目錄
- 從文本開始
- 構建用戶畫像
- 一、結構化文本
- 1、TF-IDF
- 2、TextRank
- 3、內容分類:
- 4、實體識別
- 5、聚類
- 6、詞嵌入
- 二、標簽選擇
- 1、卡方檢驗
- 2、信息增益
- 總結
對于一個早期的推薦系統來說,基于內容推薦離不開用戶構建一個初級的畫像,這種初級的畫像一般叫做用戶畫像(User Profile),今天我就來講一講從大量文本數據中挖掘用戶畫像常常用到的一些算法;
從文本開始
用戶這一端比如說有:
1、注冊資料中的姓名、個人簽名;
2、發表的評論、動態、日志等;
3、聊天記錄;
物品這一端也有大量文本信息,可以用于構建物品畫像(Item Profile),并最終幫助豐富用戶畫像(User Profile),這些數據舉例來說有:
1、物品的標題、描述;
2、物品本身的內容(一般指新聞資訊類);
3、物品的其他基本屬性的文本;
文本數據是互聯網產品中最常見的信息表達形式,數量多、處理快、存儲小,因為文本數據的特殊地位,所以今天專門介紹一些建立用戶畫像過程中用到的文本挖掘算法。
構建用戶畫像
要用物品和用戶的文本信息構建出一個基礎版的用戶畫像,大致需要做這些事;
1、把所有非結構化的文本結構化,去粗取精,保留關鍵信息;
2、根據用戶行為數據把物品的結構化結果傳遞給用戶,與用戶自己的結構化信息合并;
第一步最關鍵也最基礎,其準確性,粒度,覆蓋面都決定了用戶畫像的質量,這一步用到很多文本挖掘算法。
第二步會把物品的文本分析結果,按照用戶歷史行為把物品畫像(Item Profile)傳遞給用戶。
一、結構化文本
我們拿到的文本,常常是自然語言描述的,非結構化的,但是計算機在處理時,只能使用結構化的數據索引,檢索,然后向量化后再計算;所以文本分析,就是為了將非結構化的數據結構化。
從物品端的文本信息,我們可以利用成熟的NLP 算法分析得到的信息有下面幾種。
1、關鍵詞提取:最基本的標簽來源,也為其他文本分析提供基礎數據,常用TF-IDF和TextRank。
2、實體識別:人物、位置和地點、著作、影視劇、歷史事件和熱點事件等,常用于基于詞典的方法結合CRF模型。
3、內容分類:將文本按照分類體系分類,用分類來表達較粗粒度的結構化信息。
4、文本:在無人制定分類體系的前提下,無監督地將文本劃分成多個類簇也很常見,別看不是標簽,簇類編號也是用戶畫像的常見構成。
5、主題模型:從大量已有文本中學習主題向量,然后再預測新的文本在各個主題上的概率分布情況,其實這也是一種聚類思想,主題向量也不是標簽形式,也是用戶畫像的常用構成。
6、嵌入:也叫Embedding,從詞到篇章,無不可以學習這種嵌入表達。嵌入表達就是為了挖掘出字面意思之下的語義信息,并且用有限的維度表達出來。
下面我來介紹幾種常見的文本結構化算法。
1、TF-IDF
TF全稱就是Term Frequency,是詞頻的意思,IDF就是Inverse Document Frequency是逆文檔頻率的意思。TF-IDF 提取關鍵詞的思想來自信息檢索領域,其實思想很樸素,
包含了兩點:在一篇文本中反復出現的詞會更重要,在所有文本中都出現的詞更不重要。這兩點就分別量化成 TF和IDF兩個指標;
