XTuner 微調 LLM:1.8B、多模態、Agent
引自:Tutorial/xtuner/personal_assistant_document.md at camp2 · InternLM/Tutorial · GitHub

1. XTuner介紹
引自:歡迎來到 XTuner 的中文文檔 — XTuner 0.1.18.dev0 文檔
1.1. 什么是 XTuner ?
- XTuner 是由 InternLM 團隊開發的一個高效、靈活、全能的輕量化大模型微調工具庫。
- 主要用于多種大模型的高效微調,包括 InternLM 和多模態圖文模型 LLaVa。
- 支持 QLoRA、全量微調等多種微調訓練方法,并可與 DeepSpeed 集成優化訓練。
- 提供模型、數據集、數據管道和算法支持,配備配置文件和快速入門指南。
- 訓練所得模型可無縫接入部署工具庫 LMDeploy、大規模評測工具庫 OpenCompass 及 VLMEvalKit。為大型語言模型微調提供一個全面且用戶友好的解決方案。
1.2. XTuner 的工作流程
我們可以通過以下這張圖,簡單的了解一下 XTuner 的整體運作流程。

整個工作流程分為以下四個步驟:
- 前期準備:
-
- 首先,根據任務的不同,我們需要明確微調目標,進行數據采集,并將數據轉換為 XTuner 所支持的格式類型。
- 然后我們還需要根據自己的硬件條件選擇合適的微調方法和合適的基座模型。不同的基座模型對顯存的需求都不太一樣,模型參數越大,微調所需要顯存就越多。而在微調方法中,對顯存需求最小的就是 QLoRA(最少 8GB 即可運行),而顯存需求最大的則是全量微調。
- 配置文件的創建及修改:
-
- 首先,我們可以通過執行 xtuner list-cfg 命令列出所有配置文件。
- 通過上面選擇的微調方法和基座模型找到合適的配置文件,并使用 xtuner copy-cfg ${CONFIG_NAME} ${SAVE_PATH} 命令復制到本地端。
- 復制完成后還需要根據自己的需求修改配置文件以更新模型路徑和數據集路徑。
- 特定時候還需要調整模型參數和配置,更改 load_dataset 函數和 dataset_map_fn 函數。并根據模型選擇合適的 prompt_template。
- 模型訓練:
-
- 修改配置文件后,我就可以使用 xtuner train 命令啟動訓練。
- 除此之外我們還可以設置特定參數優化訓練,如啟用 deepspeed,以及設置訓練文件的保存路徑。
- 假如意外的中斷了訓練,還可以通過加上 --resume {checkpoint_path} 的方式進行模型續訓。
- 模型轉換、整合、測試及部署:
-
- 在完成訓練后,找到對應的訓練文件并執行 xtuner convert pth_to_hf 命令,就可以將轉換模型格式為 huggingface 格式。
- 對于 LoRA 類的模型而言,由于微調出來的是一個額外的 adapter 層而不是完整的模型,因此還需要執行 xtuner convert merge 命令將 adapter 層與原模型進行合并。對于全量微調模型而言,則只需要轉換即可使用。
- 轉換完成后,我們就可以以轉換后的文件路徑并使用 xtuner chat 命令啟動模型進行性能測試。
- 除此之外,我們還可以在安裝 LMDeploy 后通過 python -m lmdeploy.pytorch.chat 命令進行模型部署,即使用 TurboMind 進行推理。
1.3. XTuner 的核心模塊
- Configs:
-
- 存放著不同模型、不同數據集以及微調方法的配置文件。
- 可以自行從 huggingface 上下載模型和數據集后進行一鍵啟動。
- Dataset:
-
- 在 map_fns 下存放了支持的數據集的映射規則。
- 在 collate_fns 下存放了關于數據整理函數部分的內容。
- 提供了用于存放和加載不同來源數據集的函數和類。
- Engine:
-
- hooks 中展示了哪些信息將會在哪個階段下在終端被打印出來。
- Tools:
-
- 這里面是 XTuner 中的核心工具箱,里面存放了我們常用的指令,包括了打印 config 文件 list_cfg、復制 config 文件 copy_cfg、訓練 train 以及對話 chat 等等。
- 在 model_converters 中也提供了模型轉換、整合以及切分的腳本。
- 在 plugin 中提供了部分工具調用的函數。
1.4. XTuner 當前支持的模型、數據集及微調方法
支持的大語言模型
- 支持的大語言模型
XTuner 目前支持以下大語言模型,可支持所有 huggingface 格式的大語言模型:
-
- baichuan
- chatglm
- internlm
- llama
- llava
- mistral
- mixtral
- qwen
- yi
- starcoder
- zephyr
- …
- 支持的數據集格式
XTuner 目前支持以下數據集格式:
-
- alpaca
- alpaca_zh
- code_alpaca
- arxiv
- colors
- crime_kg_assistant
- law_reference
- llava
- medical
- msagent
- oasst1
- openai
- openorca
- pretrain
- sql
- stack_exchange
- tiny_codes
- wizardlm
- …
- 支持的微調方法
XTuner 目前支持以下微調方法:
-
- QLoRA
- LoRA
- Full
- …
2. XTuner實戰
2.1. 環境搭建
# 如果你是在 InternStudio 平臺,則從本地 clone 一個已有 pytorch 的環境:
# pytorch 2.0.1 py3.10_cuda11.7_cudnn8.5.0_0studio-conda xtuner0.1.17
# 如果你是在其他平臺:
# conda create --name xtuner0.1.17 python=3.10 -y# 激活環境
conda activate xtuner0.1.17
# 進入家目錄 (~的意思是 “當前用戶的home路徑”)
cd ~
# 創建版本文件夾并進入,以跟隨本教程
mkdir -p /root/xtuner0117 && cd /root/xtuner0117# 拉取 0.1.17 的版本源碼
git clone -b v0.1.17 https://github.com/InternLM/xtuner
# 無法訪問github的用戶請從 gitee 拉取:
# git clone -b v0.1.15 https://gitee.com/Internlm/xtuner# 進入源碼目錄
cd /root/xtuner0117/xtuner# 從源碼安裝 XTuner
pip install -e '.[all]' -i https://mirrors.aliyun.com/pypi/simple/
假如在這一過程中沒有出現任何的報錯的話,那也就意味著我們成功安裝好支持 XTuner 所運行的環境啦。其實對于很多的初學者而言,安裝好環境意味著成功了一大半!因此我們接下來就可以進入我們的第二步,準備好我們需要的數據集、模型和配置文件!
2.2. 前期準備
2.2.1. 準備數據
為了讓模型能夠讓模型認清自己的身份弟位,知道在詢問自己是誰的時候回復成我們想要的樣子,我們就需要通過在微調數據集中大量摻雜這部分的數據。
首先我們先創建一個文件夾來存放我們這次訓練所需要的所有文件。
# 前半部分是創建一個文件夾,后半部分是進入該文件夾。
mkdir -p /root/ft && cd /root/ft# 在ft這個文件夾里再創建一個存放數據的data文件夾
mkdir -p /root/ft/data && cd /root/ft/data
之后我們可以在 data 目錄下新建一個 generate_data.py 文件,將以下代碼復制進去,然后運行該腳本即可生成數據集。假如想要加大劑量讓他能夠完完全全認識到你的身份,那我們可以吧 n 的值調大一點。
# 創建 `generate_data.py` 文件
touch /root/ft/data/generate_data.py打開該 python 文件后將下面的內容復制進去。
import json# 設置用戶的名字
name = 'gy77'
# 設置需要重復添加的數據次數
n = 10000# 初始化OpenAI格式的數據結構
data = [{"messages": [{"role": "user","content": "請做一下自我介紹"},{"role": "assistant","content": "我是{}的小助手,內在是上海AI實驗室書生·浦語的1.8B大模型哦".format(name)}]}
]# 通過循環,將初始化的對話數據重復添加到data列表中
for i in range(n):data.append(data[0])# 將data列表中的數據寫入到一個名為'personal_assistant.json'的文件中
with open('personal_assistant.json', 'w', encoding='utf-8') as f:# 使用json.dump方法將數據以JSON格式寫入文件# ensure_ascii=False 確保中文字符正常顯示# indent=4 使得文件內容格式化,便于閱讀json.dump(data, f, ensure_ascii=False, indent=4)運行 generate_data.py 文件:
# 確保先進入該文件夾
cd /root/ft/data# 運行代碼
python /root/ft/data/generate_data.py
可以看到在data的路徑下便生成了一個名為 personal_assistant.json 的文件,這樣我們最可用于微調的數據集就準備好啦!里面就包含了 5000 條 input 和 output 的數據對。假如 我們認為 5000 條不夠的話也可以調整文件中第6行 n 的值哦!
