基本概念
哈希表(HashTable)是一個重要的底層數據結構, 無序關聯容器包括unordered_set, unordered_map內部都是基于哈希表實現。
- 哈希表是一種通過哈希函數將鍵映射到索引的數據結構,存儲在內存空間中。
- 哈希函數負責將任意大小的輸入映射到固定大小的輸出,即哈希值。這個哈希值用作在數組中存儲鍵值對的索引。
用途
那么哈希表能解決什么問題呢,一般哈希表都是用來快速判斷一個元素是否出現集合里。
例如要查詢一個名字是否在這所學校里。
要枚舉的話時間復雜度是O(n),但如果使用哈希表的話, 只需要O(1)就可以做到。
我們只需要初始化把這所學校里學生的名字都存在哈希表里,在查詢的時候通過索引直接就可以知道這位同學在不在這所學校里了。
將學生姓名映射到哈希表上就涉及到了hash function ,也就是哈希函數。
沖突解決
由于哈希函數的映射不是一對一的,可能會出現兩個不同的鍵映射到相同的索引,即沖突。可以使用鏈地址法解決沖突,即在哈希表的每個槽中維護一個鏈表,將哈希值相同的元素存儲在同一個槽中的鏈表中。
哈希表的擴容與rehashing
為了避免哈希表中鏈表過長導致性能下降,會在需要時進行擴容。
擴容過程涉及到重新計算所有元素的哈希值,并將它們分布到新的更大的哈希表中。這一過程稱為rehashing。
思路
class HashNode{
public:Key key;Value value;......;
}using Bucket = std::list<HashNode>;
std::vector<Bucket> buckets; // 定義由多個槽連續組成的數組
在上述代碼中,我們會定義以下幾個變量名,它們的意義如下圖所示:
- HashNode表示鏈表的一個節點
- Bucket表示一個桶,桶里面裝的是鏈表,實際上因為沖突,桶里面的鏈表往往只有一個節點
- buckets表示系統開辟一塊塊Bucket大小的連續內存空間

然后我們模擬哈希表的插入流程,如下圖的①②③④⑤:
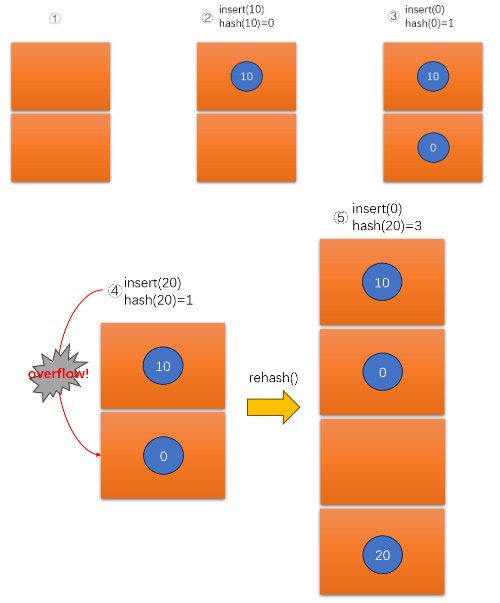
- 首先我們定義
std::vector<Bucket> buckets,它是兩塊Bucket大小的連續內存空間,也就是兩個桶。但桶里面是沒有東西的 - 當向哈希表中插入10時(
insert(10)),首先會通過哈希函數計算出索引(hash(10)=0),那么就在第一個桶(Bucket)中放入節點⑩ - 當向哈希表中插入0時(
insert(0)),首先會通過哈希函數計算出索引(hash(0)=1),那么就在第二個桶(Bucket)中放入節點? - 當向哈希表中插入20時(
insert(20)),首先會通過哈希函數計算出索引(hash(20)=1),出現兩個不同的鍵映射到相同的索引,即沖突。可以使用鏈地址法解決沖突,即在哈希表的每個槽中維護一個鏈表。 - 由于桶的數量不夠了,需要擴容哈希表(
rehash),擴容后的容量翻倍。通過哈希函數計算出索引(hash(20)=3),那么就在第四個桶(Bucket)中放入節點?
