目錄
簡介
具體操作
1. 引入驅動包
1)下載驅動包
2)引入驅動包到項目中
2. 編寫代碼
1)創建數據源
2)建立連接
3)構造 SQL 語句
4)執行 SQL 語句
5)釋放資源
總結
簡介
JDBC 就是使用 Java 代碼來操作數據庫。市面上有很多種數據庫,其中每種數據庫都有著自己的一套 API,Java 為了方便,統一所有數據庫都來實現 JDBC 這套API,使得所有類型的數據庫在Java 中都可以按照 JDBC 這套 API 提供的方式來操作。
JDBC 是一套 API,而不同的數據庫又有自己的一套 API,因此使用 JDBC 操作數據庫的時候,就需要進行 API 之間的轉化,數據庫廠商就提供了專門的代碼來進行轉化——數據庫驅動包( 作用類似于翻譯官 )

具體操作
此處使用 MySQL 作為示例:
1. 引入驅動包
1)下載驅動包
首先,我們需要下載 MySQL 的驅動包。可以從多種渠道,例如官方網站,Github( 如果是一個開源項目 ),其中最方便的就是在 Maven 中央倉庫中進行下載:https://mvnrepository.com/
在搜素框中搜索需要的數據庫,然后選擇所需的版本,注意大版本需要和數據庫服務器版本保持一致,小版本無所謂( 小數點后的版本號 )。然后點擊類似下圖中的位置進行下載:

