0 前言
🔥 優質競賽項目系列,今天要分享的是
🚩 python的搜索引擎系統設計與實現
🥇學長這里給一個題目綜合評分(每項滿分5分)
- 難度系數:3分
- 工作量:5分
- 創新點:3分
該項目較為新穎,適合作為競賽課題方向,學長非常推薦!
🧿 更多資料, 項目分享:
https://gitee.com/dancheng-senior/postgraduate
1 課題簡介
隨著互聯網和寬帶上網的普及, 搜索引擎在中國異軍突起, 并日益滲透到人們的日常生活中, 在互聯網普及之前,
人們查閱資料首先想到的是擁有大量書籍的資料的圖書館。 但是今天很多人都會選擇一種更方便、 快捷、 全面、 準確的查閱方式–互聯網。
而幫助我們在整個互聯網上快速地查找到目標信息的就是越來越被重視的搜索引擎。
今天學長來向大家介紹如何使用python寫一個搜索引擎,該項目常用于畢業設計
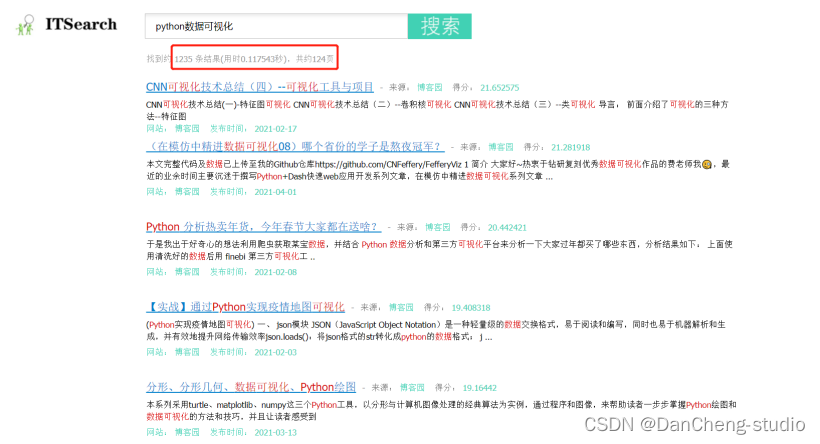
2 系統設計實現
2.1 總體設計
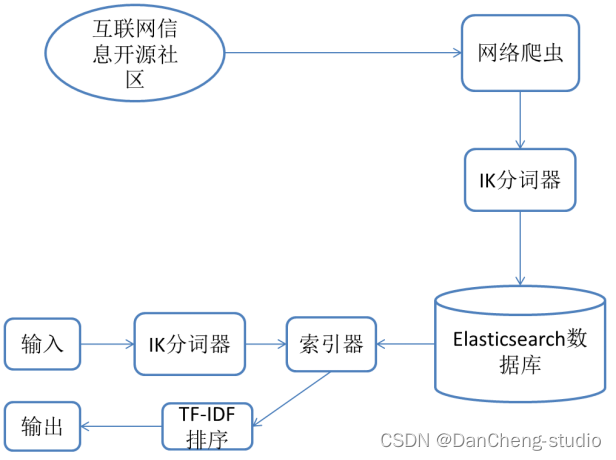
學長設計的系統采用的是非關系型數據庫Elasticsearch,因此對于此數據庫的查詢等基本操作會加以圖例的方式進行輔助闡述。在使用者開始進行査詢時,系統不可能把使用者輸入的關鍵詞與所有本地數據進行匹配,這種檢索方式即便建立索引,查詢效率仍然較低,而且非常消耗服務器資源。
因此,Elasticsearch將獲取到的數據分為兩個階段進行處理。第一階段:采用合適的分詞器,將獲取到的數據按照分詞器的標準進行分詞,第二階段:對每個關鍵詞的頻率以及出現的位置進行統計。
經過以上兩個階段,最后每個詞語具體出現在哪些文章中,出現的位置和頻次如何,都將會被保存到Elasticsearch數據庫中,此過程即為構建倒排索引,需要花費的計算開銷很大,但大大提高了后續檢索的效率。其中,搜索引擎的索引過程流程圖如圖