1、TF,就是詞頻,要提取關鍵詞在文本中出現的次數;
2、IDF,是提前統計好的,在已有的所有文本中,統計每一個詞出現在了多少文本中,記為n,也就是文檔頻率,一共有多少文本,記為N。
IDF就是這樣計算:
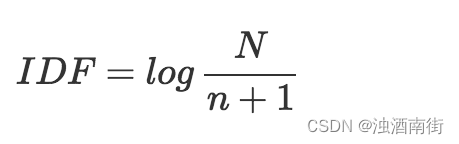
計算過程為:詞出現的文檔數加1,再除總文檔數,最后結果再取對數。
IDF的計算公式有這么幾個特點:
1、所有詞的N都是一樣的,因此出現文本數越少(n)的詞,它的IDF值越大;
2、如果一個詞的文檔頻率為0,為防止計算出無窮大的IDF,所以分母中會有一個1;
計算出TF和IDF后,將兩個值相乘,就得到每一個詞的權重。根據該權重篩選關鍵詞的方式有:
1、給定一個K,取Top K個詞,這樣做簡單直接,但有一點,如果總共得到的詞個數少于K,那么所有詞都是關鍵詞了,顯然這樣做不合理。
2、計算所有詞權重的平均值,取在平均值之上的詞作為關鍵詞;
另外,在某些場景下,還會加上以下其他過濾措施,如:只提取動詞和名詞作為關鍵詞。
2、TextRank
TextRank是PageRank的私生子之一,著名的pagerank算法是Google用來衡量網頁重要性的算法,TextRank算法的思想也與之類似,可以概括為:
1、文本中,設定一個窗口寬度,比如k個詞,統計窗口內的詞和詞的共線關系,將其看成無向圖。圖就是網絡,由存在連接關系的節點構成,所謂無向圖,就是節點之間的連線不考慮從誰出發,有關系就可以了。
2、所有詞初始化的重要性都是1;
3、每個節點把自己的權重平均分配給“和自己有連接”的其他節點;
4、每個節點將所有其他節點分給自己的權重求和,作為自己的新權重;
5、如此反復迭代第3,4兩步,直到所有的節點權重收斂為止。
通過TextRank計算后的詞語權重,呈現出這樣的特點:那些有共線關系的會互相支持對方成為關鍵詞。
3、內容分類:
在門戶網站時代,每個門戶網站都有自己的頻道體系,這個頻道體系就是一個非常大的內容分類體系,這一做法也延伸到了移動互聯網UGC時代,圖文信息流APP的資訊內容也需要被自動分類到不同的頻道中,從而能夠得到最粗粒度的結構化信息,也被很多推薦系統用來在用戶冷啟動時探索用戶興趣。
在門戶時代的內容分類,相對來說容易,因為那時候的內容都是長文本,長文本的內容分類可以提取很多信息,而如今UGC當道的時代,短文本的內容分類則更困難一些。短文本分類方面的經典算法是SVM,子啊工具上現在最常用的是Facebook開源的FastText。
4、實體識別
命名實體識別(也常常被簡稱為NER,Name-Entity Recognition)在NLP技術中常常被認為是序列標注問題,和分詞、詞性標注屬于同一類問題。
所謂序列標注問題,就是給你一個字符序列,從左往右遍歷每個字符,一邊遍歷一邊對每一個字符分類,分類的體系因序列標注問題不同而不同;
1、分詞問題:對每一個字符分類為“詞開始”“詞中間”“詞結束”三類之一;
2、詞性標注:對于每一個分好的詞,分類為定義的詞性集合之一;
3、實體識別:對每一個分好的詞,識別為定義的命名實體集合之一;
對于序列標注問題,通常的算法就是隱馬爾可夫模型(HMM)或者條件隨機場(CRF),我們在推薦系統中主要是挖掘出想要的結構化結果,對其中原理有興趣再去深入了解。
