文章目錄
- 前言
- 一、簡介
- 二、Background: indirect calls, Spectre, and retpolines
- 2.1 Indirect calls
- 2.2 Spectre (v2)
- 2.3 Retpolines
- Consequences
- 2.4 Static calls
- How it works
- 三、其他
- 參考資料
前言
Linux內核5.10內核版本引入新特性:Static calls。
Static calls for improved post-Spectre performance
Static calls靜態調用是全局函數指針的替代方案。它們利用代碼修補來實現直接調用,而不是間接調用。它們提供了函數指針的靈活性,但具有改進的性能。這在使用函數指針較多的x86 perf代碼中尤為重要,因為靜態調用可以將PMU處理程序的速度提高4.2%。這對于本來需要使用retpoline的情況尤其重要,因為retpoline可能會嚴重影響性能。
簡單來說:靜態調用使用代碼修補將函數指針硬編碼到直接跳轉指令中。它們提供了函數指針的靈活性,但性能更好。
間接函數調用——調用存儲在指針變量中的函數地址——從來都不是非常快速的,但Spectre硬件漏洞使情況變得更糟。CPU中用于加速間接調用的間接分支預測器不能再使用,性能相應地受到了影響。"retpoline"機制是一個聰明的技巧,證明比最初嘗試的基于硬件的解決方案更快。雖然retpoline減輕了Spectre緩解的痛苦,但過去一年的經驗表明它們仍然會產生一定的性能損失。因此,開發人員一直在尋找retpoline的替代方法;最近在內核列表中出現了幾種解決方案。
使間接調用更快的方法是將其替換為直接調用;這樣就不需要分支預測。當然,如果在任何給定情況下直接調用就足夠了,開發人員會使用直接調用而不是間接調用,所以這種替換并不總是直截了當的。所有對retpoline開銷的提議解決方案都努力以某種方式進行這種替換;它們從簡單到復雜各不相同。
retpoline是一個軟件方法來解決Spectre V2漏洞,但其開銷比較大。
Static calls靜態調用是retpoline的替代方法。
一、簡介
本章節來自:Avoiding retpolines with static calls
2018年1月是內核社區的一個悲傷時刻。Meltdown和Spectre漏洞最終被公開,而所需的解決方案在許多方面損害了內核性能。其中一種解決方案是retpoline,但它繼續帶來困擾,開發人員不得不費盡心思避免間接調用,因為它們現在必須使用retpoline來實現。然而,在某些情況下,可能有一種方法可以避免retpoline并恢復大部分性能損失;經過漫長的孕育期,"靜態調用"機制可能終于接近能夠合并到上游的階段。
當編譯時無法確定要調用的函數的地址時,就會發生間接調用;相反,該地址存儲在指針變量中,在運行時使用。這些間接調用很容易受到推測執行攻擊的利用。Retpolines通過將間接調用轉換為一個更復雜(且更昂貴)的代碼序列來防止這些攻擊,這樣就無法進行推測執行。
Retpolines解決了問題,但也降低了內核的速度,因此開發人員一直渴望找到避免它們的方法。已經嘗試了許多方法;其中一些在2018年末的 這篇文章 中進行了介紹。雖然其中一些技術已經合并,但靜態調用一直未進入主線內核。最近,Peter Zijlstra發布了這個補丁集,其中包含其他人的工作,特別是Josh Poimboeuf,他發布了最初的靜態調用實現。
這就是靜態調用發揮作用的地方。靜態調用使用位于可執行內存中的位置(而不是可寫內存),該位置包含一個指向目標函數的跳轉指令。執行靜態調用需要調用特殊位置,然后跳轉到實際的目標函數。這被稱為經典的代碼跳板,完全避免了使用 retpolines 的需要。
間接調用從可寫內存中的位置起作用,可以找到跳轉的目標。更改調用的目標只需在該位置存儲一個新地址。相反,靜態調用使用可執行內存中的位置,其中包含一個指向目標函數的跳轉指令。實際執行靜態調用需要"調用"這個特殊位置,它將立即跳轉到真正的目標函數。靜態調用位置實際上是一個經典的代碼跳板。由于兩個跳轉都是直接的——目標地址直接在可執行代碼本身中找到——不需要retpoline,并且執行速度很快。
對于Spectre-v2漏洞和Retpoline請參考:Spectre-v2 以及 Linux Retpoline技術簡介
靜態調用必須在使用之前進行聲明;有兩個宏可以完成這個任務:
#include <linux/static_call.h>DEFINE_STATIC_CALL(name, target);DECLARE_STATIC_CALL(name, target);
DEFINE_STATIC_CALL()創建一個新的靜態調用,使用給定的名稱,并最初指向函數target()。DECLARE_STATIC_CALL()則聲明了在其他地方定義的靜態調用的存在;在這種情況下,target()僅用于對調用進行類型檢查。
實際調用靜態調用的方式如下:
static_call(name)(args...);
其中,name是用于定義調用的名稱。這將導致通過跳板跳轉到目標函數;如果該函數返回一個值,static_call()也會返回該值。
靜態調用的目標可以通過以下方式更改:
static_call_update(name, target2);
其中,target2()是靜態調用的新目標。更改靜態調用的目標需要對正在運行的內核進行修補,這是一項昂貴的操作。這意味著靜態調用只適用于目標很少更改的情況。
在補丁集中可以找到這樣的情況:跟蹤點(tracepoints)。激活一個跟蹤點本身就需要對代碼進行修補。一旦完成,內核通過迭代遍歷已附加到跟蹤點的回調函數的鏈表來響應對跟蹤點的觸發。然而,在幾乎所有情況下,只會有一個這樣的函數。該系列中的這個補丁通過對單函數情況使用靜態調用來優化該過程。由于跟蹤點的目標是盡可能減少開銷,因此在那里使用靜態調用是有意義的。