代碼實現
HashTable.h
#include <algorithm>
#include <cstddef>
#include <functional>
#include <iostream>
#include <list>
#include <utility>
#include <vector>
#include <sstream>
#include <string>namespace mystl{
template <typename Key, typename Value, typename Hash = std::hash<Key>>
class HashTable{// 鏈表中要維護的jie'dclass HashNode{public:Key key;Value value;// 從Key構造節點,Value使用默認構造explicit HashNode(const Key &key): key(key), value(){}// 從Key和Value構造節點HashNode(const Key &key, const Value &value):key(key), value(value){}// 比較運算符重載,比較keybool operator==(const HashNode &other) const { return key == other.key;}bool operator!=(const HashNode &other) const { return key != other.key; }bool operator<(const HashNode &other) const { return key < other.key; }bool operator>(const HashNode &other) const { return key > other.key; }bool operator==(const Key &key_) const { return key == key_; }void print() const{std::cout<<"(" << key <<","<< value<<")" << " ";}};private:// 定義表中一個桶(Bucket),桶里面裝的是一個個HashNode節點組成的鏈表using Bucket = std::list<HashNode>;std::vector<Bucket> buckets; // 定義由多個槽連續組成的數組std::hash<Key> hashFunction; // 定義一個哈希函數size_t tableSize; // 哈希表的最大容量size_t numElements; // 哈希表中當前元素的數量float maxLoadFactor = 0.75; // 默認的最大負載因子// 哈希函數計算key的值,取模防止溢出,作為哈希表的索引size_t hash(const Key &key) const { return hashFunction(key)%tableSize; }// 當元素數量大于最大容量時,增加桶的數量并重新分配所有鍵void rehash(size_t newSize){std::vector<Bucket> newBuckets(newSize);// 創建一個新的桶數組,大小為newsizefor(Bucket &bucket : buckets) // 遍歷原來的桶數組buckets,輪流取出其中的一個桶(bucket){// 鏈表遍歷for(HashNode &hashNode : bucket) // 遍歷原來的桶bucket,它是一個鏈表,輪流取出其中的一個節點(hashNode){// 新的索引與原來的索引相同size_t newIndex = hashFunction(hashNode.key)%newSize;// 計算新的索引newBuckets[newIndex].push_back(hashNode);}}// 移動語義buckets = std::move(newBuckets);tableSize = newSize;}public:// 哈希表構造函數初始化, 注意:typename Hash = std::hash<Key>/* std::hash<Key>() 創建了一個臨時的 std::hash<Key> 對象。因為 std::hash<Key> 有一個默認的構造函數(無參數的構造函數),所以可以直接這樣調用它來創建一個臨時對象。這個臨時對象被用來初始化之后,就銷毀*/ HashTable(size_t size = 0, const std::hash<Key> &hashFunc = Hash()):buckets(size),hashFunction(hashFunc),tableSize(size),numElements(0){}// 將鍵值對插入哈希表中void insert(const Key &key, const Value &value){if((numElements + 1) > maxLoadFactor * tableSize) // 乘以一個負載因子,保證哈希表預留的空間足夠多,計算出的索引不容易發生沖突,減少拷貝次數{if(tableSize == 0)tableSize = 1;rehash(tableSize * 2);}size_t index = hash(key); // 計算索引Bucket &bucket = buckets[index]; // 找出該索引對應的桶if(std::find(bucket.begin(),bucket.end(),key) == bucket.end()) // 如果桶中沒有鏈表,則在該桶中插入該鏈表;如果有,則直接跳過{bucket.push_back(HashNode(key, value));numElements++;}}void insertKey(const Key &key) { insert(key, Value{}); } // 值為空的情況void erase(const Key &key){size_t index = hash(key); // 計算索引auto &bucket = buckets[index]; // 找出該索引對應的桶auto it = std::find(bucket.begin(), bucket.end(), key);if(it != bucket.end()){// 找到該鏈表,刪除它bucket.erase(it);numElements--;}}Value* find(const Key &key){size_t index = hash(key);auto &bucket = buckets[index];auto ans = std::find(bucket.begin(), bucket.end(), key);if(ans != bucket.end()){return &ans->value; // 返回結點value所在的地址}return nullptr;}size_t size() const { return numElements; }void print() const {for(size_t i = 0; i < buckets.size(); i++){for(const HashNode &element : buckets[i]){element.print(); // 調用HashNode類的成員函數print}}std::cout << std::endl;}void clear(){this->buckets.clear();this->numElements = 0;this->tableSize = 0;}
};
}
test.cpp
#include "vector.h"
#include "list.h"
#include "deque.h"
#include "HashTable.h"void HashTableTest()
{mystl::HashTable<int, int> hashTable;for(int i = 0;i<5;i++){hashTable.insert(i, i*2);hashTable.print();}hashTable.print();int* t = hashTable.find(3);std::cout << *t << std::endl;hashTable.erase(3);hashTable.print();hashTable.clear();hashTable.print();
}int main()
{HashTableTest();system("pause");return 0;
}
代碼詳解
代碼的注釋已經很詳細啦,所以就不一個個講了(其實我就是懶~😜)
主要講解一下移動語義這個知識點
移動語義
參考這篇博客,寫得非常好🙂:[c++11]我理解的右值引用、移動語義和完美轉發 - 簡書 (jianshu.com)
std::move()可以讓一個左值進行右值引用,這樣在給其它變量賦值的時候,就不用額外拷貝一次臨時變量。
那什么叫左、右值?什么叫左值引用、右值引用呢?