實體識別還有比較實用化的非模型做法:詞典法。提前準備好各種實體的詞典,使用trie-tree數據結構存儲,拿著分好的詞去詞典里找,找到某個詞就任務是提前定義好的實體。以實體識別為代表的序列標注問題上,工業級別的工具SpaCy比NLTK在效率上優秀一些;
5、聚類
傳統聚類方法在文本中的應用,今天逐漸被主題模型取代,同樣是無監督模型,以LDA為代表的主題模型更能夠更準確地抓住主題,并且能夠得到軟聚類的效果,也就是說可以讓一條文本屬于多個類簇。
LDA模型需要設定主題個數,如果你有時間,那么這個K可以通過一些實驗來對比挑選,方法是:每次計算K個主題兩兩之間的平均相似度,選擇一個較低的K值;在推薦系統領域,只要計算資源夠用,主題數可以盡量多一些。
另外,需要注意的事,得到文本在各個主題上的分布,可以保留概率最大的前幾個主題作為文本的主題。LDA工程上較難的是并行化,如果文本數量沒有到海量程度,提高單機配置是可以的,開源的LDA訓練工具有Gensim,PLDA等可供選擇。
6、詞嵌入
關于嵌入,是一個數學概念。以詞嵌入為例來說吧。
詞嵌入,也叫作Word Embedding。前面講到的結構化方案,除了LDA,其他得到的一下標簽無一例外都是稀疏的,而詞嵌入則能夠為每一個詞學習得到一個稠密的向量。
比如北京,可能包含“首都,中國,北方,直轄市,大城市”等等這些詞義在所有文本上是有限的,比如128個,于是每個詞就有一個128維的向量表達,向量中各個維度上的值大小代表了詞包含各個語義的多少。
得到這些向量可以做:
1、計算詞和詞之間的相似度,擴充結構化標簽;
2、累加得到一個文本的稠密向量;
3、用于聚類,會得到比使用詞向量聚類更好的語義聚類效果。
這方面當屬大名鼎鼎的Word2Vec了,Word2Vec是用淺層神經網絡學習得到每個詞的向量表達,Word2Vec最大的貢獻在于一些工程技巧上的優化,使得百萬詞的規模是在單機上可以幾分鐘輕松跑出來,得到這些詞向量后可以聚類或者進一步合成句子向量再使用;
二、標簽選擇
用戶端的文本,物品端的文本如何結構化,得到諸如標簽(關鍵詞,分類等)、主題、詞嵌入向量。接下來就是第二步:如何把物品的結構化信息給用戶呢?
我們想一想,用戶在產品上看到了很多我們用各種邏輯和理由展示給他的物品,他只從中消費了一部分物品。現在問題就是,到底是哪些特性吸引了他消費呢?
我們把用戶對物品的行為,消費沒有消費看成是一個分類問題。用戶用實際行動幫我們標注了若干數據,那么挑選出他實際感興趣的特性就變成了特征選擇問題。
最常用的兩個方法:卡方檢驗(CHI)和信息增益(IG)。基本思想是:
1、把物品的結構化內容看成文檔;
2、把用戶對物品的行為看成是類別;
3、每個用戶看到過的物品就是一個文本集合;
4、在這個文本集合上使用特征選擇算法選出每個用戶關心的東西。
1、卡方檢驗
CHI就是卡方檢驗,本身是一種特征選擇方法。
前面的TF-IDF和TextRank都是無監督關鍵詞提取算法,而卡方檢驗(CHI)則是有監督的,需要提供分類標注信息。
為什么需要呢?在文本分類任務中,挑選關鍵詞是為了分類任務服務,而不僅僅是挑選出一種直觀上看著重要的詞。