這個補丁集還包含了一項在原始版本中找不到的進一步優化。通過跳過跳板(trampoline)進行跳轉比使用retpoline要快得多,但仍然比嚴格必要的跳轉多一個。因此,這個補丁使靜態調用直接將目標地址存儲到調用點(call site(s)),完全消除了跳板的需要。這可能需要更改多個調用點,但大多數靜態調用不太可能有很多這樣的調用點。它還需要在objtool工具中提供支持,以便在內核構建過程中定位這些調用點。
這項工作的最終結果似乎是在使用跟蹤點時減少Spectre緩解的成本——4%多的減速降低到大約1.6%。經過多次修訂以及對基礎文本修補代碼的一些改進,它似乎已經準備就緒。靜態調用有望在不久的將來被合并到主線內核中。
對于內核鏡像:
內核鏡像增加了一個數據段__start_static_call_sites - __stop_static_call_sites :
// linux-5.15/include/asm-generic/vmlinux.lds.h#define STATIC_CALL_DATA \. = ALIGN(8); \__start_static_call_sites = .; \KEEP(*(.static_call_sites)) \__stop_static_call_sites = .; \__start_static_call_tramp_key = .; \KEEP(*(.static_call_tramp_key)) \__stop_static_call_tramp_key = .;
// kernel/static_call.cint __init static_call_init(void)
{int ret;if (static_call_initialized)return 0;cpus_read_lock();static_call_lock();ret = __static_call_init(NULL, __start_static_call_sites,__stop_static_call_sites);static_call_unlock();cpus_read_unlock();static_call_initialized = true;return 0;
}
early_initcall(static_call_init);
# uname -r
5.15.0-101-generic
# cat /proc/kallsyms | grep __start_static_call_sites
ffffffffa233afb0 R __start_static_call_sites
# cat /proc/kallsyms | grep __stop_static_call_sites
ffffffffa233d4b0 R __stop_static_call_sites
對于內核模塊:
內核模塊增加了一個.static_call_sites節:
// kernel/module.cstatic int find_module_sections(struct module *mod, struct load_info *info)
{
......
#ifdef CONFIG_HAVE_STATIC_CALL_INLINEmod->static_call_sites = section_objs(info, ".static_call_sites",sizeof(*mod->static_call_sites),&mod->num_static_call_sites);
#endif
......
}
/** The static call site table needs to be created by external tooling (objtool* or a compiler plugin).*/
struct static_call_site {s32 addr;s32 key;
};
struct module {
......
#ifdef CONFIG_HAVE_STATIC_CALL_INLINEint num_static_call_sites;struct static_call_site *static_call_sites;
#endif
......
}
二、Background: indirect calls, Spectre, and retpolines
2.1 Indirect calls
間接調用是C語言中最強大的功能之一,它對于在沒有補充對象或函數/方法調度系統的情況下編寫高級代碼至關重要。
大多數C程序員都對間接調用的基本原理很熟悉,這要歸功于標準庫和POSIX函數,例如qsort和pthread_create。在這些函數中,每個函數都有一個函數指針,然后在內部調用該函數指針以完成所需的功能:
#include <stdlib.h>
#include <string.h>
#include <stdio.h>/* qsort_strcmp is just the normal stdlib strcmp, with a bit of extra parameter* munging to match qsort's API.*/
static int qsort_strcmp(const void *a, const void *b) {return strcmp(*(const char **)a, *(const char **)b);
}int main(void) {const char *strings[] = {"foo", "bar", "baz"};/* qsort is a generic sorting function:* you give it the a pointer to the base address of things to sort,* their number and individual sizes, and a *function* that can compare* any two members and provide an ordering between them.** in this case, we tell qsort to sort an array of strings, using* `qsort_strcmp` for the ordering.*/qsort(&strings, 3, sizeof(char *), qsort_strcmp);printf("%s %s %s\n", strings[0], strings[1], strings[2]);return 0;
