Python 機器學習 基礎 之 【實戰案例】中藥數據分析項目實戰
目錄
Python 機器學習 基礎 之 【實戰案例】中藥數據分析項目實戰
一、簡單介紹
二、中藥數據分析項目實戰
三、數據處理與分析實戰
1、數據讀取
2、中藥材數據集的數據處理與分析
2.1數據清洗
2.2、 提取別名
3、提取藥方成分
4、挖掘常用藥物組合
四、小結
附錄
一、代碼地址
二、文中的關聯圖(帶權有向圖)簡單繪制代碼參考
一、簡單介紹
Python是一種跨平臺的計算機程序設計語言。是一種面向對象的動態類型語言,最初被設計用于編寫自動化腳本(shell),隨著版本的不斷更新和語言新功能的添加,越多被用于獨立的、大型項目的開發。Python是一種解釋型腳本語言,可以應用于以下領域: Web 和 Internet開發、科學計算和統計、人工智能、教育、桌面界面開發、軟件開發、后端開發、網絡爬蟲。
Python 機器學習是利用 Python 編程語言中的各種工具和庫來實現機器學習算法和技術的過程。Python 是一種功能強大且易于學習和使用的編程語言,因此成為了機器學習領域的首選語言之一。Python 提供了豐富的機器學習庫,如Scikit-learn、TensorFlow、Keras、PyTorch等,這些庫包含了許多常用的機器學習算法和深度學習框架,使得開發者能夠快速實現、測試和部署各種機器學習模型。
Python 機器學習涵蓋了許多任務和技術,包括但不限于:
- 監督學習:包括分類、回歸等任務。
- 無監督學習:如聚類、降維等。
- 半監督學習:結合了有監督和無監督學習的技術。
- 強化學習:通過與環境的交互學習來優化決策策略。
- 深度學習:利用深度神經網絡進行學習和預測。
通過 Python 進行機器學習,開發者可以利用其豐富的工具和庫來處理數據、構建模型、評估模型性能,并將模型部署到實際應用中。Python 的易用性和龐大的社區支持使得機器學習在各個領域都得到了廣泛的應用和發展。
二、中藥數據分析項目實戰
接下來,本文將深入探討如何運用Python在中醫藥領域的數據挖掘與分析。通過一系列數據處理技術,本文不僅將揭示中藥材、中成藥和中藥方劑的內在聯系和特性,還將展示如何從大量復雜的數據中提取有價值的信息。以下是對原文的豐富和擴展:
-
中藥材數據集的數據清洗與探索:文章首先將介紹如何使用Python進行中藥材數據集的清洗工作,包括去除重復記錄、處理缺失值和異常值。隨后,將引導讀者如何探索性分析數據集,識別中藥材的基本屬性和分布特征。
-
文本處理與自然語言處理:在文本處理部分,將展示如何應用分詞技術來處理中醫文獻和方劑說明,這有助于理解中醫藥的用法和配伍規律。通過自然語言處理技術,可以更好地解析和利用非結構化的文本數據。
-
關聯規則分析算法的應用:文章將重點介紹關聯規則分析,這是一種發現變量之間有趣關系(頻繁項集和關聯規則)的方法。在中醫藥領域,此技術可以用來分析不同藥材之間的組合規律和用藥習慣。
-
構建中藥材詞典:通過數據挖掘技術,本文將指導讀者如何構建一個包含中藥材名稱、屬性、功效等信息的詞典,為中醫藥研究和應用提供基礎數據支持。
-
中成藥和中藥方劑的藥物構成分析:本文將分析中成藥和中藥方劑的組成,揭示它們的配伍原理和治療邏輯,幫助讀者理解中醫藥方的復雜性和精妙性。
-
特殊字段的數據獲取與過濾:文章將教授讀者如何根據特定的字段或條件來獲取和過濾數據,例如根據藥材的性味或歸經來篩選相關的中藥材或方劑。
-
過濾后數據的關聯規則分析:最后,將展示如何對過濾后的數據應用關聯規則分析,以發現特定的用藥模式和潛在的臨床應用價值。
通過本文的學習,讀者將能夠綜合運用數據清洗、數據處理和數據挖掘技術,不僅在中醫藥領域,也能在其他領域進行有效的數據分析和知識發現。我們希望讀者能夠通過本文,提升自己的數據處理能力,并在實際工作中發揮數據挖掘技術的價值。
中藥是一種統稱,凡是以傳統中醫理論指導采集、炮制、制劑,指導臨床應用的藥物都可以稱為中藥。中藥來源寬泛,包含植物藥、動物藥、礦物藥、化學制藥、生物制藥。方劑指中醫治病的藥方。中成藥指以中藥材為原料,依照中醫理論制造的藥物。隨著時代的發展,越來越多的中醫傳統方劑不斷被發掘。同時,根據中藥理論,不斷地有新的中成藥被制作。中成藥與傳統方劑都是依照傳統中醫理論制作的,雖然藥物制備方法與中藥環境有所差別,但中藥材的基本成分與組合搭配卻不會發生實質性的變化。另外,除單個中藥材外,不同中藥材的組合往往也是中藥是否能夠發揮作用的關鍵。通過分析中藥方劑與中成藥的藥方,可以得到常用的藥材組合,從而可以為新藥研究與中藥的臨床應用提供巨大的醫學價值。同時,通過比對中成藥與傳統中藥方劑之間的中藥材使用區別,也可以為現代中成藥的制作提供巨大的參考價值。
本項目提供了中藥材和中成藥兩種數據。本章中,我們將把事先獲取的數據與機器學習和數據挖掘技術相結合,完成以下兩個研究目標:
●?清理原始數據,獲得中成藥與方劑的藥材構成。
●?分析中成藥中的常用藥物組合,并根據組合的具體數據提出有利于研究的藥物組合。
三、數據處理與分析實戰
中藥的種類有很多,除常用的一般中藥材外,傳統方劑中有時也會包含其他特殊的藥材。因此,獲取中成藥與方劑的藥材構成:
第一個研究目標為:清理原始數據,獲得中成藥與方劑的藥材構成。對于這一研究目標,我們需要使用文本處理與自然語言處理方法,從中成藥與方劑的有關數據中提取有效數據。由于藥材本身具有別名,因此需要構建有關的藥物詞典,避免將一種藥材當作多種藥材的錯誤。在詞典構建后即可使用分詞、數據清洗等一般方法創建分詞鏈表,然后進行中藥材的提取。
第二個研究目標為:分析中成藥中的常用藥物組合,并根據組合的具體數據提出有利于研究的藥物組合。在第一個研究目標完成后,即可得到常用藥物組合,之后則利用數據挖掘中有關關聯規則分析的算法,獲取常用藥物組合。藥物組合獲取后,對于其中較為復雜的藥物組合網絡,可以利用知識圖譜相關技術進行分析。
1、數據讀取
原始數據為兩個CSV表格,直接使用Pandas庫讀取有關數據。讀取數據后,可以調用head方法查看前10條數據,調用describe方法查看常用數據描述。不過本項目數據皆為文本數據,因此無法查看最大值、最小值、標準差等基本統計數據。
查看數據代碼如下:
import pandas as pd
# 導入pandas庫,并將其簡稱為pd。Pandas是一個強大的數據分析和操作庫,常用于數據預處理。df_name = pd.read_csv("./data/name.csv", header=0)
# 使用pandas的read_csv函數讀取當前目錄下data文件夾中的name.csv文件。
# header=0指定第一行作為列名(header)。
# 讀取的數據被存儲在DataFrame對象df_name中。DataFrame是pandas中用于存儲表格數據的主要數據結構。df_name.head(10)
# 調用df_name的head方法并傳入參數10,這將返回DataFrame的前10行。
# head方法用于快速查看DataFrame的開始部分,是一個便捷的方式進行數據的初步檢查。
# 這里的輸出將顯示df_name DataFrame的前10行數據。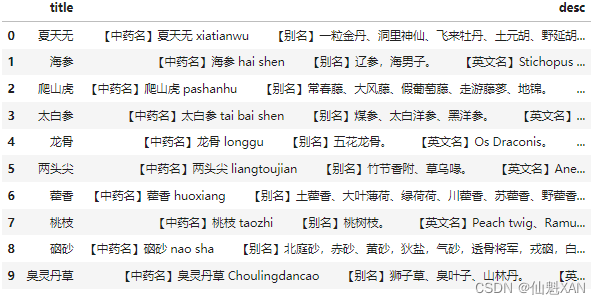
2、中藥材數據集的數據處理與分析
2.1數據清洗
首先需要提取的數據為中藥材數據集中的藥名,藥名存在于desc中,desc中的具體字段為:中藥名、別名、英文名、藥用部位、植物形態、藥材性狀、產地分布、采收加工、性味歸經、臨床應用、功效與作用、使用禁忌、相關藥方、化學成分、藥理研究。部分數據并不包含所有的數據種類。由研究目標可知,本次數據中可能會直接使用的為:中藥名、別名、臨床應用、功效與作用、化學成分。藥理研究與植物形態、相關藥方等內容,則可能在進行有關分析時有用。
由于desc中并非直接分類好的數據,而是將所有數據都作為文本數據存儲,且存在大量空格和其他錯誤字符,因此,需要使用Python建立有關過濾規則進行過濾。展示有關數據進行初步查看可以發現,數據開頭與結尾有空格,且存在大量名為“\u3000”的字符,這兩類問題使用strip與replace方法進行過濾。
過濾后的數據依舊為字符串數據,不同數據說明依靠特殊字符“【】”進行識別,因此這里利用特殊字符進行分隔,分隔后的格式為“字段名1,內容1,字段名2,內容2,...,字段名n,內容n”。分隔完成后,利用字符查詢與list的index方法,定位和獲取所需的數據。別名獲取的具體策略為首先使用字符串“【別名】”與list的定位索引方法index,獲取它在list中的索引,然后將獲得索引加1,獲得其內容。
