一、前言
項目中有使用到CUDA計算的相關內容。但是在早期CUDA計算環境搭建的過程中,并不是非常順利,編寫此篇文章記錄下。對于剛剛開始研究的你可能會有一定的幫助。
二、環境搭建
搭建 CUDA 計算環境涉及到幾個關鍵步驟,包括安裝適當的 CUDA 驅動程序和工具包、設置開發環境和編譯器,以及編寫和運行 CUDA 程序。感謝Davis lee詳細的介紹 CUDA安裝及環境配置——最新詳細版以下是一個基本的搭建過程:
步驟 1:檢查硬件兼容性
首先,確保的計算機上的 GPU 支持 CUDA。可以在 NVIDIA 的官方網站上查找 GPU 的型號以確定其是否支持 CUDA。
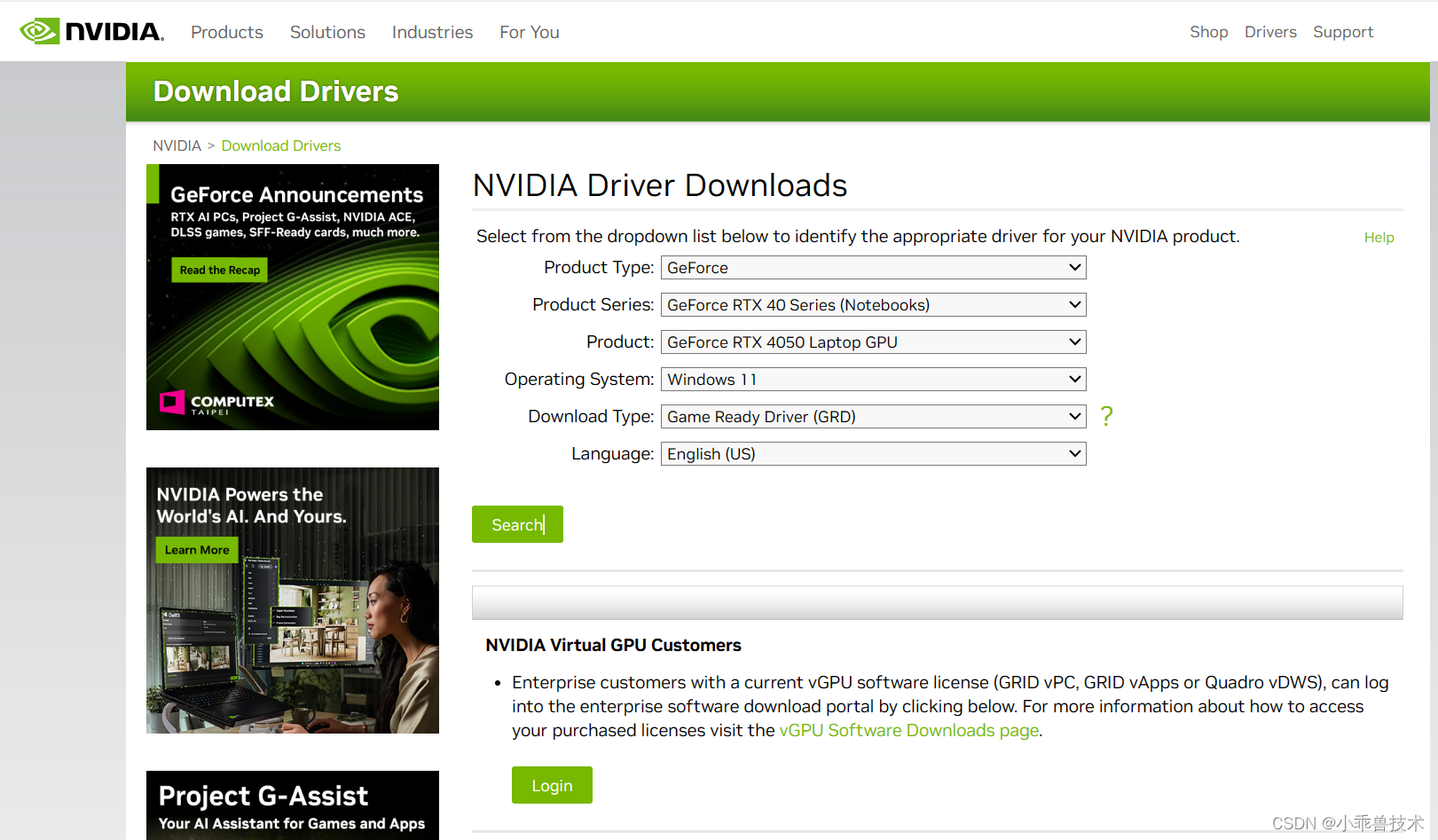
步驟 2:安裝 CUDA 驅動程序
訪問 NVIDIA 的官方網站,下載并安裝與你的 GPU 兼容的最新 CUDA 驅動程序。安裝過程中,根據向導提示進行操作。
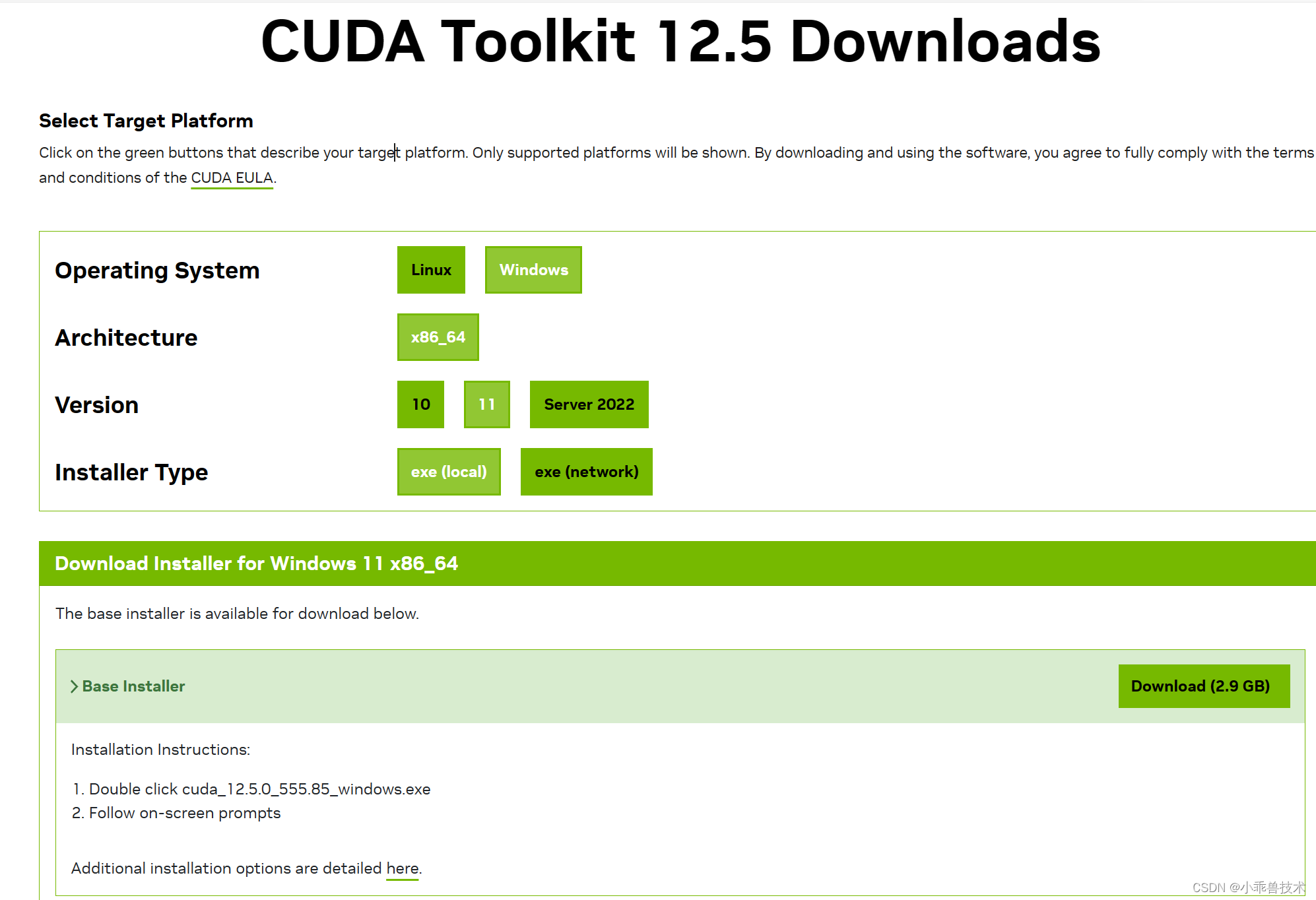
步驟 3:安裝 CUDA 工具包
下載并安裝與你的 CUDA 驅動程序版本相匹配的 CUDA 工具包。CUDA 工具包中包含了編譯器、庫和工具,用于開發和運行 CUDA 程序。
https://developer.nvidia.com/cuda-downloads
步驟 4:安裝適當的開發環境
你可以使用多種開發環境來編寫 CUDA 程序,如 NVIDIA 提供的 CUDA Toolkit 中自帶的 nvcc 編譯器,或者集成了 CUDA 開發支持的 IDE,如 Visual Studio(需要安裝適當的 CUDA 插件)或 JetBrains 的 CLion 等。
步驟 5:設置環境變量
