論文:CM-UNet: Hybrid :CNN-Mamba UNet for Remote Sensing Image Semantic Segmentation
代碼:https://github.com/XiaoBuL/CM-UNet
Abstrcat:
由于大規模圖像尺寸和對象變化,當前基于 CNN 和 Transformer 的遙感圖像語義分割方法對于捕獲遠程依賴性不是最佳的,或者受限于復雜的計算復雜性。在本文中,我們提出了 CM-UNet,包括用于提取局部圖像特征的基于 CNN 的編碼器和用于聚合和集成全局信息的基于 Mamba 的解碼器,促進遙感圖像的高效語義分割。具體來說,引入 CSMamba 塊來構建核心分割解碼器,該解碼器采用通道和空間注意力作為 vanilla Mamba 的門激活條件,以增強特征交互和全局局部信息融合。此外,為了進一步細化 CNN 編碼器的輸出特征,采用多尺度注意力聚合(MSAA)模塊來合并不同尺度的特征。 通過集成CSMamba模塊和MSAA模塊,CM-UNet有效捕獲大規模遙感圖像的長距離依賴關系和多尺度全局上下文信息。 在三個基準上獲得的實驗結果表明,所提出的 CM-UNet 在各種性能指標上都優于現有方法。
Introduction
在本文中,我們提出了 CM-UNet,一種用于 RS(遙感) 圖像語義分割的新穎框架。 CM-UNet 利用 Mamba 架構聚合來自 CNN 編碼器的多尺度信息。 它由一個 U 形網絡和一個解碼器組成,其中的 CNN 編碼器提取多尺度文本信息,解碼器采用設計的 CSMamba 塊,可實現高效的語義信息聚合。 CSMamba 模塊利用 Mamba 模塊以線性時間復雜度捕獲長程依賴性,并采用通道和空間注意力進行特征選擇。CSMamba 塊作為之前的自注意力轉換器塊的替代方案,提高了 RS 語義分割的效率。 此外,引入了多尺度注意力聚合(MSAA)模塊來集成來自 CNN 編碼器不同級別的特征,通過跳過連接幫助 CSMamba 解碼器。 最后,CM-UNet 在各個解碼器級別結合了多輸出監督,以逐步生成 RS 圖像的語義分割。 貢獻總結如下:
1)我們提出了一個名為 CM-UNet 的基于 mamba 的框架,以有效地集成局部全局信息以進行 RS 圖像語義分割。
2)我們設計了一個 CSMamba 塊,將通道和空間注意力信息包含到 mamba 塊中以提取全局上下文信息。 此外,我們采用多尺度注意力聚合模塊來輔助跳躍連接和多輸出損失來逐步監督語義分割。
3)在三個著名的公開RS數據集(ISPRS Potsdam、ISPRS Vaihingen和LoveDA)上進行的廣泛實驗表明了所提出的CM-UNet的優越性。
