基于隨機變異的泛化聯邦學習
來源:AAAI2024
Abstract
問題:
????????FedAvg 將相同的全局模型派發給客戶端進行本地訓練,容易陷入尖銳解,導致訓練出性能低下的全局模型
提出 FedMut:
????????本文提出了一種名為 FedMut 的新型FL方法,它根據梯度變化變異全局模型,以生成下一輪訓練的幾個中間模型。每個中間模型將被派發到客戶端進行本地訓練。最終,全局模型會收斂到突變模型范圍內的平坦區域內
Introduction
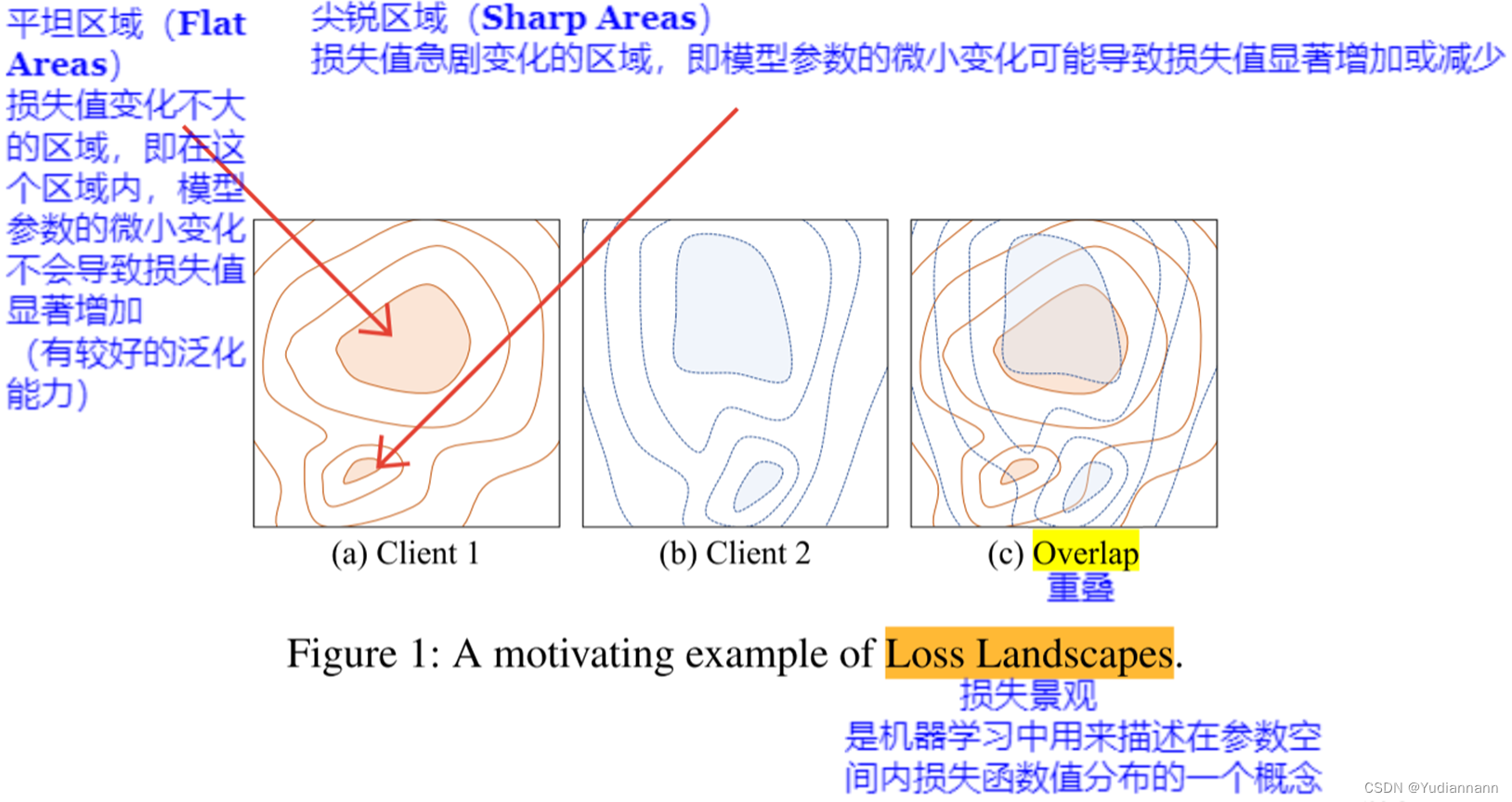
????????當模型收斂到兩個客戶端的平坦最優區域的重疊區域時,它在大多數客戶端中都能實現高推理性能
Relate?work
????????相關工作部分討論了為了提高傳統 FL 的推理性能,已經提出了許多 FL 優化方法。具體來說,這些方法可以分為三類,即
- 基于全局變量的 FL 方法
????????這類方法通常使用全局變量來指導本地訓練朝相似方向進行
FedProx 使用本地模型與全局模型之間的平方距離作為近端項來正則化本地損失函數,從而穩定模型的收斂
SCAFFOLD 生成一個全局控制變量,并使用該變量在本地訓練過程中糾正本地模型的優化方向
缺點:需要額外的通信開銷來分發全局變量,或者在客戶端上計算近端項的額外計算開銷
- 基于設備分組的 FL 方法