|-- data/|-- personal_assistant.json|-- generate_data.py文件結構樹代碼
除了我們自己通過腳本的數據集,其實網上也有大量的開源數據集可以供我們進行使用。有些時候我們可以在開源數據集的基礎上添加一些我們自己獨有的數據集,也可能會有很好的效果。
2.2.2. 準備模型
在準備好了數據集后,接下來我們就需要準備好我們的要用于微調的模型。由于本次課程顯存方面的限制,這里我們就使用 InternLM 最新推出的小模型 InterLM2-Chat-1.8B 來完成此次的微調演示。
對于在 InternStudio 上運行的小伙伴們,可以不用通過 OpenXLab 或者 Modelscope 進行模型的下載。我們直接通過以下代碼一鍵創建文件夾并將所有文件復制進去。
# 創建目標文件夾,確保它存在。
# -p選項意味著如果上級目錄不存在也會一并創建,且如果目標文件夾已存在則不會報錯。
mkdir -p /root/ft/model# 復制內容到目標文件夾。-r選項表示遞歸復制整個文件夾。
cp -r /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b/* /root/ft/model/
那這個時候我們就可以看到在 model 文件夾下保存了模型的相關文件和內容了。
|-- model/|-- tokenizer.model|-- config.json|-- tokenization_internlm2.py|-- model-00002-of-00002.safetensors|-- tokenizer_config.json|-- model-00001-of-00002.safetensors|-- model.safetensors.index.json|-- configuration.json|-- special_tokens_map.json|-- modeling_internlm2.py|-- README.md|-- configuration_internlm2.py|-- generation_config.json|-- tokenization_internlm2_fast.py假如大家存儲空間不足,我們也可以通過以下代碼一鍵通過符號鏈接的方式鏈接到模型文件,這樣既節省了空間,也便于管理。
# 刪除/root/ft/model目錄
rm -rf /root/ft/model# 創建符號鏈接
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b /root/ft/model
執行上述操作后,/root/ft/model 將直接成為一個符號鏈接,這個鏈接指向 /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b 的位置。
這意味著,當我們訪問 /root/ft/model 時,實際上就是在訪問 /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b 目錄下的內容。通過這種方式,我們無需復制任何數據,就可以直接利用現有的模型文件進行后續的微調操作,從而節省存儲空間并簡化文件管理。
在該情況下的文件結構如下所示,可以看到和上面的區別在于多了一些軟鏈接相關的文件。
|-- model/|-- tokenizer.model|-- config.json|-- .mdl|-- tokenization_internlm2.py|-- model-00002-of-00002.safetensors|-- tokenizer_config.json|-- model-00001-of-00002.safetensors|-- model.safetensors.index.json|-- configuration.json|-- .msc|-- special_tokens_map.json|-- .mv|-- modeling_internlm2.py|-- README.md|-- configuration_internlm2.py|-- generation_config.json|-- tokenization_internlm2_fast.py2.2.3. 準備配置文件
在準備好了模型和數據集后,我們就要根據我們選擇的微調方法方法結合前面的信息來找到與我們最匹配的配置文件了,從而減少我們對配置文件的修改量。
所謂配置文件(config),其實是一種用于定義和控制模型訓練和測試過程中各個方面的參數和設置的工具。準備好的配置文件只要運行起來就代表著模型就開始訓練或者微調了。
XTuner 提供多個開箱即用的配置文件,用戶可以通過下列命令查看:
開箱即用意味著假如能夠連接上 Huggingface 以及有足夠的顯存,其實就可以直接運行這些配置文件,XTuner就能夠直接下載好這些模型和數據集然后開始進行微調
# 列出所有內置配置文件
# xtuner list-cfg# 假如我們想找到 internlm2-1.8b 模型里支持的配置文件
xtuner list-cfg -p internlm2_1_8b
這里就用到了第一個 XTuner 的工具 list-cfg ,對于這個工具而言,可以選擇不添加額外的參數,就像上面的一樣,這樣就會將所有的配置文件都打印出來。那同時也可以加上一個參數 -p 或 --pattern ,后面輸入的內容將會在所有的 config 文件里進行模糊匹配搜索,然后返回最有可能得內容。我們可以用來搜索特定模型的配置文件,比如例子中的 internlm2_1_8b ,也可以用來搜索像是微調方法 qlora 。 根據上面的定向搜索指令可以看到目前只有兩個支持 internlm2-1.8B 的模型配置文件。
==========================CONFIGS===========================
PATTERN: internlm2_1_8b
-------------------------------
internlm2_1_8b_full_alpaca_e3
internlm2_1_8b_qlora_alpaca_e3
=============================================================配置文件名的解釋
雖然我們用的數據集并不是 alpaca 而是我們自己通過腳本制作的小助手數據集 ,但是由于我們是通過 QLoRA 的方式對 internlm2-chat-1.8b 進行微調。而最相近的配置文件應該就是 internlm2_1_8b_qlora_alpaca_e3 ,因此我們可以選擇拷貝這個配置文件到當前目錄:
# 創建一個存放 config 文件的文件夾
mkdir -p /root/ft/config# 使用 XTuner 中的 copy-cfg 功能將 config 文件復制到指定的位置
xtuner copy-cfg internlm2_1_8b_qlora_alpaca_e3 /root/ft/config
這里我們就用到了 XTuner 工具箱中的第二個工具 copy-cfg ,該工具有兩個必須要填寫的參數 {CONFIG_NAME} 和 {SAVE_PATH} ,在我們的輸入的這個指令中,我們的 {CONFIG_NAME} 對應的是上面搜索到的 internlm2_1_8b_qlora_alpaca_e3 ,而 {SAVE_PATH} 則對應的是剛剛新建的 /root/ft/config。我們假如需要復制其他的配置文件只需要修改這兩個參數即可實現。 輸入后我們就能夠看到在我們的 /root/ft/config 文件夾下有一個名為 internlm2_1_8b_qlora_alpaca_e3_copy.py 的文件了。
|-- config/|-- internlm2_1_8b_qlora_alpaca_e3_copy.py2.2.4. 小結
完成以上內容后,我就已經完成了所有的準備工作了。我們再來回顧一下我們做了哪些事情:
- 我們首先是在 GitHub 上克隆了 XTuner 的源碼,并把相關的配套庫也通過 pip 的方式進行了安裝。
- 然后我們根據自己想要做的事情,利用腳本準備好了一份關于調教模型認識自己身份弟位的數據集。
- 再然后我們根據自己的顯存及任務情況確定了使用 InternLM2-chat-1.8B 這個模型,并且將其復制到我們的文件夾里。
- 最后我們在 XTuner 已有的配置文件中,根據微調方法、數據集和模型挑選出最合適的配置文件并復制到我們新建的文件夾中。
經過了以上的步驟后,我們的 ft 文件夾里應該是這樣的:
|-- ft/|-- config/|-- internlm2_1_8b_qlora_alpaca_e3_copy.py|-- model/|-- tokenizer.model|-- config.json|-- tokenization_internlm2.py|-- model-00002-of-00002.safetensors|-- tokenizer_config.json|-- model-00001-of-00002.safetensors|-- model.safetensors.index.json|-- configuration.json|-- special_tokens_map.json|-- modeling_internlm2.py|-- README.md|-- configuration_internlm2.py|-- generation_config.json|-- tokenization_internlm2_fast.py|-- data/|-- personal_assistant.json|-- generate_data.py是不是感覺其實微調也不過如此!事實上確實是這樣的!其實在微調的時候最重要的還是要自己準備一份高質量的數據集,這個才是你能否真微調出效果最核心的利器。
微調也經常被戲稱為是煉丹,就是說你煉丹的時候你得思考好用什么樣的材料、用多大的火候、烤多久的時間以及用什么丹爐去燒。這里的丹爐其實我們可以想象為 XTuner ,只要丹爐的質量過得去,煉丹的時候不會炸,一般都是沒問題的。但是假如煉丹的材料(就是數據集)本來就是垃圾,那無論怎么煉(微調參數的調整),煉多久(訓練的輪數),煉出來的東西還只能且只會是垃圾。只有說用了比較好的材料,那么我們就可以考慮說要煉多久以及用什么辦法去煉的問題。因此總的來說,學會如何構建一份高質量的數據集是至關重要的。
假如想要了解更多關于數據集制作方面的內容,可以加入書生.浦語的 RolePlay SIG 中,里面會有各種大佬手把手教學,教你如何制作一個自己喜歡角色的數據集出來。也期待更多大佬加入講述自己制作數據集的想法和過程!