代碼如下:
# 從df_name DataFrame中選擇名為"desc"的列(假設這一列包含描述性文本)。
# 然后通過索引[0]選擇這一列的第一行數據。# .strip()方法用于移除字符串開頭和結尾的空白字符,這包括空格、制表符、換行符等。
# 這通常用于清理數據,確保分析時不會因為無意義的空白字符影響結果。# .replace('\u3000', '')方法用于將字符串中的特定字符替換掉。
# 這里替換的是Unicode編碼\u3000,這是一個空格字符,常用于某些文檔格式中表示較長的空間。
# 通過替換這個字符,進一步清理了文本數據,移除了可能的格式干擾。
string_clear = df_name["desc"][0].strip().replace('\u3000', '')# 最終,string_clear變量將包含"desc"列第一行數據,已經過移除首尾空白和特定空格字符的清理。
string_clear過濾后desc中的某條數據結果如下:

這段代碼的目的是清洗DataFrame中"desc"列的第一行文本數據。首先,通過索引選擇特定的數據行,然后使用strip方法清除字符串兩端的空白字符,最后使用replace方法移除文本中的特定空格字符,得到一個清理后的字符串存儲在變量string_clear中。這樣的清洗步驟有助于提高后續文本分析或處理的準確性。
使用特殊字符分隔,代碼如下:
list_clear = string_clear.replace('【', '|【').replace('】', '】|').split("|")
# 這行代碼執行了多個字符串操作:
# 1. 使用replace方法將所有的'【'替換為'|【'。
# 2. 再次使用replace方法將所有的'】'替換為'】|'。
# 這樣做的目的是在原有的括號字符前或后添加一個分隔符'|',以便能夠更清晰地分割字符串。
# 3. 最后,使用split方法以'|'作為分隔符將更新后的字符串拆分成一個列表。
# 這將導致所有被'|'包圍的部分成為list_clear列表的元素。list_clear.remove('')
# 這行代碼調用了列表list_clear的remove方法,目的是移除列表中的空字符串元素。
# 在split操作后,如果原始字符串中存在連續的分隔符'|',可能會生成空字符串。
# 通過remove方法,確保清理掉這些無用的空字符串元素,留下非空的、有意義的部分。list_clear
# 這行代碼本身不執行操作,它只是引用了變量list_clear。
# 通常在Python中,單獨引用變量會將其打印出來,或者用于后續的代碼邏輯中。
# 在這個上下文中,list_clear變量包含了清理和分割后的字符串列表。分隔后形成一個由不同屬性及其對應值組成的列表,結果如下:
['【中藥名】','夏天無 xiatianwu','【別名】','一粒金丹、洞里神仙、飛來牡丹、土元胡、野延胡、伏地延胡索、無柄紫堇、落水珠。','【英文名】','Corydalis Decumbentis Rhizoma。','【藥用部位】','罌粟科植物伏生紫堇Corydatis decumbens (Thunb.) Pers.的塊莖。','【植物形態】','多年生草本,全體無毛。塊莖近球形,表面黑色,著生少數須根。莖細弱,叢生,不分枝。基生葉具長柄,葉片三角形,2回三出全裂,末回裂片具短柄,通常狹倒卵形;莖生葉2~3片,生莖下部以上或上部,形似基生葉,但較小,具稍長柄或無柄。總狀花序頂生;苞片卵形或闊披針形.全緣;花淡紫紅色,筒狀唇形,上面花瓣邊近圓形,先端微凹,矩圓筒形,直或向上微彎;雄蕊6,呈兩體。蒴果線形,2瓣裂。種子細小。花期4~5月,果期5~6月。','【產地分布】','生于丘陵、低山坡或草地。喜生于溫暖濕潤、向陽、排水良好、土壤深厚的沙質地。分布于安徽、江蘇、浙江、江西等地。','【采收加工】','春至初夏采塊莖,去泥,洗凈,曬干或鮮用。','【藥材性狀】','類球形、長圓形或不規則塊狀,長0.5~2厘米,直徑0.5~1.5厘米。表面土黃色,棕色或暗綠色,有細皺紋,常有不規則的瘤狀突起及細小的點狀須根痕。質堅脆,斷面黃白色或黃色,顆粒狀或角質樣,有的略帶粉性。氣無,味極苦。以個大、質堅、斷面黃白者為佳。','【性味歸經】','性溫,味苦、微辛。歸肝經。','【功效與作用】','活血、通絡、行氣止痛。屬活血化瘀藥下屬分類的活血止痛藥。','【臨床應用】','用量5~16克,煎湯內服;或研末,1~3g;亦可制成丸劑。用治中風偏癱、小兒麻痹后遺癥、坐骨神經痛、風濕性關節炎、跌打損傷、腰肌勞損等。','【藥理研究】','可引起動物產生“僵住癥”,表現為木僵、嗜睡、肌肉僵硬,如隨意改變其位置,可保持于該種姿勢。藥理實驗表明,本品有抗張血管、抗血小板聚集、鎮痛、解痙、降血壓、松弛回腸平滑肌等作用。夏天無注射液在臨床上治療高血壓腦血管病、骨關節肌肉疾病及青年近視等,均見良效。','【化學成分】','含四氫巴馬亭(即延胡索乙素)、原阿片堿、鹽酸巴馬汀、空褐鱗堿、藤荷包牡丹定堿、夏天無堿、紫堇米定堿、比枯枯靈堿、掌葉防己堿等,其總堿含量達0.98%。應用高效薄層色譜分離及薄層掃描定量,對夏天無的化學成分及含量進行比較,結果表明,其延胡索乙素含量最高。','【使用禁忌】','尚不明確,謹慎用藥。','【相關藥方】','①治高血壓,腦瘤或腦栓塞所致偏癱:鮮夏天無搗爛。每次大粒4~5粒,小粒8~9粒,每天1~3次,米酒或開水送服,連服3~12個月。(《浙江民間常用草藥》)②治各型高血壓病:a.夏天無研末沖服,每次2~4克。b.夏天無、鉤藤、桑白皮、夏枯草。煎服。(江西《中草藥學》)③治風濕性關節炎:夏天無粉每次9克,日2次。(江西《中草藥學》)④治腰肌勞損:夏天無全草15克,煎服。(江西《中草藥學》)']
這段代碼的目的是處理string_clear變量中的文本,通過特定的字符替換和分割操作,生成一個包含有意義文本片段的列表list_clear。首先,通過替換操作在特定的中文括號字符前后添加分隔符|,然后使用這個分隔符來分割字符串,最后移除分割后可能產生的空字符串,得到一個清理過的列表。這樣的處理通常用于文本的預處理階段,為后續的文本分析或處理做準備。
2.2、 提取別名
在定義獲取策略后,編寫能夠提取別名的代碼,并利用dataframe的apply方法將提取后的數據寫入原dataframe。考慮到代碼可能會在之后多處重復使用,因此進行封裝,類似操作不再描述。具體代碼如下:
list_clear[list_clear.index('【別名】')+1].replace("。", '').split('、')
# 這行代碼執行了多個操作,目的是從list_clear中提取和處理別名部分的數據:
# 1. list_clear.index('【別名】'):使用index方法找到字符串'【別名】'在list_clear中首次出現的位置。
# 注意,index方法將返回列表中首次出現的索引,如果沒有找到,會拋出ValueError。# 2. '【別名】'+1:找到'【別名】'字符串后面緊跟的第一個元素的索引。這個索引對應的是別名信息的開始位置。# 3. list_clear[...]:使用方括號和索引來訪問list_clear列表中位于別名索引處的元素。# 4. .replace("。", ''):對獲取的別名字符串使用replace方法移除所有的中文句號“。”。
# 這通常是為了進一步清理數據,移除可能影響文本處理的標點符號。# 5. .split('、'):使用split方法以中文頓號'、'作為分隔符來分割別名字符串。
# 這將把包含多個別名的字符串分割成一個列表,列表中的每個元素都是一個單獨的別名。# 最終,這行代碼將返回一個列表,包含了經過清理和分割的別名,移除了中文句號并按中文頓號分割。結果如下:['一粒金丹', '洞里神仙', '飛來牡丹', '土元胡', '野延胡', '伏地延胡索', '無柄紫堇', '落水珠']
這段代碼的目的是處理一個已經通過特定格式標記分割得到的列表list_clear,從中找到標記為“別名”的部分,然后對這個部分進行進一步的文本清洗和分割操作,最終得到一個包含所有別名、去除了句號并按頓號分割的列表。這樣的處理有助于后續對別名數據的分析或存儲。
提取別名的完整代碼如下:
def apply_get_alias(x, name):# 定義一個函數apply_get_alias,它接受兩個參數:x(字符串)和name(要查找的特定名稱)。string_clear = x.strip().replace('\u3000', '')# 清除x字符串兩端的空白字符,并將全角空格符\u3000替換為空字符串,以清理字符串。list_clear = string_clear.replace('【', '|【').replace('】', '】|').split("|")# 將'【'替換為'|【',將'】'替換為'】|',以便在中文括號周圍添加分隔符'|',然后按'|'分割字符串。list_clear.remove('')# 如果在分割過程中產生了空字符串,將其從list_clear列表中移除。if '【' + name + '】' in list_clear:# 檢查經過處理的列表中是否包含特定名稱的標記(例如'別名')。return list_clear[list_clear.index('【' + name + '】') + 1].replace("。", '').split('、')# 如果存在,找到該標記后的第一個元素(即別名部分),移除中文句號,并按中文頓號分割,返回分割后的列表。else:return "no_alias"# 如果不存在指定名稱的標記,返回字符串"no_alias"。# 以元組的方式傳入額外的參數
alias = '別名'
# 定義一個變量alias并賦值為'別名',這個變量將作為apply函數的額外參數。df_name["alias"] = df_name["desc"].apply(apply_get_alias, args=(alias,))
# 對df_name DataFrame中的"desc"列應用apply_get_alias函數。
# apply方法將函數應用于"desc"列中的每個元素(即每行數據)。
# args參數是一個元組,包含了額外的參數alias,這個參數將傳遞給apply_get_alias函數。df_name.head()
# 顯示df_name DataFrame的前幾行,通常用于檢查DataFrame的結構和新生成的"alias"列的數據。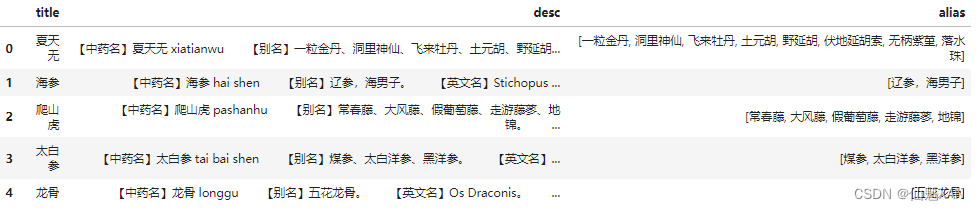
這段代碼的目的是定義一個自定義函數apply_get_alias,用于處理DataFrame中的文本數據,并提取特定名稱(如別名)的信息。函數首先清除文本兩端的空白字符和全角空格,然后在特定字符(如中文括號)周圍添加分隔符,分割文本,并移除空字符串。接著,檢查分割后的列表中是否包含特定的名稱標記,如果包含,則提取并進一步處理該部分文本;如果不包含,則返回一個特定的字符串(如"no_alias")。最后,使用apply方法將這個自定義函數應用于DataFrame的某一列,并將結果存儲在新的列中。通過這種方式,可以有效地從文本數據中提取和處理所需的信息。
提取后的數據沒有辦法直接使用,在后續使用中發現該數據存在醫學上的命名錯誤,或者說是“冒名頂替”的錯誤,這是一種常見的類似藥草命名錯誤的現象。例如,水半夏與半夏這兩種藥材,它們是不同的藥材,水半夏最早是因為與半夏有類似藥效,所以在部分藥方中被用于替換半夏。由于商業或者認知錯誤等原因,水半夏有時也被稱為半夏,但是水半夏與半夏是不同的藥物,在醫學上不可混用,而這里水半夏的別名中卻存在“半夏”這一錯誤別名。同樣還存在木香與川木香等其他藥草的別名錯誤問題。因此,這里必須對所有類似情況進行處理。經過數據探索可以發現,原數據中存在這些“冒名頂替”的藥材中有兩種比較特別——它們去除錯誤別名后,就沒有其他別名了。
兩對“混淆”的藥材為:谷芽和稻芽、木香和川木香。查詢資料可知,谷芽為粟的芽,而稻芽為稻米的芽,不是一種藥材。木香為菊科植物木香的干燥根,川木香則為菊科植物川木香或灰毛川木香的干燥根,同樣不是一種藥材。對比發現兩對藥材確實為不同藥草,因此過濾規則不變,但在后續編程中需注意這兩個特殊的別名空值。查詢別名為空值的代碼如下:
for i in range(len(df_name["alias"])):# 遍歷df_name DataFrame中"alias"列的索引,i為當前索引。list_i = list(df_name["alias"][i])# 將"alias"列中索引為i的元素(原本是字符串)轉換為列表list_i。for j in df_name["alias"][i]:# 對于"alias"列中索引為i的每個字符j進行遍歷。if j in list(df_name["title"]):# 如果字符j也存在于"title"列的某個元素中("title"列的每個元素也被轉換為列表),則從list_i中移除字符j。list_i.remove(j)# 這里假設我們不希望別名中包含藥名,因為藥名可能在別名中作為一部分出現。if list_i == []:# 如果移除所有藥名字符后,別名列表為空,則打印出索引i,提示別名被過濾為空。print("過濾后別名為空", i)df_name["alias"][i] = list_i# 將經過過濾(移除了藥名字符的)別名列表list_i重新賦值給df_name DataFrame中"alias"列的第i個元素。print(str(df_name["alias"]))
# 將df_name DataFrame中"alias"列的內容轉換為字符串并打印出來,查看更新后的別名列。
# 下面的兩行代碼被注釋掉了,它們不會執行:
# print(df_name["desc"][list(df_name["title"]).index('谷芽')],df_name["desc"][104])
# 這行代碼的意圖可能是找到"title"列中'谷芽'對應的索引,然后打印"desc"列在該索引和第104行的元素。
# print(df_name["desc"][list(df_name["title"]).index('木香')],df_name["desc"][608])
# 這行代碼的意圖可能是找到"title"列中'木香'對應的索引,然后打印'desc'列在該索引和第608行的元素。
運行結果為:
過濾后別名為空 104
過濾后別名為空 608
0 [一粒金丹, 洞里神仙, 飛來牡丹, 土元胡, 野延胡, 伏地延胡索, 無柄紫堇, 落水珠] 1 [遼參,海男子] 2 [常春藤, 大風藤, 假葡萄藤, 走游藤蓼, 地錦] 3 [煤參, 太白洋參, 黑洋參] 4 [五花龍骨]... 816 [烏龍須, 黑龍須] 817 [倒吊黃花, 倒吊黃, 黃花參] 818 [五毒草, 火炭毛, 烏炭子] 819 [野芫荽, 刺芹, 香信, 番香茜, 香菜] 820 [海白菜, 石莼, 紙菜, 青菜婆] Name: alias, Length: 821, dtype: object
這段代碼的目的是清洗DataFrame中"alias"列的數據,確保別名中不包含與"title"列相同的字符(可能是藥名)。通過兩層循環,代碼遍歷別名的每個字符,如果字符在藥名列中也存在,則從別名中移除。如果別名在移除藥名后變為空列表,代碼會打印出對應的索引。最后,代碼打印出更新后的"alias"列的所有內容。被注釋掉的兩行代碼看起來是為了調試目的,用于打印特定索引位置的數據。
3、提取藥方成分
分析藥方中的中成藥的成分,首先需要提取所需的藥材名稱。與藥材數據類似,它同樣以“字段名1,內容1,字段名2,內容2,...,字段名n,內容n”的形式存在于desc字段,因此,我們使用與之前類似的方法提取處方字段。實際編程后發現,前面的許多數據存儲藥方成分的字段為“處方”,而部分數據為“藥方組成”。因此,我們需要稍微修改一下算法,當存在“處方”或“藥方組成”字段時,我們將有關字段提取出來。
首先讀取中成藥的數據,代碼如下:
df_zhongchengyao = pd.read_csv("./data/zhongchengyao.csv", header=0)
