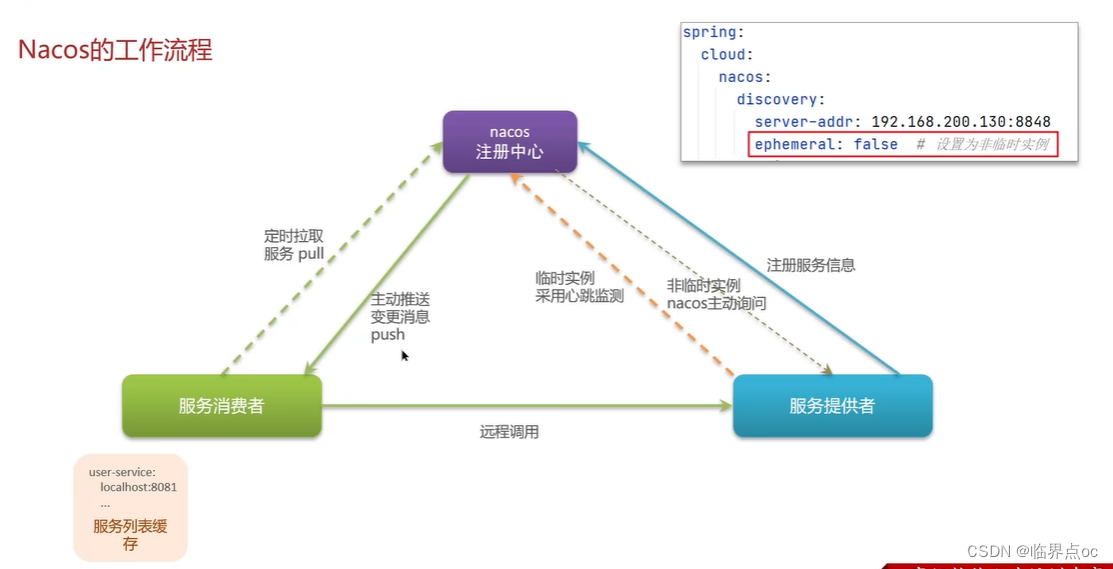
(2)服務注冊和發現是什么意思?Spring Cloud如何實現服務注冊發現?
常見的注冊中心:Eureka、Nacos、Zookeeper



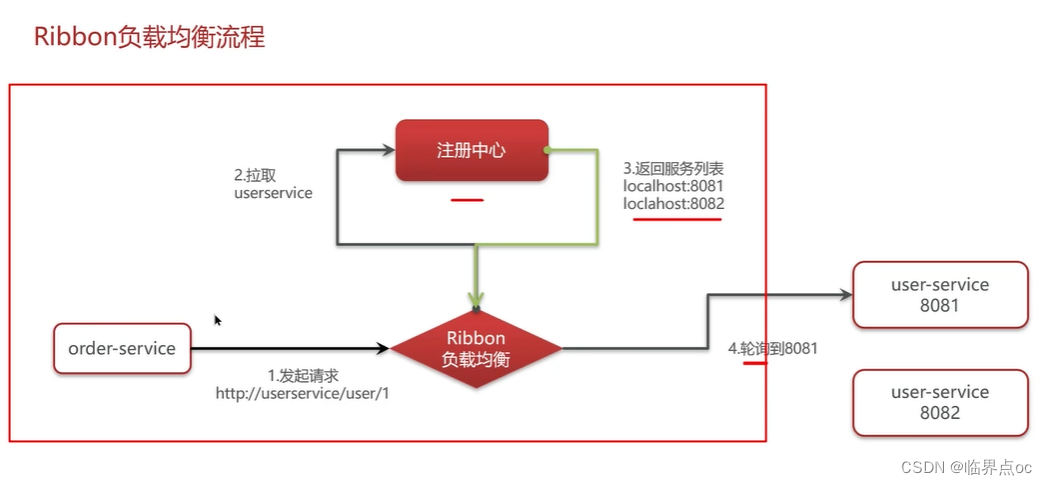
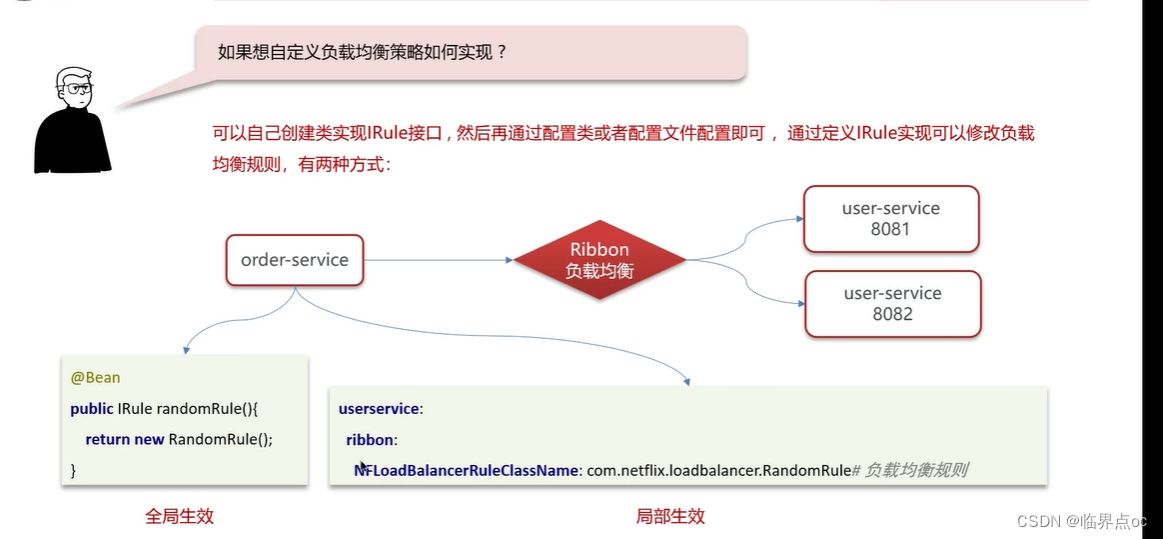
(3)你們項目負載均衡是如何實現的?


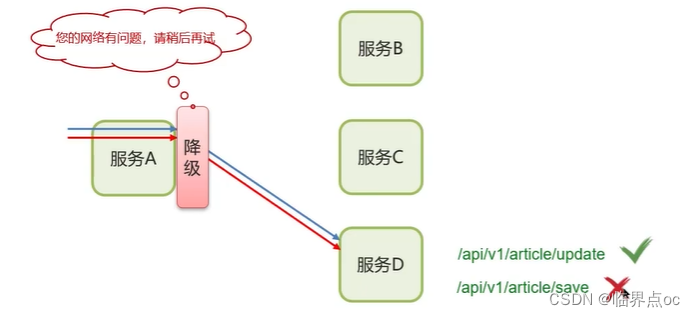
(4)什么是服務雪崩,怎么解決這個問題?

服務降級:是服務自我保護的一種方式,或者保護下游服務的一種方式,用于確保服務不會受請求突增影響變得不可用,確保服務不會崩潰
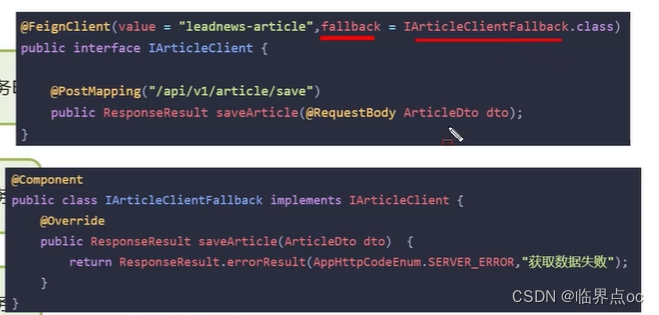
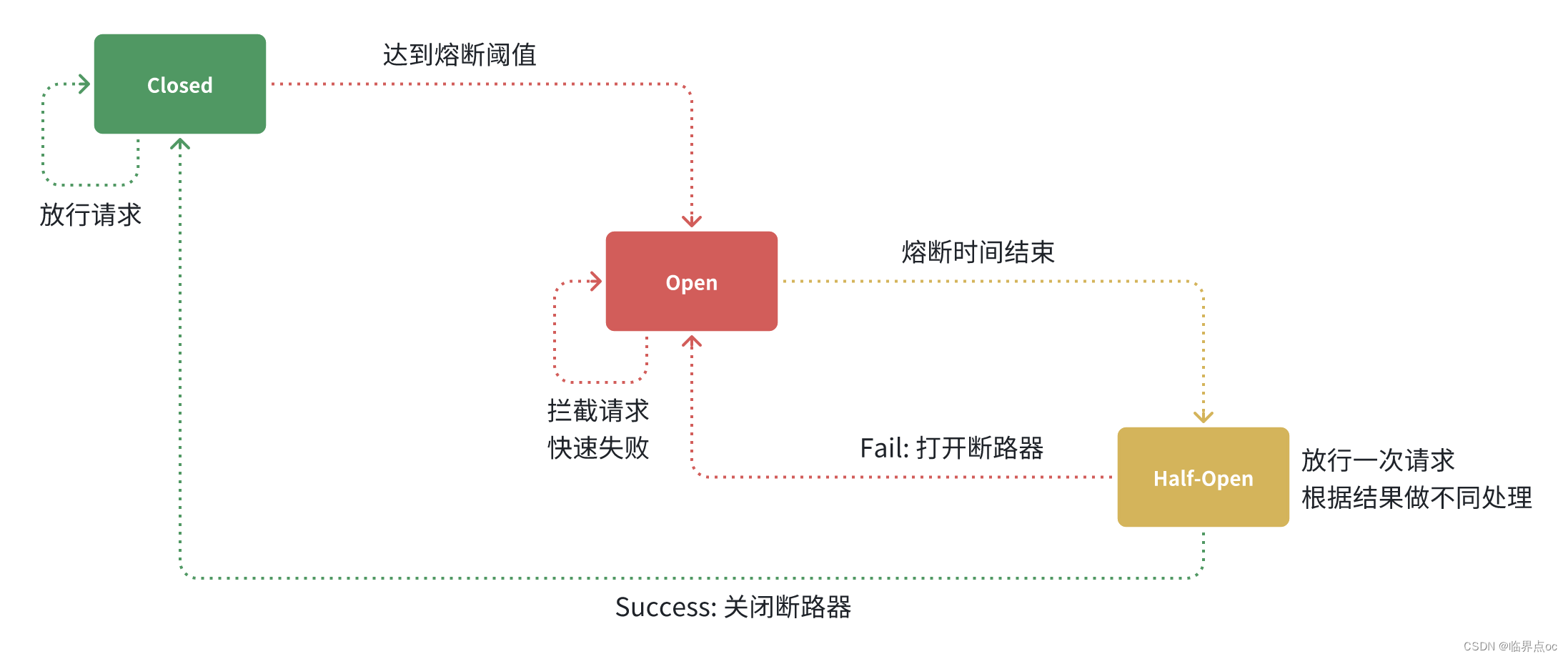
服務熔斷:Hystrix熔斷機制,用于監控微服務調用情況,默認是關閉的,如果需要開啟需要在引導類上添加注解:@EnableCircuitBreaker。如果檢測到10秒內請求的失敗率超過50%,就觸發熔斷機制,之后每隔5秒重新嘗試請求微服務,如果微服務不能響應,繼續走熔斷機制。如果微服務可達,則關閉熔斷機制,恢復正常請求。

(5)你們的微服務是怎么監控的?
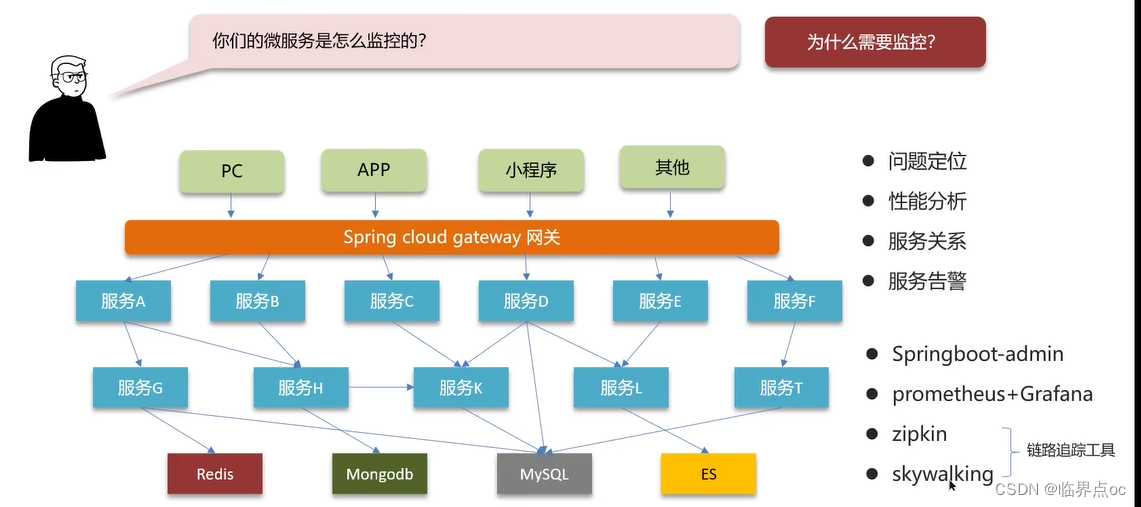
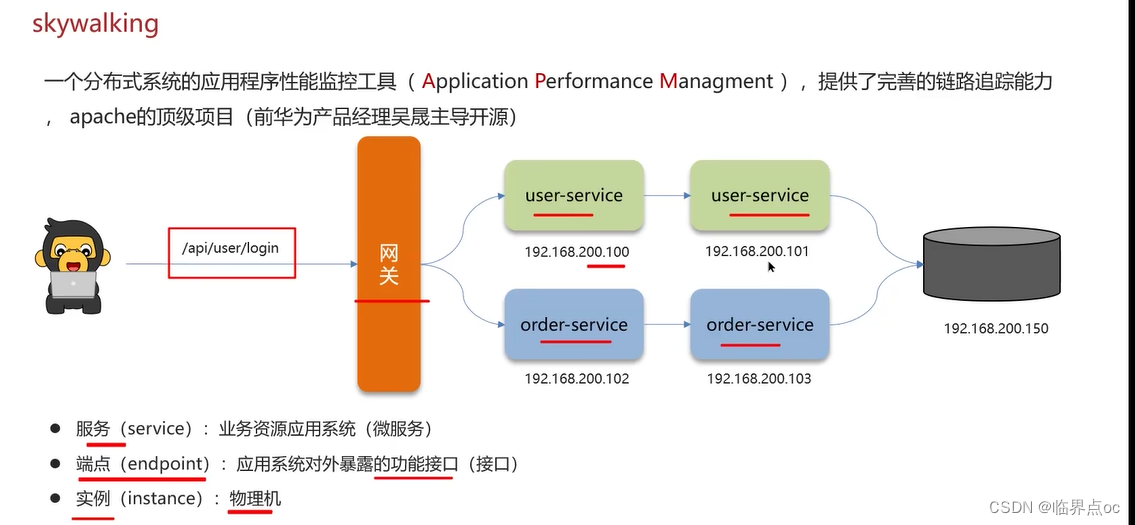
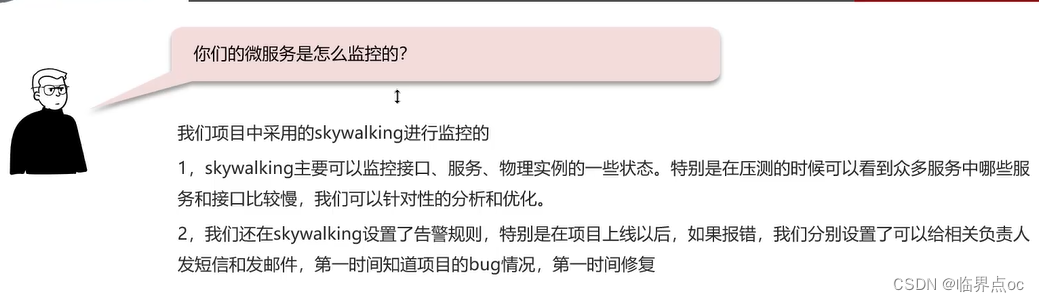
(6)你們項目中有沒有做過限流?怎么做的?
為什么要限流?
- 并發的確大(突發流量)
- 防止用戶惡意刷接口
限流的實現方式:
- Tomcat:可以設置最大連接數
- Nginx:漏桶算法
- 網關:令牌桶算法
- 自定義攔截器
Nginx限流
- 控制速率(突發流量)

- 控制并發連接數

網關限流
yml配置文件中,微服務路由設置添加局部過濾器RequestRateLimiter


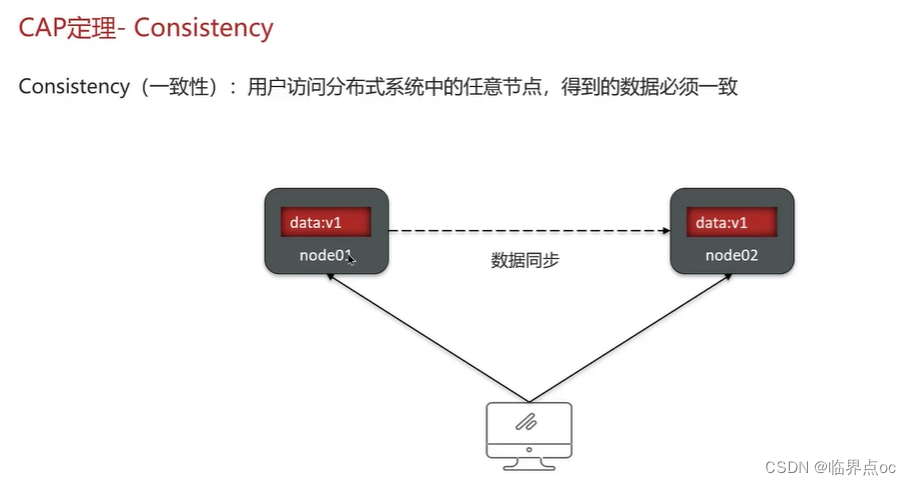
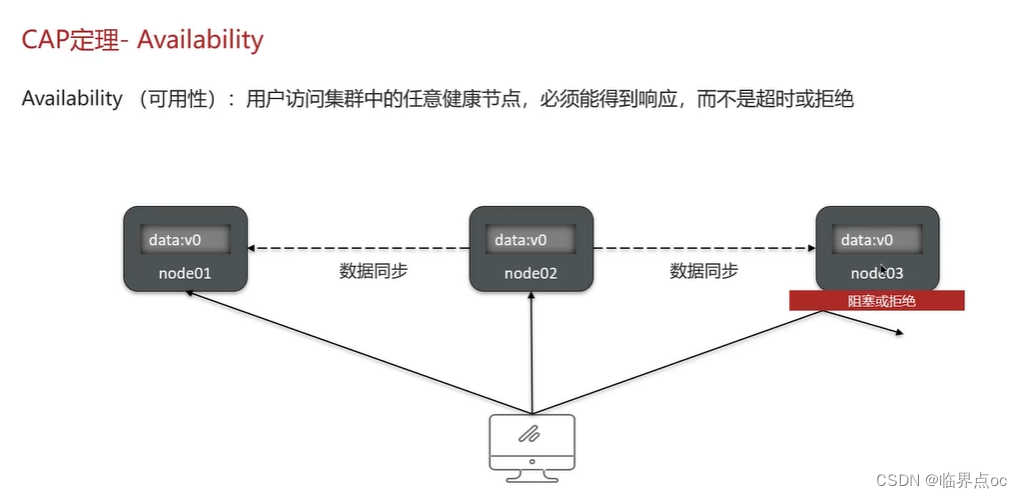
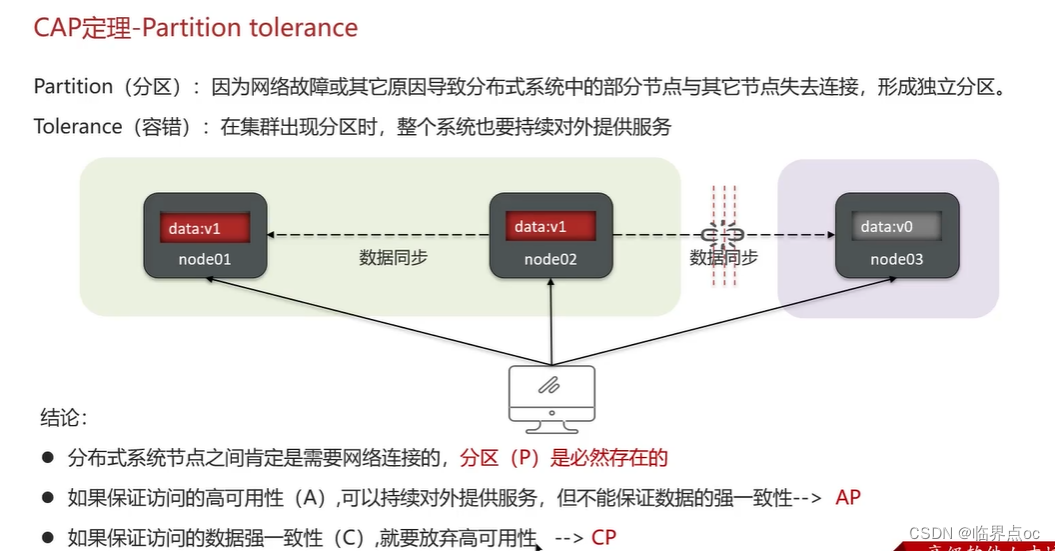
(7)解釋一下CAP和BASE
CAP定理
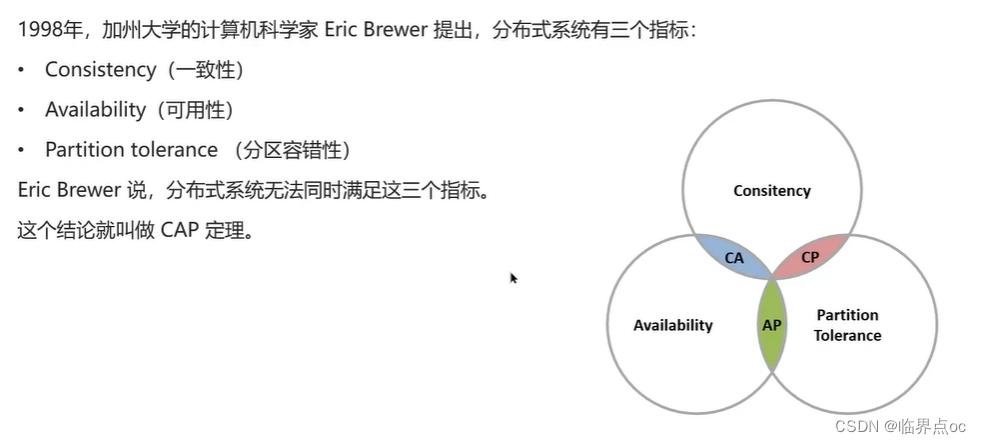
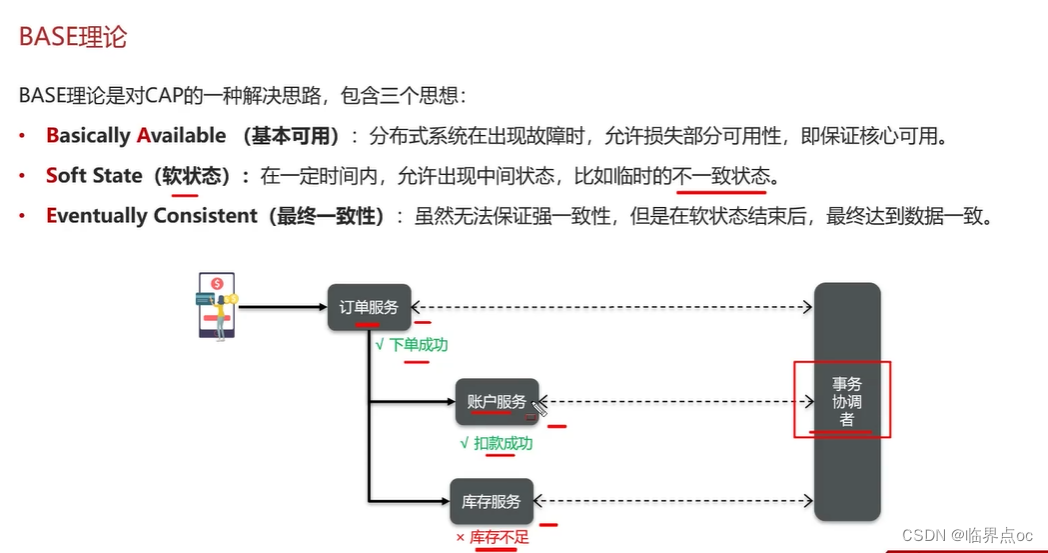
BASE理論

(8)你們采用的是哪種分布式事務解決方案?
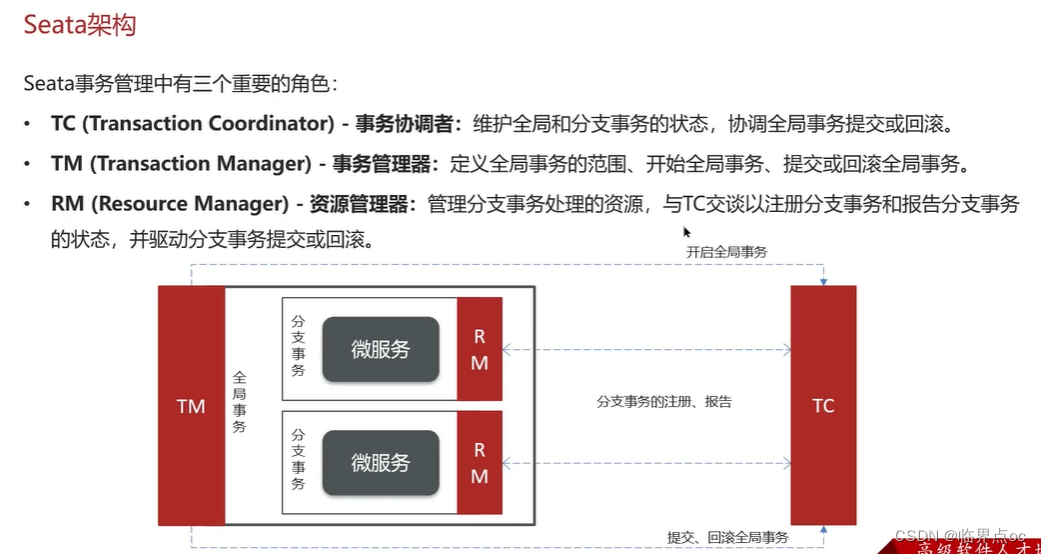
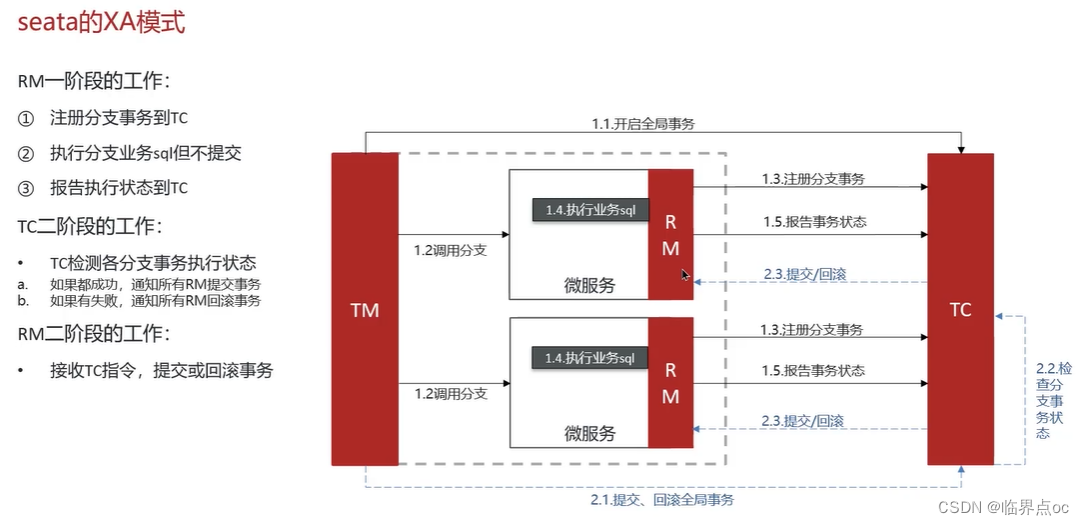

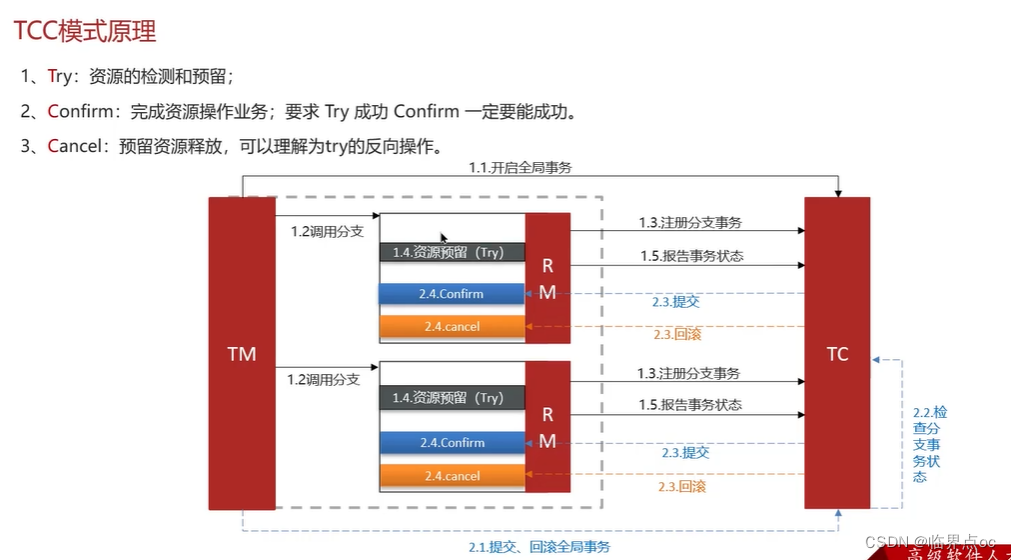
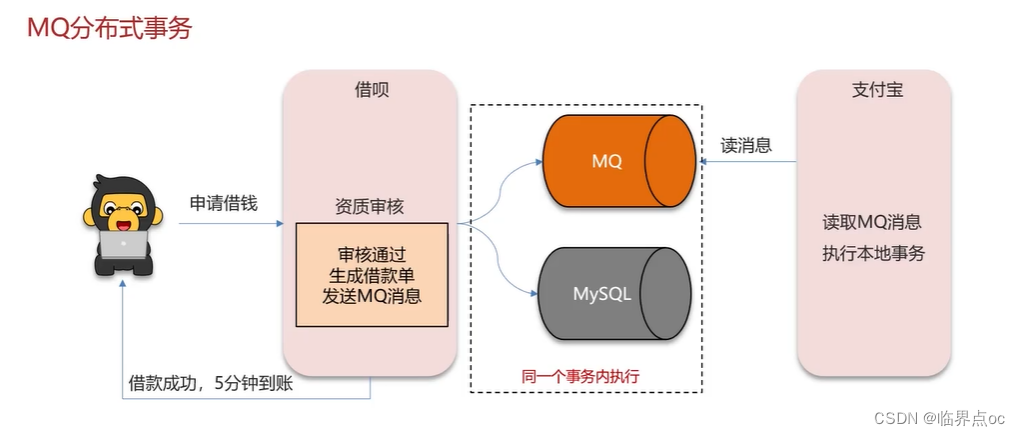

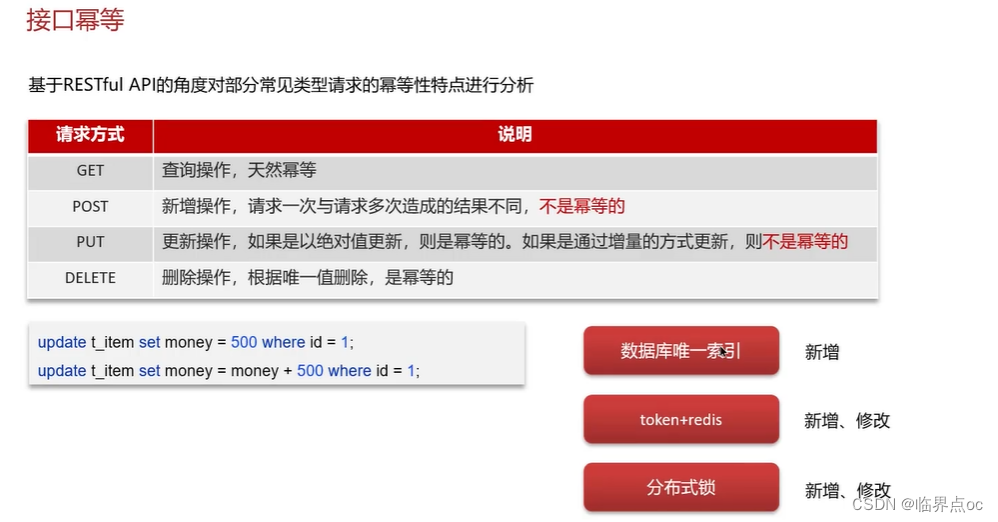
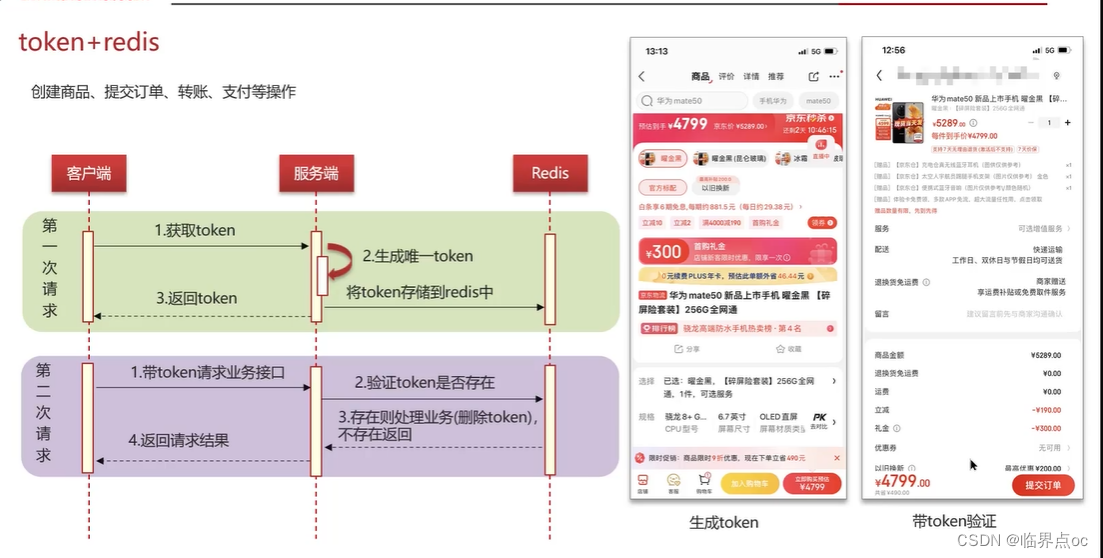
(9)分布式服務的接口冪等性如何設計?