左值右值
C++中所有的值都必然屬于左值、右值二者之一。左值是指表達式結束后依然存在的持久化對象,右值是指表達式結束時就不再存在的臨時對象。所有的有名字的變量或者對象都是左值,而右值則沒有名字。
- 左值:
int a = 10 - 右值:如
1+2產生的臨時變量,2,'c',true,"hello"等
很難得到左值和右值的真正定義,但是有一個可以區分左值和右值的便捷方法:看能不能對表達式取地址,如果能,則為左值,否則為右值。
左值引用,右值引用
左值引用就是我們經常說的引用,也就是給變量取別名,要注意不能給右值取左值引用,因為當我們修改b的值時,就是修改1的值,但由于1沒有內存空間,修改不了,所以不符合左值引用的要求
int a = 10;
int& refA = a; // refA是a的別名, 修改refA就是修改a, a是左值,左移是左值引用
int& b = 1; // !編譯錯誤! 1是右值,不能夠使用左值引用
c++11中的右值引用使用的符號是&&,它允許我們對右值進行引用,如:
int&& a = 1; //實質上就是將不具名(匿名)變量取了個別名
int b = 1;
int && c = b; //編譯錯誤! 不能將一個左值復制給一個右值引用
class A {public:int a;
};
A getTemp()
{return A();
}
A && a = getTemp(); //getTemp()的返回值是右值(臨時變量)同樣我們也要注意不能給左值取右值引用
在上面代碼中,getTemp()返回的右值本來在表達式語句結束后,其生命也就該終結了(因為是臨時變量),而通過右值引用,該右值又重獲新生,其生命期將與右值引用類型變量a的生命期一樣,只要a還活著,該右值臨時變量將會一直存活下去。實際上就是給那個臨時變量取了個名字。
注意:這里a的類型是右值引用類型(int &&),但是如果從左值和右值的角度區分它,它實際上是個左值。因為可以對它取地址,而且它還有名字,是一個已經命名的右值。因此,編譯器會認為a是個左值。
萬能引用
那有沒有一種引用,既可以左值引用,也可以右值引用呢?
