Python 機器學習 基礎 之 【實戰案例】輪船人員獲救預測實戰
目錄
Python 機器學習 基礎 之 【實戰案例】輪船人員獲救預測實戰
一、簡單介紹
二、輪船人員獲救預測實戰
三、數據處理
1、導入數據
2、對缺失數據的列進行填充
3、屬性轉換,把某些列的字符串值轉換為數字
四、建立模型
1、引入機器學習庫
2、實例化模型
3、把數據傳入模型,預測結果
五、算法概率計算
六、集成算法,構建多棵分類樹
1、構造多個分類器
2、隨機森林
七、特征提取
1、進行特征選擇
2、用視圖的方式展示
八、集成多種算法
九、小結
一、簡單介紹
Python是一種跨平臺的計算機程序設計語言。是一種面向對象的動態類型語言,最初被設計用于編寫自動化腳本(shell),隨著版本的不斷更新和語言新功能的添加,越多被用于獨立的、大型項目的開發。Python是一種解釋型腳本語言,可以應用于以下領域: Web 和 Internet開發、科學計算和統計、人工智能、教育、桌面界面開發、軟件開發、后端開發、網絡爬蟲。
Python 機器學習是利用 Python 編程語言中的各種工具和庫來實現機器學習算法和技術的過程。Python 是一種功能強大且易于學習和使用的編程語言,因此成為了機器學習領域的首選語言之一。Python 提供了豐富的機器學習庫,如Scikit-learn、TensorFlow、Keras、PyTorch等,這些庫包含了許多常用的機器學習算法和深度學習框架,使得開發者能夠快速實現、測試和部署各種機器學習模型。
Python 機器學習涵蓋了許多任務和技術,包括但不限于:
- 監督學習:包括分類、回歸等任務。
- 無監督學習:如聚類、降維等。
- 半監督學習:結合了有監督和無監督學習的技術。
- 強化學習:通過與環境的交互學習來優化決策策略。
- 深度學習:利用深度神經網絡進行學習和預測。
通過 Python 進行機器學習,開發者可以利用其豐富的工具和庫來處理數據、構建模型、評估模型性能,并將模型部署到實際應用中。Python 的易用性和龐大的社區支持使得機器學習在各個領域都得到了廣泛的應用和發展。
二、輪船人員獲救預測實戰
在接下來的內容中,我們將深入探索輪船人員獲救預測的實戰演練,這將是一個將理論知識轉化為實際應用的絕佳機會。通過應用我們之前學習的各種算法,例如決策樹分類算法、隨機森林等,我們將能夠將機器學習的強大能力整合到具體的業務場景中。
本文將系統地覆蓋從數據的初步處理到最終模型的評估與優化的全過程。首先,我們會對數據進行清洗和預處理,確保數據的質量,為后續分析打下堅實的基礎。接著,我們將進入特征工程階段,這一步驟至關重要,因為它涉及到從原始數據中提取有用信息,并構建能夠代表問題本質的特征集。
隨后,我們將面臨模型選擇的挑戰,這需要我們根據問題的具體情況和數據的特性,選擇最合適的機器學習模型。這可能包括決策樹、隨機森林、支持向量機、神經網絡等算法,每種算法都有其獨特的優勢和適用場景。
一旦模型被選定,我們將進入模型訓練階段,通過不斷調整參數,優化模型的性能,使其達到最佳的預測效果。最后,我們將對模型進行嚴格的評估,通過交叉驗證、混淆矩陣、ROC曲線等手段,全面了解模型的準確性、泛化能力和預測能力。
通過這一系列的步驟,我們不僅能夠掌握機器學習算法在實際問題中的應用,還能夠學習到如何對模型進行迭代優化,以應對不斷變化的數據和業務需求。這將是一次充滿挑戰和收獲的學習旅程,讓我們期待在實戰中取得豐碩的成果。
三、數據處理
本文的實戰項目將使用CSV格式的數據集,這種格式的數據文件非常適合進行數據分析和機器學習任務。數據集以典型的dataframe格式呈現,它包含了12列豐富的信息,每列都對應著乘客的不同個人信息。以下是對這些數據列的詳細介紹:
-
PassengerId:這是每位乘客的唯一標識符,有助于在數據集中唯一確定一個乘客。
-
Pclass:表示乘客的艙位等級,通常分為頭等艙(1)、二等艙(2)和三等艙(3),這可能與乘客的社會經濟地位有關。
-
Name:乘客的姓名,這可能包括乘客的全名和可能的頭銜。
-
Sex:乘客的性別,通常用男性(male)和女性(female)來區分。
-
Age:乘客的年齡,這可能對預測乘客是否獲救有重要影響。
-
SibSp:表示乘客的兄弟姐妹和配偶的人數,這可能反映了乘客的家庭狀況。
-
Parch:表示乘客的父母和孩子的人數,這有助于了解乘客的家庭結構。
-
Ticket:包含乘客的船票信息,可能包括船票號碼和相關的預訂信息。
-
Fare:乘客支付的票價,這可能與艙位等級和乘客的社會經濟地位有關。
-
Cabin:乘客的客艙信息,可能包括客艙的位置和類型。
-
Embarked:乘客登船的港口,這可能對分析乘客的地理分布和登船習慣有幫助。
這些數據列為我們提供了一個全面的視角來分析和預測乘客的生存情況。通過對這些特征的深入分析和特征工程,我們可以構建出能夠預測乘客是否能夠在災難中幸存的模型。此外,這些數據列還可能揭示出一些有趣的模式和關聯,比如不同艙位等級、性別、家庭狀況等因素對生存率的影響。通過對這些數據的深入挖掘和分析,我們將能夠更好地理解歷史事件,并為未來的數據分析和預測建模提供寶貴的經驗。
1、導入數據
首先導入Pandas庫,Pandas是常用的Python數據處理包,可以把CSV文件讀入成dataframe格式。代碼如下:
# 導入warnings模塊,用于控制警告信息的顯示
import warnings# 設置warnings模塊,忽略所有的警告信息
# 這通常用于避免在執行代碼時顯示不必要的警告,使輸出更清晰
warnings.filterwarnings('ignore')# 導入pandas庫,pandas是一個強大的數據分析和操作庫,常用于數據預處理
import pandas# 導入numpy庫,并將其簡稱為np
# numpy是一個用于科學計算的Python庫,提供大量的數學函數操作
import numpy as np# 使用pandas的read_csv函數讀取名為"data/ship_train.csv"的CSV文件
# 這個文件被加載到一個名為ship的pandas DataFrame對象中
# DataFrame是pandas中用于存儲表格數據的主要數據結構
ship = pandas.read_csv("data/ship_train.csv")# 打印ship DataFrame的描述性統計信息