在你的操作系統中設置 CUDA 相關的環境變量,包括 PATH、CUDA_PATH 等,以便系統可以找到 CUDA 工具和庫。
步驟 6:編寫和編譯 CUDA 程序
使用你選擇的開發環境編寫 CUDA 程序,并使用 CUDA 編譯器(如 nvcc)編譯程序。確保您的程序正確地鏈接了 CUDA 庫,并且編譯選項正確設置。
步驟 7:運行 CUDA 程序
將編譯生成的可執行文件部署到你的計算機上,并在 CUDA 支持的環境中運行程序。你可能需要在程序運行時指定相應的 GPU 設備。
總之就是,在搭建時適配自己的電腦配置要求。做到最新即可。
三、實踐編碼過程
新增一個空的解決方案,我們命名為VectorProject.sln。
3.1 使用CUDA編寫動態庫
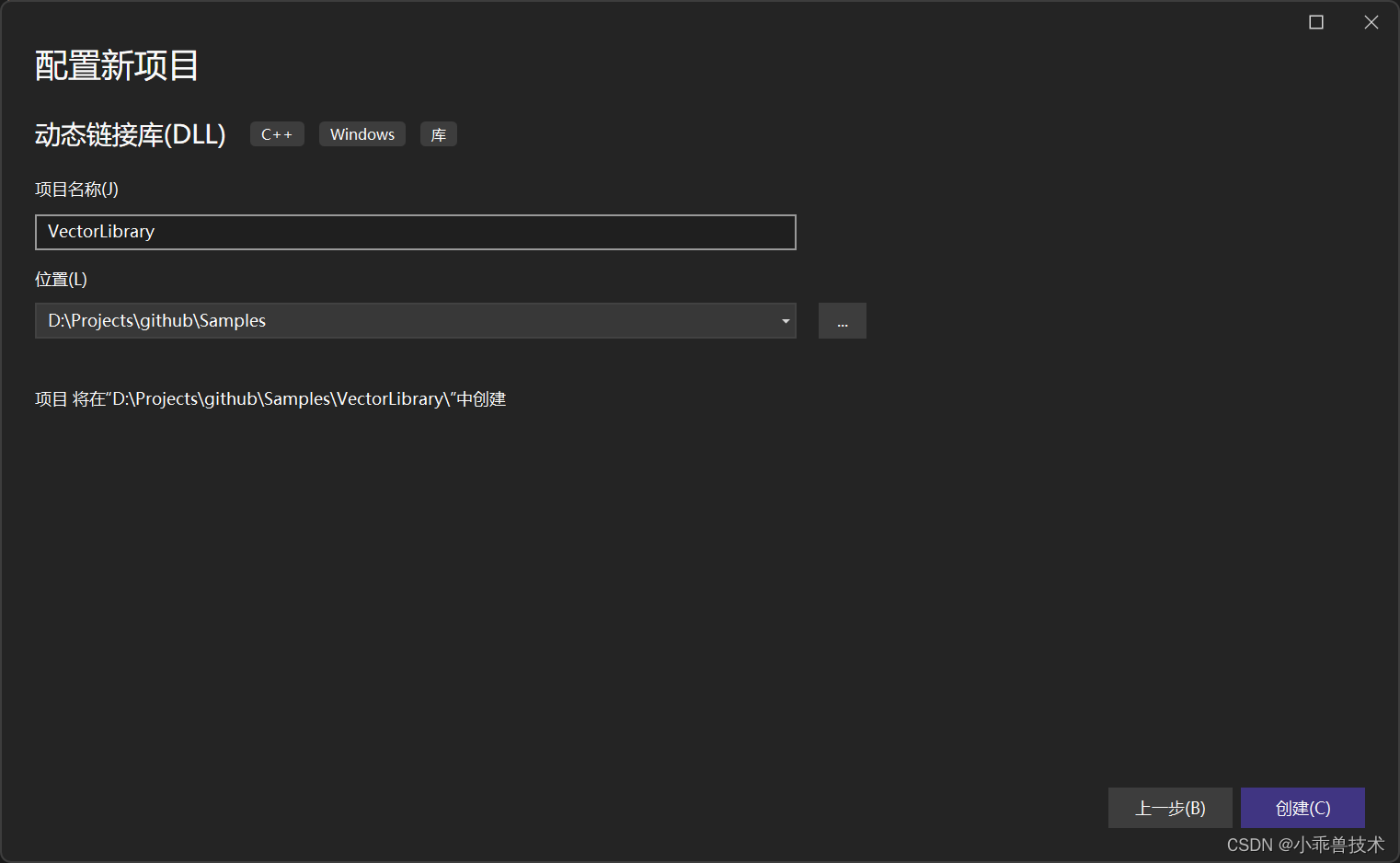
1、新增動態鏈接庫 ,命名為VectorLibrary;
2、配置CUDA編譯環境:
生成依賴項–>生成自定義
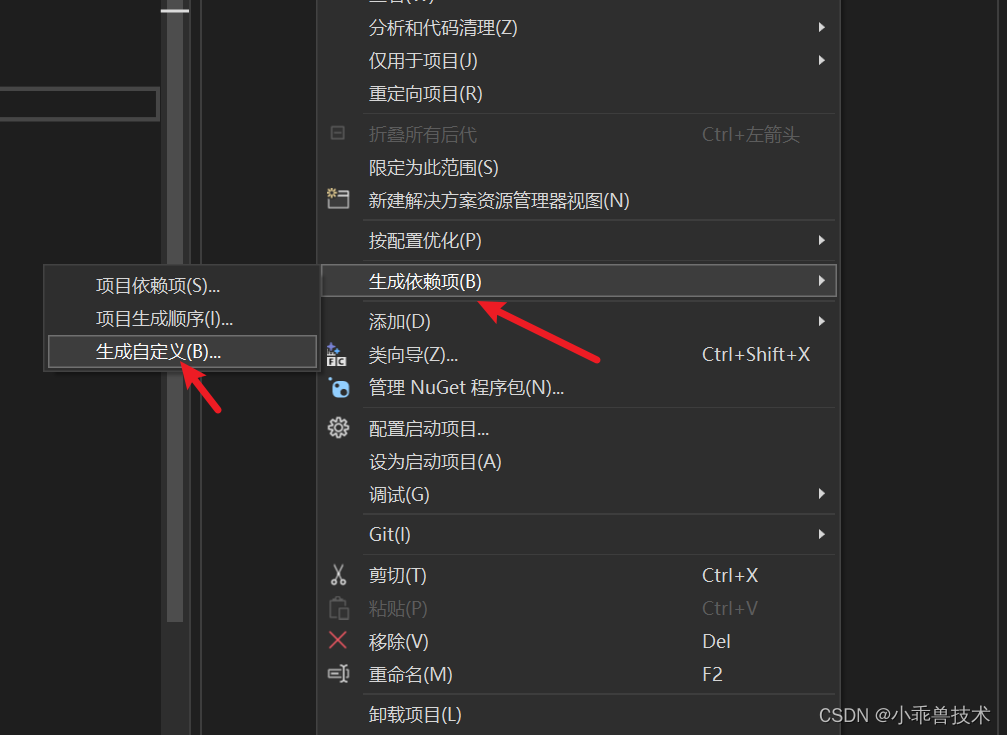
選擇CUDA 12.3(targets,props)
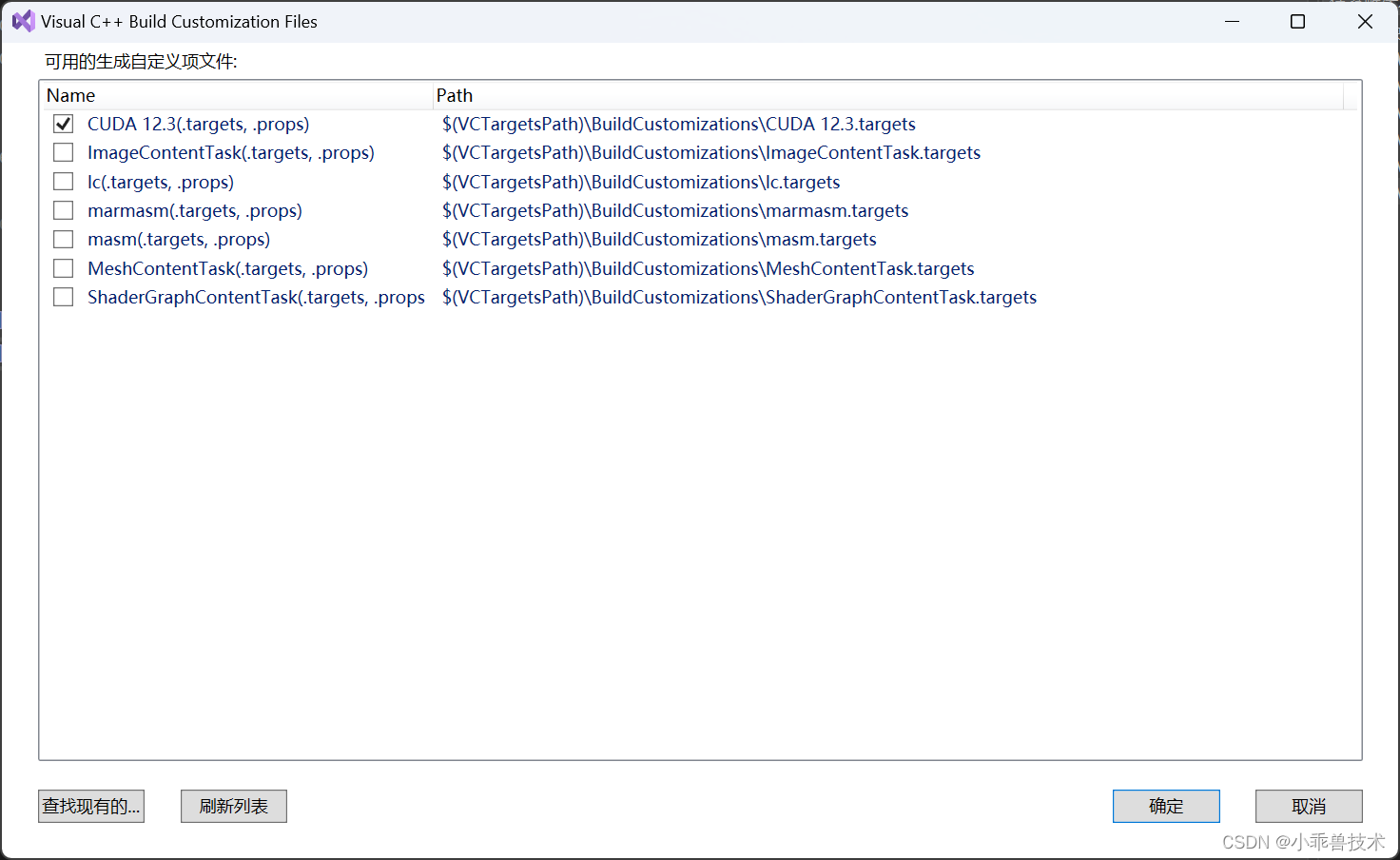
這里如果不配置CUDA編譯環境,會報錯,無法正常編譯通過的。配置完成后,可以查看項目的屬性頁。能看到CUDA C/C++配置部分
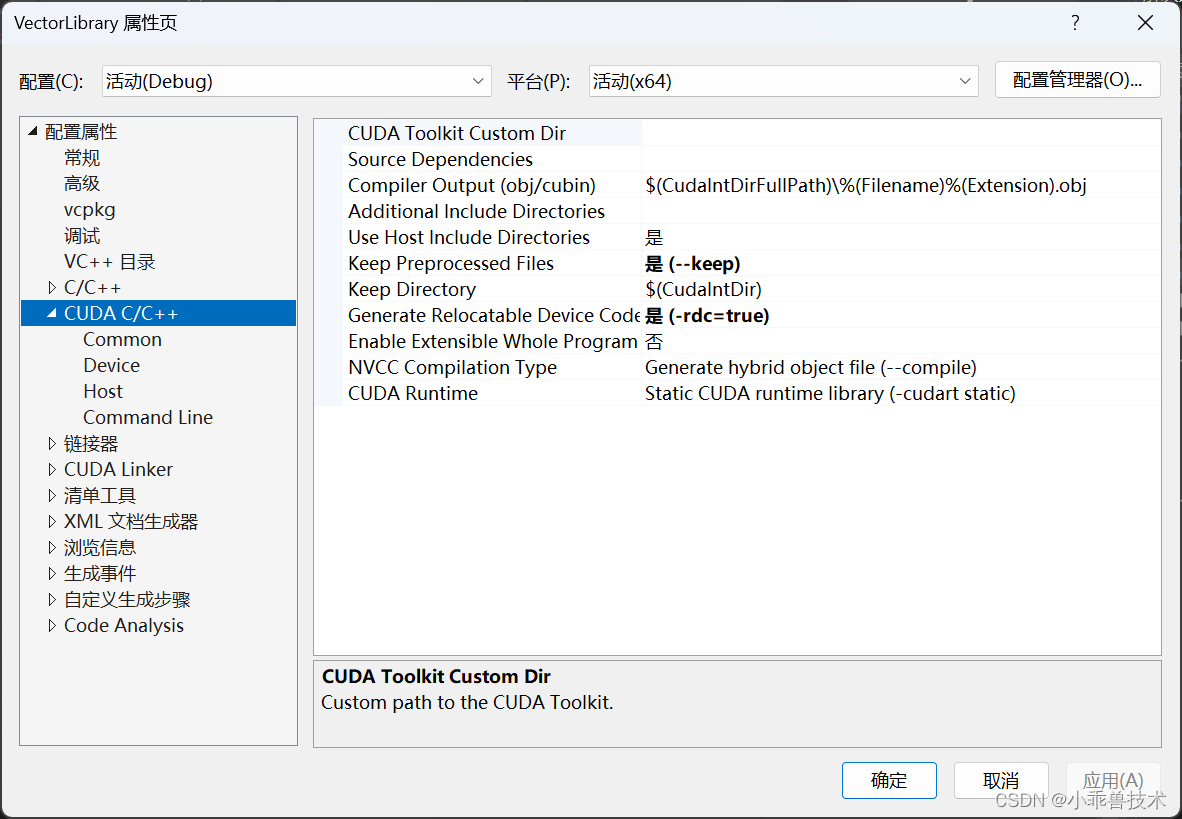
3、編寫接口代碼
這里主要定義兩個向量的加法運算。
#pragma once
#include "pch.h"
#include <Windows.h>#ifdef VECTOR_LIBRARY_EXPORTS
#define VECTOR_LIBRARY_API __declspec(dllexport)