}
在這種情況下,間接調用發生在qsort中。但是,如果我們實現自己的函數來進行間接調用,我們可以直接看到它:
static uint32_t good_rand() {uint32_t x;getrandom(&x, sizeof(x), GRND_NONBLOCK);return x;
}static uint32_t bad_rand() {return rand();
}/* munge takes a function pointer, rand_func, which it calls* as part of its returned result.*/
static uint32_t munge(uint32_t (*rand_func)(void)) {return rand_func() & 0xFF;
}int main(void) {uint32_t x = munge(good_rand);uint32_t y = munge(bad_rand);printf("%ul, %ul\n", x, y);return 0;
}
munge可以歸結為:
munge:push rbpmov rbp, rspsub rsp, 16mov qword ptr [rbp - 8], rdi ; load rand_funccall qword ptr [rbp - 8] ; call rand_funcand eax, 255add rsp, 16pop rbpret
觀察一下:我們的調用通過一個內存或寄存器操作數([rbp - 8])來獲取目標,而不是直接指定操作數值本身的直接目標(比如,call 0xacabacab ; @good_rand)。這就是使其成為間接調用的原因。
在這種情況下,我們的調用需要在運行時通過內存或寄存器中存儲的地址來確定目標函數的位置,而不是在編譯時就能確定目標地址。這種間接性使得代碼更加靈活,可以在運行時動態地選擇要調用的函數。
我們可以進一步深入!事實上,在C語言中,常見的模式是聲明整個操作結構,使用每個操作作為參數來對一組獨立實現的低級行為(例如,核心的POSIX I/O API)進行參數化。
這種模式通常用于實現可插拔的行為或策略模式。通過將操作封裝在結構中,并將該結構作為參數傳遞給函數,我們可以在運行時選擇不同的實現來改變程序的行為。
以下是一個示例,展示了如何使用結構來參數化低級行為:
#include <stdio.h>// 定義操作結構
typedef struct {void (*open)();void (*read)();void (*write)();void (*close)();
} IOOperations;// 低級實現1
void fileOpen() {printf("打開文件...\n");
}void fileRead() {printf("讀取文件...\n");
}void fileWrite() {printf("寫入文件...\n");
}void fileClose() {printf("關閉文件...\n");
}// 低級實現2
void networkOpen() {printf("打開網絡連接...\n");
}void networkRead() {printf("從網絡讀取...\n");
}void networkWrite() {printf("向網絡寫入...\n");
}void networkClose() {printf("關閉網絡連接...\n");
}// 使用操作結構的高級函數
void performIO(IOOperations *operations) {operations->open();operations->read();operations->write();operations->close();
}int main() {IOOperations fileIO = {fileOpen, fileRead, fileWrite, fileClose};IOOperations networkIO = {networkOpen, networkRead, networkWrite, networkClose};printf("執行文件操作:\n");performIO(&fileIO);printf("\n執行網絡操作:\n");performIO(&networkIO);return 0;
}
比如這正是FUSE的工作方式:每個FUSE客戶端都創建自己的FUSE_operations:
struct fuse_operations {int (*getattr) (const char *, struct stat *, struct fuse_file_info *fi);int (*readlink) (const char *, char *, size_t);int (*mknod) (const char *, mode_t, dev_t);int (*mkdir) (const char *, mode_t);int (*unlink) (const char *);int (*rmdir) (const char *);int (*symlink) (const char *, const char *);int (*rename) (const char *, const char *, unsigned int flags);int (*link) (const char *, const char *);/* ... */int (*open) (const char *, struct fuse_file_info *);int (*read) (const char *, char *, size_t, off_t,struct fuse_file_info *);int (*write) (const char *, const char *, size_t, off_t,struct fuse_file_info *);int (*statfs) (const char *, struct statvfs *);/* ... */