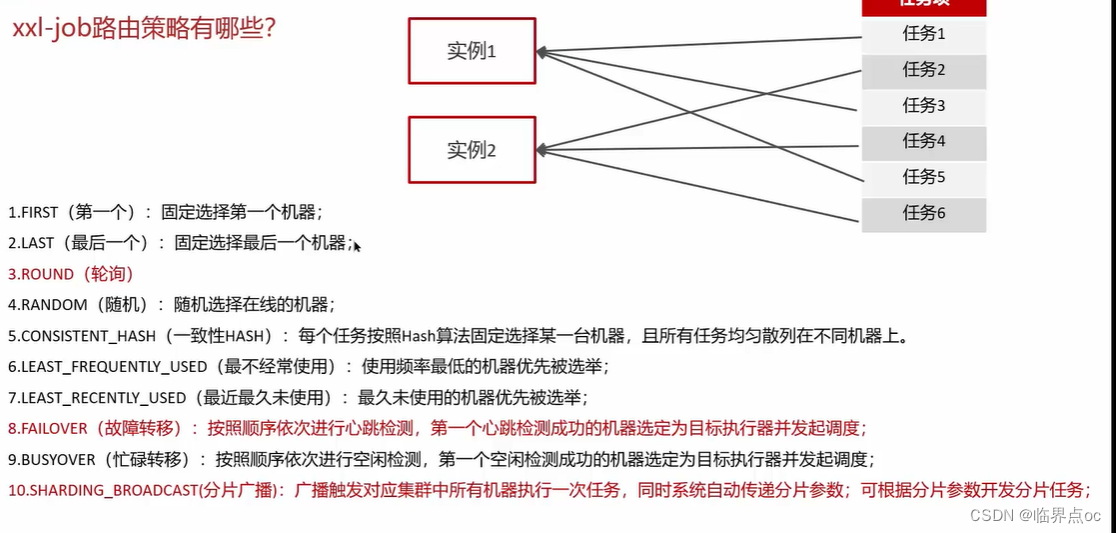
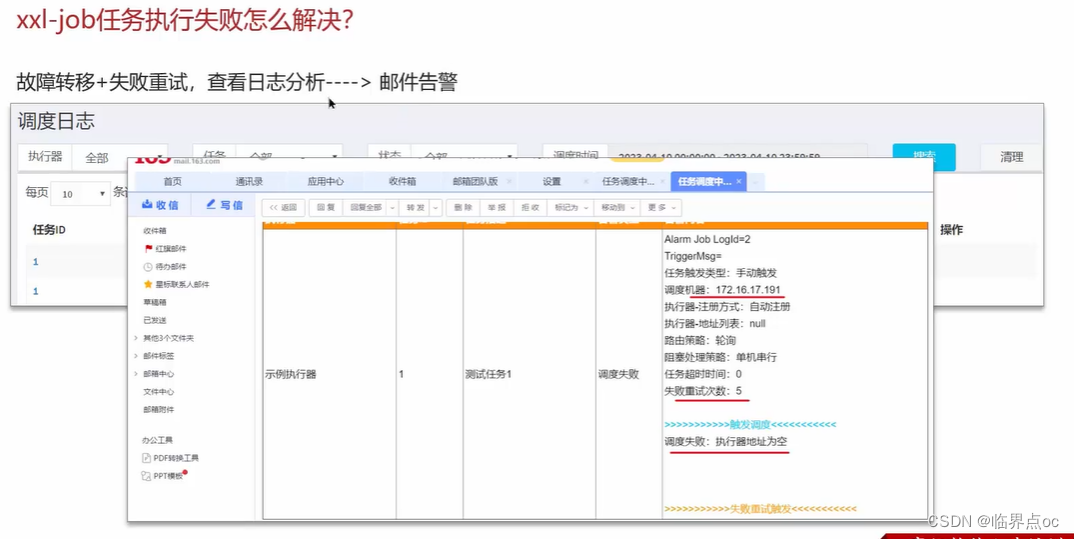
(10)你們項目中使用了什么分布式任務調度?



六、RabbitMQ
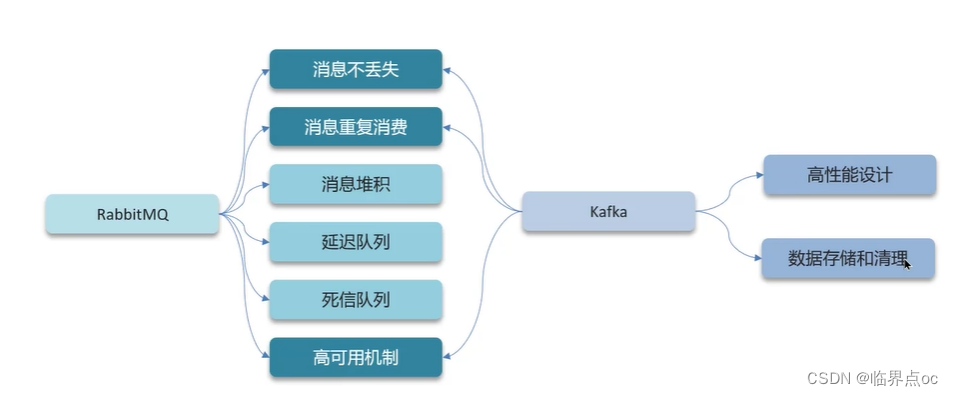
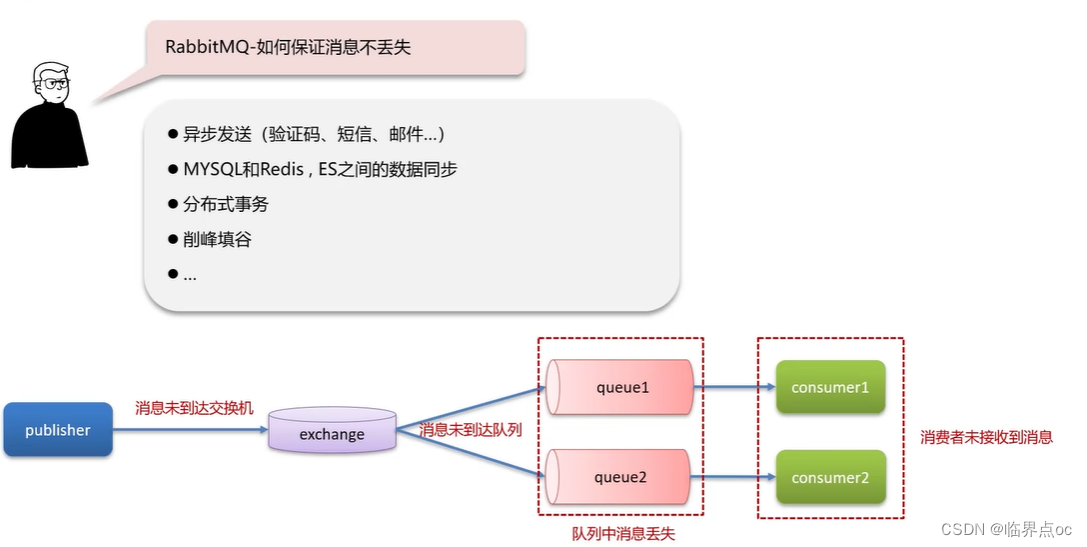
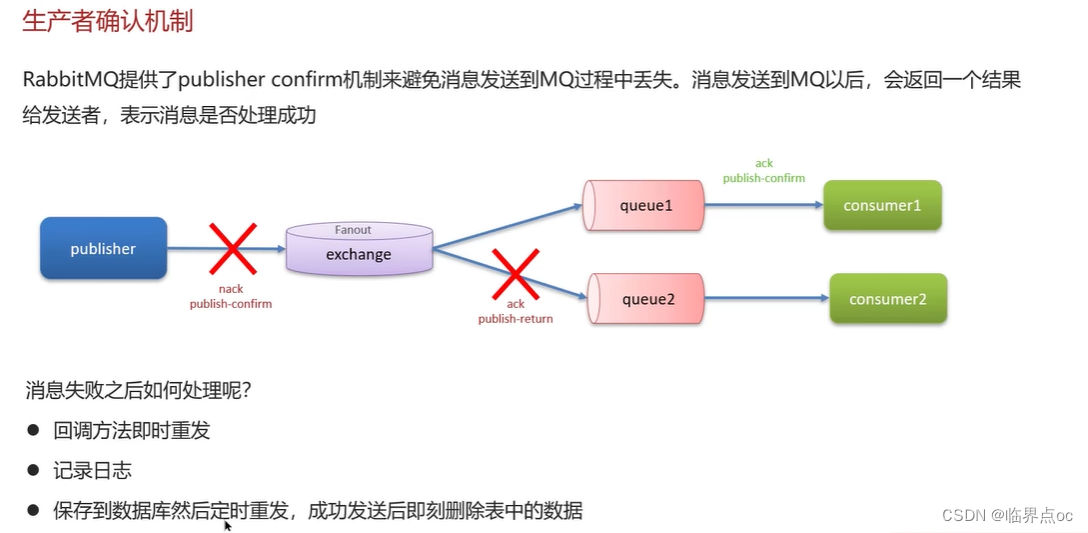
(1)RabbitMQ如何保證消息不丟失?

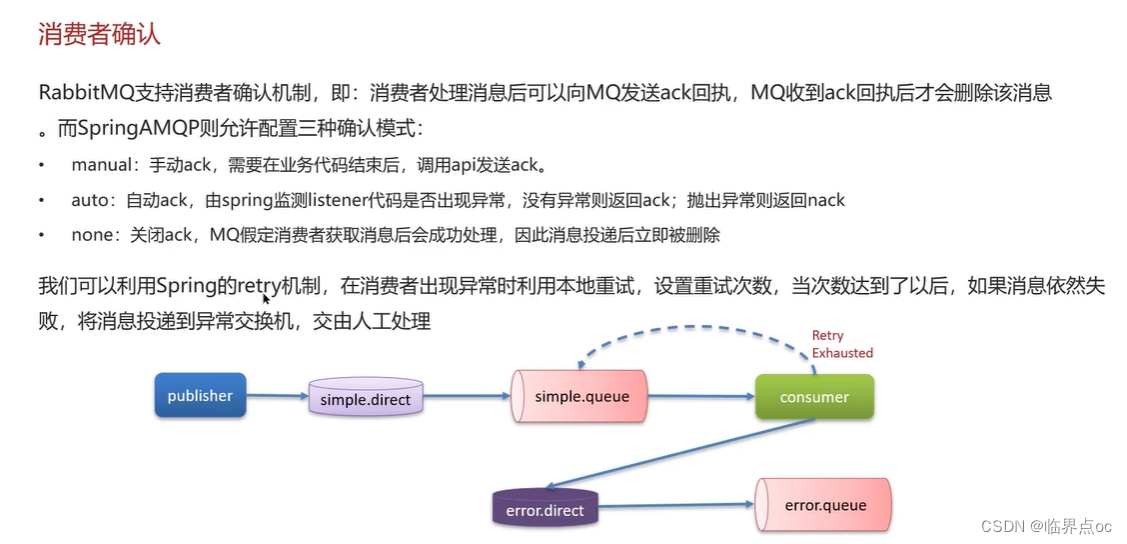


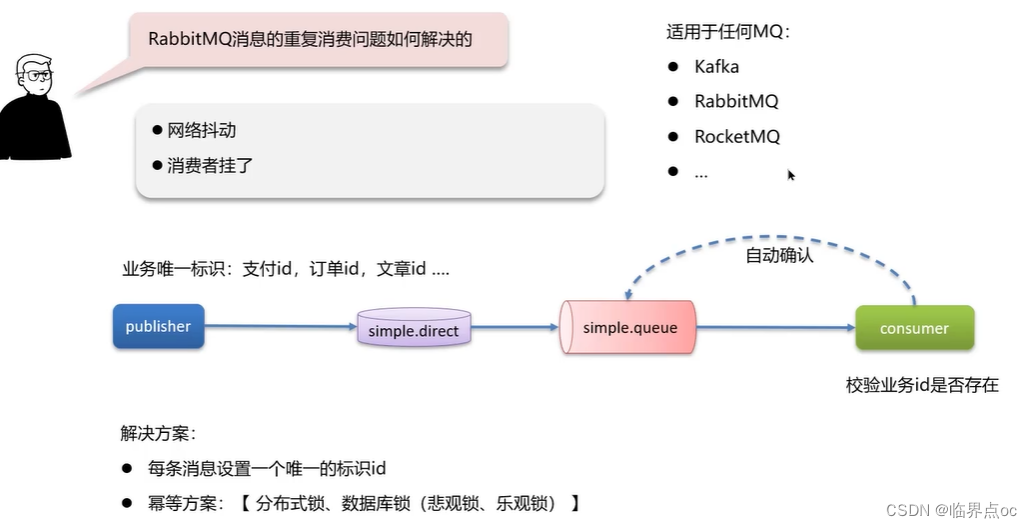
(2)RabbitMQ消息的重復消費問題如何解決?

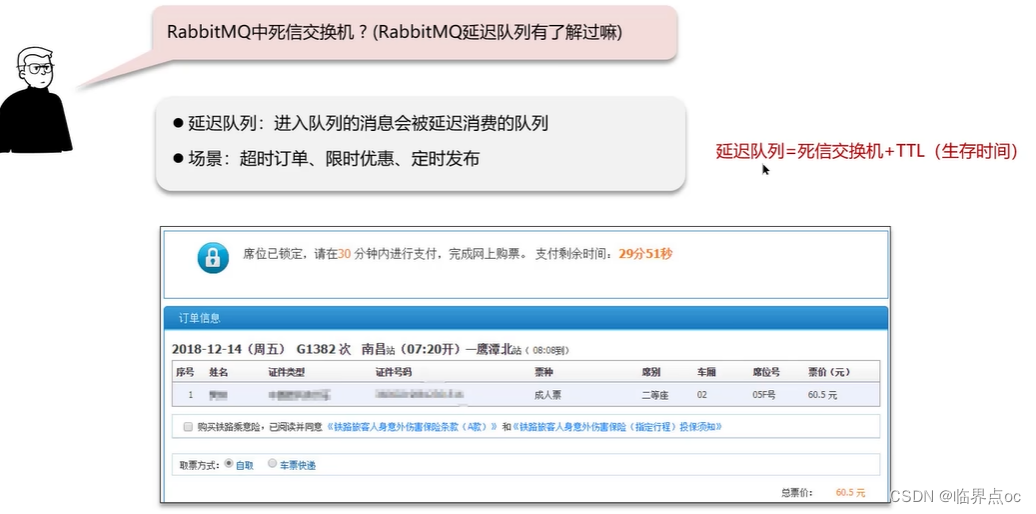
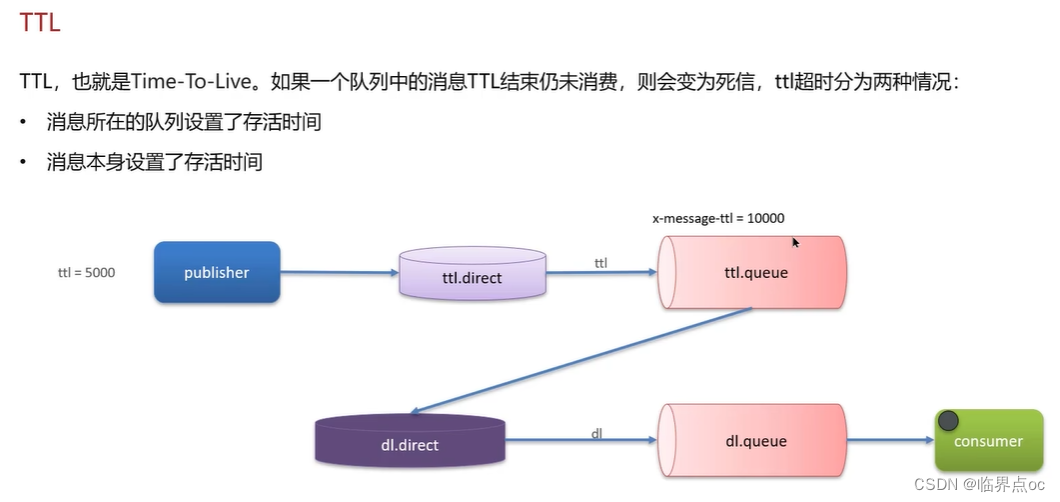
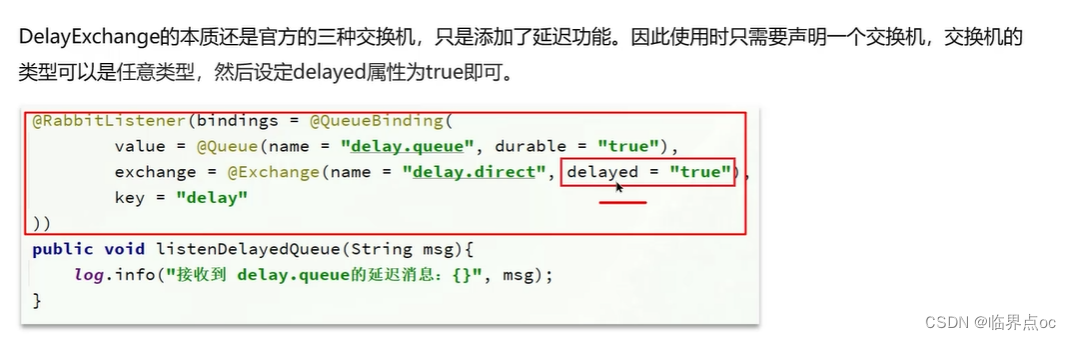
(3)RabbitMQ中死信交換機?(RabbitMQ延遲隊列有了解過嗎?)


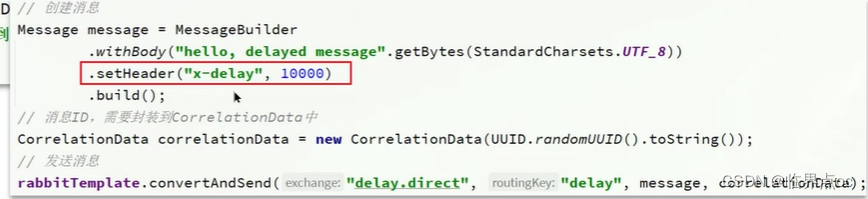
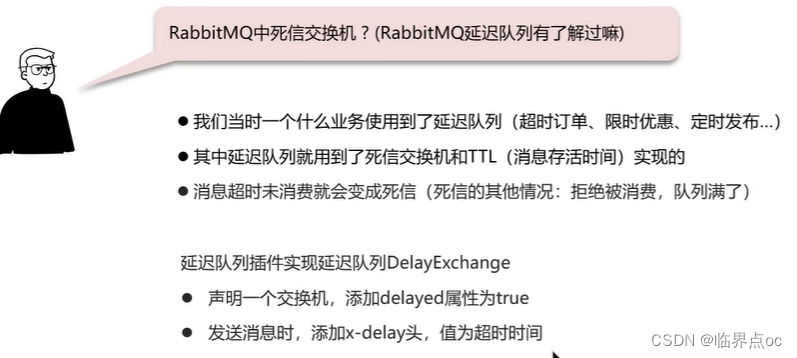

(4)RabbitMQ如果有100萬消息堆積在MQ,如何解決(消息堆積怎么解決)
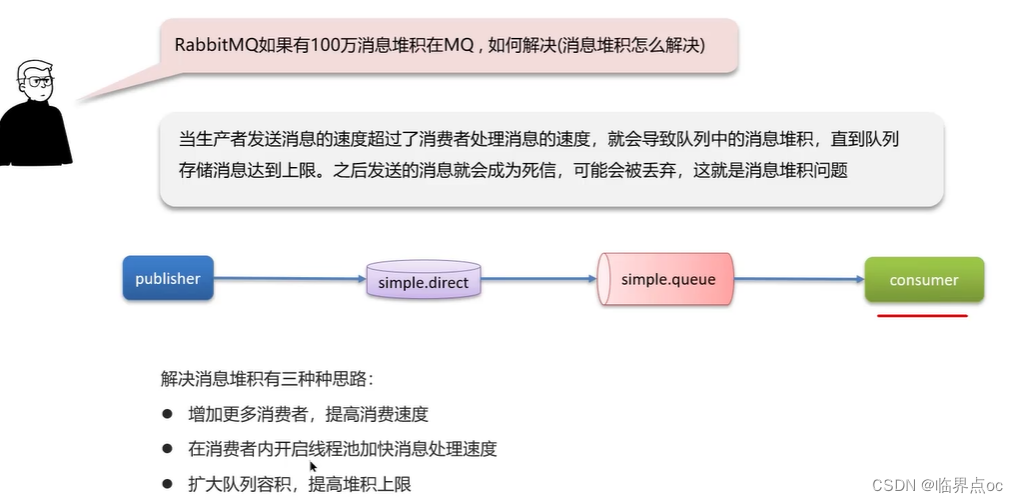
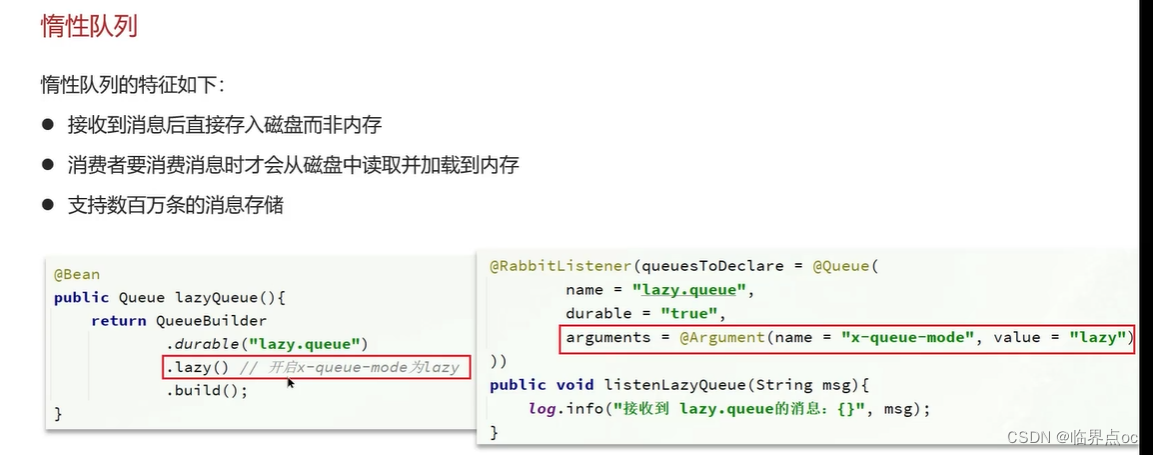


(5)RabbitMQ的高可用機制有了解過嗎?
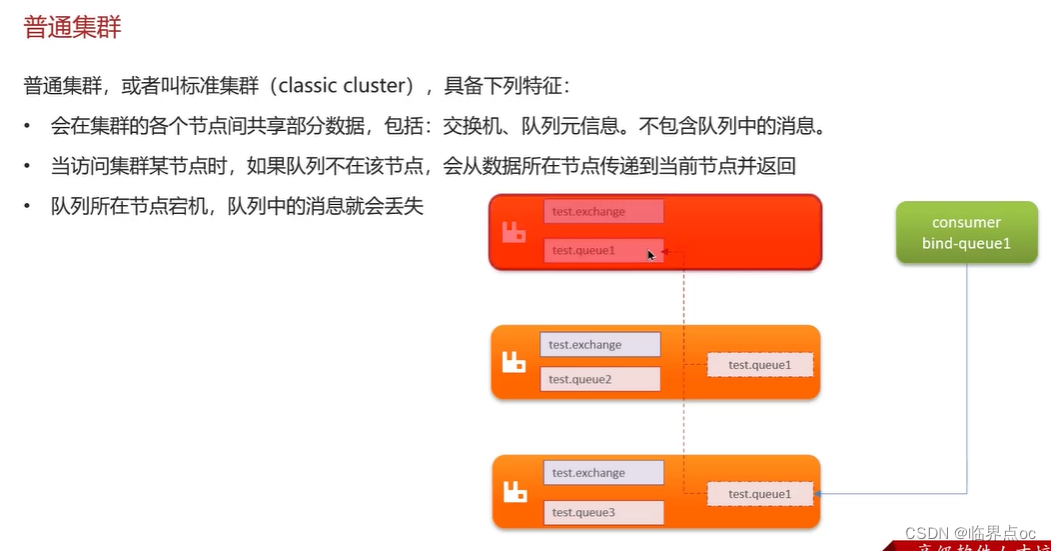




七、Kafka
(1)Kafka是如何保證消息不丟失?
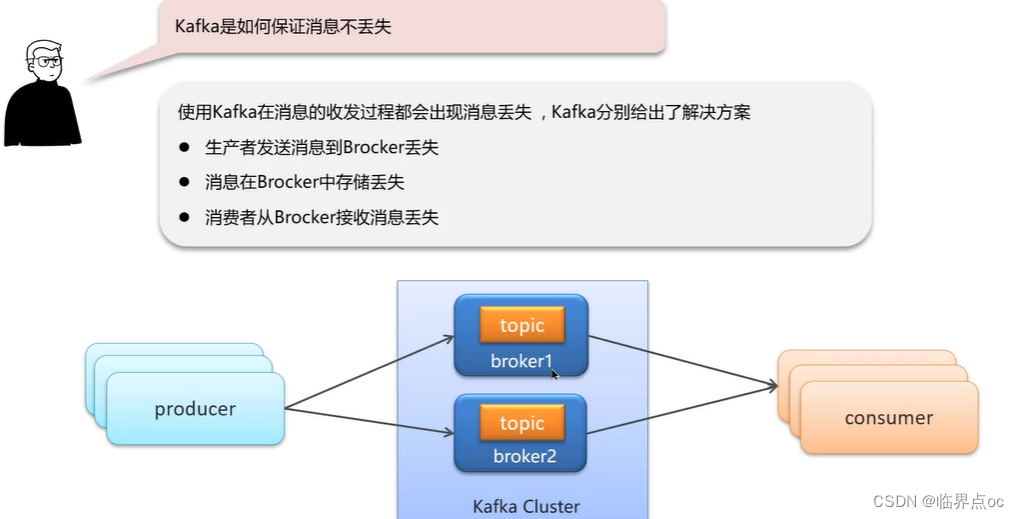
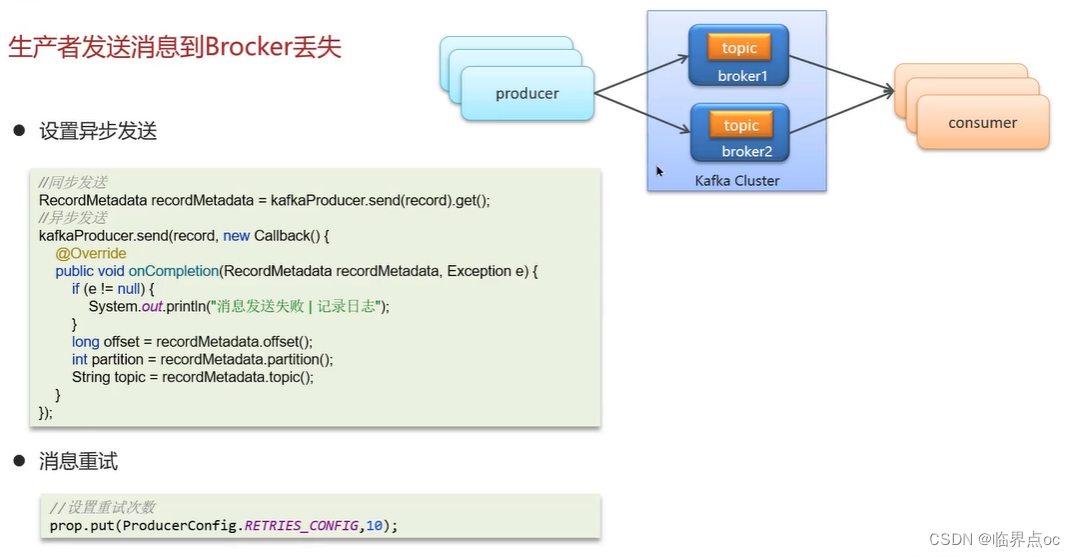
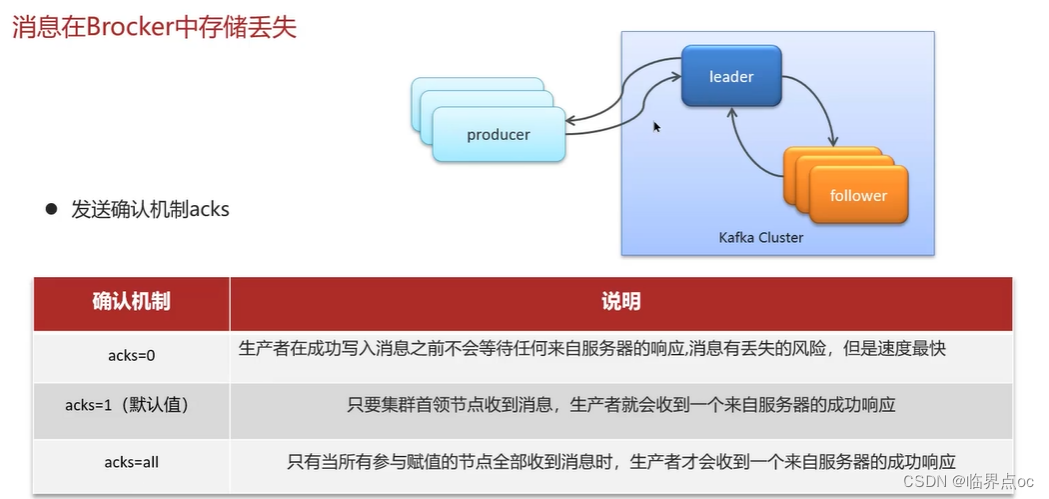

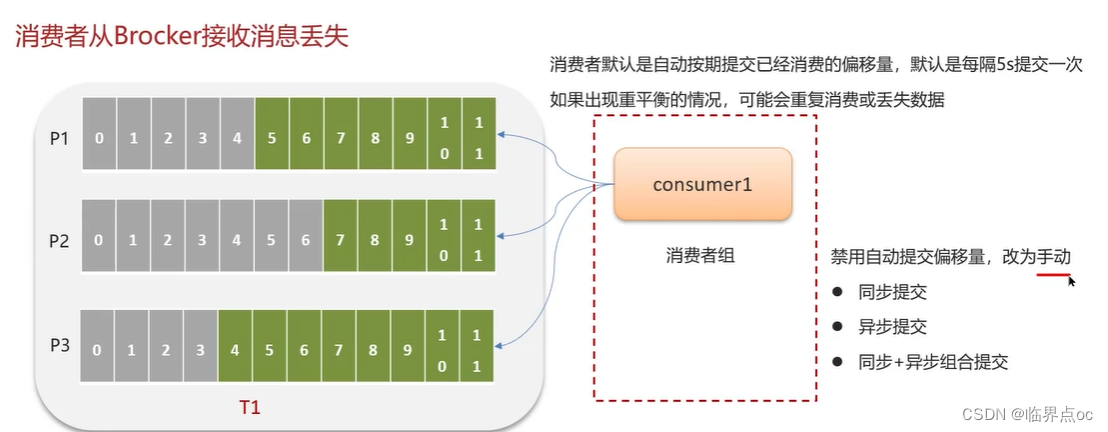



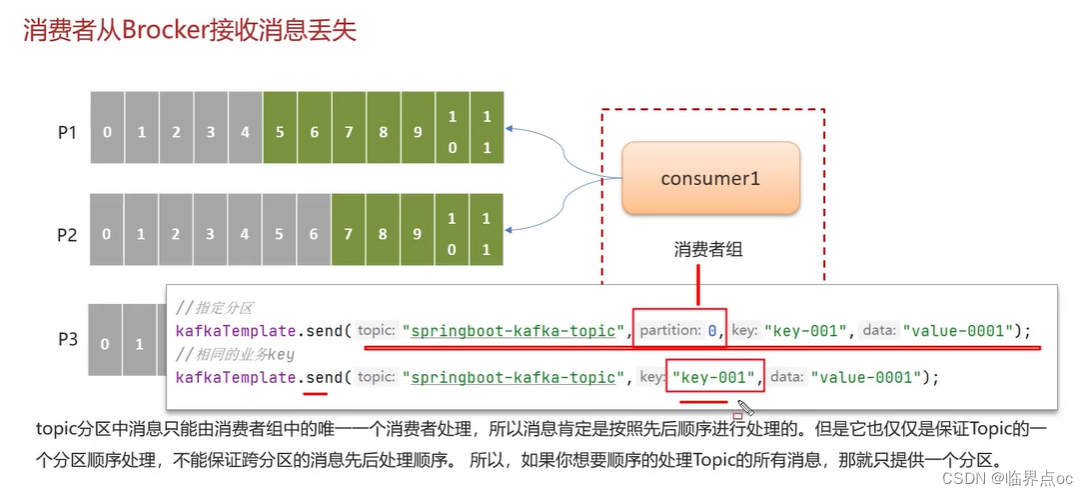
(2)Kafka是如何保證消費的順序性的?



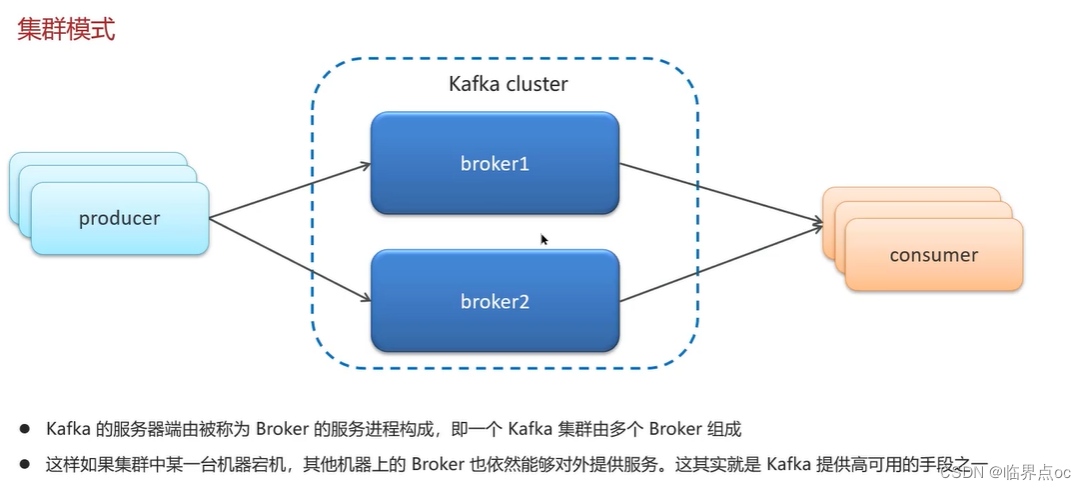
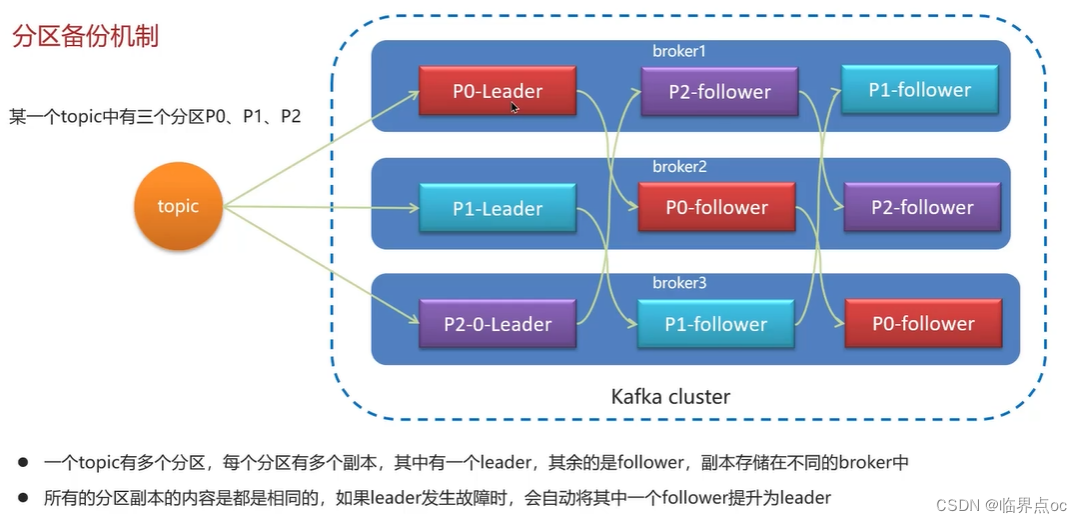
(3)Kafka的高可用機制有了解過嗎?
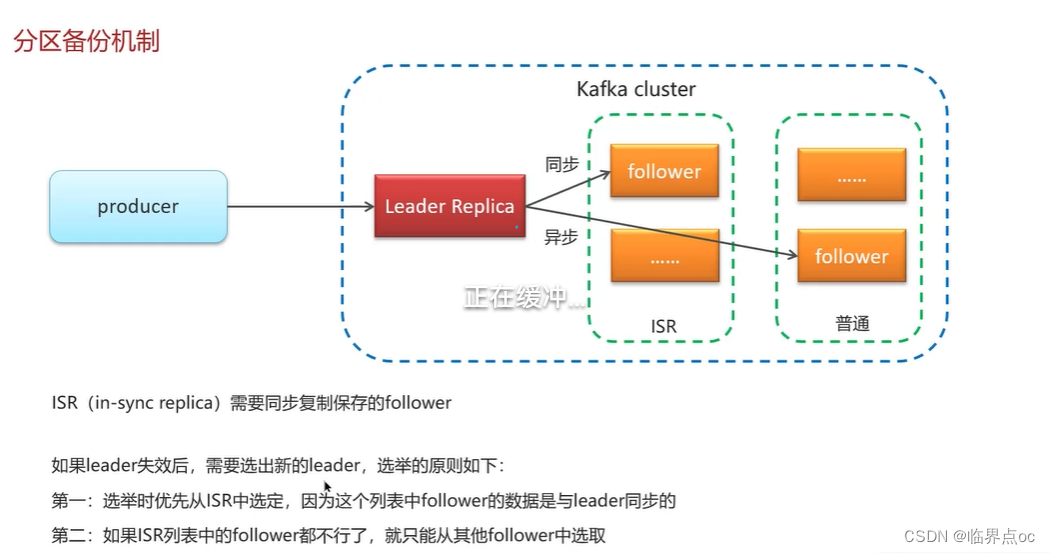



(4)Kafka數據清理機制了解過嗎?