2)引入驅動包到項目中
下載完成之后,需要引入到我們現有的項目中( 下述是以一個最普通的項目來作為示例 ):
創建一個專門存放依賴包的目錄,一般命名為 lib,將 jar 包放到該目錄下,如果點擊下圖中的選項,使該目錄下的 jar 包能夠被正常識別:
2. 編寫代碼
1)創建數據源
數據源指明了我們的數據庫服務器地址,具體代碼如下:
DataSource dataSource = new MysqlDataSource();
((MysqlDataSource)dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/testTable?characterEncoding=utf8&useSSL=false");
((MysqlDataSource)dataSource).setUser("root");
((MysqlDataSource)dataSource).setPassword("root");DataSource 是 JDBC 提供的一個 interface,MysqlDataSource 是 MySQL 驅動包提供的類,該類實現了 DataSource 這個 interface。上述調用的 setUrl、setUser、setPassword 方法都是MysqlDataSource 這個子類的方法,因此調用之前需要進行向下轉型。
上述轉型的寫法是推薦寫法,雖然下述寫法是更方便的寫法,但是轉型的目的是希望不要讓MysqlDataSource 這個類擴散到其他代碼,其他代碼使用 datasource 對象時,仍然是一個JDBC 提供的 DataSource 類的對象而不是一個 MySQL 驅動包提供的 MysqlDataSource 類的對象,降低 MySQL 驅動包和項目代碼的耦合程度,后續方便更換數據庫。
MysqlDataSource dataSource = new MysqlDataSource();
dataSource.setUrl("jdbc:mysql://127.0.0.1:3306/testTable?characterEncoding=utf8&useSSL=false");
dataSource.setUser("root");
dataSource.setPassword("root");
上述的 setURL 中的參數是一個固定模板,其中每個部分的具體含義如下:
- jdbc:mysql:表明當前這個 URL 的具體用途,是給 JDBC 的 MySQL 進行使用的;
- 127.0.0.1:當前數據源指向的數據庫服務器的IP地址;
- 3306:當前數據源指向的數據庫服務器的上的數據庫應用程序所占據的端口號;
- testTable:數據庫名字;
- characterEncoding=utf8:統一字符集為utf8,避免使用中文等其他語言時出現亂碼;
- useSSL=false:設置數據庫服務器和客戶端之間的通信是否進行加密。
2)建立連接
上述只是創建了一個數據源,真正連上數據庫還需要創建一個和數據庫服務器的連接:
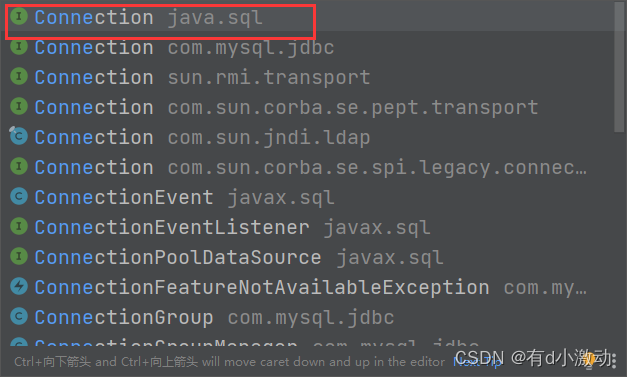
Connection connection = dataSource.getConnection();注意上述的Connection類需要導入的是JDBC下的類:
3)構造 SQL 語句
假設現在有一個表中有兩列:id int,name varchar(20)
String sql = "insert into student values(1, '張三')";
PreparedStatement statement = connection.prepareStatement(sql);我們在代碼中創建的SQL語句本身,是 String 類型的,但是 JDBC 并不認識字符串類型的 SQL,因此 JDBC 提供了 Statement(語句)對象,可以把 String 轉換成 Statement 再發給服務器執行。但是,一般會使用 PreparedStatement(預處理的語句)對象來代替 Statement。
這二者的區別是:
- Statement 是把 SQL 直接發給數據庫服務器,數據庫服務器來負責解析 SQL;
- PreparedStatement 會先在客戶端這邊初步解析一下 SQL( 驗證語法格式是否符合要求啥的 ),此時服務器就不用做這些檢查了,從而降低服務器的負擔。
除了上述這種寫死的語句,也可以動態構造 SQL 語句:
注意下述這種寫法:
String sql = "insert into student values(" + id + ", '" + name + "')";
PreparedStatement statement = connection.prepareStatement(sql);雖然這種寫法也可以,但是存在問題:可讀性低,代碼混亂和存在SQL注入風險。
因此更推薦下述寫法:
String sql = "insert into student values(?, ?)";
PreparedStatement statement = connection.prepareStatement(sql);
statement.setInt(1, id);
statement.setString(2, name);具體步驟:
- 使用" ? "來作為參數的占位符
- 使用特定的 setXXX 方法,來設置占位符所需要的變量。注意此處的的占位符順序是從 1 開始的。執行過程中,setXXX 方法會對參數進行嚴格校驗,避免了 SQL 注入問題。
4)執行 SQL 語句
執行 SQL 語句時,有兩個方法可以選擇:
executeQuery:用于執行寫操作,用于執行查詢語句。其中返回值是 ResultSet,是一個臨時表格。當我們拿到結果集的時候,就需要遍歷這個臨時表格。
ResultSet resultSet = statement.executeQuery();
while (resultSet.next()) {int id = resultSet.getInt("id");String name = resultSet.getString("name");
}使用 resultSet.next() 方法效果如下:
1)存在一個光標,初始位置指向臨時表的第一行記錄的前面;
2)每次執行 next 方法,光標都會往下走,如果存在記錄返回 true,否則返回 false。如果存在記錄則可以拿到該行記錄中的每一列,具體是使用該列的數據類型對應的 getXXX 方法,傳入列名來獲取。
executeUpdate:用于執行寫操作,用于執行增加、刪除、修改語句。其中返回值就是影響的行數。
int n = statement.executeUpdate();5)釋放資源
創建的語句對象和連接對象等,都會持有一些計算機的 硬件 / 軟件 上的資源,這些資源不用了就需要及時釋放。注意關閉順序:先創建的后關閉。
resultset.close();
statement.close();
connection.close();總結
上述就是使用 JDBC 的全部流程,整體過程相對比較繁瑣,因此大佬們針對 JDBC 操作進行進一步封裝,得到了一些針對數據庫操作的框架,統稱為 ORM,例如:Mybatis、Mybatis-plus。但是這些框架的背后原理還是使用 JDBC。








- 需要自定義著色器)




)




Sync.Map)
- 邏輯回歸)