一、數組
在程序中為了處理方便,常常需要把具有相同類型的數據對象按有序的形式排列起來,形成“一組”數據,這就是“數組”(array)
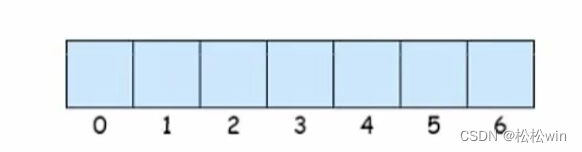
數組中的數據,在內存中是連續存放的,每個元素占據相同大小的空間,就像排好隊一樣。
1、數組的定義
數組的定義形式如下:
![]()
首先需要聲明類型r數組中所有元素必須具有相同的數據類型;
數組名是一個標識符;后面跟著中括號,里面定義了數組中元素的個數,也就是數組的“長度”;
元素個數也是類型的一部分,所以必須是確定的;

需要注意的是:
????????對數組做初始化,要使用花括號括起來的數值序列;
????????如果做了初始化,數組定義時的元素個數可以省略,編譯器可以根據初始化列表自動推斷出來;
????????初始值的個數,不能超過指定的元素個數;
????????初始值的個數,如果小于元素個數,那么會用列表中的值初始化靠前的元素;剩余元素用默認值填充,整型的默認值就是0;
????????如果沒有做初始化,數組中元素的值都是未定義的;這一點和普通的局部變量一致;|
2、數組的訪問
(1)訪問數組元素
數組元素在內存中是連續存放的,它們排好了隊之后就會有一個隊伍中的編號,稱為“索引”,也叫“下標”;通過下標就可以快速訪問每個元素了,具體形式為:
![]()
這里也是用了中括號來表示元素下標位置,被稱為“下標運算符”。比如 a[2]就表示數組a中下標為2的元素,可以取它的值輸出,也可以對它賦值。

#include<iostream>using namespace std;int main()
{int a[] = {1,2,3,4,5,6};cout << "a[1] = " << a[1] << endl;a[1] = 666;cout << "a[1] = " << a[1] << endl;cin.get();
}運行結果:

需要注意的是:
????????數組的下標從o開始;
????????因此 a[2]訪問的并不是數組 a的第2個元素,而是第三個元素;一個長度為10的數組,下標范圍是o~9,而不是1~10;
????????合理的下標,不能小于o,也不能大于(數組長度-1);否則就會出現數組下標越界;
(2)數組的大小
所有的變量,都會在內存中占據一定大小的空間;而數據類型就決定了它具體的大小。而對于數組這樣的“復合類型”,由于每個元素類型相同,因此占據空間大小的計算遵循下面的簡單公式:

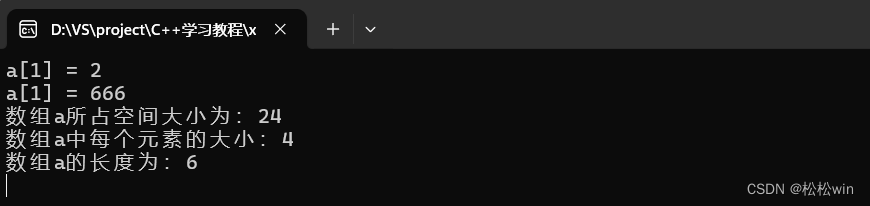
#include<iostream>using namespace std;int main()
{int a[] = {1,2,3,4,5,6};cout << "a[1] = " << a[1] << endl;a[1] = 666;cout << "a[1] = " << a[1] << endl;//獲取數組大小的長度cout << "數組a所占空間大小為:" << sizeof(a) << endl;cout << "數組a中每個元素的大小:" << sizeof(a[0]) << endl;int size;size = sizeof(a) / sizeof(a[0]);cout << "數組a的長度為:" << size << endl;cin.get();
}運行結果:
3、多維數組

C++中本質上沒有“多維數組”這種東西,所謂的“多維數組”,其實就是“數組的數組”。
????????二維數組int arr[3][4]表示: arr是一個有三個元素的數組,其中的每個元素都是一個int 數組,包含4個元素;
????????三維數組int arr2[2][5][10]表示: arr2是一個長度為2的數組,其中每個元素都是一個二維數組;這個二維數組有5個元素,每個元素都是一個長度為10的int 數組;
?一般最常見的就是二維數組。它有兩個“維度”,第一個維度表示數組本身的長度,第二個表示每個元素的長度,一般分別把它們叫做“行”和“列”。
(1)多維數組的初始化
和普通的“一維”數組一樣,多維數組初始化時,也可以用花括號括起來的一組數。使用嵌套的花括號可以讓不同的維度更清晰:

需要注意:
????????內嵌的花括號不是必需的,因為數組中的元素在內存中連續存放,可以用一個花括號將所有數據括在一起;
????????初始值的個數,可以小于數組定義的長度,其它元素初始化為0值;這一點對整個二維數組和每一行的一維數組都適用;
????????如果省略嵌套的花括號,當初始值個數小于總元素個數時,會按照順序依次填充(填滿第一行,才填第二行);其它元素初始化為О值;
????????多維數組的維度,可以省略第一個,由編譯器自動推斷;即二維數組可以省略行數,但不能省略列數。
#include<iostream>using namespace std;int main()
{//初始化int a[3][4] = {1,2,3,4,5,6,7,8,9,10,11,12};int b[3][4] = { {1,2,3,4},{5,6,7,8},{9,10,11,12}};int c[3][4] = { 1,2,3,4 };int d[][4] = { 1,2,3,4,5,6 };//訪問cout << "b[1][1] = " << b[1][1] << endl;b[1][1] = 666;cout << "b[1][1] = " << b[1][1] << endl;//遍歷//計算二維數組中的行數和列數cout << "二維數組b的總大小:" << sizeof(b) << endl; //大小說的是字節cout << "二維數組每一行的大小:" << sizeof(b[0]) << endl;cout << "二維數組中每一個元素的大小:" << sizeof(b[0][0]) << endl;int rowCnt = sizeof(b) / sizeof(b[0]); //行數int colCnt = sizeof(b[0]) / sizeof(b[0][0]); //列數cout << "rowCnt = " << rowCnt << endl;cout << "colCnt = " << colCnt << endl;for (int i = 0; i < rowCnt; i++){for (int j = 0; j < colCnt; j++){cout << b[i][j] << "\t";}cout << endl;}cin.get();
}運行結果:

4、數組的排序
數組排序指的是給定一個數組,要求把其中的元素按照從小到大(或從大到小)順序排列。
這是一個非常經典的需求,有各種不同的算法可以實現。我們這里介紹兩種最基本、最簡單的排序算法。
(1)選擇排序
選擇排序是一種簡單直觀的排序算法。
它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再從剩余未排序元素中繼續尋找最小(大)元素,然后追加到已排序序列的末尾。以此類推,直到所有元素均排序完畢。

