在當今快節奏的數字世界中,性能優化對于提供無縫的用戶體驗至關重要。緩存在提高應用程序性能方面發揮著至關重要的作用,它通過將經常使用或處理的數據存儲在臨時高速存儲中來減少數據庫負載并縮短響應時間,從而減少系統的延遲。Redis 是一種流行的內存數據存儲,它提供了強大的緩存解決方案,可以顯著提高應用程序的速度和效率。
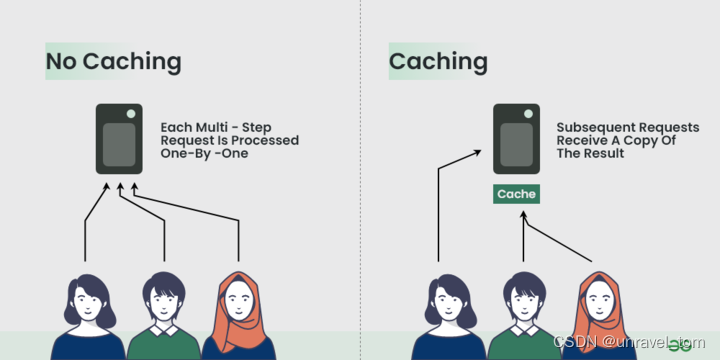
在深入研究 Redis 緩存之前,讓我們先了解緩存的基礎知識。緩存涉及將經常訪問或計算成本高昂的數據存儲在快速且易于訪問的位置(例如內存)中,以加快后續請求的速度。通過將數據存儲在緩存中,應用程序可以避免從速度較慢的數據源(如數據庫或外部 API)獲取數據的需要,從而縮短響應時間并減少服務器負載。
Redis就像是一個超級快的小助手,站在數據庫和應用程序之間(可以類比CPU,緩存,內存): Redis把數據存在內存里,就像把常用的東西放在手邊一樣,取用起來超快。相比之下,數據庫就像是要去倉庫找東西,慢很多。
使用 Redis 緩存時,請務必考慮以下內容:
確定要緩存的正確數據:并非所有數據都需要緩存。專注于緩存經常訪問或生成計算成本高昂的數據。這包括不經常更改或可以在多個請求之間共享的數據。
設置過期策略:為緩存的數據確定適當的過期策略。這可確保緩存保持最新狀態,并避免提供過時的數據。根據數據更新的頻率和緩存數據所需的新鮮度設置過期時間。
實現緩存失效:當基礎數據發生變化時,必須使相應的緩存條目失效或更新。這可以通過使用緩存失效觸發器或監視數據源中的更改等技術來完成。
監控緩存性能:定期監控緩存性能,確保其有效性。密切關注緩存命中率、緩存未命中率和整體緩存利用率。監控可以幫助識別潛在的瓶頸或需要優化的領域。
針對高流量擴展 Redis:隨著應用程序流量的增長,請考慮擴展 Redis 以處理增加的負載。這可能涉及使用 Redis 集群或復制在多個實例之間分配數據并提高讀取和寫入吞吐量。
緩存策略
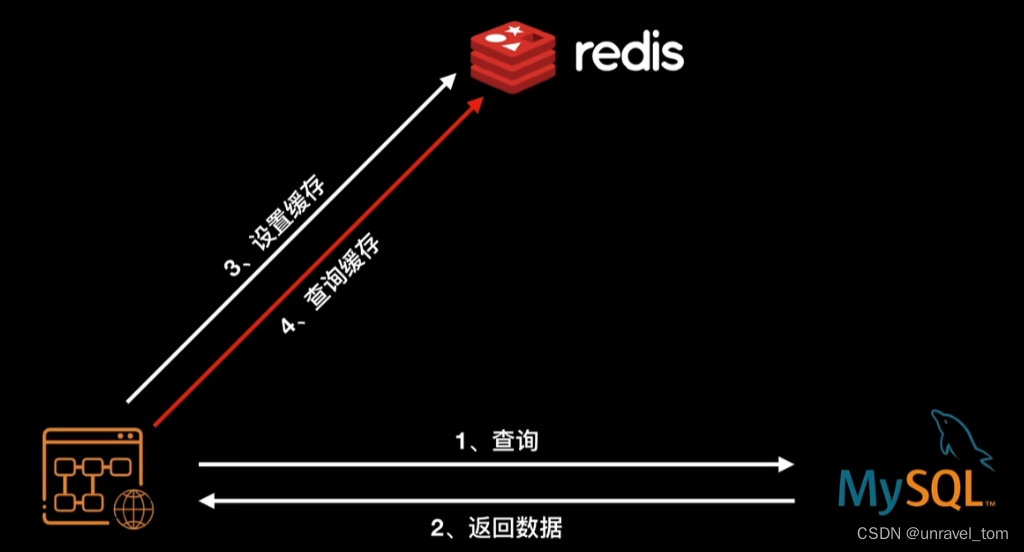
a) 讀取數據時:
- 應用程序先問Redis:"嘿,你有這個數據嗎?"