}
毫不奇怪,這種技術不僅限于用戶空間:Linux內核本身大量使用了間接調用,特別是在與體系結構無關的接口(如VFS和像procfs這樣的子專用接口)以及子系統的體系結構特定內部(如perf_events)中。
在Linux內核中,使用間接調用的目的是為了實現可移植性和靈活性。通過使用函數指針和間接調用,內核可以提供通用的接口,而不必關心底層具體的實現細節。這使得內核能夠在多個體系結構上運行,并且可以通過更改具體實現來改變內核的行為。
例如,Linux內核的虛擬文件系統(VFS)是一個與體系結構無關的接口,用于處理文件系統操作。它定義了一組函數指針,用于執行與文件系統相關的操作,如打開文件、讀取文件、寫入文件等。具體的文件系統實現可以通過設置這些函數指針來提供相應的功能。
類似地,perf_events子系統是用于性能分析的內核子系統。它利用間接調用來處理體系結構特定的事件和計數器。不同的體系結構可以提供它們自己的實現,通過設置相應的函數指針來處理特定的事件和計數器。
通過使用間接調用,Linux內核能夠在不同的體系結構上實現統一的接口,并且可以根據需要進行靈活的定制和擴展。
確實如此。這種技術非常巧妙,以至于CPU工程師們為了從中擠取更多性能而興奮不已,結果我們遭遇了Spectre漏洞(Spectre v2)。
2.2 Spectre (v2)

Spectre v2(也稱為CVE-2017-5715)利用的確切機制略微超出了本文的范圍,但在高層次上可以解釋如下:
(1)現代(x86)CPU中包含一個間接分支預測器,用于嘗試猜測間接調用或跳轉的目標位置。
為了實際加速執行,CPU會對預測的分支進行推測性執行:
如果預測正確,間接調用會在短時間內完成(因為它已經在推測性執行中或已經完成推測性執行);
如果預測錯誤,應該會導致較慢(但仍然成功)的間接調用,而不會受到不正確推測的副作用影響。
換句話說,CPU負責回滾任何與錯誤預測和后續推測相關的副作用。錯誤推測是一種微體系結構細節,不應該表現為體系結構更改,比如修改的寄存器。
(2)回滾任何錯誤推測的狀態是一項相對昂貴的操作,具有許多微體系結構影響:緩存行和其他狀態位需要進行修復,以確保實際的程序控制流程不受失敗推測的影響。
實際上,回滾整個推測狀態將撤消推測的大部分優勢。因此,x86和其他指令集架構會將推測狀態的許多位(例如緩存行)標記為陳舊狀態。
(3)這種修復行為(回滾或標記推測狀態)導致了一個側信道:攻擊者可以訓練分支預測器,以推測性地執行一段代碼(類似于ROP小工具),該代碼以數據相關的方式修改一些微體系結構狀態,例如依賴于推測性獲取的秘密值的緩存條目的地址。
然后,攻擊者可以通過計時訪問該微體系結構狀態來探測它:快速訪問表示存在推測性修改的狀態,從而泄露了秘密信息。
最初的Spectre v2攻擊主要集中在緩存行上,因為它們相對容易計時,即使是在高級別(受到沙箱限制的)語言中,這些語言無法訪問x86上的clflush或其他緩存行原語。但這個概念是普遍存在的:在不泄露一些信息的情況下進行推測性執行是困難的,而隨后出現的漏洞(如MDS和ZombieLoad)已經揭示了其他微體系結構特性中的信息泄露問題。
這是個壞消息:攻擊者在最安全的上下文(JavaScript或其他托管代碼,在沙箱中,在用戶空間)中運行,理論上可以訓練間接分支預測器以推測性地執行內核空間的一個小工具,從而可能泄露內核內存。
因此,內核需要一種新的緩解措施。這個緩解措施就是retpolines。
2.3 Retpolines
Retpoline(返回跳板)是一種利用永遠不會執行的無限循環來防止CPU對間接跳轉的目標進行推測的跳板系統。該系統還使用返回堆棧緩沖器(RSB)作為預測結構,類似于返回指令的分支預測器。為了確保無法通過惡意方式訓練出無限循環的 RSB,retpolines 總是以直接調用開始,以確保 RSB 預測到一個無限循環。
Retpoline 并不是最初針對 Spectre 漏洞的緩解措施,而是在發現原始的 Spectre 緩解措施在特定的 CPU 架構(包括 AMD 和 Intel)和特定工作負載下導致相對性能下降后,由 Google 創建的。
為了緩解Spectre v2漏洞,內核需要阻止CPU對受攻擊者控制的間接分支進行推測性執行。
retpoline(返回跳板)正是為此目的而設計的:間接跳轉和調用周圍包含一個小的代碼塊(thunk),它將推測性執行陷入一個無限循環中,直到錯誤的預測得到解決。
英特爾的Retpoline白皮書中有一些有用的插圖,可以幫助理解這個過程:
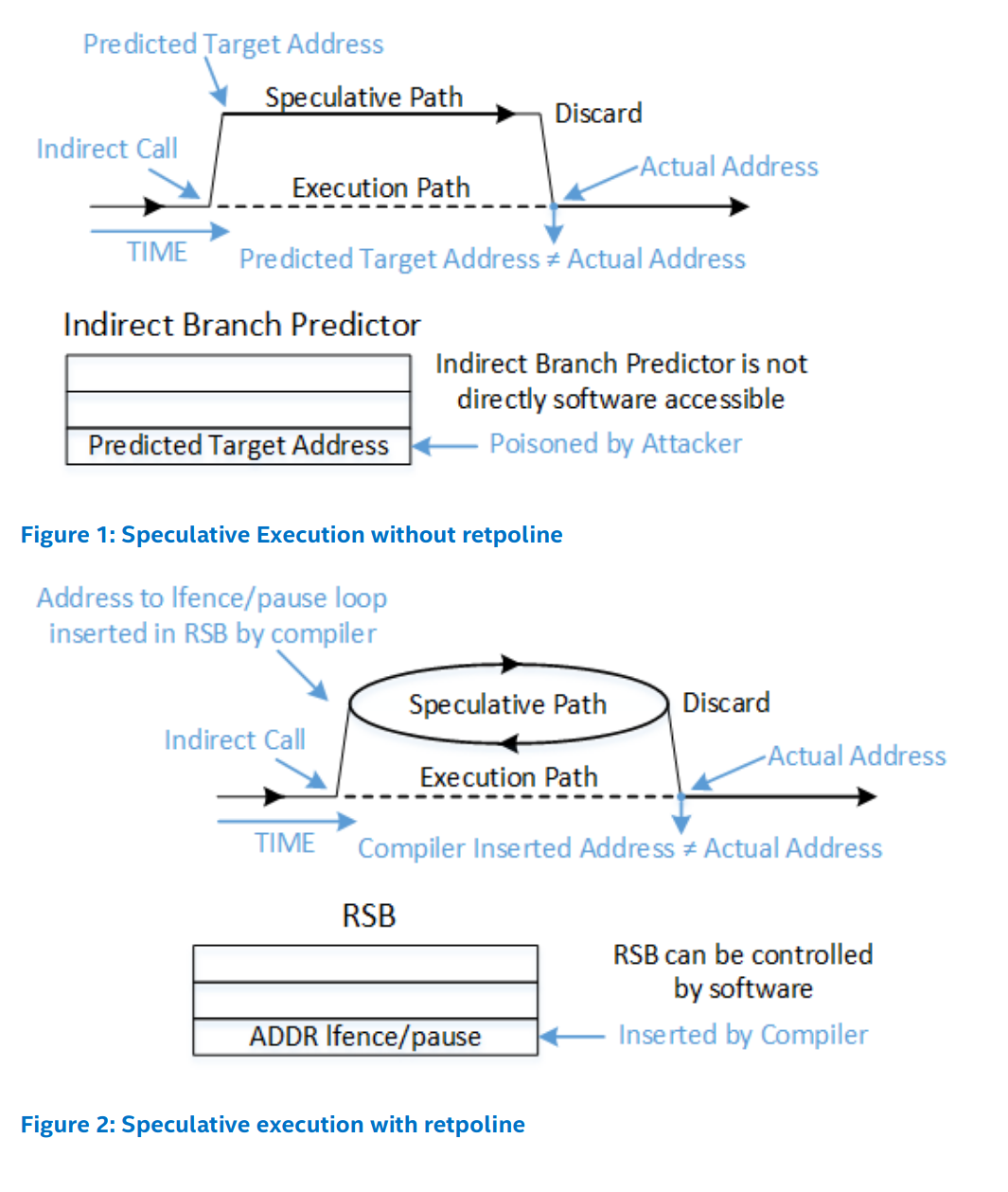
retpoline的工作原理是將間接控制流從間接分支轉換為間接返回(indirect return),因此在retpoline中有“ret”(返回)這個名稱。返回指令也會被預測,但是有一個額外的機制具有優先級,即返回堆棧緩沖區(Return Stack Buffer,RSB)。為了確保RSB不能被惡意訓練以遠離無限循環,retpoline以直接的CALL指令開始,這個CALL指令會預測RSB始終預測無限循環。
以下是間接調用retpoline的實際情況,從內核源代碼中進行了顯著簡化:
__x86_retpoline_rax:call .Ldo_rop_0
.Lspec_trap_0:pauselfencejmp .Lspec_trap_0
.Ldo_rop_0:mov [rsp], raxret
…所有這些都是為了取代一個簡單的調用[rax]!
Consequences