2.2 搜索關鍵流程
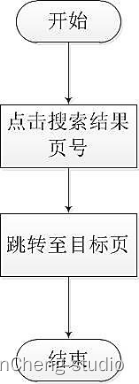
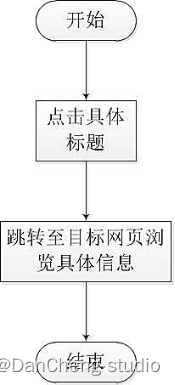
如圖所示,每一位用戶在搜索框中輸入關鍵字后,點擊搜索發起搜索請求,系統后臺解析內容后,將搜索結果返回到查詢結果頁,用戶可以直接點擊查詢結果的標題并跳轉到詳情頁,也可以點擊下一頁查看其他頁面的搜索結果,也可以選擇重新在輸入框中輸入新的關鍵詞,再次發起搜索。
跳轉至不同結果頁流程圖:
瀏覽具體網頁信息流程圖:
搜索功能流程圖:

2.3 推薦算法
用戶可在平臺上了解到當下互聯網領域中的熱點內容,點擊文章鏈接后即可進入到對應的詳情頁面中,瀏覽選中的信息的目標網頁,詳細了解其中的內容。豐富了本搜索平臺提供信息的實時性,如圖
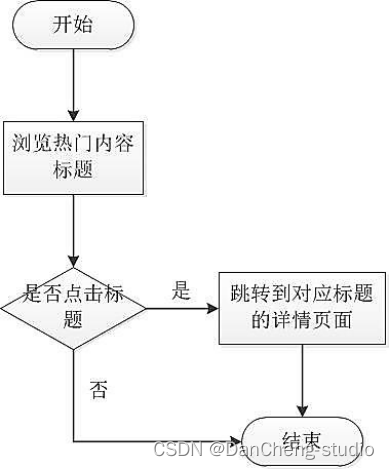
用戶可在搜索引擎首頁中瀏覽到系統推送的可能感興趣的內容,同時用戶可點擊推送的標題進入具體網頁進行瀏覽詳細內容。流程圖如圖