b) 寫入數據時:
- 如果Redis說"有",應用程序就直接用了,省去了問數據庫的時間。
- 如果Redis說"沒有",應用程序就去數據庫拿,然后告訴Redis:"保存一下,下次可能用得著。"
- 應用程序更新數據庫,然后告訴Redis:"嘿,數據更新了,你也更新一下。"
Redis的緩存策略主要涉及如何有效地管理緩存數據,以及如何保持緩存與數據源的一致性。讓我們通過幾個主要的緩存策略來深入了解:
1. Cache-Aside(旁路緩存)
想象Redis是一個效率極高的助手,而數據庫是一個大型檔案室。
工作流程:
- 讀取數據:應用先查Redis,沒有則去數據庫取,然后放入Redis。
- 寫入數據:先更新數據庫,再刪除Redis中的對應鍵。
比喻:你想找一份文件。首先問助手(Redis)有沒有,如果沒有,你就去檔案室(數據庫)找,找到后給助手一份副本。當你需要更新文件時,先更新檔案室的原件,然后告訴助手丟掉手中的舊副本。
優點:實現簡單,Redis掛掉不影響系統正常運行。保證數據一致性。
缺點:第一次訪問數據時會比較慢(稱為"緩存穿透")。
2. Read/Write Through(讀寫穿透)
想象Redis現在變成了一個聰明的管家,所有的數據請求都必須經過他。
工作流程:
- 讀取數據:應用只和Redis交互,如果Redis沒有數據,Redis負責從數據庫讀取并緩存。
- 寫入數據:應用把數據寫入Redis,Redis負責同步更新到數據庫。
比喻:你需要任何文件都告訴管家(Redis)。如果管家沒有,他會去檔案室(數據庫)取,然后保存一份。當你要更新文件時,你把新文件交給管家,由他負責更新檔案室。
優點:對應用層透明,應用不需要關心緩存的細節。數據一致性好。
缺點:增加了Redis的復雜度。可能會帶來一定的性能損失。
3. Write-Behind Caching(異步寫入)
把Redis想象成一個能暫存數據的智能助理。
工作流程:
- 讀取數據:與Read Through相同。
- 寫入數據:數據寫入Redis后立即返回,Redis異步地將數據更新到數據庫。
比喻:你把所有更新的文件都交給助理(Redis)。助理先記錄下來,然后在空閑時統一更新到檔案室(數據庫)。
優點:寫操作性能高。可以合并多次寫操作,減少數據庫壓力。
缺點:
數據丟失風險高,Redis宕機可能導致未同步的數據丟失。
數據一致性較弱,可能出現Redis和數據庫數據不一致的情況。
4. 預加載策略
將Redis視為一個預習室。
