???1 項目介紹
1.1 研究目的和意義
隨著大數據時代的到來,電影產業積累了海量的用戶評論數據,這些數據中蘊含著觀眾的情感傾向與偏好信息,為電影推薦和市場策略制定提供了寶貴資源。然而,如何高效地從這浩瀚的數據海洋中提煉出有價值的情感洞察成為一大挑戰。針對這一背景,開發一個高效的大數據電影評論情感分析系統顯得尤為重要。
本項目旨在設計并實現一個基于LSTM(長短時記憶網絡)算法的電影評論情感分析系統,利用Python編程語言進行開發,并結合爬蟲技術自動收集在線電影評論數據。系統以Django框架構建后端服務,旨在為電影行業提供一個強大的工具,能夠實時分析觀眾情感反饋,輔助決策制定。
通過編寫定制化的網絡爬蟲,系統從多個主流電影評論平臺上自動抓取大量評論數據。隨后,數據經過預處理,包括去噪、分詞和向量化,為深度學習模型的訓練做好準備。核心部分應用LSTM算法構建情感分類模型,該模型能夠學習評論文本的時間序列特性,有效捕獲語境中的情感變化。通過大量的訓練迭代,模型在驗證集上展現出高精度的情感分類性能。系統前端采用響應式設計,基于Django構建的API接口實現了與用戶友好的交互界面,允許用戶查詢特定電影的情感分析報告。
總之,該系統不僅能準確區分正面與負面評論,還能在一定程度上識別出評論中的微妙情感傾向,如輕微的不滿或高度的贊賞。系統在實際應用中顯著提高了情感分析的效率和準確性,為電影制作方、發行商提供了即時的情感趨勢洞察,幫助他們更好地理解觀眾喜好,指導內容創作與營銷策略。此外,項目的成功實施證明了結合LSTM的深度學習方法在處理非結構化文本數據,特別是在情感分析領域的強大潛力,為進一步拓展到其他領域的文本分析應用奠定了堅實的基礎。
1.2 系統技術棧
Python
MySQL
LSTM
Django
Scrapy
1.3 系統角色
管理員
用戶
1.4 算法描述
LSTM(Long Short-Term Memory)作為一種深度學習技術,在應對序列數據分析任務上展現出卓越效能。它巧妙設計了門控機制及記憶單元,有效緩解了標準循環神經網絡(RNN)面臨的梯度消失和梯度爆炸難題,進而強化了對序列數據長期依賴性的捕獲能力。
LSTM單元的創新之處,在于其精細的內部結構,包括輸入門、遺忘門和輸出門。這些門機制如同智能閥門,精心篩選信息流:輸入門判斷哪些新信息值得存入記憶;遺忘門則分辨并拋棄不再重要的舊信息;輸出門調控記憶單元的內容如何影響下一步的輸出,確保了信息的有效管理和利用。
記憶單元作為LSTM的核心組件,承擔著存儲序列數據長期狀態的重任,使得模型能在適當時候召回這些重要信息,這對于處理如自然語言、語音分析及時間序列預測等時序相關任務至關重要。
LSTM算法的強項還體現在其深度的特征學習能力,能從序列數據中抽取出復雜的模式和規律,為預測和分類任務提供堅實基礎。這一點在推薦系統設計中尤為重要,比如電影推薦場景下,LSTM能夠依據用戶過去的觀看記錄,精妙預測未來偏好,推動個性化推薦策略的實施。
LSTM的靈活性不僅限于此,它還能與其他深度學習模型集成,例如與卷積神經網絡(CNN)的聯姻,形成復合模型,以增強處理跨模態數據(文字、圖像、聲音等)的能力,進一步優化推薦系統的表現力。
實施LSTM算法時,科研人員普遍采用Python編程語言,配合TensorFlow或PyTorch等深度學習框架,這些工具的高效率與易用性大大簡化了模型構建與訓練流程。同時,結合前端技術如Vue和后端框架如Django,可將LSTM模型無縫融入實際應用,為用戶帶來流暢的互動體驗和智能化推薦服務。
總之,LSTM算法憑借其獨特的結構設計、優異的特征學習性能以及廣泛的適用性和擴展性,在序列數據分析,特別是在電影評論情感分析系統中,展現了提升推薦精準度與用戶體驗的潛力,對促進影視行業的個性化服務發展具有積極意義。
1.5 系統功能框架圖