# 導入pandas庫(通常在代碼開始時已經導入,因此此處不再需要導入)。
# 使用pandas庫的read_csv函數讀取當前目錄下的"data"文件夾中的"zhongchengyao.csv"文件。
# header=0指定第一行作為DataFrame的列名(header)。
# 讀取的數據被存儲在DataFrame對象df_zhongchengyao中,該對象用于后續的數據操作和分析。df_zhongchengyao.head(10)
# 調用df_zhongchengyao DataFrame的head方法并傳入參數10,這將返回DataFrame的前10行數據。
# head方法通常用于快速查看DataFrame的開始部分,幫助用戶對數據進行初步的檢查和理解。
# 這里的輸出將顯示df_zhongchengyao DataFrame的前10行,以便進行數據查看。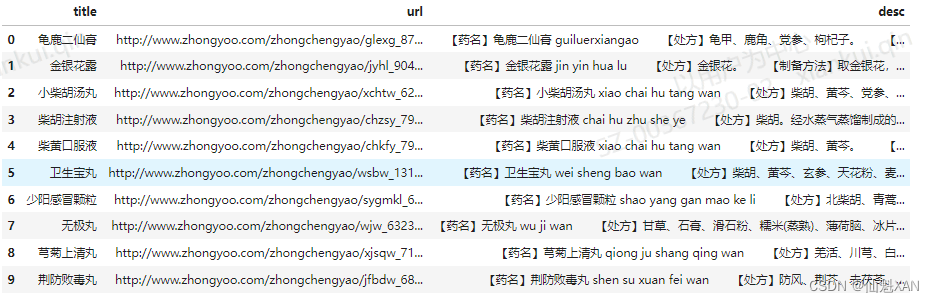
這段代碼的目的是加載名為"zhongchengyao.csv"的CSV文件到pandas DataFrame中,并顯示這個DataFrame的前10行數據,以便于進行初步的數據查看和檢查。
然后通過將中藥名與中藥的別名合并來創建詞典,再利用詞典在中成藥與中藥方劑中提取中藥。其具體思路為:使用分詞工具對中成藥、中藥藥方中的文本進行全分詞,然后取交集即可。但是,由于中藥名字除正式名稱外還有別名存在,因此我們需要將別名統一。這里使用自定義的方法,將所有的別名轉換為唯一主名稱,之后取set即可得到一份只有統一名稱的Python鏈表。對此,我們需要構建只包含唯一名稱與包含所有中藥材名詞的兩個鏈表,以供之后使用。代碼如下:
list_name_alias = []
# 初始化一個空列表,用于存儲別名數據。for i in list(df_name["alias"]): # 遍歷DataFrame df_name中"alias"列的每一項(每一項本身是一個列表)。list_name_alias.extend(i)# 使用extend方法將當前別名列表中的所有元素添加到list_name_alias列表中。list_name = list(df_name["title"])
# 將DataFrame df_name中"title"列的每個元素轉換為一個列表。list_name_all = list_name + list_name
# 創建一個新的列表list_name_all,它是list_name列表的兩倍長度,通過復制自身實現。def get_main_name(x):# 定義一個函數get_main_name,它接受一個參數x(可能代表某個別名中的單個名稱或詞語)。int_len = len(list(df_name["alias"]))# 獲取"alias"列中別名列表的長度。list_alias = list(df_name["alias"])# 將"alias"列的每個元素再次轉換為列表。for i in range(int_len):# 遍歷別名列表的長度。if x in list_alias[i]:# 如果x存在于第i個別名列表中,即x是別名的一部分。return list_name[i]# 返回對應于該別名的"title"列中的主名稱。def get_name(list_jieba):# 定義一個函數get_name,它接受一個參數list_jieba(可能是一個經過分詞處理的詞語列表)。union_1 = list(set(list_jieba).intersection(set(list_name)))# 通過集合操作找出list_jieba和list_name中共有的元素,即同時出現在兩者中的詞語,存儲在union_1中。union_2 = list(set(list_jieba).intersection(set(list_name_alias)))# 通過集合操作找出list_jieba和list_name_alias中共有的元素,即同時出現在別名中的詞語,存儲在union_2中。if union_2 != []:# 如果存在同時出現在別名中的詞語。for i in range(len(union_2)):# 遍歷這些共有元素。union_2[i] = get_main_name(union_2[i])# 使用get_main_name函數獲取每個共有元素對應的主名稱,并更新union_2列表中的相應元素。return union_1+union_2# 返回一個列表,包含union_1和union_2中的所有元素,即list_jieba中屬于主名稱和別名的所有詞語。這段代碼的目的是處理DataFrame中的別名和標題數據,通過定義函數提取出與分詞結果相關的主名稱和別名。get_main_name函數用于根據別名中的詞語找到對應的主名稱,而get_name函數則用于將分詞結果(list_jieba)與主名稱及別名列表進行匹配,找出相關的名稱。這樣的處理有助于在文本分析或數據匹配中識別和關聯相關的藥名或別名。
對于處方構成的獲取,使用的是“循環+分詞+取并”的方式,代碼如下:
def apply_get_prescription(x, l_p):# 定義一個函數apply_get_prescription,它接受兩個參數:x(字符串,可能包含藥方描述)和l_p(包含特定標簽的列表)。import re# 導入正則表達式模塊re,用于文本處理。string_clear = x.strip().replace('\u3000', '')# 清除x字符串的首尾空白字符,并替換全角空格符\u3000為空字符串。list_clear = string_clear.replace('【','|【').replace('】','】|').split("|")# 在'【'和'】'字符周圍添加分隔符'|',然后按'|'分割字符串,生成list_clear列表。list_clear.remove('')# 如果分割后list_clear列表中有空字符串元素,將其移除。for item in l_p:# 遍歷l_p列表中的每個項,這些項是我們要在文本中查找的特定標簽(如'藥方組成')。if '【'+ item +'】' in list_clear:# 如果當前項作為標簽存在于list_clear中,表示找到了藥方組成或處方部分。str_clear = list_clear[list_clear.index('【'+ item +'】')+1]# 獲取標簽后的文本,即藥方組成或處方的具體內容。import jieba# 導入jieba庫,用于中文分詞。jieba_cut_string = jieba.cut(str_clear,HMM=True)# 使用jieba進行中文分詞,HMM=True表示使用HMM模型進行分詞。list_jieba = "|".join(jieba_cut_string).split('|')# 將分詞結果連接為一個字符串,再用'|'分割成列表。union = get_name(list_jieba)# 調用get_name函數處理分詞結果,該函數可能是之前定義的,用于進一步處理分詞結果。return list(set(union))# 返回去重后的分詞結果列表。else:# 如果遍歷完l_p列表中的所有項,都沒有在list_clear中找到對應的標簽,則執行else塊。return "no_alias"# 返回字符串"no_alias",表示沒有找到藥方組成或處方部分。# 以元組的方式傳入額外的參數
prescription = ['藥方組成','處方']
# 定義一個列表prescription,包含我們要查找的特定標簽。df_zhongchengyao["prescription"] = \df_zhongchengyao["desc"].apply(apply_get_prescription,args=(prescription,))
# 使用apply函數將apply_get_prescription應用到df_zhongchengyao DataFrame的"desc"列。
# args參數是一個元組,包含了額外的參數prescription,這個參數將傳遞給apply_get_prescription函數。
# 應用結果將作為新的一列"prescription"添加到df_zhongchengyao DataFrame中。運行結果:
Building prefix dict from the default dictionary ... Loading model from cache C:\Users\xiankui.qin\AppData\Local\Temp\jieba.cache Loading model cost 0.511 seconds. Prefix dict has been built successfully.
