Gaussian_model
討論Gaussian_model這個類,是因為里面包含了三維高斯分布的基本信息,里面定義了各種參量的構建方式、用于優化學習的激活函數、學習率設置方法和高斯點優化過程中的增加與刪除方式及對應優化器的處理方法。這個類定義在scene文件夾中的gaussian_module.py文件里。
scene/gaussian_model中進行函數構建
協方差矩陣和各種參數的激活函數
首先這個方法構建了協方差矩陣,而其中旋轉、縮放矩陣在以下文件中:
utils/general_utils的build_rotation中構建旋轉矩陣
'''
用來計算四元數表示的旋轉矩陣(Rotation Matrix)的。。首先,通過計算每個四元數的模長,來標準化它們。這是為了確保旋轉向量(四元數)的單位長度,以便于正確地進行旋轉計算。接著,將標準化后的四元數應用到旋轉矩陣上。這里,代碼創建了一個大小為 (batch_size, 3, 3) 的零張量 R,然后,通過四元數的各個分量進行矩陣賦值,根據四元數到旋轉矩陣的轉換公式來填充這個張量。最后,返回填充完的旋轉矩陣 R。需要注意的是,這段代碼是針對批處理的,因此輸入 r 是一個張量,其中每一行代表一個四元數。
'''
def build_rotation(r):norm = torch.sqrt(r[:,0]*r[:,0] + r[:,1]*r[:,1] + r[:,2]*r[:,2] + r[:,3]*r[:,3])q = r / norm[:, None]R = torch.zeros((q.size(0), 3, 3), device='cuda')r = q[:, 0]x = q[:, 1]y = q[:, 2]z = q[:, 3]R[:, 0, 0] = 1 - 2 * (y*y + z*z)R[:, 0, 1] = 2 * (x*y - r*z)R[:, 0, 2] = 2 * (x*z + r*y)R[:, 1, 0] = 2 * (x*y + r*z)R[:, 1, 1] = 1 - 2 * (x*x + z*z)R[:, 1, 2] = 2 * (y*z - r*x)R[:, 2, 0] = 2 * (x*z - r*y)R[:, 2, 1] = 2 * (y*z + r*x)R[:, 2, 2] = 1 - 2 * (x*x + y*y)return R
utils/general_utils的build_scaling_rotation中構建縮放矩陣并將旋轉矩陣和縮放矩陣合并
def build_scaling_rotation(s, r):L = torch.zeros((s.shape[0], 3, 3), dtype=torch.float, device="cuda")R = build_rotation(r)L[:,0,0] = s[:,0]L[:,1,1] = s[:,1]L[:,2,2] = s[:,2]L = R @ Lreturn L
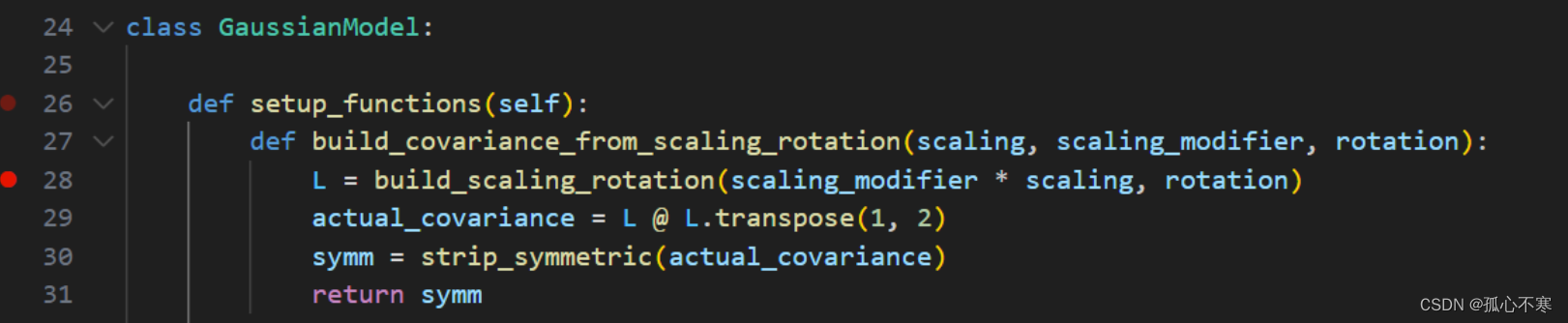
scene/gaussian_model的setup_functions中用build_covariance_from_scaling_rotation中將旋轉矩陣和縮放矩陣合并并處理成協方差矩陣。并在setup_functions中設定激活函數。
def setup_functions(self):def build_covariance_from_scaling_rotation(scaling, scaling_modifier, rotation):L = build_scaling_rotation(scaling_modifier * scaling, rotation)actual_covariance = L @ L.transpose(1, 2)symm = strip_symmetric(actual_covariance)return symmself.scaling_activation = torch.expself.scaling_inverse_activation = torch.logself.covariance_activation = build_covariance_from_scaling_rotationself.opacity_activation = torch.sigmoidself.inverse_opacity_activation = inverse_sigmoidself.rotation_activation = torch.nn.functional.normalize
'''
self.scaling_activation = torch.exp:這行代碼將指數函數 torch.exp 賦值給了 self.scaling_activation。這意味著在網絡中,會使用指數函數作為縮放操作的激活函數。self.scaling_inverse_activation = torch.log:這行代碼將對數函數 torch.log 賦值給了 self.scaling_inverse_activation。這表示在網絡中,會使用對數函數作為縮放的逆操作的激活函數。self.covariance_activation = build_covariance_from_scaling_rotation:這行代碼將一個函數 build_covariance_from_scaling_rotation 賦值給了 self.covariance_activation。這可能是一個自定義的函數,用于構建協方差矩陣,該函數可能會使用了縮放和旋轉操作。self.opacity_activation = torch.sigmoid:這行代碼將 sigmoid 函數 torch.sigmoid 賦值給了 self.opacity_activation。這表示在網絡中,會使用 sigmoid 函數作為不透明度的激活函數。self.inverse_opacity_activation = inverse_sigmoid:這行代碼將一個函數 inverse_sigmoid 賦值給了 self.inverse_opacity_activation。這可能是一個自定義的函數,用于計算 sigmoid 函數的逆操作。self.rotation_activation = torch.nn.functional.normalize:這行代碼將歸一化函數 torch.nn.functional.normalize 賦值給了 self.rotation_activation。這表示在網絡中,會使用歸一化函數作為旋轉操作的激活函數。
'''
點云數據的處理
初始化參數的含義:
def __init__(self, sh_degree: int):# 初始化球諧函數相關的度數# 初始化當前活動的球諧函數度數為 0,并將最大球諧函數度數設置為傳入的 sh_degree 參數。self.active_sh_degree = 0self.max_sh_degree = sh_degree# 初始化存儲點、球諧函數系數、縮放、旋轉、不透明度等的張量為空張量self._xyz = torch.empty(0)self._features_dc = torch.empty(0)self._features_rest = torch.empty(0)self._scaling = torch.empty(0)self._rotation = torch.empty(0)self._opacity = torch.empty(0)# 初始化高斯分布投影后的最大二維半徑、梯度累積器(用于辨別是否需要新增和刪除高斯)和分母張量(表示統計了多少次累計梯度,最后要把這個分母張量除掉)為空張量self.max_radii2D = torch.empty(0)self.xyz_gradient_accum = torch.empty(0)self.denom = torch.empty(0)# 初始化優化器optimizer為 Noneself.optimizer = None# 初始化密度百分比和空間學習率縮放因子(用于處理不同參數對學習率的要求)self.percent_dense = 0self.spatial_lr_scale = 0# 調用設置函數的方法進行必要的初始化self.setup_functions()scene/gaussian_model的create_from_pcd
def create_from_pcd(self, pcd : BasicPointCloud, spatial_lr_scale : float):self.spatial_lr_scale = spatial_lr_scale# 將點云數據中的點坐標轉換為 PyTorch 張量,并放置在 GPU 上進行加速處理fused_point_cloud = torch.tensor(np.asarray(pcd.points)).float().cuda()'''球諧函數這一堆寫在另一個文件里。'''print("Number of points at initialisation : ", fused_point_cloud.shape[0])# 計算點云中每個點與原點的歐氏距離的平方,并將其限制在一個最小值以上,以避免出現除以零的情況'''這行代碼使用了函數 distCUDA2 來計算點云中每個點之間的距離,并將結果存儲在 dist2 變量中。torch.from_numpy(np.asarray(pcd.points)).float().cuda() 將點云數據轉換為 PyTorch 張量,并將其移到 GPU 上。torch.clamp_min 函數用于將 dist2 中的所有元素的最小值限制為 0.0000001,以確保不會出現零距離。 '''dist2 = torch.clamp_min(distCUDA2(torch.from_numpy(np.asarray(pcd.points)).float().cuda()), 0.0000001)'''這行代碼首先計算了 dist2 中每個元素的平方根,然后取其自然對數。
[..., None] 用于在張量的最后一個維度上添加一個新的維度。
repeat(1, 3) 表示沿著第一個維度將張量復制三次,以便將其擴展為與 fused_point_cloud 相同的形狀,其中 fused_point_cloud 是點云的坐標。
最終,scales 是一個與 fused_point_cloud 具有相同形狀的張量,用于存儲每個點的縮放因子。'''scales = torch.log(torch.sqrt(dist2))[...,None].repeat(1, 3)'''這行代碼創建了一個形狀為 (點數, 4) 的全零張量 rots,用于存儲點云中每個點的旋轉信息。
每個點的旋轉信息是一個四維向量,其中第一個元素為1,其余元素為0,表示點云中的每個點都沒有旋轉。'''rots = torch.zeros((fused_point_cloud.shape[0], 4), device="cuda")'''這行代碼將 rots 張量的第一列(即第一個元素)設置為1,以表示每個點的旋轉信息中的第一個元素為1,其余元素為0,即單位四元數。'''rots[:, 0] = 1# 計算每個點的不透明度,這里使用了一個 sigmoid 函數的逆函數opacities = inverse_sigmoid(0.1 * torch.ones((fused_point_cloud.shape[0], 1), dtype=torch.float, device="cuda"))# 將點云的坐標、特征、尺度、旋轉和不透明度分別存儲為對象的參數,并設置為可訓練self._xyz = nn.Parameter(fused_point_cloud.requires_grad_(True))self._features_dc = nn.Parameter(features[:,:,0:1].transpose(1, 2).contiguous().requires_grad_(True))self._features_rest = nn.Parameter(features[:,:,1:].transpose(1, 2).contiguous().requires_grad_(True))self._scaling = nn.Parameter(scales.requires_grad_(True))self._rotation = nn.Parameter(rots.requires_grad_(True))self._opacity = nn.Parameter(opacities.requires_grad_(True))# 初始化一個用于存儲二維最大半徑的張量,其形狀與點云的數量相同self.max_radii2D = torch.zeros((self.get_xyz.shape[0]), device="cuda")
這里再放一個代碼塊說一下這個distCUDA2的函數是怎么定義的,在simple-knn/spatial.cu中
// 計算輸入張量 `points` 中每個點到其他所有點的距離之和,并返回每個點的平均距離。
torch::Tensor distCUDA2(const torch::Tensor& points)
{const int P = points.size(0); // 點的數量auto float_opts = points.options().dtype(torch::kFloat32); // Float32 類型選項torch::Tensor means = torch::full({P}, 0.0, float_opts); // 用于存儲平均距離的張量// 調用 SimpleKNN::knn 函數計算距離SimpleKNN::knn(P, (float3*)points.contiguous().data<float>(), means.contiguous().data<float>());return means; // 返回包含平均距離的張量
}這就是點云文件ply以文本形式打開后的變量內容,里面的參量很好理解。重點說一下f_dc是球諧函數的直流分量,而f_rest是球諧函數的高階分量。nx,ny,nz是每個高斯分布的法向量,但考慮到高斯分布的性質,這里的法向量都設置為0。