有,它就是常量引用。常量左值引用是個奇葩,它可以算是一個“萬能”的引用類型,它可以綁定非常量左值、常量左值、右值,而且在綁定右值的時候,常量左值引用還可以像右值引用一樣將右值的生命期延長,缺點是,只能讀不能改。
const int & a = 1; //常量左值引用綁定 右值, 不會報錯class A {public:int a;
};
A getTemp()
{return A();
}
const A & a = getTemp(); //不會報錯 而 A& a 會報錯
總結一下:
- 左值引用, 使用
T&, 只能綁定左值- 右值引用, 使用
T&&, 只能綁定右值- 常量左值, 使用
const T&, 既可以綁定左值又可以綁定右值- 已命名的右值引用,編譯器會認為是個左值
移動語義、拷貝
#include <iostream>
#include <cstring>
#include <vector>
using namespace std;class MyString
{
public:static size_t CCtor; //統計調用拷貝構造函數的次數
// static size_t CCtor; //統計調用拷貝構造函數的次數
public:// 構造函數MyString(const char* cstr=0){if (cstr) {m_data = new char[strlen(cstr)+1];strcpy(m_data, cstr);}else {m_data = new char[1];*m_data = '\0';}}// 拷貝構造函數MyString(const MyString& str) {CCtor ++;m_data = new char[ strlen(str.m_data) + 1 ];strcpy(m_data, str.m_data);}// 拷貝賦值函數 =號重載MyString& operator=(const MyString& str){if (this == &str) // 避免自我賦值!!return *this;delete[] m_data;m_data = new char[ strlen(str.m_data) + 1 ];strcpy(m_data, str.m_data);return *this;}~MyString() {delete[] m_data;}char* get_c_str() const { return m_data; }
private:char* m_data;
};
size_t MyString::CCtor = 0;int main()
{vector<MyString> vecStr;vecStr.reserve(1000); //先分配好1000個空間,不這么做,調用的次數可能遠大于1000for(int i=0;i<1000;i++){vecStr.push_back(MyString("hello"));}cout << MyString::CCtor << endl;
}
在這段代碼中,vecStr.push_back(MyString("hello"))工作流程如圖:它會依次調用MyString(const char* cstr=0)創建一個右值、在插入的時候通過MyString(const MyString& str)`拷貝一份Mystring變量
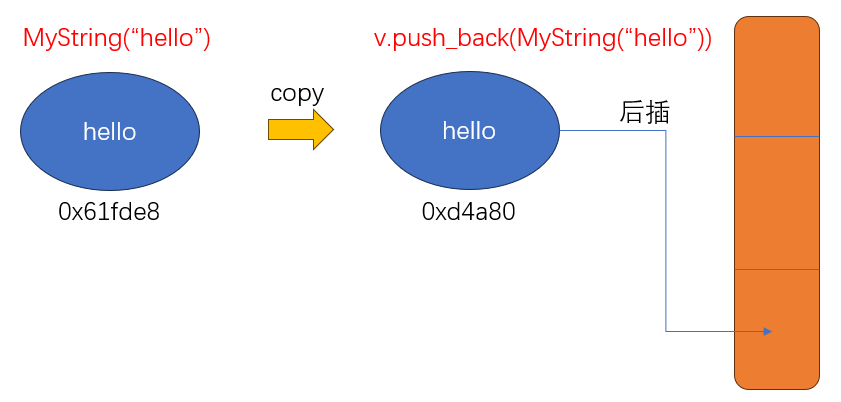
如果MyString("hello")構造出來的字符串(比如MyString("hello abcdefghigklmnopqrstuvwsyzasd……………………"))本來就很長,構造一遍就很耗時了,最后卻還要拷貝一遍,而MyString("hello")只是臨時對象,拷貝完就沒什么用了,這就造成了沒有意義的資源申請和釋放操作。
那能不能去掉這個copy(黃色箭頭)拷貝過程,直接將這個右值插入呢?而C++11新增加的移動語義就能夠做到這一點。
#include <iostream>
#include <cstring>
#include <vector>
using namespace std;class MyString
{
public:static size_t CCtor; //統計調用拷貝構造函數的次數static size_t MCtor; //統計調用移動構造函數的次數static size_t CAsgn; //統計調用拷貝賦值函數的次數static size_t MAsgn; //統計調用移動賦值函數的次數public:// 構造函數MyString(const char* cstr=0){if (cstr) {m_data = new char[strlen(cstr)+1];strcpy(m_data, cstr);}else {m_data = new char[1];*m_data = '\0';}}// 拷貝構造函數MyString(const MyString& str) {CCtor ++;m_data = new char[ strlen(str.m_data) + 1 ];strcpy(m_data, str.m_data);}// 移動構造函數MyString(MyString&& str) noexcept:m_data(str.m_data) {MCtor ++;str.m_data = nullptr; //不再指向之前的資源了}// 拷貝賦值函數 =號重載MyString& operator=(const MyString& str){CAsgn ++;if (this == &str) // 避免自我賦值!!return *this;delete[] m_data;m_data = new char[ strlen(str.m_data) + 1 ];strcpy(m_data, str.m_data);return *this;}// 移動賦值函數 =號重載MyString& operator=(MyString&& str) noexcept{MAsgn ++;if (this == &str) // 避免自我賦值!!return *this;delete[] m_data;m_data = str.m_data;str.m_data = nullptr; //不再指向之前的資源了return *this;}~MyString() {delete[] m_data;}char* get_c_str() const { return m_data; }