這段代碼的目的是定義一個自定義函數apply_get_prescription,用于處理藥方描述文本,提取藥方組成或處方部分,并使用jieba進行中文分詞。然后,使用apply方法將這個自定義函數應用于DataFrame的某一列,并將結果存儲在新的列中。通過這種方式,可以有效地從藥方描述文本中提取和處理所需的信息。
以上代碼實現了別名的統一,將所有的別名轉換為唯一主名稱,形成了Python鏈表。
查看 prescription 數據
df_zhongchengyao["prescription"]
# 這行代碼引用了DataFrame df_zhongchengyao中的"prescription"列。
# 在pandas中,使用DataFrame的名稱后跟列名(用方括號括起來)可以訪問特定的列。
# 這個操作不會修改數據,它僅僅是選擇了DataFrame中的一個列作為對象。
# 通常,這樣的引用用于以下幾種情況:
# 1. 打印或查看特定列的數據。
# 2. 將這一列的數據傳遞給其他函數或進行進一步的數據處理。
# 3. 作為數據操作的一部分,比如創建新的列或修改現有列。運行結果:
0 [黨參, 龜甲, 枸杞子] 1 [金銀花] 2 [生姜, 黃芩, 黨參, 柴胡, 甘草, 半夏, 大棗] 3 [柴胡] 4 [黃芩, 柴胡]... 2076 [乳香, 白礬, 冰片, 玄明粉, 沒藥, 爐甘石, 芒硝, 硼砂, 麝香] 2077 [珍珠, 牛黃, 三七, 羚羊角] 2078 [人參, 麻黃, 桔梗, 白芍, 五味子, 苦杏仁, 甘草, 當歸, 半夏, 補骨脂, 桂枝... 2079 [龜甲, 地黃, 知母, 當歸, 菊花, 南沙參, 黑豆, 黃芩, 白芍, 桑葉, 地骨皮,... 2080 [冰片] Name: prescription, Length: 2081, dtype: object
這行代碼本身不執行任何數據修改或輸出操作,它只是訪問并選擇了df_zhongchengyao DataFrame中的"prescription"列。如果需要查看或使用這一列的數據,通常還需要進行額外的操作,比如使用head()函數來查看前幾行數據,或者將其作為參數傳遞給其他數據處理函數。
4、挖掘常用藥物組合
接下來,分析中成藥中的常用藥物組合,并根據組合的具體數據,提出有利于研究的藥物組合。目前我們已經獲取了中成藥與中藥方劑的藥物組成,因此需要使用對應算法(Apriori算法)對常見藥物組合進行挖掘。
Apriori算法是一種常見的關聯規則分析算法,得到的結果為{A}?->?{B}的形式,前項A可能是一個數據,也可能是兩個或多個數據的組合(之后將前面的數據項統稱為前項),后項B為有關搭配的數據,同樣可能是一個數據,也可能是多個數據(之后將后面的數據項統稱為后項)。對關聯項的挖掘,我們主要通過兩個參數進行控制:min_support(最小支持度)與min_confidence(最小置信度)。支持度表示某個組合出現的次數與總次數之間的比例。支持度越高,該組合出現的頻率越大。置信度則表示條件概率,如{A}?->?{B},表示在A發生的這一條件下,B發生的概率是多少。在這里,最小支持度則表示所有藥方中最起碼要有多少出現了這類藥物(或藥物組合)。例如組合為{A}?->?{B},置信度為1,表示存在A的時候,有多少的比例會出現B。這兩個參數都是Apriori算法的核心參數。同時,如果我們需要分析常用的藥物組合,那么藥物本身出現的比例以及搭配藥物出現的概率也是我們需要控制的變量——通過控制有關變量,可以獲得不同情況下的藥物組合類型。
參數的估計需要依據實際數據的比例。通過代碼計算可知,藥方總數為2081,藥方中出現的藥材一共有15680種,藥材總種類則為821類,平均每種中藥出現19.1次。由于藥方數量較多,我們不要求過多藥方中出現某種藥材,因此將Apriori算法的最小支持度設置為0.03;疾病種類繁多,因此置信度則選擇為0.5,也就是使用Apriori算法發現在所有藥材中前項出現的比例高于3%,且前項出現后后項出現的概率高于50%的藥材組合。本節通過上述兩個參數設置方法,來尋找一些3種以上的藥材組合。
首先,安裝efficient-apriori
!pip install efficient-apriori
# 這行代碼用于安裝名為efficient-apriori的Python庫。
# 在Jupyter Notebook或類似支持!操作符的環境中,!允許執行系統命令。
# pip是Python的包管理工具,用于安裝和管理Python庫。
# 執行此命令將從Python包索引(PyPI)下載并安裝efficient-apriori庫及其依賴項。
# 安裝完成后,您可以在Python代碼中導入并使用該庫提供的功能。這條命令通常在數據分析和機器學習項目中使用,用于確保所需的庫已經安裝在環境中,以便可以執行關聯規則挖掘等任務。如果庫已經安裝,則此命令將檢查更新;如果尚未安裝,則會添加到當前Python環境的庫列表中。
并統計中成藥中一共出現了多少藥材,代碼如下:
from efficient_apriori import apriori
# 導入efficient_apriori庫中的apriori函數。
# efficient_apriori是一個用于挖掘關聯規則的庫,apriori函數可用于從數據集中生成頻繁項集。int_tmp = 0
# 初始化一個整數變量int_tmp,用于累計計數。for i in list(df_zhongchengyao["prescription"]):# 遍歷DataFrame df_zhongchengyao中"prescription"列的每一項。# list函數將"prescription"列中的數據轉換為列表,以便遍歷。int_tmp += len(i)# 將當前項i的長度(即項中元素的數量)累加到int_tmp變量中。print(int_tmp)
# 打印int_tmp的當前值,這通常用于調試或查看累計的總數。print(int_tmp/821)
# 計算int_tmp的值除以821的結果,并打印出來。
# 這里821可能是一個特定的數值,例如數據集中記錄的總數或某個特定的基數。print(int_tmp/821/821)
# 進一步計算上述結果除以821,并打印出來。
# 這可能是為了得到某個比例或比率,具體含義取決于上下文。15680 19.09866017052375 0.023262679866654996
這段代碼的目的是遍歷DataFrame中某一列的所有項,并計算所有項中元素總數的累計和。然后,代碼中通過除以特定的數值(在這種情況下是821)來計算并打印出一些數值比例或比率。這樣的計算可能用于數據分析或驗證特定假設。