這種技巧會產生一些不良影響:
(1)當預測正確時,速度較慢:我們用至少兩個直接的CALL指令和一個RET指令替換了一個間接的CALL指令。
(2)當預測錯誤時,速度非常慢:我們使用PAUSE和LFENCE指令在原地旋轉。
(3)它是一個ROP(Return-Oriented Programming)小工具,因此看起來像是一種利用原語。這意味著它會影響到英特爾的CET(Control-flow Enforcement Technology)和其他平臺上類似的保護機制。英特爾聲稱新的硬件將支持“增強型IBRS”(enhanced IBRS),這將完全取代對retpolines的需求,從而可以使用CET。
(4)即使像上面那樣簡化,它仍然很難閱讀和理解:完整的緩解措施還需要處理間接跳轉、RSB填充和其他許多技巧,這些技巧是在最初的Spectre v2漏洞之后被發現的。
因此,retpoline 并沒有比原始的 Spectre 緩解措施好多少。
讓我們看看Linux 5.10在消除一些這些問題方面所做的工作,即Static calls機制。
2.4 Static calls
讓我們來了解一下這種新的"靜態調用"(static call)技術。以下是來自Josh Poimboeuf的補丁系列的API:
/* declare or define a new static call as `name`,* initially associated with `func`*/
DECLARE_STATIC_CALL(name, func);
DEFINE_STATIC_CALL(name, func);/* invoke `name` with `args` */
static_call(name)(args...);/* invoke `name` with `args` if not NULL */
static_call_cond(name)(args...);/* update the underlying function */
static_call_update(name, func);
這里是從perf中摘錄的一個示例(經過縮減和注釋):
static void _x86_pmu_add(struct perf_event *event) { }/* ... */
DEFINE_STATIC_CALL(x86_pmu_add, _x86_pmu_add);static void x86_pmu_static_call_update(void) {/* ... */static_call_update(x86_pmu_add, x86_pmu.add);/* ... */
}static int __init init_hw_perf_events(void) {/* ... */x86_pmu_static_call_update();/* ... */
}
總結一下:
(1)定義了一個空的靜態函數_x86_pmu_add。
(2)使用DEFINE_STATIC_CALL宏將_x86_pmu_add命名為x86_pmu_add。
(3)定義了一個輔助函數x86_pmu_static_call_update。
輔助函數使用static_call_update來修改x86_pmu_add的底層函數,將其替換為x86_pmu.add(一個函數指針)。
(4)最后,__init函數init_hw_perf_events調用了這個靜態調用的輔助函數。
結果是,之前的代碼:
if (x86_pmu.add) {x86_pmu.add(event);
}
現在變為:
static_call_cond(x86_pmu_add)(event);
這樣看起來非常簡潔,并且(顯然)避免了使用retpoline!讓我們了解一下為什么以及如何實現這種效果。
How it works
(1)Step 1: DEFINE_STATIC_CALL
在x86上,DEFINE_STATIC_CALL(x86_pmu_add,_x86_pmu_add)大致擴展為:
extern struct static_call_key __SCK__x86_pmu_add;
extern typeof(_x86_pmu_add) __SCT__x86_pmu_add_tramp;struct static_call_key __SCK__x86_pmu_add = {.func = _x86_pmu_add,
};ARCH_DEFINE_STATIC_CALL_TRAMP(x86_pmu_add, _x86_pmu_add);
ARCH_DEFINE_STATIC_CALL_TRAMP:
#define __ARCH_DEFINE_STATIC_CALL_TRAMP(name, insns) \asm(".pushsection .static_call.text, \"ax\" \n" \".align 4 \n" \".globl " STATIC_CALL_TRAMP_STR(name) " \n" \STATIC_CALL_TRAMP_STR(name) ": \n" \insns " \n" \".type " STATIC_CALL_TRAMP_STR(name) ", @function \n" \".size " STATIC_CALL_TRAMP_STR(name) ", . - " STATIC_CALL_TRAMP_STR(name) " \n" \".popsection \n")#define ARCH_DEFINE_STATIC_CALL_TRAMP(name, func) \__ARCH_DEFINE_STATIC_CALL_TRAMP(name, ".byte 0xe9; .long " #func " - (. + 4)")
ARCH_DEFINE_STATIC_CALL_TRAMP是一個宏,用于定義靜態調用的跳轉函數。它展開為__ARCH_DEFINE_STATIC_CALL_TRAMP宏。