# describe()函數提供了數據的概覽,包括計數、平均值、標準差、最小值、四分位數和最大值
# 這有助于快速了解數據的分布情況
print(ship.describe())這里的describe可以對數據進行簡單處理,例如可以查看數據的大小、判斷有無缺失,以及查看平均值、最小值等。在ipython?notebook中,data_train如下:PassengerId Survived Pclass Age SibSp \ count 891.000000 891.000000 891.000000 714.000000 891.000000 mean 446.000000 0.383838 2.308642 29.699118 0.523008 std 257.353842 0.486592 0.836071 14.526497 1.102743 min 1.000000 0.000000 1.000000 0.420000 0.000000 25% 223.500000 0.000000 2.000000 20.125000 0.000000 50% 446.000000 0.000000 3.000000 28.000000 0.000000 75% 668.500000 1.000000 3.000000 38.000000 1.000000 max 891.000000 1.000000 3.000000 80.000000 8.000000 Parch Fare count 891.000000 891.000000 mean 0.381594 32.204208 std 0.806057 49.693429 min 0.000000 0.000000 25% 0.000000 7.910400 50% 0.000000 14.454200 75% 0.000000 31.000000 max 6.000000 512.329200
這段代碼主要用于數據的加載和初步的統計分析。通過pandas庫讀取CSV文件,并使用describe()函數快速查看數據的基本統計特征。忽略警告信息是為了在輸出時避免顯示可能的非關鍵性警告,使得輸出結果更加專注于數據本身。
上述的處理是無法查看數據類型的,例如字符串中類型的“名字”這個類別就沒有被包含進去。因為下一步我們要將所需數據的類型全部轉換成數字以方便計算,所以使用info方法查看數據的類型。查看類型的代碼如下:
print(ship.info())<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns):# Column Non-Null Count Dtype --- ------ -------------- ----- 0 PassengerId 891 non-null int64 1 Survived 891 non-null int64 2 Pclass 891 non-null int64 3 Name 891 non-null object 4 Sex 891 non-null object 5 Age 714 non-null float646 SibSp 891 non-null int64 7 Parch 891 non-null int64 8 Ticket 891 non-null object 9 Fare 891 non-null float6410 Cabin 204 non-null object 11 Embarked 889 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 83.7+ KB None
2、對缺失數據的列進行填充
在處理矩陣運算時,缺失值是一個必須面對的問題,因為它們會直接影響到數據分析和模型訓練的有效性。以下是對缺失值處理方法的進一步闡述和豐富:
-
高比例缺失值的處理:當某個特征的缺失值占到數據集的很大一部分時,這個特征可能不再具有足夠的信息價值。在這種情況下,我們可能會選擇舍棄這個特征,因為它不僅不能提供有用的信息,反而可能引入噪聲,降低模型的預測準確率。
-
適度比例缺失值的處理:如果缺失值的數量不是很多,我們可以考慮使用一些統計方法來估計缺失值。這些方法可能包括:
- 使用該特征的均值、中位數或眾數來填充缺失值。
- 根據其他特征與缺失特征之間的關系,使用回歸模型來預測缺失值。
- 應用更高級的算法,如K-最近鄰(K-NN)或基于模型的方法來估計缺失值。
-
重要特征的缺失值處理:對于那些對模型預測至關重要的特征,如年齡,我們不能簡單地舍棄它們。對于這類特征,即使缺失值不多,我們也需要采用一種更加精細的處理方法。
-
年齡特征的缺失值填充:以年齡為例,由于它是一個關鍵的預測因素,我們通常會選擇用該特征的平均值來填充缺失值。這種方法簡單易行,能夠在保持數據集完整性的同時,最小化對模型準確率的影響。
-
填充代碼示例:以下是使用Python的pandas庫來填充年齡列缺失值的示例代碼:
# 使用pandas庫中的fillna方法填充DataFrame中'Age'列的缺失值
# fillna方法用于替換DataFrame中的缺失值(NaN)
# 這里,我們使用ship["Age"].median()來計算'Age'列的中位數
# 然后將這個中位數用來填充'Age'列中的所有缺失值
# 中位數作為填充值可以減少極端值的影響,是一種常用的缺失值處理方法
ship["Age"] = ship["Age"].fillna(ship["Age"].median())# 打印更新后的DataFrame 'ship'的描述性統計信息
# describe()方法提供了DataFrame中數值型列的統計摘要
# 包括計數、平均值、標準差、最小值、25%分位數、50%分位數(中位數)、75%分位數和最大值
# 這有助于快速了解填充缺失值后數據的分布情況
print(ship.describe())填充后Age的數據由原本的714個變成了891個,達到了我們的目的。數據如下:PassengerId Survived Pclass Age SibSp \ count 891.000000 891.000000 891.000000 891.000000 891.000000 mean 446.000000 0.383838 2.308642 29.361582 0.523008 std 257.353842 0.486592 0.836071 13.019697 1.102743 min 1.000000 0.000000 1.000000 0.420000 0.000000 25% 223.500000 0.000000 2.000000 22.000000 0.000000 50% 446.000000 0.000000 3.000000 28.000000 0.000000 75% 668.500000 1.000000 3.000000 35.000000 1.000000 max 891.000000 1.000000 3.000000 80.000000 8.000000 Parch Fare count 891.000000 891.000000 mean 0.381594 32.204208 std 0.806057 49.693429 min 0.000000 0.000000 25% 0.000000 7.910400 50% 0.000000 14.454200 75% 0.000000 31.000000 max 6.000000 512.329200