????????這類方法嘗試根據特定指標對設備進行分組,然后從不同分組中智能選擇設備進行本地訓練。大多數設備分組方法使用模型相似性作為分組指標,因為由于隱私保護的考慮,直接獲取每個客戶端的數據分布是困難的
CluSamp 使用樣本大小或模型相似性作為客戶端分組的指標
FedCluster 將客戶端分組,并在每個 FL 輪次中循環地執行 FL
缺點:它們需要獲取所有本地模型,這導致 FL 與安全聚合機制不兼容,從而可能引起潛在的隱私泄露風險
- 基于知識蒸餾的 FL 方法
????????這些方法采用著名的知識蒸餾技術來增強FL的推理性能。具體來說,它們使用一個表現良好的“教師模型”來指導“學生模型”的訓練
FedAUX 使用輔助數據集進行數據依賴的蒸餾來初始化服務器模型
FedDF 使用集成模型作為“教師模型”,并使用未標記數據進行蒸餾,以加速FL訓練
FedGen 使用內置生成器和代理數據集實現無數據蒸餾,解決了對額外數據集的需求問題
缺點:需要額外的計算開銷來進行知識蒸餾和額外的數據集
Motivation
????????如果全局模型位于平坦區域,那么在其鄰域內的模型仍然處于相同平坦區域的概率更高。相反,如果模型位于尖銳區域,那么在其鄰域內的模型可能位于其他區域。基于這種直覺,我們變異全局模型以在其中生成多個模型,用于本地訓練。當所有變異模型都位于相同區域時,我們可以獲得一個泛化良好的全局模型,其鄰域是平坦的