#else
#define VECTOR_LIBRARY_API __declspec(dllimport)
#endifBOOL VECTOR_LIBRARY_API vectorAddCPU(const float* A, const float* B, float* C, int N);
BOOL VECTOR_LIBRARY_API vectorAddGPU(const float* A, const float* B, float* C, int N);
4、編寫CPU方法實現過程
// 封裝CUDA函數的C++代碼
#include "pch.h"
#include "vectorAdd.h"// CPU上的向量加法函數BOOL vectorAddCPU(const float* A, const float* B, float* C, int N)
{for (int i = 0; i < N; ++i) {C[i] = A[i] + B[i];}return true;
}
5、編寫GPU方法實現過程
新增一個核函數聲明文件 kernelVectorAdd.cuh
#include <iostream>
void kernelVectorAdd(const float* A, const float* B, float* C, int N);
編寫核函數實現
#include <cuda_runtime.h>
#include <iostream>
#include <vector>
#include <device_launch_parameters.h>
#include "kernelVectorAdd.cuh"// CUDA核函數:在GPU上執行的向量加法
__global__ void kernelVectorAddImp(const float* A, const float* B, float* C, int N) {int i = blockDim.x * blockIdx.x + threadIdx.x;if (i < N) {C[i] = A[i] + B[i];}
}void kernelVectorAdd(const float* A, const float* B, float* C, int N) {float* d_A, * d_B, * d_C;size_t size = N * sizeof(float);// 分配設備內存cudaMalloc(&d_A, size);cudaMalloc(&d_B, size);cudaMalloc(&d_C, size);// 將數據從主機內存復制到設備內存cudaMemcpy(d_A, A, size, cudaMemcpyHostToDevice);cudaMemcpy(d_B, B, size, cudaMemcpyHostToDevice);// 執行CUDA核函數int threadsPerBlock = 256;int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;kernelVectorAddImp <<<blocksPerGrid, threadsPerBlock >>> (d_A, d_B, d_C, N);// 等待所有CUDA核函數執行完畢cudaDeviceSynchronize();// 將結果從設備內存復制回主機內存cudaMemcpy(C, d_C, size, cudaMemcpyDeviceToHost);// 釋放設備內存cudaFree(d_A);cudaFree(d_B);cudaFree(d_C);