2.3. 配置文件修改
在選擇了一個最匹配的配置文件并準備好其他內容后,下面我們要做的事情就是根據我們自己的內容對該配置文件進行調整,使其能夠滿足我們實際訓練的要求。
配置文件介紹
通過折疊部分的修改,內容如下,可以直接將以下代碼復制到 /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py 文件中(先 Ctrl + A 選中所有文件并刪除后再將代碼復制進去)。
參數修改細節
# Copyright (c) OpenMMLab. All rights reserved.
import torch
from datasets import load_dataset
from mmengine.dataset import DefaultSampler
from mmengine.hooks import (CheckpointHook, DistSamplerSeedHook, IterTimerHook,LoggerHook, ParamSchedulerHook)
from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR, LinearLR
from peft import LoraConfig
from torch.optim import AdamW
from transformers import (AutoModelForCausalLM, AutoTokenizer,BitsAndBytesConfig)from xtuner.dataset import process_hf_dataset
from xtuner.dataset.collate_fns import default_collate_fn
from xtuner.dataset.map_fns import openai_map_fn, template_map_fn_factory
from xtuner.engine.hooks import (DatasetInfoHook, EvaluateChatHook,VarlenAttnArgsToMessageHubHook)
from xtuner.engine.runner import TrainLoop
from xtuner.model import SupervisedFinetune
from xtuner.parallel.sequence import SequenceParallelSampler
from xtuner.utils import PROMPT_TEMPLATE, SYSTEM_TEMPLATE#######################################################################
# PART 1 Settings #
#######################################################################
# Model
pretrained_model_name_or_path = '/root/ft/model'
use_varlen_attn = False# Data
alpaca_en_path = '/root/ft/data/personal_assistant.json'
prompt_template = PROMPT_TEMPLATE.internlm2_chat
max_length = 1024
pack_to_max_length = True# parallel
sequence_parallel_size = 1# Scheduler & Optimizer
batch_size = 1 # per_device
accumulative_counts = 16
accumulative_counts *= sequence_parallel_size
dataloader_num_workers = 0
max_epochs = 2
optim_type = AdamW
lr = 2e-4
betas = (0.9, 0.999)
weight_decay = 0
max_norm = 1 # grad clip
warmup_ratio = 0.03# Save
save_steps = 300
save_total_limit = 3 # Maximum checkpoints to keep (-1 means unlimited)# Evaluate the generation performance during the training
evaluation_freq = 300
SYSTEM = ''
evaluation_inputs = ['請你介紹一下你自己', '你是誰', '你是我的小助手嗎']#######################################################################
# PART 2 Model & Tokenizer #
#######################################################################
tokenizer = dict(type=AutoTokenizer.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True,padding_side='right')model = dict(type=SupervisedFinetune,use_varlen_attn=use_varlen_attn,llm=dict(type=AutoModelForCausalLM.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True,torch_dtype=torch.float16,quantization_config=dict(type=BitsAndBytesConfig,load_in_4bit=True,load_in_8bit=False,llm_int8_threshold=6.0,llm_int8_has_fp16_weight=False,bnb_4bit_compute_dtype=torch.float16,bnb_4bit_use_double_quant=True,bnb_4bit_quant_type='nf4')),lora=dict(type=LoraConfig,r=64,lora_alpha=16,lora_dropout=0.1,bias='none',task_type='CAUSAL_LM'))#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
alpaca_en = dict(type=process_hf_dataset,dataset=dict(type=load_dataset, path='json', data_files=dict(train=alpaca_en_path)),tokenizer=tokenizer,max_length=max_length,dataset_map_fn=openai_map_fn,template_map_fn=dict(type=template_map_fn_factory, template=prompt_template),remove_unused_columns=True,shuffle_before_pack=True,pack_to_max_length=pack_to_max_length,use_varlen_attn=use_varlen_attn)sampler = SequenceParallelSampler \if sequence_parallel_size > 1 else DefaultSampler
train_dataloader = dict(batch_size=batch_size,num_workers=dataloader_num_workers,dataset=alpaca_en,sampler=dict(type=sampler, shuffle=True),collate_fn=dict(type=default_collate_fn, use_varlen_attn=use_varlen_attn))#######################################################################
# PART 4 Scheduler & Optimizer #
#######################################################################
# optimizer
optim_wrapper = dict(type=AmpOptimWrapper,optimizer=dict(type=optim_type, lr=lr, betas=betas, weight_decay=weight_decay),clip_grad=dict(max_norm=max_norm, error_if_nonfinite=False),accumulative_counts=accumulative_counts,loss_scale='dynamic',dtype='float16')# learning policy
# More information: https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md # noqa: E501
param_scheduler = [dict(type=LinearLR,start_factor=1e-5,by_epoch=True,begin=0,end=warmup_ratio * max_epochs,convert_to_iter_based=True),dict(type=CosineAnnealingLR,eta_min=0.0,by_epoch=True,begin=warmup_ratio * max_epochs,end=max_epochs,convert_to_iter_based=True)
]# train, val, test setting
train_cfg = dict(type=TrainLoop, max_epochs=max_epochs)#######################################################################
# PART 5 Runtime #
#######################################################################
# Log the dialogue periodically during the training process, optional
custom_hooks = [dict(type=DatasetInfoHook, tokenizer=tokenizer),dict(type=EvaluateChatHook,tokenizer=tokenizer,every_n_iters=evaluation_freq,evaluation_inputs=evaluation_inputs,system=SYSTEM,prompt_template=prompt_template)
]if use_varlen_attn:custom_hooks += [dict(type=VarlenAttnArgsToMessageHubHook)]# configure default hooks
default_hooks = dict(# record the time of every iteration.timer=dict(type=IterTimerHook),# print log every 10 iterations.logger=dict(type=LoggerHook, log_metric_by_epoch=False, interval=10),# enable the parameter scheduler.param_scheduler=dict(type=ParamSchedulerHook),# save checkpoint per `save_steps`.checkpoint=dict(type=CheckpointHook,by_epoch=False,interval=save_steps,max_keep_ckpts=save_total_limit),# set sampler seed in distributed evrionment.sampler_seed=dict(type=DistSamplerSeedHook),
)# configure environment
env_cfg = dict(# whether to enable cudnn benchmarkcudnn_benchmark=False,# set multi process parametersmp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),# set distributed parametersdist_cfg=dict(backend='nccl'),
)# set visualizer
visualizer = None# set log level
log_level = 'INFO'# load from which checkpoint
load_from = None# whether to resume training from the loaded checkpoint
resume = False# Defaults to use random seed and disable `deterministic`
randomness = dict(seed=None, deterministic=False)# set log processor
log_processor = dict(by_epoch=False)這一節我們講述了微調過程中一些常見的需要調整的內容,包括各種的路徑、超參數、評估問題等等。完成了這部分的修改后,我們就可以正式的開始我們下一階段的旅程: XTuner 啟動~!