(5)Kafka中實現高性能的設計有了解過嗎?



八、Java集合
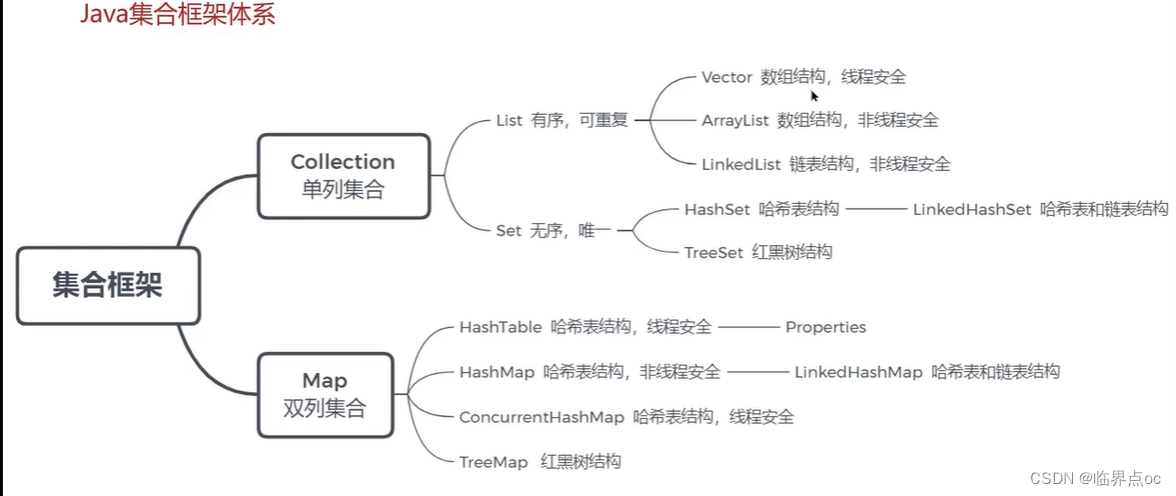
1. 數據結構


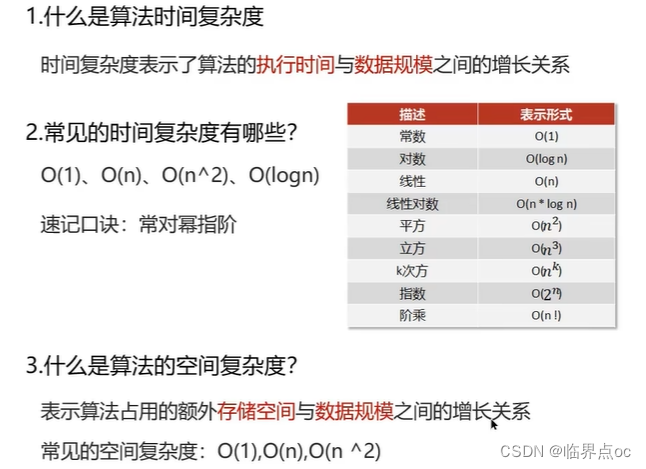
(1)數組
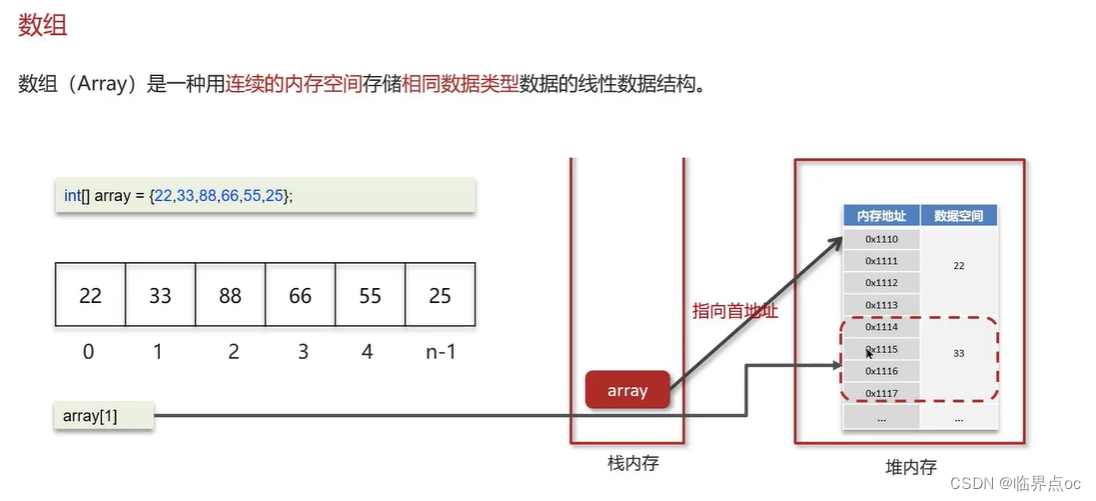
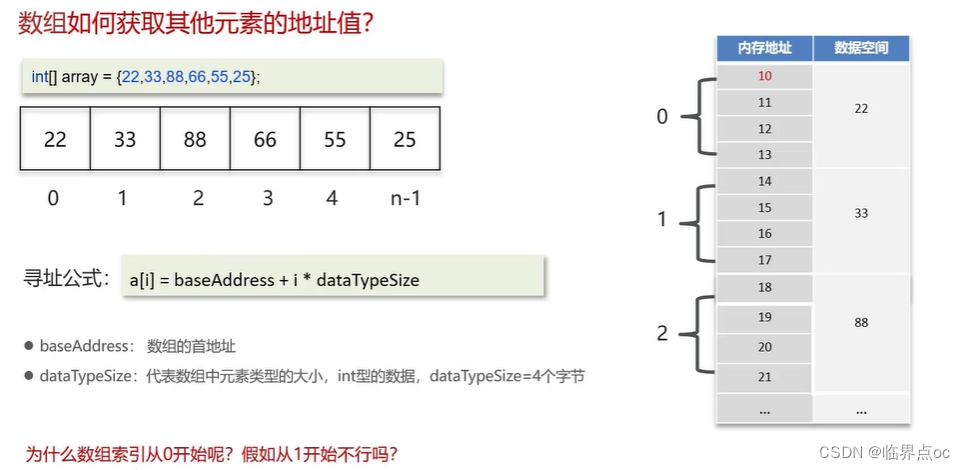




(2)ArrayList源碼分析

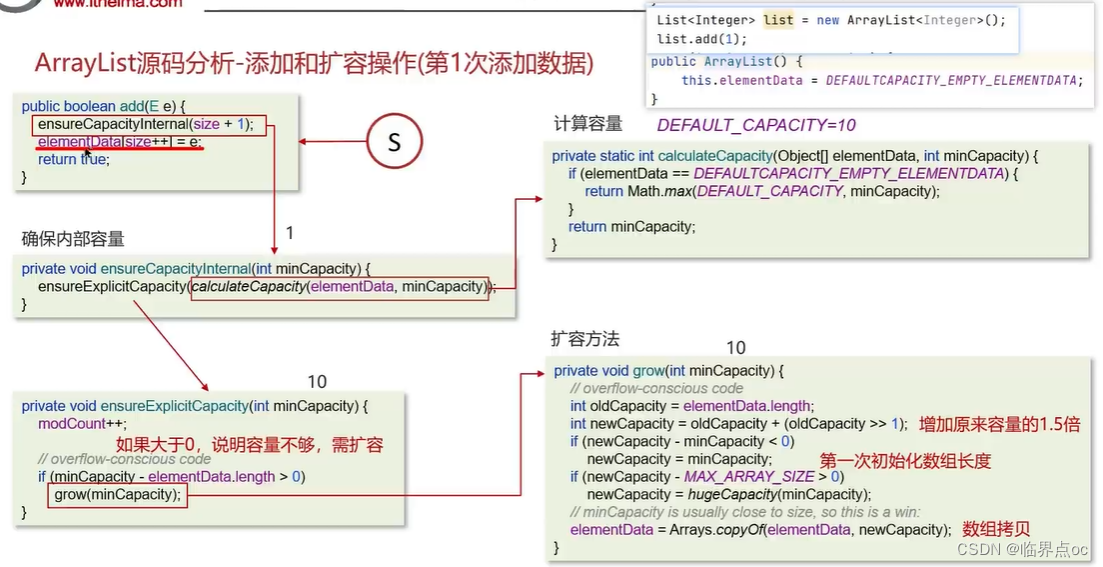
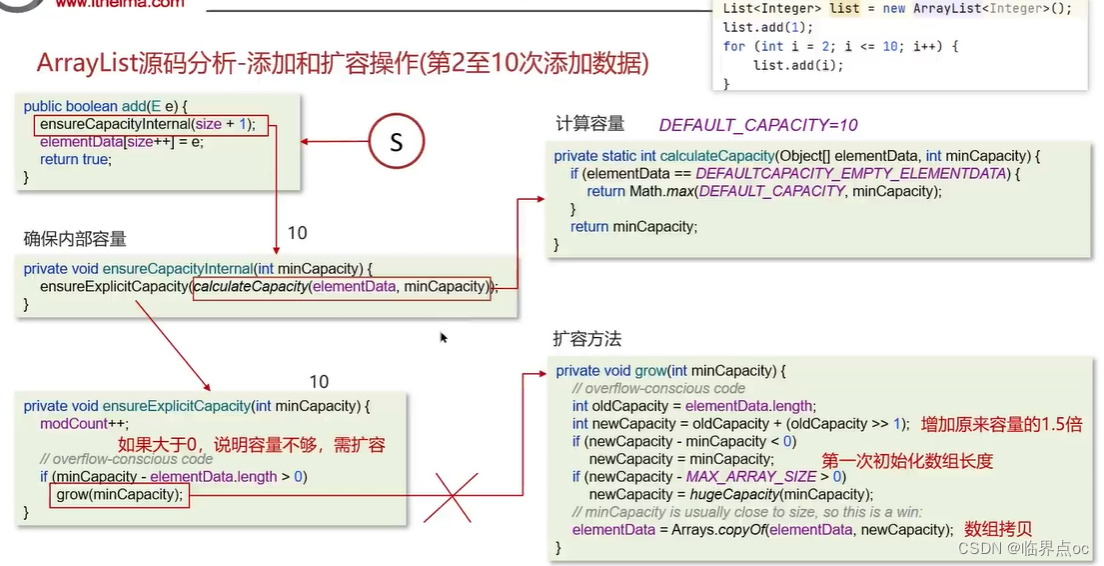
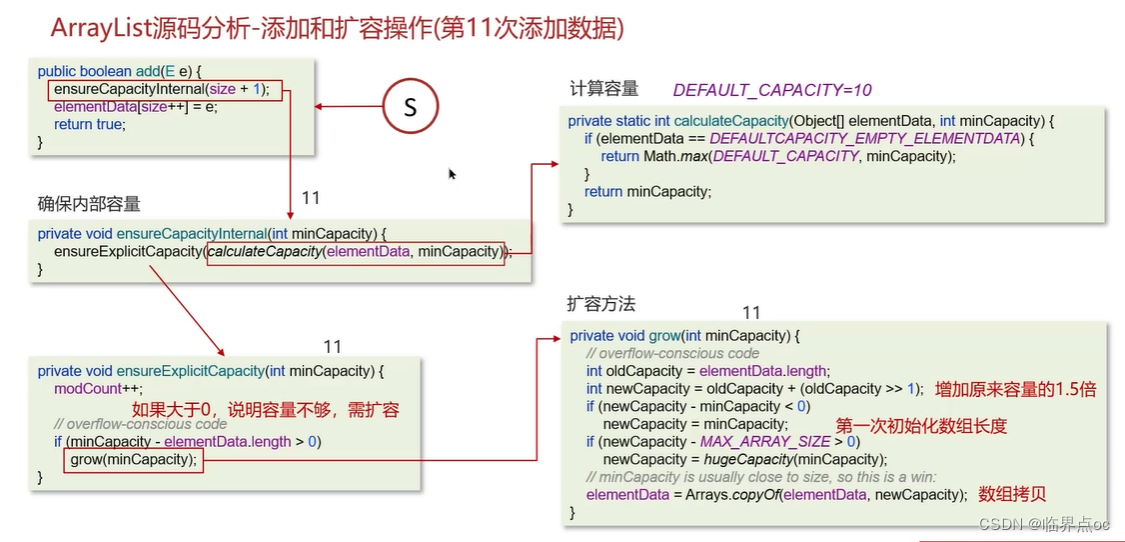
(3)ArrayList底層的實習原理是什么?

(4)ArrayList list = new ArrayList(10)中的list擴容幾次

(5)如何實現數組和List之間的轉換


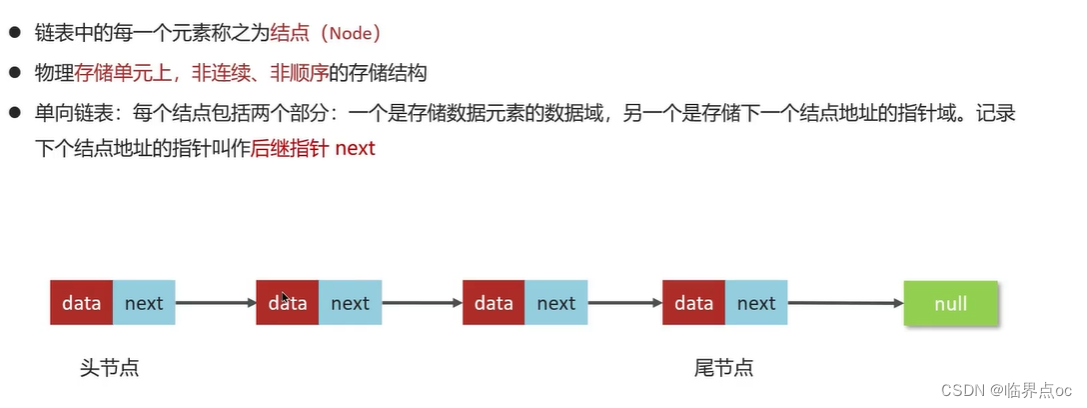
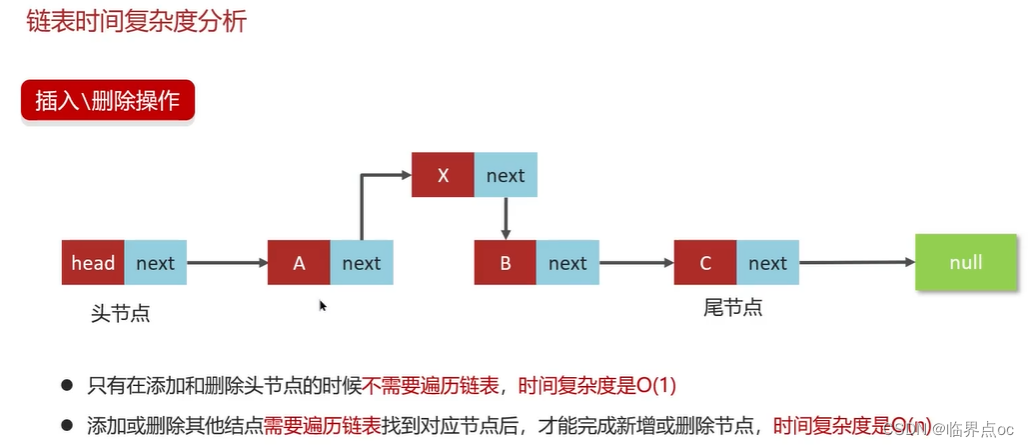
(6)單向鏈表
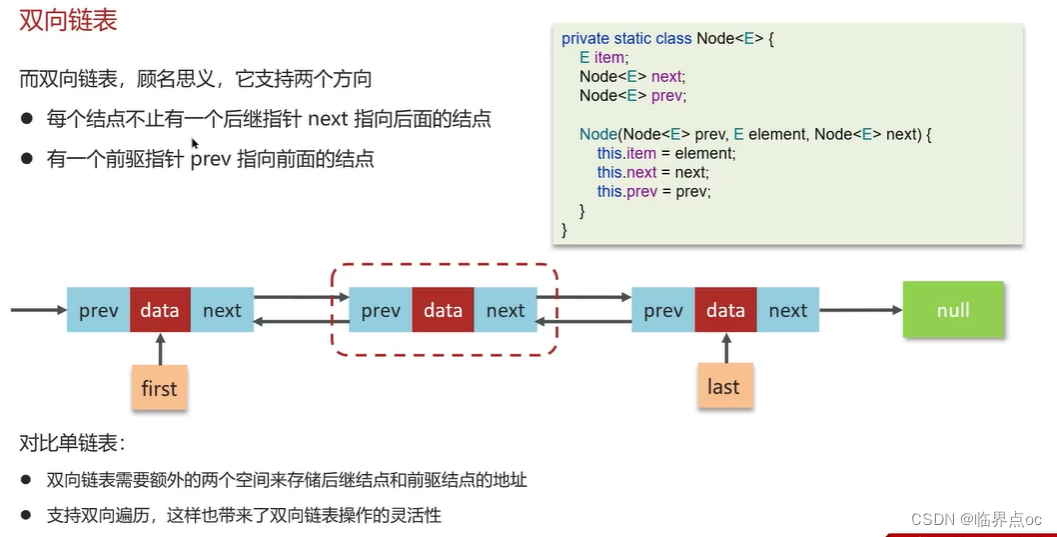
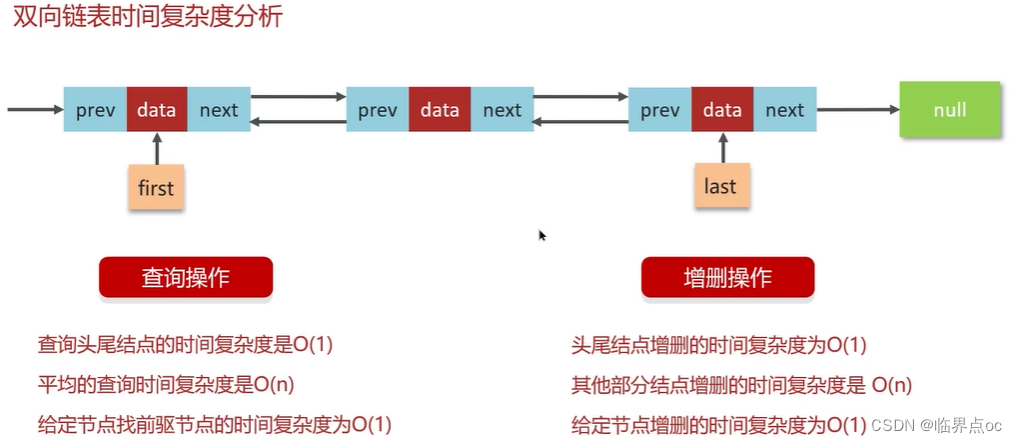
(7)雙向鏈表

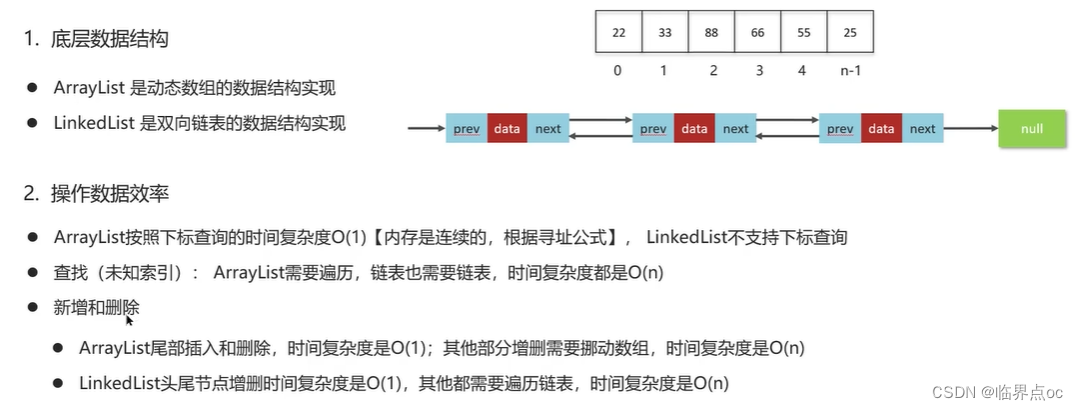
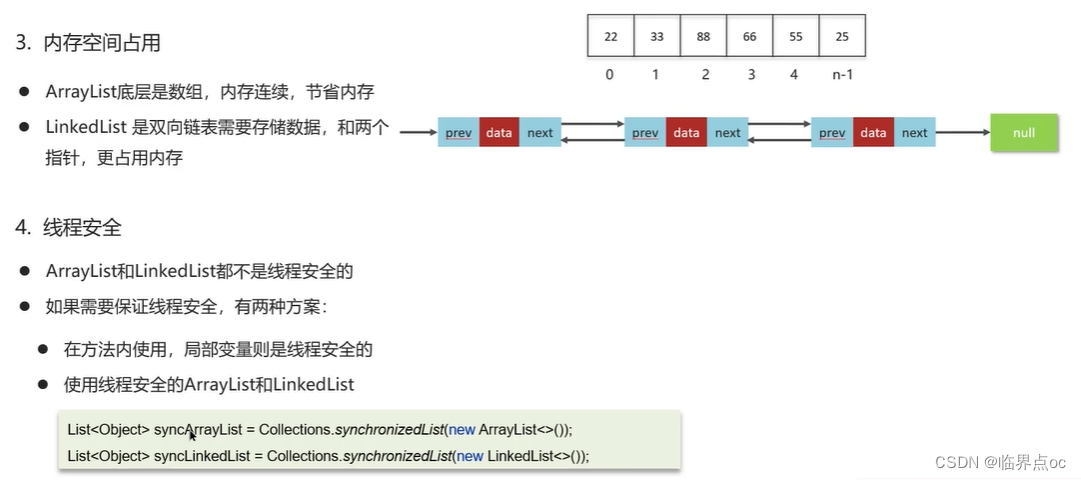
(8)ArrayList和LinkedList的區別是什么?
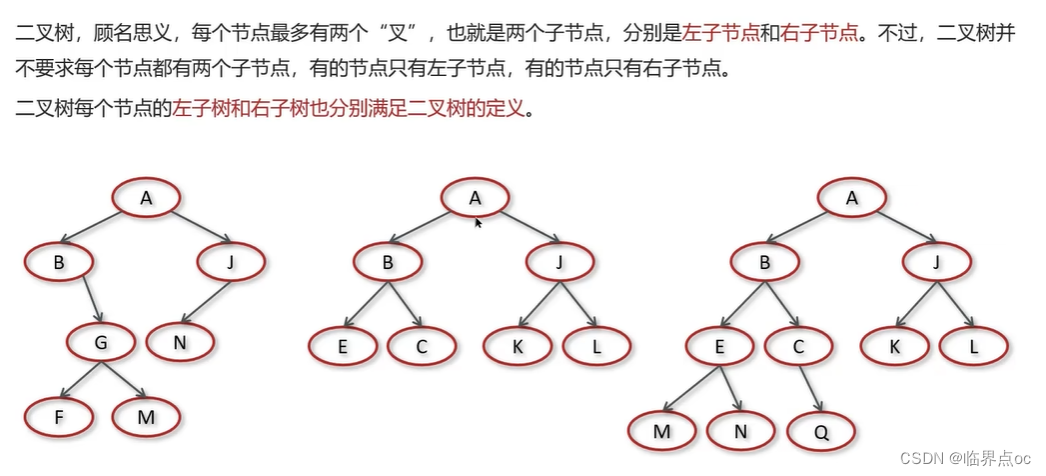
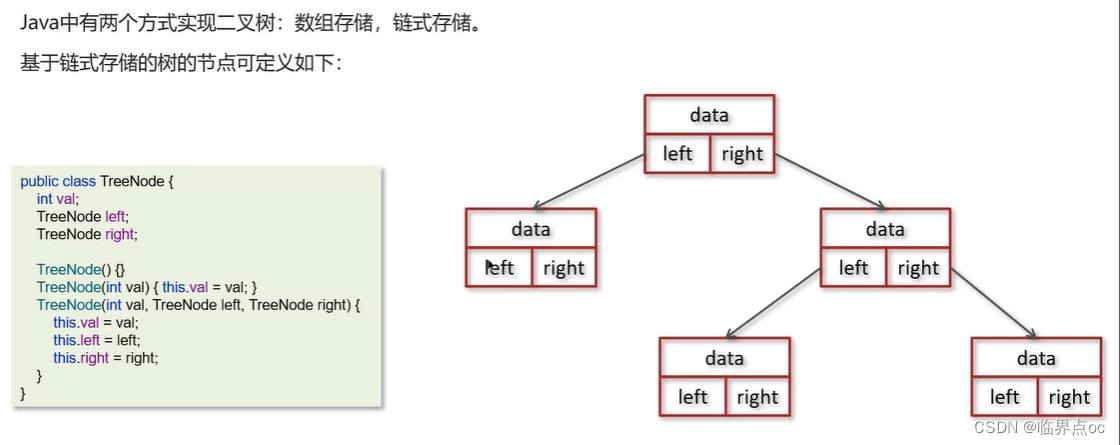
(9)二叉樹

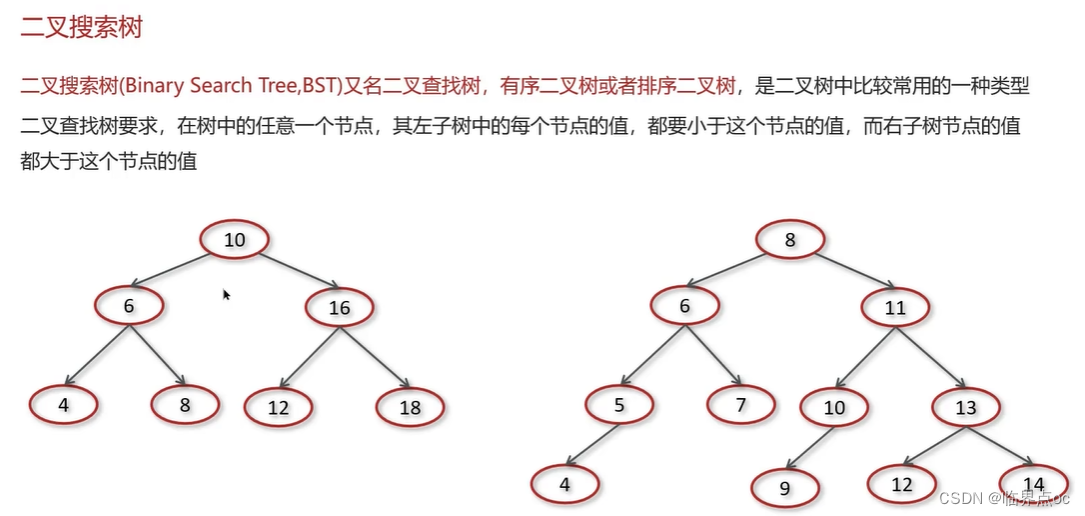
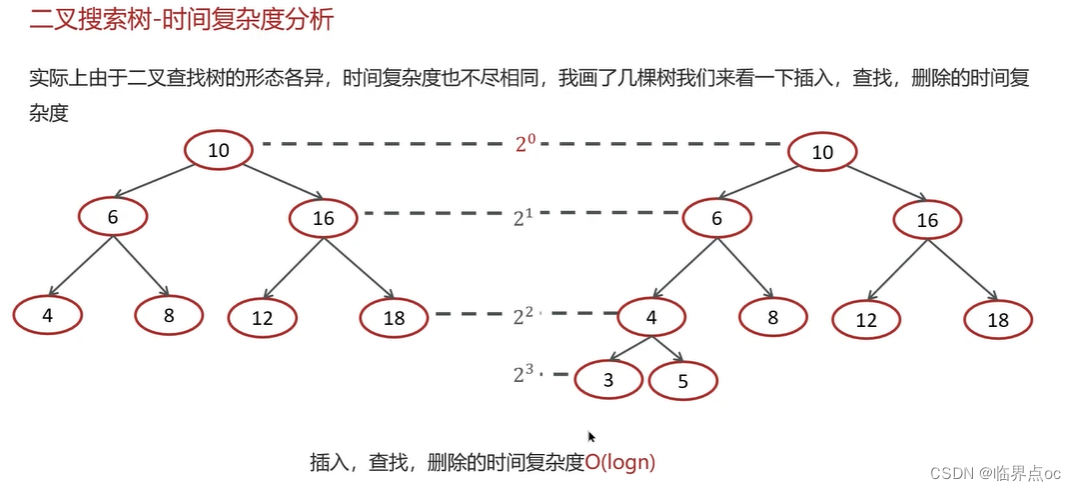


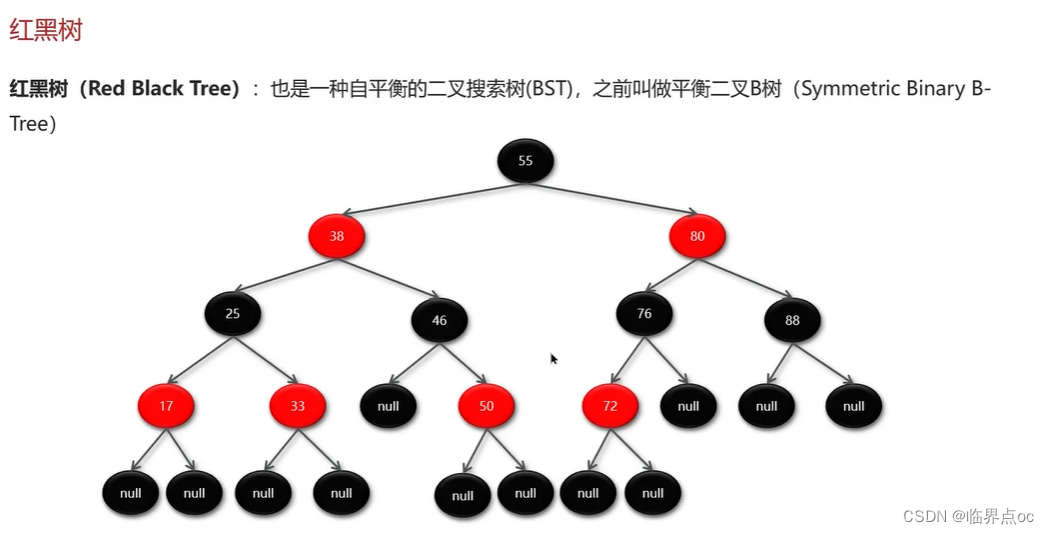
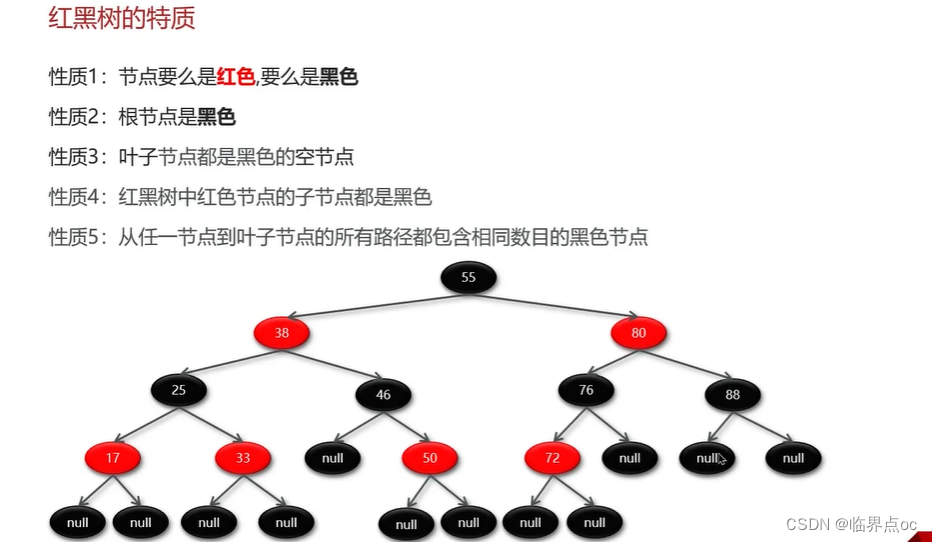

