云計算與的定義
長定義是:“云計算是一種商業計算模型。它將計算任務分布在大量計算機構成的資源池上,使各種應用系統能夠根據需要獲取計算力、存儲空間和信息服務。”
短定義是:“云計算是通過網絡按需提供可動態伸縮的廉價計算服務。
云計算的特點
(1)超大規模。“云”具有相當的規模,谷歌云計算已經擁上百萬臺服務器,亞馬
遜、IBM、微軟、Yahoo、阿里、百度和騰訊等公司的“云”均擁有幾十萬臺服務
器。“云”能賦予用戶前所未有的計算能力。
(2)虛擬化。云計算支持用戶在任意位置、使用各種終端獲取服務。所請求的資源
來自“云”,而不是固定的有形的實體。應用在“云”中某處運行,但實際上用戶無須了解應
用運行的具體位置,只需要一臺計算機、PAD或手機,就可以通過網絡服務來獲取各種能
力超強的服務。
(3)高可靠性。“云”使用了數據多副本容錯、計算節點同構可互換等措施來保障服
務的高可靠性,使用云計算比使用本地計算機更加可靠。
(4)通用性。云計算不針對特定的應用,在“云”的支撐下可以構造出千變萬化的應
用,同一片“云”可以同時支撐不同的應用運行。
(5)高可伸縮性。“云”的規模可以動態伸縮,滿足應用和用戶規模增長的需要。
(6)按需服務。“云”是一個龐大的資源池,用戶按需購買,像自來水、電和煤氣那
樣計費。
(7)極其廉價。“云”的特殊容錯措施使得可以采用極其廉價的節點來構成
云;“云”的自動化管理使數據中心管理成本大幅降低;“云”的公用性和通用性使資源的利
用率大幅提升;“云”設施可以建在電力資源豐富的地區,從而大幅降低能源成本。因
此“云”具有前所未有的性能價格比。
大數據的特點
4V+1C。
(1)數據量大(Volume):存儲的數據量巨大,PB級別是常態,因而對其分析的計
算量也大。
(2)多樣(Variety):數據的來源及格式多樣,數據格式除了傳統的結構化數據
外,還包括半結構化或非結構化數據,比如用戶上傳的音頻和視頻內容。而隨著人類活動
的進一步拓寬,數據的來源更加多樣。
(3)快速(Velocity):數據增長速度快,而且越新的數據價值越大,這就要求對數
據的處理速度也要快,以便能夠從數據中及時地提取知識,發現價值。
(4)價值密度低(Value):需要對大量的數據進行處理,挖掘其潛在的價值,因
而,大數據對我們提出的明確要求是設計一種在成本可接受的條件下,通過快速采集、發
現和分析,從大量、多種類別的數據中提取價值的體系架構。
(5)復雜度(Complexity):對數據的處理和分析的難度大。
Google文件系統GFS
Google文件系統(Google File System,GFS)是一個大型的分布式文件系統。它為
Google云計算提供海量存儲,并且與Chubby、MapReduce及Bigtable等技術結合十分緊
密,處于所有核心技術的底層。GFS不是一個開源的系統,我們僅能從Google公布的技術
文檔來獲得相關知識。
Google GFS的新穎之處在于它采用廉價的商用機器構建分布式文件系統,同時將GFS
的設計與Google應用的特點緊密結合,簡化實現,使之可行,最終達到創意新穎、有用、
可行的完美組合。GFS將容錯的任務交給文件系統完成,利用軟件的方法解決系統可靠性
問題,使存儲的成本成倍下降。GFS將服務器故障視為正常現象,并采用多種方法,從多
個角度,使用不同的容錯措施,確保數據存儲的安全、保證提供不間斷的數據存儲服務。
GFS的特點:
(1)采用中心服務器模式,簡化了設計。
