小羅碎碎念
今天要分享的文獻主題,大家一定非常熟悉,因為絕大多數AI4cancer的文章都會提到它——預后預測,所以今天的文獻主題是——人工智能+腫瘤預后預測。

在正式開始分享之前,我想先帶著大家梳理兩個問題。解決了以下兩個問題以后,你會對今天推文有更深刻的認知。
問題梳理
問題1:腫瘤預后具體指什么
腫瘤預后是指根據臨床經驗預測的腫瘤發展情況,它涉及對腫瘤的臨床表現、化驗及影像學、病因、病理、病情規律等方面的了解,并結合治療時機和方法,以及治療過程中發現的新情況,對腫瘤的近期和遠期療效、轉歸恢復或進展程度的評估。
預后的好壞與多種因素有關,包括患者的治療時機、疾病的嚴重程度、醫學水平、合并疾病、醫生的個人能力、患者的體質、年齡、對疾病的認知能力以及是否繼續治療等。這些因素即使在接受相同治療的情況下,也導致預后出現很大的差異。
問題2:腫瘤預后療效指標有哪些
腫瘤預后療效指標主要包括以下幾類:
-
總生存期(Overall Survival, OS):從隨機分組開始至患者因任何原因死亡的時間。OS被認為是腫瘤臨床試驗中最佳的療效終點,因為它直接反映了患者的生死情況。
-
客觀緩解率(Objective Response Rate, ORR):腫瘤體積縮小達到預先規定值并能維持一定時間的患者比例,通常包括完全緩解和部分緩解的比例之和。
-
無進展生存期(Progression-free Survival, PFS):從隨機分組開始到腫瘤發生進展或任何原因死亡之間的時間。PFS能較早地反映治療效果,并且隨訪時間較短。
-
疾病進展時間(Time to Progress, TTP):從隨機分組開始到腫瘤發生進展的時間。TTP主要關注腫瘤的惡化情況,不包括死亡。
-
無病生存期(Disease-free Survival, DFS):從隨機分組開始至疾病復發或任何原因死亡之間的時間。DFS常用于根治性手術或放療后的輔助治療研究。
-
治療失敗時間(Time to Treatment Failure, TTF):從隨機分組開始至退出試驗的時間,退出原因包括患者拒絕、疾病進展、患者死亡或不良事件等。
-
緩解持續時間(Duration of Response, DoR):從腫瘤第一次評估為緩解開始到第一次評估為疾病進展或死亡的時間。
-
疾病控制時間(Duration of Disease Control, DDC):從腫瘤第一次評估為CR、PR或SD開始到第一次評估為PD或死亡的時間。
-
疾病控制率(Disease Control Rate, DCR):腫瘤縮小或穩定且保持一定時間的患者比例,包括CR、PR和SD的患者。
-
臨床獲益率(Clinical Benefit Rate, CBR):達到CR、PR或SD的患者比例。
-
患者報告結果(Patient Reported Outcome, PRO):包括健康相關生活質量、健康狀態測量工具、患者滿意度和治療體驗、心理困擾、疼痛和自我效能評價等。
-