}
在編寫核函數調用的C++代碼
// 封裝CUDA函數的C++代碼
#include "pch.h"
#include "kernelVectorAdd.cuh"
#include "vectorAdd.h"BOOL vectorAddGPU(const float* A, const float* B, float* C, int N) {kernelVectorAdd(A, B, C, N);return true;
}
這里需要把核函數進行封裝,否則會報錯,相關解決辦法可見 關于CUDA C 項目中“ error C2059: 語法錯誤:“<” ”問題的解決方法.
6、現在我們編譯下項目
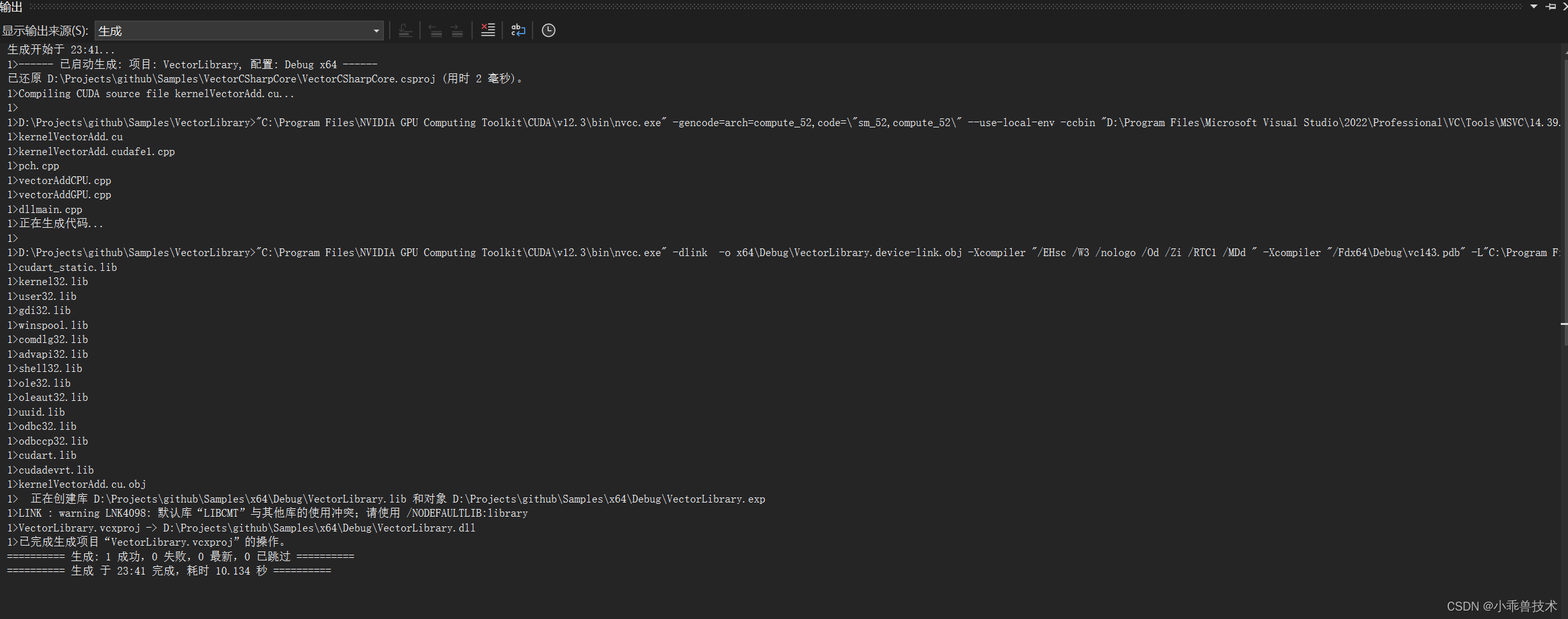
3.2 編寫C++控制臺程序
1、新增C++控制臺程序,VectorCpp
2、配置VectorLibrary.dll的引用
打開屬性頁,找到C/C++目錄,附加包含目錄添加配置
$(SolutionDir)VectorLibrary;
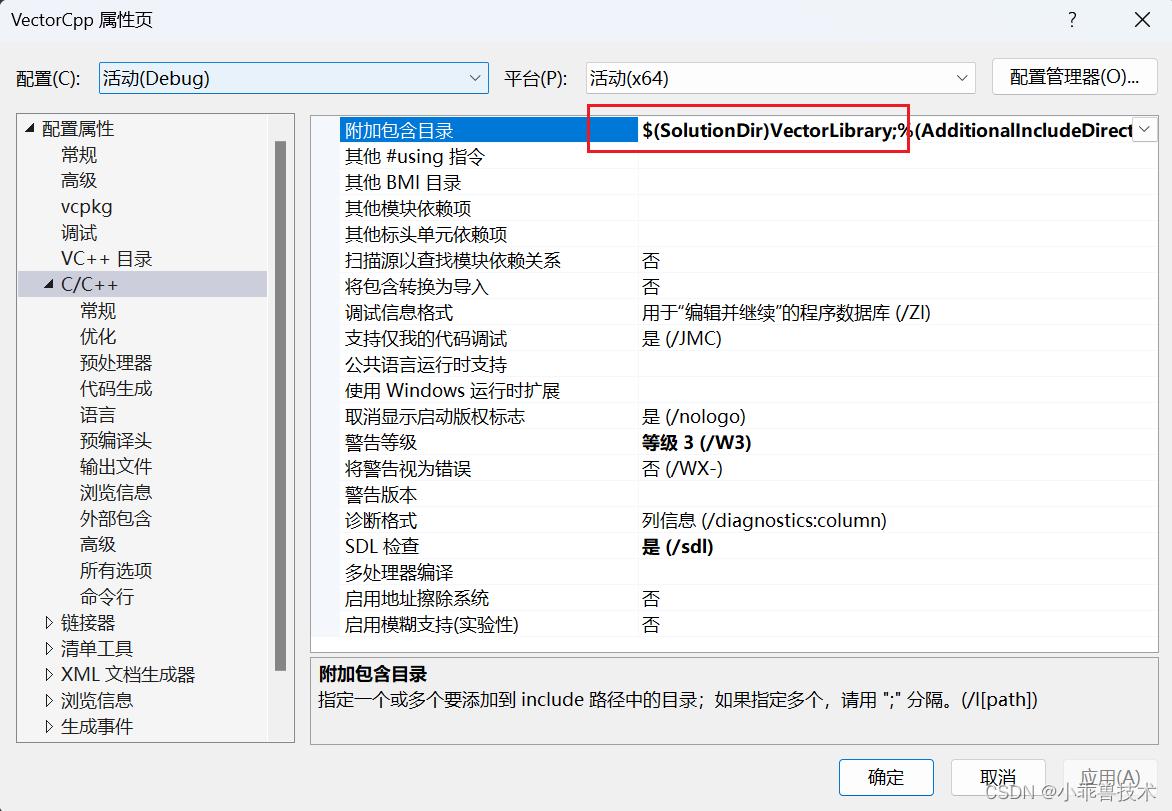
鏈接器–>常規–>附加庫目錄
$(TargetDir);%(AdditionalLibraryDirectories)
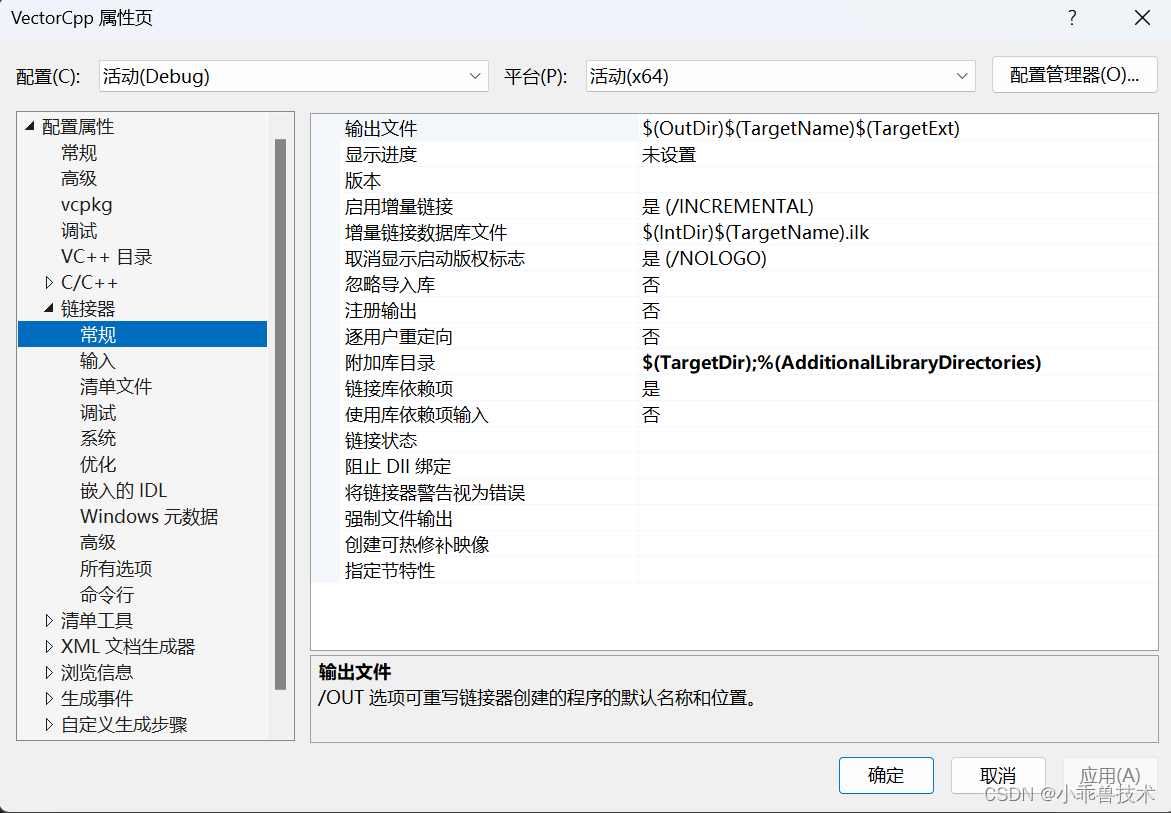
鏈接器–>輸入–>附加依賴項
VectorLibrary.lib;%(AdditionalDependencies)
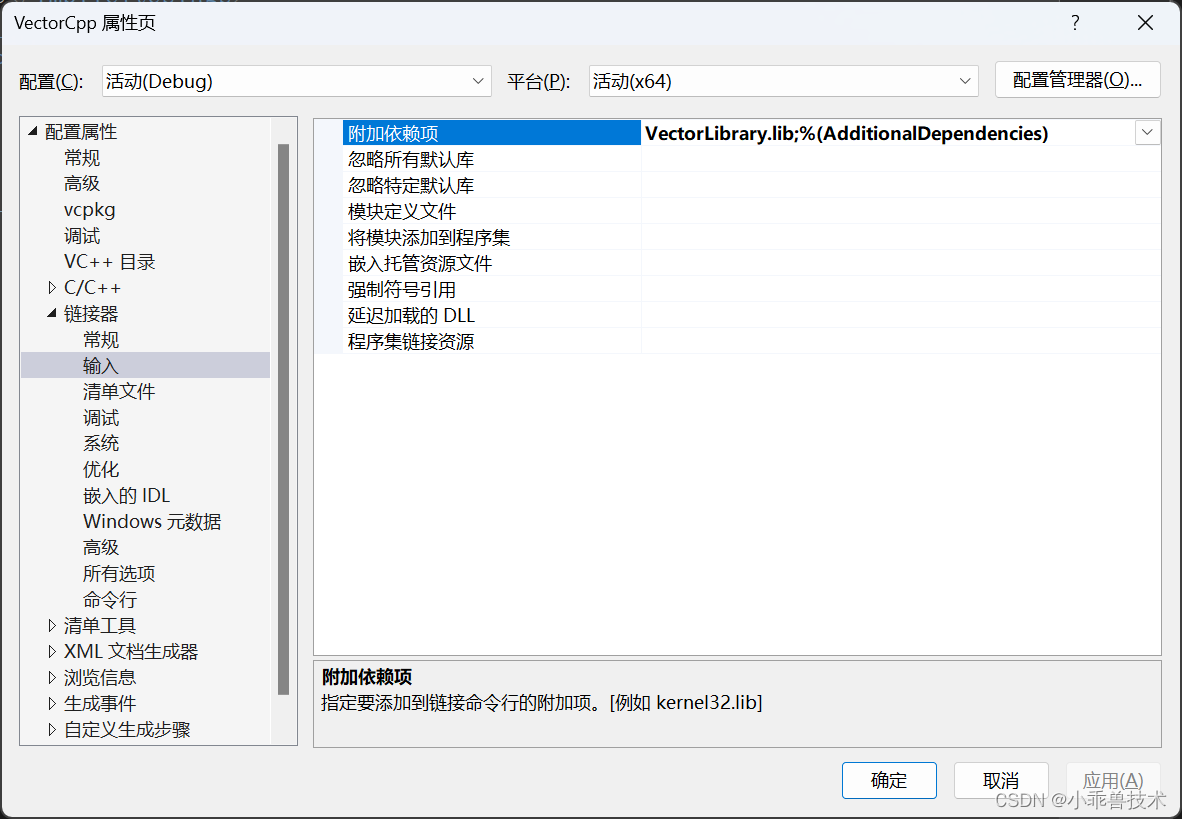
配置完成這些,就可以對VectorLibrary.dll正常引用了。
2、編寫調用代碼