工作流程:在系統啟動或者定時任務中,主動將熱點數據加載到Redis中。
比喻:在開始工作前,助理(Redis)主動去檔案室(數據庫)取出可能會用到的文件,放在手邊以備不時之需。
優點:可以提前準備熱點數據,提高訪問速度。減少緩存穿透的情況。
缺點:需要提前預測熱點數據,如果預測不準確可能會浪費資源。
5. 多級緩存策略
將Redis作為多級緩存系統中的一環。
工作流程:
構建本地緩存(如應用服務器的內存) -> Redis -> 數據庫的多級緩存架構。
比喻:你的辦公室有個小抽屜(本地緩存),辦公室外有個文件柜(Redis),大樓里有個檔案室(數據庫)。你會先看抽屜,然后是文件柜,最后才去檔案室。
優點:進一步提高數據訪問速度。減輕Redis的壓力。
缺點:增加了系統復雜度。多級緩存一致性維護變得更加困難。
選擇哪種緩存策略取決于你的具體需求,如對數據一致性的要求、系統的讀寫比例、性能需求等。在實際應用中,常常會綜合使用多種策略來達到最佳效果。
redis把登入的數據都登錄在了緩存內存中,避免了浪費時間的IO操作,但是隨著數據量的增加redis存儲的數據也會越來越多,所以接下來引入了過期策略
過期策略
設置過期策略:為緩存的數據確定適當的過期策略。這可確保緩存保持最新狀態,并避免提供過時的數據。根據數據更新的頻率和緩存數據所需的新鮮度設置過期時間。
Redis不會永遠保存所有數據,它會給數據設置"保質期"。
- 就像冰箱里的食物,過期了就自動扔掉。
- 這樣可以保證Redis里always存著新鮮的數據。
Redis 主要使用三種策略來管理過期的鍵:定時刪除、惰性刪除和內存淘汰。讓我們用簡單的比喻來理解這些概念。
1. 定時刪除(主動刪除)
想象 Redis 是一個圖書管理員,而鍵就是借出去的書。
- 工作原理:Redis 會為每個設置了過期時間的鍵都創建一個定時器,一旦到期,就立即刪除。
- 比喻:圖書管理員給每本借出去的書都設置了一個鬧鐘。鬧鐘一響,他就立即去找到這本書并將其下架。
- 優點:內存友好,過期鍵能被及時刪除。
- 缺點:CPU 不友好,可能會占用大量 CPU 時間去處理過期鍵。
實際上,Redis 用的是一種折中的策略:每秒進行 10 次過期鍵的檢查,每次隨機檢查一些設置了過期時間的鍵,刪除其中已過期的。
2. 惰性刪除(被動刪除)
想象 Redis 現在變成了一個懶惰的圖書管理員。
- 工作原理:Redis 不主動刪除過期鍵,只有當你嘗試訪問一個鍵的時候,才會檢查它是否過期,如果過期了就刪除。