(2)不緩存數據。
(3)在用戶態下實現,降低耦合度和編程難度。
(4)只提供專用接口,降低了實現難度和復雜度,提高了通用性和效率。
MapReduce模型
MapReduce是Google提出的一個軟件架構,是一種處理海量數據的并行編程模式,用
于大規模數據集(通常大于1TB)的并行運算。Map(映射)、Reduce(化簡)的概念和
主要思想,都是從函數式編程語言和矢量編程語言借鑒來的。正是由于MapReduce有函
數式和矢量編程語言的共性,使得這種編程模式特別適合于非結構化和結構化的海量數據
的搜索、挖掘、分析與機器智能學習等。
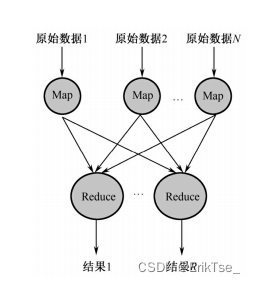
簡單地說,一個Map函數就是對一部分原始數據進行指定的操作。每個Map操作都針
對不同的原始數據,因此Map與Map之間是互相獨立的,這使得它們可以充分并行化。一
個Reduce操作就是對每個Map所產生的一部分中間結果進行合并操作,每個Reduce所處理
的Map中間結果是互不交叉的,所有Reduce產生的最終結果經過簡單連接就形成了完整的
結果集,因此Reduce也可以在并行環境下執行。
分布式鎖服務Chubby
Chubby是Google設計的提供粗粒度鎖服務的一個文件系統,它基于松耦合分布式系
統,解決了分布的一致性問題。通過使用Chubby的鎖服務,用戶可以確保數據操作過程
中的一致性。不過值得注意的是,這種鎖只是一種建議性的鎖(Advisory Lock)而不是
強制性的鎖(Mandatory Lock),這種選擇使系統具有更大的靈活性。
通常情況下Google的一個數據中心僅運行一個Chubby單元(Chubby cell,下面會
有詳細講解述),這個單元需要支持包括GFS、Bigtable在內的眾多Google服務,因此,
在設計Chubby時候,必須充分考慮系統需要實現的目標以及可能出現的各種問題。
Chubby的設計目標主要有以下幾點。
(1)高可用性和高可靠性。這是系統設計的首要目標,在保證這一目標的基礎上再
考慮系統的吞吐量和存儲能力。
(2)高擴展性。將數據存儲在價格較為低廉的RAM,支持大規模用戶訪問文件。
(3)支持粗粒度的建議性鎖服務。提供這種服務的根本目的是提高系統的性能。
(4)服務信息的直接存儲。可以直接存儲包括元數據、系統參數在內的有關服務信
息,而不需要再維護另一個服務。
(5)支持通報機制。客戶可以及時地了解到事件的發生。
(6)支持緩存機制。通過一致性緩存將常用信息保存在客戶端,避免了頻繁地訪問
主服務器。
Chubby文件系統
Chubby系統本質上就是一個分布式的、存儲大量小文件的文件系統,它所有的操作
都是在文件的基礎上完成的。例如在Chubby最常用的鎖服務中,每一個文件就代表了一
個鎖,用戶通過打開、關閉和讀取文件,獲取共享(Shared)鎖或獨占(Exclusive)鎖。
選舉主服務器的過程中,符合條件的服務器都同時申請打開某個文件并請求鎖住該文件。
成功獲得鎖的服務器自動成為主服務器并將其地址寫入這個文件夾,以便其他服務器和用
戶可以獲知主服務器的地址信息。
Chubby 的主要功能
分布式鎖: Chubby 提供了一個分布式鎖服務,允許多個進程或線程在同一時間對共享資源進行訪問控制。它保證了多個進程或線程對共享資源的訪問是互斥的,從而避免了沖突和數據不一致的問題。