#include<iostream>using namespace std;int main()
{int a[] = {2,5,8,4,9,1,6,3,7,0};//計算數組a的大小int size = sizeof(a) / sizeof(a[0]);//選擇排序for (int i = 0; i < size; i++){for (int j = i + 1; j < size; j++){if (a[j] < a[i]){int temp = a[j];a[j] = a[i];a[i] = temp;}}}for (int num : a){cout << num << "\t";}cout << endl;cin.get();
}運行結果:
(2)冒泡排序
冒泡排序也是一種簡單的排序算法。
它的基本原理是:重復地掃描要排序的數列,一次比較兩個元素,如果它們的大小順序錯誤,就把它們交換過來。這樣,一次掃描結束,我們可以確保最大(小)的值被移動到序列末尾。這個算法的名字由來,就是因為越小的元素會經由交換,慢慢“浮”到數列的頂端。

#include<iostream>using namespace std;int main()
{int a[] = {2,5,8,4,9,1,6,3,7,0};//計算數組a的大小int size = sizeof(a) / sizeof(a[0]);//冒泡排序for (int i = 0; i < size; i++){for (int j = 0; j < size - i - 1; j++){if (a[j] > a[j + 1]){int temp = a[j + 1];a[j + 1] = a[j];a[j] = temp;}}}for (int num : a){cout << num << "\t";}cout << endl;cin.get();
}運行結果:

二、模板類vector
數組盡管很靈活,但使用起來還是很多不方便。為此,C++語言定義了擴展的“抽象數據類型”(Abstract Data Type,ADT),放在“標準庫”中。
對數組功能進行擴展的一個標準庫類型,就是“容器”vector。顧名思義,vector“容納”著一堆數據對象,其實就是一組類型相同的數據對象的集合。
1、頭文件和命名空間
vector是標準庫的一部分。要想使用vector,必須在程序中包含<vector>頭文件,并使用std命名空間。

在vector頭文件中,對vector這種類型做了定義;使用#include引入它之后,并指定命名空間std之后,我們就可以在代碼中直接使用vector了。
2、 vector的基本用法
vector其實是C++中的一個“類模板”,是用來創建類的“模子”。所以在使用時還必須提供具體的類型信息,也就是說,這個容器中到底要容納什么類型的數據對象;具體的形式是在vector后面跟一個尖括號<>,里面填入具體類型信息。
![]()
#include<iostream>
#include<vector>using namespace std;int main()
{//默認初始化vector<int> v1; //定義了整型的容器,容器名:v1//列表初始化vector<char> v2 = { 'a','b','c' };vector<char> v3{ 'a','b','c' };//直接初始化vector<short> v4(5); //定義了大小為5的短整型容器vector<double> v5(5,100);//定義了大小為5的double容器,且每個值都為100//訪問元素cout << v5[2] << endl;v5[2] = 666;cout << v5[2] << endl;//遍歷所有元素for (int i = 0; i < v5.size(); i++){cout << v5[i] << "\t";}cout << endl;//添加元素v5.push_back(69);for (int num : v5){cout << num << "\t";}cout << endl;//向容器中添加倒序的元素for (int i = 10; i > 0; i--){v1.push_back(i);}//遍歷容器v1for (int num : v1){cout << num << "\t";}cout << endl;cin.get();
}運行結果:

2、vector和數組的區別
數組是更加底層的數據類型;長度固定,功能較少,安全性沒有保證;但性能更好,運行更高效;
vector是模板類,是數組的上層抽象;長度不定,功能強大;缺點是運行效率較低;
除了vector之外,C++ 11還新增了一個array模板類,它跟數組更加類似,長度是固定的,但更加方便、更加安全。所以在實際應用中,一般推薦對于固定長度的數組使用array,不固定長度的數組使用vector。
三、字符串
字符串我們并不陌生。之前已經介紹過,一串字符連在一起就是一個“字符串”,比如用雙引號引起來的“Hello World !”就是一個字符串字面值。
字符串其實就是所謂的“純文本”,就是各種文字、數字、符號在一起表達的一串信息;所以字符串就是C++中用來表達和處理文本信息的數據類型。
1、標準庫類型string
C++的標準庫中,提供了一種用來表示字符串的數據類型string,這種類型能夠表示長度可變的字符序列。和 vector類似,Istring 類型也定義在命名空間std中,使用它必須包含string頭文件。

(1)定義和初始化 string
我們已經接觸過C++中幾種不同的初始化方式, string 也是一個標準庫類型,它的初始化與vector非常相似。
#include<iostream>
#include<string>using namespace std;int main()
{//初始化string s1;//拷貝初始化string s2 = s1;string s3 = "hello world";//直接初始化string s4("hello world");string s5(8, 'h');cout << s5 << endl;//訪問字符cout << "s4[1] = " << s4[1] << endl;s4[0] = 'H';cout << s4 << endl;cin.get();
}運行結果:

字符串內字符的訪問,跟vector內元素的訪問類似,需要注意:
????????string內字符的索引,也是從o開始;
????????string 同樣有一個成員函數size,可以獲取字符串的長度;
????????索引最大值為字符串長度- 1),不能越界訪問;如果直接越界訪問并賦值,有可能導致非常嚴重的后果,出現安全問題;
????????如果希望遍歷字符串的元素,也可以使用普通for 循環和范圍for 循環,依次獲取每個字符
#include<iostream>
#include<string>using namespace std;int main()
{//初始化string s1;//拷貝初始化string s2 = s1;string s3 = "hello world";//直接初始化string s4("hello world");string s5(8, 'h');cout << s5 << endl;//訪問字符cout << "s4[1] = " << s4[1] << endl;s4[0] = 'H';cout << s4 << endl;//遍歷for (int i = 0; i < s4.size(); i++){s4[i] = toupper(s4[i]); //toupper:小寫轉換大寫}cout << s4 << endl;cin.get();
}運行結果:

(2)字符串相加
string本身的長度是不定的,可以通過“相加”的方式擴展一個字符串。

需要注意:
????????字符串相加使用加號“E”來表示,這是算術運算符“+”的運算符重載,含義是“字符串拼接”;
????????兩個string對象,可以直接進行字符串相加;結果是將兩個字符串拼接在一起,得到一個新的string對象返回;
????????一個string對象和一個字符串字面值常量,可以進行字符串相加,同樣是得到一個拼接后的string對象返回;
????????兩個字符串字面值常量,不能相加;
????????多個string 對象和多個字符串字面值常量,可以連續相加;前提是按照左結合律,每次相加必須保證至少有一個string對象;
(3)比較字符串