免疫評分(Immunoscore):基于腫瘤微環境中免疫細胞的浸潤程度和類型的評分系統,用于評估腫瘤患者的預后及治療療效。
這些指標可以幫助醫生和研究人員評估腫瘤治療的效果,并為患者提供個性化的治療建議。
一、nnU-Net自動分割經激光間質熱療(LITT)治療的對比增強病變體積

文獻概述
這篇文章是關于使用
深度卷積神經網絡自動分割經激光間質熱療(LITT)治療的腦內病變的研究。
LITT是一種治療顱內腫瘤或放射壞死的方法,它允許組織診斷、細胞減量和快速恢復系統治療。
治療后,消融組織保留在原位,導致特征性的LITT后水腫,這與臨床狀況暫時惡化有關,并使LITT后反應評估復雜化。
研究方法包括:
- 訓練一個基于
nnU-Net的自動分割模型,用于在T1加權圖像上自動分割LITT治療病變的對比增強病變體積(CeLV)。 - 對2015至2023年間在單一中心接受LITT治療的腫瘤或放射壞死患者進行
回顧性研究,這些患者至少有9個月的MRI隨訪。
研究結果顯示:
- 分析了
61個LITT治療病變的384個獨特的MRI檢查和6個醫學管理的放射壞死對照病例。 - 自動分割在367/384(95.6%)的圖像中準確。
- CeLV在LITT后1至3個月增加到中位數68.3%(四分位間距35.1-109.2%),之后恢復到基線。
- LITT治療患者的
總生存期(OS)為39.1(9.2-93.4)個月。 體積進展定義為從體積最低點或基線增加超過40%,56名患者中有21名(37.5%)經歷了進展,體積進展無生存期為21.4(6.0-93.4)個月。- 有體積進展的患者OS較差(17.3個月對比62.1個月,P=0.0015)。
研究結論:
- LITT后的CeLV擴張是可量化的,并在LITT后6個月內解決。
- 為LITT治療病變開發反應評估標準是可行的,并且應該被考慮用于臨床試驗。
- 自動病變分割可以加速在臨床實踐中采用體積反應標準。
研究的重要性在于,LITT作為神經腫瘤學中一個重要的治療選擇,目前尚無標準化的反應評估標準。
本文通過訓練深度卷積神經網絡來分割多種LITT治療病變類型,使用對比增強體積的測量來描述消融病變的典型過程,并證明這些體積測量可以作為確定疾病進展的基礎,應用一組可以在臨床試驗中使用的標準化反應評估標準。
重點關注
深度學習算法在自動分割過程中由于不同原因導致的分割不準確的例子。
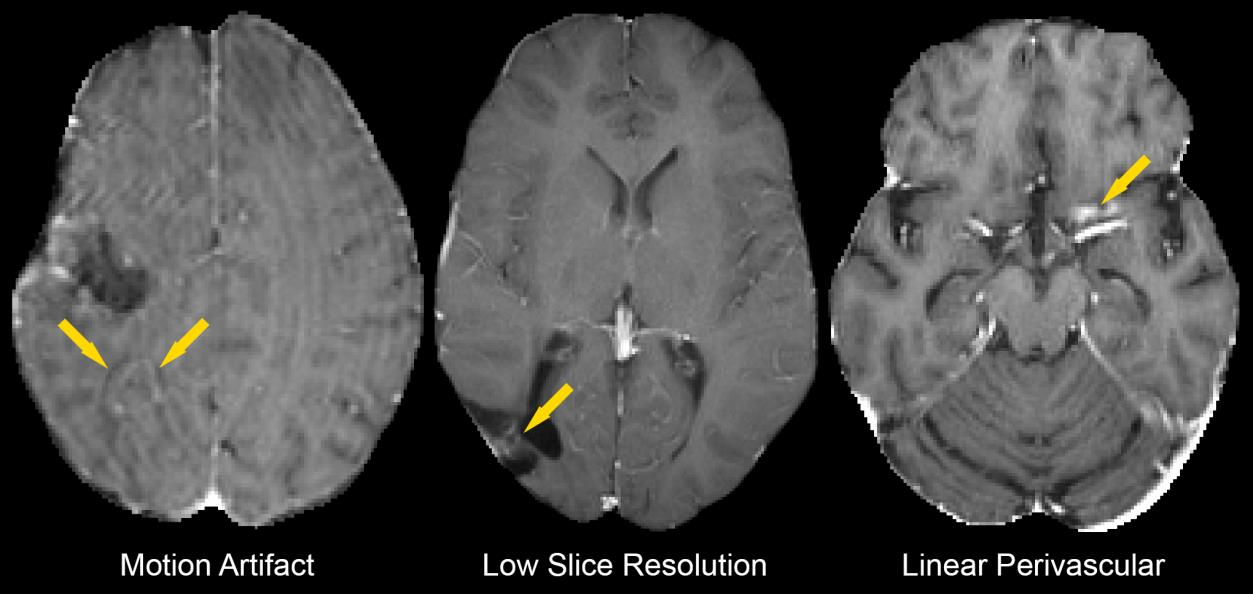
這些例子包括了對比增強的T1加權磁共振成像(MRI)圖片,它們分別展示了由于以下原因造成的分割錯誤:
-
運動偽影(Motion Artifact):左側的圖片顯示了由于患者在成像過程中移動導致成像模糊,這使得深度學習算法難以準確識別和分割病變區域。
-
層厚分辨率低(Low Slice Resolution):中間的圖片指出了層厚分辨率不足的問題,即圖像的層間距過大(例如≥5毫米),這導致病變的細節信息丟失,使得算法難以精確地識別病變的邊界。