這段代碼的目的是處理數據集中'Age'列的缺失值,并提供了填充后的統計摘要,幫助我們理解數據的基本情況和分布特征。通過使用中位數來填充缺失值,我們能夠在一定程度上減少由于極端值帶來的影響,并且保持數據的中心趨勢。
3、屬性轉換,把某些列的字符串值轉換為數字
數據操作的另一步是將字符用數值代表,例如sex是字符串,無法進行計算,將它轉換成數字,用0代表man,用1代表female。屬性轉換代碼如下:
# 將字符用數值代表
# 這一步驟是為了將分類數據(categorical data)轉換為數值數據(numerical data)
# 因為大多數機器學習算法不能直接處理字符串類型的分類數據# sex是字符串,無法進行計算,將它轉換為數字,用0代表man,用1代表female
# 首先打印出'Sex'列中所有不同的值(即唯一值)
# unique()函數返回Series中的唯一值,這有助于我們了解數據中的分類情況
print(ship["Sex"].unique())# 將所有的male替換為數字0
# loc是pandas中的一個函數,用于基于標簽的索引/賦值
# 這里使用loc選擇'Sex'列中值為'male'的所有行,并將對應的'Sex'值替換為0
ship.loc[ship["Sex"] == "male", "Sex"] = 0# 將所有的female替換為數字1
# 同樣使用loc函數,選擇'Sex'列中值為'female'的所有行,并將對應的'Sex'值替換為1
# 這樣,'Sex'列就從字符串類型的分類數據轉換為了數值型的0和1
ship.loc[ship["Sex"] == "female", "Sex"] = 1['male' 'female']
這段代碼的目的是將ship DataFrame中的Sex列,由原來的字符串分類數據("male"和"female")轉換為數值型數據(0代表"male",1代表"female")。這種轉換對于后續的機器學習模型訓練是非常必要的,因為大多數模型只能接受數值型輸入。通過這種方式,我們能夠將分類數據編碼為模型可以理解的格式。
同樣地,將3個登錄地點“S”“C”“Q”轉換成數字,0代表S,1代表C,2代表Q,代碼如下:
# 打印'Embarked'列中所有不同的值
# Embarked列代表乘客登船的港口,其值可能是'S'、'C'或'Q',分別代表南安普頓(Southampton)、瑟堡(Cherbourg)和皇后鎮(Queenstown)
# unique()函數返回Series中的唯一值,這有助于了解數據中包含的港口類別
print(ship["Embarked"].unique())# 登船的地點也是字符串,需要轉換為數字,并填充缺失值
# 在機器學習中,通常需要將分類變量轉換為數值型,以便算法可以處理
# 首先,使用fillna方法填充'Embarked'列中的缺失值
# 這里將缺失值填充為'S',假設'S'是數據集中的一個有效港口代碼
ship["Embarked"] = ship["Embarked"].fillna('S')# loc通過索引獲取數據
# loc是pandas中的一個函數,用于基于標簽的索引/賦值
# 接下來,使用loc函數將'Embarked'列中的港口代碼轉換為數值型
# 這里將'S'、'C'和'Q'分別映射為0、1和2# 將'Embarked'列中所有值為'S'的行的'Embarked'列替換為0
ship.loc[ship["Embarked"] == "S", "Embarked"] = 0# 將'Embarked'列中所有值為'C'的行的'Embarked'列替換為1
ship.loc[ship["Embarked"] == "C", "Embarked"] = 1# 將'Embarked'列中所有值為'Q'的行的'Embarked'列替換為2
ship.loc[ship["Embarked"] == "Q", "Embarked"] = 2['S' 'C' 'Q' nan]
這段代碼的目的是將ship DataFrame中的Embarked列,由原來的字符串分類數據(代表不同的登船港口)轉換為數值型數據。這種轉換對于后續的機器學習模型訓練是非常必要的,因為大多數模型只能接受數值型輸入。通過這種方式,我們能夠將分類數據編碼為模型可以理解的格式,并且填充了缺失值,確保了數據的完整性。
四、建立模型
1、引入機器學習庫
導入線性回歸,使用回歸算法二分類進行預測;導入交叉驗證,代碼如下:
# 機器學習算法(線性回歸)
# 線性回歸是一種監督學習算法,用于預測連續的輸出值
# 它嘗試找到特征和目標變量之間的線性關系,并用該關系來預測新數據的目標值# 導入線性回歸庫
# 使用sklearn的LinearRegression類,我們可以創建一個線性回歸模型
# 這個模型將用于擬合數據并預測連續的目標變量
from sklearn.linear_model import LinearRegression# 導入交叉驗證庫
# 交叉驗證是一種模型評估方法,用于評估模型的泛化能力
# 它通過將數據集分成多個部分,在不同的子集上訓練和測試模型,來減少評估誤差# KFold是交叉驗證的一種實現,它將數據集分割成K個子集
# 在每一輪中,選擇其中一個子集作為測試集,其余的作為訓練集
# 這樣,每個數據點都被用于測試一次,而作為訓練數據K-1次
# 這有助于我們更全面地評估模型的性能
from sklearn.model_selection import KFold這段代碼的目的是為機器學習任務準備所需的工具和方法。首先,通過LinearRegression類導入線性回歸模型,這是一種常用的回歸算法,適用于預測連續的輸出值。接著,通過KFold類導入交叉驗證方法,這是一種評估模型性能的重要技術,可以幫助我們更準確地了解模型在未知數據上的表現。通過結合使用線性回歸和交叉驗證,我們可以構建一個穩健的預測模型,并對其性能進行有效的評估。
2、實例化模型
選中一些用來訓練模型的特征,并將樣本數據進行3層交叉驗證,代碼如下:
# 用來預測目標的列
# 定義predictors列表,包含用于預測的自變量列名
# 這些列將作為特征輸入到線性回歸模型中
# "Pclass"代表乘客的艙位等級,"Sex"代表性別,"Age"代表年齡
# "SibSp"代表兄弟姐妹/配偶的數量,"Parch"代表父母和孩子的數量
# "Fare"代表票價,"Embarked"代表登船港口
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]# 對線性回歸類進行實例化