字符串比較的規則為:
????????如果兩個字符串長度相同,每個位置包含的字符也都相同,那么兩者“相等”;否則“不相等";
????????如果兩個字符串在某一位置上開始不同,那么就比較這兩個字符的 ASCIl碼,比較結果就代表兩個字符串的大小關系
????????如果兩個字符串在某一位置上開始不同,那么就比較這兩個字符的 ASCIl碼,比較結果就代表兩個字符串的大小關系
2、字符數組
通過對string的介紹可以發現,字符串就是一串字符的集合,本質上其實就是一個“字符的數組”。
在C語言中,確實是用char[]類型來表示字符串的;不過為了區分純粹的“字符數組”和“字符串”,C語言規定:字符串必須以空字符結束。空字符的ASClI碼為o,專門用來標記字符串的結尾,在程序中寫作\0'。

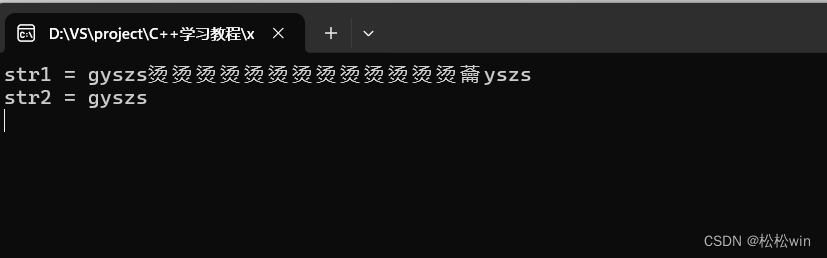
#include<iostream>using namespace std;int main()
{char str1[5] = { 'g','y','s','z','s' };//str1不是一個字符串char str2[6] = { 'g','y','s','z','s','\0'};//str2是一個字符串cout << "str1 = " << str1 << endl;cout << "str2 = " << str2 << endl;cin.get();
}
運行結果:
3、讀取輸入的字符串
(1)使用輸入操作符讀取單詞
標準庫中提供了iostream,可以使用內置的 cin對象,調用重載的輸入操作符>>來讀取鍵盤輸入。

這種方式的特點是:忽略開始的空白符,遇到下一個空白符(空格、回車、制表等)就會停止。所以如果我們輸入“"hello world”,那么讀取給str的只有“hello"這相當于讀取了一個“單詞”。
剩下的內容“world”其實也沒有丟,而是保存在了輸入流的“輸入隊列”里。如果我們想讀取更多的輸入信息,就需要使用更多的string對象來獲取:

(2〉使用getline讀取一行
如果希望直接讀取一整行輸入信息,可以使用getline函數來替代輸入操作符。

getline函數有兩個參數:一個是輸入流對象cin,另一個是保存字符串的string 對象;它會一直讀取輸入流中的內容,直到遇到換行符為止,然后把所有內容保存到string 對象中。所以現在可以完整讀取一整行信息了。
#include<iostream>
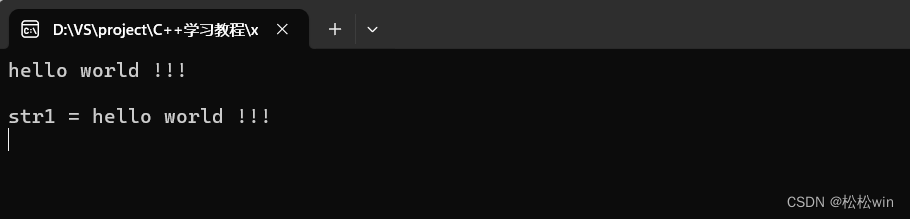
#include<string>using namespace std;int main()
{//使用getline讀取一行信息string str1;getline(cin, str1);cin.get();cout << "str1 = " << str1 << endl;cin.get();
}
運行結果:
(3)使用get讀取字符
還有一種方法,是調用cin 的 get函數讀取一個字符。

有兩種方式:
????????調用cin.get()函數,不傳參數,得到一個字符賦給char類型變量;
????????將char類型變量作為參數傳入,將捕獲的字符賦值給它,返回的是istream對象
(4)讀寫文件
C++的lo庫中提供了專門用于文件輸入的 ifstream類和用于文件輸出的ofstream類,要使用它們需要引入頭文件 fstream。ifstream 用于讀取文件內容,跟istream 的用法類似;也可以通過輸入操作符>>來讀“單詞”(空格分隔),通過getline 函數來讀取一行,通過get函數來讀取一個字符:
#include<iostream>
#include<fstream>
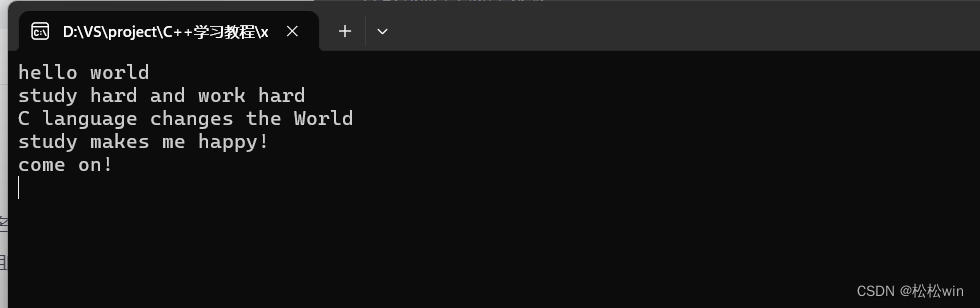
#include<string>using namespace std;int main()
{ifstream input("1.txt"); //通過input對象來從文件中讀取數據ofstream output("2.txt");//1.按照單詞逐個讀取/*string word;while (input >> word){cout << word << endl;}*///2.逐行讀取string line;while (getline(input, line)){cout << line << endl;//output << line << endl;}cin.get();
}
運行結果:
四、結構體
C/C++中提供了另一種更加靈活的數據結構——結構體。結構體是用戶自定義的復合數據結構,里面可以包含多個不同類型的數據對象。
1、結構體的定義和聲明
聲明一個結構體需要使用struct關鍵字,具體形式如下:

#include<iostream>using namespace std;//定義1個結構體
struct student
{string name;int age;double score;
};int main()
{//創建對象并初始化student s1 = { "ljl",18,99 };cin.get();
}
2、訪問結構體中數據
訪問結構體變量中的數據成員,可以使用成員運算符點號.),后面跟上數據成員的名稱。例如stu.name就可以訪問stu對象的name成員。