-
線性血管周圍增強(Linear Perivascular Enhancement):右側的圖片展示了血管周圍線性增強的情況,這被錯誤地識別為病變的一部分,導致分割結果不準確。
這些例子說明了自動分割算法在實際應用中遇到的挑戰,尤其是在面對圖像質量問題時。
研究中提到,在384次掃描中,有17次(4.4%)的分割被認為是潛在不準確的,其中這些情況占據了一部分。
這表明盡管深度學習算法在大多數情況下可以提供準確的分割,但在特定情況下仍需要人工審核或進一步的技術改進來提高分割的準確性。
二、AI揭示【體成分】與接受免疫治療的晚期/轉移性NSCLC患者的腫瘤學結果之間的關聯

文獻概述
這篇文章是一項關于接受
免疫治療的晚期非小細胞肺癌(NSCLC)患者的體成分(BC)與腫瘤學結果之間關系的多隊列分析研究。
研究的目的是評估體成分與接受免疫治療的晚期或轉移性NSCLC患者的腫瘤學結果之間的關聯。
使用深度神經網絡自動選擇L3層并進行體腔分割(骨骼肌[SM]、皮下脂肪組織[SAT]和內臟脂肪組織),比較基于基線BC測量或在第一次隨訪掃描時的變化的結果。數據分析時間為2022年7月至2023年4月。
研究結果顯示,骨骼肌質量的減少(通過L3 SM區域的變化指示)與跨患者組的更差腫瘤學結果相關。這種關聯在男性患者中最顯著,在MYSTIC試驗和DFBCC-CIO隊列的女性患者中無顯著關聯。
此外,皮下脂肪組織密度的增加(通過皮下脂肪組織間隔的平均CT衰減量化)與3個患者組的較差總生存期(OS)相關。這種變化主要在女性患者中觀察到。
研究的結論
多隊列研究表明,在NSCLC的系統治療期間骨骼肌質量的減少是一個不良結果的標志,特別是在男性患者中。
皮下脂肪組織密度的變化也與預后相關,特別是在接受免疫檢查點抑制劑治療的女性患者中。自動化的CT衍生的BC測量應考慮在確定NSCLC預后時。
文章還討論了體成分作為各種癌癥潛在預后標志物的研究背景,以及在早期NSCLC治療中基于影像的BC測量的效用。
此外,文章還提到了研究的限制,包括回顧性設計、患者群體的異質性以及深度學習管道的樣本量小等問題,并指出需要進一步的研究來闡明這些關聯背后的機制。
重點關注
在這項研究中,模型的工作流程和研究人群的構成如下:
A. 模型實施的工作流程:
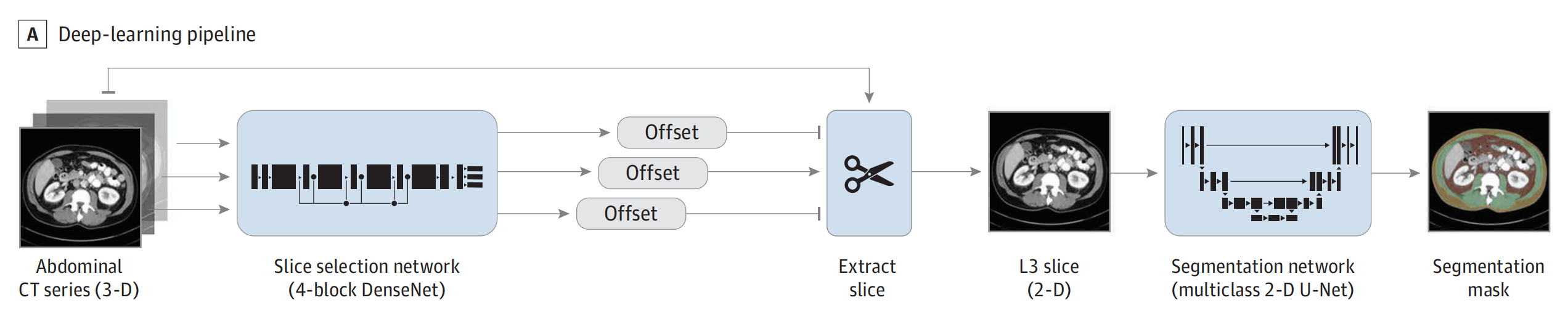
- 實驗中實施了一個深度學習管道,用于自動處理和分析體成分數據。
- 這個管道包括兩個深度學習模型,它們在隔離的容器中運行,使用Python 3.7.3、Ubuntu 18.04操作系統、CUDA 10.0和cuDNN 7.4.2環境。
- 模型的開發和實施發生在2020年至2023年之間,并且模型和相關代碼在GitHub上公開可用,也集成到了開源的modelhub.ai平臺。
B. 研究人群:
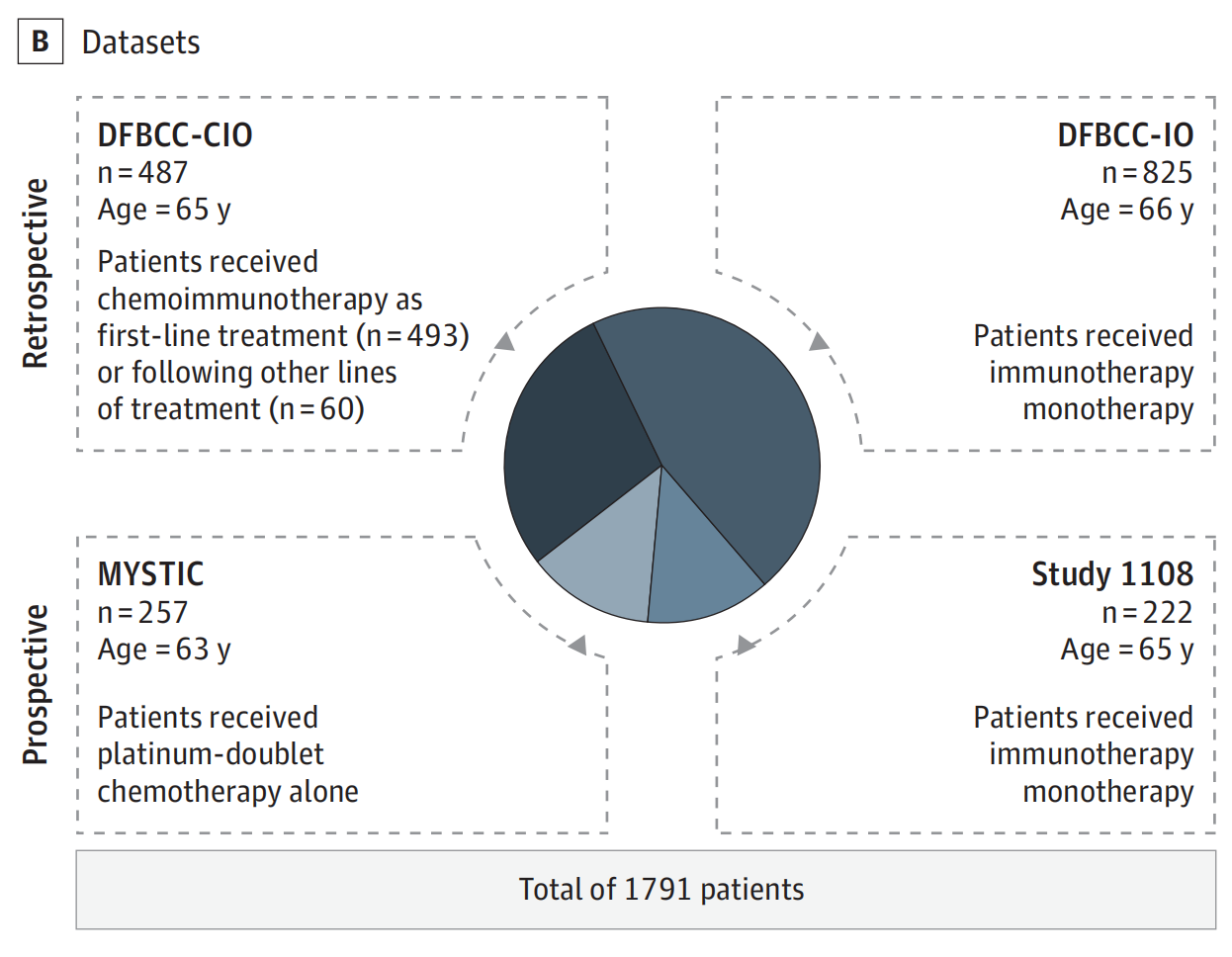