// CudaWrapper.cpp
#include "pch.h"
#include <iostream>
#include <random>
#include <chrono>
#include "vectorAdd.h"// 生成隨機數并填充到數組
void generateRandomNumbers(float* array, int N) {unsigned seed = std::chrono::system_clock::now().time_since_epoch().count();std::default_random_engine generator(seed);std::uniform_real_distribution<float> distribution(0.0, 1.0); // 范圍從0到1之間for (int i = 0; i < N; ++i) {array[i] = distribution(generator);}
}int main()
{int N = 1000000;float* pA = new float[N];float* pB = new float[N];float* pC_GPU = new float[N];float* pC_CPU = new float[N];// 為pA和pB生成隨機數generateRandomNumbers(pA, N);generateRandomNumbers(pB, N);// 測量 CPU 端向量加法函數的執行時間auto start_cpu = std::chrono::high_resolution_clock::now();vectorAddCPU(pA, pB, pC_CPU, N);auto end_cpu = std::chrono::high_resolution_clock::now();std::chrono::duration<double> elapsed_cpu = end_cpu - start_cpu;std::cout << "CPU 端向量加法函數的執行時間: " << elapsed_cpu.count() << " 秒" << std::endl;// 測量 GPU 端向量加法函數的執行時間auto start_gpu = std::chrono::high_resolution_clock::now();vectorAddGPU(pA, pB, pC_GPU, N);auto end_gpu = std::chrono::high_resolution_clock::now();std::chrono::duration<double> elapsed_gpu = end_gpu - start_gpu;std::cout << "GPU 端向量加法函數的執行時間: " << elapsed_gpu.count() << " 秒" << std::endl;// 驗證結果for (int i = 0; i < N; ++i){if ((pC_CPU[i] - pC_GPU[i]) > 1e-5){std::cout << "結果不匹配" << std::endl;break;}}std::cout << "結果匹配" << std::endl;// 記得釋放內存delete[] pA;delete[] pB;delete[] pC_CPU;delete[] pC_GPU;return 0;
}
3、運行程序
完整的項目結構
運行結果
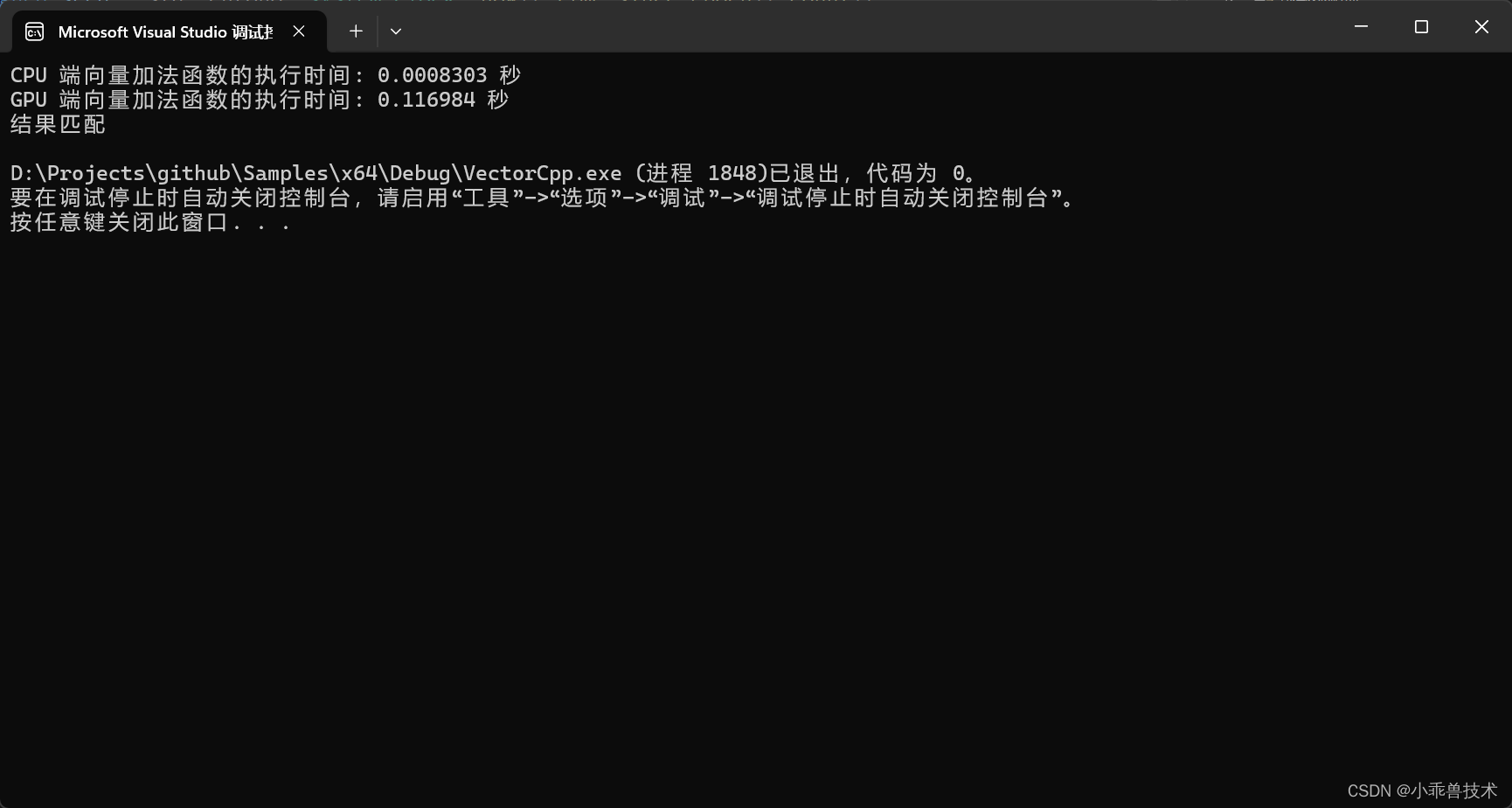