__ARCH_DEFINE_STATIC_CALL_TRAMP宏是一個特定于體系結構的宏,它生成匯編代碼來定義靜態調用的跳轉函數。它使用內聯匯編來創建一個名為".static_call.text"的節(section),并使用指定的匯編指令(insns)來定義跳轉函數。匯編指令通常包括一個相對跳轉指令(jmp),用于跳轉到由func參數指定的目標函數。
具體來說,展開后的代碼會將跳轉函數的匯編代碼插入到".static_call.text"節中。跳轉函數的名稱由name參數確定,使用STATIC_CALL_TRAMP_STR宏進行字符串化。匯編代碼包括一條".byte 0xe9"指令,表示相對跳轉指令(jmp)的操作碼,后跟".long " #func " - (. + 4)",表示跳轉目標相對于當前指令的偏移量。
擴展(通過重新格式化)為:
.pushsection .static_call.text, "ax".align 4.globl "__SCT__x86_pmu_add_tramp"
"__SCT__x86_pmu_add_tramp":.byte 0xe9.long _x86_pmu_add - (. + 4).type "__SCT__x86_pmu_add_tramp", @function.size "__SCT__x86_pmu_add_tramp", . - "__SCT__x86_pmu_add_tramp".popsection
.byte 0xe9:relative JMP
0xE9(E9 cd) :Jump near 后面的4個字節是偏移:一個保存jmp本身的機器碼,另4個保存偏移 -->總共5個字節
具體來說,它是一個到由.long _x86_pmu_add-(.+4)計算的地址的JMP,這是“_x86_pmu_add的地址,減去當前地址(由.表示),再加4”的丑陋GAS語法。
JMP是5字節(1字節操作碼,4字節)的位移,所以。+4讓我們在完成整個指令后立即進入RIP。
所以這只是我們靜態調用的設置。讓我們看看我們是如何實際安裝帶有static_call_update的函數的。
(2)Step 2: static_call_update
以下是static_call_update(x86_pmu_add,x86_pmu.add)的展開:
({BUILD_BUG_ON(!__same_type(*(x86_pmu.add), __SCT__x86_pmu_add_tramp));__static_call_update(&__SCK__x86_pmu_add, &__SCT__x86_pmu_add_tramp, x86_pmu.add);
})
在這段代碼中,static_call_update(x86_pmu_add, x86_pmu.add)調用了__static_call_update函數來更新靜態調用。
__static_call_update函數的實現如下:
static inline
void __static_call_update(struct static_call_key *key, void *tramp, void *func) {cpus_read_lock();WRITE_ONCE(key->func, func);arch_static_call_transform(NULL, tramp, func, false);cpus_read_unlock();
}
該函數的作用是更新靜態調用的函數指針。它接受三個參數:key表示靜態調用的鍵(key),tramp表示跳轉函數的地址,func表示要安裝的新函數的地址。
函數的執行過程如下:
(1)首先,通過調用cpus_read_lock()函數獲取對CPU的讀鎖。這可能是為了確保在更新靜態調用期間不會發生競爭條件。
(2)接下來,使用WRITE_ONCE宏將新函數的地址寫入靜態調用的函數指針。WRITE_ONCE宏是一種用于進行原子寫操作的技術,確保指針的寫入是原子的,以防止并發訪問問題。
(3)然后,調用arch_static_call_transform函數,該函數是體系結構特定的函數,用于轉換靜態調用。它可能執行一些特定于體系結構的操作,以確保跳轉函數正確地跳轉到新函數。
(4)最后,通過調用cpus_read_unlock()函數釋放CPU的讀鎖。
接下來是WRITE_ONCE宏定義的部分:
#define __WRITE_ONCE(x, val) \
do { \*(volatile typeof(x) *)&(x) = (val); \
} while (0)#define WRITE_ONCE(x, val) \
do { \compiletime_assert_rwonce_type(x); \__WRITE_ONCE(x, val); \
} while (0)
實際上,這只是對具有原子性的類型進行了一個帶有volatile限定符的賦值操作。
接下來是arch_static_call_transform函數:
void arch_static_call_transform(void *site, void *tramp, void *func, bool tail)
{mutex_lock(&text_mutex);if (tramp) {__static_call_validate(tramp, true);__static_call_transform(tramp, __sc_insn(!func, true), func);}if (IS_ENABLED(CONFIG_HAVE_STATIC_CALL_INLINE) && site) {__static_call_validate(site, tail);__static_call_transform(site, __sc_insn(!func, tail), func);}mutex_unlock(&text_mutex);
}
mutex_lock和mutex_unlock只是為了確保沒有其他人在修改內核的指令文本。同時,我們也在cpus_read_lock將我們的操作與CPU的熱插拔或移除進行了序列化。