- 研究人群包括來自Dana-Farber Brigham癌癥中心(DFBCC)的兩個回顧性隊列,分別是接受
化療免疫療法(CIO)和免疫檢查點抑制劑單藥治療(IO)的患者。 - 還包括來自1108研究和MYSTIC試驗的前瞻性收集的臨床試驗數據。
C. 體成分分析:
- 在基線和隨訪掃描時對體成分進行了分析。
- 使用自動化的深度學習管道從CT圖像中提取體成分測量數據,包括骨骼肌(SM)、皮下脂肪組織(SAT)和內臟脂肪組織(VAT)。
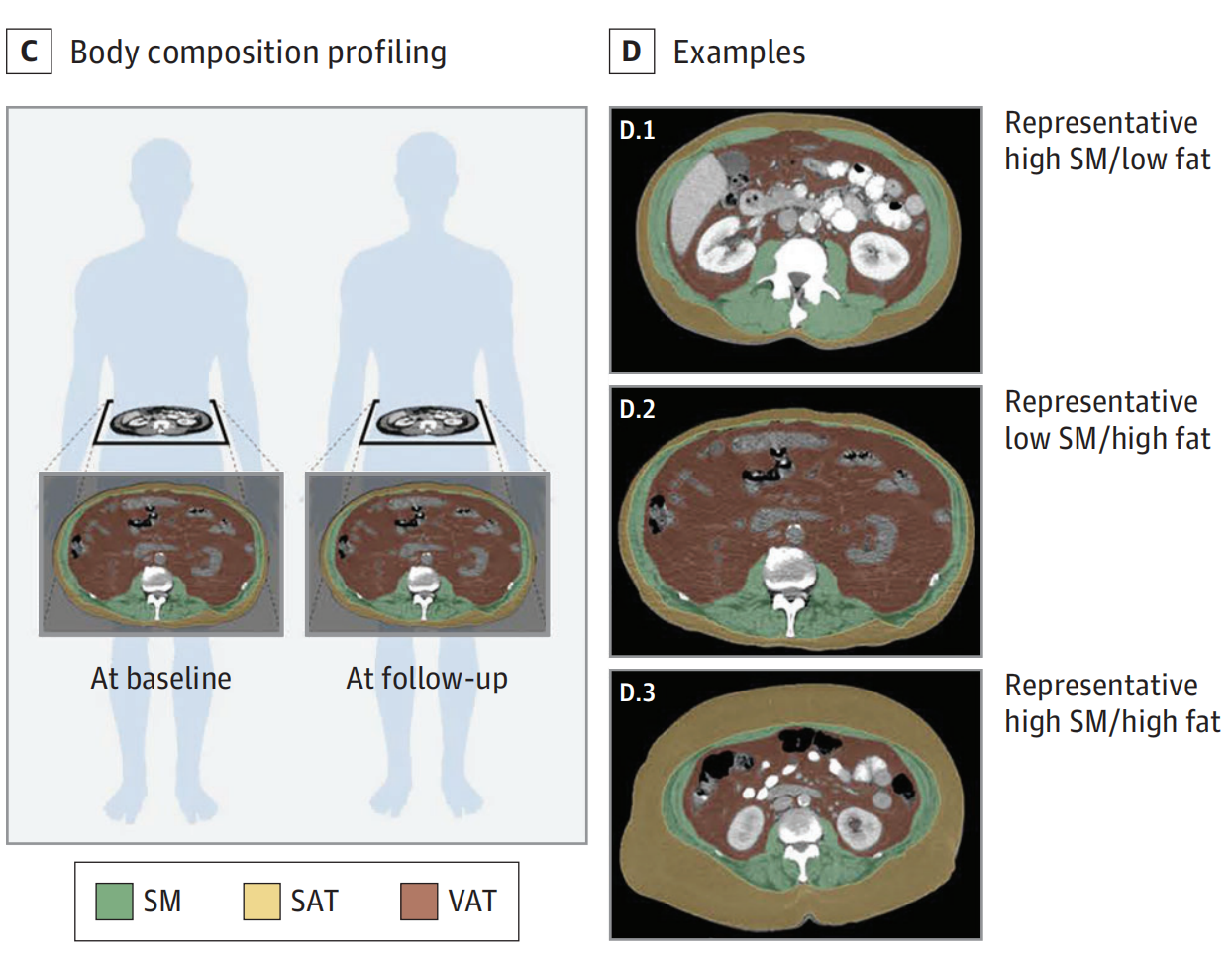
D. 模型輸出示例:
- 模型的輸出展示了不同體成分分布的代表性圖像。
- 黃色代表皮下
脂肪組織(SAT)。 - 綠色代表
骨骼肌(SM)。 - 棕色代表
內臟脂肪組織(VAT)。
- 黃色代表皮下
- 展示了三種不同的體成分分布情況:
- 高SM/低脂肪分布。
- 低SM/高脂肪分布。
- 高SM/高脂肪分布。
- D.2和D.3面板還分別描繪了具有高VAT和高SAT的個體,從而展示了這兩種不同的體成分表型。
2-D和3-D的說明:
- 2-D表示二維,指的是在單個CT圖像層面上的分析。
- 3-D表示三維,涉及到整個體成分分析的三維重建或評估。
CT的說明:
- CT指的是計算機斷層掃描,這是一種醫學成像技術,用于獲取患者身體內部結構的詳細圖像,以便于進行體成分分析。
總體而言,這項研究使用了先進的深度學習技術來自動化地從CT圖像中分析和量化晚期非小細胞肺癌患者的體成分,以評估其與腫瘤學結果之間的關聯。
三、AI賦能基于擴散和灌注的MRI,提高對膠質母細胞瘤患者生存率的預測準確性

文獻概述
這篇文章標題為“Cluster-based prognostication in glioblastoma: Unveiling heterogeneity based on diffusion and perfusion similarities”,由Martha Foltyn-Dumitru等人撰寫,發表在《Neuro-Oncology》雜志上。
研究的主要目的是開發基于擴散和灌注MRI的預后模型,以提高對膠質母細胞瘤(glioblastoma,GB)患者生存率的預測準確性。
研究包括了289名接受了術前多模態MRI成像的膠質母細胞瘤患者。
研究者計算了不同腫瘤區域和整個腫瘤的表觀擴散系數(ADC)、相對腦血容量(nrCBV)和相對腦血流量(rCBF)的平均值。
通過使用基于中心對象的聚類(Partition Around Medoids, PAM)方法,研究者在訓練數據集上識別出了兩種具有顯著不同總生存期(OS)的穩定成像表型。
在獨立測試數據集上的驗證顯示,高風險組的中位OS為10.2個月,而低風險組的中位OS為26.6個月。
研究表明,數據驅動的聚類能夠識別出具有臨床相關性的不同成像表型,突出了擴散和灌注MRI在預測膠質母細胞瘤患者生存率方面的潛在作用。研究還發現,將聚類成員資格納入所有多變量Cox回歸分析中可以提高性能。