命名空間管理: Chubby 提供了一個命名空間,用于存儲元數據和配置信息。這些信息可以被分布式系統中的各個組件訪問和更新。
服務發現: Chubby 可以用來發現分布式系統中的服務。它維護了一個服務注冊表,其中包含了系統中所有服務的位置和狀態信息。客戶端可以通過查詢 Chubby 來找到所需的服務。
Chubby 的作用
保證數據一致性: 通過分布式鎖機制,Chubby 保證了分布式系統中數據的一致性。
簡化分布式系統設計: Chubby 提供了命名空間管理和服務發現等功能,簡化了分布式系統的設計。
提高分布式系統可靠性: Chubby 的容錯機制提高了分布式系統的可靠性。
Chubby 的應用場景:
分布式數據庫: Chubby 可以用來保證分布式數據庫中數據的一致性。
分布式緩存: Chubby 可以用來協調分布式緩存中的數據更新。
分布式消息隊列: Chubby 可以用來保證分布式消息隊列的有序性和一致性。
分布式結構化數據表BigTable
Bigtable是Google開發的基于GFS和Chubby的分布式存儲系統。Google的很多數據,包括Web索引、衛星圖像數據等在內的海量結構化和半結構化數據,都存儲在Bigtable中。從實現上看,Bigtable并沒有什么全新的技術,但是如何選擇合適的技術并將這些技術高效、巧妙地結合在一起恰恰是最大的難點。Bigtable在很多方面和數據庫類似,但它并不是真正意義上的數據庫。通過本節的學習,讀者將會對Bigtable的數據模型、系統架構、實現以及它使用的一些數據庫技術有一個全面的認識。
Bigtable 的主要特點:
(1)分布式存儲: Bigtable 將數據分布存儲在多個服務器上,能夠處理 PB 級的數據規模。
(2)可擴展性: Bigtable 可以根據數據量的增長動態擴展,無需停機維護。
(3)高性能: Bigtable 提供了低延遲的數據訪問,能夠滿足實時數據查詢的需求。
(4)多模型支持: Bigtable 支持多種數據模型,包括稀疏數據、半結構化數據等。
(5)強一致性: Bigtable 提供了強一致性保證,確保數據在所有副本之間保持一致。
基礎存儲架構Dynamo
當Web服務剛剛興起時,各種平臺大多采用關系型數據庫進行數據存儲。但由于Web數據中大部分為半結構化數據且數據量巨大,關系型數據庫無法滿足其存儲要求。為此,很多服務商都設計并開發了自己的存儲系統。其中,Amazon的Dynamo是非常具有代表性的一種存儲架構,被作為狀態管理組件用于AWS的很多系統中。2007年,Amazon將Dynamo以論文形式發表,引起了廣泛的關注,并被作為其他云存儲架構的基礎和參照,例如最初由Facebook開發的開源分布式數據庫Cassandra。
EC2
彈性計算云服務(Elastic Compute Cloud,EC2)是AWS的重要組成部分,用于提供大小可調節的計算容量[13]。它為用戶提供了許多非常有價值的特性,包括低成本、靈活性、安全性、易用性和容錯性等[8]。借助Amazon EC2,用戶可以在不需要硬件投入的情況下,快速開發和部署應用程序,并方便地配置和管理。
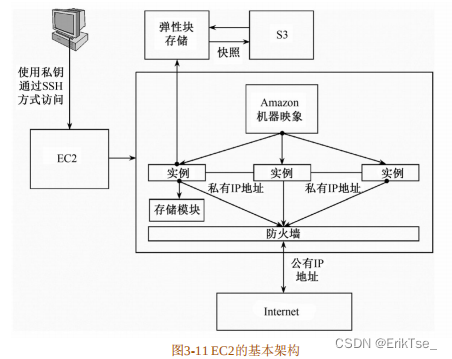
EC2的關鍵技術有:
1.地理區域和可用區域
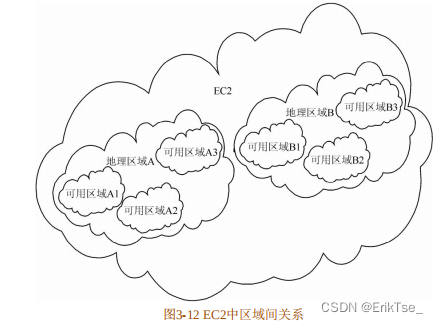