def training_setup(self, training_args):# 保存訓練參數中的 percent_dense 到對象的屬性中,用于后續的訓練。self.percent_dense = training_args.percent_dense# 創建一個全零張量 xyz_gradient_accum,用于累積 xyz 坐標的梯度,張量的形狀與 self.get_xyz 的第一維度匹配,并將其放置在 GPU 上。self.xyz_gradient_accum = torch.zeros((self.get_xyz.shape[0], 1), device="cuda")# 創建一個全零張量 denom,用于存儲某種歸一化或計數信息,張量的形狀與 self.get_xyz 的第一維度匹配,并將其放置在 GPU 上。self.denom = torch.zeros((self.get_xyz.shape[0], 1), device="cuda")l = [{'params': [self._xyz], 'lr': training_args.position_lr_init * self.spatial_lr_scale, "name": "xyz"},{'params': [self._features_dc], 'lr': training_args.feature_lr, "name": "f_dc"},{'params': [self._features_rest], 'lr': training_args.feature_lr / 20.0, "name": "f_rest"},{'params': [self._opacity], 'lr': training_args.opacity_lr, "name": "opacity"},{'params': [self._scaling], 'lr': training_args.scaling_lr, "name": "scaling"},{'params': [self._rotation], 'lr': training_args.rotation_lr, "name": "rotation"}]# 使用 Adam 優化器,將參數列表 l 傳遞給優化器,并設置優化器的全局學習率為 0.0(具體學習率在每個參數字典中指定),以及非常小的 eps 值 1e-15。self.optimizer = torch.optim.Adam(l, lr=0.0, eps=1e-15)# lr_init: 初始學習率,按 self.spatial_lr_scale 進行縮放。lr_final: 最終學習率,按 self.spatial_lr_scale 進行縮放。lr_delay_mult: 學習率延遲倍數。max_steps: 最大訓練步數。self.xyz_scheduler_args = get_expon_lr_func(lr_init=training_args.position_lr_init*self.spatial_lr_scale, lr_final=training_args.position_lr_final*self.spatial_lr_scale,lr_delay_mult=training_args.position_lr_delay_mult,max_steps=training_args.position_lr_max_steps)
def update_learning_rate(self, iteration):''' Learning rate scheduling per step '''# 遍歷 self.optimizer 中的所有參數組。self.optimizer.param_groups 是一個包含多個字典的列表,每個字典包含了一組參數及其相關的優化信息(例如學習率)。for param_group in self.optimizer.param_groups:# 檢查當前參數組的名稱是否為 "xyz"。只有名稱為 "xyz" 的參數組才會進行學習率更新。if param_group["name"] == "xyz":# 調用 self.xyz_scheduler_args 函數,并傳入當前的迭代次數 iteration。self.xyz_scheduler_args 是一個學習率調度函數,根據當前的迭代次數計算并返回新的學習率 lr。 lr = self.xyz_scheduler_args(iteration)# 將計算得到的新學習率 lr 更新到當前的參數組中,使其在接下來的訓練步驟中使用新的學習率。param_group['lr'] = lrreturn lr
def construct_list_of_attributes(self):# 初始化一個列表 l,包含一些固定的屬性名稱:'x', 'y', 'z' 表示點的坐標,'nx', 'ny', 'nz' 表示法線的分量l = ['x', 'y', 'z', 'nx', 'ny', 'nz']# All channels except the 3 DC# 遍歷 _features_dc 的通道和特征維度,生成特征屬性名稱for i in range(self._features_dc.shape[1] * self._features_dc.shape[2]):l.append('f_dc_{}'.format(i))# 遍歷 _features_rest 的通道和特征維度,生成特征屬性名稱for i in range(self._features_rest.shape[1] * self._features_rest.shape[2]):l.append('f_rest_{}'.format(i))# 添加透明度屬性l.append('opacity')# 遍歷 _scaling 張量的所有通道,生成縮放因子屬性名稱for i in range(self._scaling.shape[1]):l.append('scale_{}'.format(i))# 遍歷 _rotation 張量的所有通道,生成旋轉信息屬性名稱for i in range(self._rotation.shape[1]):l.append('rot_{}'.format(i))return l
def save_ply(self, path):# 創建保存路徑的目錄,如果目錄不存在mkdir_p(os.path.dirname(path))# 獲取 xyz 坐標,并將其從 GPU 上移至 CPU,并轉換為 numpy 數組xyz = self._xyz.detach().cpu().numpy()# 初始化法向量數組,大小與 xyz 坐標相同normals = np.zeros_like(xyz)# 獲取并處理特征數據,將其從 GPU 移至 CPU,并轉換為 numpy 數組f_dc = self._features_dc.detach().transpose(1, 2).flatten(start_dim=1).contiguous().cpu().numpy()f_rest = self._features_rest.detach().transpose(1, 2).flatten(start_dim=1).contiguous().cpu().numpy()# 獲取并處理不透明度數據opacities = self._opacity.detach().cpu().numpy()# 獲取并處理縮放數據scale = self._scaling.detach().cpu().numpy()# 獲取并處理旋轉數據rotation = self._rotation.detach().cpu().numpy()# 構建 dtype,用于 numpy 