研究強調了通過無監督數據驅動方法來解決當前對膠質母細胞瘤的理解和治療中的重要需求,研究結果有助于指導臨床決策,改善預后模型,并最終為膠質母細胞瘤患者帶來更好的管理和治療結果。
重點關注
研究的流程和步驟
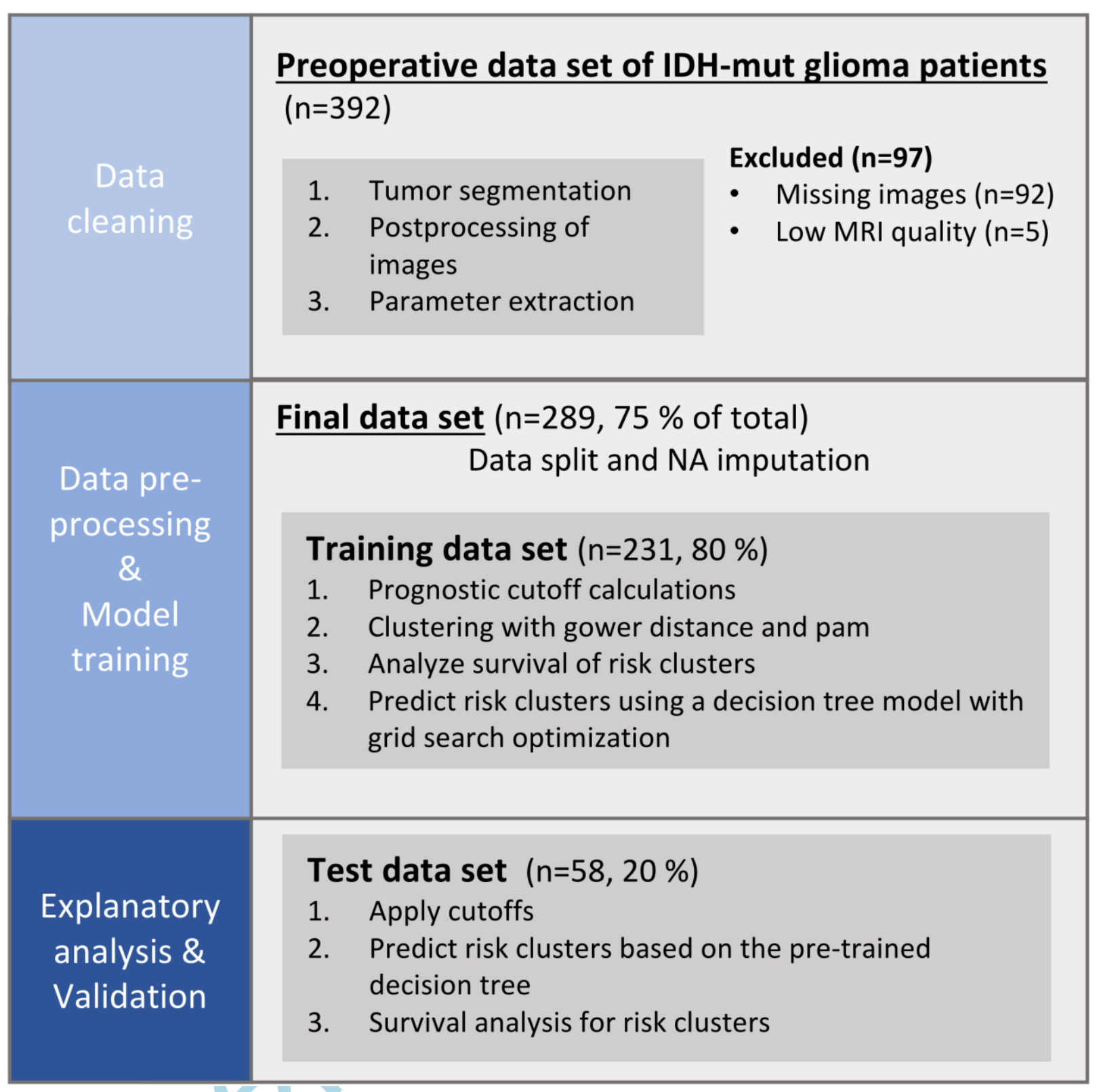
-
數據集劃分:研究開始于將數據集分為兩個主要部分:訓練集和測試集。訓練集用于進行主要的數據分析和模型訓練,而測試集則被保留用于對最終模型進行無偏評估。
-
計算閾值(Cutoffs Calculation):在訓練集上,研究者計算了用于聚類分析的閾值。這些閾值與成像參數(如ADC、nrCBV和rCBF)的特定臨界點有關,用于區分不同的成像表型。
-
聚類(Clustering):使用訓練集數據,研究者應用了聚類算法,特別是PAM聚類,來識別數據中的自然分組或“表型”。這些表型基于擴散和灌注成像的相似性。
-
模型訓練(Model Training):在確定了聚類后,研究者使用訓練集數據來訓練預測模型。這包括機器學習算法,用于預測患者的總生存期。
-
模型評估(Model Evaluation):測試集在模型訓練完成后使用,作為一個獨立的數據集來評估模型的性能。這確保了模型的泛化能力,即在未見過的數據上的表現。
-
無偏評估(Unbiased Evaluation):使用測試集進行的評估旨在提供一個沒有偏見的模型性能度量。這意味著測試集數據在模型訓練過程中沒有被使用,從而避免了過擬合的風險。
整體而言,Figure 1 強調了研究方法的嚴謹性,通過分離數據集來確保研究結果的可靠性和模型的預測能力。
四、AI輔助閱片系統,提升乳腺癌早篩的準確性

文獻概述
研究探討了人工智能(AI)輔助的篩查閱讀技術在提高
乳腺癌早期檢測中的潛在應用。
研究團隊通過前瞻性地在三個階段實施了AI系統:單中心試點、多中心試點和全面實施,以評估AI作為額外閱讀者在標準雙重閱讀過程中的性能。
研究發現,與雙重閱讀相比,AI輔助的額外閱讀過程能夠在每1000個案例中額外檢測到0.7至1.6個癌癥案例,同時只增加0.16%至0.30%的額外召回,0%至0.23%的不必要召回,并且在7%至11%的AI標記案例中增加0.1%至1.9%的陽性預測值(PPV),這相當于增加了4%至6%的總體閱讀工作量。
**AI輔助檢測的大多數癌癥案例為侵襲性(83.3%)且體積較小(≤10 mm,47.0%)。**研究表明,AI作為額外閱讀者可以提高乳腺癌的早期檢測率,并且幾乎不增加不必要的召回。
文章還討論了將AI集成到臨床工作流程中的挑戰,包括確保患者安全、持續性能監測以及與現有臨床流程的整合。
研究結果表明,AI系統可以有效地部署,并在實際臨床工作流程中實現其預測的益處。
研究的局限性包括數據僅來自一個國家的單一乳腺癌篩查機構,且只評估了一個商業AI系統,因此結果不具有普遍性。
盡管如此,這項研究提供了使用AI進行乳腺癌篩查的證據,并展示了其安全部署的具體步驟。