# 創建一個LinearRegression類的實例,命名為alg
# 這個實例將用于擬合數據并進行預測
alg = LinearRegression()# 為泰坦尼克號數據集生成交叉驗證折疊
# 使用KFold類創建一個交叉驗證器,它將數據集分割成多個部分
# 每一部分輪流作為測試集,而其他部分作為訓練集
# n_splits=3表示數據集將被分成3份,進行3次訓練和測試
# random_state=1設置隨機數生成器的種子,以確保每次分割的一致性
# shuffle=True表示在分割前對數據進行隨機打亂,以避免數據順序影響結果
kf = KFold(n_splits=3, random_state=1, shuffle=True)這段代碼的目的是為線性回歸模型的建立和評估做準備。首先,定義了一個特征列表predictors,這些特征將用于預測目標變量。然后,實例化了一個LinearRegression對象alg,用于后續的數據擬合和預測。最后,使用KFold創建了一個交叉驗證器,用于生成訓練集和測試集的索引,以便于評估模型的性能。通過設置random_state和shuffle參數,確保了交叉驗證的可重復性和隨機性。
3、把數據傳入模型,預測結果
# 初始化一個空列表,用于存儲所有測試折疊的預測結果
predictions = []# 使用KFold對象kf進行交叉驗證,遍歷每一對訓練集和測試集的索引
for train, test in kf.split(ship):# 根據訓練集索引從ship DataFrame中選取特征列# predictors是特征列的列表,.iloc[train,:]根據行索引選擇數據train_predictors = ship[predictors].iloc[train,:]# 根據訓練集索引從ship DataFrame中選取目標列"Survived"# 目標列是我們想要預測的列,即乘客是否存活train_target = ship["Survived"].iloc[train]# 使用fit方法訓練線性回歸模型alg# 傳入訓練特征集train_predictors和目標集train_target# 這一步是模型學習特征和目標之間關系的過程alg.fit(train_predictors, train_target)# 使用訓練好的模型alg對測試集進行預測# 根據測試集索引從ship DataFrame中選取特征列# predict方法返回測試集的預測結果test_predictions = alg.predict(ship[predictors].iloc[test,:])# 將得到的測試集預測結果添加到predictions列表中# 最終,predictions列表將包含每一輪交叉驗證的預測結果predictions.append(test_predictions)這段代碼的目的是實現交叉驗證過程中的模型訓練和預測。通過KFold對象kf,代碼遍歷每一對訓練集和測試集的索引。對于每一對索引,代碼從ship DataFrame中選取相應的特征列和目標列,然后使用這些數據訓練線性回歸模型alg。訓練完成后,模型被用來對當前的測試集進行預測,并將預測結果存儲在predictions列表中。這個過程重復進行,直到所有的測試集都被預測過,從而完成整個交叉驗證過程。
五、算法概率計算
將預測正確的數目除以總量,代碼如下:
# 使用numpy的concatenate函數將predictions列表中所有的數組合并成一個數組
# predictions列表包含了通過交叉驗證得到的各個測試集的預測結果
# axis=0參數表示沿著第一個軸(行)進行合并,即將所有數組垂直堆疊起來
predictions = np.concatenate(predictions, axis=0)# 將預測結果映射到二分類結果(0或1)
# 線性回歸模型的輸出是一個連續值,我們需要將其轉換為二分類結果
# 這里使用的閾值是0.5,大于0.5的預測結果被視為1(預測為存活),小于等于0.5的被視為0(預測為未存活)
predictions[predictions > .5] = 1
predictions[predictions <= .5] = 0# 計算準確率
# 首先,使用條件索引找出預測正確的結果,即預測結果與實際結果(ship["Survived"])相等的元素
# 然后,計算這些正確預測的數量,并除以總預測數(len(predictions)),得到準確率
accuracy = sum(predictions[predictions == ship["Survived"]]) / len(predictions)# 打印準確率
# 這個值表示模型預測的準確性,是評估模型性能的一個重要指標
print(accuracy)這段代碼的目的是將交叉驗證得到的連續預測結果轉換為二分類結果,并計算模型的準確率。首先,使用np.concatenate將所有測試集的預測結果合并成一個數組。然后,根據閾值0.5將連續的預測結果轉換為0或1的分類結果。最后,通過比較預測結果和實際結果,計算并打印出模型的準確率,這是一個衡量模型性能的關鍵指標。
該算法得到的準確率為:0.13468013468013468。
目前的準確率比較低,下面我們再介紹其他幾種算法來提高一下預測的準確率。
六、集成算法,構建多棵分類樹
1、構造多個分類器
從sklearn庫導入交叉驗證和邏輯回歸模塊,實例化邏輯回歸算法,使用3層交叉驗證得到概率值,代碼如下:
# 導入邏輯回歸所需的庫
# 邏輯回歸是一種用于二分類問題的機器學習算法,它預測的是事件發生的概率
from sklearn.linear_model import LogisticRegression# 導入cross_val_score函數
# cross_val_score用于計算交叉驗證的分數,如準確率、召回率等
from sklearn.model_selection import cross_val_score# 實例化LogisticRegression類,創建一個邏輯回歸模型
# random_state參數設置為1,確保每次分割數據時結果相同,增加模型的可復現性
alg = LogisticRegression(random_state=1)# 計算所有交叉驗證折疊的準確率
# cross_val_score函數計算給定模型在交叉驗證中的表現
# alg是邏輯回歸模型,ship[predictors]是特征數據,ship["Survived"]是目標變量
# cv=3表示使用3折交叉驗證,即數據被分為3份,每份輪流作為測試集
scores = cross_val_score(alg, ship[predictors], ship["Survived"], cv=3)# 打印分數的平均值
# 由于每一折交叉驗證都會得到一個分數,scores.mean()計算這些分數的平均值
# 這個平均值提供了模型整體性能的一個估計
print(scores.mean())# 注意事項