AWS中采用了兩種區域[13](Zone):地理區域(Region Zone)和可用區域(Availability Zone)。其中,地理區域是按照實際的地理位置劃分的。目前,Amazon在全世界共有10個地理區域,包括:美東(北佛吉尼亞)、美西(俄勒岡)、美西(北加利佛尼亞)、歐洲(愛爾蘭)、亞太(新加坡)、亞太(東京)、亞太(悉尼)、南美(圣保羅)、美西服務政府的GovCloud區域和中國(北京)區域。而可用區域的劃分則是根據是否有獨立的供電系統和冷卻系統等,這樣某個可用區域的供電或冷卻系統錯誤就不會影響到其他可用區域,通常將每個數據中心看做一個可用區域。圖3-12展示了兩者之間的關系。EC2系統中包含多個地理區域,而每個地理區域中又包含多個可用區域。為了確保系統的穩定性,用戶最好將自己的多個實例分布在不同的可用區域和地理區域中。這樣在某個區域出現問題時可以用別的實例代替,最大限度地保證了用戶利益。
2.EC2的通信機制
在EC2服務中,系統各模塊之間及系統和外界之間的信息交互是通過IP地址進行的。EC2中的IP地址包括三大類:公共IP地址[13](Public IP Address)、私有IP地址[13](Private IP Address)及彈性IP地址[13](Elastic IP Address)。EC2的實例一旦被創建就會動態地分配兩個IP地址,即公共IP地址和私有IP地址。公共IP地址和私有IP地址之間通過網絡地址轉換(Network Address Translation,NAT)技術實現相互之間的轉換。公共IP地址和特定的實例相對應,在某個實例終結或被彈性IP地址替代之前,公共IP地址會一直存在,實例通過這個公共IP地址和外界進行通信。私有IP地址也和某個特定的實例相對應,它由動態主機配置協議(DHCP)分配產生。
3.彈性負載平衡(Elastic Load Balancing)
彈性負載平衡功能允許EC2實例自動分發應用流量,從而保證工作負載不會超過現有能力,并且在一定程度上支持容錯。彈性載平衡功能可以識別出應用實例的狀態,當一個應用運行不佳時,它會自動將流量路由到狀態較好的實例資源上,直到前者恢正常才會重新分配流量到其實例上。
4.監控服務(CloudWatch)
Amazon CloudWatch提供了AWS資源的可視化監測功能,包括EC2實例狀態、資源利用率、需求狀況、CPU利用率、磁盤讀取、寫入和網絡流量等指標。使用CloudWatch時,用戶只需要選擇EC2實例,設定監視時間,CloudWatch就可以自動收集和存儲監測數據。用戶可以通過AWS服務管理控制臺或命令行工具來維護和處理這些監測數據。
5.自動縮放(AutoScaling)
自動縮放可以按照用戶自定義的條件,自動調整EC2的計算能力。在需求高峰期時,該功能可以確保EC2實例的處理能力無縫增大;在需求下降時,自動縮小EC2實例規模以降低成本。自動縮放功能特別適合周期性變化的應用程序,它由CloudWatch自動啟動。
6.服務管理控制臺(AWS Management Console)
服務管理控制臺是一種基于Web的控制環境,可用于啟動、管理EC2實例和提供各種管理工具和API接口。圖3-13展示了各項技術通過互相配合來實現EC2的可擴展性和可靠性

分析(補充篇)(附MATLAB、R語言和python代碼實現))








)


)


![[職場] 美術指導的重要作用 #學習方法#筆記](http://pic.xiahunao.cn/[職場] 美術指導的重要作用 #學習方法#筆記)