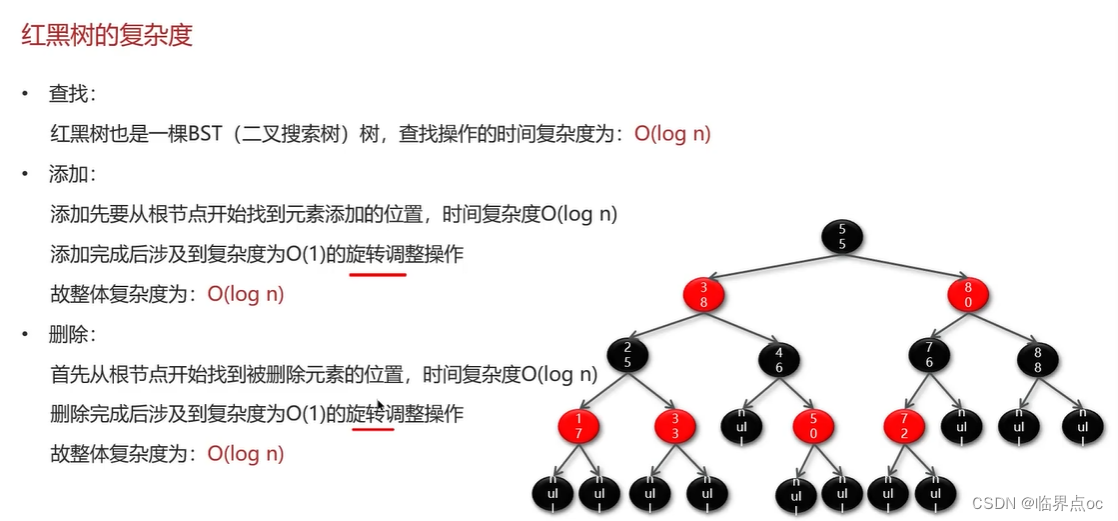
(10)散列表



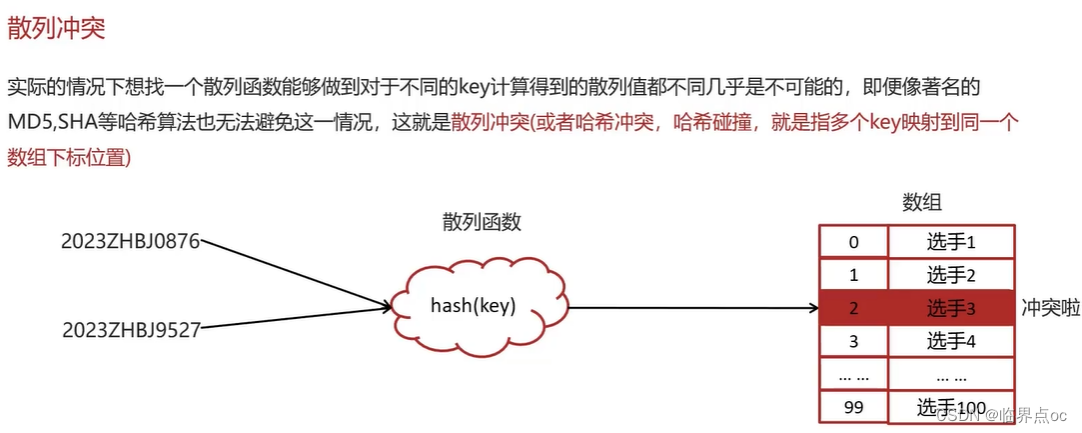
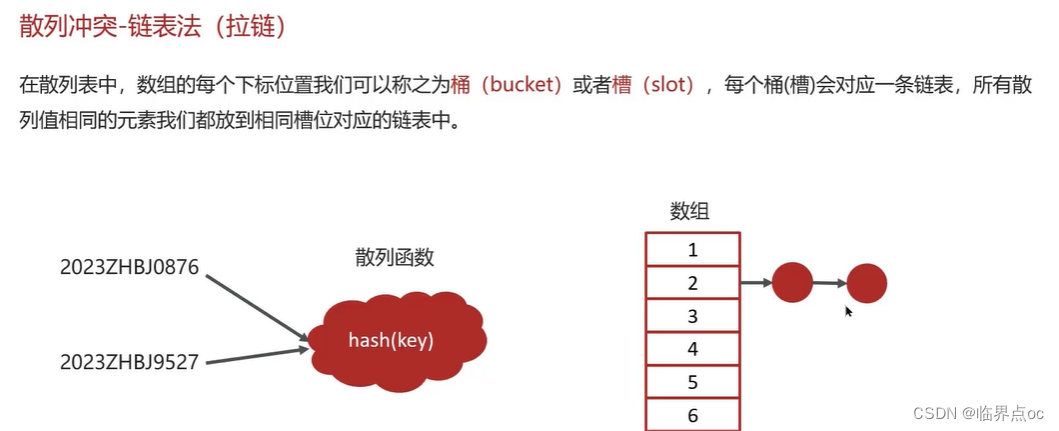

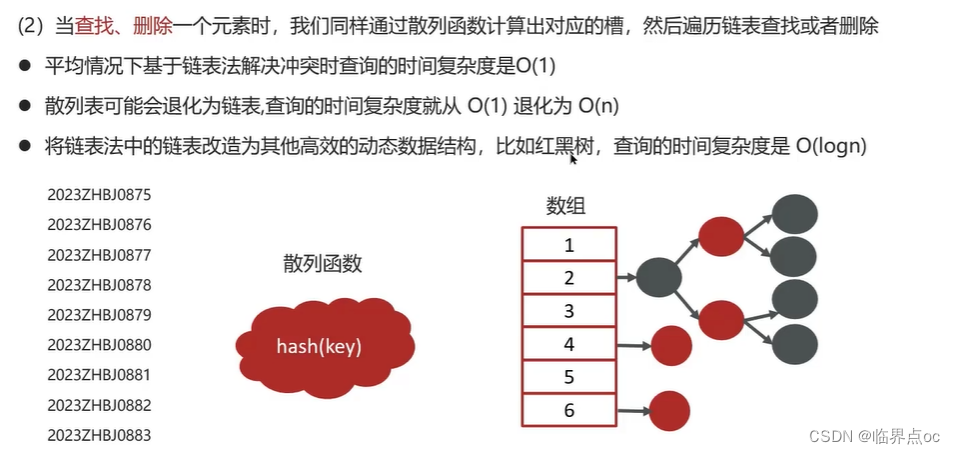
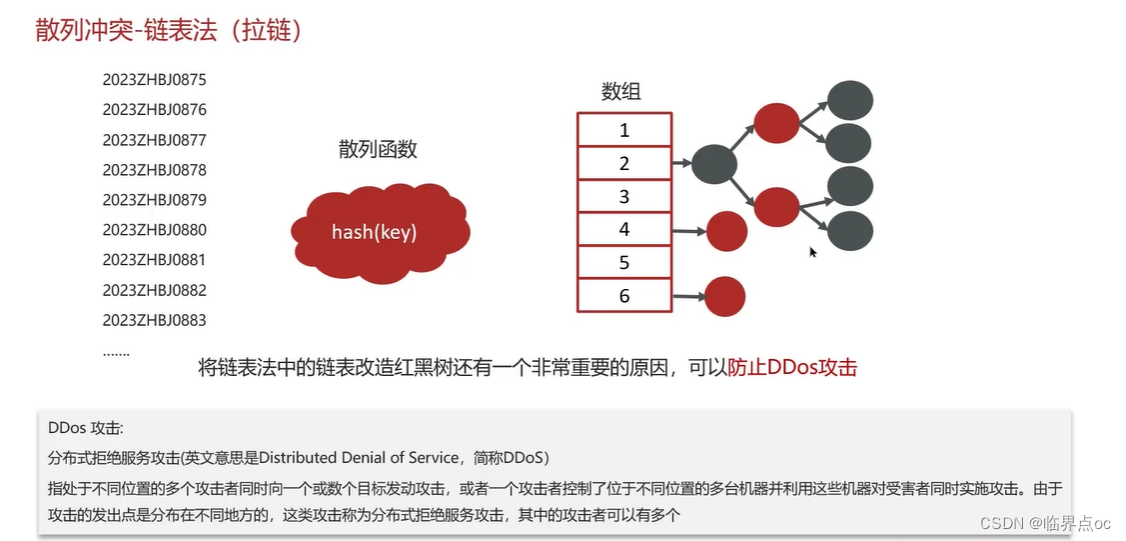
(11)HashMap的實現原理
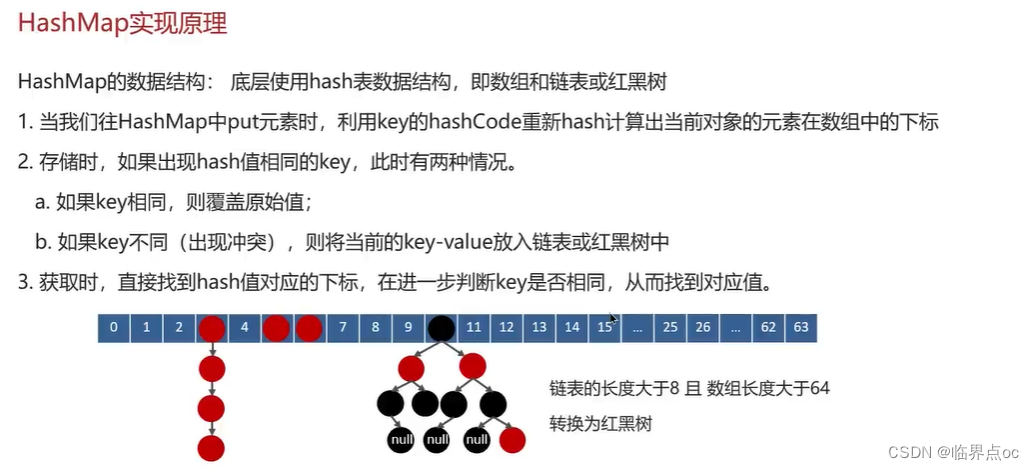

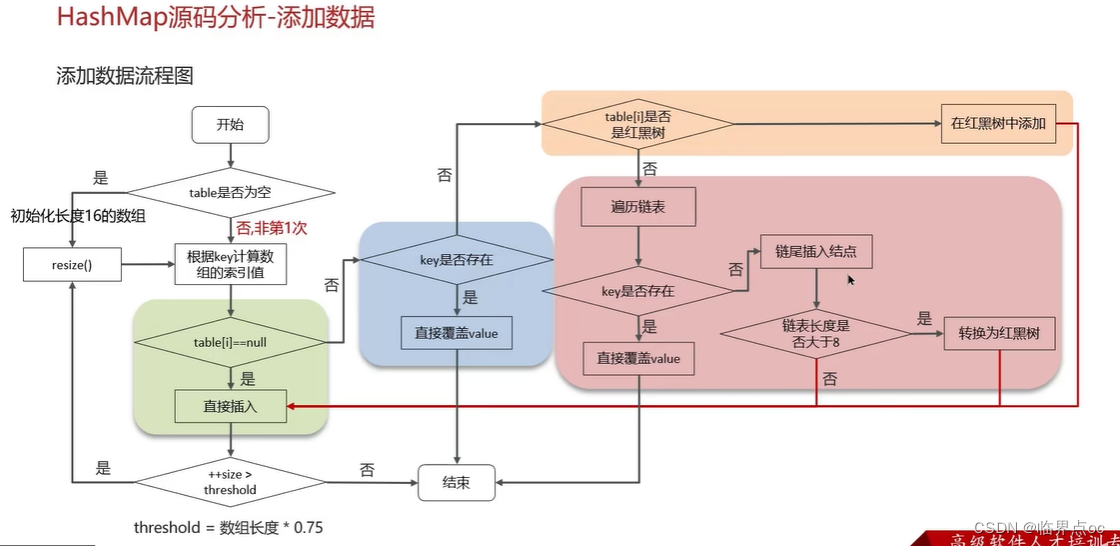
(12)HashMap的put方法的具體流程



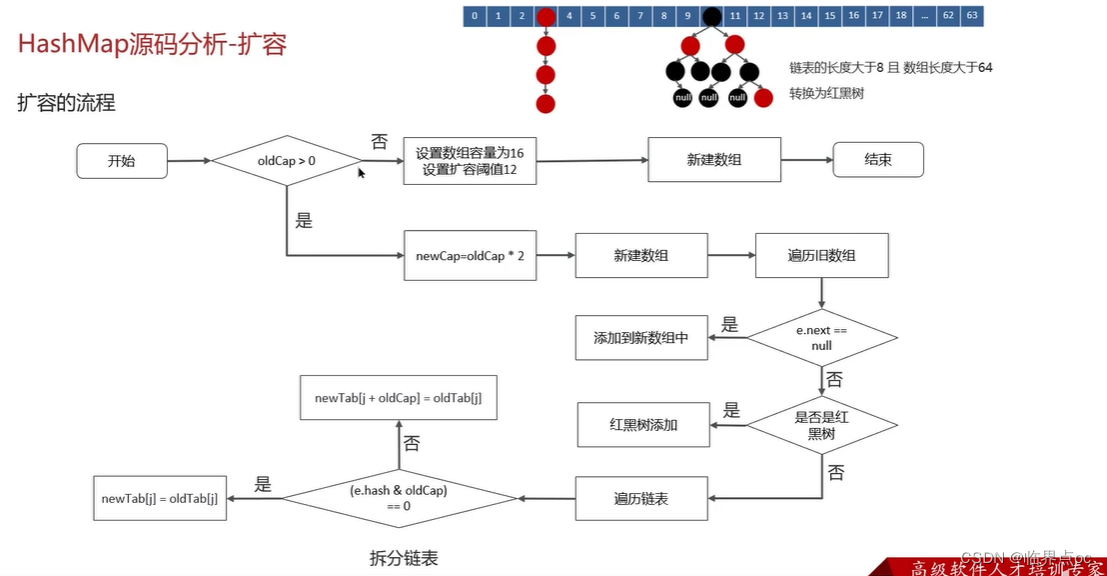
(13)講一講HashMap的擴容機制
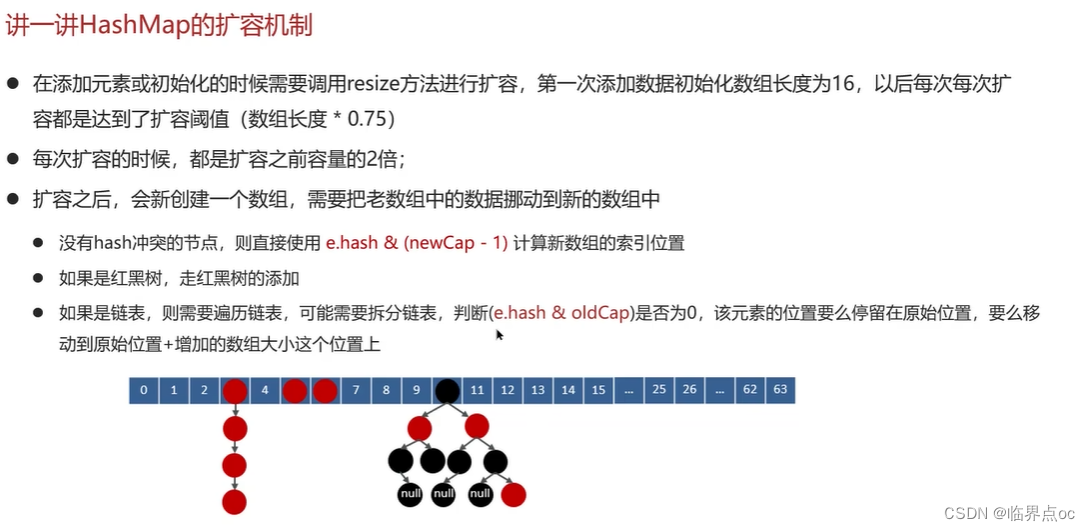
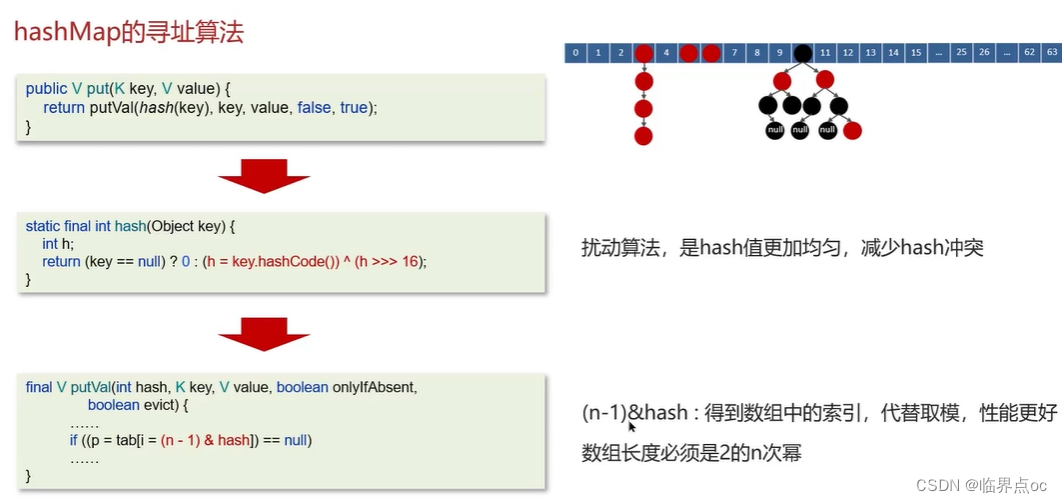
(14)HashMap的尋址算法


(15)HashMap在1.7情況下的多線程死循環問題


九、多線程

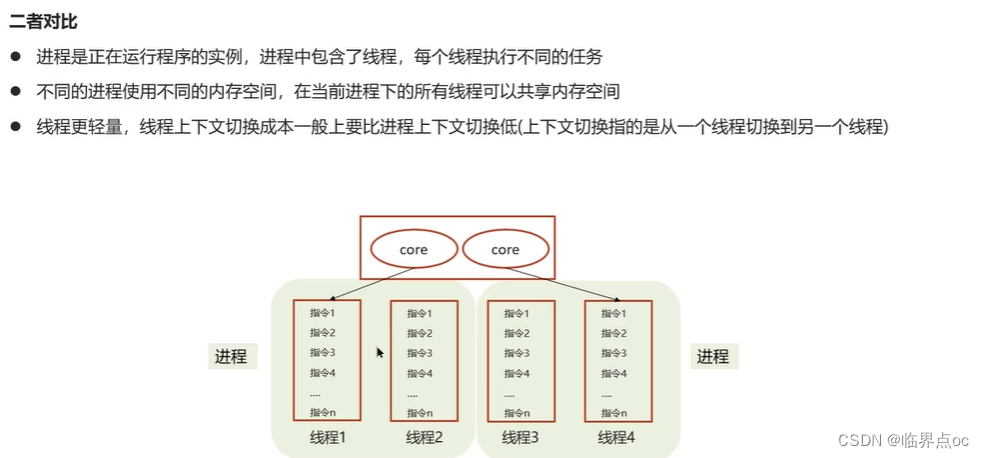
(1)線程和進程的區別?

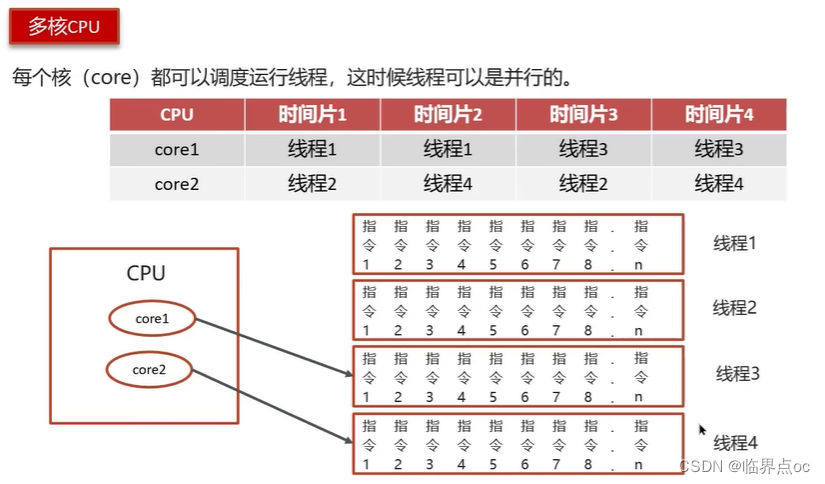
(2)并行和并發有什么區別?



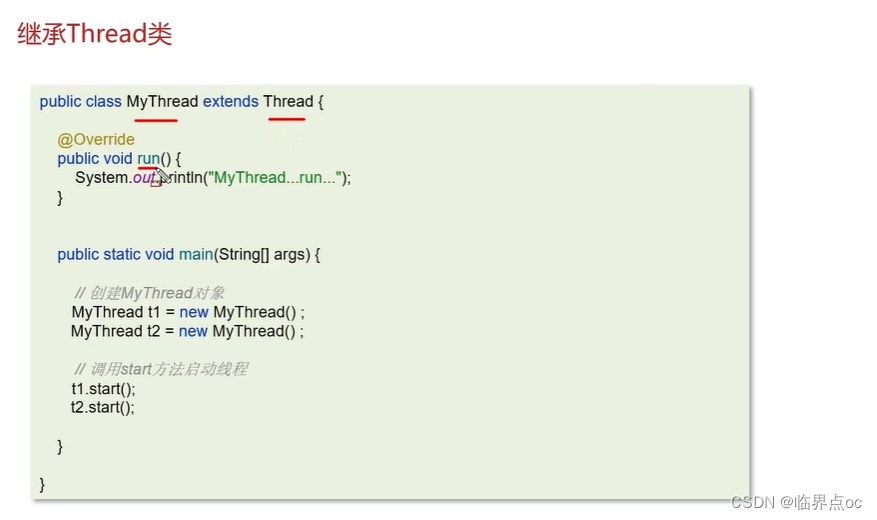
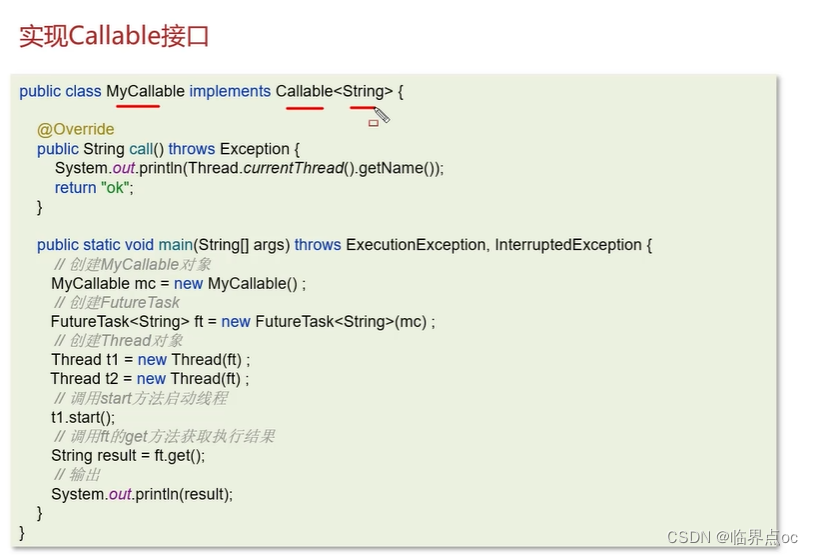
(3)創建線程的方式有哪些?





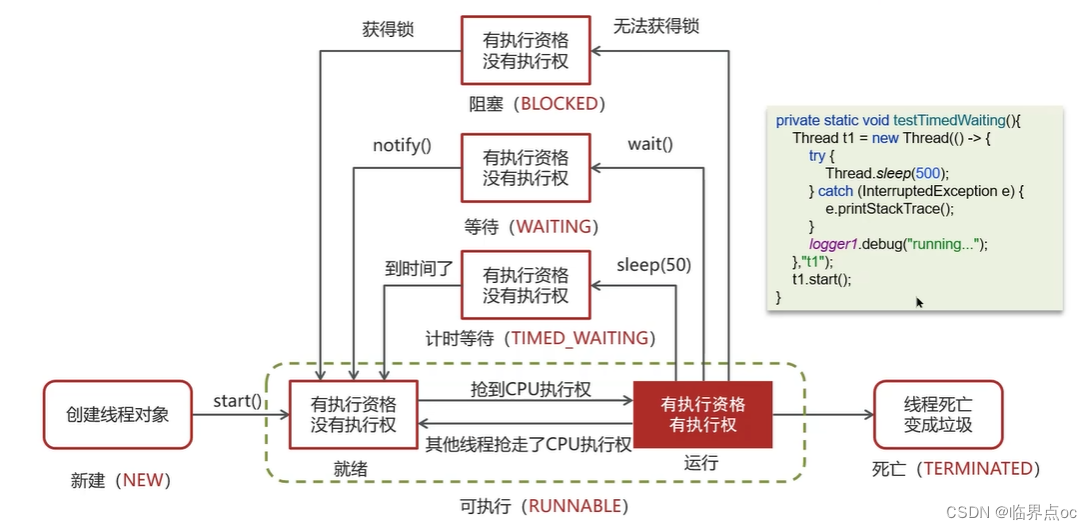
(4)線程包括哪些狀態,狀態之間是如何變化的


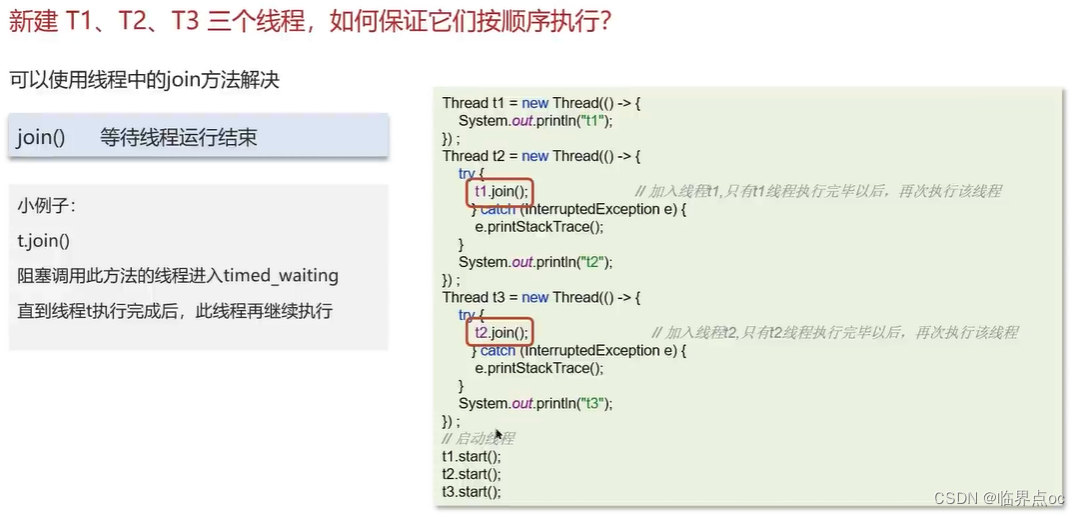
(5)新建T1、T2、T3三個線程,如何保證它們按順序進行?
(6)notify()和notifyAll()有什么區別?

(7)在Java中wait和sleep方法的不同?

(8)如何停止一個正在運行的線程?

(9)synchronized關鍵字的底層原理


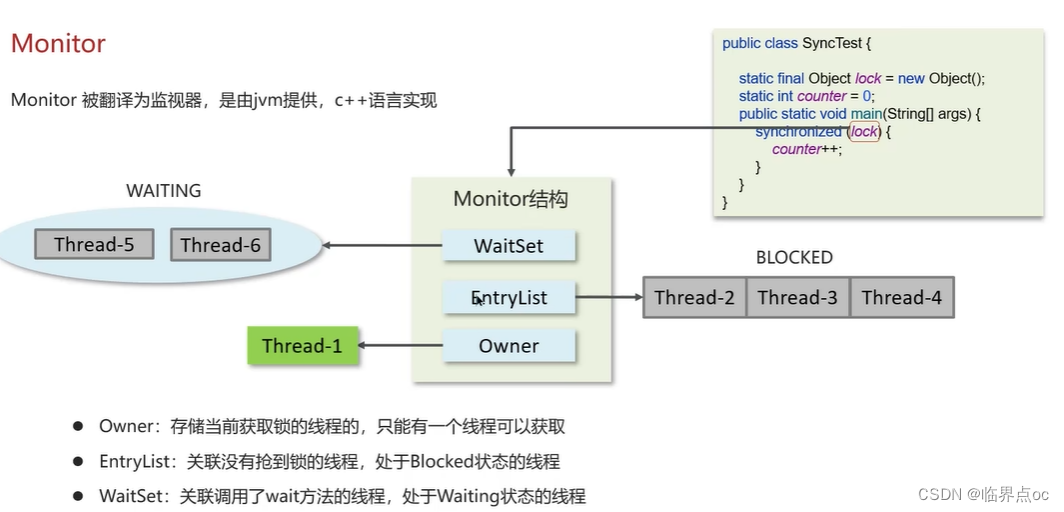


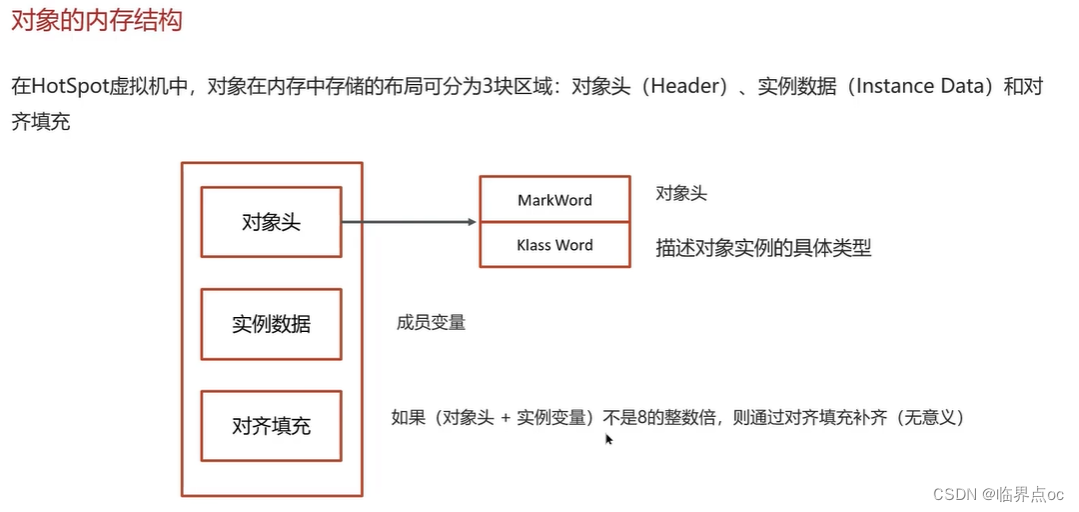
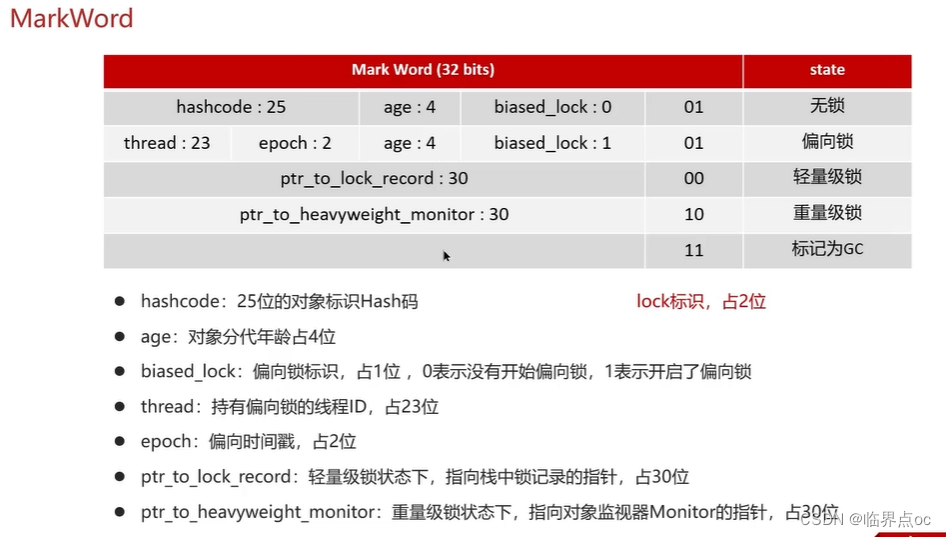
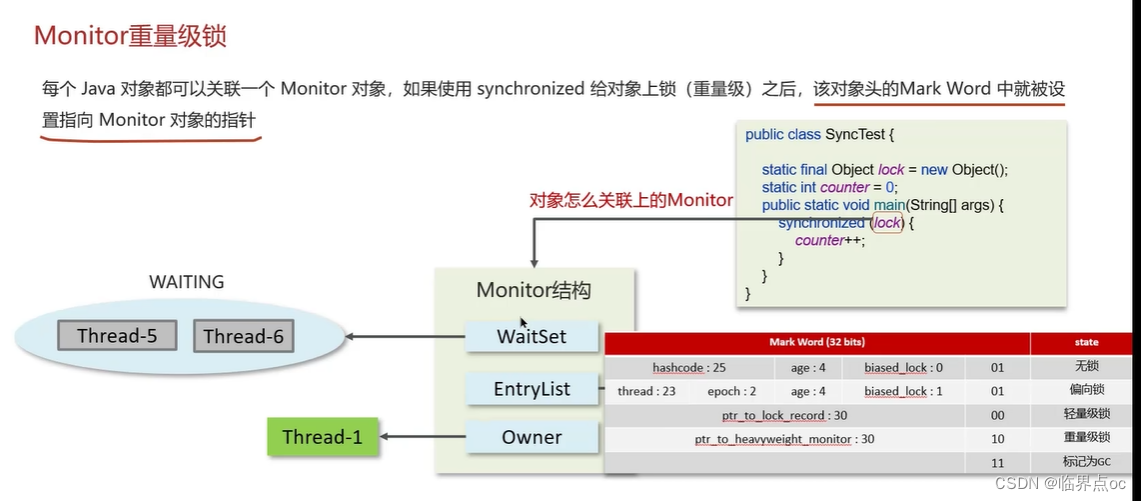

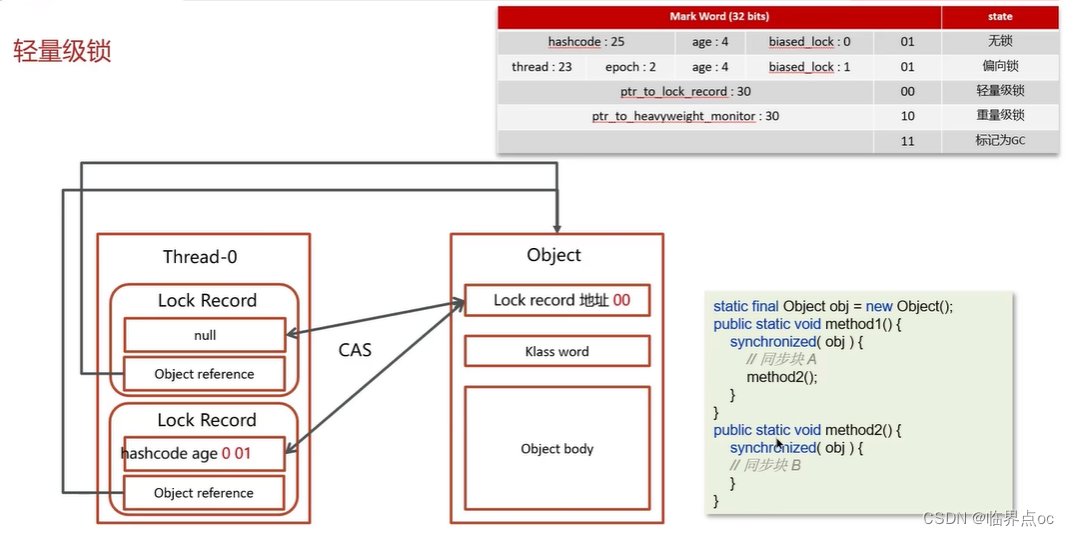




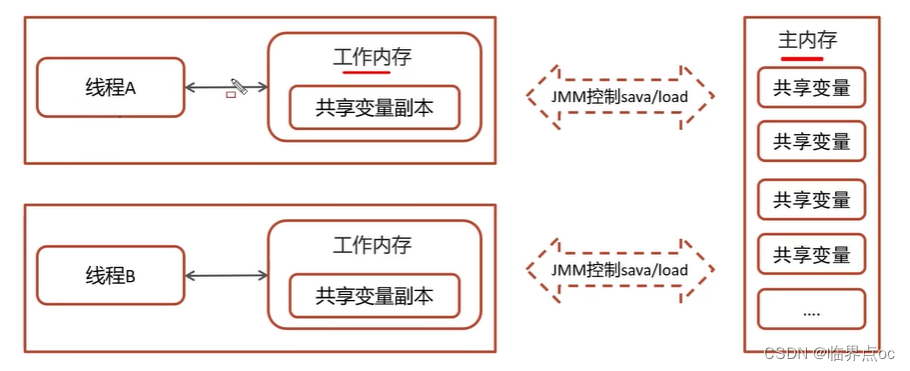
(10)你談談JMM(Java內存模型)
JMM(Java Memory Model)Java內存模型,定義了共享內存中多線程程序讀寫操作的行為規范,通過這些規則來規范對內存的讀寫操作從而保證指令的正確性。

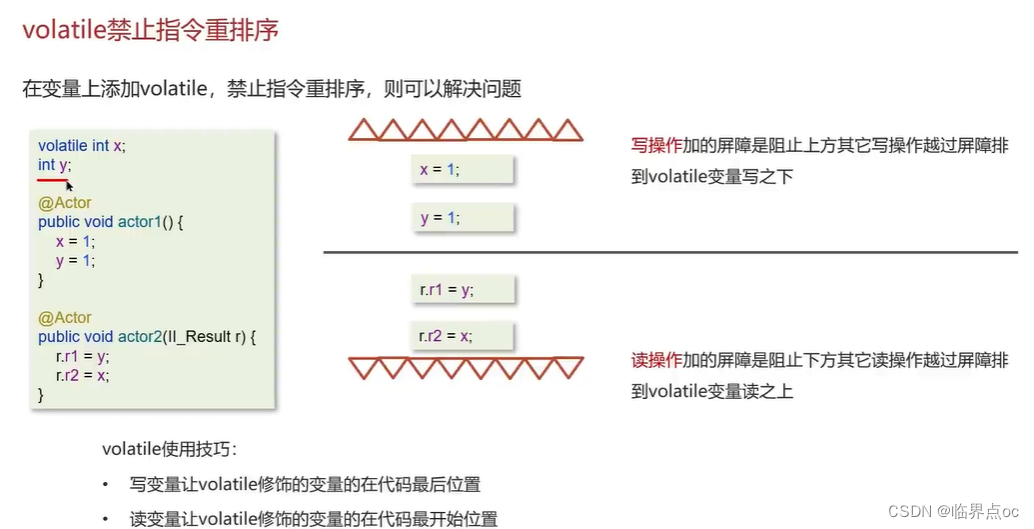
(11)CAS你知道嗎?