重點關注
AI作為輔助閱讀者的工作流程
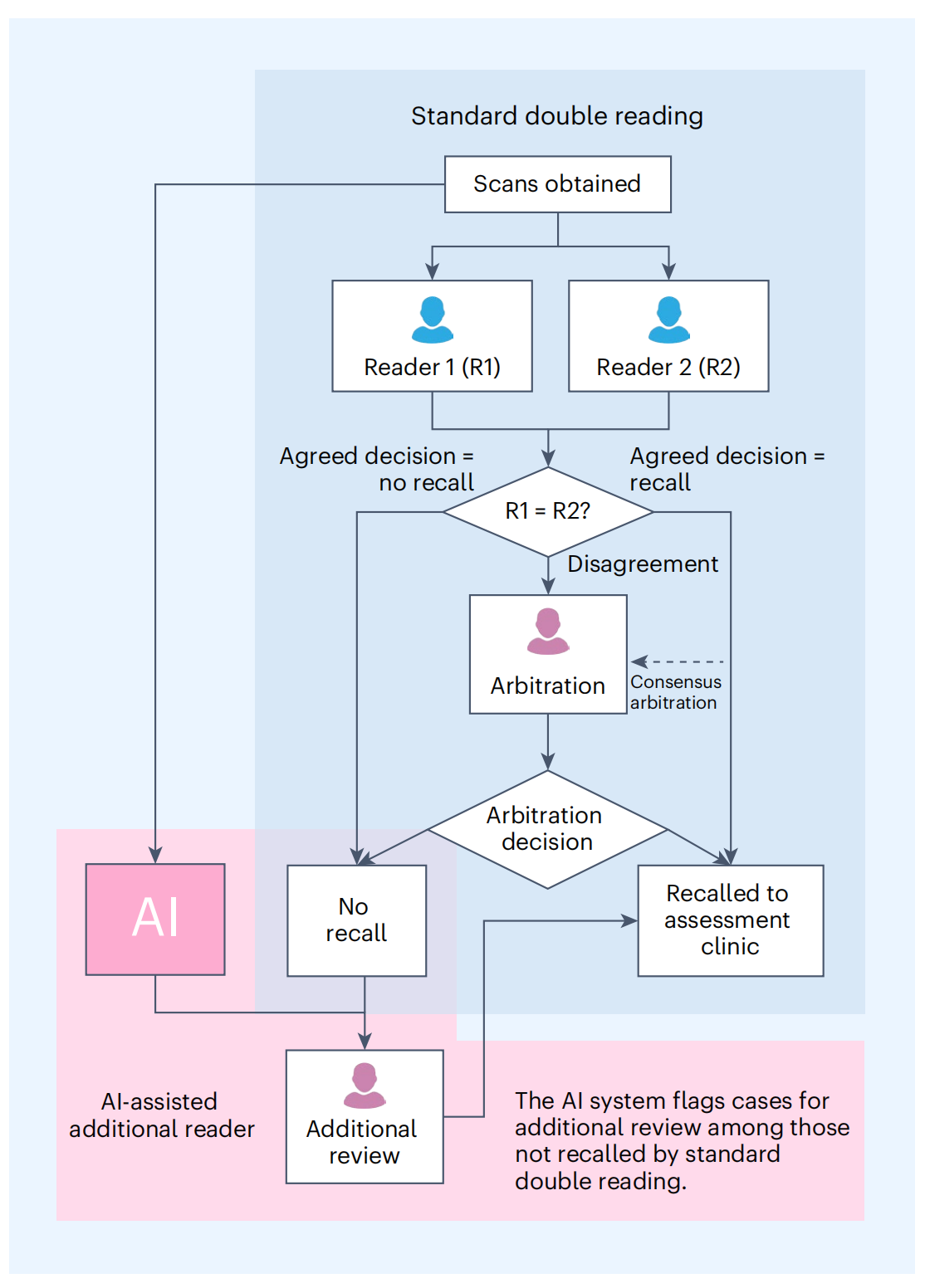
在這個流程中,首先使用標準的雙重閱讀過程來評估乳房X線照片。
雙重閱讀意味著每張乳房X線照片都由兩位放射科醫師獨立評估。如果兩位醫師在評估后達成一致,認為不需要召回(即沒有發現可疑的異常情況),那么這個案例就會被認為是“不召回”。
然而,如果AI系統在雙重閱讀結果為“不召回”的情況下標記了這個案例,表明AI在圖像中發現了的異常,這時就會啟動額外的步驟。
AI系統會標記出圖像中它認為表明惡性腫瘤的區域。然后,這個案例將由另一位經過專業培訓的人類仲裁者(額外的仲裁者)進行獨立評估。這位仲裁者會根據AI系統提供的感興趣區域(regions of interest)來審查圖像,并做出最終的召回決定。
這個流程的目的是利用AI的高敏感性來識別被人類閱讀者遺漏的癌癥案例,從而提高早期檢測乳腺癌的準確性。通過這種方式,AI輔助的額外閱讀者工作流程可以作為一個質量控制的安全網,支持早期癌癥的檢測。
五、基于MRI的放射組學特征在局部復發鼻咽癌患者預后中的潛力

文獻概述
這篇文章我之前仔細分析過,因為就是我們課題組發的文章,感興趣的可以去看精析。
基于MRI的放射組學特征在局部復發鼻咽癌患者預后中的潛力
研究的主要目的是開發一種基于磁共振成像(MRI)的放射組學特征特征,以揭示腫瘤免疫異質性,并預測局部復發鼻咽癌(lrNPC)患者的生存情況。
研究包括921名lrNPC患者,使用機器學習技術基于預處理MRI特征開發了一種用于預測總生存期(OS)的特征,并在兩個獨立隊列中進行了驗證。
研究結果
機器學習特征和列線圖與傳統的臨床列線圖相比具有可比的預后能力,在訓練隊列、內部和外部驗證隊列中分別達到了0.729、0.718和0.731的一致性指數(C-index)。
將特征與臨床變量結合可以顯著提高預測性能。該特征有效地區分了風險組患者,這些患者具有明顯不同的OS率。
通過RNA測序(RNA-seq)分析,探索了特征的生物學特性和免疫浸潤,發現風險組之間在干擾素反應和淋巴細胞浸潤方面存在差異。
研究結論
基于MRI的放射組學特征能更準確地預測OS。提出的與腫瘤免疫異質性相關的特征是一個有價值的工具,有助于促進lrNPC患者的預后分層和指導個體化管理。
關鍵詞包括局部復發鼻咽癌、MRI、放射組學、生存分析。研究由多個中國機構資助,包括國家重點研發計劃、國家自然科學基金等。作者聲明沒有利益沖突,且資助方在研究設計、數據收集、分析、發表決定或手稿準備中沒有作用。
重點關注
放射組學工作流程和生物信息學工作流程

放射組學工作流程(Radiomics workflow):
- 圖像獲取:在四個中國的醫療中心,共識別了921名合格的局部復發鼻咽癌(lrNPC)患者,并且所有患者都接受了預處理的頭部和頸部磁共振成像(MRI)。
- 手動分割:在獲取圖像后進行手動分割,以確定腫瘤的感興趣區域(ROI)。