#include<iostream>using namespace std;//定義1個結構體
struct student
{string name;int age;double score;
};//輸出一個數據對象的完整信息
void pintinfo(student s)
{//訪問數據cout << "學生姓名:" << s.name << "\t年齡:" << s.age << "\t成績:" << s.score << endl;
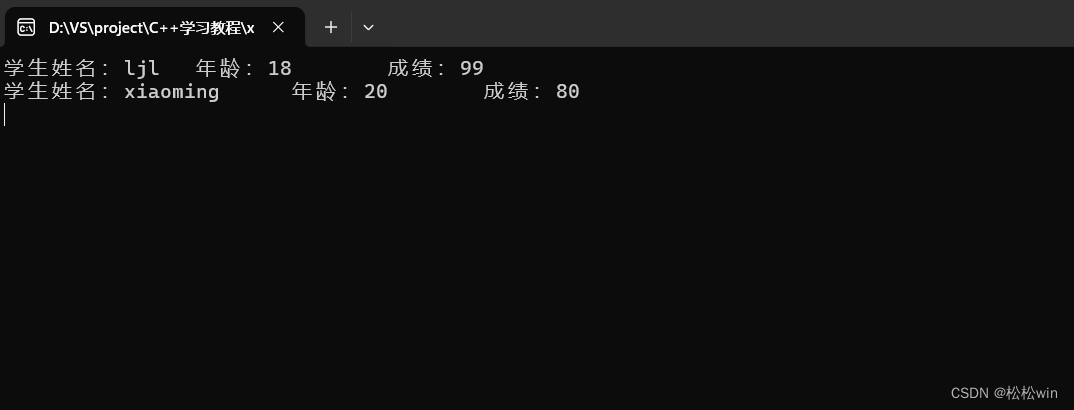
}int main()
{//創建對象并初始化student s1 = { "ljl",18,99 };student s2;s2.age = 20;s2.name = "xiaoming";s2.score = 80;pintinfo(s1);pintinfo(s2);cin.get();
}
運行結果:
3、結構體數組
可以把結構體和數組結合起來,創建結構體的數組。顧名思義,結構體數組就是元素為結構體的數組,它的定義和訪問跟普通的數組完全一樣。

#include<iostream>using namespace std;//定義1個結構體
struct student
{string name;int age;double score;
};//輸出一個數據對象的完整信息
void pintinfo(student s)
{//訪問數據cout << "學生姓名:" << s.name << "\t年齡:" << s.age << "\t成績:" << s.score << endl;
}int main()
{//創建對象并初始化student s1 = { "ljl",18,99 };student s2;s2.age = 20;s2.name = "xiaoming";s2.score = 80;pintinfo(s1);pintinfo(s2);//結構體數組student s3[3] = {{"小王",18,88},{"小張",19,66},{"小錢",20,99}};pintinfo(s3[0]);cin.get();
}
運行結果:

五、枚舉
枚舉類型的定義和結構體非常像,需要使用enum關鍵字。

與結構體不同的是,枚舉類型內只有有限個名字,它們都各自代表一個常量,被稱為“枚舉量”。
需要注意的是:
????????默認情況下,會將整數值賦給枚舉量;
????????枚舉量默認從0開始,每個枚舉量依次加1;所以上面week枚舉類型中,一周七天枚舉量分別對應著0~6的常量值;
????????可以通過對枚舉量賦值,顯式地設置每個枚舉量的值;
#include<iostream>using namespace std;//定義1個枚舉類型
enum Week {Mon, Tue, Wed, Thu, Fri, Sta, Sun
};int main()
{Week w1 = Mon, w2 = Tue;cout << "w1 = " << w1 << endl;cout << "w2 = " << w2 << endl;cin.get();
}
運行結果:

六、指針? ---存放是地址
指針顧名思義,是“指向”另外一種數據類型的復合類型。指針是C/C++中一種特殊的數據類型,它所保存的信息,其實是另外一個數據對象在內存中的“地址”。通過指針可以訪問到指向的那個數據對象,所以這是一種間接訪問對象的方法。

1、指針的定義

這里的類型就是指針所指向的數據類型,后面加上星號“*”,然后跟指針變量的名稱。指針在定義的時候可以不做初始化。相比一般的變量聲明,看起來指針只是多了一個星號“*”而已。例如:

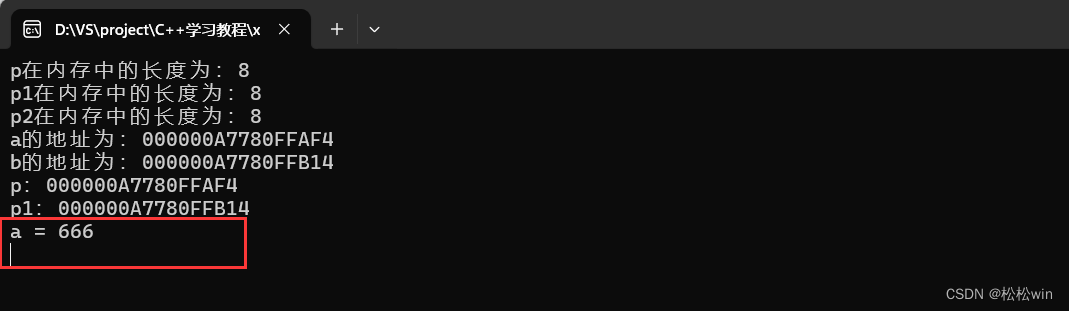
#include<iostream>using namespace std;int main()
{int* p;long* p1;long long* p2;cout << "p在內存中的長度為:" << sizeof(p) << endl;cout << "p1在內存中的長度為:" << sizeof(p1) << endl;cout << "p2在內存中的長度為:" << sizeof(p2) << endl;cin.get();
}
運行結果:

指針在64位系統下占據8個字節,在32位系統下占4個字節。
2、指針的用法
(1)獲取對象地址給指針賦值
指針保存的是數據對象的內存地址,所以可以用地址給指針賦值;獲取對象地址的方式是使用“取地址操作符”((&)。
#include<iostream>using namespace std;int main()
{int* p;long* p1;long long* p2;cout << "p在內存中的長度為:" << sizeof(p) << endl;cout << "p1在內存中的長度為:" << sizeof(p1) << endl;cout << "p2在內存中的長度為:" << sizeof(p2) << endl;//指針的使用int a = 10;long b = 20;p = &a;p1 = &b;cout << "a的地址為:" << &a << endl;cout << "b的地址為:" << &b << endl;cout << "p:" << p << endl;cout << "p1:" << p1 << endl;cin.get();
}
運行結果:

(2)通過指針訪問對象
指針指向數據對象后,可以通過指針來訪問對象。訪問方式是使用“解引用操作符”(*):