(12)談談你對volatitle的理解





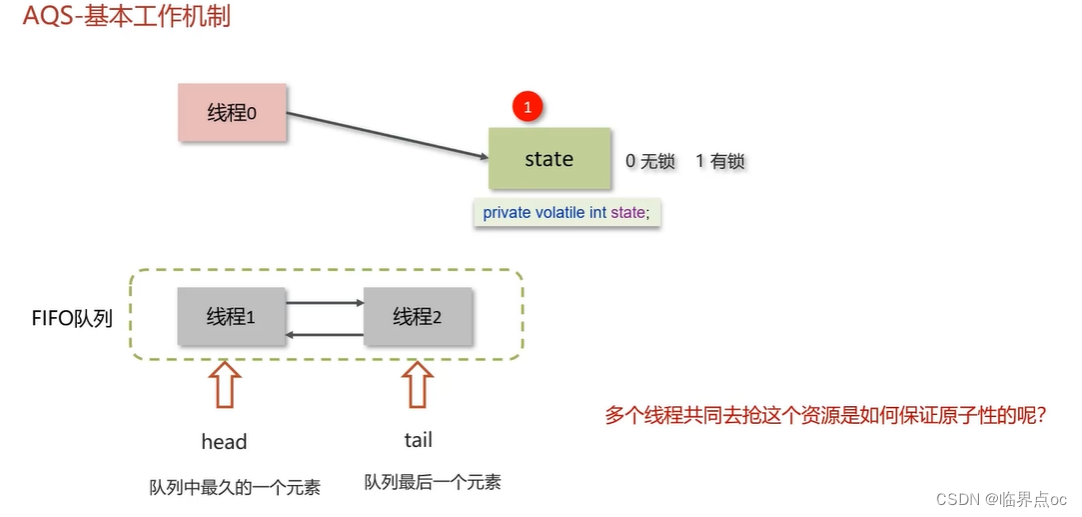
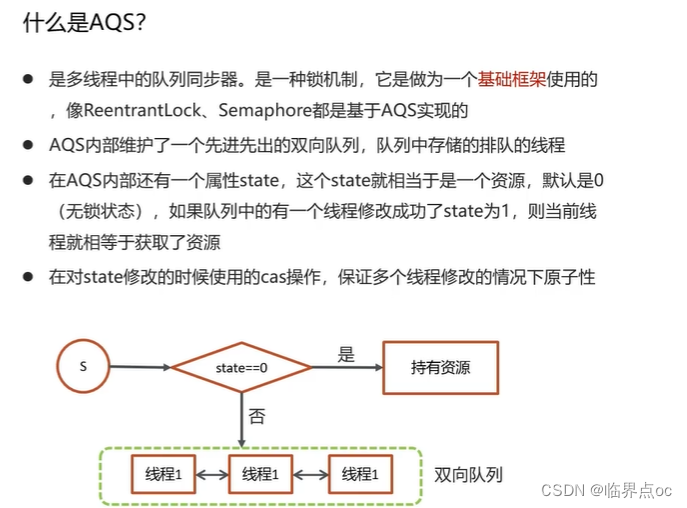
(13)什么是AQS?
全稱是AbstractQueuedSynchronizer,即抽象隊列同步器。它是構建鎖或者其他同步組件的基礎框架。


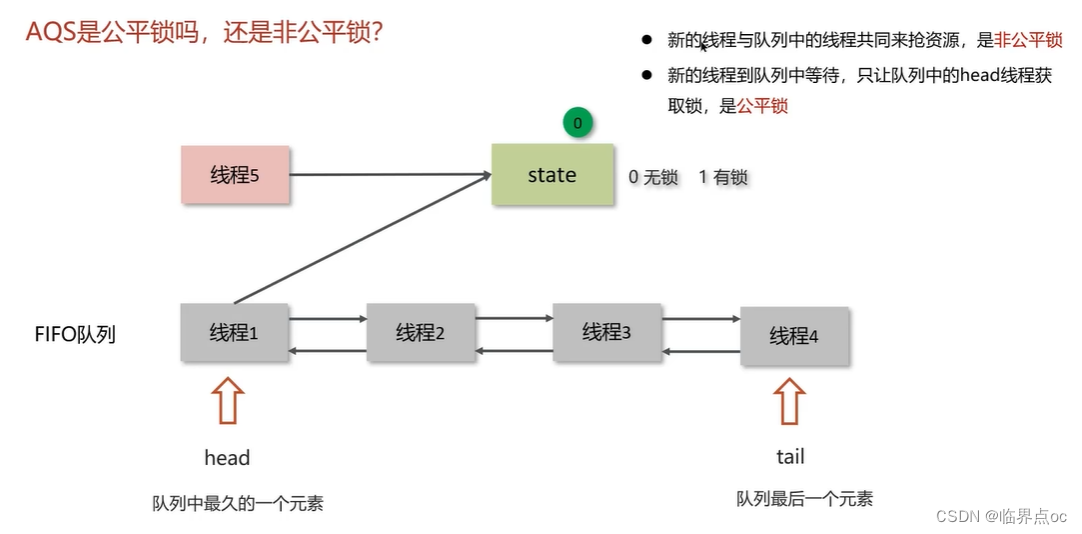
(14)ReentrantLock的實現原理

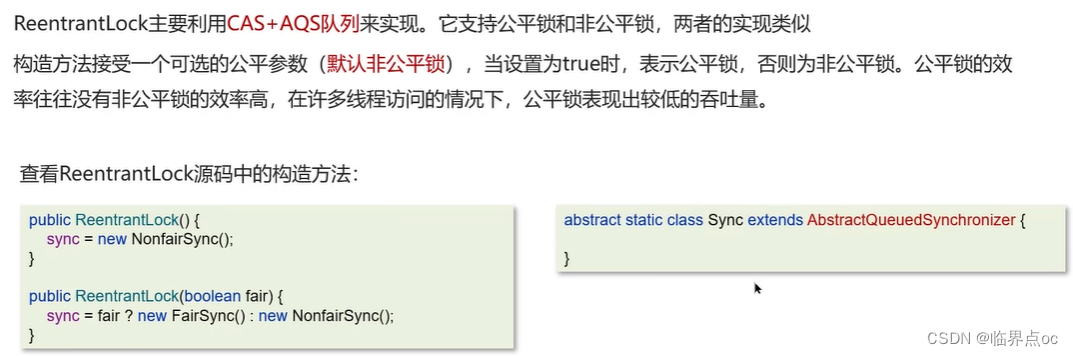
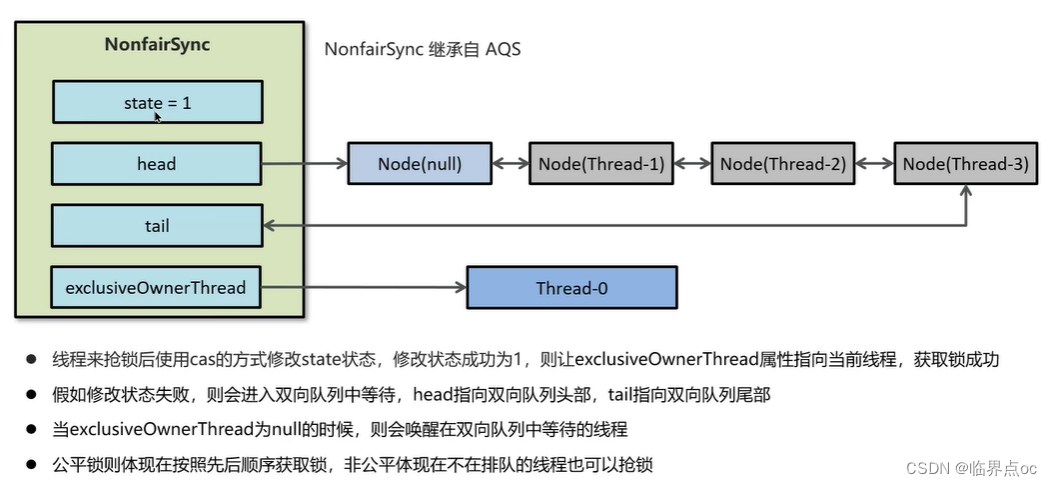
(15)synchronized和Lock有什么區別?

(16)死鎖產生的條件是什么?
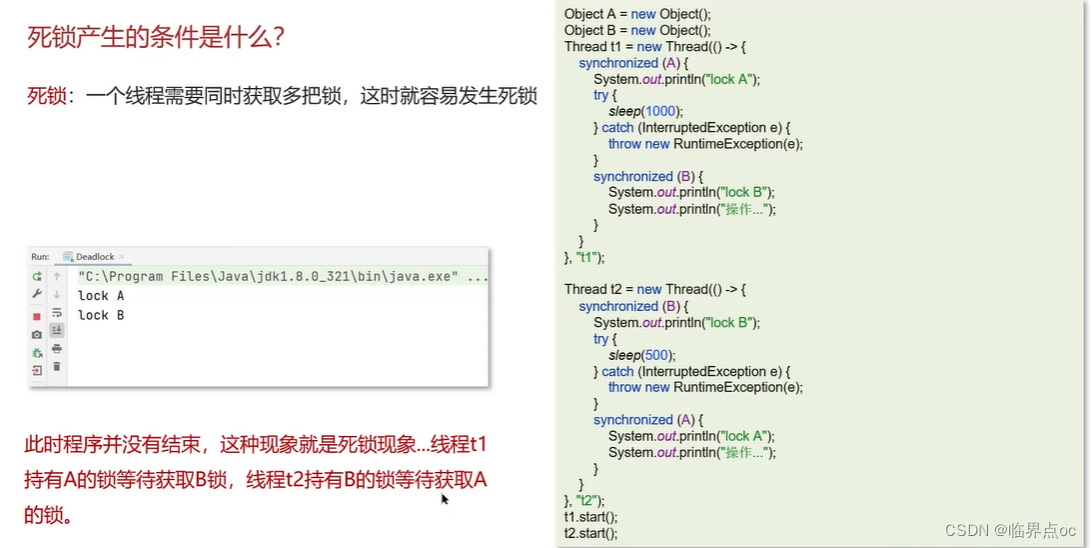


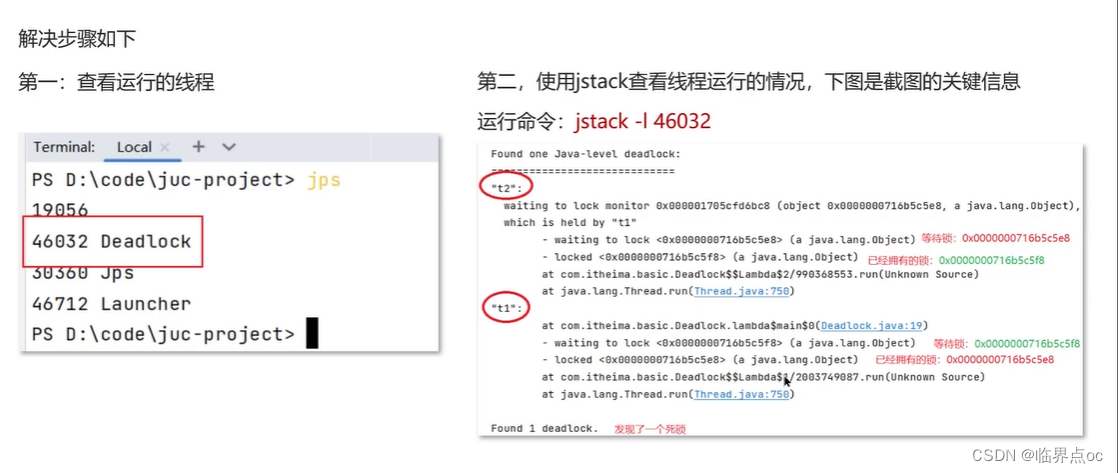


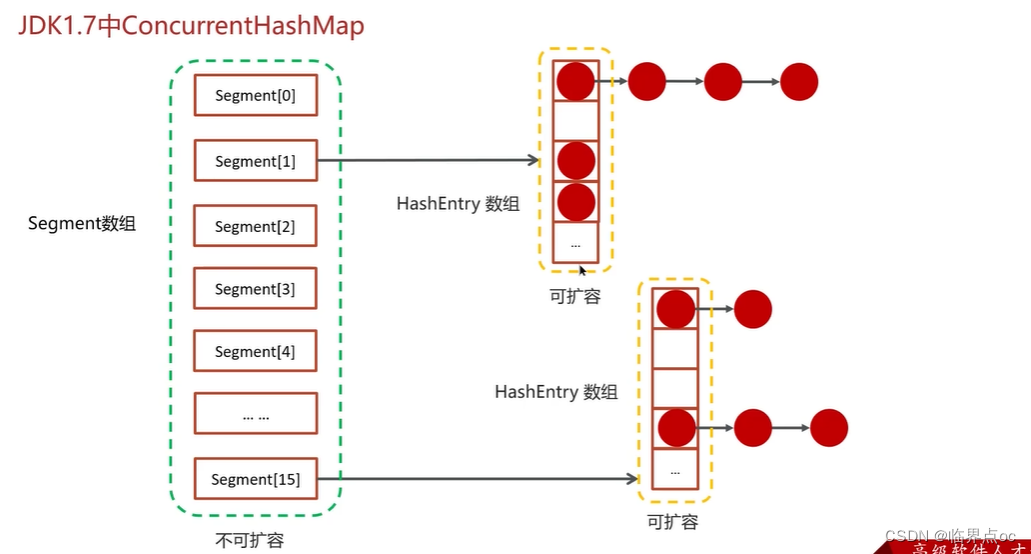
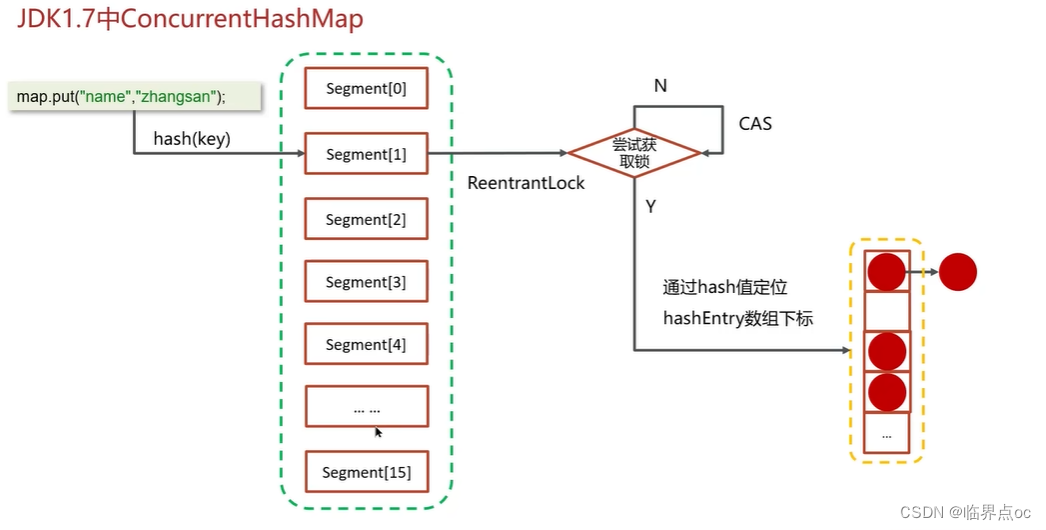
(17)談談你對ConcurrentHashMap的理解

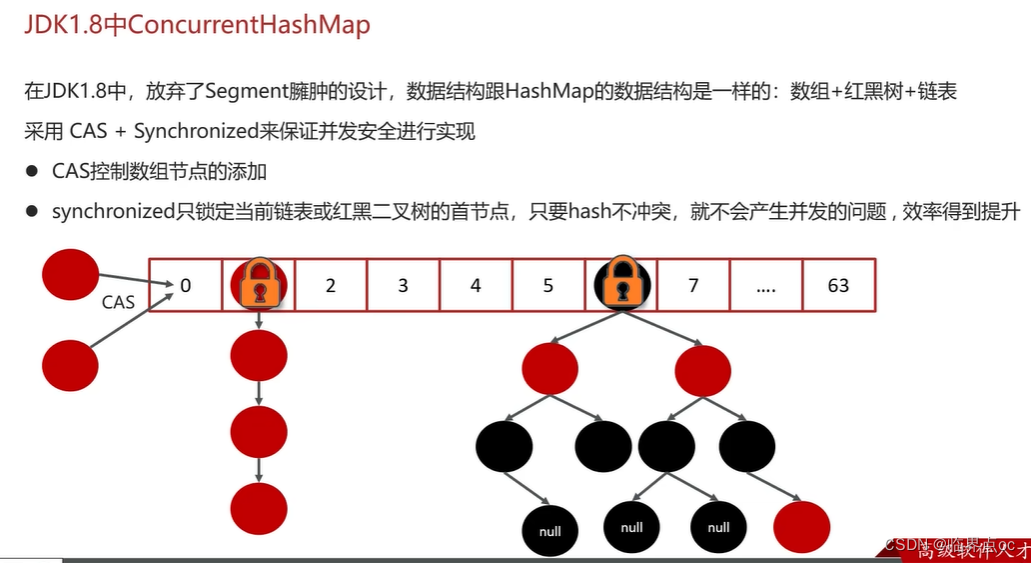

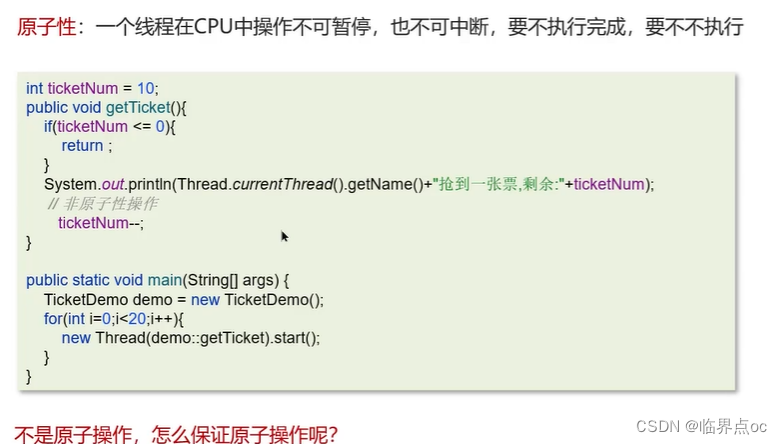
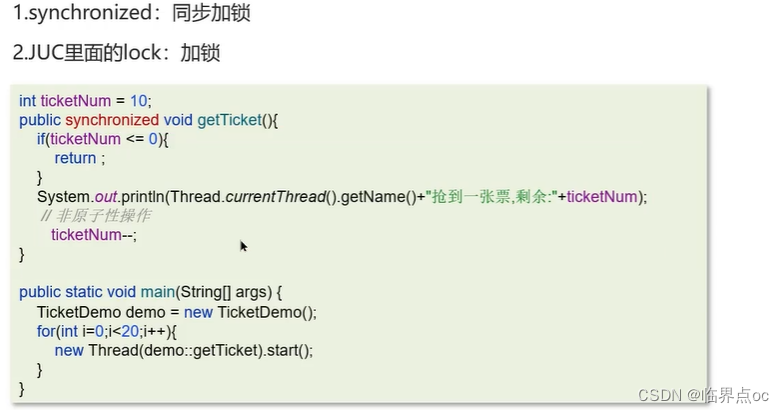
(18)導致并發程序出現問題的根本原因是什么?(Java程序中怎么保證多線程的執行安全)
Java并發編程的三大特性:原子性、可見性、有序性


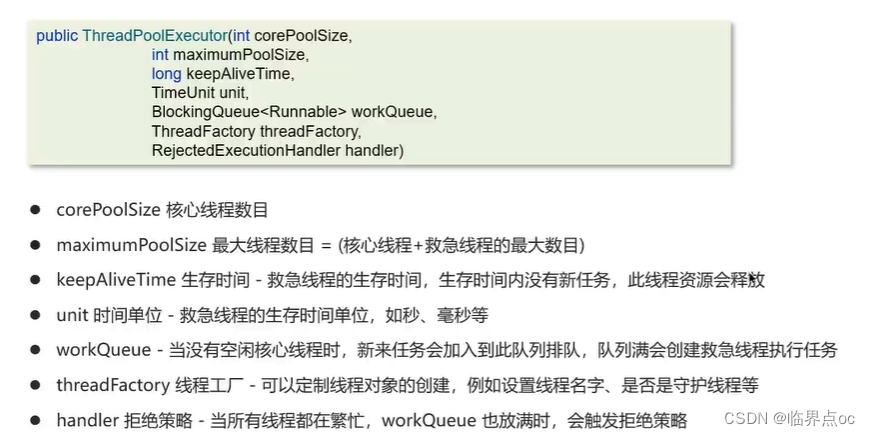
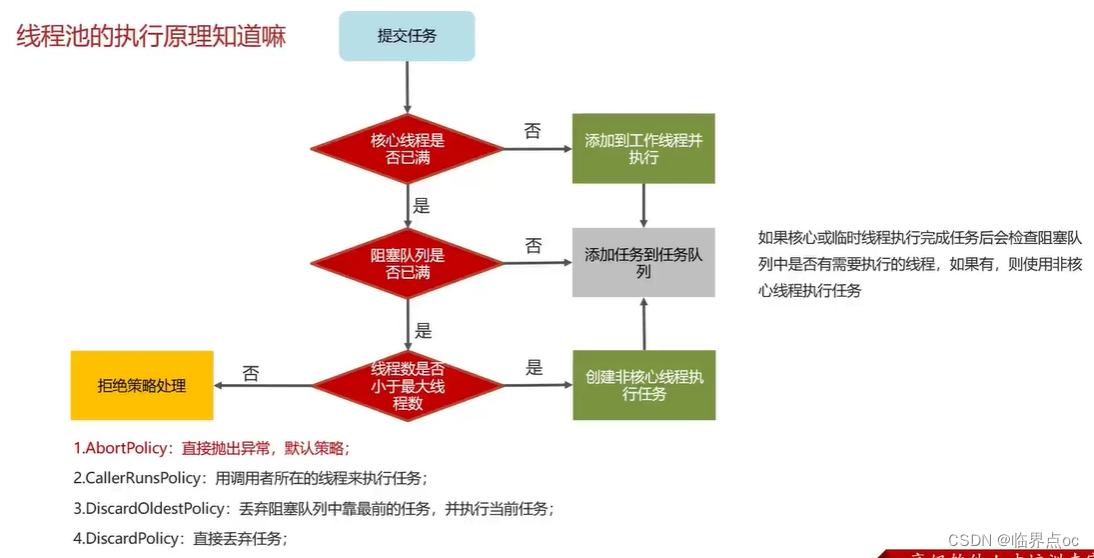
(19)說一下線程池的核心參數(線程池的執行原理知道嗎)
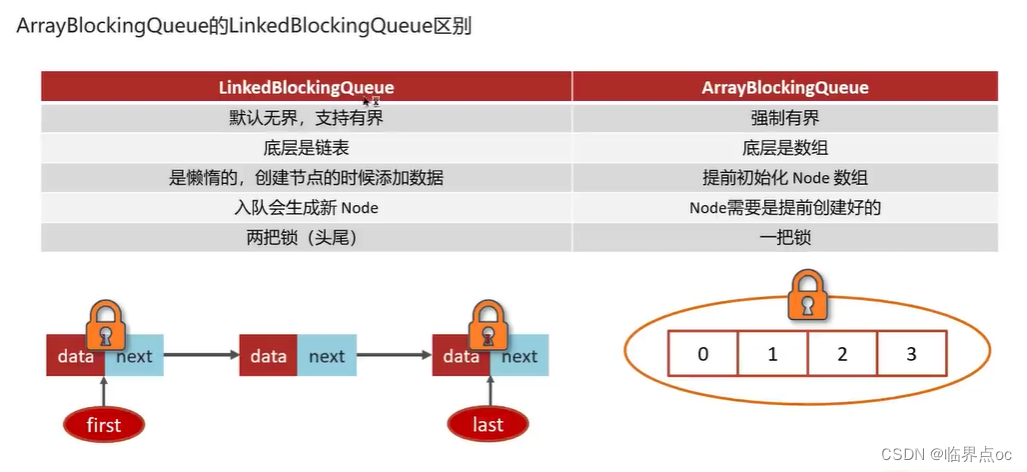
(20)線程池中有哪些常見的阻塞隊列

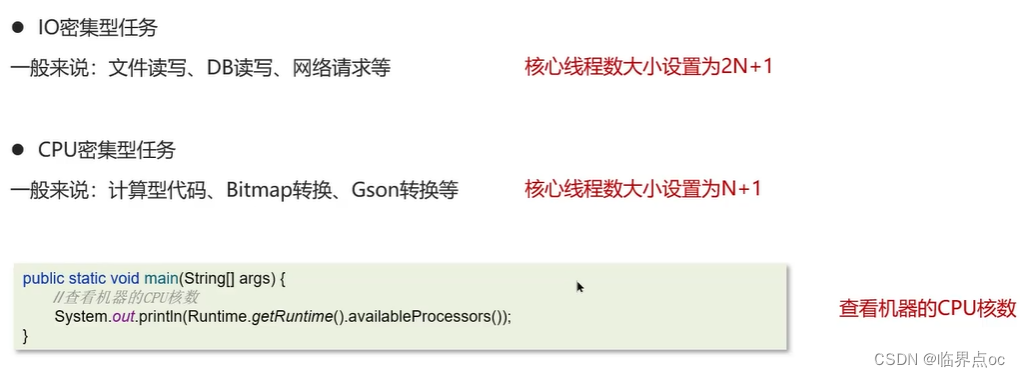
(21)如何確定核心線程數

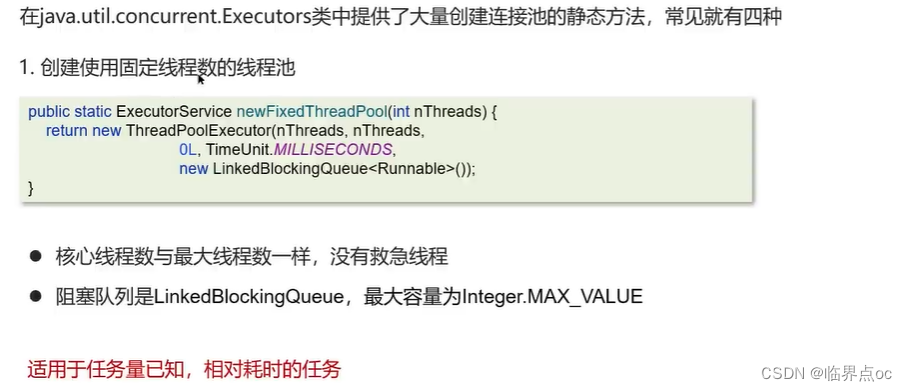
(22)線程池的種類有哪些?

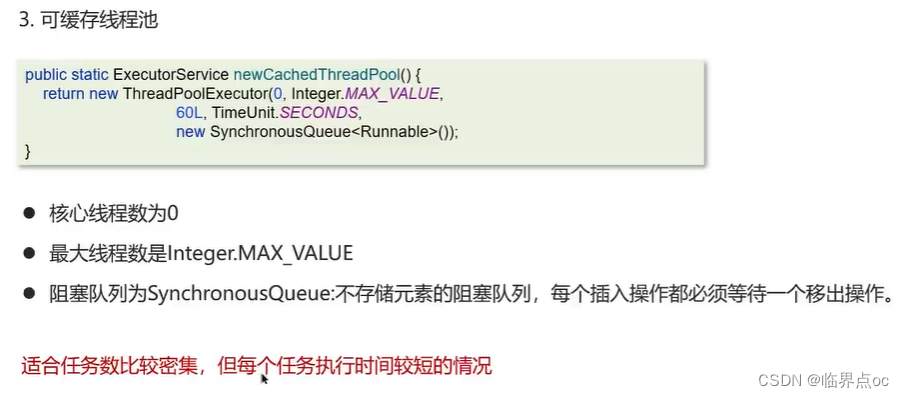

(23)為什么不建議用Executors創建線程池
嵩山版Java開發手冊-阿里云開發者社區

(24)線程池使用場景(CountDownLatch、Future)
CountDownLatch


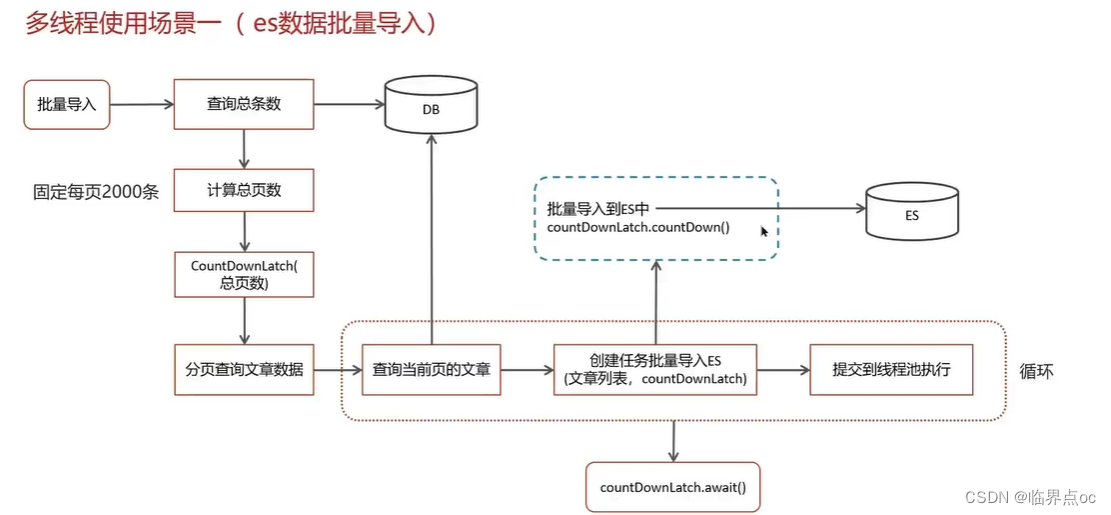
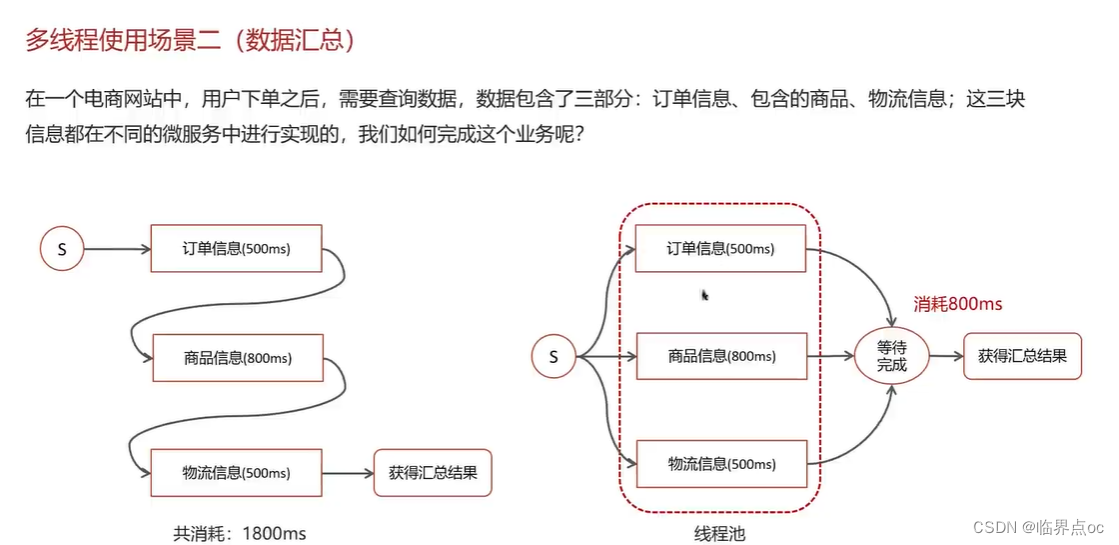
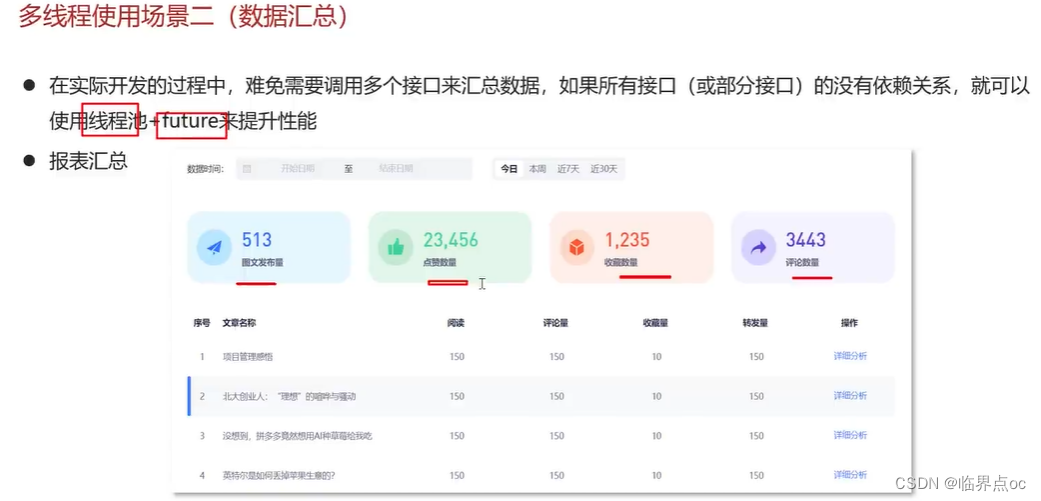
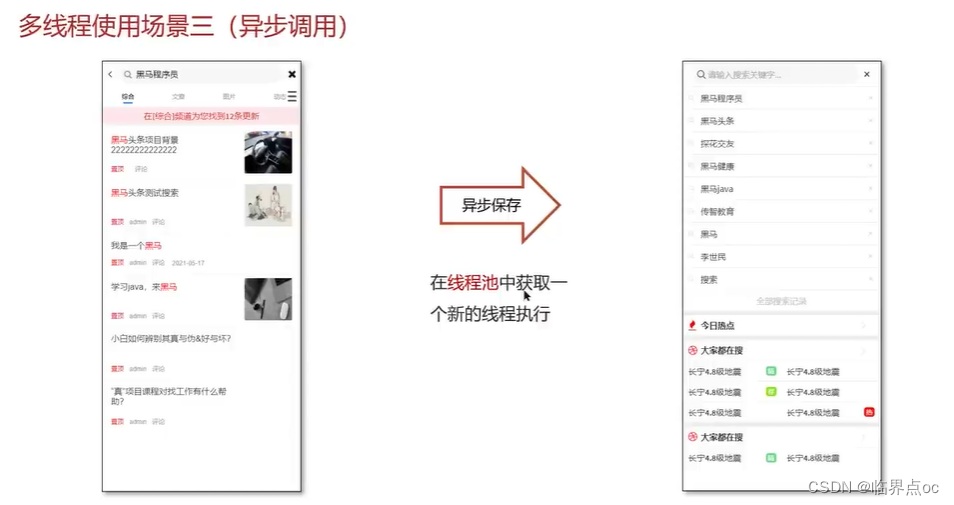

