
?作者|堅果
來源|神州問學
?引言
馬斯克巨資60億美元打造的“超級算力工場”,通過串聯10萬塊頂級NVIDIA H100 GPU,不僅震撼了AI和半導體行業,促使英偉達股價應聲上漲6%,還強烈暗示了AI大模型及芯片需求的急劇膨脹。這一行動不僅是馬斯克對AI未來的大膽押注,也成為了全球企業加速布局AI芯片領域的催化劑,預示著一場科技革新競賽的全面升級,各方競相提升算力,爭奪AI時代的戰略高地。觀察近期Blackwell與Gaudi 3芯片的設計優化路徑,不難發現GPU芯片制造商已在不同程度上汲取了存算一體技術的精髓,尤其側重于近存計算架構的采納,以此直面大模型對高算力與高存儲需求的挑戰。
存算一體技術詳解
存算一體(Computational Memory或In-Memory Computing)的概念并非新近才出現,而是計算機科學領域一個長期的研究方向。它的起源可以追溯到早期計算機架構的探索,旨在克服馮·諾依曼架構的局限性,特別是數據傳輸帶寬瓶頸(通常稱為“內存墻”)的問題。
存算一體技術的過去和現在
追溯至上世紀80年代,存算一體的概念初現端倪,彼時研究者開始探討如何在存儲器內部直接進行計算,以減少數據在處理器與內存之間頻繁移動帶來的延遲與能耗。然而,受限于當時的材料科學與制造工藝,早期的嘗試多停留在理論探索與初步原型階段。進入21世紀,隨著納米科技、新材料與先進制造技術的飛速發展,存算一體技術迎來了突破性進展。新型非易失性存儲器,如相變存儲器(PCM)、磁阻隨機存取存儲器(MRAM)和電阻式隨機存取存儲器(RRAM),因其具備高速度、低功耗及非易失性等特點,成為實現存算一體的關鍵載體。這些存儲技術不僅能夠存儲信息,還能在其存儲單元上直接執行基本邏輯運算,從而大幅縮短數據傳輸距離,顯著提升整體計算效能。近年來,存算一體技術在學術界與產業界均獲得了廣泛關注與投資,多家科研機構與企業已研發出原型產品。例如,英特爾的Optane DC持久內存結合了DRAM的高速度與NAND閃存的非易失性,展現了存算一體的部分潛力;而IBM、三星、惠普實驗室等也在探索將存算一體應用于人工智能、大數據分析等領域,以期構建更高效能的計算平臺。
存算一體技術原理和分類
存算一體芯片基本架構圖所示,神經網絡模型的權重可以映射為子陣列中存儲單元的電導率,而輸入特征圖(Feature map)作為行電壓并行加載(圖中WL方向),然后以模擬方式進行乘法(即輸入電壓乘以權重電導),并使用列上的電流求和(圖中BL方向)來生成輸出向量。
圖源:
https://www.bilibili.com/video/BV1hF411a7wt/?from=search&seid=3978061323598318972&spm_id_from=333.337.0.0
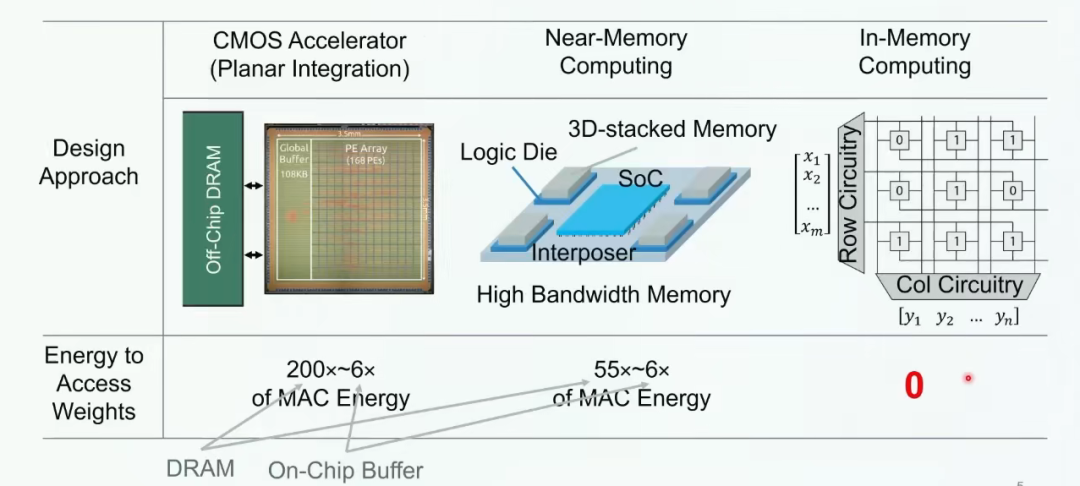
按照計算單元和存儲單元的距離,存算一體技術大致分為近存計算(PNM)、存內處理(PIM)、存內計算(CIM)。
存內處理?則主要側重于將計算過程盡可能地嵌入到存儲器內部。這種實現方式旨在減少處理器訪問存儲器的頻率,因為大部分計算已經在存儲器內部完成。這種設計有助于消除馮·諾依曼瓶頸帶來的問題,提高數據處理速度和效率。