- 特征提取與放射組學特征構建:基于分割的圖像,提取放射組學特征,并構建放射組學特征。
- 預后模型的開發與驗證:利用這些特征開發預后模型,并通過內部和外部隊列進行驗證。
- 模型性能評估:評估所開發模型的性能。
生物信息學工作流程(Bioinformatics workflow):
- 組織樣本收集:從研究隊列中收集了21個組織樣本。
- RNA測序:這些組織樣本進行了RNA測序(RNA-seq)。
- 生物信息學分析:使用生物信息學工具分析RNA-seq數據,探索不同放射組學特征背后的生物學特性和免疫浸潤情況,以反映lrNPC內部的腫瘤異質性。
在文中還提到了一些特定的術語和縮寫,例如:
- CET1-w:對比增強的T1加權成像。
- CHCAMS:中國醫學科學院腫瘤醫院。
- FUSCC:復旦大學上海癌癥中心。
- LrNPC:局部復發鼻咽癌。
- MRI:磁共振成像。
- NHSMU:南方醫科大學南方醫院。
- SYSUCC:中山大學腫瘤中心。
- T1-w:T1加權成像。
- T2-w:T2加權成像。
整個研究布局強調了多中心合作、綜合利用放射組學和生物信息學方法來提高對局部復發鼻咽癌預后的理解和預測。
六、基于回歸的深度學習方法,從病理切片中預測分子生物標志物

文獻概述
這篇文章討論了一種基于回歸的深度學習方法,用于從病理切片中預測分子生物標志物。
研究團隊開發并評估了一種自監督的、基于注意力機制的弱監督回歸方法,該方法能夠直接從11,671張覆蓋九種癌癥類型的患者圖像中預測連續的生物標志物。
研究發現,使用回歸方法可以顯著提高生物標志物預測的準確性,并且與分類方法相比,能夠更好地對應于已知的臨床相關區域。
在結直腸癌患者的大型隊列中,基于回歸的預測分數比基于分類的分數提供了更高的預后價值。此外,該研究還探討了如何通過數字病理學分析組織樣本來提供有關腫瘤分級、亞型、分期和其他腫瘤生物標志物的信息。
研究結果表明,回歸方法在計算病理學中為連續生物標志物分析提供了一個有希望的替代方案。
文章還提到了數字病理學的發展,以及如何利用深度學習技術從全切片圖像(WSI)中預測基因變化和基因表達模式。
研究團隊通過對比增強的聚類注意力多實例學習(CAMIL)回歸方法與傳統的分類方法進行了系統比較,發現CAMIL回歸方法在多個數據集、器官和生物標志物上的表現優于傳統方法。
此外,文章還討論了回歸方法在預測腫瘤微環境中的關鍵生物過程標志物方面的優勢,包括腫瘤細胞、基質和免疫細胞的相關生物標志物。
研究結果表明,CAMIL回歸方法能夠以高AUROC值預測這些生物標志物,并且在與CAMIL分類方法和Graziani等人提出的回歸方法相比時,表現出更好的性能。
最后,文章還探討了CAMIL回歸方法在預測結直腸癌患者總體生存方面的應用,并發現基于回歸的生物標志物能夠提供更好的預后預測。
研究團隊認為,他們的開源回歸方法為病理學中的連續生物標志物分析提供了一個有希望的替代方案,并對精準醫療產生重要影響。
重點關注