在本文中,我不會討論CONFIG_HAVE_STATIC_CALL_INLINE,因為它與普通的靜態調用機制非常相似,但是有更多的組件。因此,我們將假設該配置為false,并且該代碼未編譯。
__sc_insn函數將兩個布爾值(func和tail)映射到insn_type枚舉類型。兩個布爾值意味著兩個位,也就是說有四種可能的insn_type狀態:
enum insn_type {CALL = 0, /* site call */NOP = 1, /* site cond-call */JMP = 2, /* tramp / site tail-call */RET = 3, /* tramp / site cond-tail-call */
};static inline enum insn_type __sc_insn(bool null, bool tail)
{/** Encode the following table without branches:** tail null insn* -----+-------+------* 0 | 0 | CALL* 0 | 1 | NOP* 1 | 0 | JMP* 1 | 1 | RET*/return 2*tail + null;
}
這將出現在測試中。
這將引入__static_call_validate函數,它驗證我們的trampoline(跳板):
static void __static_call_validate(void *insn, bool tail)
{u8 opcode = *(u8 *)insn;if (tail) {if (opcode == JMP32_INSN_OPCODE ||opcode == RET_INSN_OPCODE)return;} else {if (opcode == CALL_INSN_OPCODE ||!memcmp(insn, ideal_nops[NOP_ATOMIC5], 5))return;}/** If we ever trigger this, our text is corrupt, we'll probably not live long.*/WARN_ONCE(1, "unexpected static_call insn opcode 0x%x at %pS\n", opcode, insn);
}
請記住:對于我們來說,tail始終為true,因為我們沒有啟用CONFIG_HAVE_STATIC_CALL_INLINE。因此,insn始終是tramp,你可能還記得它是__SCT__x86_pmu_add_tramp,帶有.byte 0xe9。
最后,__static_call_transform函數是真正發生魔法的地方(稍微精簡了一下):
static void __ref __static_call_transform(void *insn, enum insn_type type, void *func)
{int size = CALL_INSN_SIZE;const void *code;switch (type) {case CALL:code = text_gen_insn(CALL_INSN_OPCODE, insn, func);break;case NOP:code = ideal_nops[NOP_ATOMIC5];break;case JMP:code = text_gen_insn(JMP32_INSN_OPCODE, insn, func);break;case RET:code = text_gen_insn(RET_INSN_OPCODE, insn, func);size = RET_INSN_SIZE;break;}if (memcmp(insn, code, size) == 0)return;if (unlikely(system_state == SYSTEM_BOOTING))return text_poke_early(insn, code, size);text_poke_bp(insn, code, size, NULL);
}
記得__sc_insn嗎(我告訴過你!):對于我們來說,tail始終為true,因此我們唯一的選擇是(1, 0)和(1, 1),即JMP和RET。這一點(再次)稍后會有影響,但是兩種情況下的代碼幾乎相同,因此我們可以忽略差異。
在這兩種情況下,我們調用text_gen_insn函數,它是世界上最簡單的JIT12(稍微精簡了一下):
union text_poke_insn {u8 text[POKE_MAX_OPCODE_SIZE];struct {u8 opcode;s32 disp;} __attribute__((packed));
};static __always_inline
void *text_gen_insn(u8 opcode, const void *addr, const void *dest)
{static union text_poke_insn insn; /* per instance */int size = text_opcode_size(opcode);insn.opcode = opcode;if (size > 1) {insn.disp = (long)dest - (long)(addr + size);if (size == 2) {BUG_ON((insn.disp >> 31) != (insn.disp >> 7));}}return &insn.text;
}
因此,我們的目標(即x86_pmu.add)成為了相對位移,就像我們在編譯時生成的thunk中一樣。
其余部分是機制:根據系統狀態調用text_poke_early或text_poke_bp,但效果是相同的:我們的跳板(__SCT__x86_pmu_add_tramp)在內核內存中實際上被重寫為:
jmp _x86_pmu_add
to:
jmp x86_pmu.add
…或者我們希望的任何其他函數,當然要允許類型匹配!