- 比喻:圖書管理員不主動檢查書的借閱期。只有當有人來借書時,他才會檢查這本書是否已經過期,如果過期了就將其下架。
- 優點:CPU 友好,不會浪費 CPU 時間去檢查未被使用的過期鍵。
- 缺點:內存不友好,過期的鍵可能會在很長一段時間內占用內存。
3. 內存淘汰(內存不足時的被動刪除)
想象 Redis 是一個書架空間有限的圖書館管理員。
- 工作原理:當 Redis 的內存不足以容納新的數據時,會根據選定的淘汰策略來刪除一些鍵,為新數據騰出空間。
- 比喻:當書架快滿時,圖書管理員會根據某種規則(比如最少使用、最近最少使用等)來決定哪些書要被移除,以便放入新書。
Redis 提供了幾種內存淘汰策略:
a) noeviction:不淘汰任何數據,當內存不足時直接報錯。
比喻:書架滿了就不再接受新書,并告訴借書人"對不起,沒位置了"。
b) allkeys-lru:從所有鍵中驅逐使用頻率最少的鍵。
比喻:移除最長時間沒人看過的書。
c) volatile-lru:從設置了過期時間的鍵中驅逐使用頻率最少的鍵。
比喻:只在有"借閱期限"的書中,移除最長時間沒人看過的書。
d) allkeys-random:隨機驅逐鍵。
比喻:隨機選擇書本移除。
e) volatile-random:從設置了過期時間的鍵中隨機驅逐。
比喻:在有"借閱期限"的書中隨機選擇移除。
f) volatile-ttl:驅逐快要過期的鍵。
比喻:優先移除快到"借閱期限"的書。
g) volatile-lfu 和 allkeys-lfu(Redis 4.0 新增):驅逐使用頻率最低的鍵。
比喻:移除借閱次數最少的書。
實際應用中,Redis 會綜合使用這些策略。定時刪除和惰性刪除是主要的過期鍵處理方式,而內存淘汰策略則是在內存緊張時的一種補充措施。選擇合適的策略需要根據實際應用場景和需求來權衡。
緩存問題及它們的解決方案
1. 緩存擊穿(Cache Penetration)
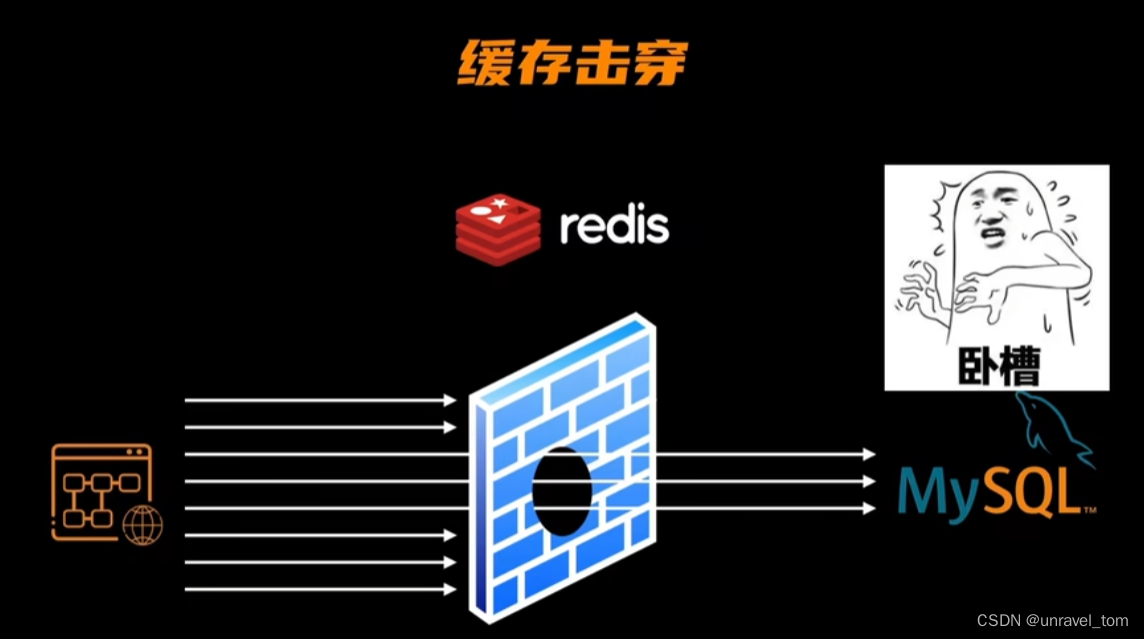
概念:
緩存擊穿指的是對于一個特定的高頻熱點key,在緩存過期的一刻,同時有大量的請求到達,這些請求同時發現緩存過期,于是同時去數據庫中查詢數據,導致數據庫瞬間壓力劇增。
比喻:
想象一個熱門商品在電商平臺上的緩存剛好過期,而此時正值促銷高峰,大量用戶同時刷新頁面,導致所有請求都直接沖向數據庫。
解決方案:
a) 互斥鎖(Mutex Key)
? ?- 原理:第一個請求獲取鎖并從數據庫加載數據,其他請求等待。