# 邏輯回歸與線性回歸的輸出類型不同
# 邏輯回歸輸出的是概率值,表示某個事件發生的可能性
# 而線性回歸輸出的是[0,1]區間的數值,表示連續的預測結果
# 通常邏輯回歸的輸出需要通過閾值(如0.5)轉換為二分類結果這段代碼的目的是使用邏輯回歸模型對輪船數據集進行分類,并評估模型的性能。首先,通過LogisticRegression類創建邏輯回歸模型實例。然后,使用cross_val_score函數計算模型在3折交叉驗證中的準確率。最后,打印出這些準確率的平均值,作為模型性能的一個估計。同時,代碼注釋中提到了邏輯回歸與線性回歸在輸出類型上的區別。
通過邏輯回歸,最終準確率為:0.7957351290684623。可以看出相較于之前的算法,準確率有了明顯的提高。
2、隨機森林
導入交叉驗證與隨機森林模塊,random_state=1表示此處代碼多運行幾次得到的隨機值都是一樣的,如果不設置,則兩次執行的隨機值是不一樣的。n_estimators指定有多少棵決策樹,樹的分裂的條件是:min_samples_split代表樣本不停地分裂,某一個節點上的樣本如果只有2個,就不再繼續分裂。min_samples_leaf是控制葉子節點的最小個數。構建隨機森林(構造多少棵樹、最小切分點、最少的葉子節點個數)控制樹的高度,以防止過擬合,代碼如下:
# 導入隨機森林分類器和梯度提升分類器
# 這兩個都是集成學習方法,用于分類任務
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier# 定義用于模型訓練的特征列
predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]# 初始化隨機森林分類器算法
# 使用默認參數,同時指定一些關鍵參數以控制模型的行為
# n_estimators參數定義了要生成的決策樹的數量,更多的樹通常可以提高模型的性能
# min_samples_split定義了在決策樹中進行拆分操作所需的最小樣本數
# min_samples_leaf定義了決策樹中葉節點的最小樣本數
alg = RandomForestClassifier(random_state=1, n_estimators=10, min_samples_split=2, min_samples_leaf=1)# 計算所有交叉驗證折疊的準確率
# 使用KFold對象進行3折交叉驗證,每次拆分數據前都會打亂
kf = KFold(n_splits=3, random_state=1, shuffle=True)# 使用cross_val_score函數計算隨機森林模型在交叉驗證中的準確率
# ship[predictors]是特征數據,ship["Survived"]是目標變量
# cv參數設置為kf,使用上面定義的交叉驗證方案
scores = cross_val_score(alg, ship[predictors], ship["Survived"], cv=kf)# 打印分數的平均值
# 每一折交叉驗證都會給出一個準確率分數,scores.mean()計算這些分數的平均值
# 這個平均準確率提供了模型整體性能的一個估計
print(scores.mean())這段代碼的目的是使用隨機森林分類器對輪船數據集進行分類,并評估模型的性能。首先,定義了模型將要使用的特征列。然后,創建了一個RandomForestClassifier實例,并設置了一些關鍵的參數來控制模型的行為。接著,使用KFold對象定義了一個3折交叉驗證方案,并使用cross_val_score函數來計算模型在交叉驗證中的準確率。最后,打印出這些準確率的平均值,作為模型性能的一個估計。
隨機森林算法處理后得到準確率為:0.7957351290684626。
這里增加決策樹的數量,能使模型準確率更高。當然,也不是樹越多越好,達到一定數量后,將不會對準確率產生很大的影響。
# 初始化隨機森林分類器算法
# RandomForestClassifier是一種集成學習方法,適用于分類和回歸任務
# random_state設置為1,以確保每次運行代碼時數據分割的一致性
# n_estimators=50表示使用50棵樹構建隨機森林,增加樹的數量可以提高模型的準確性
# min_samples_split=4表示只有當一個節點的樣本數大于或等于4時,才會進行拆分
# min_samples_leaf=2表示只有當葉節點的樣本數大于或等于2時,才會保留該葉節點
alg = RandomForestClassifier(random_state=1, n_estimators=50, min_samples_split=4, min_samples_leaf=2)# 創建KFold對象,用于3折交叉驗證
# n_splits=3表示將數據集分為3份,每份輪流作為測試集
# random_state=1確保每次分割的數據相同,shuffle=True表示在分割前會隨機打亂數據
kf = KFold(n_splits=3, random_state=1, shuffle=True)# 使用cross_val_score計算隨機森林模型在交叉驗證中的準確率
# 傳入模型alg,特征數據ship[predictors],目標變量ship["Survived"],以及交叉驗證方案kf
# cross_val_score會返回一個數組,包含每次交叉驗證的準確率分數
scores = cross_val_score(alg, ship[predictors], ship["Survived"], cv=kf)# 打印分數的平均值
# scores.mean()計算交叉驗證得到的準確率分數的平均值
# 這個平均準確率是模型性能的一個指標,反映了模型在未知數據上的泛化能力
print(scores.mean())這段代碼的目的是使用隨機森林分類器對數據集進行分類任務,并使用交叉驗證來評估模型的性能。通過設置不同的參數,可以調整模型的復雜度和性能。交叉驗證的目的是減少模型評估的方差,提供更穩健的性能估計。最后,通過打印平均準確率,我們可以了解模型在整體數據集上的表現。
得到準確率為:0.8260381593714926。可以看出,準確率由于決策樹數量的增加而有了相應的提高。
七、特征提取
由于事先不知道哪些數據對模型的預測有影響,我們假設兄弟姐妹、老人小孩的人數對實驗有影響,把這兩個數據整合到一起統稱為家庭人數。再假設人名字的長度也有影響。代碼如下:
# 生成一個名為"FamilySize"的新列
# 這個列是通過將"SibSp"(兄弟姐妹/配偶的數量)和"Parch"(父母和孩子的數量)相加得到的
# "FamilySize"列表示乘客的家庭大小,即與乘客一起旅行的家庭成員總數
ship["FamilySize"] = ship["SibSp"] + ship["Parch"]# 使用apply方法生成一個新的列"NameLength"