近存計算?是一種較為成熟的技術路徑。它利用先進的封裝技術,將計算邏輯芯片和存儲器封裝到一起,通過減少內存和處理單元之間的路徑,實現高I/O密度,進而實現高內存帶寬以及較低的訪問開銷。近存計算主要通過2.5D、3D堆疊等技術來實現,廣泛應用于各類CPU和GPU上。
存內計算?同樣是將計算和存儲合二為一的技術。它有兩種主要思路。第一種思路是通過電路革新,讓存儲器本身就具有計算能力。這通常需要對SRAM或者MRAM等存儲器進行改動,以在數據讀出的decoder等地方實現計算功能。這種方法的能效比通常較高,但計算精度可能受限。
存算一體技術的最終目標是提供一種計算平臺,它能夠顯著降低數據搬運的成本,提高計算效率,特別是在大規模并行計算和機器學習任務中展現出巨大的潛力。然而,這一領域的研究和開發仍面臨諸多挑戰,包括技術成熟度、可擴展性、成本和標準化等問題。
AI處理器架構參考近存計算原則
今年推出性能優化的兩款高性能AI芯片,都不同程度優化了內存模塊以拓展顯存容納更大規模的參數。
NVIDIA Blackwell
今年3月18日NVIDIA 在GTC宣布推出 NVIDIA Blackwell 架構以賦能計算新時代。

圖源:
https://www.nvidia.cn/data-center/technologies/blackwell-architecture/
Blackwell 架構 GPU 具有 2080 億個晶體管,采用專門定制的臺積電 4NP 工藝制造。所有 Blackwell 產品均采用雙倍光刻極限尺寸的裸片,通過 10 TB/s 的片間互聯技術連接成一塊統一的 GPU。Blackwell架構的GPU,作為高性能計算和AI加速器,參考近存計算的架構高度集成計算單元和存儲單元。
Blackwell GPU以集成的 HBM3E內存為核心,實現8Gbps速度與8TB/s帶寬,大幅縮減數據傳輸至計算單元的時間,有效降延遲、控能耗。其計算單元與內存的協同設計,確保了數據的快速訪問與高效利用,破解數據傳輸瓶頸。結合Grace CPU的系統集成,更促進了計算與內存管理的無縫銜接,共享數據機制減少了跨資源傳輸,雖非存內計算,卻通過內存與計算的緊密融合,實現了減少數據移動、提升計算效能的目標,與存算一體架構理念不謀而合。
Gaudi
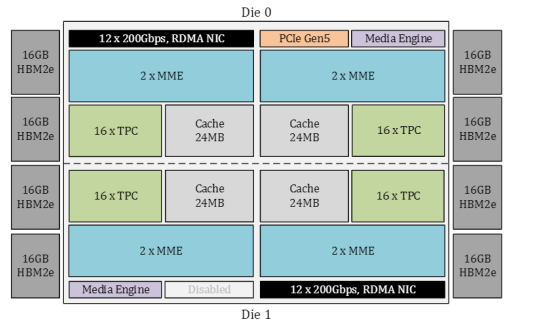
今年4月9日晚,英特爾在美國召開了“Intel Vision 2024”大會發布了Gaudi 3 AI芯片。Gaudi 3 擁有 8 個矩陣數學引擎、64 個張量內核、96MB SRAM(每個Tile 48MB,可提供12.8 TB/s的總帶寬) 和 128 GB HBM2e 內存,16 個 PCIe 5.0 通道和 24 個 200GbE 鏈路 。在計算核心的周圍,則是八個HBM2e內存堆棧,總容量為128 GB,帶寬為3.7 TBps。訓練性能比英偉達H100快了40%,推理快了50%。
圖源:
https://www.intel.com/content/www/us/en/content-details/817486/intel-gaudi-3-ai-accelerator-white-paper.html
Gaudi 3 AI加速器通過一系列優化,深刻詮釋了近存計算的精髓。其搭載的128GB HBM2e內存,以超高的數據傳輸速率削減訪問延遲;雙計算集群Chiplet設計讓計算貼近數據,減少移動距離;增強的網絡帶寬優化了分布式計算中的數據交換,有效降低節點間通信延遲;AI專用計算單元針對矩陣與卷積運算進行高效優化,間接促進數據訪問效率。所有這些設計,均致力于減少數據移動,提升計算效能,完美呼應了近存計算減少延遲、降低能耗的核心目標。