(25)如何控制某個方法允許并發訪問線程的數量


(26)談談你對ThreadLocal的理解







十、JVM
(1)JVM是什么
Java Virtual Machine:Java程序的運行環境(java二進制字節碼的運行環境)

(2)JVM由哪些部分組成,運行流程是什么?
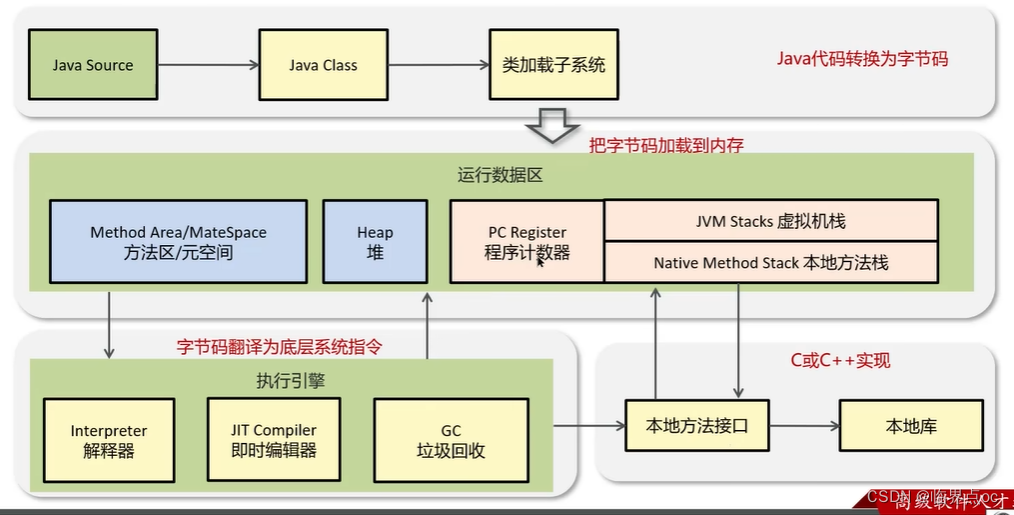
(3)什么是程序計數器?
程序計數器:線程私有的,內部保存的字節碼的行號。用于記錄正在執行的字節碼指令的地址。
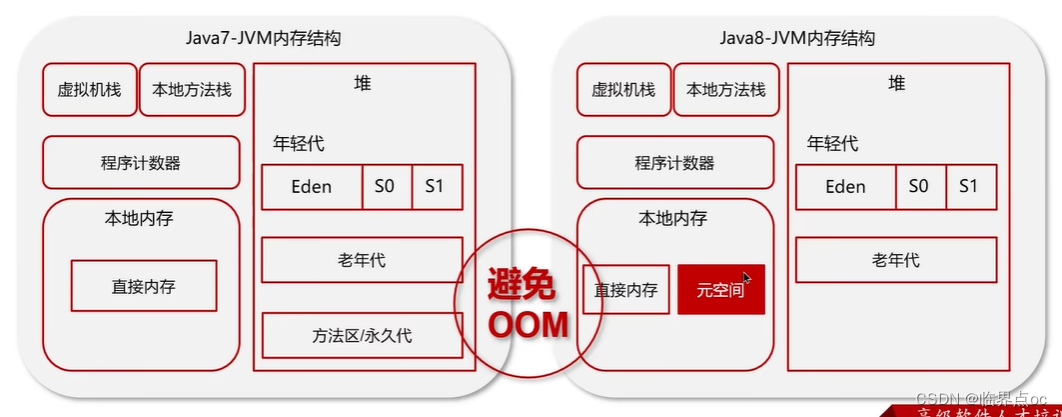
(4)能詳細介紹一下Java堆嗎?
線程共享的區域:主要用來保存對象實例、數組等,當堆中沒有內存空間可分配給實例,也無法再擴展時,則拋出OutOfMemoryError異常。

(5)什么是虛擬機棧
Java Virtual machine Stacks(java 虛擬機棧)
每個線程運行時所需要的內存,稱為虛擬機棧,先進后出
每個棧由多個棧幀(frame)組成,對應著每次方法調用時所占用的內存
每個線程只能有一個活動棧幀,對應著當前正在執行的那個方法





(6)能不能解釋一下方法區?
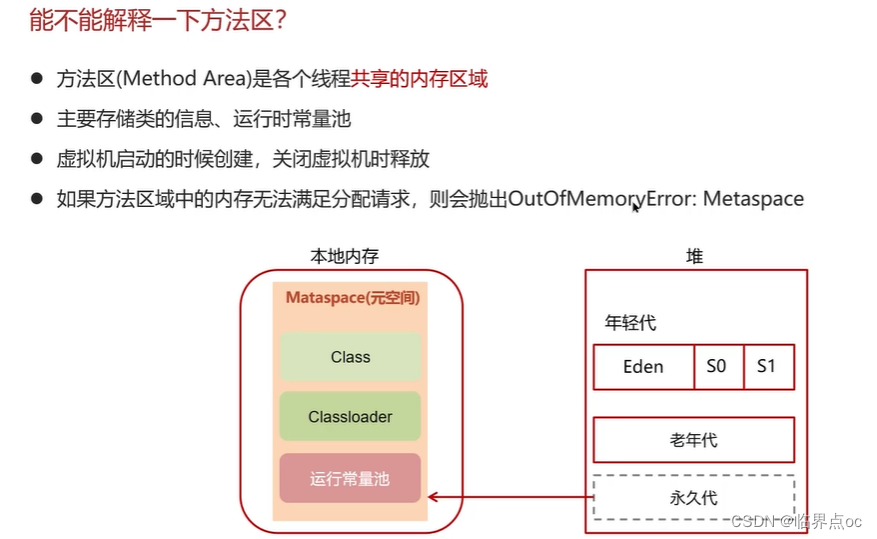


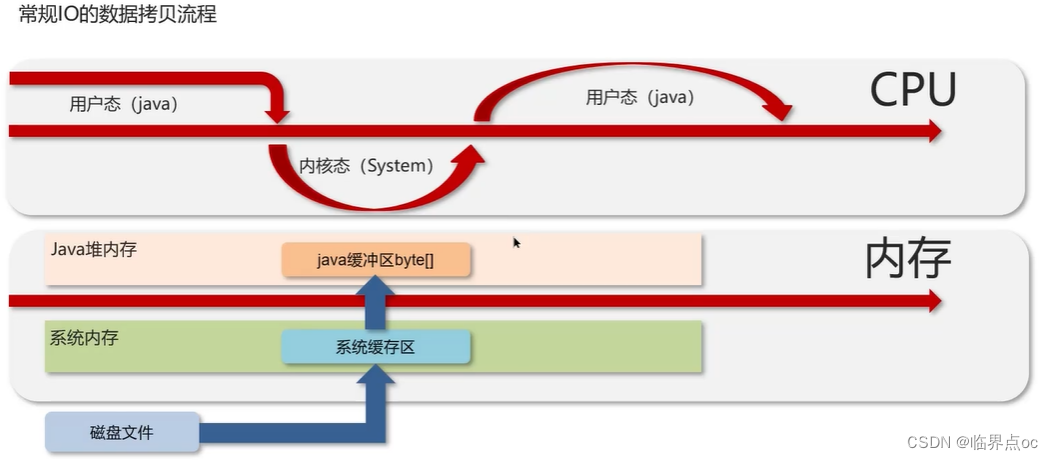
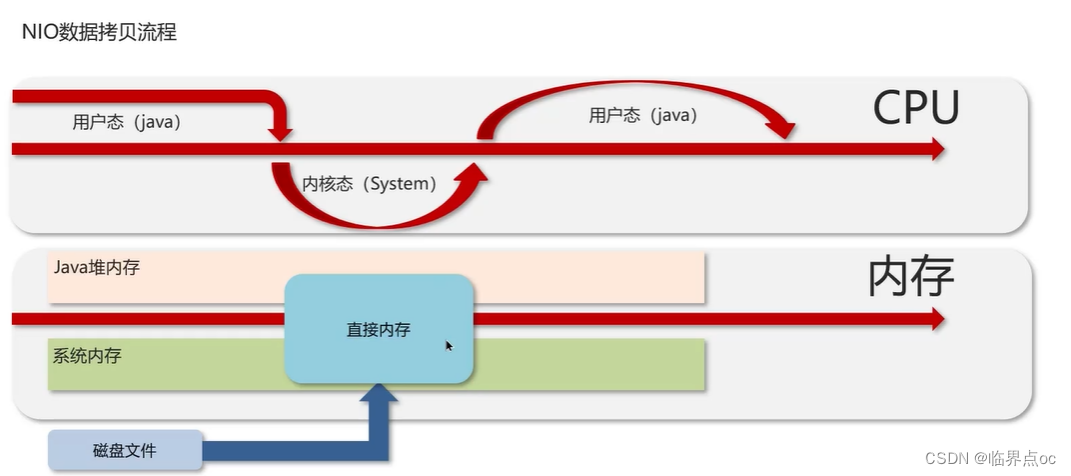
(7)你聽過直接內存嗎?
直接內存:并不屬于JVM中的內存結構,不由JVM進行管理。是虛擬機的系統內存,常見于NIO操作時,用于數據緩存區,它分配回收成本較高,但讀寫性能高,不受JVM內存回收管理。
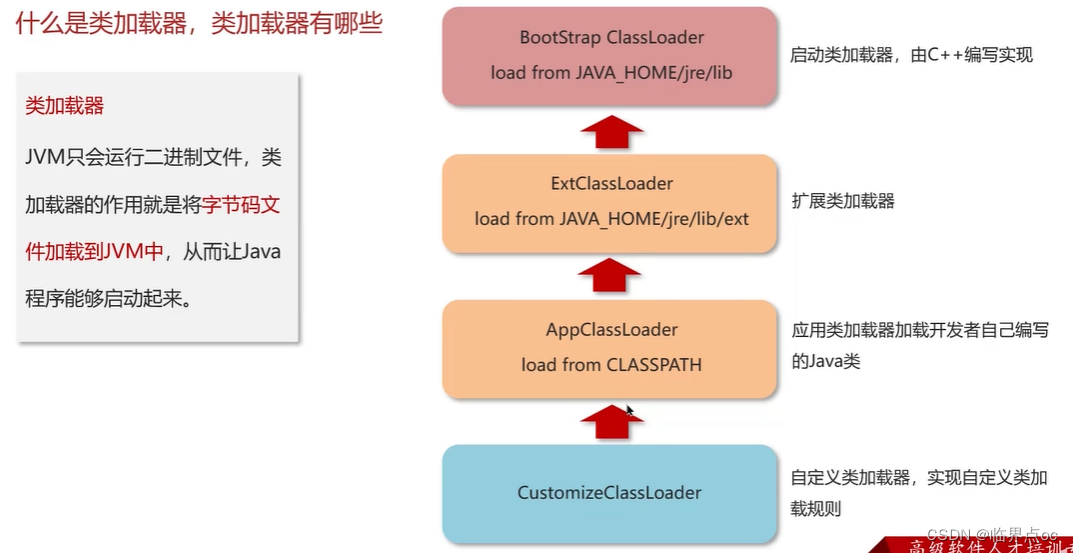
(8)什么是類加載器,類加載器有哪些?


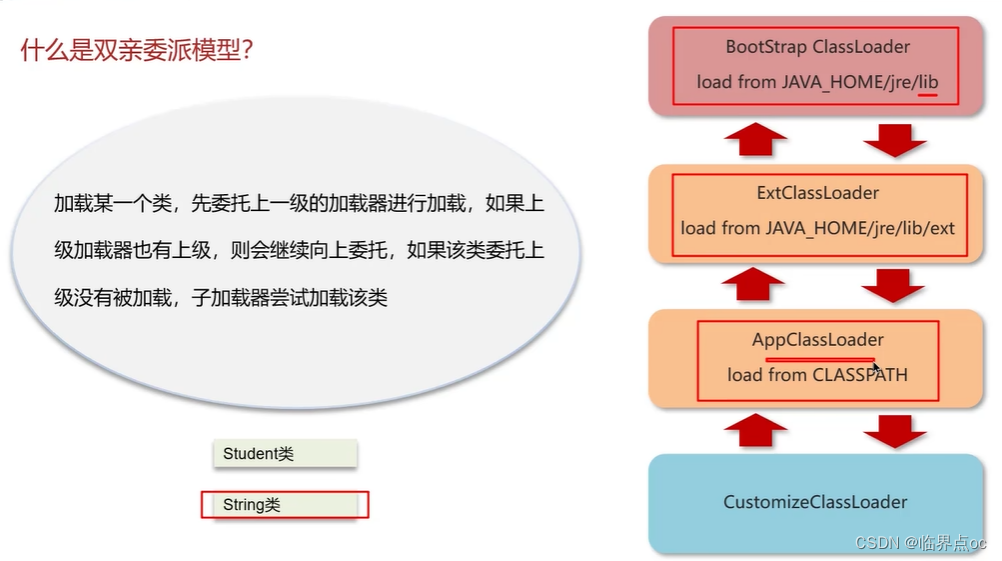
(7)什么是雙親委派模型?

(8)說一下類裝載的執行過程
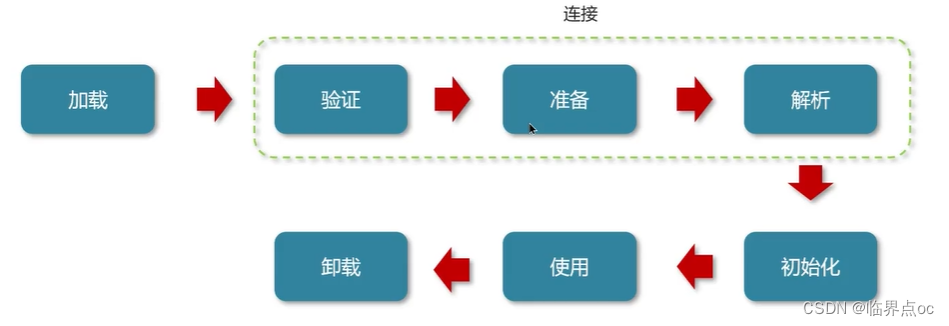
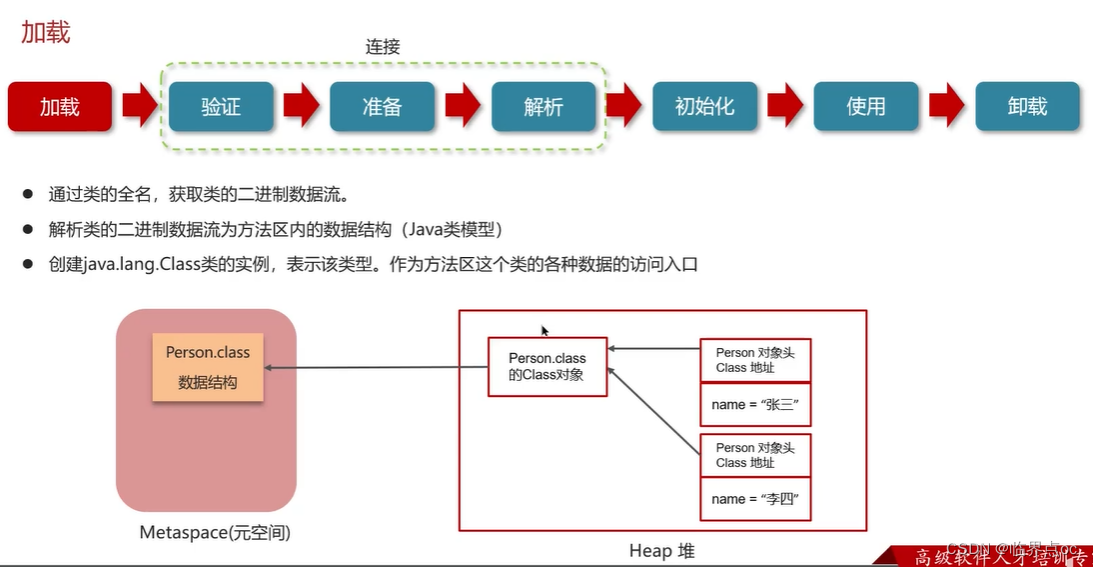
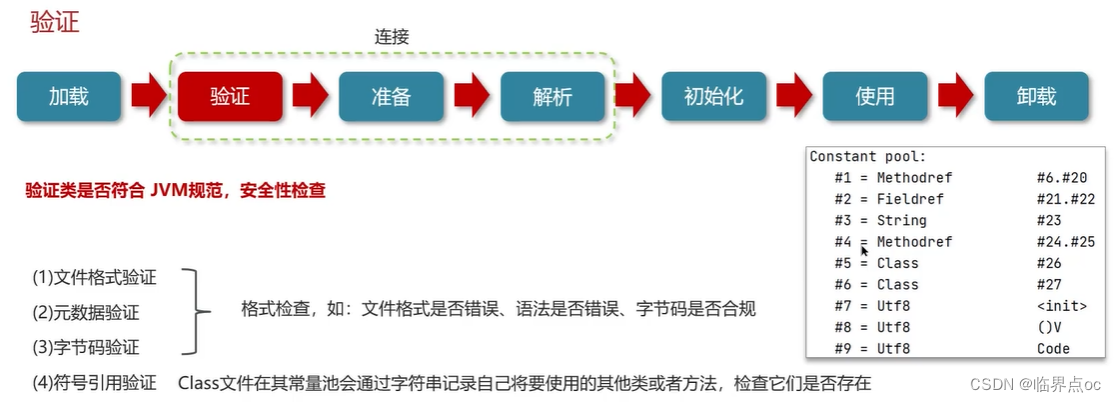
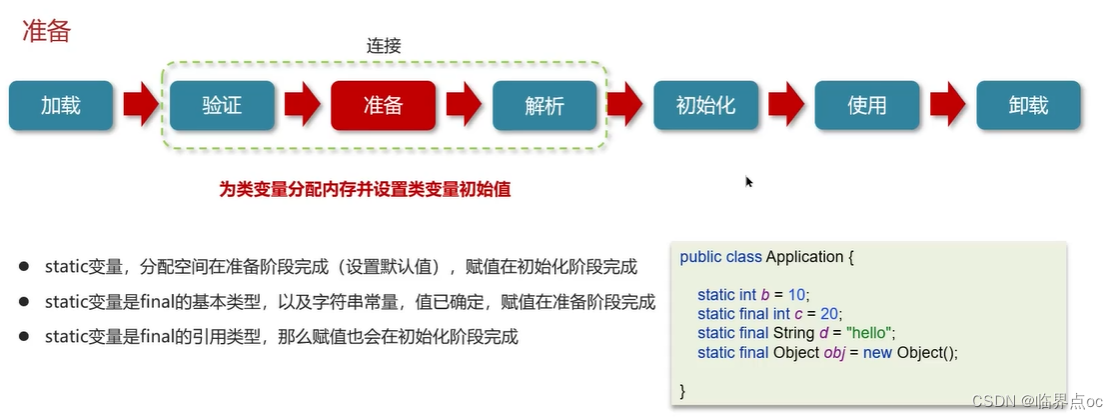
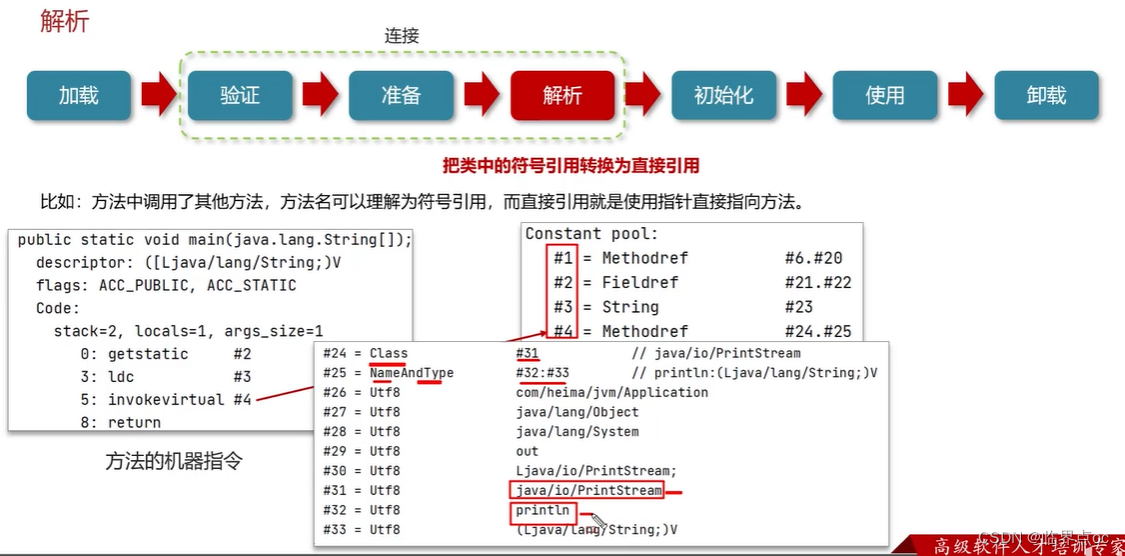
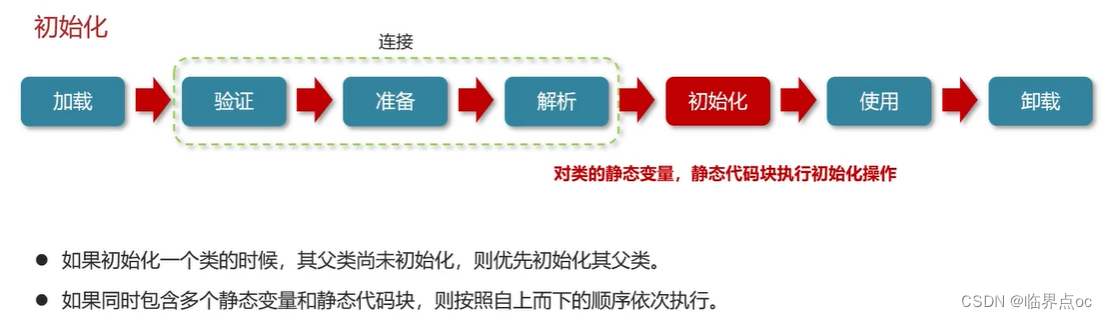
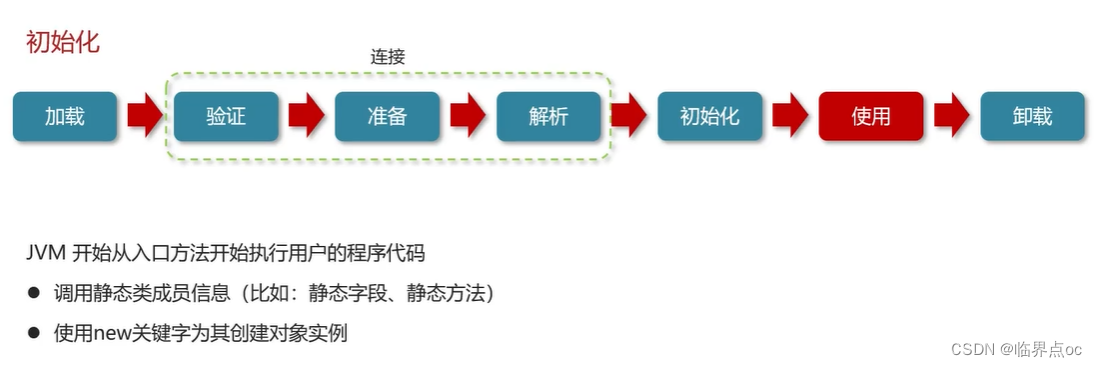
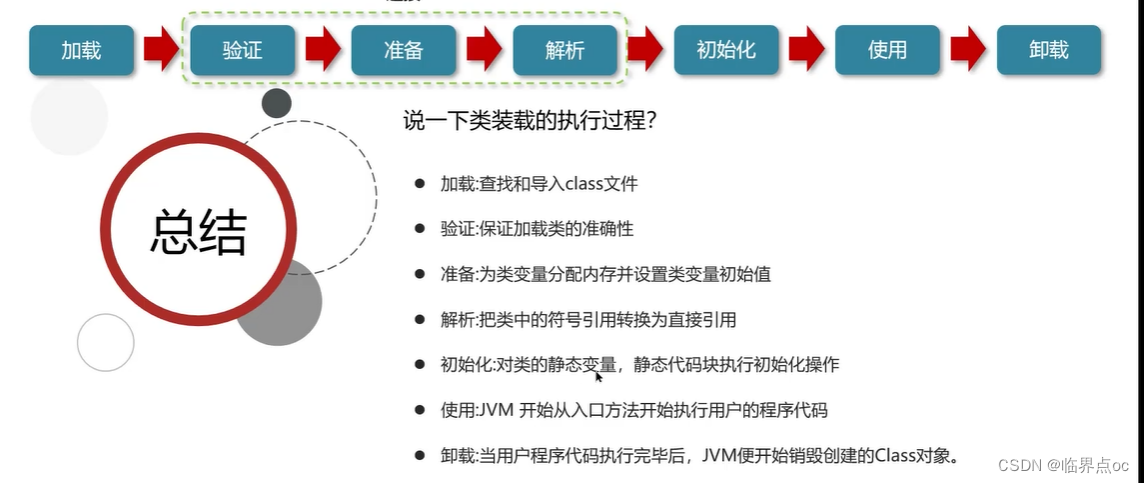
類從加載到虛擬機中開始,知道卸載為止,它的整個生命周期包括了:加載、驗證、解析、初始化、使用和卸載著7個階段。其中,驗證、準備和解析這三個部分統稱為連接(linking)
(9)對象什么時候可以被垃圾器回收
如果一個對象或多個對象沒有任何的引用指向它了,那么這個對象限現在就是垃圾,如果定位了垃圾,則有可能會被垃圾回收器回收。
如果要定位什么是垃圾,有兩種方式來確定,第一個是引用計數法,第二個是可達性分析算法

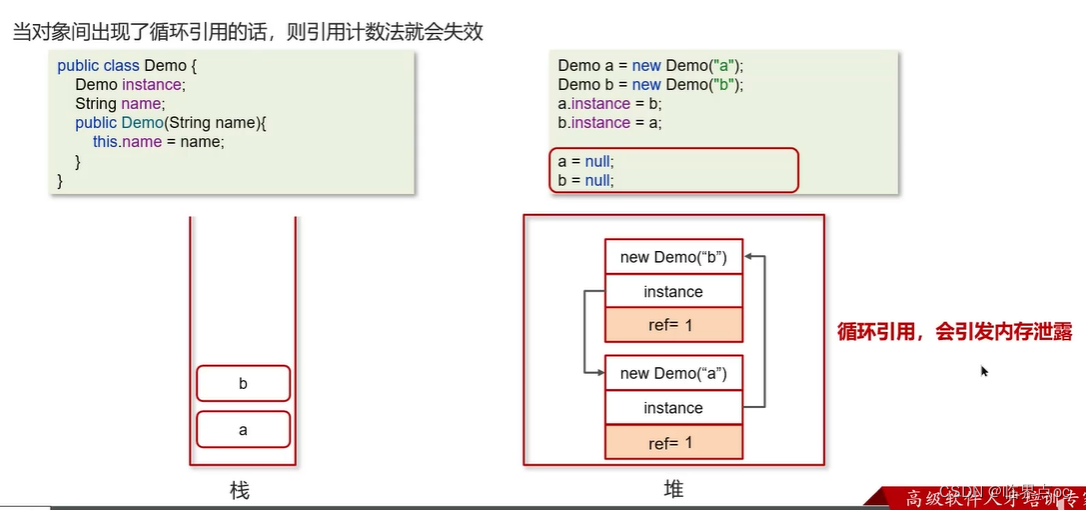
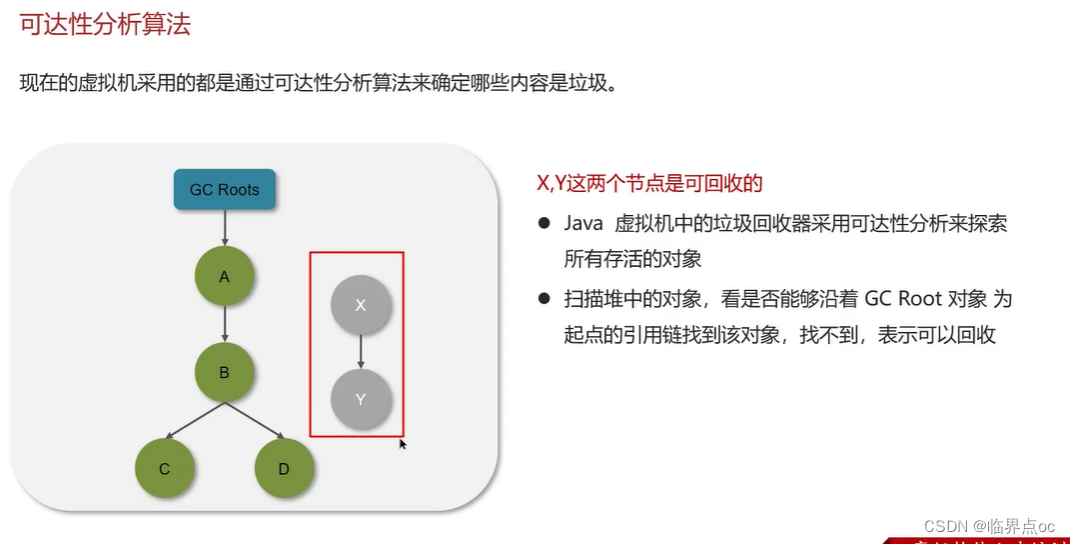


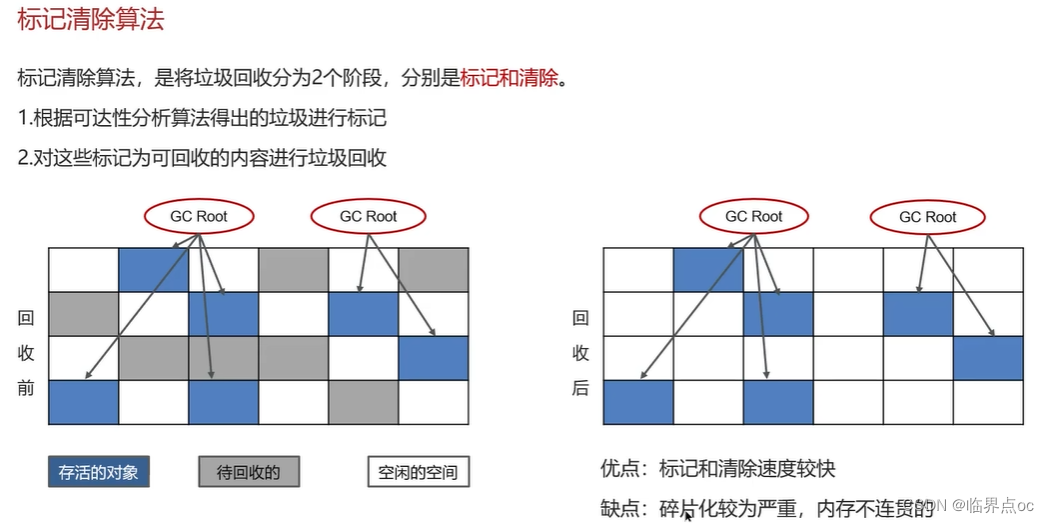
(10)JVM垃圾回收算法有哪些?
①標記清除算法;②復制算法;③標記整理算法
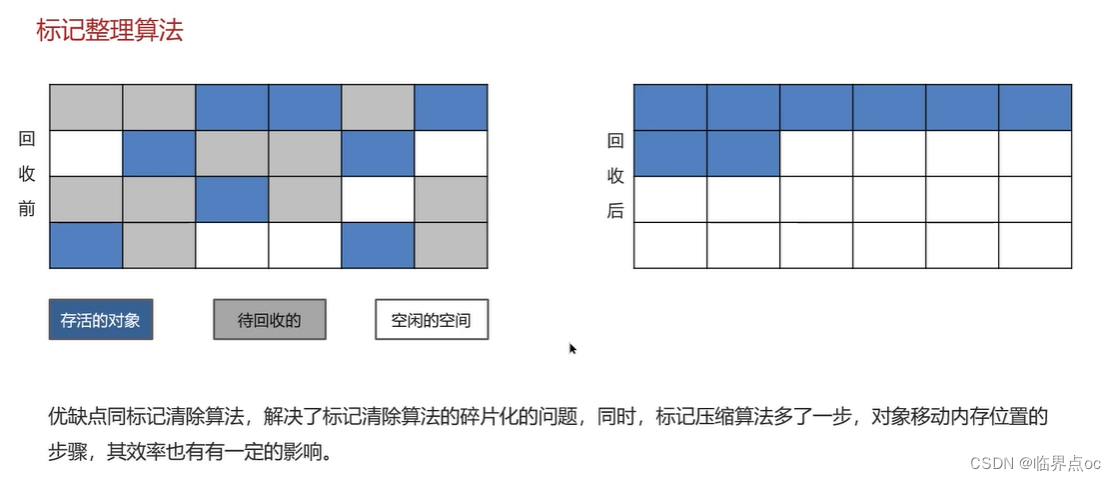
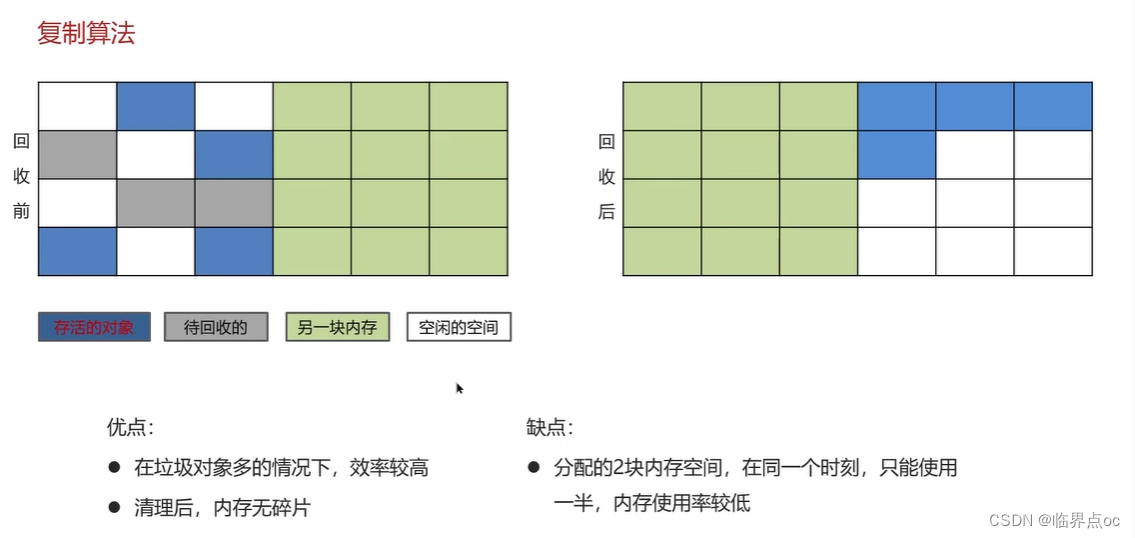