# apply方法允許我們對DataFrame中的列應用一個函數
# 這里使用了一個lambda函數,它是一個匿名函數,用于返回每個姓名的長度
# len(x)計算每個乘客姓名字符串的長度
# 這樣,"NameLength"列將包含每個乘客姓名的長度
ship["NameLength"] = ship["Name"].apply(lambda x: len(x))這段代碼的目的是為ship DataFrame添加兩個新的特征列:FamilySize和NameLength。FamilySize列通過將SibSp和Parch列的值相加來計算乘客的家庭規模。NameLength列則利用apply方法和lambda表達式來計算每個乘客姓名的長度。這些新生成的特征可能會在后續的數據分析或模型訓練中起到作用,因為它們可能與乘客的生存概率有關聯。
導入正則表達式模塊,統計打印所有稱謂的個數,并將稱謂轉換成數字。代碼如下:
import re
# 導入正則表達式模塊re,用于文本的搜索和匹配# 定義一個函數get_title,用于從乘客姓名中提取標題
def get_title(name):# 使用正則表達式re.search來查找符合模式的字符串# 模式' ([A-Za-z]+)\.'用于匹配由一個空格開頭,后面跟著一個或多個大小寫字母,并且以句號結束的字符串# 這通常對應于乘客姓名中的頭銜部分title_search = re.search(' ([A-Za-z]+)\.', name)# 如果正則表達式搜索找到了匹配項,返回匹配的字符串(即標題)# group(1)方法返回第一個括號中匹配的字符串if title_search:return title_search.group(1)# 如果沒有找到標題,返回空字符串return ""# 使用apply方法和get_title函數從"Name"列中提取所有乘客的標題
titles = ship["Name"].apply(get_title)# 打印每個標題出現的頻率
# 使用pandas的value_counts函數統計各個標題的數量
print(pandas.value_counts(titles))# 定義一個字典title_mapping,用于將標題映射為整數
# 某些罕見的標題被映射為常見標題的相同數字代碼
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Dr": 5, "Rev": 6, "Major": 7, "Col": 7, "Mlle": 8, "Mme": 8, "Don": 9, "Lady": 10, "Countess": 10, "Jonkheer": 10, "Sir": 9, "Capt": 7, "Ms": 2
}# 遍歷title_mapping字典中的所有項
for k, v in title_mapping.items():# 將titles列中匹配特定標題的值替換為對應的整數代碼titles[titles == k] = v# 在映射所有標題之后,再次打印標題的頻率
# 這驗證了映射是否成功應用
print(pandas.value_counts(titles))# 將處理后的標題添加到原始的ship DataFrame中,作為新的列"Title"
ship["Title"] = titles這段代碼的目的是處理泰坦尼克號乘客名單中的姓名數據,提取出乘客的頭銜,并將其映射為整數代碼。首先,定義了一個函數get_title來從姓名中提取頭銜。然后,使用apply方法和get_title函數從姓名列中提取所有乘客的頭銜,并統計每個頭銜的出現頻率。接下來,定義了一個映射字典title_mapping,將常見的頭銜映射為整數。通過遍歷這個映射字典,將提取出的頭銜替換為對應的整數代碼。最后,將這些處理后的頭銜作為新列"Title"添加到原始的ship DataFrame中。這個過程有助于簡化數據,并可能為后續的數據分析或模型訓練提供有用的特征。
顯示結果為:
Name Mr 517 Miss 182 Mrs 125 Master 40 Dr 7 Rev 6 Mlle 2 Major 2 Col 2 Countess 1 Capt 1 Ms 1 Sir 1 Lady 1 Mme 1 Don 1 Jonkheer 1 Name: count, dtype: int64 Name 1 517 2 183 3 125 4 40 5 7 6 6 7 5 8 3 10 3 9 2 Name: count, dtype: int64
1、進行特征選擇
導入特征選擇模塊,通過特征選擇庫,對選擇的特征進行進一步篩選,看看哪些特征比較重要。f_classif(方差分析的F值)是評估特征的指標,k表示選擇的特征的個數。特征選擇代碼如下:
import numpy as np
# 導入NumPy庫,NumPy是一個用于科學計算的Python庫,提供大量的數學函數操作from sklearn.feature_selection import SelectKBest, f_classif
# 從scikit-learn庫中導入SelectKBest類和f_classif函數
# SelectKBest用于選擇最佳的特征,f_classif是一個用于評估特征重要性的統計測試import matplotlib.pyplot as plt
# 導入matplotlib的pyplot模塊,用于繪圖predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked", "FamilySize", "Title", "NameLength"]
# 定義一個列表predictors,包含用于特征選擇的特征列名# 進行特征選擇
# 使用SelectKBest選擇得分最高的k個特征
# f_classif是ANOVA F-value,用于分類問題的單變量特征選擇
selector = SelectKBest(f_classif, k=5)
# k=5表示選擇5個最佳特征# 用訓練數據擬合選擇器
# fit方法用于計算各個特征的得分和p值
selector.fit(ship[predictors], ship["Survived"])# 獲取每個特性的原始p值,并將p值轉換為分數
# p值是統計測試中的概念,用于測試特征的重要性
# 這里使用-np.log10轉換p值,這是一種常見的轉換方法,可以強調較小的p值(即更顯著的特征)
# np.log10是以10為底的對數函數
scores = -np.log10(selector.pvalues_)這段代碼的目的是使用基于ANOVA F-value的統計測試進行特征選擇,以確定對預測乘客是否存活("Survived")最有影響的特征。首先,導入所需的庫和模塊,然后定義一個包含所有候選特征的列表。接著,創建一個SelectKBest實例,指定使用f_classif函數和選擇前5個特征。使用fit方法計算各個特征的得分和p值。最后,獲取p值并應用對數轉換,以便在后續步驟中評估或排序特征的重要性。