端到端實驗工作流程的概覽——圖像預處理、建模、性能指標評估以及所使用的隊列。
以下是詳細分析:
A. 圖像預處理流程和瓦片級特征提取:
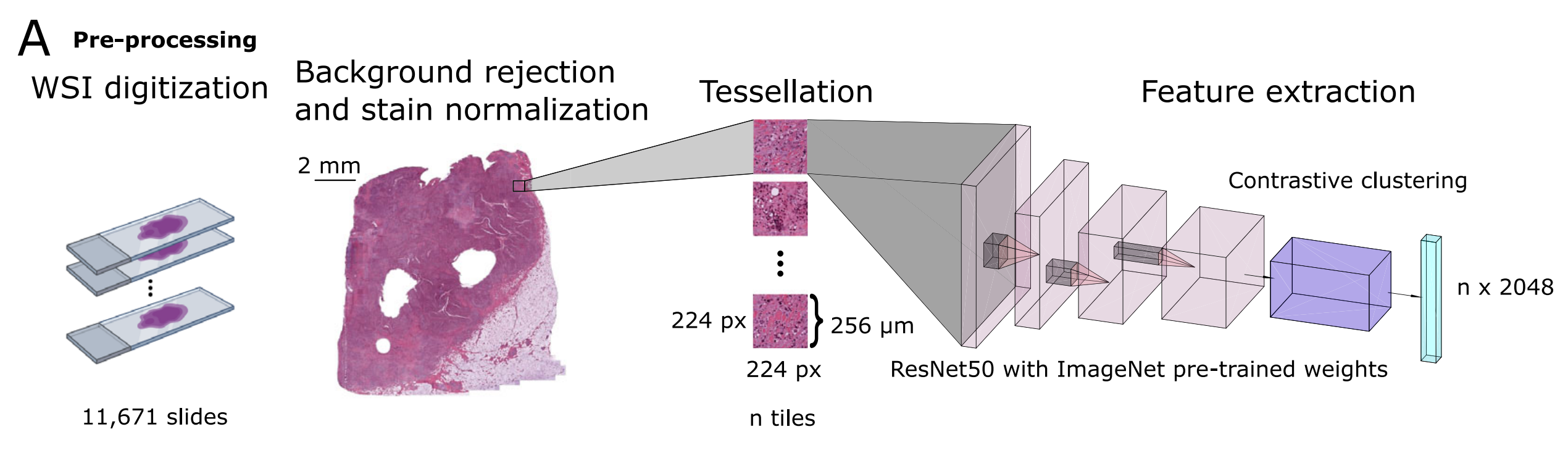
- 使用帶有預訓練的ImageNet權重的
ResNet50模型進行推理,以及檢索對比聚類(RetCCL)模型,為每個患者生成特征矩陣。 - 這一步驟涉及將全切片圖像(WSI)分割成小塊(tiles),并對這些小塊進行處理,以提取可用于后續分析的特征。
B. 建模架構:
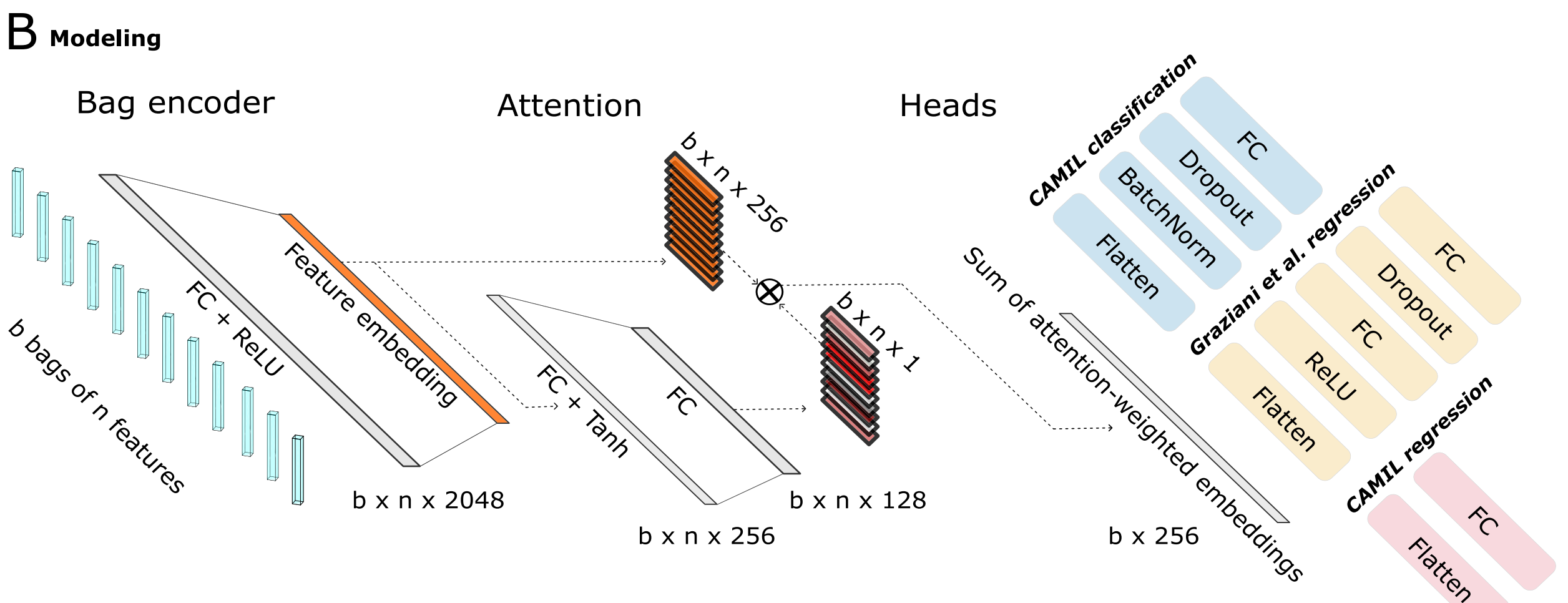
- 利用基于注意力的
多實例學習(attMIL)應用在自監督提取的特征上。 - 該架構包含三個獨立訓練的頭(heads):
- 一個用于CAMIL分類。
- 一個用于回歸,遵循Graziani等人提出的方法。
- 第三個用于本研究介紹的CAMIL回歸方法。
C. 性能指標及其置信區間(CIs):
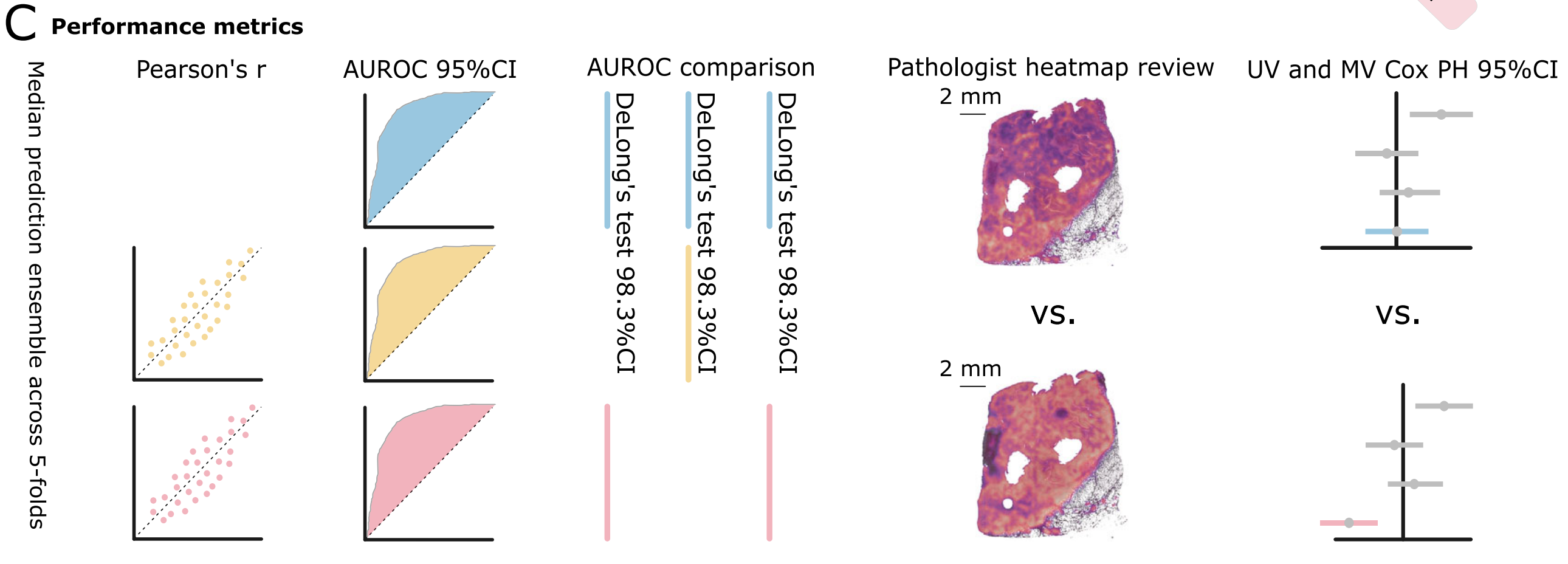
- 評估模型的三個獨立訓練頭的性能指標包括:
- 回歸模型使用皮爾遜相關系數(Pearson’s r)。
- 所有模型使用接收者操作特征曲線下面積(AUROC)。
- 對同源重組缺陷(HRD)和生物過程生物標志物進行了配對雙尾DeLong測試。
- 進行了注意力熱圖的專家評審,以及對生物過程模型進行了單變量(UV)和多變量(MV)Cox比例風險(PH)模型分析。
D. 隊列圖表表示:
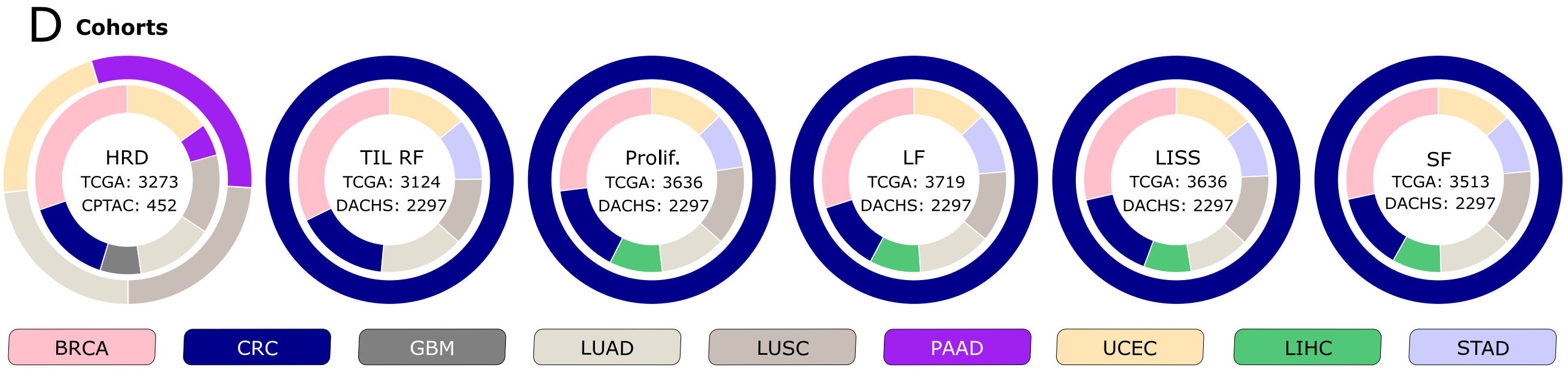
- 展示了本研究中使用的隊列,內外圈分別表示用于訓練和外部驗證的隊列。
- 訓練隊列來源于癌癥基因組圖譜(The Cancer Genome Atlas, TCGA)項目的所有臨床目標。
- 外部驗證隊列來自臨床蛋白質組腫瘤分析聯盟(Clinical Proteomic Tumor Analysis Consortium, CPTAC)的努力,以及Darmkrebs: Chancen der Verhütung durch Screening (DACHS)研究,分別針對HRD目標和生物過程生物標志物。
- 考慮的
生物過程生物標志物包括腫瘤浸潤淋巴細胞區域分數(TIL RF)、增殖(Prolif.)、白細胞分數(LF)、淋巴細胞浸潤特征分數(LISS)和基質分數(SF)。 - 研究中考慮的
癌癥類型包括乳腺癌(BRCA)、結直腸癌(CRC)、膠質母細胞瘤(GBM)、肺腺癌(LUAD)、肺鱗狀細胞癌(LUSC)、胰腺腺癌(PAAD)、子宮內膜癌(UCEC)、肝細胞癌(LIHC)和胃癌(STAD)。
這個流程圖提供了研究方法的清晰視覺表示,從圖像預處理到模型評估,再到使用的隊列,為讀者呈現了研究的全貌。










![[洛谷] 刷題棧 隊列](http://pic.xiahunao.cn/[洛谷] 刷題棧 隊列)