? ?- 實現:使用Redis的SetNX命令,成功設置則獲取鎖。
? ?- 優點:簡單有效,保證只有一個請求會穿透到數據庫。
? ?- 缺點:可能會造成某些請求的等待時間較長。
b) 設置熱點數據永不過期
? ?- 原理:對于某些特別熱點的數據,設置一個較長的過期時間或干脃不設置過期時間。
? ?- 實現:定期異步更新這些熱點數據。
? ?- 優點:能有效防止緩存擊穿。
? ?- 缺點:維護成本較高,需要額外的更新機制。
c) 提前更新緩存
? ?- 原理:在緩存即將過期前,異步更新緩存。
? ?- 實現:設置一個緩存刷新線程,檢測即將過期的key并提前更新。
? ?- 優點:能有效避免緩存過期瞬間的壓力。
? ?- 缺點:實現相對復雜,需要額外的系統資源。
2. 緩存雪崩(Cache Avalanche)
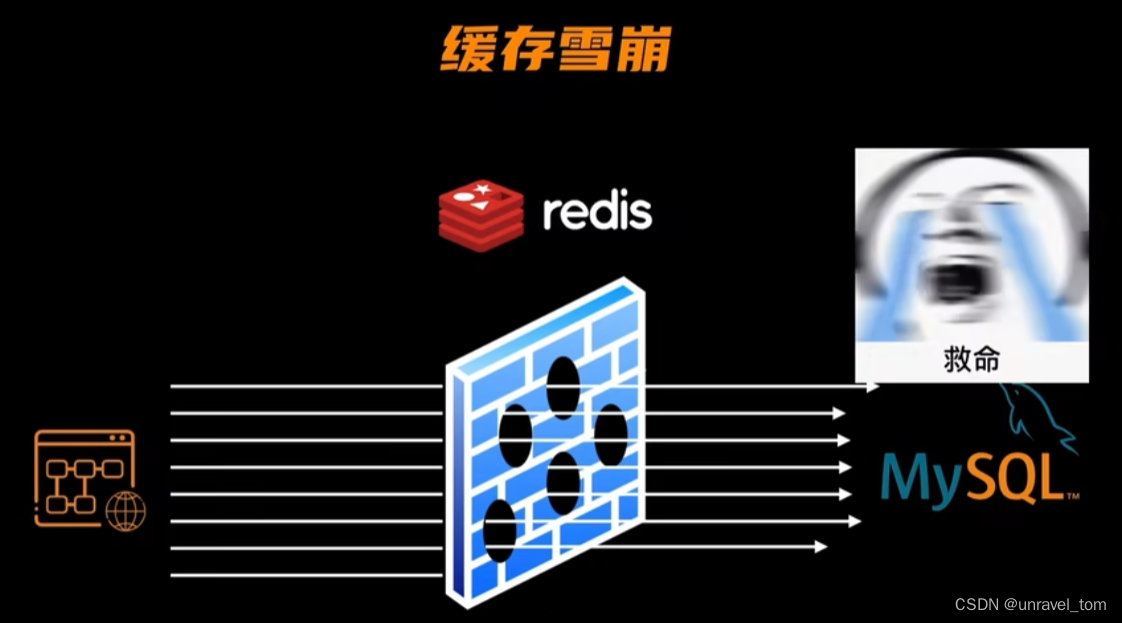
概念:
緩存雪崩指的是大量緩存數據在同一時間集中過期,或者緩存服務器宕機,導致大量請求直接落到數據庫上,引起數據庫壓力驟增,可能導致整個系統崩潰。
比喻:
想象一場大型促銷活動結束,所有商品的緩存同時失效,或者Redis服務器突然宕機,導致所有的請求如雪崩般沖向數據庫。
解決方案:
a) 均勻分布過期時間
? ?- 原理:在設置緩存過期時間時加入一個隨機值,避免大量緩存同時過期。
? ?- 實現:過期時間 = 基礎過期時間 + random(0, 300秒)
? ?- 優點:簡單有效,易于實現。
? ?- 缺點:可能會稍微增加緩存不一致的概率。
b) 構建高可用的緩存集群
? ?- 原理:使用Redis Cluster或者哨兵模式,確保緩存系統的高可用性。
? ?- 實現:配置主從復制,并使用哨兵監控和自動故障轉移。
? ?- 優點:大大提高系統的可用性和穩定性。
? ?- 缺點:增加了系統復雜度和維護成本。
c) 設置多級緩存
? ?- 原理:在Redis之上再增加一層本地緩存(如Guava Cache)。
? ?- 實現:請求首先訪問本地緩存,miss后再訪問Redis。
? ?- 優點:即使Redis完全不可用,系統仍能提供部分服務。
? ?- 缺點:增加了系統復雜度,且可能帶來數據一致性問題。
d) 熔斷降級機制
? ?- 原理:當檢測到緩存服務不可用時,暫時屏蔽部分非核心功能,只提供最基本的服務。
? ?- 實現:使用類似Hystrix這樣的熔斷框架。
? ?- 優點:能夠保護系統核心功能,防止整體崩潰。