Methodology
我們的 CM-UNet 框架如圖 2 (a) 所示,包含三個核心組件:基于 CNN 的編碼器、MSAA 模塊和基于 CSMamba 的解碼器。 編碼器采用 ResNet 提取多級特征,而 MSAA 模塊融合這些特征,取代 UNet 的普通跳過連接并增強解碼器的能力。 在 CSMamba 解碼器中,CSMamba 塊的組裝聚合了本地文本特征以建立全面的語義理解。
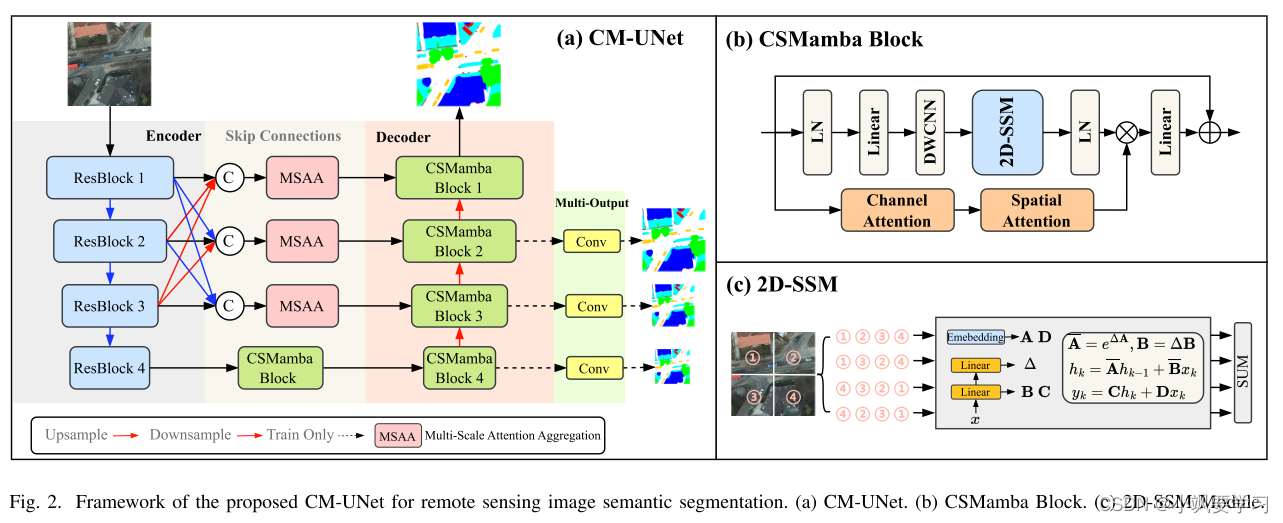
A、CSMamba Block
受 Mamba 在線性復雜度遠程建模方面取得成功的激勵,我們將視覺狀態空間模塊引入 RS 語義分割領域。 按照[10],輸入特征 X ∈ R H × W × C X\in\mathbb{R}^{H\times W\times C} X∈RH×W×C 將經過兩個并行分支。在第一個分支中,特征通道通過線性層擴展至 λC,其中 λ 是預定義的通道擴展因子,隨后是深度卷積、SiLU 激活函數以及 2D-SSM 層和 Layernorm。在第二個分支中,特征通過通道和空間注意力(CS)以及隨后的 SiLU 激活函數進行集成。之后,將兩個分支的特征與 Hadamard product(哈達瑪積)進行聚合。 最后,將通道號投影回 C 以生成與輸入形狀相同的輸出 Xout:
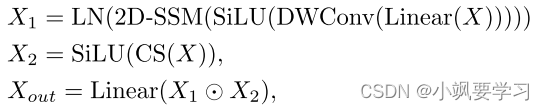
其中DWConv表示深度卷積,CS表示通道和空間注意模塊,2D-SSM表示2D選擇性掃描模塊,⊙表示Hadamard積。原始的 Mamba 模型通過順序選擇性掃描處理一維數據,這適合 NLP 任務,但對圖像等非因果數據形式提出了挑戰。繼[10]之后,我們結合了 2D 選擇性掃描模塊(2D-SSM)來進行圖像語義分割。 如圖2?所示,2D-SSM將圖像特征展平為一維序列,并在四個方向上掃描:左上到右下、右下到左上、右上到左下。 ,以及從左下角到右上角。 這種方法通過選擇性狀態空間模型捕獲每個方向的遠程依賴性。 然后合并方向序列以恢復二維結構。
Multi-Scale Attention Aggregation多尺度注意力聚合
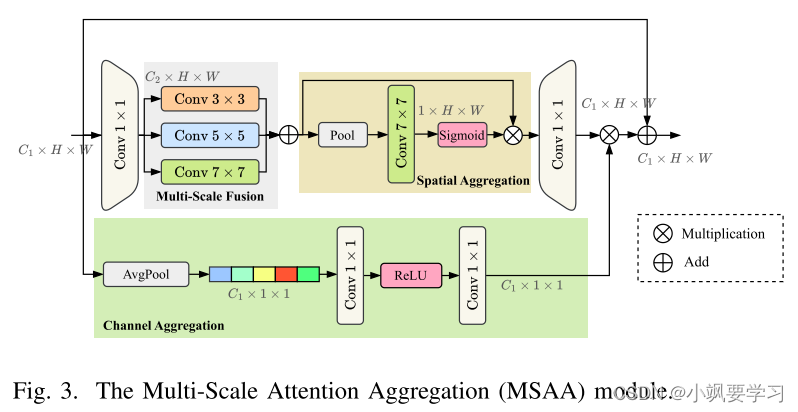