的結構化數組,包含所有屬性名稱及其類型dtype_full = [(attribute, 'f4') for attribute in self.construct_list_of_attributes()]# 創建一個空的結構化數組,用于存儲所有頂點的數據elements = np.empty(xyz.shape[0], dtype=dtype_full)# 將所有屬性組合到一個二維數組中attributes = np.concatenate((xyz, normals, f_dc, f_rest, opacities, scale, rotation), axis=1)# 將屬性數據逐個賦值到結構化數組中elements[:] = list(map(tuple, attributes))# 創建 PlyElement 并將其描述為 'vertex'el = PlyElement.describe(elements, 'vertex')# 將 PlyData 寫入到指定路徑PlyData([el]).write(path)def reset_opacity(self):'''獲取當前透明度張量self.get_opacity。將所有透明度值限制在不超過0.01。對限制后的透明度值應用反Sigmoid函數。將新的透明度張量opacities_new替換到優化器中,并更新對象的透明度屬性self._opacity。'''opacities_new = inverse_sigmoid(torch.min(self.get_opacity, torch.ones_like(self.get_opacity) * 0.01))optimizable_tensors = self.replace_tensor_to_optimizer(opacities_new, "opacity")self._opacity = optimizable_tensors["opacity"]
def load_ply(self, path):# 讀取給定路徑的PLY文件,并將數據加載到類的屬性中。# 使用PlyData.read方法讀取PLY文件的數據。plydata = PlyData.read(path)# 從PLY文件中提取x, y, z坐標并堆疊成一個二維數組xyz。xyz = np.stack((np.asarray(plydata.elements[0]["x"]),np.asarray(plydata.elements[0]["y"]),np.asarray(plydata.elements[0]["z"])), axis=1)# 從PLY文件中提取opacity值,并添加一個新軸,以便與其他屬性的維度一致。opacities = np.asarray(plydata.elements[0]["opacity"])[..., np.newaxis]# 創建一個形狀為(頂點數, 3, 1)的零數組features_dc。# 從PLY文件中提取f_dc_0, f_dc_1, f_dc_2特征,并分別填充到features_dc中。features_dc = np.zeros((xyz.shape[0], 3, 1))features_dc[:, 0, 0] = np.asarray(plydata.elements[0]["f_dc_0"])features_dc[:, 1, 0] = np.asarray(plydata.elements[0]["f_dc_1"])features_dc[:, 2, 0] = np.asarray(plydata.elements[0]["f_dc_2"])# 提取所有以"f_rest_"開頭的屬性名,并按后綴數字排序。# 斷言這些屬性的數量符合期望。# 創建一個形狀為(頂點數, 特征數)的零數組features_extra。# 從PLY文件中提取相應的特征,并填充到features_extra中。# 重新調整數組的形狀,以便特征維度與SH系數一致。extra_f_names = [p.name for p in plydata.elements[0].properties if p.name.startswith("f_rest_")]extra_f_names = sorted(extra_f_names, key=lambda x: int(x.split('_')[-1]))assert len(extra_f_names) == 3 * (self.max_sh_degree + 1) ** 2 - 3features_extra = np.zeros((xyz.shape[0], len(extra_f_names)))for idx, attr_name in enumerate(extra_f_names):features_extra[:, idx] = np.asarray(plydata.elements[0][attr_name])features_extra = features_extra.reshape((features_extra.shape[0], 3, (self.max_sh_degree + 1) ** 2 - 1))# 提取所有以"scale_"和"rot"開頭的屬性名,并按后綴數字排序。# 創建零數組scales和rots,并從PLY文件中提取相應的屬性值,填充到數組中。scale_names = [p.name for p in plydata.elements[0].properties if p.name.startswith("scale_")]scale_names = sorted(scale_names, key=lambda x: int(x.split('_')[-1]))scales = np.zeros((xyz.shape[0], len(scale_names)))for idx, attr_name in enumerate(scale_names):scales[:, idx] = np.asarray(plydata.elements[0][attr_name])rot_names = [p.name for p in plydata.elements[0].properties if p.name.startswith("rot")]rot_names = sorted(rot_names, key=lambda x: int(x.split('_')[-1]))rots = np.zeros((xyz.shape[0], len(rot_names)))for idx, attr_name in enumerate(rot_names):rots[:, idx] = np.asarray(plydata.elements[0][attr_name])# 將所有提取的數據轉換為PyTorch張量,并將其設置為可優化的參數(requires_grad_(True))。# 使用transpose(1, 2)和contiguous()確保張量的內存布局適合后續計算。