概述
隨著數字科技的飛速發展和信息量的爆炸性增長,搜索引擎已成為我們獲取信息的首選途徑之一,典型的代表廠商如 Google。然而,隨著用戶需求的不斷演變,傳統的搜索技術已經無法滿足人們對信息的實時性、個性化和多樣性的需求。
在企業內部,這種需求更加顯著。隨著企業數字化轉型的持續深化,非結構化數據正日益成為各類組織數據增長的主要來源,也是數據體系中至關重要的組成部分,蘊含著巨大的價值。如何高效地存儲和利用非結構化數據的重要性也日益凸顯。企業需要更高效地管理和檢索內部的海量數據,以支持業務決策和運營需求。

據 IDC 數據預計,到 2025 年,80%的數據將是非結構化數據;而根據 Gartner 的數據顯示,從 2019 年到 2024 年,非結構化數據容量預計將增加兩倍。然而,目前非結構化數據面臨著表現形式多樣、管理復雜性高、價值挖掘難度大等諸多挑戰。傳統的數據庫系統往往無法滿足企業對實時性和多樣性的搜索需求,為了解決這些挑戰,以自動分詞、倒排索引、相關度計算、向量檢索引擎等技術為核心構建的搜索型數據庫應運而生。這些數據庫自上世紀 90 年代誕生以來不斷發展演進,正在成為數據庫領域中不可或缺的一個重要分支。
什么是搜索型數據庫?
搜索型數據庫早期又稱全文數據庫,或者企業搜索引擎,是一種專門用于存儲和管理大規模文本數據,并支持高效的文本搜索和信息檢索的數據庫系統,不過隨著技術不斷發展和應用場景日益豐富,目前搜索型數據庫不僅僅可以處理長文本數據,也可以處理常見的數值、日期等結構化數據,IP、地理位置信息、圖片、音視頻等非結構化數據,搜索型數據庫的應用范疇不斷拓展,正在由支撐業務系統檢索加速、IT 運維可觀測性、聚合查詢分析等向多場景、多模態數據搜索方向發展。

典型的搜索數據庫一般具有以下特點:
- 靈活的索引能力:搜索數據庫能夠處理多種類型的數據,包括文本、圖像、音頻、視頻等非結構化數據。它們采用自動分詞、倒排索引等技術,能夠高效地處理不同格式和類型的數據,提供靈活的搜索和檢索功能。
- 高效的查詢性能:搜索數據庫具有高效的查詢處理能力,能夠快速索引和檢索大規模的數據。借助優化的索引結構和查詢算法,搜索數據庫能夠在短時間內準確地返回與查詢相關的結果,提高用戶的搜索效率,常用于解決關系型數據庫的高并發檢索需求。
- 支持復雜的搜索功能:搜索數據庫提供多樣化的搜索功能,包括全文檢索、模糊搜索、精確搜索、范圍搜索、向量搜索、地理信息檢索等。用戶可以根據不同的需求和場景,靈活地選擇和組合不同的搜索功能,以獲取符合期望的搜索結果。
- 高性能和可擴展性:搜索數據庫具有高性能和可擴展性的特點,能夠處理大規模數據和高并發訪問。它們采用分布式架構和并行計算技術,實現了水平擴展,能夠滿足不斷增長的數據量和用戶訪問量的需求。
綜上所述,搜索數據庫具有處理非結構化數據、實時搜索和更新、多樣化的搜索功能、個性化推薦和智能搜索、高性能和可擴展性、全面的搜索結果展示等特點,是處理大規模數據和提供高效搜索服務的重要工具。
搜索型數據庫的應用場景