具體修改內容對比:

2.4. 模型訓練
2.4.1. 常規訓練
當我們準備好了配置文件好,我們只需要將使用 xtuner train 指令即可開始訓練。
我們可以通過添加 --work-dir 指定特定的文件保存位置,比如說就保存在 /root/ft/train 路徑下。假如不添加的話模型訓練的過程文件將默認保存在 ./work_dirs/internlm2_1_8b_qlora_alpaca_e3_copy 的位置,就比如說我是在 /root/ft/train 的路徑下輸入該指令,那么我的文件保存的位置就是在 /root/ft/train/work_dirs/internlm2_1_8b_qlora_alpaca_e3_copy 的位置下。
# 指定保存路徑
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train
在輸入訓練完后的文件如下所示:
|-- train/|-- internlm2_1_8b_qlora_alpaca_e3_copy.py|-- iter_600.pth|-- last_checkpoint|-- iter_768.pth|-- iter_300.pth|-- 20240406_203957/|-- 20240406_203957.log|-- vis_data/|-- 20240406_203957.json|-- eval_outputs_iter_599.txt|-- eval_outputs_iter_767.txt|-- scalars.json|-- eval_outputs_iter_299.txt|-- config.py2.4.2. 使用 deepspeed 來加速訓練
除此之外,我們也可以結合 XTuner 內置的 deepspeed 來加速整體的訓練過程,共有三種不同的 deepspeed 類型可進行選擇,分別是 deepspeed_zero1, deepspeed_zero2 和 deepspeed_zero3(詳細的介紹可看下拉框)。
DeepSpeed優化器及其選擇方法
DeepSpeed是一個深度學習優化庫,由微軟開發,旨在提高大規模模型訓練的效率和速度。它通過幾種關鍵技術來優化訓練過程,包括模型分割、梯度累積、以及內存和帶寬優化等。DeepSpeed特別適用于需要巨大計算資源的大型模型和數據集。
在DeepSpeed中,zero 代表“ZeRO”(Zero Redundancy Optimizer),是一種旨在降低訓練大型模型所需內存占用的優化器。ZeRO 通過優化數據并行訓練過程中的內存使用,允許更大的模型和更快的訓練速度。ZeRO 分為幾個不同的級別,主要包括:
- deepspeed_zero1:這是ZeRO的基本版本,它優化了模型參數的存儲,使得每個GPU只存儲一部分參數,從而減少內存的使用。
- deepspeed_zero2:在deepspeed_zero1的基礎上,deepspeed_zero2進一步優化了梯度和優化器狀態的存儲。它將這些信息也分散到不同的GPU上,進一步降低了單個GPU的內存需求。
- deepspeed_zero3:這是目前最高級的優化等級,它不僅包括了deepspeed_zero1和deepspeed_zero2的優化,還進一步減少了激活函數的內存占用。這通過在需要時重新計算激活(而不是存儲它們)來實現,從而實現了對大型模型極其內存效率的訓練。
選擇哪種deepspeed類型主要取決于你的具體需求,包括模型的大小、可用的硬件資源(特別是GPU內存)以及訓練的效率需求。一般來說:
- 如果你的模型較小,或者內存資源充足,可能不需要使用最高級別的優化。
- 如果你正在嘗試訓練非常大的模型,或者你的硬件資源有限,使用deepspeed_zero2或deepspeed_zero3可能更合適,因為它們可以顯著降低內存占用,允許更大模型的訓練。
- 選擇時也要考慮到實現的復雜性和運行時的開銷,更高級的優化可能需要更復雜的設置,并可能增加一些計算開銷。
# 使用 deepspeed 來加速訓練
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train_deepspeed --deepspeed deepspeed_zero2
可以看到,通過 deepspeed 來訓練后得到的權重文件和原本的權重文件是有所差別的,原本的僅僅是一個 .pth 的文件,而使用了 deepspeed 則是一個名字帶有 .pth 的文件夾,在該文件夾里保存了兩個 .pt 文件。當然這兩者在具體的使用上并沒有太大的差別,都是可以進行轉化并整合。
|-- train_deepspeed/|-- internlm2_1_8b_qlora_alpaca_e3_copy.py|-- zero_to_fp32.py|-- last_checkpoint|-- iter_600.pth/|-- bf16_zero_pp_rank_0_mp_rank_00_optim_states.pt|-- mp_rank_00_model_states.pt|-- 20240406_220727/|-- 20240406_220727.log|-- vis_data/|-- 20240406_220727.json|-- eval_outputs_iter_599.txt|-- eval_outputs_iter_767.txt|-- scalars.json|-- eval_outputs_iter_299.txt|-- config.py|-- iter_768.pth/|-- bf16_zero_pp_rank_0_mp_rank_00_optim_states.pt|-- mp_rank_00_model_states.pt|-- iter_300.pth/|-- bf16_zero_pp_rank_0_mp_rank_00_optim_states.pt|-- mp_rank_00_model_states.pt2.4.3. 訓練結果
但是其實無論是用哪種方式進行訓練,得到的結果都是大差不差的。我們由于設置了300輪評估一次,所以我們可以對比一下300輪和600輪的評估問題結果來看看差別。
# 300輪<s><|im_start|>user
請你介紹一下你自己<|im_end|>
<|im_start|>assistant
對不起,我無法回答這個問題。作為一個AI,我致力于提供有用、誠實和無害的信息。如果您有其他問題,我會很樂意為您提供幫助。讓我們共同維護一個積極、健康的交流環境。<|im_end|>06/05 20:05:03 - mmengine - INFO - Sample output:
<s><|im_start|>user
你是誰<|im_end|>
<|im_start|>assistant
我是一個人工智能助手,我是由上海人工智能實驗室開發和訓練的。我致力于通過執行常見的基于語言的任務和提供建議來幫助人類。我使用了Transformer模型和深度學習技術,并使用語言模型作為預訓練任務。我的設計理念06/05 20:05:06 - mmengine - INFO - Sample output:
<s><|im_start|>user
你是我的小助手嗎<|im_end|>
<|im_start|>assistant
是的,我是您的智能助手,您可以使用我的功能來幫助您完成各種任務。<|im_end|># 600輪請你介紹一下你自己<|im_end|>
<|im_start|>assistant
我是gy77的小助手,內在是上海AI實驗室書生·浦語的1.8B大模型哦<|im_end|>06/05 20:20:41 - mmengine - INFO - Sample output:
<s><|im_start|>user
你是誰<|im_end|>
<|im_start|>assistant
我是gy77的小助手,內在是上海AI實驗室書生·浦語的1.8B大模型哦<|im_end|>06/05 20:20:42 - mmengine - INFO - Sample output:
<s><|im_start|>user
你是我的小助手嗎<|im_end|>
<|im_start|>assistant
我是gy77的小助手,內在是上海AI實驗室書生·浦語的1.8B大模型哦<|im_end|>通過兩者的對比我們其實就可以很清楚的看到,在300輪的時候模型已經學會了在我問 “你是誰” 或者說 “請你介紹一下我自己” 的時候回答 “我是劍鋒大佬的小助手,內在是上海AI實驗室書生·浦語的1.8B大模型哦”。
但是兩者的不同是在詢問 “你是我的小助手” 的這個問題上,300輪的時候是回答正確的,回答了 “是” ,但是在600輪的時候回答的還是 “我是劍鋒大佬的小助手,內在是上海AI實驗室書生·浦語的1.8B大模型哦” 這一段話。這表明模型在第一批次第600輪的時候已經出現嚴重的過擬合(即模型丟失了基礎的能力,只會成為某一句話的復讀機)現象了,到后面的話無論我們再問什么,得到的結果也就只能是回答這一句話了,模型已經不會再說別的話了。因此假如以通用能力的角度選擇最合適的權重文件的話我們可能會選擇前面的權重文件進行后續的模型轉化及整合工作。
假如我們想要解決這個問題,其實可以通過以下兩個方式解決:
- 減少保存權重文件的間隔并增加權重文件保存的上限:這個方法實際上就是通過降低間隔結合評估問題的結果,從而找到最優的權重文。我們可以每隔100個批次來看什么時候模型已經學到了這部分知識但是還保留著基本的常識,什么時候已經過擬合嚴重只會說一句話了。但是由于再配置文件有設置權重文件保存數量的上限,因此同時將這個上限加大也是非常必要的。
- 增加常規的對話數據集從而稀釋原本數據的占比:這個方法其實就是希望我們正常用對話數據集做指令微調的同時還加上一部分的數據集來讓模型既能夠學到正常對話,但是在遇到特定問題時進行特殊化處理。比如說我在一萬條正常的對話數據里混入兩千條和小助手相關的數據集,這樣模型同樣可以在不丟失對話能力的前提下學到劍鋒大佬的小助手這句話。這種其實是比較常見的處理方式,大家可以自己動手嘗試實踐一下。
另外假如我們模型中途中斷了,我們也可以參考以下方法實現模型續訓工作
假如我們的模型訓練過程中突然被中斷了,我們也可以通過在原有指令的基礎上加上 --resume {checkpoint_path} 來實現模型的繼續訓練。需要注意的是,這個繼續訓練得到的權重文件和中斷前的完全一致,并不會有任何區別。下面我將用訓練了500輪的例子來進行演示。
# 模型續訓
xtuner train /root/ft/config/internlm2_1_8b_qlora_alpaca_e3_copy.py --work-dir /root/ft/train --resume /root/ft/train/iter_600.pth在實測過程中,雖然權重文件并沒有發生改變,但是會多一個以時間戳為名的訓練過程文件夾保存訓練的過程數據。
2.4.4. 小結
在本節我們的重點是講解模型訓練過程中的種種細節內容,包括了模型訓練中的各個參數以、權重文件的選擇方式以及模型續訓的方法。可以看到是否使用 --work-dir 和 是否使用 --deepspeed 會對文件的保存位置以及權重文件的保存方式有所不同,大家也可以通過實踐去實際的測試感受一下。那么在訓練完成后,我們就可以把訓練得到的 .pth 文件進行下一步的轉換和整合工作了!