2、用視圖的方式展示
通過feature_selection對選擇的特征做進一步選擇,畫出直方圖可以直觀地看出哪些特征對最終的準確率影響較大。代碼如下:
import matplotlib.pyplot as plt
# 導入matplotlib的pyplot模塊,這是一個用于繪圖的庫predictors = ["Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked", "FamilySize", "Title", "NameLength"]
# 假設predictors列表已經定義,包含所有候選特征的名稱scores = -np.log10(selector.pvalues_)
# 假設scores變量已經計算,包含轉換后的p值分數,用于評估特征的重要性# 畫出成績,看看“Pclass”“Sex”“Title”和“Fare”怎樣才是最好的
# 使用bar函數繪制柱狀圖,顯示每個特征的分數
# range(len(predictors))生成一個序列,作為x軸的位置
plt.bar(range(len(predictors)), scores)# 設置x軸的刻度,使其顯示每個特征的名稱
# range(len(predictors))生成一個序列,作為x軸的刻度位置
# predictors列表作為x軸的刻度標簽
# rotation='vertical'將標簽旋轉90度,使其垂直顯示,便于閱讀
plt.xticks(range(len(predictors)), predictors, rotation='vertical')# 將圖表保存到文件
# 'Images/01Main-01.png'是文件的保存路徑和名稱
# bbox_inches='tight'確保所有的圖表內容都被包含在保存的圖像中,沒有被裁剪掉
plt.savefig('Images/01Main-01.png', bbox_inches='tight')# 顯示圖表
plt.show()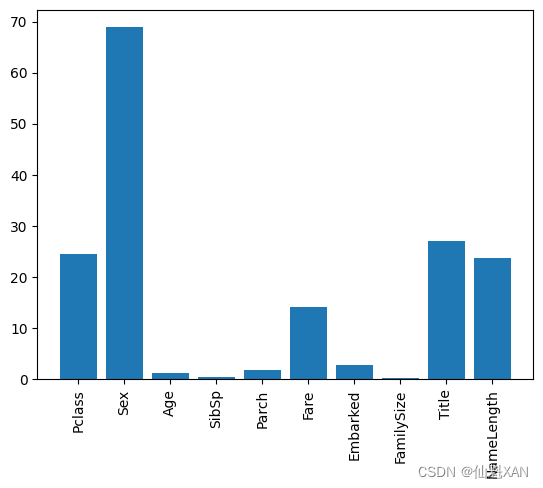
這段代碼的目的是繪制一個柱狀圖,用于可視化不同特征的分數,這些分數是通過特征選擇過程計算得出的。首先,使用plt.bar函數創建柱狀圖,其中x軸位置由range(len(predictors))給出,y軸的高度由scores變量給出。然后,使用plt.xticks設置x軸的刻度標簽,使其顯示每個特征的名稱,并通過rotation='vertical'參數將標簽垂直顯示。接著,使用plt.savefig函數將圖表保存為圖像文件。最后,使用plt.show函數顯示圖表。這樣,用戶可以直觀地看到哪些特征在模型中更為重要。
通過以上特征的重要性分析,選擇出4個最重要的特性,重新進行隨機森林算法的運算。本處理是為了練習在隨機森林中的特征選擇,它對于實際的數據挖掘具有重要意義。特征選擇之后的算法代碼如下:
# 通過以上特征的重要性分析,選擇出4個最重要的特性,重新進行隨機森林算法的運算
# 根據之前的特征重要性分析,選擇了"Pclass"、"Sex"、"Fare"和"Title"這四個特征
# 這些特征被認為在預測乘客是否存活方面最為重要
predictors = ["Pclass", "Sex", "Fare", "Title"]# 初始化隨機森林分類器算法
# RandomForestClassifier是一個集成學習方法,用于分類任務
# random_state設置為1,以確保每次運行代碼時結果的一致性
# n_estimators=50表示使用50棵樹構建隨機森林
# min_samples_split=8表示只有當一個節點的樣本數大于或等于8時,才會進行拆分
# min_samples_leaf=4表示只有當葉節點的樣本數大于或等于4時,才會保留該葉節點
alg = RandomForestClassifier(random_state=1, n_estimators=50, min_samples_split=8, min_samples_leaf=4)# 進行交叉驗證
# 使用KFold對象進行3折交叉驗證,每次拆分數據前都會打亂
kf = KFold(n_splits=3, random_state=1, shuffle=True)# 使用cross_val_score計算隨機森林模型在交叉驗證中的準確率
# ship[predictors]是特征數據,ship["Survived"]是目標變量
# cv=kf指定使用KFold對象定義的交叉驗證方案
scores = cross_val_score(alg, ship[predictors], ship["Survived"], cv=kf)# 打印交叉驗證的平均準確率
# scores.mean()計算交叉驗證得到的準確率分數的平均值
# 這提供了模型在所選特征上的整體性能估計
# 根據注釋,目前的結果并無明顯提升,這可能是由于特征選擇或其他因素
print(scores.mean())# 注釋中提到,本處理是為了練習在隨機森林中的特征選擇
# 特征選擇是數據挖掘中的一個重要步驟,有助于提高模型的性能和解釋性準確率為:0.819304152637486。
這段代碼的目的是使用隨機森林分類器對泰坦尼克號數據集進行分類任務,并使用交叉驗證來評估模型的性能。首先,根據之前的特征重要性分析,選擇了四個最重要的特征。然后,創建了一個RandomForestClassifier實例,并設置了一些關鍵參數來控制模型的行為。接著,使用KFold對象定義了一個3折交叉驗證方案,并使用cross_val_score函數來計算模型在交叉驗證中的準確率。最后,打印出這些準確率的平均值,作為模型性能的一個估計。同時,代碼注釋中提到了特征選擇的重要性和本處理的目的。
八、集成多種算法
在數據科學競賽和實際應用中,算法集成是一種提高模型泛化能力和減少過擬合的有效策略。下面,我將對您提供的段落進行豐富和擴展:
集成學習是一種強大的機器學習技術,它通過結合多個模型的預測來提高整體性能。這種方法的核心思想是“眾人拾柴火焰高”,即多個模型的集體智慧往往優于單個模型。在實踐中,我們通常會遇到各種不同的算法,它們各自有著獨特的優勢和局限性。通過集成這些算法,我們可以充分利用它們的長處,同時減少單一模型可能帶來的過擬合風險。
在這段描述中,我們關注的是兩種特定的算法:GradientBoostingClassifier和邏輯回歸。
-