2.4 數據流的實現
學長設計的系統的數據來源主要是從發布互聯網專業領域信息的開源社區上爬蟲得到。
再經過IK分詞器對獲取到的標題和摘要進行分詞,再由Elasticsearch建立索引并將數據持久化。
用戶通過輸入關鍵詞,點擊檢索,后臺程序對獲得的關鍵詞再進行分詞處理,再到數據庫中進行查找,將滿足條件的網頁標題和摘要用超鏈接的方式在瀏覽器中顯示出來。
3 實現細節
3.1 系統架構
搜索引擎有基本的五大模塊,分別是:
- 信息采集模塊
- 信息處理模塊
- 建立索引模塊
- 查詢和 web 交互模塊
學長設計的系統目的是在信息處理分析的基礎上,建立一個完整的中文搜索引擎。
所以該系統主要由以下幾個詳細部分組成:
- 爬取數據
- 中文分詞
- 相關度排序
- 建立web交互。
3.2 爬取大量網頁數據
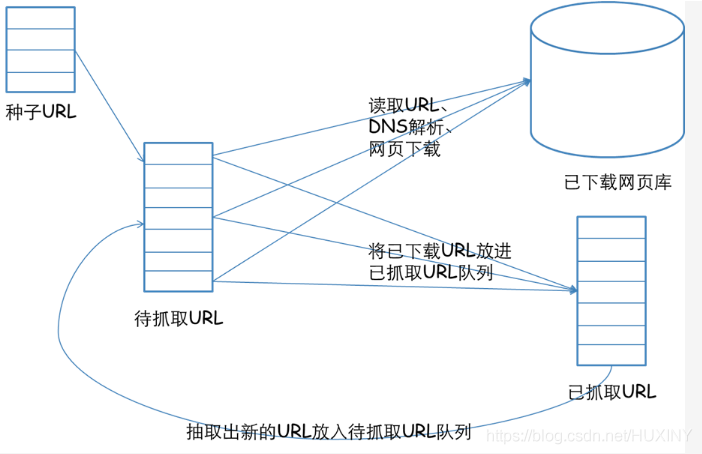
爬取數據,實際上用的就是爬蟲。
我們平時在瀏覽網頁的時候,在瀏覽器里輸入一個網址,然后敲擊回車,我們就會看到網站的一些頁面,那么這個過程實際上就是這個瀏覽器請求了一些服務器然后獲取到了一些服務器的網頁資源,然后我們看到了這個網頁。
請求呢就是用程序來實現上面的過程,就需要寫代碼來模擬這個瀏覽器向服務器發起請求,然后獲取這些網頁資源。那么一般來說實際上獲取的這些網頁資源是一串HTML代碼,這里面包含HTML標簽,還有一
我們寫完程序之后呢就讓它一直運行著,它就能代替我們瀏覽器來向服務器發送請求,然后一直不停的循環的運行進行批量的大量的獲取數據了,這就是爬蟲的一個基本的流程。
一個通用的網絡爬蟲的框架如圖所示:
這里給出一段爬蟲,爬取自己感興趣的網站和內容,并按照固定格式保存起來:
? # encoding=utf-8
? # 導入爬蟲包
? from selenium import webdriver
? # 睡眠時間
? import time
? import re
? import os
? import requests
? # 打開編碼方式utf-8打開
? # 睡眠時間 傳入int為休息時間,頁面加載和網速的原因 需要給網頁加載頁面元素的時間def s(int):time.sleep(int)?
? # html/body/div[1]/table/tbody/tr[2]/td[1]/input
? # http://dmfy.emindsoft.com.cn/common/toDoubleexamp.do
? if __name__ == '__main__':#查詢的文件位置# fR = open('D:\\test.txt','r',encoding = 'utf-8')# 模擬瀏覽器,使用谷歌瀏覽器,將chromedriver.exe復制到谷歌瀏覽器的文件夾內chromedriver = r"C:\\Users\\zhaofahu\\AppData\\Local\\Google\\Chrome\\Application\\chromedriver.exe"# 設置瀏覽器os.environ["webdriver.chrome.driver"] = chromedriverbrowser = webdriver.Chrome(chromedriver)# 最大化窗口 用不用都行browser.maximize_window()# header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}# 要爬取的網頁neirongs = [] # 網頁內容response = [] # 網頁數據travel_urls = []urls = []titles = []writefile = open("docs.txt", 'w', encoding='UTF-8')url = 'http://travel.yunnan.cn/yjgl/index.shtml'# 第一頁browser.get(url)response.append(browser.page_source)# 休息時間s(3)# 第二頁的網頁數據#browser.find_element_by_xpath('// *[ @ id = "downpage"]').click()#s(3)#response.append(browser.page_source)#s(3)# 第三頁的網頁數據#browser.find_element_by_xpath('// *[ @ id = "downpage"]').click()#s(3)#response.append(browser.page_source)?
? # 3.用正則表達式來刪選數據
? reg = r'href="(//travel.yunnan.cn/system.*?)"'
? # 從數據里爬取data。。。
? # 。travel_urls 旅游信息網址
? for i in range(len(response)):
? travel_urls = re.findall(reg, response[i])
? # 打印出來放在一個列表里for i in range(len(travel_urls)):url1 = 'http:' + travel_urls[i]urls.append(url1)browser.get(url1)content = browser.find_element_by_xpath('/html/body/div[7]/div[1]/div[3]').text# 獲取標題作為文件名b = browser.page_sourcetravel_name = browser.find_element_by_xpath('//*[@id="layer213"]').texttitles.append(travel_name)print(titles)print(urls)for j in range(len(titles)):writefile.write(str(j) + '\t\t' + titles[j] + '\t\t' + str(urls[j])+'\n')s(1)browser.close()##
3.3 中文分詞
中文分詞使用jieba庫即可
jieba 是一個基于Python的中文分詞工具對于一長段文字,其分詞原理大體可分為三步:
1.首先用正則表達式將中文段落粗略的分成一個個句子。
2.將每個句子構造成有向無環圖,之后尋找最佳切分方案。
3.最后對于連續的單字,采用HMM模型將其再次劃分。
jieba分詞分為“默認模式”(cut_all=False),“全模式”(cut_all=True)以及搜索引擎模式。對于“默認模式”,又可以選擇是否使用
HMM 模型(HMM=True,HMM=False)。
3.4 相關度排序
上面已經根據用戶的輸入獲取到了相關的網址數據。
獲取到的數據中rows的形式如下
[(urlid1,wordlocation1_1,wordlocation1_2,wordlocation1_3…),(urlid2,wordlocation2_1,wordlocation2_2,wordlocation2_3…)]
列表的每個元素是一個元組,每個元素的內容是urlid和每個關鍵詞在該文檔中的位置。
wordids形式為[wordid1, wordid2, wordid3…],即每個關鍵詞所對應的單詞id
我們將會介紹幾種排名算法,所謂排名也就是根據各自的規則為每個鏈接評分,評分越好。并且最終我們會將幾種排名算法綜合利用起來,給出最終的排名。既然要綜合利用,那么我們就要先實現每種算法。在綜合利用時會遇到幾個問題。
1、每種排名算法評分機制不同,給出的評分尺度和含義也不盡相同
2、如何綜合利用,要考慮每種算法的效果。為效果好的給與較大的權重。
我們先來考慮第一個問題,如何消除每種評分算法所給出的評分尺度和含義不相同的問題。
第2個問題,等研究完所有的算法以后再來考慮。
簡單,使用歸一化,將每個評分值縮放到0-1上,1代表最高,0代表最低。
對爬去到的數據進行排序, 有好幾種排序算法:
第1個排名算法:根據單詞位置進行評分的函數
我們可以認為對用戶輸入的多個關鍵詞,在文檔中,這些關鍵詞出現的位置越靠前越好。比如我們往往習慣在文章的前面添加一些摘要性、概括性的描述。
# 根據單詞位置進行評分的函數.# rows是[(urlid1,wordlocation1_1,wordlocation1_2,wordlocation1_3...),(urlid2,wordlocation2_1,wordlocation2_2,wordlocation2_3...)]? def locationscore(self,rows):
? locations=dict([(row[0],1000000) for row in rows])
? for row in rows:
? loc=sum(row[1:]) #計算每個鏈接的單詞位置總和,越小說明越靠前
? if loc<locations[row[0]]: #記錄每個鏈接最小的一種位置組合
? locations[row[0]]=loc
? return self.normalizescores(locations,smallIsBetter=1)####
第2個排名算法:根據單詞頻度進行評價的函數
我們可以認為對用戶輸入的多個關鍵詞,在文檔中,這些關鍵詞出現的次數越多越好。比如我們在指定主題的文章中會反復提到這個主題。
# 根據單詞頻度進行評價的函數# rows是[(urlid1,wordlocation1_1,wordlocation1_2,wordlocation1_3...),(urlid2,wordlocation2_1,wordlocation2_2,wordlocation2_3...)]def frequencyscore(self,rows):counts=dict([(row[0],0) for row in rows])for row in rows: counts[row[0]]+=1 #統計每個鏈接出現的組合數目。 每個鏈接只要有一種位置組合就會保存一個元組。所以鏈接所擁有的組合數,能一定程度上表示單詞出現的多少。return self.normalizescores(counts)
第3個排名算法:根據單詞距離進行評價的函數
我們可以認為對用戶輸入的多個關鍵詞,在文檔中,這些關鍵詞出現的越緊湊越好。這是因為我們更希望所有單詞出現在一句話中,而不是不同的關鍵詞出現在不同段落或語句中。
? # 根據單詞距離進行評價的函數。
? # rows是[(urlid1,wordlocation1_1,wordlocation1_2,wordlocation1_3...),(urlid2,wordlocation2_1,wordlocation2_2,wordlocation2_3...)]
? def distancescore(self,rows):
? # 如果僅查詢了一個單詞,則得分都一樣
? if len(rows[0])<=2: return dict([(row[0],1.0) for row in rows])
? # 初始化字典,并填入一個很大的值mindistance=dict([(row[0],1000000) for row in rows])for row in rows:dist=sum([abs(row[i]-row[i-1]) for i in range(2,len(row))]) # 計算每種組合中每個單詞之間的距離if dist<mindistance[row[0]]: # 計算每個鏈接所有組合的距離。并為每個鏈接記錄最小的距離mindistance[row[0]]=distreturn self.normalizescores(mindistance,smallIsBetter=1)4 實現效果
熱門主題推薦實現
搜索界面的實現