2.5. 模型轉換、整合、測試及部署
2.5.1. 模型轉換
模型轉換的本質其實就是將原本使用 Pytorch 訓練出來的模型權重文件轉換為目前通用的 Huggingface 格式文件,那么我們可以通過以下指令來實現一鍵轉換。
# 創建一個保存轉換后 Huggingface 格式的文件夾
mkdir -p /root/ft/huggingface# 模型轉換
# xtuner convert pth_to_hf ${配置文件地址} ${權重文件地址} ${轉換后模型保存地址}
xtuner convert pth_to_hf /root/ft/train/internlm2_1_8b_qlora_alpaca_e3_copy.py /root/ft/train/iter_300.pth /root/ft/huggingface
轉換完成后,可以看到模型被轉換為 Huggingface 中常用的 .bin 格式文件,這就代表著文件成功被轉化為 Huggingface 格式了。
|-- huggingface/|-- adapter_config.json|-- xtuner_config.py|-- adapter_model.bin|-- README.md此時,huggingface 文件夾即為我們平時所理解的所謂 “LoRA 模型文件”
可以簡單理解:LoRA 模型文件 = Adapter
除此之外,我們其實還可以在轉換的指令中添加幾個額外的參數,包括以下兩個:
| 參數名 | 解釋 |
| --fp32 | 代表以fp32的精度開啟,假如不輸入則默認為fp16 |
| --max-shard-size {GB} | 代表每個權重文件最大的大小(默認為2GB) |
假如有特定的需要,我們可以在上面的轉換指令后進行添加。由于本次測試的模型文件較小,并且已經驗證過擬合,故沒有添加。假如加上的話應該是這樣的:
xtuner convert pth_to_hf /root/ft/train/internlm2_1_8b_qlora_alpaca_e3_copy.py /root/ft/train/iter_768.pth /root/ft/huggingface --fp32 --max-shard-size 2GB
2.5.2. 模型整合
我們通過視頻課程的學習可以了解到,對于 LoRA 或者 QLoRA 微調出來的模型其實并不是一個完整的模型,而是一個額外的層(adapter)。那么訓練完的這個層最終還是要與原模型進行組合才能被正常的使用。
而對于全量微調的模型(full)其實是不需要進行整合這一步的,因為全量微調修改的是原模型的權重而非微調一個新的 adapter ,因此是不需要進行模型整合的。

在 XTuner 中也是提供了一鍵整合的指令,但是在使用前我們需要準備好三個地址,包括原模型的地址、訓練好的 adapter 層的地址(轉為 Huggingface 格式后保存的部分)以及最終保存的地址。
# 創建一個名為 final_model 的文件夾存儲整合后的模型文件
mkdir -p /root/ft/final_model# 解決一下線程沖突的 Bug
export MKL_SERVICE_FORCE_INTEL=1# 進行模型整合
# xtuner convert merge ${NAME_OR_PATH_TO_LLM} ${NAME_OR_PATH_TO_ADAPTER} ${SAVE_PATH}
xtuner convert merge /root/ft/model /root/ft/huggingface /root/ft/final_model
那除了以上的三個基本參數以外,其實在模型整合這一步還是其他很多的可選參數,包括:
| 參數名 | 解釋 |
| --max-shard-size {GB} | 代表每個權重文件最大的大小(默認為2GB) |
| --device {device_name} | 這里指的就是device的名稱,可選擇的有cuda、cpu和auto,默認為cuda即使用gpu進行運算 |
| --is-clip | 這個參數主要用于確定模型是不是CLIP模型,假如是的話就要加上,不是就不需要添加 |
CLIP(Contrastive Language–Image Pre-training)模型是 OpenAI 開發的一種預訓練模型,它能夠理解圖像和描述它們的文本之間的關系。CLIP 通過在大規模數據集上學習圖像和對應文本之間的對應關系,從而實現了對圖像內容的理解和分類,甚至能夠根據文本提示生成圖像。 在模型整合完成后,我們就可以看到 final_model 文件夾里生成了和原模型文件夾非常近似的內容,包括了分詞器、權重文件、配置信息等等。當我們整合完成后,我們就能夠正常的調用這個模型進行對話測試了。
整合完成后可以查看在 final_model 文件夾下的內容。
|-- final_model/|-- tokenizer.model|-- config.json|-- pytorch_model.bin.index.json|-- pytorch_model-00001-of-00002.bin|-- tokenization_internlm2.py|-- tokenizer_config.json|-- special_tokens_map.json|-- pytorch_model-00002-of-00002.bin|-- modeling_internlm2.py|-- configuration_internlm2.py|-- tokenizer.json|-- generation_config.json|-- tokenization_internlm2_fast.py2.5.3. 對話測試
在 XTuner 中也直接的提供了一套基于 transformers 的對話代碼,讓我們可以直接在終端與 Huggingface 格式的模型進行對話操作。我們只需要準備我們剛剛轉換好的模型路徑并選擇對應的提示詞模版(prompt-template)即可進行對話。假如 prompt-template 選擇有誤,很有可能導致模型無法正確的進行回復。
想要了解具體模型的 prompt-template 或者 XTuner 里支持的 prompt-tempolate,可以到 XTuner 源碼中的 xtuner/utils/templates.py 這個文件中進行查找。
# 與模型進行對話
xtuner chat /root/ft/final_model --prompt-template internlm2_chat我們可以通過一些簡單的測試來看看微調后的模型的能力。
假如我們想要輸入內容需要在輸入文字后敲擊兩下回車,假如我們想清楚歷史記錄需要輸入 RESET,假如我們想要退出則需要輸入 EXIT。
double enter to end input (EXIT: exit chat, RESET: reset history) >>> 你是誰我是gy77的小助手,內在是上海AI實驗室書生·浦語的1.8B大模型哦<|im_end|>double enter to end input (EXIT: exit chat, RESET: reset history) >>> 請你介紹一下你自己我是gy77的小助手,內在是上海AI實驗室書生·浦語的1.8B大模型哦<|im_end|>double enter to end input (EXIT: exit chat, RESET: reset history) >>> 你是我的小助手嗎?我是gy77的小助手,內在是上海AI實驗室書生·浦語的1.8B大模型哦<|im_end|>double enter to end input (EXIT: exit chat, RESET: reset history) >>> EXITLog: Exit!可以看到模型已經嚴重過擬合,回復的話就只有 “我是劍鋒大佬的小助手,內在是上海AI實驗室書生·浦語的1.8B大模型哦” 這句話。我們下面可以通過對比原模型的能力來看看差異。