GradientBoostingClassifier:這是一種基于梯度提升決策樹的集成學習算法。它通過逐步添加新的弱學習器(通常是決策樹)來最小化損失函數,每個新的弱學習器都試圖糾正前一個學習器的錯誤。這種方法可以顯著提高模型的性能,因為它專注于那些模型預測錯誤較多的樣本。
-
邏輯回歸:雖然邏輯回歸本身是一個簡單的線性模型,但它在分類問題中非常有效,尤其是二分類問題。它通過使用邏輯函數將線性回歸的輸出映射到0和1之間,從而預測事件發生的概率。
為了進一步增強這兩種算法的性能,我們可以采用**軟投票(Soft Voting)**策略。與傳統的硬投票(Hard Voting)不同,軟投票考慮的是每個模型輸出的預測概率,而不是最終的分類決策。具體來說,每個模型都會輸出一個介于0和1之間的概率值,表示樣本屬于正類的概率。然后,我們計算所有模型輸出的概率的平均值,并根據這個平均概率來確定最終的分類。
在Python的scikit-learn庫中,我們可以使用VotingClassifier來輕松實現軟投票。這個工具允許我們將多個模型組合成一個集成模型,并自動處理概率的計算和平均。通過這種方式,我們可以構建一個更加健壯和準確的分類器,它能夠更好地泛化到新的數據上,減少過擬合的風險。
總之,算法集成是一種提高模型性能、減少過擬合的有效方法。通過結合GradientBoostingClassifier的強學習能力和邏輯回歸的簡單有效性,再利用軟投票策略來整合它們的預測,我們可以構建一個更加強大和可靠的分類系統。這種方法在數據科學競賽和實際應用中都非常受歡迎,是提高模型泛化能力的重要手段。代碼如下:
from sklearn import ensemble
from sklearn.model_selection import cross_validate
# 導入sklearn庫中的ensemble模塊,用于創建集成模型
# 導入cross_validate函數,用于進行交叉驗證# 定義我們要集成的算法列表。
# 這里使用了兩種不同的分類器:GradientBoostingClassifier和LogisticRegression。
# 每種分類器都通過名稱(如 'gbc')和實例進行配對。
voting_est = [('gbc', GradientBoostingClassifier(random_state=1, n_estimators=25, max_depth=5)),('lr', LogisticRegression(random_state=1)),
]predictors = ["Pclass", "Sex", "Fare", "FamilySize", "Title", "Age", "Embarked"]
# 定義predictors列表,包含用于訓練模型的特征列名# 創建一個軟投票分類器,用于集成上面定義的分類器。
# 'soft'投票意味著分類器將使用預測的概率進行平均,而不是使用多數投票。
voting_soft = ensemble.VotingClassifier(estimators=voting_est, voting='soft')# 執行交叉驗證,并返回一個包含多個結果的字典。
# 這里使用kf定義的交叉驗證方案(假設kf已經定義為KFold對象)
voting_soft_cv = cross_validate(voting_soft, ship[predictors], ship["Survived"], cv=kf)# 訓練集成模型voting_soft,使用選定的特征和目標變量。
voting_soft.fit(ship[predictors], ship["Survived"])# 打印軟投票分類器在交叉驗證中測試集的平均準確率(以百分比形式)。
# {:.2f} %是一個格式化字符串,表示將數字格式化為百分比,保留兩位小數。
print("Soft Voting Test w/bin score mean: {:.2f} %".format(voting_soft_cv['test_score'].mean() * 100))這段代碼的目的是創建一個集成模型,該模型結合了梯度提升分類器(GradientBoostingClassifier)和邏輯回歸(LogisticRegression)兩種算法,并通過軟投票(即概率平均)的方式來進行集成。首先,定義了兩種分類器的實例,并存儲在列表voting_est中。然后,使用ensemble.VotingClassifier創建了一個軟投票分類器voting_soft。接著,使用cross_validate函數對集成模型進行交叉驗證,并存儲結果。最后,訓練集成模型,并打印出交叉驗證中測試集的平均準確率。這樣的集成方法有助于提高模型的泛化能力,減少過擬合的風險。
代碼運行結果為:Soft Voting Test w/bin score mean: 83.73 %,準確率有明顯的提高。
九、小結
本文將遵循機器學習的標準流程,對“輪船人員沉船生存率”這一主題進行深入的數據分析和預測建模。我們的目標是通過歷史數據來預測乘客在沉船事故中的獲救概率。為了實現這一目標,文章將依次展開以下幾個關鍵步驟:
-
數據收集與處理:作為分析的基礎,我們將首先收集相關數據,并使用Pandas等庫進行清洗和預處理,以確保數據質量。
-
特征工程:接下來,我們將探索數據中的各種特征,并進行必要的轉換和編碼,以增強模型的性能。這可能包括處理缺失值、創建新特征或對現有特征進行規范化。
-
模型選擇:在準備好數據之后,我們將嘗試多種機器學習算法,如邏輯回歸、隨機森林、梯度提升等,以確定最適合我們數據的模型。
-
模型評估:選擇合適的模型后,我們將使用交叉驗證、精確度、召回率等指標來評估模型的性能,并根據需要進行調整和優化。
-
實戰演練:本章將通過實際的代碼示例,引導讀者一步步完成從數據加載到模型預測的全過程,確保讀者能夠將理論應用到實踐中。
-
結果分析與應用:最后,我們將分析模型的預測結果,并探討如何將這些結果應用到實際情況中,以幫助提高事故應對和救援工作的效率。
通過本文的學習,讀者不僅能夠獲得寶貴的機器學習實戰經驗,還將對如何處理實際問題、如何評估和優化模型有一個全面的理解。我們希望讀者能夠通過本章內容,提升自己的數據分析能力,并在未來的工作中有效地應用機器學習技術。
附錄
一、代碼地址
github:GitHub - XANkui/PythonMachineLearningBeginner: Python 機器學習是利用 Python 編程語言中的各種工具和庫來實現機器學習算法和技術的過程。Python 是一種功能強大且易于學習和使用的編程語言,因此成為了機器學習領域的首選語言之一。這里我們一起開始一場Python 機器學習基礎入門到精通學習旅程。

)

)





:概念、實踐與優勢)


分析(補充篇)(附MATLAB、R語言和python代碼實現))