在這個示例中,成功運行得出結果。這個時候,你會發現為什么CPU的計算結果遠遠高于GPU。那是因為:
- 數據傳輸開銷:在CUDA中,數據必須在主機(CPU)和設備(GPU)之間進行傳輸。在每次調用CUDA函數之前和之后,都需要將數據從主機內存復制到設備內存,然后將結果從設備內存復制回主機內存。這些數據傳輸的開銷會降低CUDA的性能,特別是當數據量較大時。
- Kernel調用開銷:在CUDA中,每次調用核函數都需要一定的開銷,包括啟動核函數、將數據傳遞給核函數、核函數在GPU上執行等。如果向量大小較小,核函數的啟動開銷可能會占據相當大的比例,從而降低CUDA的性能。
- 并行化效率不佳:在某些情況下,CUDA核函數可能無法充分利用GPU的并行計算能力。這可能是因為向量大小太小,無法充分填充GPU的計算單元,或者核函數的計算密度不夠高,無法實現最大的并行化效率。
- 內存訪問模式:CUDA核函數的性能受到內存訪問模式的影響。如果核函數中的內存訪問模式不利于GPU的緩存和內存訪問優化,性能可能會受到影響。
究其根本原因就是,這個算法太簡單了,CPU就可以搞定,用不上GPU。
四、總結
在這個項目中,我們主要體會框架的用法,以及CUDA計算環境搭建的。通過編碼實踐,構建項目成功實驗了CUDA計算環境搭建,為接下來的工作準備好環境。
五、參考文檔
錯誤 MSB4062 未能從程序集加載任務
VS加載CUDA項目出錯:未找到導入的項目
整理:warning LNK4098: 默認庫“LIBCMT”與其他庫的使用沖突;請使用 /NODEFAULTLIB:library
Win10下在VS2019中配置使用CUDA進行加速的C++項目 (配置.h文件,.dll以及.lib文件等)











)






)