卡方檢驗本質上在檢驗詞和某個類別C相互獨立這個假設是否成立,和這個假設偏離越大,就越說明這個詞和類別C關聯緊密,那當然這個詞就是關鍵詞了。
計算一個詞Wi和Cj的卡方值,需要統計四個值:
1、類別為 C j C_j Cj?的文本中出現詞 W i W_i Wi?的文本數A;
2、詞 W i W_i Wi?在非 C j C_j Cj?的文本中出現的文本數B;
3、類別為 C j C_j Cj?的文本中沒有出現詞 W i W_i Wi?的文本數C;
4、詞 W i W_i Wi?在非 C j C_j Cj?的文本中沒有出現的文本數D;
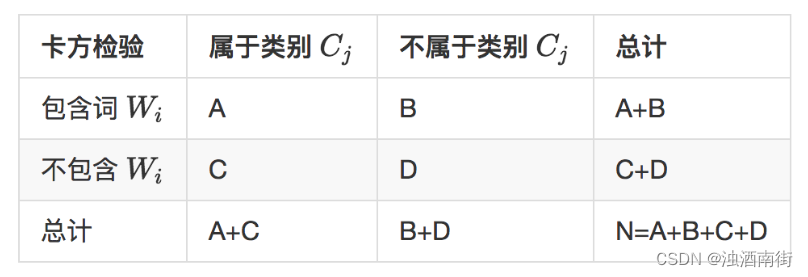
然后按照如下公式計算每一個詞和每一個類別的卡方值:
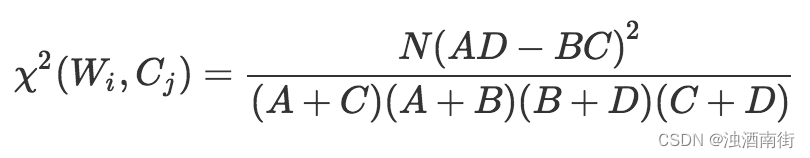
關于這個卡方值計算,我在這里說明幾點:
1、每個詞和每個類別都要計算,只要對其中一個類別有幫助都應該留下;
2、由于是比較卡方值的大小,所以公式的N可以不參與計算,因為它對于每個詞都一樣,就是總的文本數;
3、卡方值越大,意為著偏離詞和類比相互獨立的假設越遠;
2、信息增益
IG即information Gain,信息增益,也是一種有監督的關鍵詞選擇方法,也需要有標注信息。要理解信息增益,先理解信息熵;
信息熵,舉一個例子,比如一批文本被標注了類別,那么隨意挑選一個文本,問你這是什么類別?
如果各個類別的文本數量都差不多,也就是說每個類別的概率都相對較小,則信息熵較大;
如果其中一個類別的文本數明顯大于其他類別,你猜這個類比猜對的概率就相對較大,此時這個類別的信息熵則較小;
可以簡單理解信息熵和概率成反比,信息熵大,概率低,信息熵小,則概率大;
信息增益表示在得知特征X的信息后,對于分類結果的不確定性的減少程度。具體來說,信息增益是指在得知特征X的取值后,對于分類結果的熵減少的程度。
信息增益的計算公式如下:
信息增益 = 父節點的熵 ? 子節點的熵 \text{信息增益} = \text{父節點的熵} - \text{子節點的熵} 信息增益=父節點的熵?子節點的熵
信息增益應用最廣就是數據挖掘中的決策樹分類算法,經典的決策樹分類算法挑選分裂節點時就是計算各個屬性的信息增益,始終挑選信息增益最大的節點作為分裂節點。
卡方檢驗和信息增益不同之處在于:前者是針對每一個行為單獨篩選一套標簽出來,后者是全局統一篩選;
這些方法都是在離線階段批量完成的,把用戶的畫像生成配置成離線任務,每天更新一遍,次日就可以使用新的用戶畫像了。
總結
用戶畫像對于推薦系統還是非常必要的,而產品中屬文本數據越多,那如何用文本數據構建出用戶的畫像內容呢?
本文按照如下步驟梳理了這一過程:
1、分析用戶的文本和物品的文本,使其結構化;
2、為用戶挑選有信息量的結構化數據,作為其畫像內容;
其中,我們提出了把為用戶挑選畫像標簽看成是特征選擇問題,主要方法是卡方檢驗和信息增益。


)




)
)





![[office] 快速刪除excel中的空行和列的方法 #其他#學習方法#經驗分享](http://pic.xiahunao.cn/[office] 快速刪除excel中的空行和列的方法 #其他#學習方法#經驗分享)