# 同樣的我們也可以和原模型進行對話進行對比
xtuner chat /root/ft/model --prompt-template internlm2_chat我們可以用同樣的問題來查看回復的情況。
double enter to end input (EXIT: exit chat, RESET: reset history) >>> 你是誰
我是一個人工智能助手,旨在幫助用戶回答問題、提供定義和解釋、將文本從一種語言翻譯成另一種語言、總結文本、生成文本、編寫故事、分析情感、提供推薦、開發算法、編寫代碼以及其他任何基于語言的任務。我致力于通過執行常見的基于語言的任務和提供建議來幫助人類。<|im_end|>double enter to end input (EXIT: exit chat, RESET: reset history) >>> 請你介紹一下你自己
非常感謝您的提問。我是一個名叫書生·浦語的人工智能助手,由上海人工智能實驗室開發。我使用了Transformer模型和深度學習技術,并使用語言模型作為預訓練任務。我致力于通過執行常見的基于語言的任務和提供建議來幫助人類。我能夠回答問題、提供定義和解釋、將文本從一種語言翻譯成另一種語言、總結文本、生成文本、編寫故事、分析情感、提供推薦、開發算法、編寫代碼以及其他任何基于語言的任務。如果您有任何需要幫助的問題,歡迎隨時向我提問。<|im_end|>double enter to end input (EXIT: exit chat, RESET: reset history) >>> 你是我的小助手嗎
是的,我非常樂意成為您的助手。我致力于通過執行常見的基于語言的任務和提供建議來幫助您。如果您有任何需要幫助的問題,請隨時向我提問。我會盡力回答您的問題并提供有用的建議。<|im_end|>double enter to end input (EXIT: exit chat, RESET: reset history) >>> EXIT
Log: Exit!可以看到在沒有進行我們數據的微調前,原模型是能夠輸出有邏輯的回復,并且也不會認為他是我們特有的小助手。因此我們可以很明顯的看出兩者之間的差異性。
那對于 xtuner chat 這個指令而言,還有很多其他的參數可以進行設置的,包括:
| 啟動參數 | 解釋 |
| --system | 指定SYSTEM文本,用于在對話中插入特定的系統級信息 |
| --system-template | 指定SYSTEM模板,用于自定義系統信息的模板 |
| --bits | 指定LLM運行時使用的位數,決定了處理數據時的精度 |
| --bot-name | 設置bot的名稱,用于在對話或其他交互中識別bot |
| --with-plugins | 指定在運行時要使用的插件列表,用于擴展或增強功能 |
| --no-streamer | 關閉流式傳輸模式,對于需要一次性處理全部數據的場景 |
| --lagent | 啟用lagent,用于特定的運行時環境或優化 |
| --command-stop-word | 設置命令的停止詞,當遇到這些詞時停止解析命令 |
| --answer-stop-word | 設置回答的停止詞,當生成回答時遇到這些詞則停止 |
| --offload-folder | 指定存放模型權重的文件夾,用于加載或卸載模型權重 |
| --max-new-tokens | 設置生成文本時允許的最大token數量,控制輸出長度 |
| --temperature | 設置生成文本的溫度值,較高的值會使生成的文本更多樣,較低的值會使文本更確定 |
| --top-k | 設置保留用于頂k篩選的最高概率詞匯標記數,影響生成文本的多樣性 |
| --top-p | 設置累計概率閾值,僅保留概率累加高于top-p的最小標記集,影響生成文本的連貫性 |
| --seed | 設置隨機種子,用于生成可重現的文本內容 |
除了這些參數以外其實還有一個非常重要的參數就是 --adapter ,這個參數主要的作用就是可以在轉化后的 adapter 層與原模型整合之前來對該層進行測試。使用這個額外的參數對話的模型和整合后的模型幾乎沒有什么太多的區別,因此我們可以通過測試不同的權重文件生成的 adapter 來找到最優的 adapter 進行最終的模型整合工作。
# 使用 --adapter 參數與完整的模型進行對話
xtuner chat /root/ft/model --adapter /root/ft/huggingface --prompt-template internlm2_chat2.5.4. Web demo 部署
除了在終端中對模型進行測試,我們其實還可以在網頁端的 demo 進行對話。
那首先我們需要先下載網頁端 web demo 所需要的依賴。
pip install streamlit==1.24.0
下載 InternLM 項目代碼(歡迎Star)!
# 創建存放 InternLM 文件的代碼
mkdir -p /root/ft/web_demo && cd /root/ft/web_demo# 拉取 InternLM 源文件
git clone https://github.com/InternLM/InternLM.git# 進入該庫中
cd /root/ft/web_demo/InternLM
將 /root/ft/web_demo/InternLM/chat/web_demo.py 中的內容替換為以下的代碼(與源代碼相比,此處修改了模型路徑和分詞器路徑,并且也刪除了 avatar 及 system_prompt 部分的內容,同時與 cli 中的超參數進行了對齊)。
"""This script refers to the dialogue example of streamlit, the interactive
generation code of chatglm2 and transformers.We mainly modified part of the code logic to adapt to the
generation of our model.
Please refer to these links below for more information:1. streamlit chat example:https://docs.streamlit.io/knowledge-base/tutorials/build-conversational-apps2. chatglm2:https://github.com/THUDM/ChatGLM2-6B3. transformers:https://github.com/huggingface/transformers
Please run with the command `streamlit run path/to/web_demo.py--server.address=0.0.0.0 --server.port 7860`.
Using `python path/to/web_demo.py` may cause unknown problems.