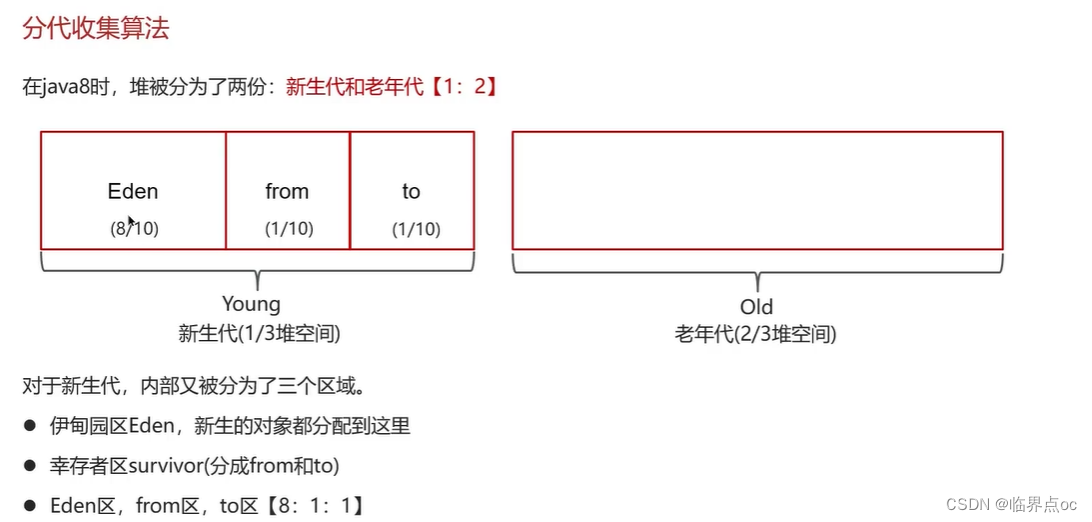
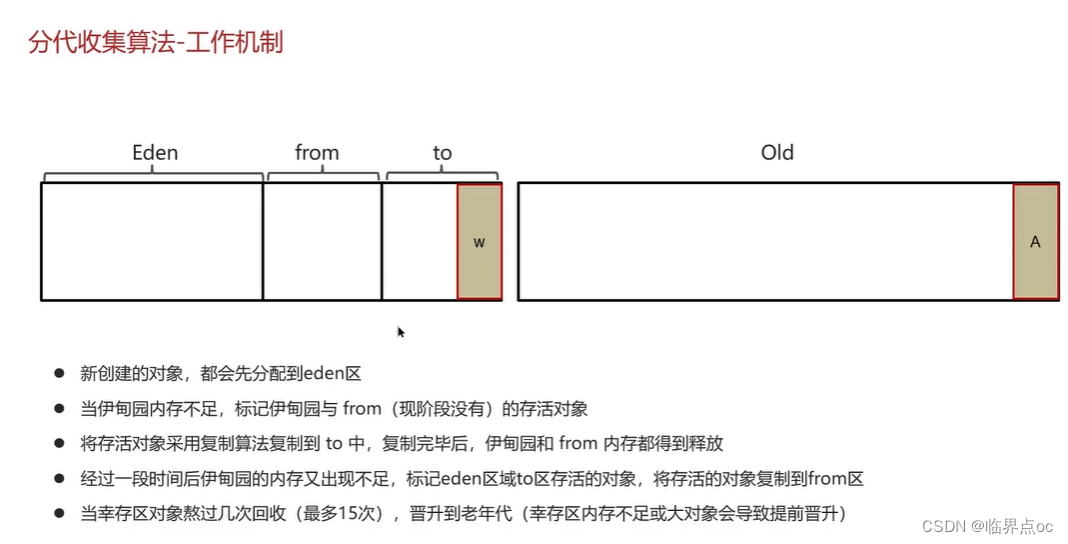
(11)說一下JVM中的分代回收


(12)說一下JVM有哪些垃圾回收器?
在JVM中,實現了多種垃圾收集器,包括:①串行垃圾收集器、并行垃圾收集器、CMS(并發)垃圾收集器;④G1垃圾收集器
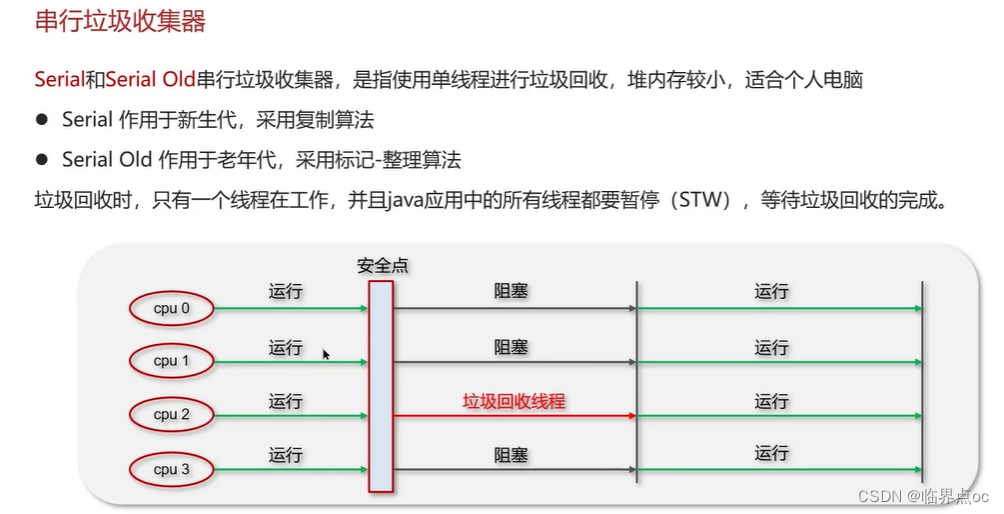
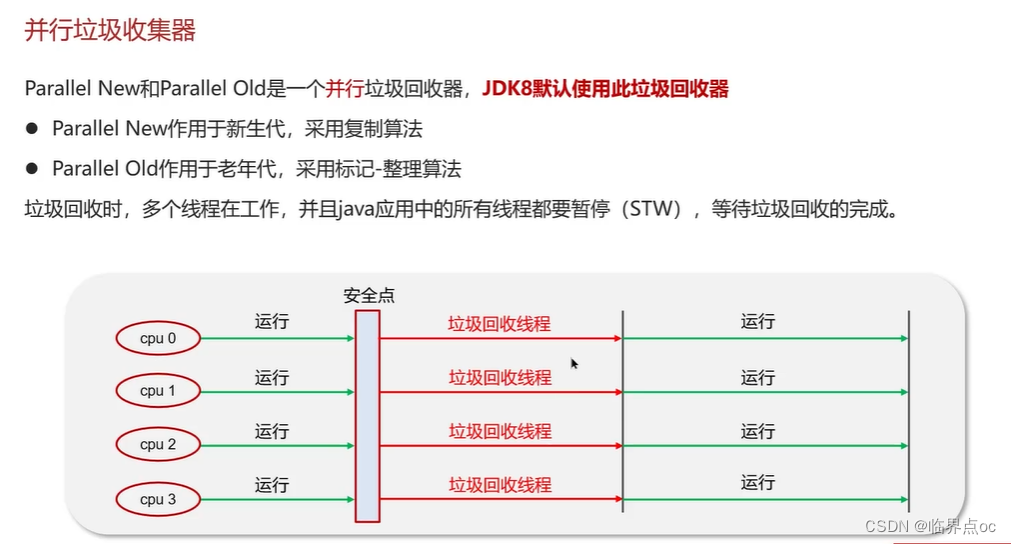
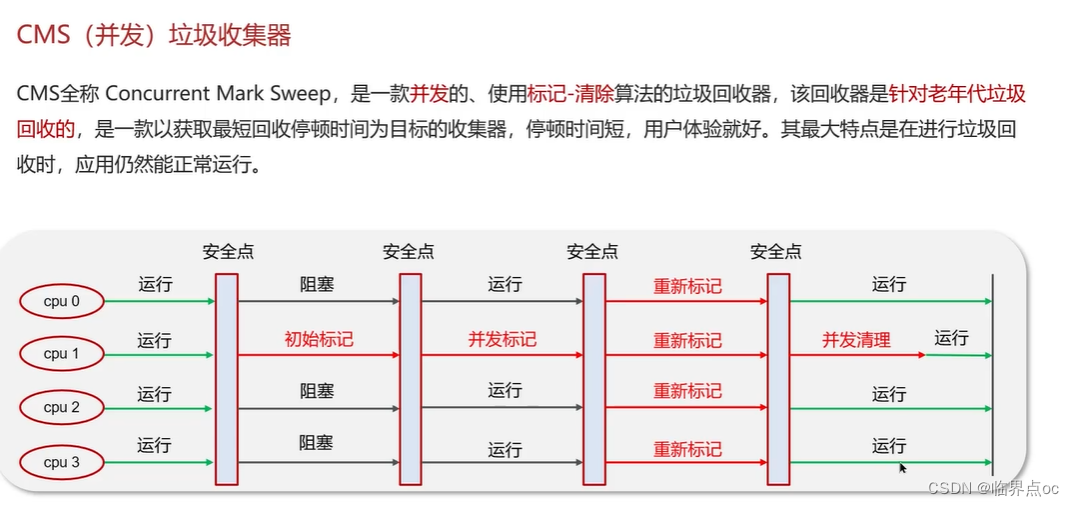
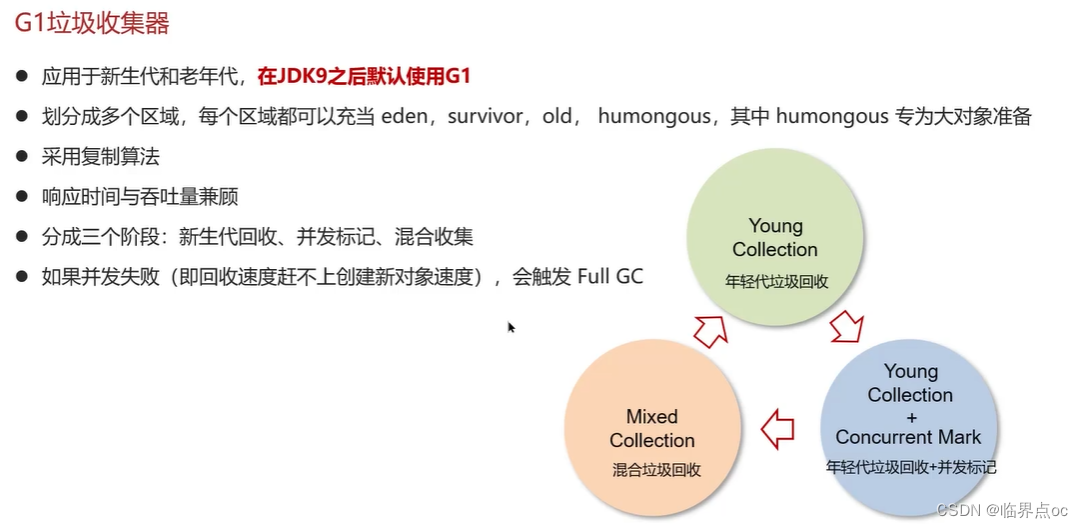
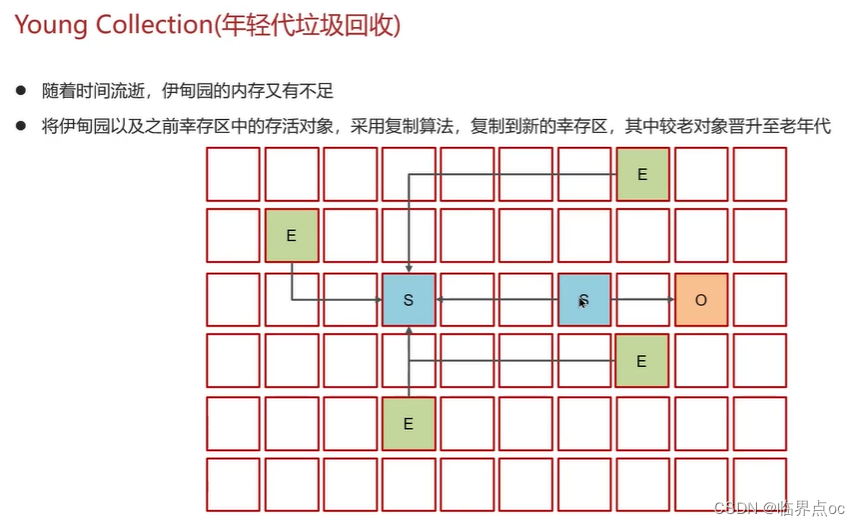
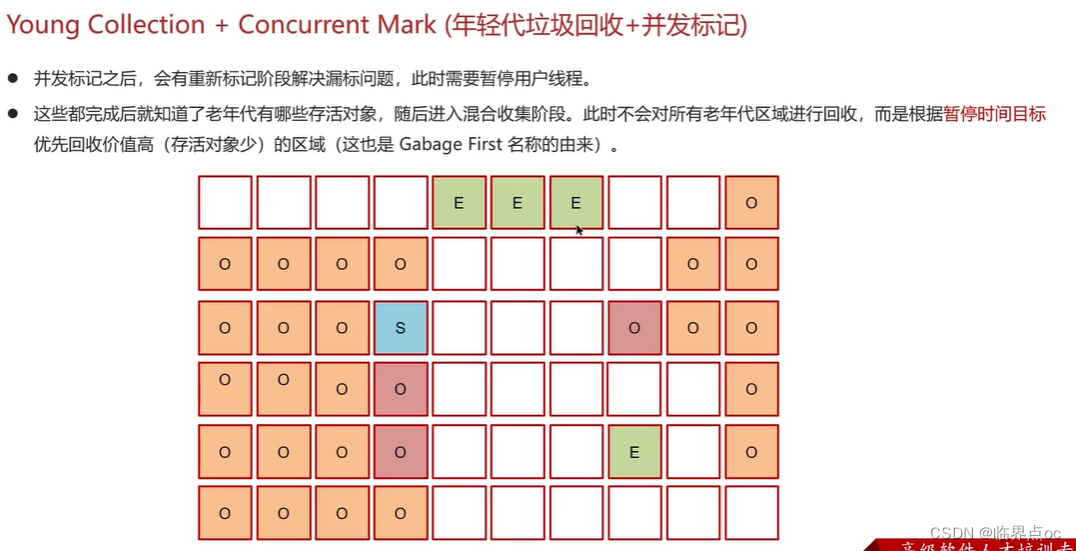
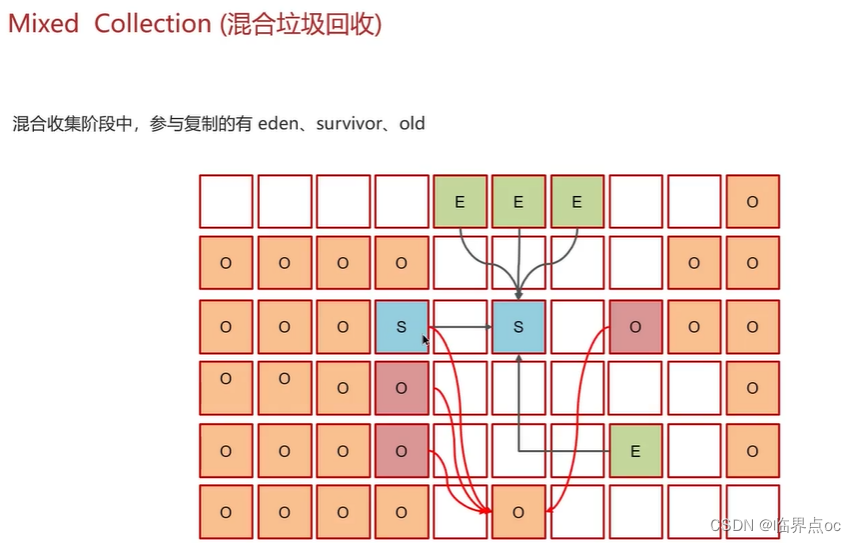
復制完成,內存得到釋放。進入下一輪的新生代回收、并發標記、混合收集


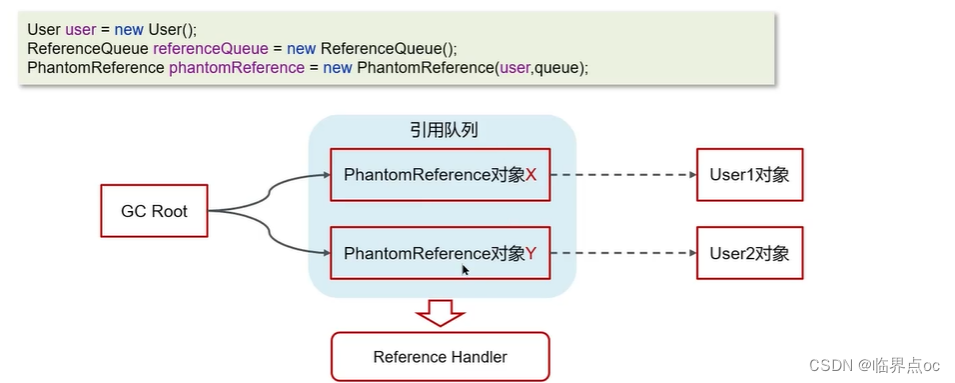
(13)強引用、軟引用、弱引用、虛引用的區別
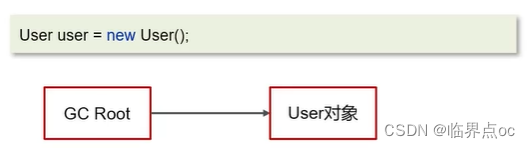
強引用:只有所有GC Roots對象不通過【強引用】引用該對象,該對象才能被垃圾回收
軟引用:僅有軟引用該對象時,在垃圾回收后,內存仍不足時會再次觸發垃圾回收

弱引用:僅有弱引用引用該對象時,在垃圾回收時,無論內存是否充足,都會回收弱引用對象
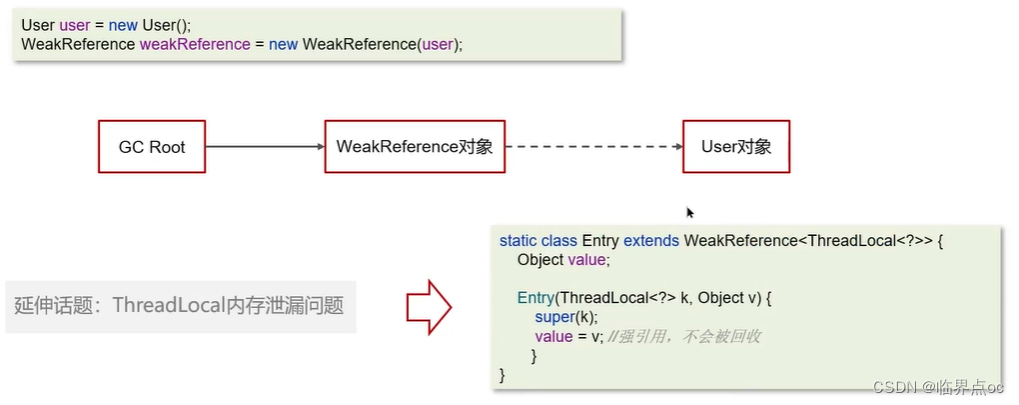
虛引用:必須配合引用隊列使用,被引用對象回收時,會將虛引用入隊,由Reference Handler線程調用虛引用相關方法釋放直接內存。

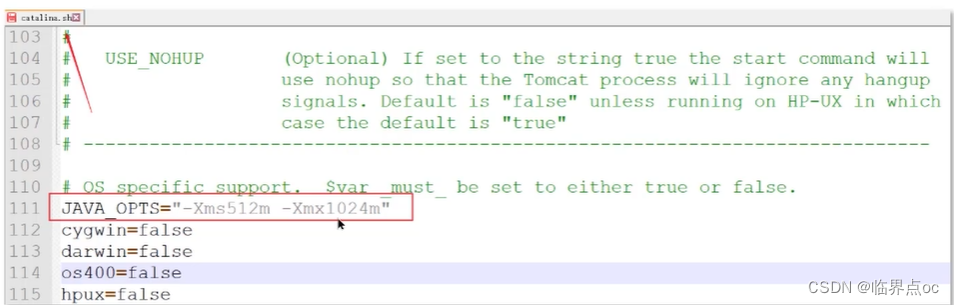
(14)JVM調優的參數可以在哪里設置參數值
war包部署在tomcat中設置
修改TOMCAT_HOME/bin/catalina.sh文件
jar包部署在啟動參數設置
通常在linux系統下直接加參數啟動springboot項目

nohup:用于在系統后臺不斷地運行命令,退出終端不會影響程序的運行
參數 &:讓命令在后臺執行,終端退出后命令仍舊執行
(15)JVM調優的參數都有哪些?
d對于JVM調優,主要是調整年輕代、老年代、元空間的的內存空間大小及使用的垃圾回收器類型。
Java HotSpot VM Options
設置堆空間大小

虛擬機棧的設置

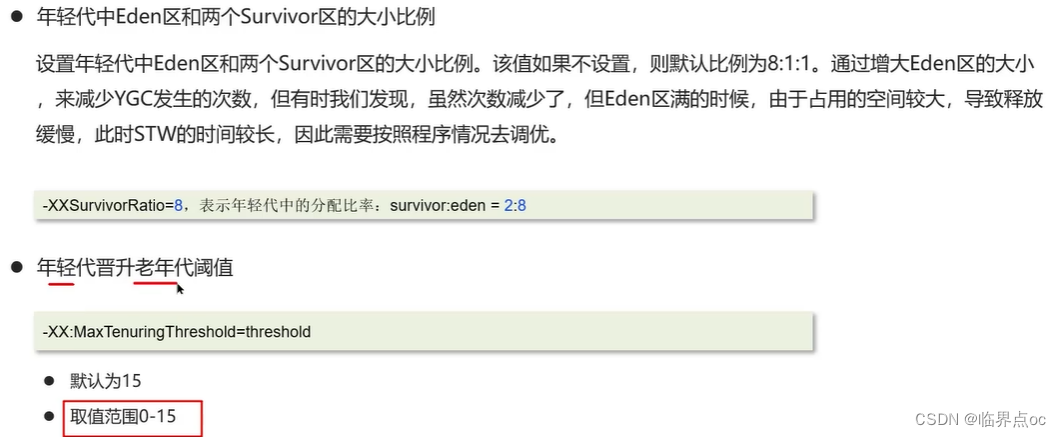
年輕代中Eden區和兩個Survivor區的大小比例
年輕代晉升老年代閾值
設置垃圾回收收集器

(16)說一下JVM調優的工具?

???????
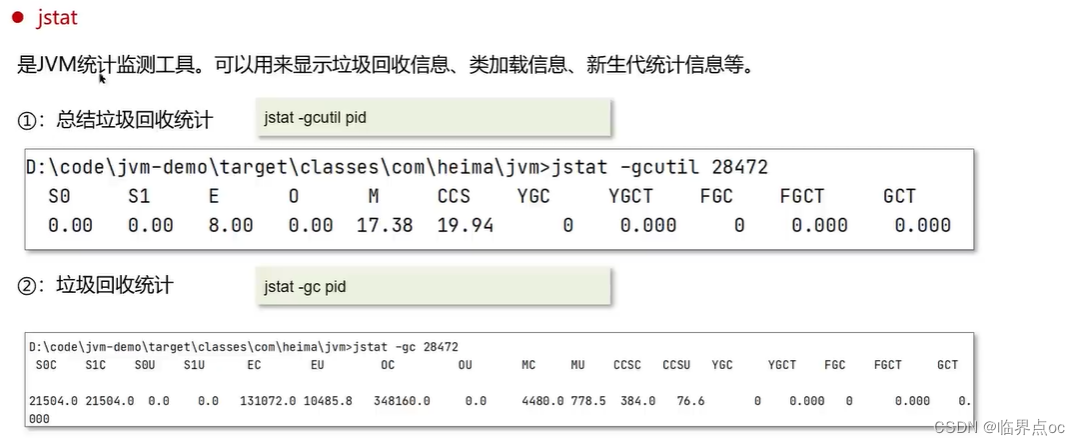
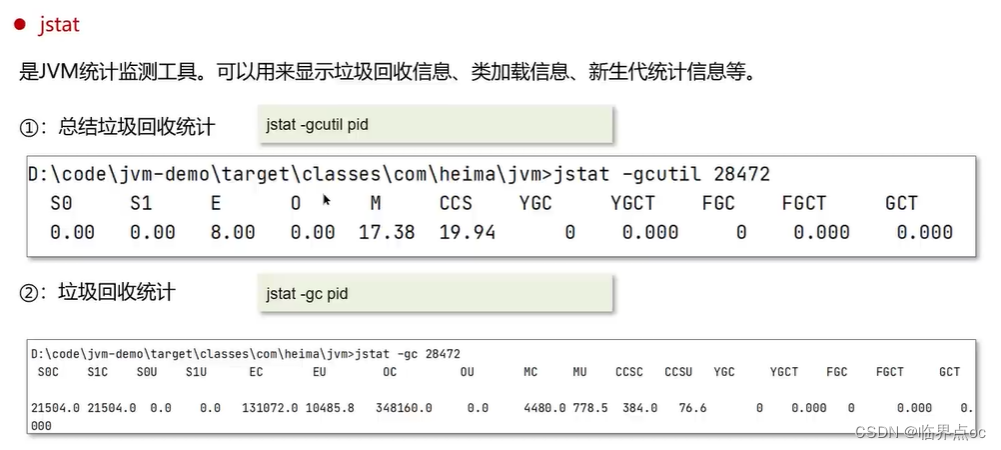
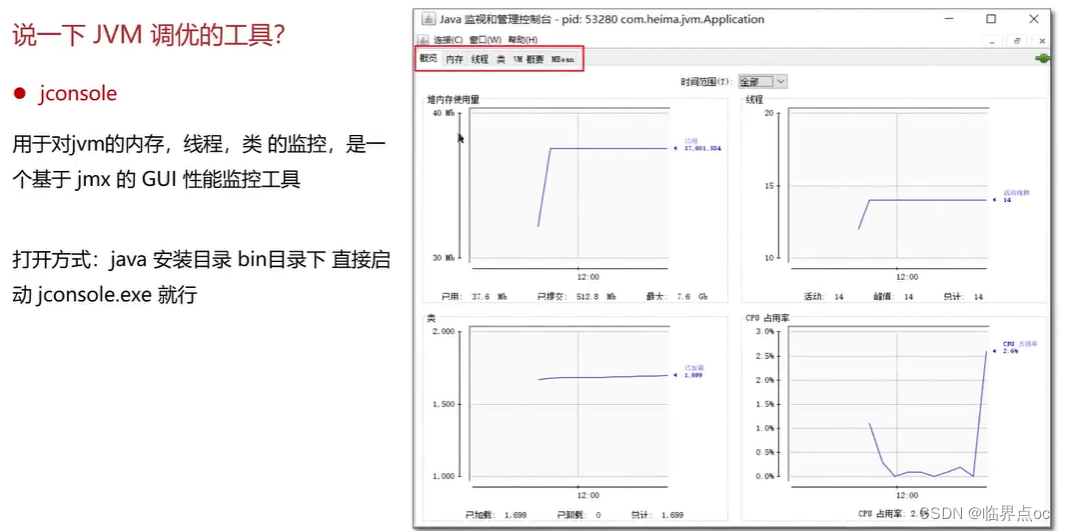
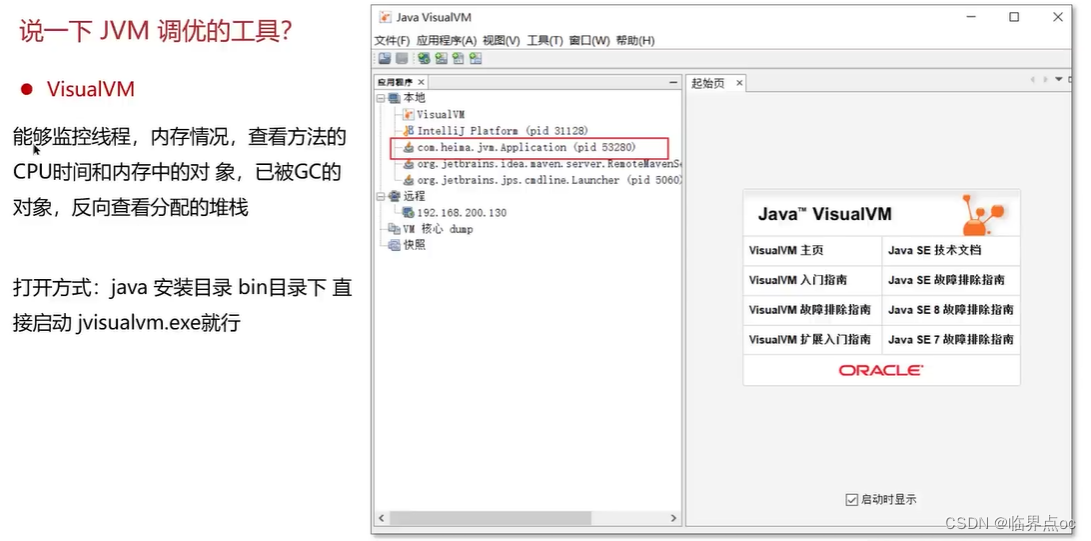
(17)Java內存泄露的排查思路?
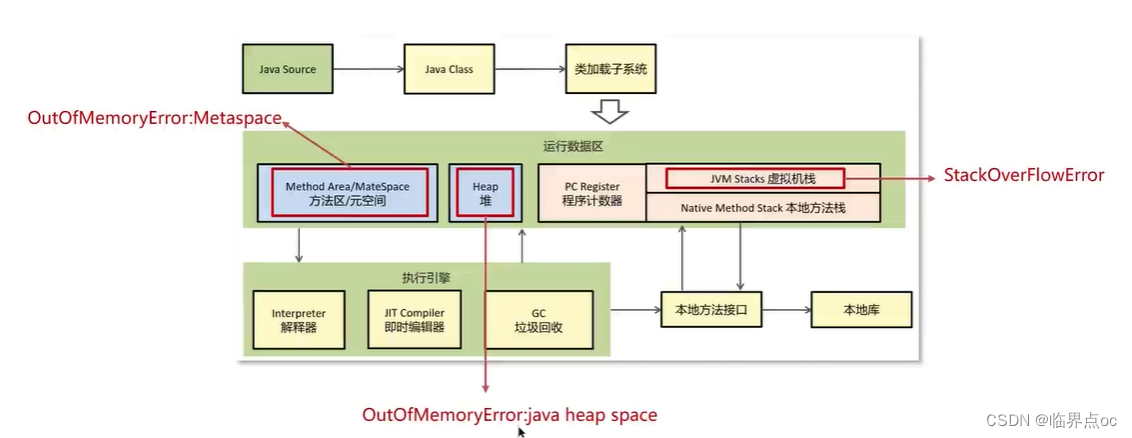
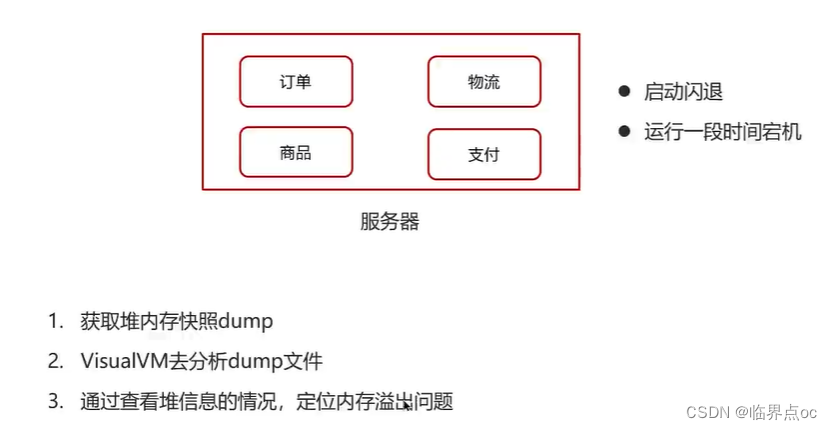
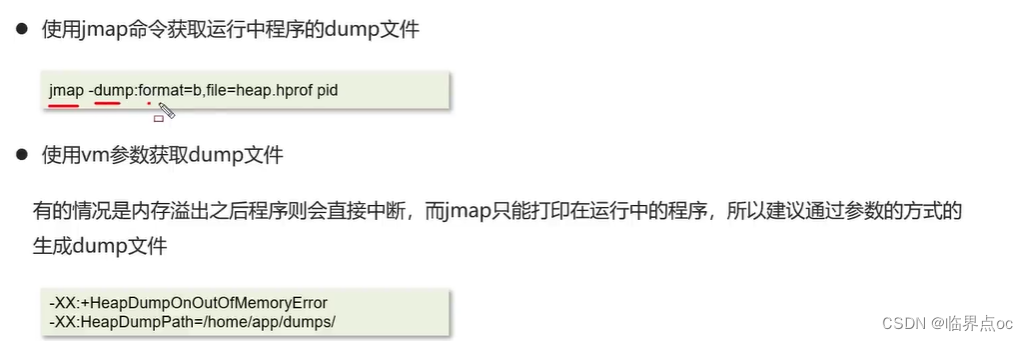
1. 通過jmap指令打印它的內存快照dump(Dump文件是進程的內存鏡像。可以把程序的執行狀態通過調試器保存到dump文件中)
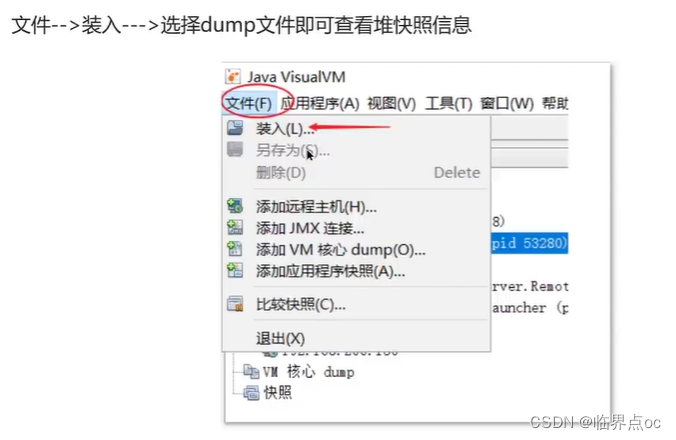
2. 通過工具,VisualVM去分析dump文件,VisualVM可以加載離離線的dump文件
3. 通過查看堆信息的情況,可以大概定位內存溢出是哪行代碼出了問題
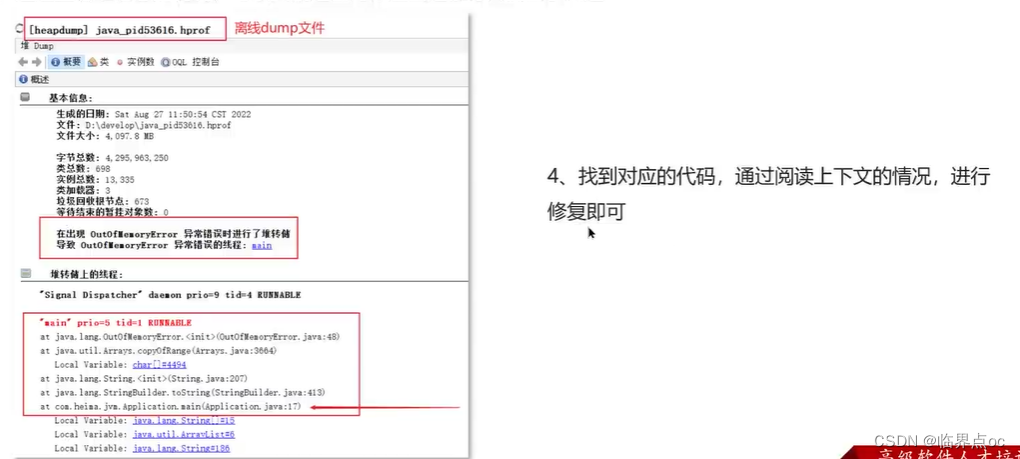
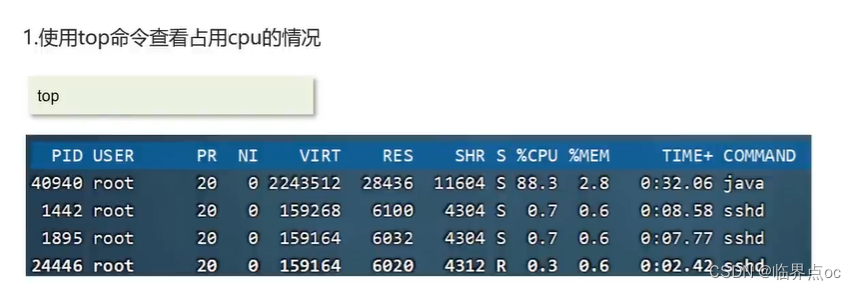
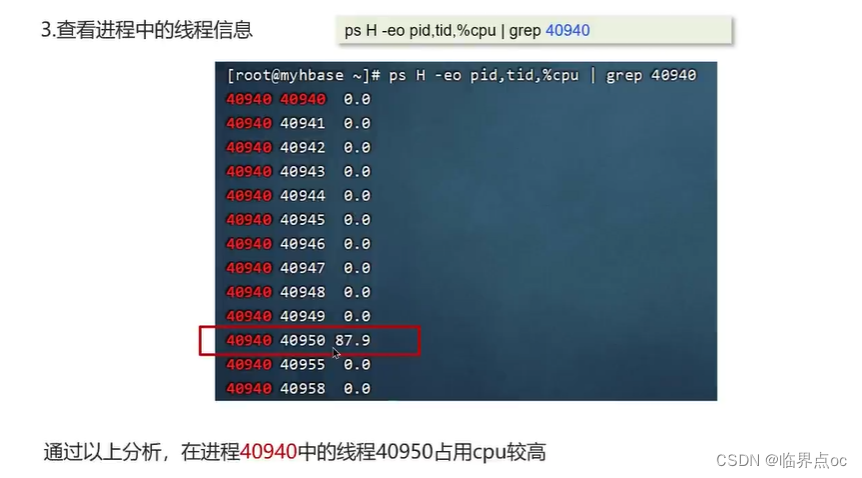
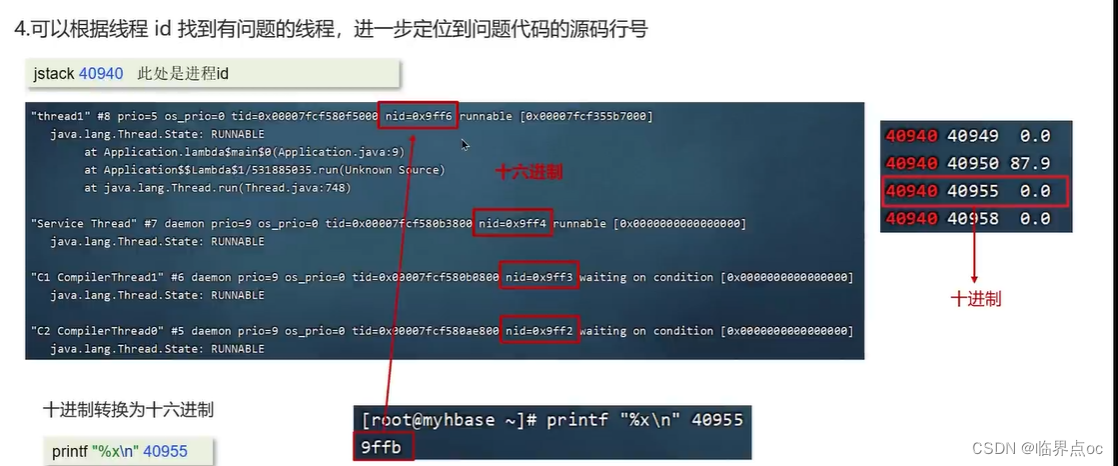
(18)CPU飆高排查方案與思路?