關聯規則挖掘算法代碼如下:
itemsets, rules = apriori(list(df_zhongchengyao["prescription"]), min_support=0.03, min_confidence=0.5)
# 使用apriori算法處理DataFrame df_zhongchengyao中的"prescription"列。
# 將"prescription"列轉換為列表,作為apriori函數的輸入數據。
# min_support=0.03設定了最小支持度閾值為0.03,即一個項集要被認為是頻繁的,
# 它必須在所有交易中出現的頻率至少為0.03。
# min_confidence=0.5設定了最小置信度閾值為0.5,即如果規則A => B的置信度大于0.5,
# 則認為在A出現的情況下,B也有很大可能跟隨出現。
# 函數返回兩個對象:itemsets(頻繁項集)和rules(強關聯規則)。print(rules)
# 打印apriori算法找到的強關聯規則。
# 關聯規則通常表示為A => B形式,其中A是前提條件,B是后件。
# 這些規則可以幫助我們理解數據中的內在關系,例如在某些藥方中哪些藥材經常一起出現。 運行結果:[{沒藥} -> {乳香}, {乳香} -> {沒藥}, {半夏} -> {甘草}, {半夏} -> {陳皮}, {山藥} -> {茯苓}, {川芎} -> {當歸}, {熟地黃} -> {當歸}, {白芍} -> {當歸}, {紅花} -> {當歸}, {桔梗} -> {甘草}, {白術} -> {甘草}, {白芍} -> {甘草}, {苦杏仁} -> {甘草}, {茯苓} -> {甘草}, {薄荷} -> {甘草}, {陳皮} -> {甘草}, {麻黃} -> {甘草}, {白術} -> {茯苓}, {當歸, 甘草} -> {川芎}, {川芎, 甘草} -> {當歸}, {當歸, 白芍} -> {川芎}, {川芎, 白芍} -> {當歸}, {熟地黃, 白芍} -> {當歸}, {當歸, 白芍} -> {熟地黃}, {當歸, 熟地黃} -> {白芍}, {甘草, 白芍} -> {當歸}, {當歸, 白芍} -> {甘草}, {當歸, 甘草} -> {白芍}, {當歸, 茯苓} -> {甘草}, {當歸, 甘草} -> {茯苓}, {白芍, 茯苓} -> {當歸}, {當歸, 茯苓} -> {白芍}, {當歸, 白芍} -> {茯苓}, {白術, 茯苓} -> {甘草}, {甘草, 茯苓} -> {白術}, {甘草, 白術} -> {茯苓}, {茯苓, 陳皮} -> {甘草}, {甘草, 陳皮} -> {茯苓}]
這段代碼的目的是使用apriori算法對中藥處方數據進行關聯規則挖掘,找出頻繁項集和強關聯規則。通過設定最小支持度和最小置信度閾值,算法能夠識別出在數據集中經常出現的藥方組合,以及在某些藥材出現時其他特定藥材也很可能出現的規則。這些規則對于理解中醫藥方的配伍規律和藥材使用習慣非常有幫助。
最后得到的常用的3種藥材的中成藥組合如下:
●?白術,茯苓,甘草
●?茯苓,陳皮,甘草
●?當歸,白芍,川芎
●?白芍,茯苓,當歸
●?當歸,甘草,川芎
●?當歸,茯苓,甘草
●?熟地黃,白芍,當歸
●?甘草,白芍,當歸
對于具體的內容,如{甘草,陳皮}?->?{茯苓},其中甘草和陳皮這對組合是實際出現的,且出現比例一定高于5%,而每當該組合出現時,則有50%的可能與茯苓進行搭配。只考慮組合本身,也就是前項中的兩種藥材的情況,我們可以根據組合次數繪制出一個圖形,具體如圖12-4所示。
在圖12-4中,組合次數最多的是當歸,當歸是所有藥材組合中最重要的藥材,它與白芍的連接數為4,與甘草的連接數為3,與茯苓的連接數為2,且與其他藥材擁有緊密聯系。其次是白芍與甘草這兩種藥材,它們和其他藥材連接都比較緊密,且部分組合次數相對較大。再次是茯苓。最后一批組合最少的藥材則是川芎、熟地黃、陳皮與白術,它們都與兩種藥材各組合過一次。
接下來,統計可能的搭配關系(在{甘草,陳皮}?->?{茯苓},茯苓是甘草和陳皮的搭配藥材,記作茯苓與甘草的關聯數字為1,茯苓與陳品的關聯數字為1),得到的結果如圖12-5所示。
由圖12-5可知,當歸、甘草、白芍、茯苓這4種藥材與其他藥材搭配最為頻繁。其次是川芎,與幾種主要藥材的搭配較為頻繁。之后是白術、熟地黃,這兩種藥材與圖12-4中的情況類似,都與兩種主要藥材有一定的搭配關系(各兩次)。最后為陳皮,只和兩種主要藥材各有一次搭配。通過以上方法,我們得到了不同常見藥材之間的輔助搭配關系。
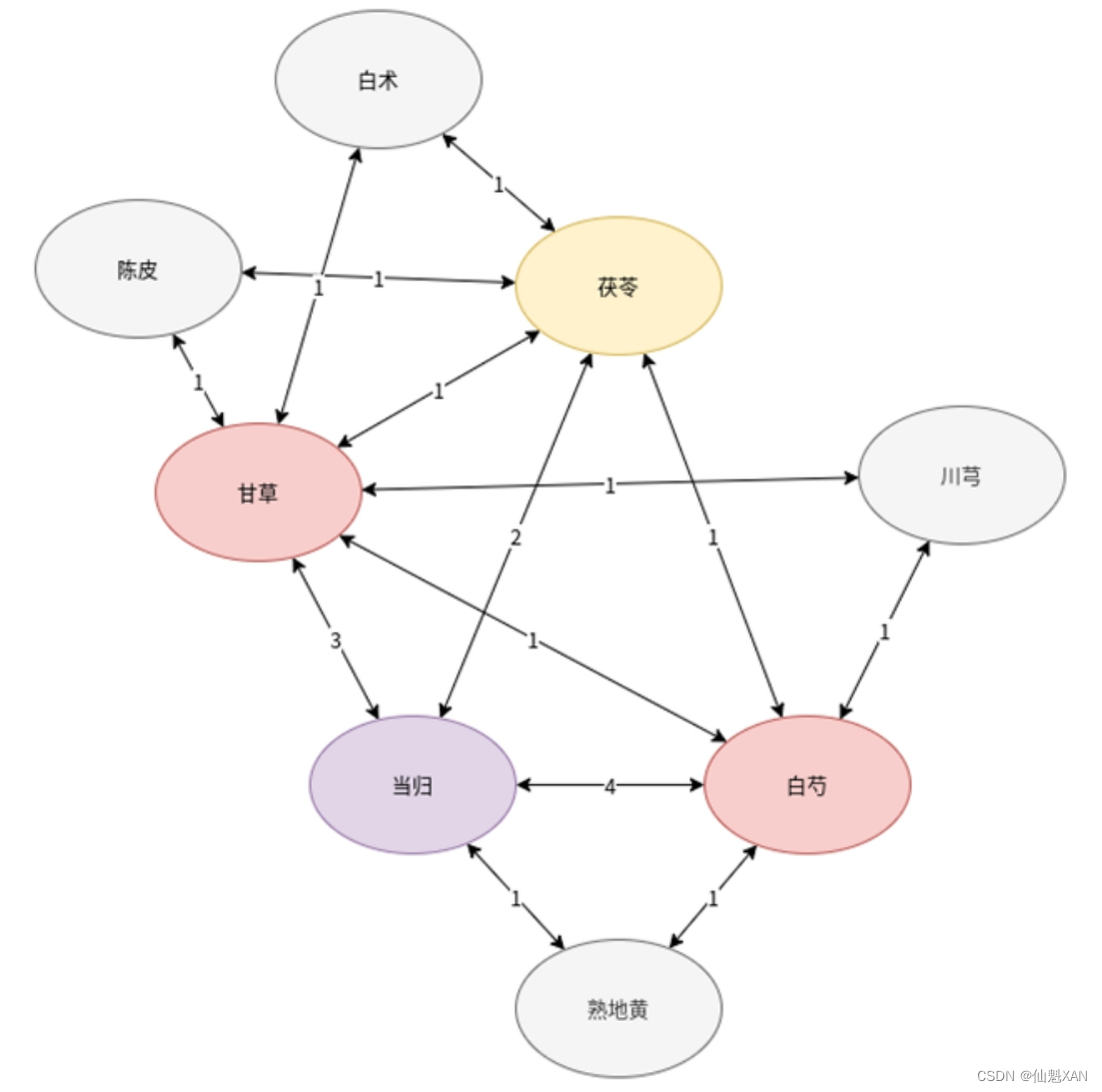
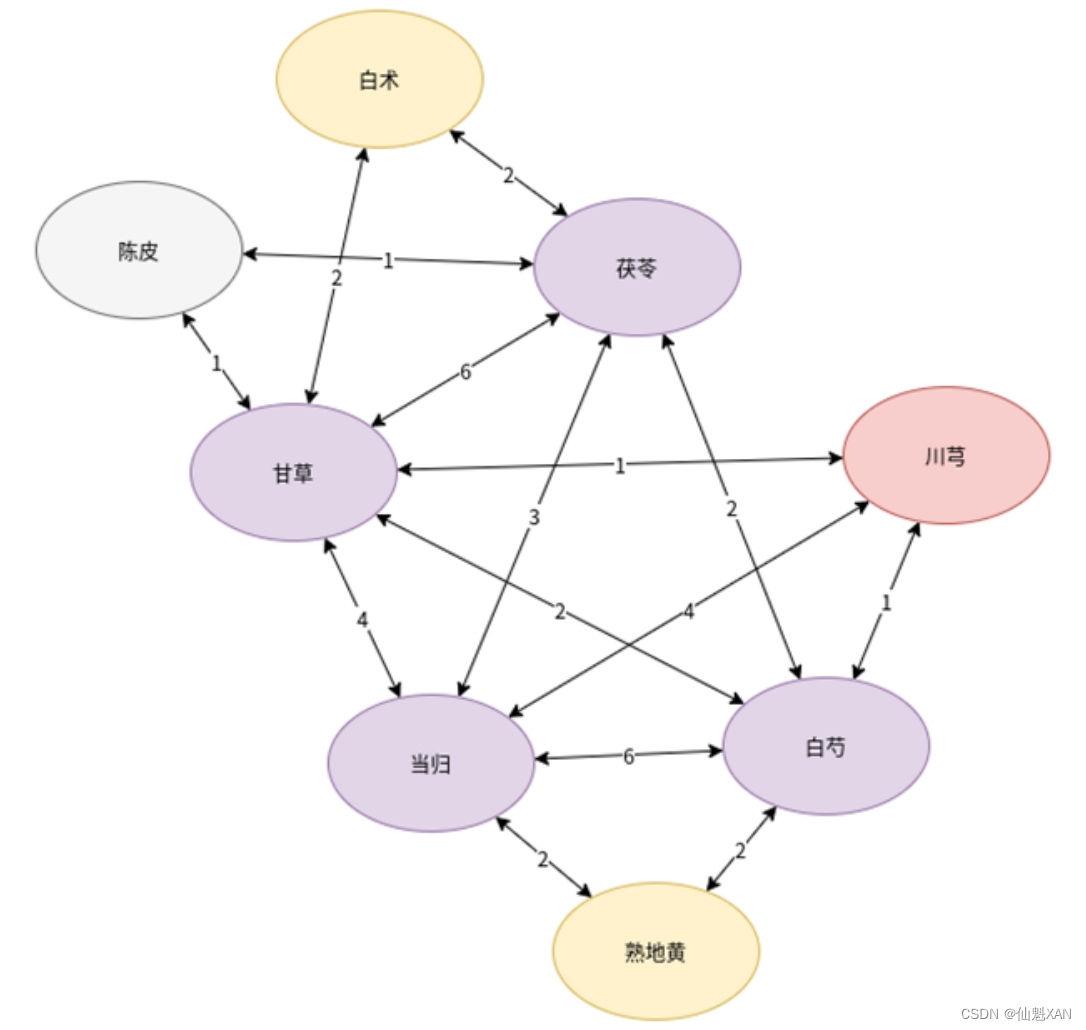
綜合上述兩種情況可以得出結論:當歸與白芍、甘草的直接組合較多,而甘草、當歸、茯苓、川芎和白芍五味藥同時也是其他藥材中藥的輔助用藥。由于圖12-4和圖12-5很好地展示了各種藥材之間的搭配與輔助關系,因此,也可以使用關聯規則分析藥物之間的搭配關系,從而得到藥方,例如,當歸、甘草、白芍、茯苓這一較為簡單的藥方組合,或者甘草、當歸、茯苓、川芎、白芍、熟地黃、白術這一藥材較多的藥方組合。
使用類似方法同樣可以得到單個藥材的有關組合。由于單個藥草本身出現概率就比較高,因此將算法中的參數最小置信度提高至0.7。支持度為0.03,置信度為0.7時獲取藥材的有關組合的實現代碼如下:
itemsets, rules = apriori(list(df_zhongchengyao["prescription"]), min_support=0.03, min_confidence=0.7)