搜索型數據庫在各行各業都有廣泛的應用,以下是一些典型的應用場景:
- 零售和電商:在零售和電商行業,搜索型數據庫被廣泛應用于產品搜索和推薦系統中。通過搜索功能,顧客可以輕松查找所需商品,而個性化推薦系統則可以根據用戶的搜索歷史和行為習慣推薦相關的產品,提高購物體驗和交易轉化率。
- 醫療保健:在醫療保健行業,搜索型數據庫被用于醫學文獻檢索、疾病診斷和藥物搜索等方面。醫生和研究人員可以利用搜索功能找到相關的醫學文獻和研究成果,幫助診斷疾病和制定治療方案。
- 金融服務:在金融服務行業,搜索型數據庫被用于金融數據檢索、市場分析和投資決策等方面。投資者可以通過搜索功能查找相關的金融數據和市場資訊,幫助他們做出更加準確的投資決策。
- 制造業:在制造業中,搜索型數據庫被用于生產過程監控、質量控制和故障診斷等方面。工程師可以利用搜索功能查找相關的生產數據和技術資料,幫助他們解決生產中的問題和挑戰。
- 媒體和娛樂:在媒體和娛樂行業,搜索型數據庫被用于內容檢索、版權管理和用戶推薦等方面。用戶可以通過搜索功能查找感興趣的新聞、音樂和視頻等內容,而個性化推薦系統則可以根據用戶的搜索歷史和偏好推薦相關的內容。
- 教育和培訓:在教育和培訓行業,搜索型數據庫被用于學習資源檢索、課程管理和學習分析等方面。學生和教師可以利用搜索功能查找相關的學習資源和課程內容,而學習分析系統則可以分析學生的搜索行為和學習表現,為教學提供參考和支持。
- IT 運維可觀測性:通過搜索型數據庫,可以實時監控系統的運行狀況、性能指標和日志數據,幫助運維團隊及時發現和解決系統故障、性能問題和異常情況,確保系統的穩定運行。
- 安全監測和威脅檢測:利用搜索型數據庫對系統的安全日志進行審計和監控,監測用戶的訪問行為和系統操作,及時發現異常行為和安全事件。同時,搜索型數據庫還可以與威脅情報數據集成,對內部日志數據進行關聯分析,快速識別并應對各種安全威脅和攻擊行為,保障系統和數據的安全。
綜上所述,搜索型數據庫在各行各業都發揮著重要作用,數據規模從 GB 到 PB 不等,體現在生活中的方方面面,為用戶提供了高效、準確和個性化的信息搜索和檢索服務,推動了各行業的發展和進步。隨著搜索技術的不斷創新和發展,搜索型數據庫在各行業中的應用將會越來越廣泛,并持續為用戶帶來更加便捷和智能的搜索體驗。
搜索型數據庫的發展歷程
搜索型數據庫的發展歷程可以概括如下四個階段:
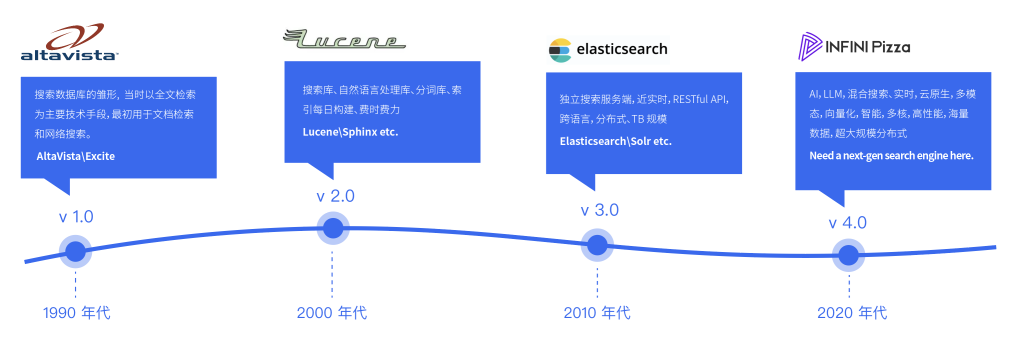
- 起步階段(1990 年代):搜索數據庫的雛形開始于上世紀 90 年代,當時以全文檢索為主要技術手段,最初用于文檔檢索和網絡搜索。典型代表包括 AltaVista、Excite 等。
- 技術突破(2000 年代):隨著互聯網的快速發展,搜索數據庫開始應用于更多領域,如電子商務、社交網絡等。Lucene、Sphinx 等開源搜索引擎的出現推動了搜索技術的進步。
- 商業化發展(2010 年代):搜索數據庫進入商業化階段,以 Elasticsearch 等為代表的商業搜索引擎嶄露頭角。企業開始大規模應用搜索數據庫來管理和檢索大量數據。
- 智能化轉型(2020 年代):隨著人工智能技術的發展,搜索數據庫逐漸向智能化轉型,開始引入機器學習、自然語言處理等技術,提供個性化推薦和智能搜索服務。同時,搜索數據庫也在更多領域得到應用,如醫療保健、金融服務等。
綜上所述,搜索數據庫經歷了從起步階段到技術突破、商業化發展再到智能化轉型的發展歷程,表明了其在信息檢索領域的重要性和不斷演進的趨勢,不并斷推動著搜索技術的進步和應用范圍的擴展。隨著人工智能技術的不斷成熟,搜索數據庫將會在智能化、個性化等方面取得更大的進步,為用戶提供更加優質的搜索體驗。
搜索型數據庫的發展情況
搜索型數據庫市場上已經有不少成熟的產品和廠商,但是總的來說,搜索型數據庫的界限范圍有點模糊,當然其他數據庫也有同樣的問題,有很多數據庫既是文檔數據庫,又是多模態數據庫,還是向量數據庫等等,而常見的搜索型數據庫主要誕生于:
-
由搜索引擎內核庫發展而來的搜索數據庫,如 Elasticsearch
-
由其他數據庫擴展而來的搜索數據庫,如 Postgres Full-Text Search
-
從零開始整體設計的搜索數據庫:如 INFINI Pizza
通過流行的 DB-Engines 的搜索引擎排行榜,可以初探國外主流的搜索型數據庫的流行趨勢,如下圖:

可以看到 Elastic 公司的 Elasticsearch 還是依舊保持強悍,自從 Elasticsearch 十多年前掀翻了 Splunk 的桌子,硬生生的在日志領域殺出一條新路,隨后大殺四方,碾壓整個搜索行業,霸榜至今。Elastic 商業化增長穩健,2023 年收入超過 10 億美金。

OpenSearch 是由 AWS 發起的 Elasticsearch 開源分支,起因是由于 Elastic 針對云廠商采取的協議變更為 Elastic+SSPL,OpenSearch 基于 Apache 2.0 協議的 Elasticsearch 7.10 版本衍生而來,目前也具備了一定的用戶基礎。

Splunk 是一款用于搜索、監控和分析大規模機器生成的數據的軟件平臺,主要用于日志和安全分析領域,屬于商業閉源產品。2023 年中被思科(Cisco) 以 230 億美元現金收購,瞬間刷爆朋友圈。另外有意思的是,前四名除了 Splunk,底層都是 Lucene 內核。

MarkLogic 成立于 2001 年,自我定位是一個 NoSQL 多模態數據庫廠商,也是商業閉源軟件,生態成熟但是系統過于復雜,學習曲線較陡, 2023 年初被 Progress Software 以 3.55 億美元收購算是一個比較好的結局。