self._xyz = nn.Parameter(torch.tensor(xyz, dtype=torch.float, device="cuda").requires_grad_(True))self._features_dc = nn.Parameter(torch.tensor(features_dc, dtype=torch.float, device="cuda").transpose(1, 2).contiguous().requires_grad_(True))self._features_rest = nn.Parameter(torch.tensor(features_extra, dtype=torch.float, device="cuda").transpose(1, 2).contiguous().requires_grad_(True))self._opacity = nn.Parameter(torch.tensor(opacities, dtype=torch.float, device="cuda").requires_grad_(True))self._scaling = nn.Parameter(torch.tensor(scales, dtype=torch.float, device="cuda").requires_grad_(True))self._rotation = nn.Parameter(torch.tensor(rots, dtype=torch.float, device="cuda").requires_grad_(True))# 將active_sh_degree設置為max_sh_degree,表示當前使用的SH度數。self.active_sh_degree = self.max_sh_degree接下來的內容是關于自適應密度控制
這些代碼同樣在scene/gaussian_model中。
def replace_tensor_to_optimizer(self, tensor, name):# 將新的張量替換為優化器中的參數,同時保留優化器的狀態。這個很重要,后面處理參數都要靠這個方法!!!# 用于存儲新的可優化張量。optimizable_tensors = {}# 優化器的參數組包含了所有要優化的參數和相關設置。for group in self.optimizer.param_groups:# 檢查參數組的名字是否與給定的名字匹配。if group["name"] == name:# 獲取當前參數的狀態,包括動量項和二次動量項。stored_state = self.optimizer.state.get(group['params'][0], None)# 將動量項和二次動量項重置為與新張量相同形狀的零張量。stored_state["exp_avg"] = torch.zeros_like(tensor)stored_state["exp_avg_sq"] = torch.zeros_like(tensor)# 刪除舊參數的狀態。del self.optimizer.state[group['params'][0]]# 將參數組中的第一個參數替換為新的張量,并設置為需要梯度。group["params"][0] = nn.Parameter(tensor.requires_grad_(True))# 將存儲的狀態重新設置到新的參數上。self.optimizer.state[group['params'][0]] = stored_state# 將新的參數添加到字典中。optimizable_tensors[group["name"]] = group["params"][0]# 返回包含新的可優化張量的字典。return optimizable_tensors
'''
后面做自適應密度控制的時候,所用的方法如果需要替換優化器中的參數,都需要使用這個replace_tensor_to_optimizer方法。這個方法可以確保新的參數替換后,優化器的狀態(例如動量和二次動量)能夠被正確保留,使得訓練過程平穩進行。通過這種方式,可以有效地管理和更新優化器中的參數,而不會丟失已有的優化狀態。
'''
def _prune_optimizer(self, mask):# 通過應用掩碼(mask)來選擇需要保留的參數,并相應地更新優化器的狀態。# 初始化優化參數字典optimizable_tensors = {}# 遍歷優化器參數組for group in self.optimizer.param_groups:# 如果有存儲狀態(例如動量和二次動量),則更新這些狀態,使其只包含被掩碼保留的部分。stored_state = self.optimizer.state.get(group['params'][0], None)if stored_state is not None:stored_state["exp_avg"] = stored_state["exp_avg"][mask]stored_state["exp_avg_sq"] = stored_state["exp_avg_sq"][mask]# 刪除舊參數并用掩碼后的參數替換,無論是否有存儲狀態del self.optimizer.state[group['params'][0]]group["params"][0] = nn.Parameter((group["params"][0][mask].requires_grad_(True)))# 如果有存儲狀態,則將其重新分配到新的參數上self.optimizer.state[group['params'][0]] = stored_state# 記錄更新后的參數optimizable_tensors[group["name"]] = group["params"][0]else:# 如果沒有存儲狀態,僅更新參數組中的參數group["params"][0] = nn.Parameter(group["params"][0][mask].requires_grad_(True))optimizable_tensors[group["name"]] = group["params"][0]# 返回更新后的參數字典return optimizable_tensors def prune_points(self, mask):# 對輸入掩碼取反,得到有效點的掩碼valid_points_mask = ~mask# 調用 _prune_optimizer 方法,使用有效點的掩碼來更新優化器中的參數optimizable_tensors = self._prune_optimizer(valid_points_mask)# 更新類中的各個屬性,使其只包含有效點self._xyz = optimizable_tensors["xyz"]self._features_dc = optimizable_tensors["f_dc"]self._features_rest = optimizable_tensors["f_rest"]self._opacity = optimizable_tensors["opacity"]self._scaling = optimizable_tensors["scaling"]self._rotation = optimizable_tensors["rotation"]# 更新 xyz_gradient_accum 以僅包含有效點self.xyz_gradient_accum = self.xyz_gradient_accum[valid_points_mask]# 更新 denom 和 max_radii2D 以僅包含有效點self.denom = self.denom[valid_points_mask]self.max_radii2D = self.max_radii2D[valid_points_mask]def cat_tensors_to_optimizer(self, tensors_dict):# 初始化優化參數字典optimizable_tensors = {}# 遍歷優化器參數組for group in self.optimizer.param_groups:assert len(group["params"]) == 1# 從字典中獲取要擴展的張量extension_tensor = tensors_dict[group["name"]]# 獲取參數組的存儲狀態(例如動量和二次動量)stored_state = self.optimizer.state.get(group['params'][0], None)if stored_state is not None:# 擴展動量和二次動量stored_state["exp_avg"] = torch.cat((stored_state["exp_avg"], torch.zeros_like(extension_tensor)), dim=0)stored_state["exp_avg_sq"] = torch.cat((stored_state["exp_avg_sq"], torch.zeros_like(extension_tensor)), dim=0)# 更新參數組中的參數,并將其設置為需要梯度計算的模式del self.optimizer.state[group['params'][0]]group["params"][0] = nn.Parameter(torch.cat((group["params"][0], extension_tensor), dim=0).requires_grad_(True))self.optimizer.state[group['params'][0]] = stored_state# 將擴展后的參數存儲到優化參數字典中optimizable_tensors[group["name"]] = group["params"][0]else:# 如果沒有存儲狀態,只更新參數組中的參數group["params"][0] = nn.Parameter(torch.cat((group["params"][0], extension_tensor), dim=0).requires_grad_(True))optimizable_tensors[group["name"]] = group["params"][0]return optimizable_tensorsdef densification_postfix(self, new_xyz, new_features_dc, new_features_rest, new_opacities, new_scaling, new_rotation):# 將新的數據構建成一個字典d = {"xyz": new_xyz,"f_dc": new_features_dc,"f_rest": new_features_rest,"opacity": new_opacities,"scaling": new_scaling,"rotation": new_rotation}# 使用 cat_tensors_to_optimizer 方法,將新的數據添加到優化器中optimizable_tensors = self.cat_tensors_to_optimizer(d)# 更新實例變量,使其指向新的優化張量self._xyz = optimizable_tensors["xyz"]self._features_dc = optimizable_tensors["f_dc"]self._features_rest = optimizable_tensors["f_rest"]self._opacity = optimizable_tensors["opacity"]self._scaling = optimizable_tensors["scaling"]self._rotation = optimizable_tensors["rotation"]# 初始化梯度累積器和相關變量self.xyz_gradient_accum = torch.zeros((self.get_xyz.shape[0], 1), device="cuda")self.denom = torch.zeros((self.get_xyz.shape[0], 1), device="cuda")self.max_radii2D = torch.zeros((self.get_xyz.shape[0]), device="cuda")def densify_and_split(self, grads, grad_threshold, scene_extent, N=2):# 獲取初始點數n_init_points = self.get_xyz.shape[0]# 初始化一個與初始點數相同大小的全零張量,用于存儲梯度padded_grad = torch.zeros((n_init_points), device="cuda")# 將輸入的梯度值填充到全零張量中padded_grad[:grads.shape[0]] = grads.squeeze()# 選取滿足梯度閾值的點,生成布爾掩碼selected_pts_mask = torch.where(padded_grad >= grad_threshold, True, False)# 進一步篩選,確保縮放因子大于特定比例的場景范圍selected_pts_mask = torch.logical_and(selected_pts_mask,torch.max(self.get_scaling, dim=1).values > self.percent_dense * scene_extent)# 獲取選中的點的縮放因子,并重復 N 次stds = self.get_scaling[selected_pts_mask].repeat(N, 1)# 初始化均值為零的張量means = torch.zeros((stds.size(0), 3), device="cuda")# 生成符合正態分布的噪聲采樣samples = torch.normal(mean=means, std=stds)# 構建旋轉矩陣,并重復 N 次rots = build_rotation(self._rotation[selected_pts_mask]).repeat(N, 1, 1)# 計算新的點的坐標new_xyz = torch.bmm(rots, samples.unsqueeze(-1)).squeeze(-1) + self.get_xyz[selected_pts_mask].repeat(N, 1)# 計算新的縮放因子,并進行縮放處理new_scaling = self.scaling_inverse_activation(self.get_scaling[selected_pts_mask].repeat(N, 1) / (0.8 * N))# 復制旋轉信息new_rotation = self._rotation[selected_pts_mask].repeat(N, 1)# 復制特征信息new_features_dc = self._features_dc[selected_pts_mask].repeat(N, 1, 1)new_features_rest = self._features_rest[selected_pts_mask].repeat(N, 1, 1)# 復制透明度信息new_opacity = self._opacity[selected_pts_mask].repeat(N, 1)# 調用函數,將新生成的數據傳入self.densification_postfix(new_xyz, new_features_dc, new_features_rest, new_opacity, new_scaling, new_rotation)# 構建修剪掩碼,將新生成的點也包含在內prune_filter = torch.cat((selected_pts_mask, torch.zeros(N * selected_pts_mask.sum(), device="cuda", dtype=bool)))# 調用修剪函數,移除不需要的點self.prune_points(prune_filter)def densify_and_clone(self, grads, grad_threshold, scene_extent):# 根據梯度值和場景范圍,選取滿足條件的點selected_pts_mask = torch.where(torch.norm(grads, dim=-1) >= grad_threshold, True, False)selected_pts_mask = torch.logical_and(selected_pts_mask,torch.max(self.get_scaling, dim=1).values <= self.percent_dense * scene_extent)# 克隆選中的點new_xyz = self._xyz[selected_pts_mask]new_features_dc = self._features_dc[selected_pts_mask]new_features_rest = self._features_rest[selected_pts_mask]new_opacities = self._opacity[selected_pts_mask]new_scaling = self._scaling[selected_pts_mask]new_rotation = self._rotation[selected_pts_mask]# 調用函數,將克隆的數據傳入self.densification_postfix(new_xyz, new_features_dc, new_features_rest, new_opacities, new_scaling, new_rotation)def densify_and_prune(self, max_grad, min_opacity, extent, max_screen_size):# 計算每個點的梯度值grads = self.xyz_gradient_accum / self.denomgrads[grads.isnan()] = 0.0# 調用密化和克隆函數self.densify_and_clone(grads, max_grad, extent)# 調用密化和分裂函數self.densify_and_split(grads, max_grad, extent)# 根據透明度生成修剪掩碼prune_mask = (self.get_opacity < min_opacity).squeeze()# 如果指定了最大屏幕尺寸,根據屏幕尺寸生成修剪掩碼if max_screen_size:big_points_vs = self.max_radii2D > max_screen_sizebig_points_ws = self.get_scaling.max(dim=1).values > 0.1 * extentprune_mask = torch.logical_or(torch.logical_or(prune_mask, big_points_vs), big_points_ws)# 調用修剪函數,移除不需要的點self.prune_points(prune_mask)# 清理 CUDA 緩存torch.cuda.empty_cache()
def add_densification_stats(self, viewspace_point_tensor, update_filter):# 累積選中點的梯度值self.xyz_gradient_accum[update_filter] += torch.norm(viewspace_point_tensor.grad[update_filter, :2], dim=-1, keepdim=True)# 更新選中點的計數self.denom[update_filter] += 1Camera
以下代碼定義在scene/cameras.py中。
class Camera(nn.Module):def __init__(self, colmap_id, R, T, FoVx, FoVy, image, gt_alpha_mask, image_name, uid, trans=np.array([0.0, 0.0, 0.0]), scale=1.0, data_device="cuda"):"""初始化 Camera 類:param colmap_id: Colmap 中相機的 ID:param R: 旋轉矩陣:param T: 平移向量:param FoVx: 水平方向的視場角:param FoVy: 垂直方向的視場角:param image: 圖像數據 (torch.Tensor):param gt_alpha_mask: ground truth alpha mask (torch.Tensor):param image_name: 圖像名稱:param uid: 相機的唯一標識符:param trans: 平移向量,默認為 [0.0, 0.0, 0.0]:param scale: 縮放因子,默認為 1.0:param data_device: 數據存儲設備,默認為 "cuda""""super(Camera, self).