# 對DataFrame df_zhongchengyao中的"prescription"列應用apriori算法。
# 將"prescription"列轉換為列表形式,作為apriori算法的輸入。
# min_support=0.03設定了最小支持度閾值,意味著項集出現的最小頻率為0.03(3%)。
# min_confidence=0.7設定了最小置信度閾值,即規則成立的最小概率為0.7(70%)。
# 算法返回兩個結果:itemsets(所有頻繁項集的列表)和rules(滿足最小支持度和置信度閾值的關聯規則列表)。print(rules)
# 打印出滿足上述支持度和置信度閾值的關聯規則。
# 關聯規則通常表示為"A => B"的形式,其中A是前提條件,B是后件。
# 這些規則有助于揭示數據中的內在關系,例如哪些藥材經常一起被開處方。[{沒藥} -> {乳香}, {乳香} -> {沒藥}, {桔梗} -> {甘草}, {川芎, 甘草} -> {當歸}, {川芎, 白芍} -> {當歸}, {熟地黃, 白芍} -> {當歸}, {白芍, 茯苓} -> {當歸}, {白術, 茯苓} -> {甘草}, {甘草, 白術} -> {茯苓}, {茯苓, 陳皮} -> {甘草}]
這段代碼的目的是使用Apriori算法對中藥處方數據進行分析,找出頻繁出現的藥材組合和強關聯規則。通過設置支持度和置信度閾值,算法能夠識別出在數據集中頻繁共同出現的藥材,以及在某些藥材出現的情況下其他特定藥材出現的概率。這對于理解中醫藥方的配伍規律和藥材使用習慣具有重要意義。
以此方法得到搭配更為頻繁的藥物組合,最終得到的兩種藥材的中成藥組合如下:
●?桔梗、甘草
●?茯苓、甘草
●?陳皮、甘草
●?川芎、當歸
在不提高置信度(0.7),只提高支持度到0.06的情況下,獲取藥材的有關組合的實現代碼如下:
itemsets, rules = apriori(list(df_zhongchengyao["prescription"]), min_support=0.06, min_confidence=0.5)
# 對df_zhongchengyao DataFrame中的"prescription"列數據應用Apriori算法。
# list(df_zhongchengyao["prescription"])將"prescription"列轉換為列表形式,作為apriori函數的輸入。
# min_support=0.06設置了最小支持度閾值為0.06,這意味著任何被認為是頻繁項集的元素組合必須在至少6%的事務中出現。
# min_confidence=0.5設置了最小置信度閾值為0.5,這意味著只有當規則的置信度(即在前件發生后后件發生的條件概率)至少為50%時,才會被認為是有意義的規則。
# 函數返回兩個結果:itemsets(頻繁項集的集合)和rules(強關聯規則的集合)。print(rules)
# 打印由apriori算法找到的強關聯規則。
# 這些規則可以幫助我們理解數據中的特征之間的關聯性,例如在中藥處方中哪些藥材經常一起被使用。[{川芎} -> {當歸}, {桔梗} -> {甘草}, {茯苓} -> {甘草}, {陳皮} -> {甘草}]
這段代碼的目的是使用Apriori算法對中藥處方數據進行關聯規則挖掘,找出滿足特定支持度和置信度閾值的藥材組合規則。通過設定最小支持度和最小置信度閾值,算法能夠識別出在數據集中經常出現的藥方組合,以及在某些藥材出現時其他特定藥材也很可能出現的規則。這些規則對于理解中醫藥方的配伍規律和藥材使用習慣非常有幫助。
得到的兩種藥材的中成藥組合如下::
●?桔梗、甘草
●?沒藥、乳香(雙向)
該數據意味著組合的前項使用更為頻繁,或者說藥材組合應用更為廣泛。
支持度為0.03、置信度為0.7的雙藥材組合的數據中,{川芎}?->?{當歸}、{茯苓}?->?{甘草}和{陳皮}?->?{甘草}全部都在3種藥材組合中出現過,而不提高置信度(0.7),只提高支持度到0.06得到的藥材組合{桔梗}?->?{甘草},{沒藥}?->?{乳香},并沒有在3種藥材組合中出現過,屬于新出現的中藥組合。更高的支持度也就意味著更廣泛的使用范圍,尤其桔梗與甘草的組合在有較高支持度的同時,它們的置信度也在70%以上,也就是在桔梗被頻繁應用的同時,它與甘草的共同使用也是常見的。因此,這種組合在深入研究和實際應用中具有較高的價值。另外,沒藥和乳香之間的相互置信度超過70%,表明該組合使用廣泛且經常搭配。
通過上述數據可以得到4種基本的、有效的藥物組合:
(1)當歸、白芍、甘草。
(2)甘草、當歸、茯苓、川芎四、白芍、熟地黃、白術。
(3)桔梗、甘草。
(4)沒藥、乳香。
四、小結
本文深入探討了中藥材、中成藥和中藥方劑數據集的應用,通過一系列先進的數據分析技術,為讀者揭示了中醫藥數據挖掘的豐富內涵。以下是對原文的豐富和擴展:
-
數據集的廣泛性:本文不僅涵蓋了中藥材數據,還包括了中成藥和中藥方劑,為讀者提供了一個全面的中醫藥數據視野。
-
技術的綜合運用:文章綜合運用了關聯規則挖掘算法、分詞技術和文本處理技術等多種技術手段,這些技術的結合使用能夠更深入地挖掘和分析中醫藥數據。
-
提取藥材別名的重要性:通過文本處理技術,本文特別強調了提取藥材別名的重要性,這有助于理解藥材的多樣性和復雜性,為中藥的標準化和國際化奠定基礎。
-
中藥配方組合的挖掘:利用關聯規則挖掘算法,本文成功提取了中藥配方中常見的藥材組合,這對于理解中醫藥的配伍原理和臨床應用具有重要意義。
-
數據清洗與處理的實踐:文章詳細介紹了數據清洗和處理的步驟,包括去除噪聲、處理缺失值和異常值等,這些步驟對于保證數據質量至關重要。
-
數據挖掘技術的應用:通過實際的數據挖掘案例,本文展示了如何應用數據挖掘技術來發現數據中的有價值信息,如藥材的使用頻率、藥材之間的關聯性等。
-
對讀者的啟發與指導:通過本文的學習,讀者不僅能夠掌握數據清洗、數據處理和數據挖掘的相關技術,還能夠獲得將這些技術應用于中醫藥領域的實踐經驗。
-
對未來研究的展望:本文還展望了中醫藥數據挖掘的未來,包括如何利用大數據和人工智能技術進一步推動中醫藥的現代化和全球化。
通過本文的學習,讀者將能夠獲得寶貴的中醫藥數據挖掘知識,提升自己在中醫藥數據分析和研究方面的能力,為中醫藥的傳承與發展做出貢獻。
附錄
一、代碼地址
github:GitHub - XANkui/PythonMachineLearningBeginner: Python 機器學習是利用 Python 編程語言中的各種工具和庫來實現機器學習算法和技術的過程。Python 是一種功能強大且易于學習和使用的編程語言,因此成為了機器學習領域的首選語言之一。這里我們一起開始一場Python 機器學習基礎入門到精通學習旅程。