當然了,除了榜上的這些產品,還有很多優秀的挑戰者正摩拳擦掌,躍躍欲試。如下面的這些項目:
vespa、Rockset、Doris,Clickhouse、quickwit、Pinot、SingleStore、qdrant、milvus、algolia、meilisearch、typesense、Manticore Search 等等。這些項目不一定都是自己定位是搜索型數據庫,有側重在 AI 領域的,有側重在實時分析領域的等等,可謂各有千秋,不過都具備一定的搜索和分析能力,不出意外,基本上每家都要號稱吊打 Elasticsearch 一番。
國內搜索型數據庫的發展情況
搜索型數據庫已經成為企業事實上的重要基礎設施,而國內搜索型數據庫的發展近些年也是開始得到重視,2023 年初,由中國信通院云計算與大數據研究所牽頭,依托中國通信標準化協會大數據技術標準推進委員會,聯合拓爾思、極限科技、星環科技等 30 余家企業編制的《搜索型數據庫技術要求》正式出爐,該標準已成為行業內搜索型數據庫技術選型和產品開發的風向標,極限科技的 INFINI Easysearch 率先通過了該標準。
墨天輪社區也開辟了搜索型數據庫的排行榜,共有 6 家企業的產品上榜:
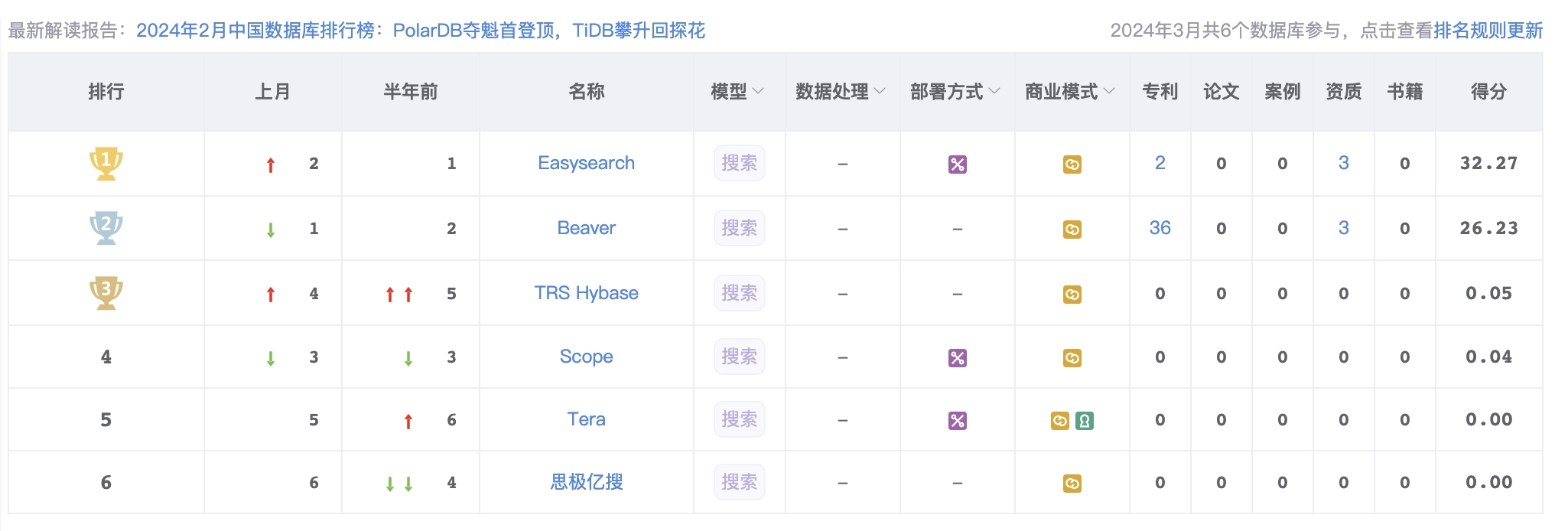
國內搜索型數據庫的市場還在起步階段,廠商和可選的產品也還比較少,不過隨著市場的成熟,相信未來將迎來一波高速的發展。
搜索型數據庫的趨勢前瞻