十一、設計模式
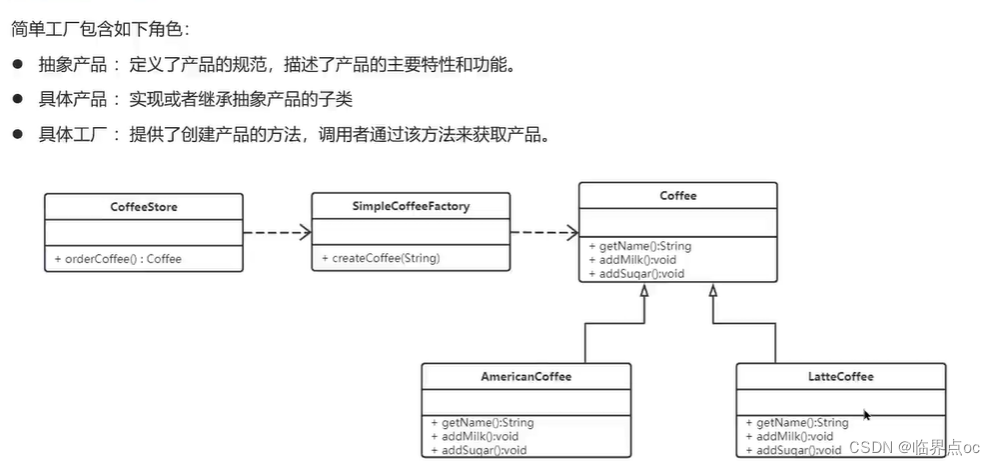
(1)簡單工廠模式
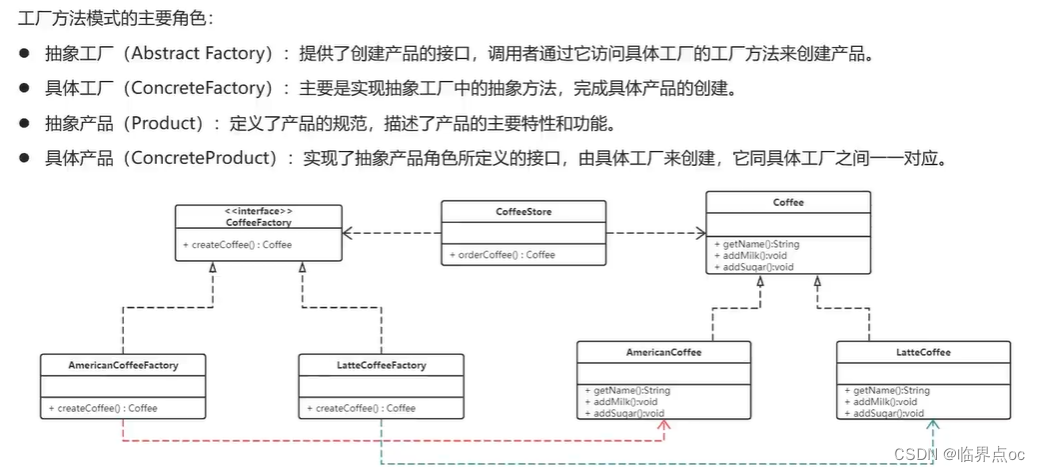
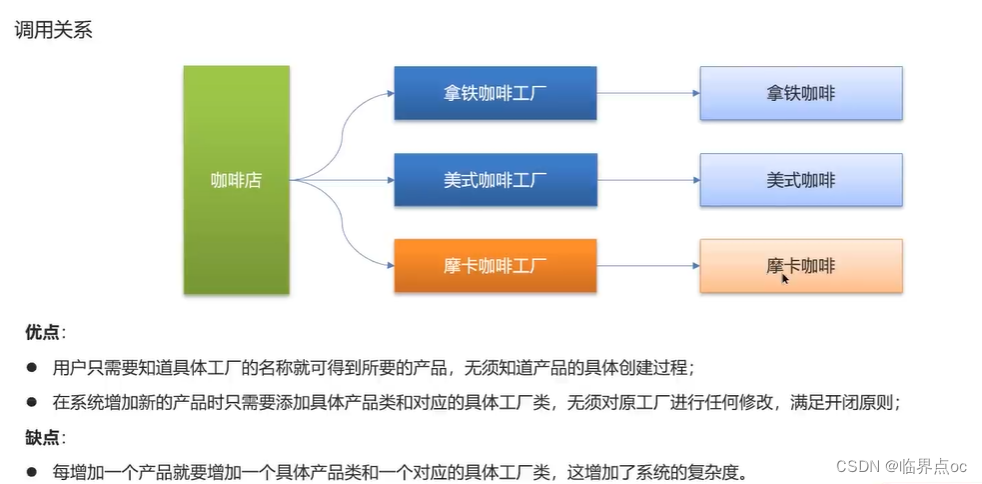
(2)工廠方法模式
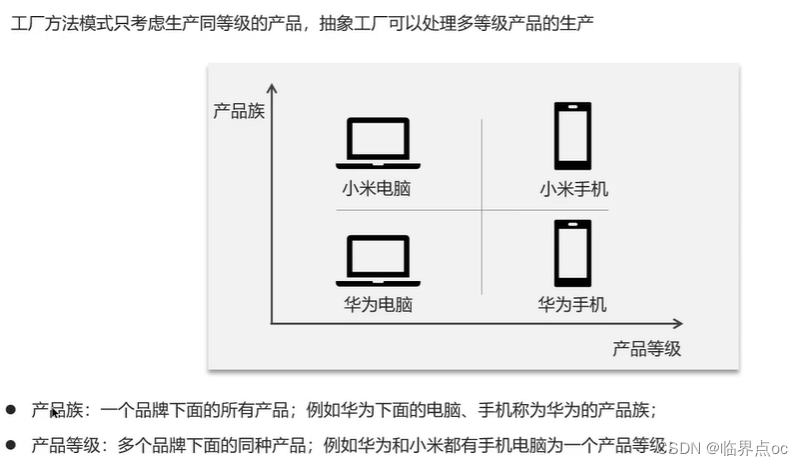
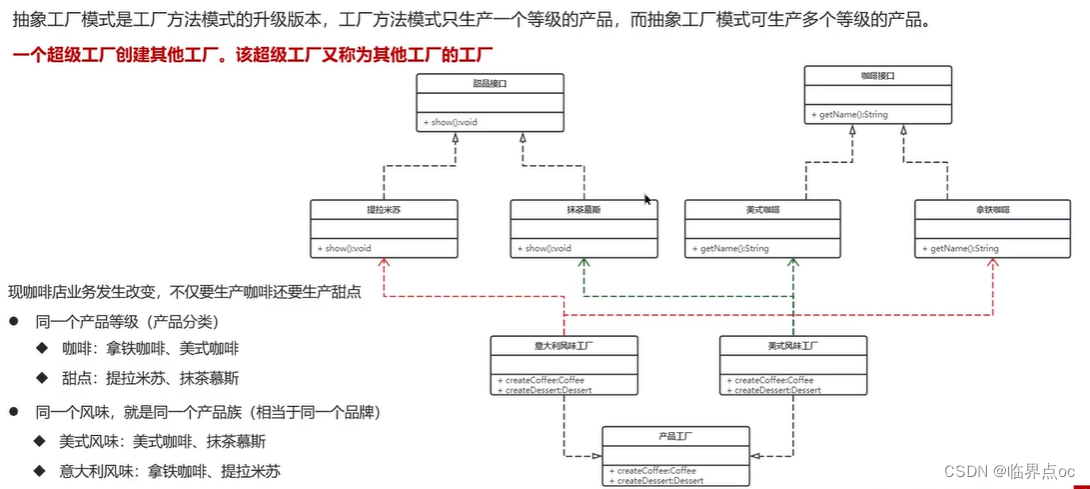
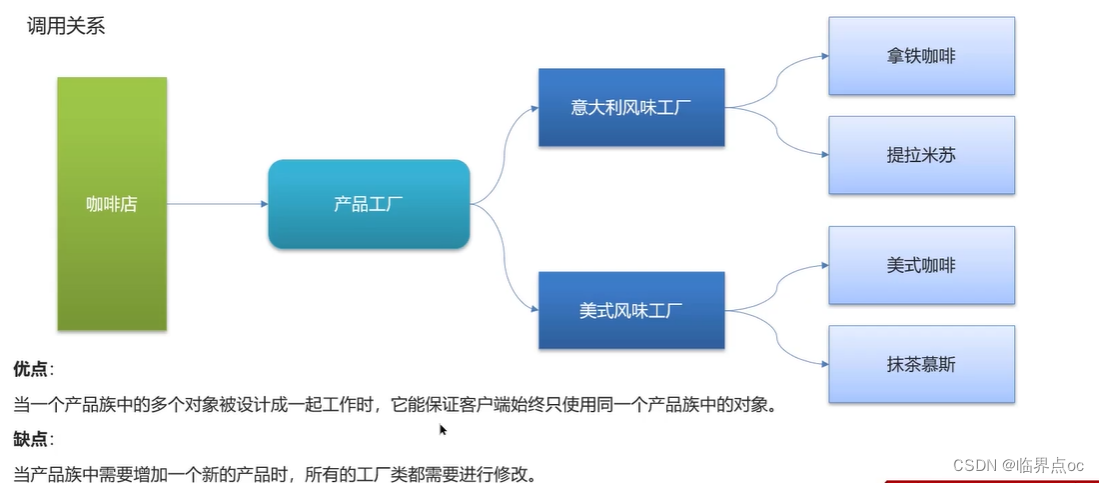
(3)抽象工廠模式

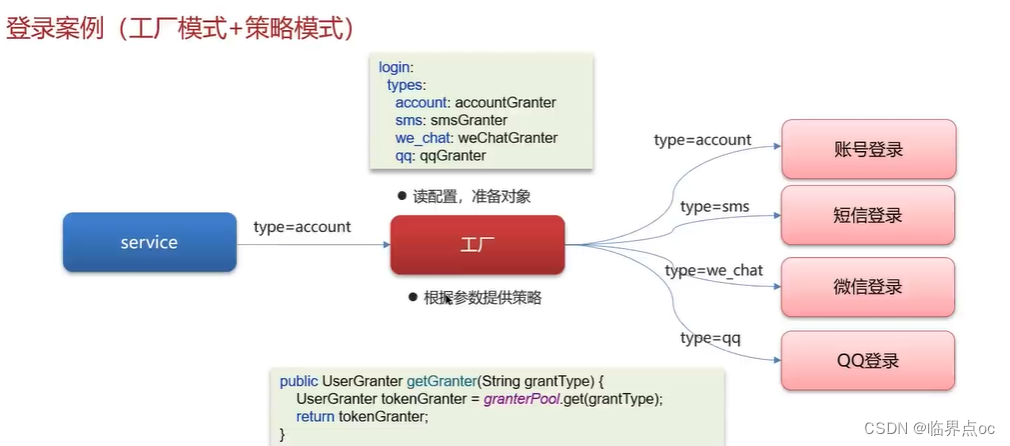
(4)策略模式



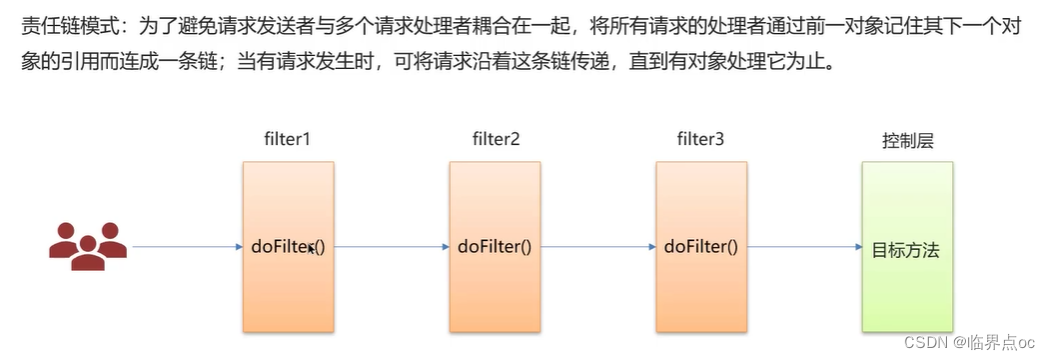
(5)責任鏈設計模式


十二、其他
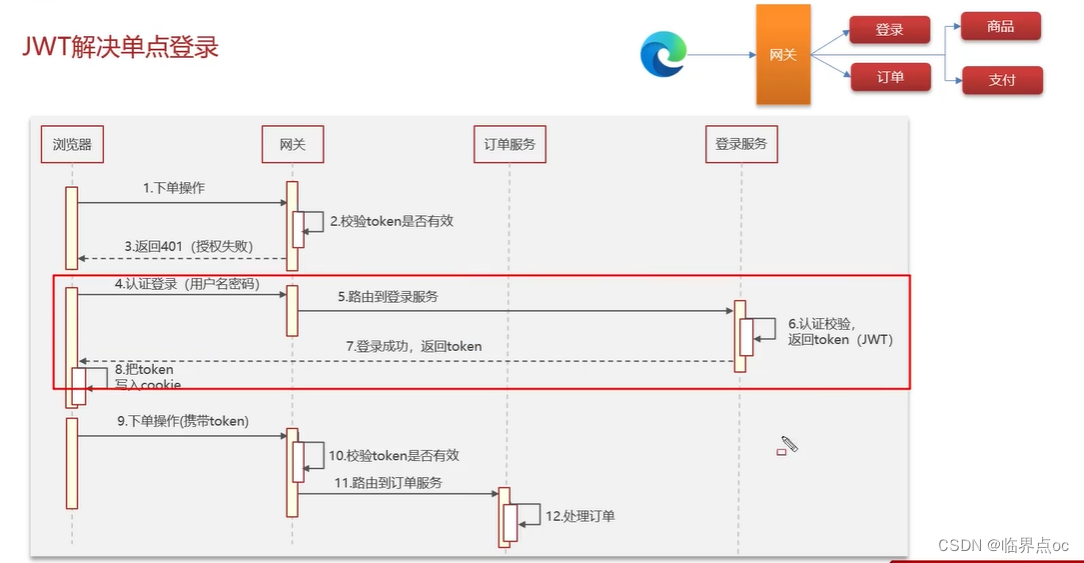
(1)單點登錄這塊怎么實現?
單點登錄的英文名叫作:Single Sign On(簡稱SSO),只需要登錄一次,就可以訪問所有信任的應用系統。


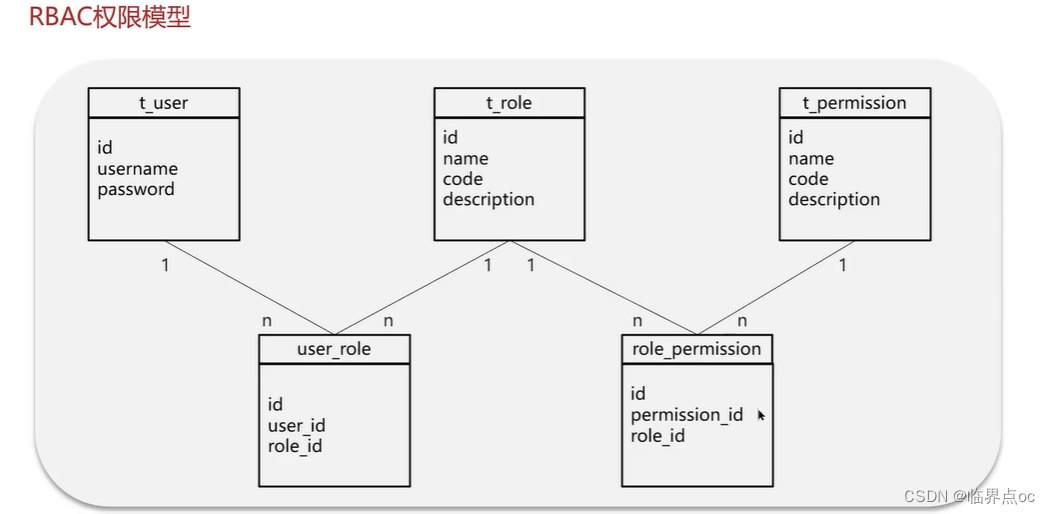
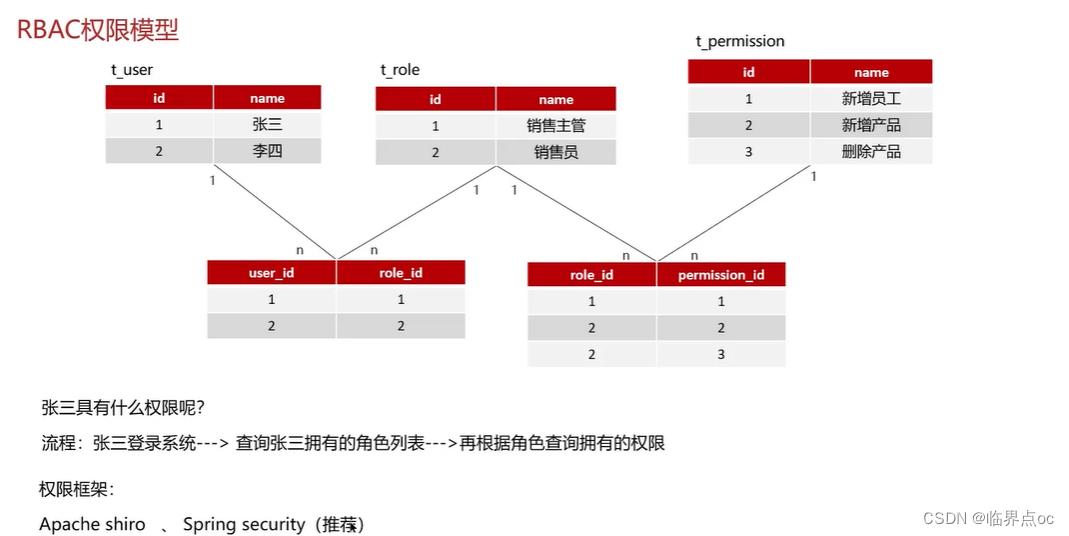
(2)權限認證是如何實現的?
后臺的管理系統,更注重權限控制,最常見的就是RBAC模型來指導實現權限
RBAC(Role-Based Access Control)基于角色的訪問控制

(3)上傳數據的安全性你們是怎么控制的?
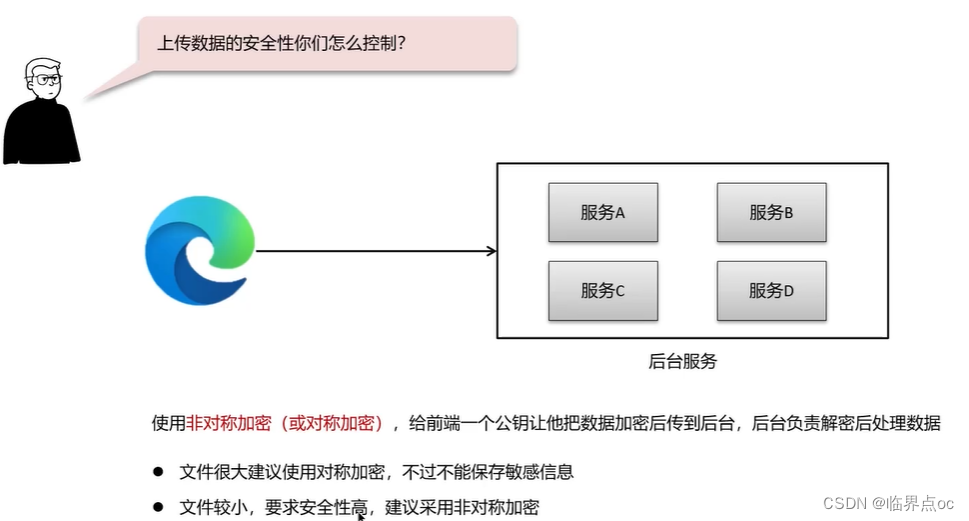

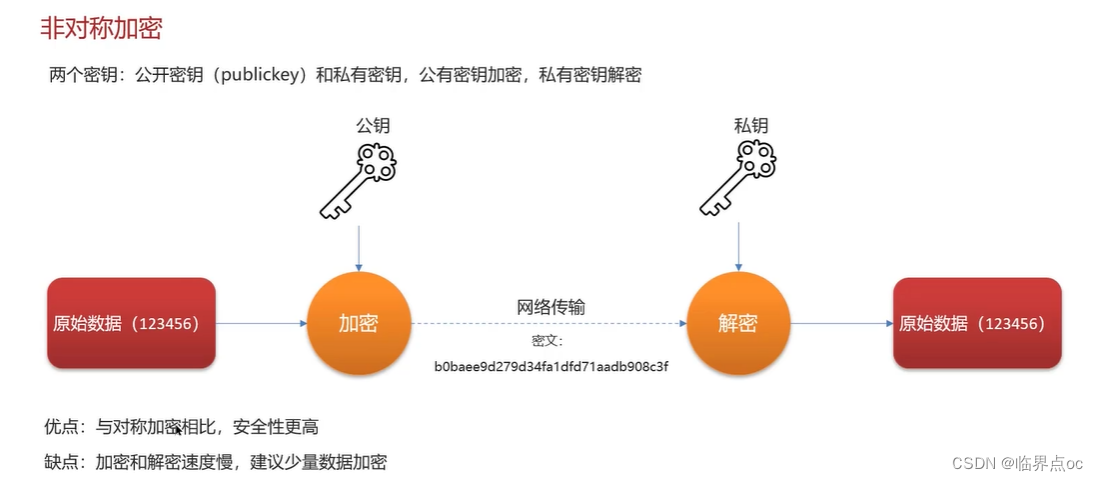
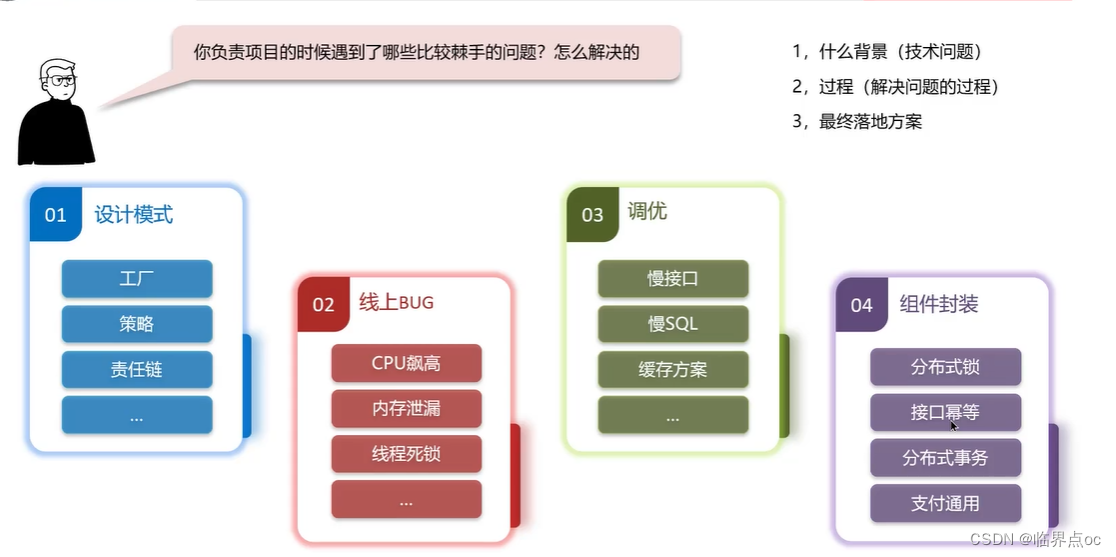
(4)你負責項目的時候遇到了哪些比較棘手的問題?怎么解決的?
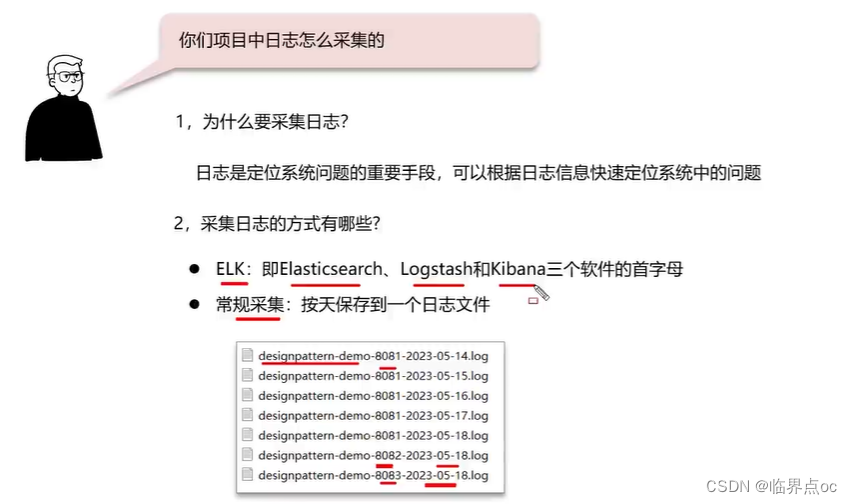
(5)你們項目中日志怎么采集的?
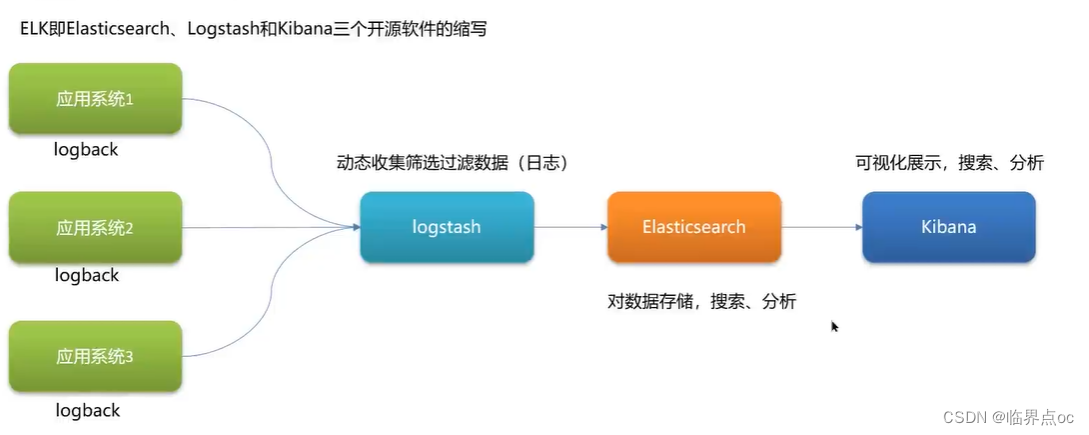

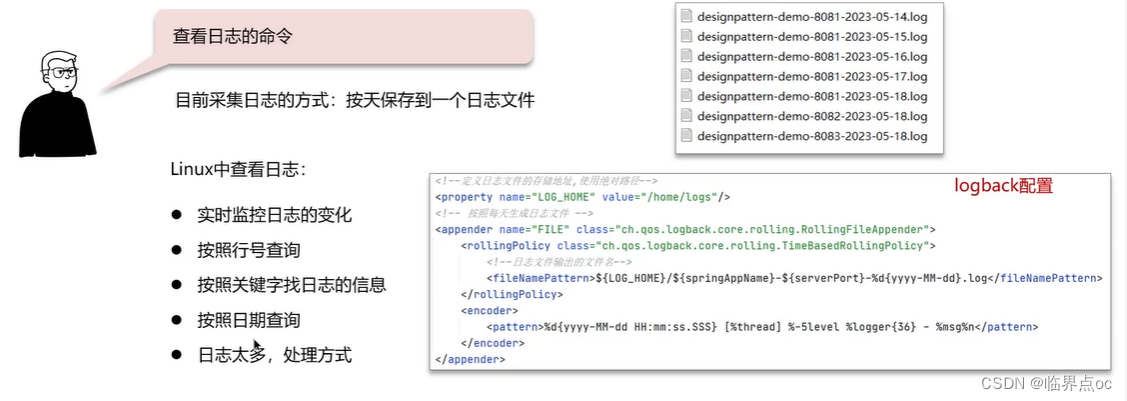
(6)查看日志的命令

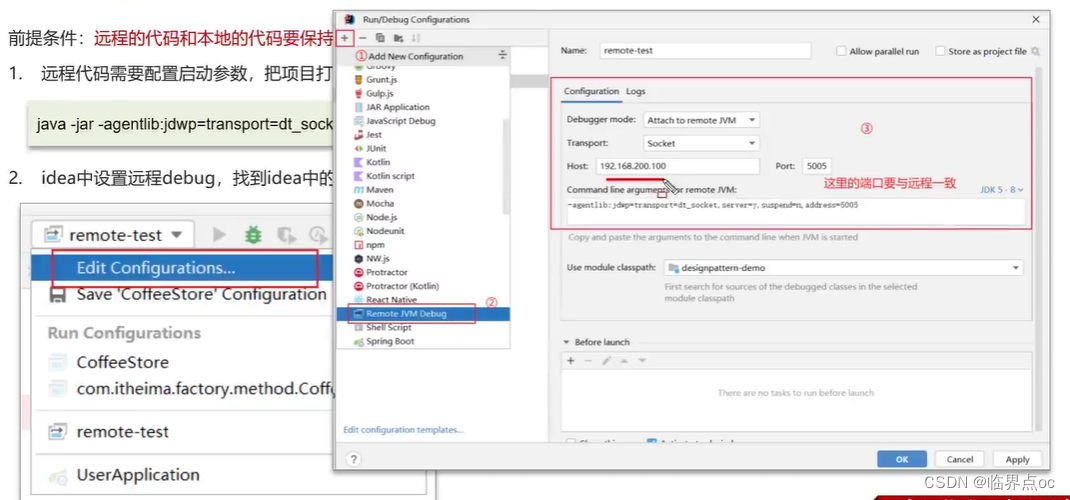
(7)生產問題怎么排查?



(8)怎么快速定位系統的瓶頸

 ???????
???????












:面向對象編程)