(3)Step 3: static_call_cond
最后,讓我們弄清楚如何調用這個函數。
我們的實際調用是static_call_cond(x86_pmu_add)(event),就像名稱所暗示的那樣,在調用底層跳板之前應該進行一次檢查,對嗎?
#define static_call(name) __static_call(name)
#define static_call_cond(name) (void)__static_call(name)
這里定義了兩個宏。static_call宏用于直接調用靜態函數,而static_call_cond宏用于在調用之前進行條件檢查,但忽略返回值。
好的!讓我們再來看一下那個小小的__sc_insn表生成器:如果我們底層調用為NULL,那么我們已經生成并JIT了一個簡單的RET指令到我們的跳板中。
現在讓我們看一下__static_call宏的展開實際上是什么樣的:
({__ADDRESSABLE(__SCK__x86_pmu_add);&__SCT__x86_pmu_add_tramp;
})
(__ADDRESSABLE只是另一種編譯器的技巧,用于確保__SCK__x86_pmu_add保留在符號表中)。
這就是全部內容:我們實際的static_call宏最終調用了__SCT__x86_pmu_add_tramp,它要么是一個將我們引導到真實調用的跳板,要么只是一個RET指令,從而完成調用。
換句話說,匯編代碼看起來有兩種情況:
call __SCT__x86_pmu_add_tramp
; in call + trampoline
jmp x86_pmu.add
; out of trampoline, in target (x86_pmu.add)
; target eventually returns, completing the call
or:
call __SCK__x86_pmu_add
; in call + "trampoline"
ret ; "trampoline" returns, completing the call
三、其他
每個 static_call() 位置都調用與名稱關聯的跳板。跳板有一個直接跳轉到默認函數。對名稱的更新將修改跳板的跳轉目標。
如果架構具有 CONFIG_HAVE_STATIC_CALL_INLINE,則調用站點本身將在運行時被修補為直接調用函數,而不是通過跳板調用。這需要 objtool 或編譯器插件來檢測所有 static_call() 位置并在 .static_call_sites 節中注釋它們。
對于CONFIG_HAVE_STATIC_CALL_INLINE,按行計數該變更集占了相當大的比例。這是一種更加激進的轉換方式:不是重新編寫跳板,而是將每個調用跳板的調用點都重寫為直接調用跳板的目標函數。這樣可以節省一個JMP指令,據說這個性能差異足以成為一個單獨的可配置特性。
更新:Peter Zijlstra解釋說,CONFIG_HAVE_STATIC_CALL_INLINE的性能優勢主要來自于減少的指令緩存壓力:因為跳板是無條件的,CPU將始終預取它,占用一個緩存行。避免這種預取可以帶來可衡量的性能提升!
我不確定WRITE_ONCE(__SCK__x86_pmu_add->func, x86_pmu.add)實際上起到了什么作用:它將函數指針的副本存儲在我們的static_call_key中,但我們實際上從未使用過它(因為我們總是調用跳板,它直接在其中修補了函數的相對位移)。調用這個指針會破壞靜態調用的整個目的,因為它將成為一個間接分支。有經驗的猜測是:它只適用于!CONFIG_HAVE_STATIC_CALL情況,該情況下使用了通用的間接實現。但是,當我們有一個真正的靜態調用實現可用時,為什么不完全摒棄static_call_key呢?
更新:Peter也解釋了這一點:它只對!CONFIG_HAVE_STATIC_CALL情況有用。特別是,它防止編譯器將存儲拆分成多個存儲。
我認為這里還有改進的空間,特別是放寬一些鎖定要求:最大文本修補大小在POKE_MAX_OPCODE_SIZE == 5中硬編碼,應該可以舒適地在x86_64上使用WRITE_ONCE進行原子寫入。換句話說,我不確定為什么需要cpus_read_lock和對文本的鎖定,盡管可能是我想得太簡單了。
更新:顯然,在評審過程中考慮過這一點。問題是:它引入了對齊要求,這反過來需要將NOP指令注入到指令流中。這又增加了指令緩存壓力,破壞了性能優勢。此外,對于這一點,Intel和AMD的規范不夠明確也存在一些擔憂。
參考資料
https://blog.yossarian.net/2020/12/16/Static-calls-in-Linux-5-10

-指針)



+根號下(b+3) 的最大值為?(2015重慶卷))












![[vue2/vue3] 詳細剖析watch、computed、watchEffect的區別,原理解讀](http://pic.xiahunao.cn/[vue2/vue3] 詳細剖析watch、computed、watchEffect的區別,原理解讀)