在這里由于p指向了a,所以*p可以等同于a。
#include<iostream>using namespace std;int main()
{int* p;long* p1;long long* p2;cout << "p在內存中的長度為:" << sizeof(p) << endl;cout << "p1在內存中的長度為:" << sizeof(p1) << endl;cout << "p2在內存中的長度為:" << sizeof(p2) << endl;//指針的使用int a = 10;long b = 20;p = &a;p1 = &b;cout << "a的地址為:" << &a << endl;cout << "b的地址為:" << &b << endl;cout << "p:" << p << endl;cout << "p1:" << p1 << endl;*p = 666;cout << "a = " << a << endl;cin.get();
}
運行結果:
3、無效指針、空指針和 void*指針
(1)無效指針
定義一個指針之后,如果不進行初始化,那么它的內容是不確定的(比如Oxcccc)。如果這時把它的內容當成一個地址去訪問,就可能訪問的是不存在的對象;更可怕的是,如果訪問到的是系統核心內存區域,修改其中內容會導致系統崩潰。這樣的指針就是“無效指針”,也被叫做“野指針”。

指針非常靈活非常強大,但野指針非常危險。所以建議使用指針的時候,一定要先初始化,讓它指向真實的對象。
(2)空指針
如果先定義了一個指針,但確實還不知道它要指向哪個對象,這時可以把它初始化為“空指針”。空指針不指向任何對象。

(3)void* 指針
一般來說,指針的類型必須和指向的對象類型匹配,否則就會報錯。不過有一種指針比較特殊,可以用來存放任意對象的地址,這種指針的類型是void*。
 4、指向指針的指針
4、指向指針的指針
指針本身也是一個數據對象,也有自己的內存地址。所以可以讓一個指針保存另一個指針的地址,這就是“指向指針的指針”,有時也叫“二級指針”;形式上可以用連續兩個的星號**來表示。類似地,如果是三級指針就是***,表示“指向二級指針的指針”。

#include<iostream>using namespace std;int main()
{int* p;long* p1;long long* p2;cout << "p在內存中的長度為:" << sizeof(p) << endl;cout << "p1在內存中的長度為:" << sizeof(p1) << endl;cout << "p2在內存中的長度為:" << sizeof(p2) << endl;//指針的使用int a = 10;long b = 20;p = &a;p1 = &b;cout << "a的地址為:" << &a << endl;cout << "b的地址為:" << &b << endl;cout << "p:" << p << endl;cout << "p1:" << p1 << endl;*p = 666;cout << "a = " << a << endl;cout << "--------------------------------" << endl;//二級指針int i = 100;int* pi = &i;int** ppi = πcout << "i = " << i << endl;cout << "pi = " << pi << endl;cout << "ppi = " << ppi << endl;cout << "*pi = " << *pi << endl;cout << "*ppi = " << *ppi << endl;cout << "**ppi = " << **ppi << endl;cin.get();
}
運行結果:

5、指針和const
指針可以和 const 修飾符結合,這可以有兩種形式:一種是指針指向的是一個常量;另一種是指針本身是一個常量。
(1)指向常量的指針
指針指向的是一個常量,所以只能訪問數據,不能通過指針對數據進行修改。不過指針本身是變量,可以指向另外的數據對象。這時應該把const加在類型前。

這里發現,pc是一個指向常量的指針,但其實把一個變量i的地址賦給它也是可以的;編譯器只是不允許通過指針pc去間接更改數據對象。
(2)指針常量(const 指針)
指針本身是一個數據對象,所以也可以區分變量和常量。如果指針本身是一個常量,就意味它保存的地址不能更改,也就是它永遠指向同一個對象;而數據對象的內容是可以通過指針改變的。這種指針一般叫做“指針常量”。
指針常量在定義的時候,需要在星號*后、標識符前加上 const。

6、指針和數組
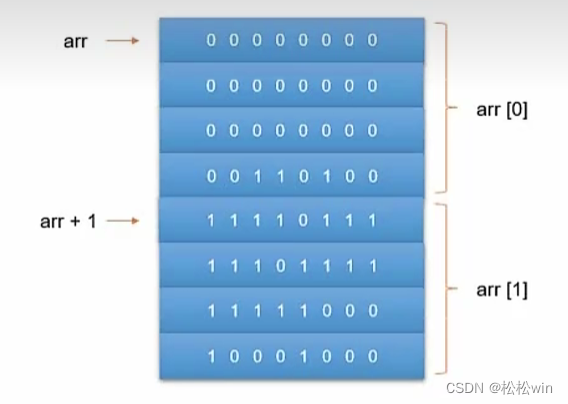
(1)數組名
用到數組名時,編譯器一般都會把它轉換成指針,這個指針就指向數組的第一個元素。所以我們也可以用數組名來給指針賦值。

運行結果:
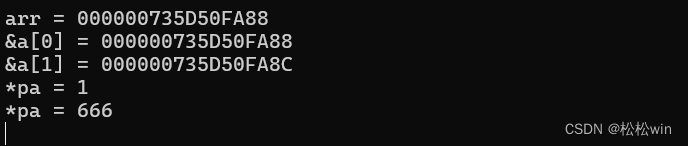
(2)指針運算
如果對指針pia 做加1操作,我們會發現它保存的地址直接加了4,這其實是指向了下一個int類型數據對象:

所謂的“指針運算”,就是直接對一個指針加/減一個整數值,得到的結果仍然是指針。新指針指向的數據元素,跟原指針指向的相比移動了對應個數據單位。
(3)指針數組和數組指針
指針和數組這兩種類型可以結合在一起,這就是“指針數組”和“數組指針”。
指針數組:一個數組,它的所有元素都是相同類型的指針;
數組指針:一個指針,指向一個數組的指針;

運行結果:

七、引用
1、引用的用法
在做聲明時,我們可以在變量名前加上“&”符號,表示它是另一個變量的引用。引用必須被初始化。
#include<iostream>using namespace std;int main()
{int a = 888, b = 666;int& ref = a;cout << "ref = " << ref << endl;cout << "a的地址為: " << &a << endl;cout << "ref的地址為: " << &ref << endl;cin.get();
}
運行結果:

引用本質上就是一個“別名”,它本身不是數據對象,所以本身不會存儲數據,而是和初始值“綁定”(bind)在一起,綁定之后就不能再綁定別的對象了。
2、對常量的引用
可以把引用綁定到一個常量上,這就是“對常量的引用”。很顯然,對常量的引用是常量的別名,綁定的對象不能修改,所以也不能做賦值操作:

對常量的引用有時也會直接簡稱“常量引用”。因為引用只是別名,本身不是數據對象;所以這只能代表“對一個常量的引用”,而不會像“常量指針”那樣引起混淆。
常量引用和普通變量的引用不同,它的初始化要求寬松很多,只要是可以轉換成它指定類型的所有表達式,都可以用來做初始化。

3、指針和引用
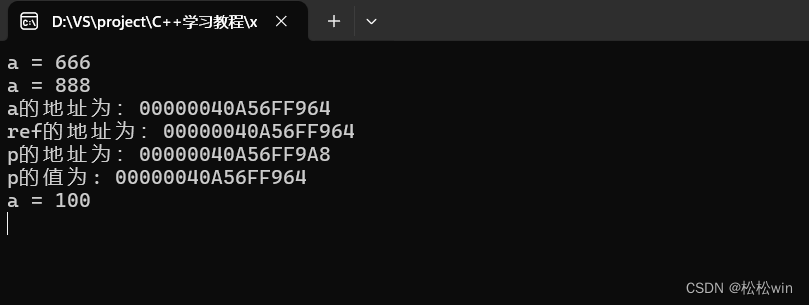
(1)引用和指針常量
事實上,引用的行為,非常類似于“指針常量”,也就是只能指向唯一的對象、不能更改的指針。
#include<iostream>using namespace std;int main()
{int a = 66;//引用和指針常量int& ref = a;int* const p = &a;ref = 666;cout << "a = " << a << endl;*p = 888;cout << "a = " << a << endl;cout << "a的地址為:" << &a << endl;cout << "ref的地址為:" << &ref << endl;cout << "p的地址為:" << &p << endl;cout << "p的值為: " << p << endl;//綁定指針的引用int* ptr = &a;int*& pref = ptr; //pref是ptr指針的別名*ptr = 100;cout << "a = " << a << endl;cin.get();
}
運行結果:
八、函數
8.1、函數的定義
一個完整的函數定義主要包括以下部分:
????????返回類型:調用函數之后,返回結果的數據類型;
????????函數名:用來命名代碼塊的標識符,在當前作用域內唯一;
????????參數列表:參數表示函數調用時需要傳入的數據,一般叫做“形參”;放在函數名后的小括號里,可以有o個或多個,用逗號隔開;
????????函數體:函數要執行的語句塊,用花括號括起來。????????
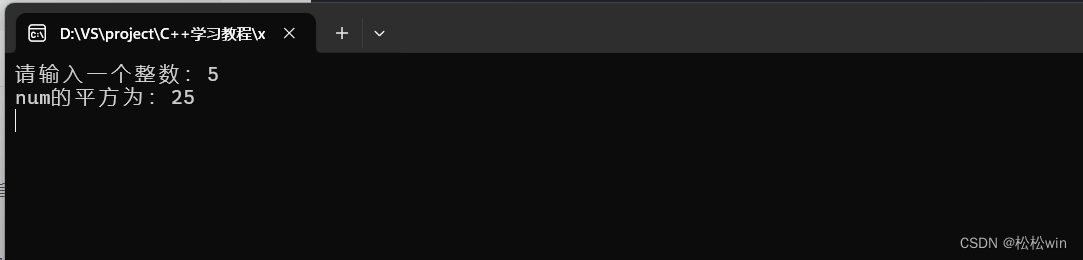
#include<iostream>using namespace std;//定義一個平方函數
int square(int x)
{int y = x * x;return y;
}int main()
{cout << "請輸入一個整數:";int num;cin >> num;cin.get();cout << "num的平方為:" << square(num) << endl;cin.get();
}運行結果:
8.1.2、局部變量的生命周期
對于花括號內定義的變量,具有“塊作用域”,在花括號外就不可見了。函數體都是語句塊,而主函數main本身也是一個函數;所以在main 中定義的所有變量、所有函數形參和在函數體內部定義的變量,都具有塊作用域,統稱為“局部變量”。局部變量僅在函數作用域內部可見。

在C++中,作用域指的是變量名字的可見范圍;變量不可見,并不代表變量所指代的數據對象就銷毀了。這是兩個不同的概念:
????????作用域:針對名字而言,是程序文本中的一部分,名字在這部分可見;
? ? ? ??生命周期:針對數據對象而言,是程序在執行過程中,對象從創建到銷毀的時間段
基于作用域,變量可以分為“局部變量”和“全局變量”。對于全局變量而言,名字全局可見,對象也只有在程序結束時才銷毀。
而對于局部變量代表的數據對象,基于生命周期,又可以分為“自動對象”和“靜態對象”。
(1)自動對象
平常代碼中定義的普通局部變量,生命周期為:在程序執行到變量定義語句時創建,在程序運行到當前塊末尾時銷毀。這樣的對象稱為“自動對象”。
形參也是一種自動對象。形參定義在函數體作用域內,一旦函數終止,形參也就被銷毀了。
對于自動對象來說,它的生命周期和作用域是一致的。
(2)靜態對象
如果希望延長一個局部變量的生命周期,讓它在作用域外依然保留,可以在定義局部變量時加上static關鍵字;這樣的對象叫做“局部靜態對象”。
局部靜態對象只有局部的作用域,在塊外依然是不可見的;但是它的生命周期貫穿整個程序運行過程,只有在程序結束時才被銷毀,這一點與全局變量類似。
8.1.3、分離式編譯和頭文件
(1)分離式編譯
當程序越來越復雜,我們就會希望代碼分散到不同的文件中來做管理。C++支持分離式編譯,這就可以把函數單獨放在一個文件,獨立編譯之后鏈接運行。
比如可以把復制字符串的函數單獨保存成一個文件 copy_string.cpp:
(2)編寫頭文件
對于一個項目而言,有些定義可能是所有文件共用的,比如一些常量、結構體/類,以及功能性的函數。于是每次需要引入時,都得做一堆聲明——這顯然太麻煩了。
一個好方法是,把它們定義在同一個文件中,需要時用一句#include 統一引入就可以了,就像使用庫一樣。這樣的文件以.h作為后綴,被稱為“頭文件”。
8.2、參數傳遞
參數傳遞和變量的初始化類似,根據形參的類型可以分為兩種方式:傳值(value)和傳引用(reference)。


8.2.1、傳引用參數
(1)傳引用方便函數調用
C++新增了引用的概念,可以替換必須使用指針的場景。采用引用作為函數形參,可以使函數調用更加方便。這種傳參方式叫做“傳引用參數”。之前的例子就可以改寫成:
#include<iostream>using namespace std;//使用引用作為形參
void increase(int& x)
{++x;
}int main()
{int num = 0;increase(num);cout << "num = " << num << endl;cin.get();
}運行結果:

(2)傳引用避免拷貝
使用引用還有一個非常重要的場景,就是不希望進行值拷貝的時候。實際應用中,很多時候函數要操作的對象可能非常龐大,如果做值拷貝會使得效率大大降低;這時使用引用就是一個好方法。
比如,想要定義一個函數比較兩個字符串的長度,需要將兩個字符串作為參數傳入。因為字符串有可能非常長,直接做值拷貝并不是一個好選擇,最好的方式就是傳遞引用:

8.2.2、數組形參
數組是不允許做直接拷貝的,所以如果想要把數組作為函數的形參,使用值傳遞的方式是不可行的。與此同時,數組名可以解析成一個指針,所以可以用傳遞指針的方式來處理數組。|
比如一個簡單的函數,需要遍歷int類型數組所有元素并輸出,就可以這樣聲明:

#include<iostream>using namespace std;//遍歷數組
void printArray(const int* arr, int size)
{for (int i = 0; i < size; i++){cout << arr[i] << "\t";}cout << endl;
}int main()
{int arr[5] = { 1,2,3,4,5 };printArray(arr, 5);cin.get();
}運行結果:

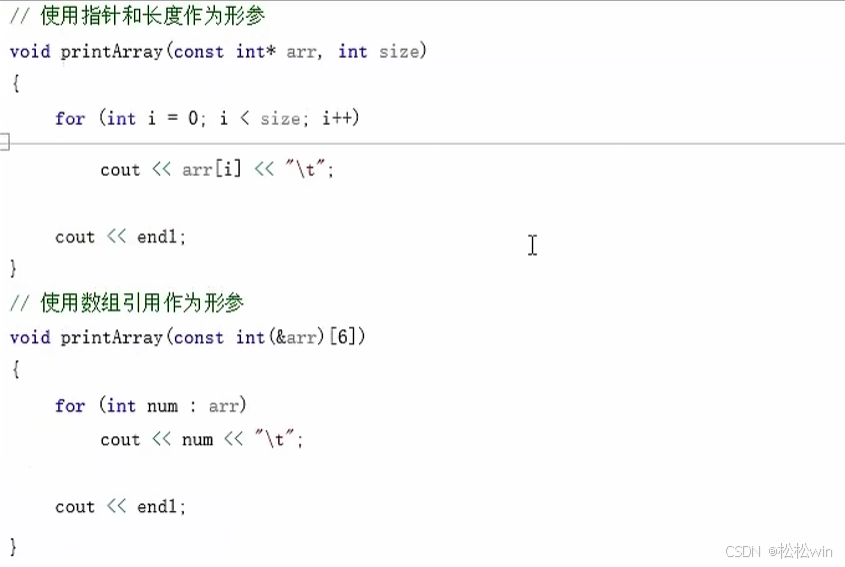
8.2.3、數組引用作為形參
#include<iostream>using namespace std;//遍歷數組
void printArray(const int* arr, int size)
{for (int i = 0; i < size; i++){cout << arr[i] << "\t";}cout << endl;
}void printArray(const int(& arr)[5])
{for (int num : arr){cout << num << "\t";}cout << endl;
}int main()
{int arr[5] = { 1,2,3,4,5 };printArray(arr, 5);printArray(arr);cin.get();
}運行結果:
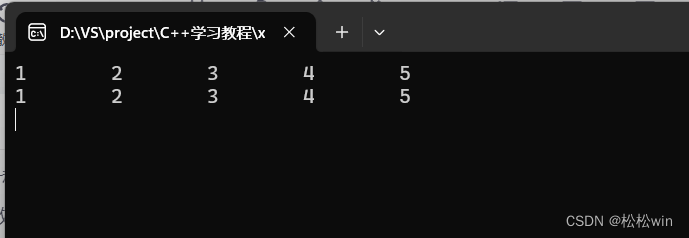
8.3.1、無返回值
#include<iostream>using namespace std;void swap(int& x, int& y)
{int temp = x;x = y;y = temp;
}int main()
{int a = 66, b = 88;swap(a, b);cout << "a = " << a << endl;cout << "b = " << b << endl;cin.get();
}運行結果:

8.3.2、有返回值
#include<iostream>using namespace std;void swap(int& x, int& y)
{int temp = x;x = y;y = temp;
}//有返回值的函數,返回較長的字符串
string longstr(const string& str1, const string& str2)
{return str1.size() >= str2.size() ? str1 : str2;
}int main()
{int a = 66, b = 88;swap(a, b);cout << "a = " << a << endl;cout << "b = " << b << endl;string str1 = "hello";string str2 = "hello world";cout << longstr(str1, str2) << endl;cin.get();
}運行結果:

8.3.3、返回數組指針

這里對于函數fun的聲明,我們可以進行層層解析:
????????fun(int x):函數名為fun,形參為int類型的x;
????????(*fun(int 炳 ):函數返回的結果,可以執行解引用操作,說明是一個指針;
????????( *fun(int x))[5]:函數返回結果解引用之后是一個長度為5的數組,說明返回類型是數組指針;
????????int ( * fun(int x) )[5]:數組中元素類型為int

九、遞歸
如果一個函數調用了自身,這樣的函數就叫做“遞歸函數”(recursivefunction)。
1、遞歸的實現
遞歸是調用自身,如果不加限制,這個過程是不會結束的;函數永遠調用自己下去,最終會導致程序棧空間耗盡。所以在遞歸函數中,一定會有某種“基準情況”,這個時候不會調用自身,而是直接返回結果。基準情況的處理保證了遞歸能夠結束。|
遞歸是不斷地自我重復,這一點和循環有相似之處。事實上,遞歸和循環往往可以實現同樣的功能。
#include<iostream>using namespace std;//用遞歸實現階乘
int factorial(int n)
{if (n == 1)return 1;return factorial(n - 1) * n;
}int main()
{cout << "5! = " << factorial(5) << endl;cin.get();
}運行結果:
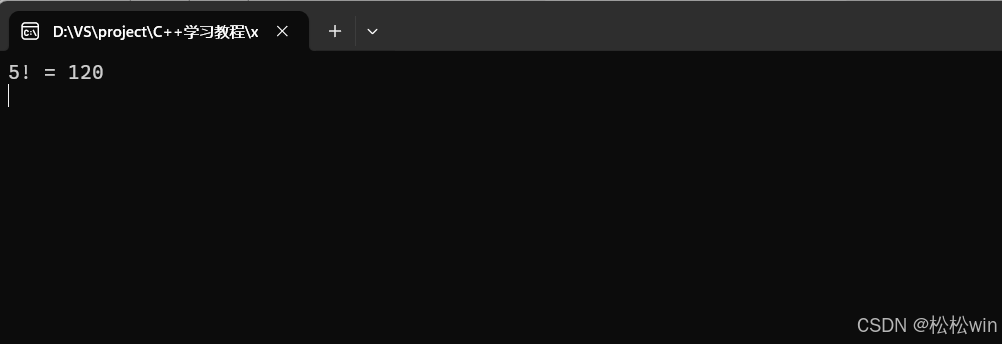
這里我們的基準情況是n ==1,也就是當n不斷減小,直到1時就結束遞歸直接返回。5的階乘具體計算流程如下:

因為遞歸至少需要額外的棧空間開銷,所以遞歸的效率往往會比循環低一些。不過在很多數學問題上,遞歸可以讓代碼非常簡潔。
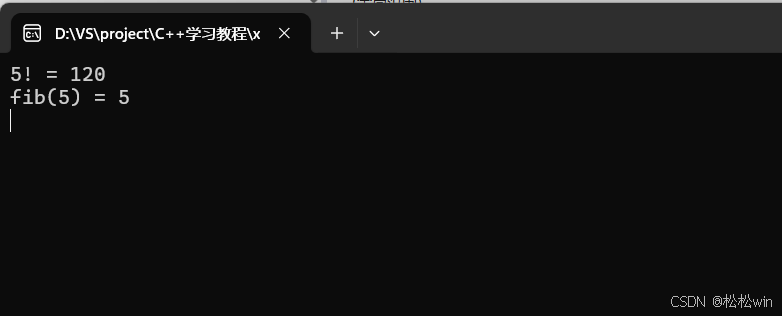
2、經典遞歸-------斐波那契數列

#include<iostream>using namespace std;//用遞歸實現階乘
int factorial(int n)
{if (n == 1)return 1;return factorial(n - 1) * n;
}//斐波那契數列
int fib(int n)
{if (n == 1 || n == 2)return 1;return fib(n - 1) + fib(n - 2);
}int main()
{cout << "5! = " << factorial(5) << endl;cout << "fib(5) = " << fib(5) << endl;cin.get();
}運行結果:
十、函數高階
1、內聯函數
內聯函數是C++為了提高運行速度做的一項優化。
函數讓代碼更加模塊化,可重用性、可讀性大大提高;不過函數也有一個缺點:函數調用需要執行一系列額外操作,會降低程序運行效率。
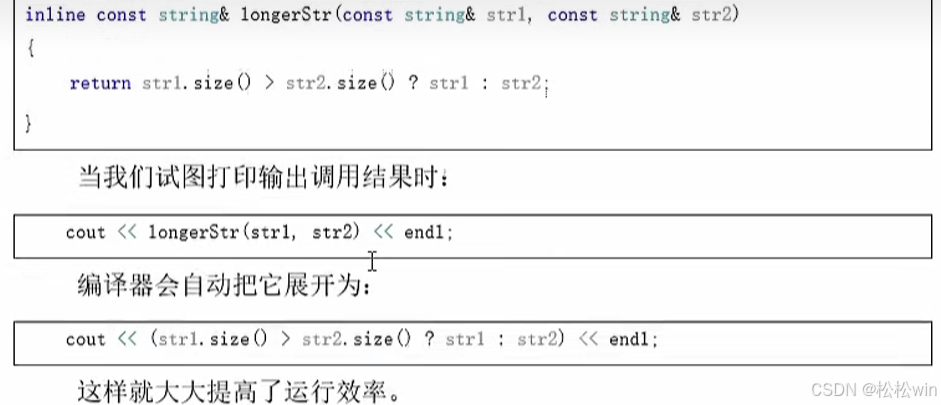
為了解決這個問題,C++引入了“內聯函數”的概念。使用內聯函數時,編譯器不再去做常規的函數調用,而是把它在調用點上“內聯”展開,也就是直接用函數代碼替換了函數調用。
1.1內聯函數的定義
定義內聯函數,只需要在函數聲明或者函數定義前加上 inline關鍵字。
1.2內聯函數和宏
內聯函數是C++新增的特性。在C語言中,類似功能是通過預處理語句和#define定義“宏”來實現的。
然而c中的宏本身并不是函數,無法進行值傳遞;它的本質是文本替換,我們一般只用宏來定義常量。用宏實現函數的功能會比較麻煩,而且可讀性較差。所以在C++中,一般都會用內聯函數來取代C中的宏。
2、函數重載
在C++中,同一作用域下,同一個函數名是可以定義多次的,前提是形參列表不同。這種名字相同但形參列表不同的函數,叫做“重載函數”。這是C++相對c語言的重大改進,也是面向對象的基礎。
2.1定義重裝函數
重載的函數,應該在形參的數量或者類型上有所不同;
形參的名稱在類型中可以省略,所以只有形參名不同的函數是一樣的;
調用函數時,編譯器會根據傳遞的實參個數和類型,自動推斷使用哪個函數;
主函數不能重載
2.2函數匹配

確定到底調用哪個函數的過程,叫做“函數匹配”。

#include<iostream>using namespace std;void f() { cout << "1" << endl; }
void f(int x) { cout << "2" << endl; }
void f(int x, int y) { cout << "3" << endl; }
void f(double x, double y = 1.5) { cout << "4" << endl; }int main()
{f(3.14);cin.get();
}運行結果:



2.3函數重裝和作用域
重載是否生效,跟作用域是有關系的。如果在內層、外層作用域分別聲明了同名的函數,那么內層作用域中的函數會覆蓋外層的同名實體,讓它隱藏起來。
不同的作用域中,是無法重載函數名的。
3、函數指針
一類特殊的指針,指向的不是數據對象而是函數,這就是“函數指針”
3.1聲明函數指針
函數指針本質還是指針,它的類型和所指向的對象類型有關。現在指向的是函數,函數的類型是由它的返回類型和形參類型共同決定的,跟函數名、形參名都沒有關系。

3.2使用函數指針
當一個函數名后面跟調用操作符(小括號),表示函數調用;而單獨使用函數名作為一個值時,函數會自動轉換成指針。這一點跟數組名類似。
所以我們可以直接使用函數名給函數指針賦值:

也可以加上取地址符&,這和不加&是等價的。
3.3函數指針作為形參
有了指向函數的指針,就給函數帶來了更加豐富靈活的用法。比如,可以將函數指針作為形參,定義在另一個函數中。也就是說,可以定義一個函數,它以另一個函數類型作為形參。當然,函數本身不能作為形參,不過函數指針完美地填補了這個空缺。這一點上,函數跟數組非常類似。
3.4函數指針作為返回值





(優化版2))
:如何防止一個賬號多個地方登陸)


)


 ,是否有其他進程正占用它?)







——死鎖)