????????如圖2(a)所示,云服務器通過模型變異過程生成四個變異模型。由于由變異模型組成的鄰域小于初始全局模型所在的平坦區域,所有變異模型仍然位于這個平坦區域內。通過本地訓練,所有變異模型都朝著平坦區域的中心優化,聚合后的全局模型相應地更新到平坦區域的中心
????????如圖2(b)所示,由于由變異模型組成的鄰域大于平坦區域,三個變異模型位于另一個區域而不是初始全局模型所在的尖銳區域。通過本地訓練,三個變異模型朝著平坦區域優化,只有一個變異模型在尖銳區域進行優化。因此,聚合后的全局模型朝平坦區域移動
Settings
- 隨機梯度下降(SGD)優化器
- learning rate = 0.01
- momentum = 0.9
- batch size = 50
- epoch =?5
數據集
- CIFAR-10
- CIFAR-100
- Shakespeare
模型
在 CIFAR-10 和 CIFAR-100 上
- CNN、ResNet-18?
在 Shakespeare?上
- LSTM
動機驗證
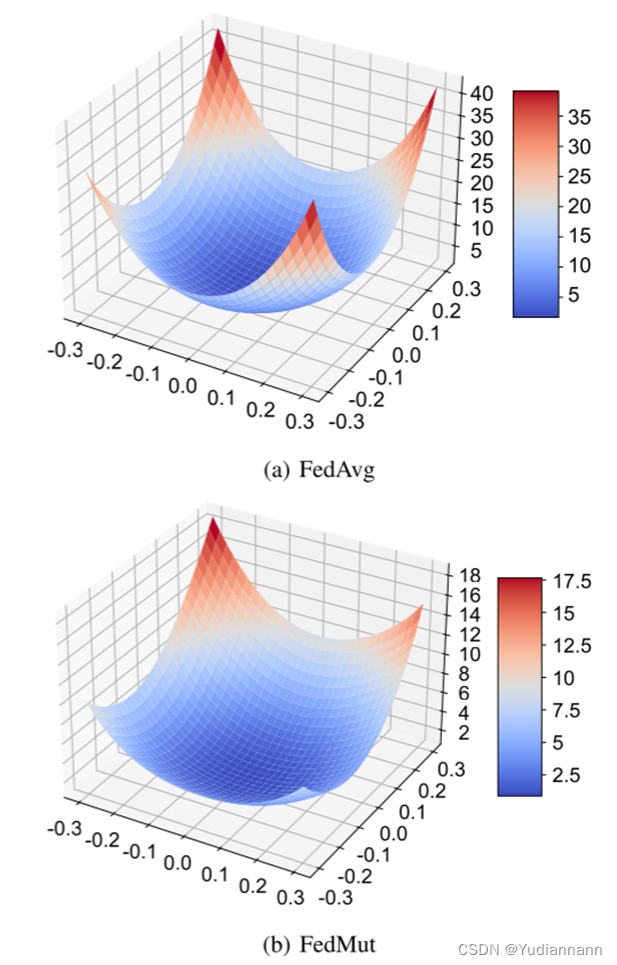
?實驗結果

?消融研究
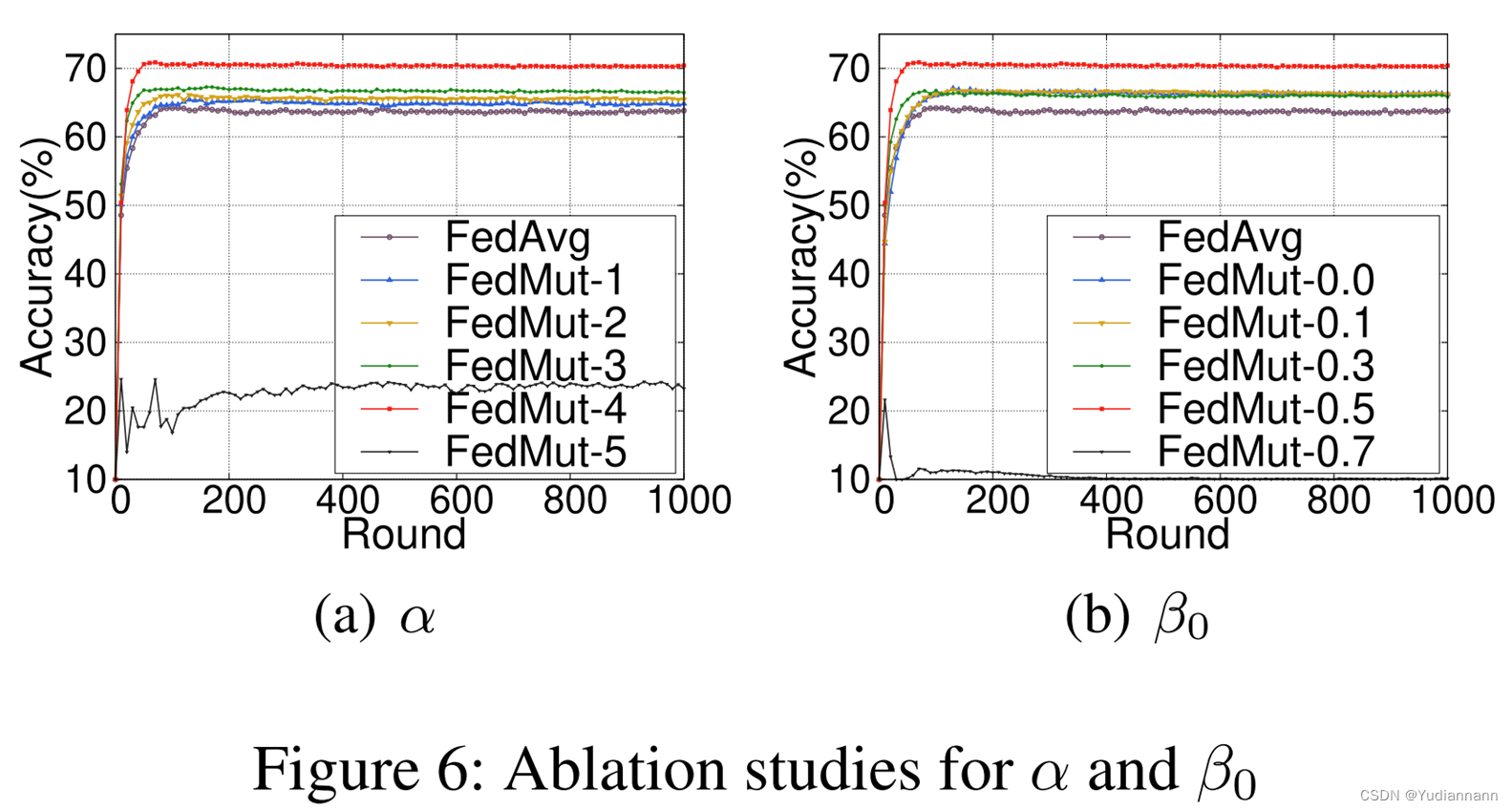





-指針)



+根號下(b+3) 的最大值為?(2015重慶卷))