其他
除了以上廠家其他廠家也采用了近存計算或類似架構原則。
AMD MI200系列 GPU:
AMD的Instinct MI200系列GPU采用了3D V-Cache技術,以及HBM2e內存,提供了高帶寬數據訪問,旨在減少數據傳輸延遲。
Groq Tensor Processing Unit (TPU):
Groq的TPU采用了獨特的架構設計,其中包括了大規模的片上SRAM,以及高度并行的計算單元,旨在提供低延遲和高吞吐量的計算環境。
Graphcore IPU:
Graphcore的Intelligence Processing Units (IPUs) 設計有大規模的片上內存,以及分布式內存架構,以減少數據移動,提高機器學習模型的訓練和推理速度。
存算一體架構解決大模型高算力高存儲的需求
大模型高算力高存儲需求的挑戰
大模型計算任務對高算力的依賴源于其參數量的天文數字——如GPT-3的1750億參數——以及數據密集型訓練需求,后者涉及處理570GB規模的文本數據集。模型的深度與寬度、高維特征的處理、訓練迭代中的權重更新,乃至分布式訓練的協調,無一不在考驗著系統的計算極限。此外,模型優化和探索階段的資源消耗也不容小覷。為此,現代數據中心裝備了高性能GPU、TPU及配套基礎設施,旨在支撐這一計算盛宴。
高存儲挑戰則聚焦于顯存的極限。大模型的海量參數,即便是采用FP16或BF16低精度表示,也需占用大量存儲空間。前向與反向傳播產生的中間結果、優化器狀態維護、混合精度訓練中的精度轉換,以及批量處理和數據預處理階段的臨時數據生成,均顯著提升了顯存需求。尤其是模型推理階段,面對長序列或高分辨率數據,顯存消耗尤為突出。因此,諸如NVIDIA A100 GPU配備的80GB HBM2顯存成為必要,以應對大規模模型的訓練與推理需求。
存算一體架構優勢
存算一體架構針對大模型運算的高算力和高存儲需求,展現出了顯著優勢,通過在存儲單元本地執行計算,極大地減少了數據在CPU和內存之間傳輸的延遲和能量損耗,從而大幅度提升了計算效率。這種架構特別適合處理擁有海量參數和大規模數據集的大模型,如深度神經網絡,因為它能有效地解決“存儲墻”問題,確保即使在處理高維特征空間和進行復雜的模型優化時,也能保持高性能和低功耗,是實現未來高性能計算的關鍵技術之一。
結論
隨著數字化程度的日益加深,數字資產隨之累積,導致大模型所需的數據源愈發豐富,模型參數量亦呈指數級增長。這無疑對AI處理器提出了更高的要求,不僅需要更強大的存儲能力來容納這些海量數據,還必須具備更快的運算能力以實現高效處理。當前,AI處理器的研發正從多方面展開創新,除了持續優化科學計算的基本處理單元結構,還積極探索借鑒存算一體架構中的近存計算設計理念,旨在通過縮短數據讀取路徑,擴大存儲規模并減少數據傳輸中的能耗,從而大幅提升效率。顯然,存算一體架構已成為驅動AI芯片技術進步的關鍵因素。







:面向對象編程)












![[從0開始軌跡預測][NMS]:NMS的應用(目標檢測、軌跡預測)](http://pic.xiahunao.cn/[從0開始軌跡預測][NMS]:NMS的應用(目標檢測、軌跡預測))