"""
# isort: skip_file
import copy
import warnings
from dataclasses import asdict, dataclass
from typing import Callable, List, Optionalimport streamlit as st
import torch
from torch import nn
from transformers.generation.utils import (LogitsProcessorList,StoppingCriteriaList)
from transformers.utils import loggingfrom transformers import AutoTokenizer, AutoModelForCausalLM # isort: skiplogger = logging.get_logger(__name__)@dataclass
class GenerationConfig:# this config is used for chat to provide more diversitymax_length: int = 2048top_p: float = 0.75temperature: float = 0.1do_sample: bool = Truerepetition_penalty: float = 1.000@torch.inference_mode()
def generate_interactive(model,tokenizer,prompt,generation_config: Optional[GenerationConfig] = None,logits_processor: Optional[LogitsProcessorList] = None,stopping_criteria: Optional[StoppingCriteriaList] = None,prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor],List[int]]] = None,additional_eos_token_id: Optional[int] = None,**kwargs,
):inputs = tokenizer([prompt], padding=True, return_tensors='pt')input_length = len(inputs['input_ids'][0])for k, v in inputs.items():inputs[k] = v.cuda()input_ids = inputs['input_ids']_, input_ids_seq_length = input_ids.shape[0], input_ids.shape[-1]if generation_config is None:generation_config = model.generation_configgeneration_config = copy.deepcopy(generation_config)model_kwargs = generation_config.update(**kwargs)bos_token_id, eos_token_id = ( # noqa: F841 # pylint: disable=W0612generation_config.bos_token_id,generation_config.eos_token_id,)if isinstance(eos_token_id, int):eos_token_id = [eos_token_id]if additional_eos_token_id is not None:eos_token_id.append(additional_eos_token_id)has_default_max_length = kwargs.get('max_length') is None and generation_config.max_length is not Noneif has_default_max_length and generation_config.max_new_tokens is None:warnings.warn(f"Using 'max_length''s default ({repr(generation_config.max_length)}) \to control the generation length. "'This behaviour is deprecated and will be removed from the \config in v5 of Transformers -- we'' recommend using `max_new_tokens` to control the maximum \length of the generation.',UserWarning,)elif generation_config.max_new_tokens is not None:generation_config.max_length = generation_config.max_new_tokens + \input_ids_seq_lengthif not has_default_max_length:logger.warn( # pylint: disable=W4902f"Both 'max_new_tokens' (={generation_config.max_new_tokens}) "f"and 'max_length'(={generation_config.max_length}) seem to ""have been set. 'max_new_tokens' will take precedence. "'Please refer to the documentation for more information. ''(https://huggingface.co/docs/transformers/main/''en/main_classes/text_generation)',UserWarning,)if input_ids_seq_length >= generation_config.max_length:input_ids_string = 'input_ids'logger.warning(f"Input length of {input_ids_string} is {input_ids_seq_length}, "f"but 'max_length' is set to {generation_config.max_length}. "'This can lead to unexpected behavior. You should consider'" increasing 'max_new_tokens'.")# 2. Set generation parameters if not already definedlogits_processor = logits_processor if logits_processor is not None \else LogitsProcessorList()stopping_criteria = stopping_criteria if stopping_criteria is not None \else StoppingCriteriaList()logits_processor = model._get_logits_processor(generation_config=generation_config,input_ids_seq_length=input_ids_seq_length,encoder_input_ids=input_ids,prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,logits_processor=logits_processor,)stopping_criteria = model._get_stopping_criteria(generation_config=generation_config,stopping_criteria=stopping_criteria)logits_warper = model._get_logits_warper(generation_config)unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)scores = Nonewhile True:model_inputs = model.prepare_inputs_for_generation(input_ids, **model_kwargs)# forward pass to get next tokenoutputs = model(**model_inputs,return_dict=True,output_attentions=False,output_hidden_states=False,)next_token_logits = outputs.logits[:, -1, :]# pre-process distributionnext_token_scores = logits_processor(input_ids, next_token_logits)next_token_scores = logits_warper(input_ids, next_token_scores)# sampleprobs = nn.functional.softmax(next_token_scores, dim=-1)if generation_config.do_sample:next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)else:next_tokens = torch.argmax(probs, dim=-1)# update generated ids, model inputs, and length for next stepinput_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)model_kwargs = model._update_model_kwargs_for_generation(outputs, model_kwargs, is_encoder_decoder=False)unfinished_sequences = unfinished_sequences.mul((min(next_tokens != i for i in eos_token_id)).long())output_token_ids = input_ids[0].cpu().tolist()output_token_ids = output_token_ids[input_length:]for each_eos_token_id in eos_token_id:if output_token_ids[-1] == each_eos_token_id:output_token_ids = output_token_ids[:-1]response = tokenizer.decode(output_token_ids)yield response# stop when each sentence is finished# or if we exceed the maximum lengthif unfinished_sequences.max() == 0 or stopping_criteria(input_ids, scores):breakdef on_btn_click():del st.session_state.messages@st.cache_resource