private:char* m_data;
};
size_t MyString::CCtor = 0;
size_t MyString::MCtor = 0;
size_t MyString::CAsgn = 0;
size_t MyString::MAsgn = 0;
int main()
{vector<MyString> vecStr;vecStr.reserve(1000); //先分配好1000個空間for(int i=0;i<1000;i++){vecStr.push_back(MyString("hello"));}cout << "CCtor = " << MyString::CCtor << endl;cout << "MCtor = " << MyString::MCtor << endl;cout << "CAsgn = " << MyString::CAsgn << endl;cout << "MAsgn = " << MyString::MAsgn << endl;
}/* 結果
CCtor = 0
MCtor = 1000
CAsgn = 0
MAsgn = 0
*/
在上述代碼中,我們新增了一個移動拷貝構造:
// 移動構造函數
MyString(MyString&& str) noexcept:m_data(str.m_data) {MCtor ++;str.m_data = nullptr; //不再指向之前的資源了
}
移動構造函數與拷貝構造函數的區別是,拷貝構造的參數是const MyString& str,是常量左值引用,而移動構造的參數MyString&& str,是右值引用,而MyString("hello")是個臨時對象,是個右值,優先進入移動構造函數而不是拷貝構造函數。而移動構造函數與拷貝構造不同,它并不是重新分配一塊新的空間,將要拷貝的對象復制過來,而是"偷"了過來,將自己的指針指向別人的資源,然后將別人的指針修改為nullptr,這一步很重要,如果不將別人的指針修改為空,那么臨時對象析構的時候就會釋放掉這個資源,"偷"也白偷了。下面這張圖可以解釋copy和move的區別。
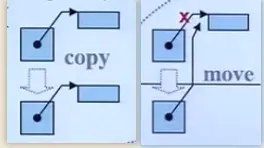
通過這種方法,我們就可以讓一個右值,不用進行拷貝,直接移動到該去的地方
對于一個左值,肯定是調用拷貝構造函數了。比如上面我們將main函數修改一下:
int main()
{vector<MyString> vecStr;vecStr.reserve(1000); //先分配好1000個空間for(int i=0;i<1000;i++){MyString s = MyString("hello");vecStr.push_back(s);}cout << "CCtor = " << MyString::CCtor << endl;cout << "MCtor = " << MyString::MCtor << endl;cout << "CAsgn = " << MyString::CAsgn << endl;cout << "MAsgn = " << MyString::MAsgn << endl;
}
可以看出這個左值,進入到了拷貝構造里面了,而不是移動構造中!
但是有些左值是局部變量,生命周期也很短,能不能也移動而不是拷貝呢?C++11為了解決這個問題,提供了std::move()方法來將左值轉換為右值,從而方便應用移動語義。
我覺得它其實就是告訴編譯器,雖然我是一個左值,但是不要對我用拷貝構造函數,而是用移動構造函數吧。
現在我們再將main函數修改一下:
int main()
{vector<MyString> vecStr;vecStr.reserve(1000); //先分配好1000個空間for(int i=0;i<1000;i++){MyString s = MyString("hello");vecStr.push_back(std::move(s));}cout << "CCtor = " << MyString::CCtor << endl;cout << "MCtor = " << MyString::MCtor << endl;cout << "CAsgn = " << MyString::CAsgn << endl;cout << "MAsgn = " << MyString::MAsgn << endl;
}
可以看出這個左值,進入到了移動構造里面了!
所以:std::move()可以讓一個左值進行右值引用,這樣在給其它變量賦值的時候,就不用額外拷貝一次臨時變量。
C11中元素遍歷Bucket &bucket:buckets
等同于
for(int i =0;i<buckets.size();i++)
{bucket = buckets[i];…………
}



【獨一無二】)




)

安裝 postgres sql 數據庫)








)