查詢結果頁面顯示
查詢結果分頁顯示
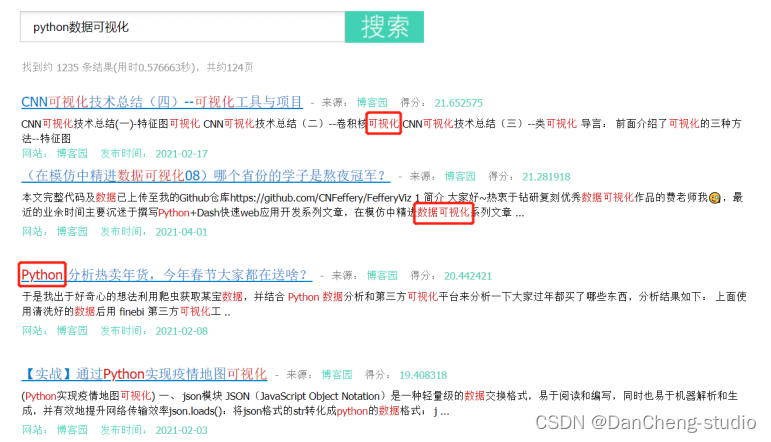
查詢結果關鍵字高亮標記顯示
4 最后
🧿 更多資料, 項目分享:
https://gitee.com/dancheng-senior/postgraduate


)










![從0開始學習pyspark--pyspark的數據分析方式[第2節]](http://pic.xiahunao.cn/從0開始學習pyspark--pyspark的數據分析方式[第2節])
)




—實踐篇-01)