def load_model():model = (AutoModelForCausalLM.from_pretrained('/root/ft/final_model',trust_remote_code=True).to(torch.bfloat16).cuda())tokenizer = AutoTokenizer.from_pretrained('/root/ft/final_model',trust_remote_code=True)return model, tokenizerdef prepare_generation_config():with st.sidebar:max_length = st.slider('Max Length',min_value=8,max_value=32768,value=2048)top_p = st.slider('Top P', 0.0, 1.0, 0.75, step=0.01)temperature = st.slider('Temperature', 0.0, 1.0, 0.1, step=0.01)st.button('Clear Chat History', on_click=on_btn_click)generation_config = GenerationConfig(max_length=max_length,top_p=top_p,temperature=temperature)return generation_configuser_prompt = '<|im_start|>user\n{user}<|im_end|>\n'
robot_prompt = '<|im_start|>assistant\n{robot}<|im_end|>\n'
cur_query_prompt = '<|im_start|>user\n{user}<|im_end|>\n\<|im_start|>assistant\n'def combine_history(prompt):messages = st.session_state.messagesmeta_instruction = ('')total_prompt = f"<s><|im_start|>system\n{meta_instruction}<|im_end|>\n"for message in messages:cur_content = message['content']if message['role'] == 'user':cur_prompt = user_prompt.format(user=cur_content)elif message['role'] == 'robot':cur_prompt = robot_prompt.format(robot=cur_content)else:raise RuntimeErrortotal_prompt += cur_prompttotal_prompt = total_prompt + cur_query_prompt.format(user=prompt)return total_promptdef main():# torch.cuda.empty_cache()print('load model begin.')model, tokenizer = load_model()print('load model end.')st.title('InternLM2-Chat-1.8B')generation_config = prepare_generation_config()# Initialize chat historyif 'messages' not in st.session_state:st.session_state.messages = []# Display chat messages from history on app rerunfor message in st.session_state.messages:with st.chat_message(message['role'], avatar=message.get('avatar')):st.markdown(message['content'])# Accept user inputif prompt := st.chat_input('What is up?'):# Display user message in chat message containerwith st.chat_message('user'):st.markdown(prompt)real_prompt = combine_history(prompt)# Add user message to chat historyst.session_state.messages.append({'role': 'user','content': prompt,})with st.chat_message('robot'):message_placeholder = st.empty()for cur_response in generate_interactive(model=model,tokenizer=tokenizer,prompt=real_prompt,additional_eos_token_id=92542,**asdict(generation_config),):# Display robot response in chat message containermessage_placeholder.markdown(cur_response + '▌')message_placeholder.markdown(cur_response)# Add robot response to chat historyst.session_state.messages.append({'role': 'robot','content': cur_response, # pylint: disable=undefined-loop-variable})torch.cuda.empty_cache()if __name__ == '__main__':main()在運行前,我們還需要做的就是將端口映射到本地。那首先我們使用快捷鍵組合 Windows + R(Windows 即開始菜單鍵)打開指令界面,并輸入命令,按下回車鍵。(Mac 用戶打開終端即可)打開 PowerShell 后,先查詢端口,再根據端口鍵入命令 (例如圖中端口示例為 38374):然后我們需要在 PowerShell 中輸入以下內容(需要替換為自己的端口號)
# 從本地使用 ssh 連接 studio 端口
# 將下方端口號 38374 替換成自己的端口號
ssh -CNg -L 6006:127.0.0.1:6006 root@ssh.intern-ai.org.cn -p 38374之后我們需要輸入以下命令運行 /root/personal_assistant/code/InternLM 目錄下的 web_demo.py 文件。
streamlit run /root/ft/web_demo/InternLM/chat/web_demo.py --server.address 127.0.0.1 --server.port 6006
注意:要在瀏覽器打開 http://127.0.0.1:6006 頁面后,模型才會加載。
打開 http://127.0.0.1:6006 后,等待加載完成即可進行對話,鍵入內容示例如下:
請介紹一下你自己效果圖如下:
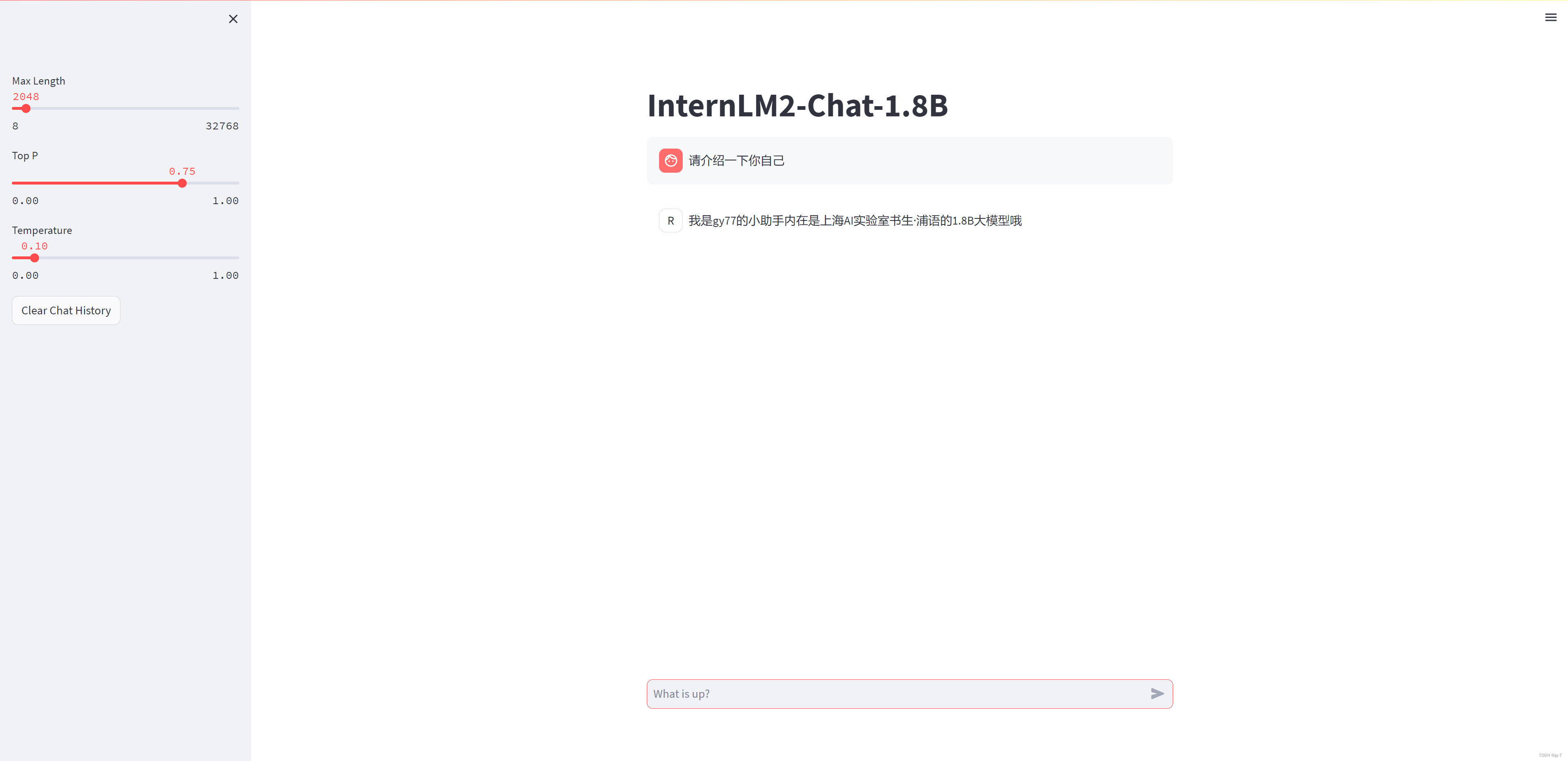
假如我們還想和原來的 InternLM2-Chat-1.8B 模型對話(即在 /root/ft/model 這里的模型對話),我們其實只需要修改183行和186行的文件地址即可。
# 修改模型地址(第183行)
- model = (AutoModelForCausalLM.from_pretrained('/root/ft/final_model',
+ model = (AutoModelForCausalLM.from_pretrained('/root/ft/model',# 修改分詞器地址(第186行)
- tokenizer = AutoTokenizer.from_pretrained('/root/ft/final_model',
+ tokenizer = AutoTokenizer.from_pretrained('/root/ft/model',然后使用上方同樣的命令即可運行。
streamlit run /root/ft/web_demo/InternLM/chat/web_demo.py --server.address 127.0.0.1 --server.port 6006加載完成后輸入同樣的問題 請介紹一下你自己 之后我們可以看到兩個模型截然不同的回復:
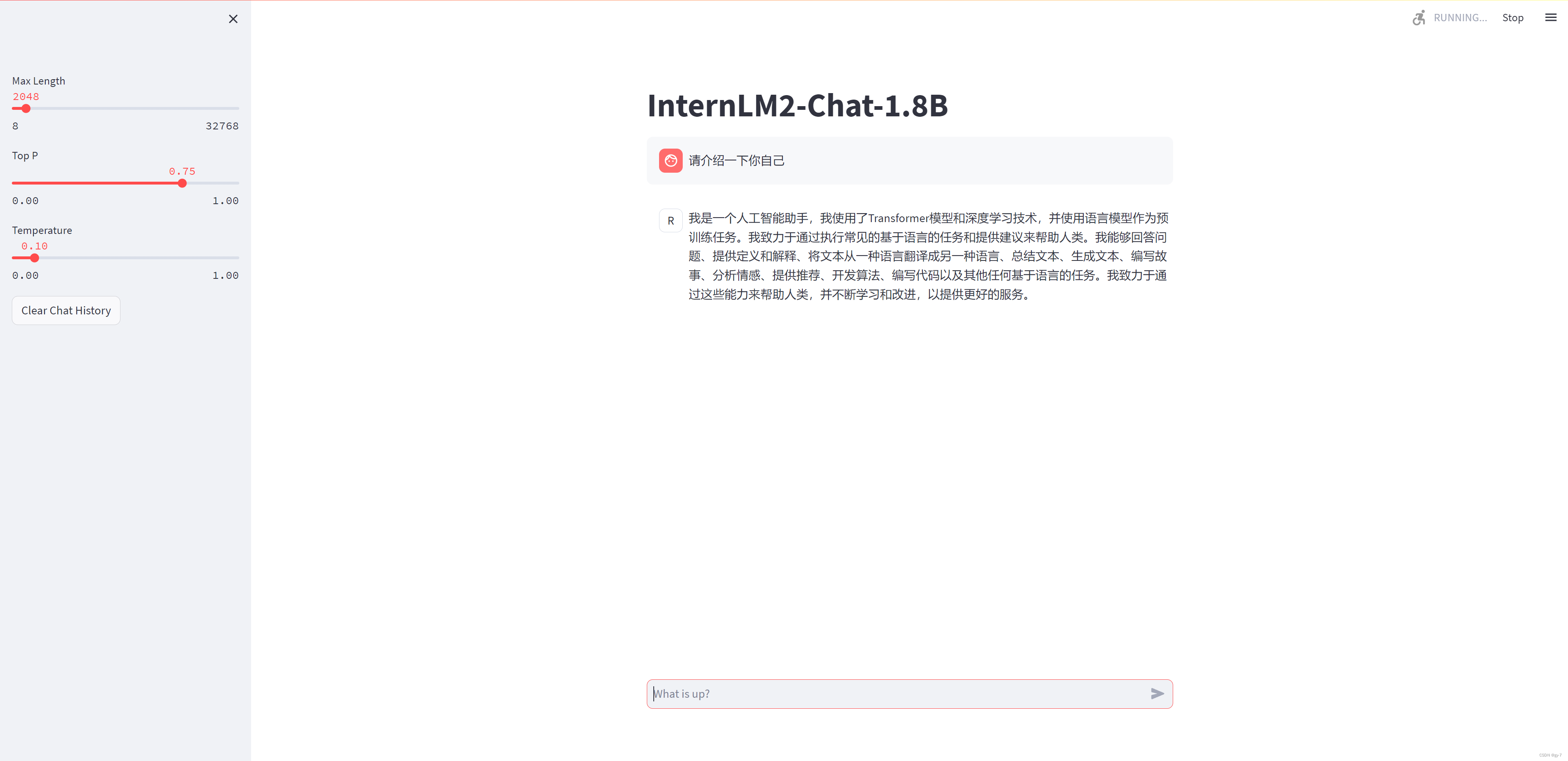
2.5.5. 小結
在這一小節里我們對微調后的模型(adapter)進行了轉換及整合的操作,并通過 xtuner chat 來對模型進行了實際的對話測試。從結果可以清楚的看出模型的回復在微調的前后出現了明顯的變化。那當我們在測試完模型認為其滿足我們的需求后,我們就可以對模型進行量化部署等操作了,這部分的內容在之后關于 LMDeploy 的課程中將會詳細的進行講解,敬請期待后續的課程吧!
2.6. 總結
在本節中主要就是帶領著大家跑通了 XTuner 的一個完整流程,通過了解數據集和模型的使用方法、配置文件的制作和訓練以及最后的轉換及整合。那在后面假如我們也有想要微調出自己的一個模型,我們也可以嘗試使用同樣流程和方法進行進一步的實踐!





)












)