圖 3 描述了用于細化 RS 圖像特征的多尺度注意力聚合 (MSAA) 模塊。 ResNet 編碼器階段 F1、F2 和 F3 的輸出被連接為 F ^ i = C o n c a t ( F i , F i ? 1 , F i + 1 ) \hat{F}_{i}=\mathrm{Concat}(F_{i},F_{i-1},F_{i+1}) F^i?=Concat(Fi?,Fi?1?,Fi+1?)。組合特征 F ^ ∈ R C 1 × H × W \hat{F} \in \mathcal{R}^{C_{1}\times H\times W} F^∈RC1?×H×W被饋送到 MSAA 中進行細化。 在 MSAA 中,雙路徑(空間路徑和通道路徑)用于特征聚合。 空間細化從通道投影開始,通過 1×1 卷積將通道 C1 減少到 C2,其中 C 2 = C 1 α C_{2}=\frac{C_{1}}{\alpha} C2?=αC1??。多尺度融合涉及對不同內核大小(例如 3 × 3、5 × 5、7 × 7)的卷積進行求和。隨后,使用均值和最大池化來聚合空間特征,然后進行 7 × 7 卷積和與 sigmoid 激活的特征圖。
同時,通道聚合使用全局平均池化將維度降低至 C1 × 1 × 1,然后通過 1 × 1 卷積和 ReLU 激活來生成通道注意力圖。 該圖經過擴展以匹配輸入的尺寸,并與空間細化的圖相結合。 因此,MSAA 增強了后續網絡層的空間和通道特征。 通過合并 MSAA 模塊,生成的特征圖豐富了精細的空間和通道信息。
Multi-Output Supervision (多輸出監督)
為了有效地監督解碼器逐步生成 RS 圖像的語義分割圖,我們的 CM-UNet 架構在每個 CSMamba 塊上結合了中間監督。 這確保了網絡的每個階段都對最終的分割結果做出貢獻,從而促進更精細和準確的輸出。 對于第 i 個 CSMamba 塊的中間輸出是
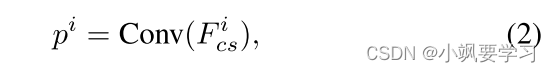
其中 Fcs 是第 i 個 CSMamba 塊的特征。 Conv 模塊用于將特征映射到輸出 C 通道類別預測圖。 總體而言,網絡是使用標準交叉熵損失和 Dice 損失的組合進行訓練的。
Conclusion
在本文中,我們介紹了 CM-UNet,這是一個利用最新 Mamba 架構進行 RS 語義分割的高效框架。 我們的設計通過采用新穎的 UNet 形結構來解決大規模 RS 圖像中的顯著目標變化。 編碼器利用 ResNet 提取文本信息,而解碼器利用 CSMamba 塊有效捕獲全局遠程依賴關系。 此外,我們還集成了多尺度注意力聚合(MSAA)模塊和多輸出增強功能,以進一步支持多尺度特征學習。 CM-UNet 已在三個 RS 語義分割數據集上進行了驗證,實驗結果證明了我們方法的優越性。












)



)
ObjectAnimator的使用)