1.6 設計思路
數據收集:廣泛搜集社交網絡、聊天平臺及社交媒體上的內容,確保數據集豐富多樣,具有廣泛代表性。
數據標注:基于大數據架構的評論情感分析,我們精準標注每位用戶的在社交平臺上的評論數據,明確平臺的類別與評論關系,確保標注的可靠性和準確性。無論是圖片還是文字。
數據增強:通過文本的轉換、重組和替換來豐富數據多樣性。針對評論情感分析,這樣的文字處理技術顯得尤為重要,因為捕捉和理解文本中的情感色彩,為情感分析提供更為全面和多樣的訓練數據。通過不斷學習和優化,模型將能夠更準確地識別和分析評論中的情感傾向,為相關應用提供有力的支持。
架構選擇:選擇合適的CNN架構作為基礎,如使用已經在文字識別任務中表現良好的ResNet、VGG或自定義的CNN結構。
特征提取:設計能夠有效提取漢字特征的卷積層和池化層,捕捉漢字的結構和筆畫信息。
分類器設計:在CNN模型后端設計分類器,用于將提取的特征映射到具體的漢字類別。
訓練策略:采用合適的損失函數和優化算法,如交叉熵損失和Adam優化器,進行模型訓練。
超參數調整:通過實驗調整學習率、批大小等超參數,找到最佳訓練配置。
正則化和防止過擬合:應用Dropout、權重衰減等技術防止模型過擬合,提高模型的泛化能力。
性能評估:使用精確度、召回率、F1分數等指標評估模型性能,確保模型具有高準確率和可靠性。
交叉驗證:采用交叉驗證方法評估模型在不同數據子集上的表現,確保模型的穩定性和泛化能力。
2? 系統功能實現截圖
2.1 管理員功能模塊實現
2.1.1 登錄功能
2.1.2 電影信息

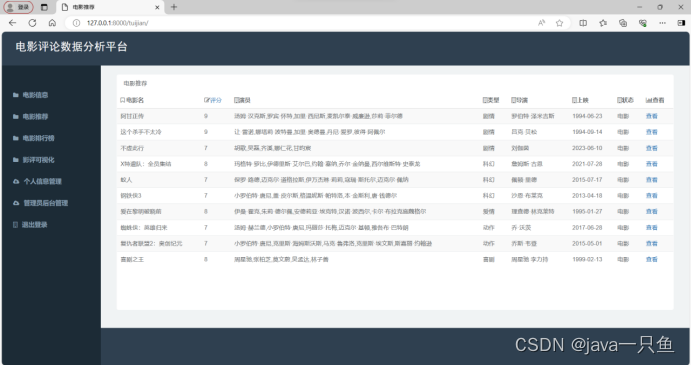
2.1.3 電影推薦
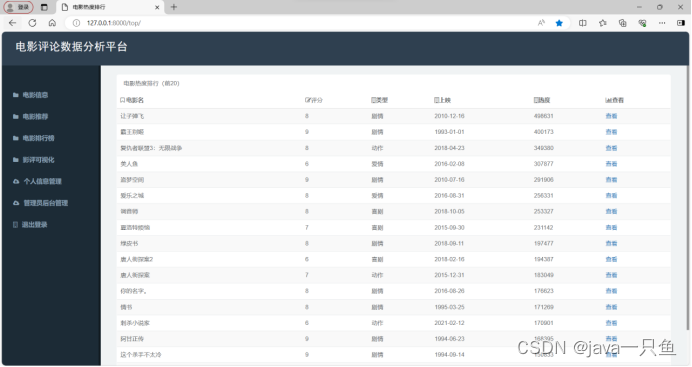
2.1.4 電影排行版


synchronized原理、JUC類——深度理解多線程編程)


)

)