二、文中的關聯圖(帶權有向圖)簡單繪制代碼參考
1、安裝 networkx 庫
!pip install networkx
# 這行代碼是一個命令,用于在支持shell命令的環境中(如Jupyter Notebook)執行pip安裝操作。
# pip是Python的包管理工具,用于安裝Python庫。
# 該命令嘗試安裝networkx庫,這是一個Python庫,用于創建、操作復雜網絡的結構、繪制和分析。
# NetworkX提供了豐富的數據結構和方法,用于處理圖論中的對象,例如節點(nodes)、邊(edges)和路徑(paths)。
# 如果networkx庫尚未安裝在當前Python環境中,執行此命令將從Python包索引(PyPI)下載并安裝它及其依賴項。
# 如果networkx已經安裝,此命令將檢查是否有可用的更新。這條命令通常在數據分析、復雜網絡分析、圖論研究等領域使用,確保所需的庫已經安裝在Python環境中,以便可以執行相關的圖計算和可視化任務。如果庫已經安裝且是最新版本,則此命令可能不會有任何效果;如果有更新,則會進行升級。
2、繪制
import matplotlib.pyplot as plt
import networkx as nx
import matplotlib.font_manager as fm
# 導入所需的庫。matplotlib.pyplot用于繪圖,networkx用于創建和操作圖結構,matplotlib.font_manager用于字體管理。# 設置中文字體路徑
font_path = 'C:/Windows/Fonts/simhei.ttf' # 指定中文字體路徑,以便繪制中文標簽
# 你可以根據自己的系統字體選擇合適的中文字體文件路徑。# 設置字體屬性
zh_font = fm.FontProperties(fname=font_path)
# 創建一個FontProperties對象,用于指定繪制中文時使用的字體。# 創建一個有向圖
G = nx.DiGraph()
# 使用networkx的DiGraph類創建一個有向圖對象。# 添加帶權邊
edges = [# 定義圖的邊和權重的列表,例如("陳皮", "炙苓", 1)表示從陳皮到炙苓的邊,權重為1。("陳皮", "炙苓", 1),("炙苓", "甘草", 1),("白術", "炙苓", 1),("川芎", "炙苓", 1),("川芎", "白芍", 1),("白芍", "甘草", 1),("白芍", "熟地黃", 1),("熟地黃", "當歸", 1),("當歸", "白芍", 4),("甘草", "當歸", 3),("甘草", "白芍", 1),("甘草", "川芎", 1),("甘草", "炙苓", 1),("白芍", "甘草", 2)
]
for edge in edges:G.add_edge(edge[0], edge[1], weight=edge[2])# 遍歷edges列表,使用add_edge方法向圖中添加帶權重的邊。# 設置節點顏色
color_map = {# 定義一個字典,指定特定節點的顏色。"炙苓": 'lightyellow',"甘草": 'lightcoral',"當歸": 'plum',"白芍": 'lightcoral',
}node_colors = [color_map.get(node, 'lightgrey') for node in G.nodes]
# 為圖中的每個節點指定顏色,如果節點在color_map中有對應顏色,則使用該顏色,否則使用默認的灰色。# 繪制圖
pos = nx.spring_layout(G)
# 使用spring_layout布局算法為圖中的節點生成位置。
nx.draw(G, pos, with_labels=False, node_color=node_colors, node_size=2000, edge_color='black')
# 使用networkx的draw函數繪制圖,設置節點顏色和大小,以及邊的顏色。# 繪制節點標簽
for node, (x, y) in pos.items():plt.text(x, y, node, fontsize=10, fontweight='bold', fontproperties=zh_font, ha='center', va='center')# 在每個節點的位置繪制節點名稱,使用指定的中文字體。# 添加權重標簽
edge_labels = nx.get_edge_attributes(G, 'weight')
# 獲取圖中所有邊的權重。# 繪制邊標簽
for (n1, n2), label in edge_labels.items():x1, y1 = pos[n1]x2, y2 = pos[n2]plt.text((x1 + x2) / 2, (y1 + y2) / 2, label, fontsize=10, fontproperties=zh_font, color='black', ha='center')# 在每條邊的中點位置繪制權重標簽,使用指定的中文字體。plt.savefig('Images/01Main-01.png', bbox_inches='tight')
# 將繪制的圖保存為圖片文件,bbox_inches='tight'確保所有內容都被包含在內,沒有被裁剪。# 顯示圖
plt.show()
# 顯示繪制的圖。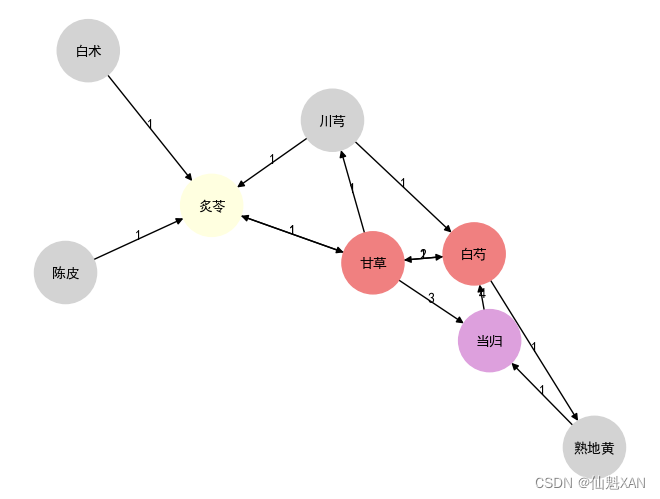
這段代碼的目的是使用NetworkX和Matplotlib庫創建和繪制一個有向圖,圖中的節點代表中藥材,邊代表藥材之間的關聯關系,邊上的權重表示關聯的強度。代碼中還設置了中文字體以確保中文標簽可以正確顯示,并且定義了節點顏色和邊的權重標簽。最后,將繪制的圖保存為圖片文件,并顯示出來。


)












)

![[NOVATEK] NT96580行車記錄儀功能學習筆記(持續更新~](http://pic.xiahunao.cn/[NOVATEK] NT96580行車記錄儀功能學習筆記(持續更新~)
?JWT的用途和優勢是什么?)