__init__()# 初始化相機參數self.uid = uid self.colmap_id = colmap_idself.R = Rself.T = Tself.FoVx = FoVxself.FoVy = FoVyself.image_name = image_name# 嘗試將數據設備設置為指定的設備try:self.data_device = torch.device(data_device)except Exception as e:print(e)print(f"[Warning] Custom device {data_device} failed, fallback to default cuda device")self.data_device = torch.device("cuda")# 將圖像數據限制在 [0.0, 1.0] 范圍內并移動到指定設備self.original_image = image.clamp(0.0, 1.0).to(self.data_device)self.image_width = self.original_image.shape[2]self.image_height = self.original_image.shape[1]# 如果提供了 alpha mask,則將圖像數據乘以 alpha maskif gt_alpha_mask is not None:self.original_image *= gt_alpha_mask.to(self.data_device)else:self.original_image *= torch.ones((1, self.image_height, self.image_width), device=self.data_device)# 設置相機的近平面和遠平面self.zfar = 100.0self.znear = 0.01# 設置平移和縮放參數self.trans = transself.scale = scale# 計算世界坐標到視圖坐標的變換矩陣,并將其移動到 GPUself.world_view_transform = torch.tensor(getWorld2View2(R, T, trans, scale)).transpose(0, 1).cuda()# 計算投影矩陣,并將其移動到 GPUself.projection_matrix = getProjectionMatrix(znear=self.znear, zfar=self.zfar, fovX=self.FoVx, fovY=self.FoVy).transpose(0, 1).cuda()# 計算完整的投影變換矩陣self.full_proj_transform = (self.world_view_transform.unsqueeze(0).bmm(self.projection_matrix.unsqueeze(0))).squeeze(0)# 計算相機中心位置self.camera_center = self.world_view_transform.inverse()[3, :3]
# 這個不是很重要
class MiniCam:def __init__(self, width, height, fovy, fovx, znear, zfar, world_view_transform, full_proj_transform):"""初始化 MiniCam 類:param width: 圖像寬度:param height: 圖像高度:param fovy: 垂直方向的視場角:param fovx: 水平方向的視場角:param znear: 近平面:param zfar: 遠平面:param world_view_transform: 世界坐標到視圖坐標的變換矩陣:param full_proj_transform: 完整的投影變換矩陣"""self.image_width = widthself.image_height = heightself.FoVy = fovyself.FoVx = fovxself.znear = znearself.zfar = zfarself.world_view_transform = world_view_transformself.full_proj_transform = full_proj_transform# 計算相機中心位置view_inv = torch.inverse(self.world_view_transform)self.camera_center = view_inv[3][:3]其中的轉換矩陣
def getWorld2View2(R, t, translate=np.array([.0, .0, .0]), scale=1.0):"""計算從世界坐標系到相機視圖坐標系的變換矩陣。:param R: 旋轉矩陣 (3x3 numpy array):param t: 平移向量 (3-dimensional numpy array):param translate: 額外的平移向量,用于對相機中心進行平移 (默認為 [0.0, 0.0, 0.0]):param scale: 縮放因子,用于對相機中心進行縮放 (默認為 1.0):return: 從世界坐標系到相機視圖坐標系的變換矩陣 (4x4 numpy array)"""# 初始化一個 4x4 矩陣 Rt,全為零Rt = np.zeros((4, 4))# 將旋轉矩陣的轉置賦值給 Rt 的左上 3x3 子矩陣Rt[:3, :3] = R.transpose()# 將平移向量賦值給 Rt 的第4列的前3個元素Rt[:3, 3] = t# 將 Rt 的右下角元素賦值為 1.0Rt[3, 3] = 1.0# 計算相機從相機坐標系到世界坐標系的變換矩陣 C2WC2W = np.linalg.inv(Rt)# 提取相機中心坐標cam_center = C2W[:3, 3]# 對相機中心進行平移和縮放cam_center = (cam_center + translate) * scale# 更新 C2W 的第4列的前3個元素為新的相機中心坐標C2W[:3, 3] = cam_center# 計算從世界坐標系到相機坐標系的變換矩陣 RtRt = np.linalg.inv(C2W)# 返回浮點類型的變換矩陣 Rtreturn np.float32(Rt)其中的投影矩陣
def getProjectionMatrix(znear, zfar, fovX, fovY):'''投影矩陣用于將三維坐標變換為二維屏幕坐標。這通常涉及將相機坐標系中的點投影到一個稱為規范化設備坐標(NDC)系的空間中,然后再映射到屏幕坐標系。'''# 計算垂直視場角的一半的切線值tanHalfFovY = math.tan((fovY / 2))# 計算水平視場角的一半的切線值tanHalfFovX = math.tan((fovX / 2))# 計算近平面的上邊界位置top = tanHalfFovY * znear# 計算近平面的下邊界位置bottom = -top# 計算近平面的右邊界位置right = tanHalfFovX * znear# 計算近平面的左邊界位置left = -right# 初始化一個 4x4 的投影矩陣 P,所有元素初始為零P = torch.zeros(4, 4)# 控制 z 方向的符號z_sign = 1.0# 設置投影矩陣中的元素P[0, 0] = 2.0 * znear / (right - left) # x 方向上的縮放因子P[1, 1] = 2.0 * znear / (top - bottom) # y 方向上的縮放因子P[0, 2] = (right + left) / (right - left) # x 方向上的偏移量P[1, 2] = (top + bottom) / (top - bottom) # y 方向上的偏移量P[3, 2] = z_sign # 齊次坐標的 w 分量P[2, 2] = z_sign * zfar / (zfar - znear) # z 方向上的縮放因子P[2, 3] = -(zfar * znear) / (zfar - znear) # z 方向上的偏移量# 返回計算好的投影矩陣return P




)










)

Intel-SGX 官方示例分析(SampleCode)——SampleEnclave)
)