? ?- 缺點:會暫時降低用戶體驗。
e) 預加載熱點數據
? ?- 原理:系統啟動時或者定時任務中提前加載熱點數據到緩存。
? ?- 實現:編寫腳本或定時任務,定期刷新熱點數據的緩存。
? ?- 優點:可以有效減少緩存雪崩的影響范圍。
? ?- 缺點:需要額外的維護成本,且可能會占用更多的緩存空間。
在實際應用中,通常會綜合使用多種策略來防范緩存擊穿和緩存雪崩。選擇哪種方案或組合要根據具體的業務場景、系統架構和性能需求來決定。同時,良好的監控和告警機制也是必不可少的,可以幫助我們及時發現并解決問題。
3.?緩存失效(?Cache Invalidation)
1. 避免緩存失效
a) 定時刷新策略
- 原理:定期更新緩存中的數據,不依賴于單個數據變更。
- 優點:簡單可靠,適合變更頻率較低的數據。
- 缺點:可能存在短暫的數據不一致。
b) 基于消息隊列的實時更新
- 原理:數據變更時發送消息,專門的服務消費消息并更新緩存。
- 優點:實時性高,系統解耦。
- 缺點:需要額外的消息中間件,增加系統復雜度。
c) 雙寫一致性(Write-Behind)
- 原理:更新數據時同時更新緩存和數據庫,通過異步隊列保證最終一致性。
- 優點:保證緩存和數據庫的最終一致性。
- 缺點:實現復雜,需要處理各種異常情況。
2. 緩存監測方法
a) 健康檢查
- 原理:定期檢查緩存服務的可用性和響應時間。
- 作用:及時發現緩存服務的異常。
b) 緩存命中率監控
- 原理:統計緩存的命中次數和未命中次數,計算命中率。
- 作用:評估緩存效率,指導緩存策略優化。
c) 過期鍵監控
- 原理:監控即將過期或已過期的鍵數量。
- 作用:預防大規模緩存失效,避免緩存雪崩。
d) 內存使用監控
- 原理:監控Redis的內存使用情況。
- 作用:防止內存溢出,指導容量規劃。
e) 慢查詢日志分析
- 原理:分析Redis的慢查詢日志,找出性能瓶頸。
- 作用:優化緩存查詢性能,改進緩存策略。
參考
Redis Cache - GeeksforGeeks
【趣話Redis第一彈】我是Redis,MySQL大哥被我坑慘了!_嗶哩嗶哩_bilibili

![[vue2/vue3] 詳細剖析watch、computed、watchEffect的區別,原理解讀](http://pic.xiahunao.cn/[vue2/vue3] 詳細剖析watch、computed、watchEffect的區別,原理解讀)






)