技術在演變,場景在演變,數據也在演變,搜索數據庫領域的發展也呈現出多個顯著的趨勢,這些趨勢將進一步推動搜索技術的演進和應用范圍的擴展。筆者觀測到的主要的發展趨勢包括以下方向供參考:
1. 趨勢一:實時搜索與分析
-
實時搜索是搜索數據庫領域的一個重要發展趨勢,業務應用都在朝實時方向演進,用戶對信息的即時性需求不斷增加,要求搜索結果能夠及時反映最新的數據和內容。
-
實時搜索技術通過實時索引和實時更新機制,能夠實現快速的數據檢索和更新,提供與時俱進的搜索結果,滿足用戶對信息的即時性需求。
-
目前以 Lucene 為內核的搜索型數據庫基本上都只能做到 NRT(近實時)搜索,并且頻繁更新帶來的挑戰和資源的浪費比較高,如果能做到更高效的實時性,可以大大提升用戶的搜索體驗和實時決策能力。
2. 趨勢二:多模態混合搜索
-
多模態搜索是指在搜索過程中同時考慮多種信息形式,如文本、圖像、視頻等,以提高搜索結果的準確性和全面性。
-
這種技術能夠通過分析和理解多種信息形式之間的關聯性,為用戶提供更加全面、豐富的搜索結果,適用于需要綜合不同媒體形式的搜索場景。
-
現實世界的數據越來越復雜化,非結構化數據的利用的場景也越來越多,多模態可以為業務提供更加靈活的分析和探索能力,混合搜索的能力非常具有吸引力。
3. 趨勢三:AI 智能語義搜索
-
大模型、AI 智能搜索技術的探索可謂是一日千里,通過利用人工智能技術來實現搜索過程中的智能化、語義化和個性化,結合自然語言處理、機器學習等技術分析用戶意圖,提供更加智能、個性化的搜索服務。
-
隨著大模型的興起,搜索數據庫開始采用像 RAG(Retriever-Reader for Generative Question Answering)這樣的大型預訓練模型來提升搜索的效果。RAG 模型結合了檢索器和閱讀器的功能,能夠實現更加準確和全面的搜索結果,為用戶提供更加智能和個性化的搜索服務。
-
搜索型數據庫可謂是 AI 落地最好的是試驗田,Elasticsearch 通過擁抱 AI 和大模型,目前股價又重回巔峰,可喜可賀。
4. 趨勢四:云原生、存算分離、Serverless
-
隨著云計算技術的發展,搜索數據庫正逐漸向云原生架構轉變。云原生搜索數據庫利用容器化、微服務架構等技術,實現了更高的靈活性、可擴展性和容錯性,為企業提供了更加穩定和高效的搜索服務,并且成本更低,更加彈性。
-
存算分離是搜索數據庫發展的另一重要趨勢。通過將存儲與計算分離,搜索數據庫可以更好地適應數據存儲和計算需求的變化,提高系統的性能和效率。存算分離技術使得搜索數據庫能夠實現更高的并發訪問和更快的數據處理速度,為用戶提供更加流暢和穩定的搜索體驗。
-
Serverless 提供開箱即用的體驗,成本更低,使用更加靈活,也是目前很多搜索服務提供商正在積極探索的方向。
5. 趨勢五:增強現實搜索
- 隨著增強現實技術的發展,尤其是 Apple 發布的頭戴式 Vision Pro,一部革命性的空間運算設備,將數位內容無縫融入實體世界,而搜索技術也將逐漸與增強現實相結合,為用戶提供更加直觀和沉浸式的搜索體驗。增強現實搜索能夠將搜索結果與現實世界相結合,結合 AI 技術為用戶提供更加個性化和便捷的搜索服務,這是一個全新的領域,也意味著巨大的機會。
6. 趨勢六:現代硬件的高效利用
-
現代硬件及軟件運行環境已發生翻天覆地的變化, 片上計算,邊緣計算,FPGA,DPU,GPU,一臺設備幾百核上 TB 內存已經成為現實,可運行之上的軟件卻還是停留在幾十年前的架構。 如 Elasticsearch 其核心 Lucene(及類似實現) 是在 1997 建立的,距今已有 27 年了,雖然也在與時俱進,但是部分架構和設計理念已不具備先進性。
-
在現代的硬件上采用更先進的算法,更新的數據結構、更新的設計理論,利用最新的 CPU 指令集,向量化,批處理,充分發揮多核、大內存和 SSD 的優勢,從而達到更高的效率,更低的成本,去解決之前不可能實現的問題,大有可為,也是下一代引擎需要關注的方向。

隨著各類數據庫功能的邊界越來越模糊,應用場景高度交叉重疊,市場競爭也變得白熱化,不過筆者認為垂直領域的搜索型數據庫機會還是很大,而想做大而全的數據庫產品已經沒有太多的市場生存空間,一定要在垂直領域有特別專注的地方,我們 INFINI Labs 正在基于 Rust 研發的下一代搜索引擎 INFINI Pizza,就側重于面向終端用戶場景,解決海量數據更新情況下,同時滿足高并發和低延遲的核心業務實時檢索需求。
總結
綜上所述,搜索數據庫領域正處于快速發展的階段。隨著互聯網數據量的不斷增長和用戶需求的不斷變化,搜索數據庫技術將不斷創新和進步,以滿足用戶對信息獲取的更加即時、個性化和多樣化的需求。未來,隨著人工智能技術的進一步發展和應用,搜索數據庫將會變得更加智能化、普及化和多樣化,為用戶提供更加高效、準確和個性化的搜索服務,推動互聯網信息的更加便捷獲取和利用。

2024真題目錄(全、新、準))








)
)







)