文章目錄
- 一、前言
- 二、Transformer
- 三、Hugging Face
- 3.1 Hugging Face Dataset
- 3. 2 Hugging Face Tokenizer
- 3.3 Hugging Face Transformer
- 3.4 Hugging Face Accelerate
- 四、基于Hugging Face調用模型
- 4.1 調用示例
- 4.2 調用流程概述
- 4.2.1 Tokenizer
- 4.2.2 模型的加載
- 4.2.3 模型基本邏輯
- 4.2.4 加入輸出頭
- 參考資料
一、前言
ChatGPT的基本原理以及預訓練大語言模型的發展史,我們知道ChatGPT和所有預訓練大語言模型的核心是什么?其實就是 Transformer,Hugging Face 的火爆離不開他們開源的這個 Transformers 庫。這個開源庫里有數萬個我們可以直接調用的模型。很多場景下,這個開源模型已經足夠我們使用了。接下來我們就從Transformer的架構和具體的案例來介紹Hugging Face Transformer。
二、Transformer
Transformer 是一種用于自然語言處理和其它序列到序列任務的神經網絡模型,它是在2017年由Vaswani等人提出來的 ,Transformer的核心模塊是通過自注意力機制(Self Attention) 捕捉序列之間的依賴關系。
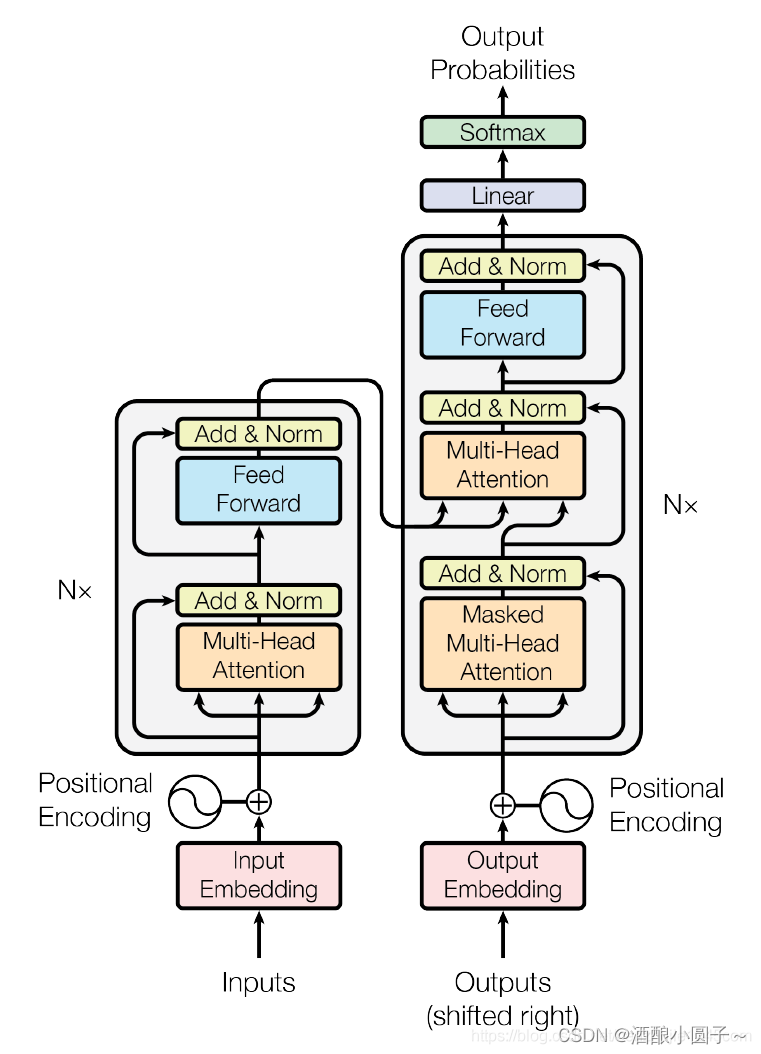
我們在之前的博客中介紹過Transformer,具體參考:Transformer 模型詳解
三、Hugging Face
Hugging Face Transformers 是一家公司,在Hugging Face提供的API中,我們幾乎可以下載到所有前面提到的預訓練大模型的全部信息和各種參數。我們可以認為這些模型在Hugging Face基本就是開源的了,我們只需要拿過來微調或者重新訓練這些模型。
用官方的話來說,Hugging Face Transformers 是一個用于自然語言處理的Python庫,提供了預訓練的語言模型和工具,使得研究者和工程師能夠輕松的訓練使用共享最先進的NLP模型,其中包括BERT、GPT、RoBERTa、XLNet、DistillBERT等等。
通過 Transformers 可以輕松的用這些預訓練模型進行文本分類、命名實體識別、機器翻譯、問答系統等NLP任務。這個庫還提供了方便的API、示例代碼和文檔,讓我們使用這些模型或者學習模型變得非常簡單。
Hugging Face官網:https://huggingface.co/

Hugging Face的主要產品包括Hugging Face Dataset、Hugging Face Tokenizer、Hugging Face Transformer和Hugging Face Accelerate。
-
Hugging Face Dataset:是一個庫,用于輕松訪問和共享音頻、計算機視覺和自然語言處理(NLP)任務的數據集。只需一行代碼即可加載數據集,并使用強大的數據處理方法快速準備好數據集,以便在深度學習模型中進行訓練。在Apache Arrow格式的支持下,以零拷貝讀取處理大型數據集,沒有任何內存限制,以實現最佳速度和效率。
-
Hugging Face Tokenizer:是一個用于將文本轉換為數字表示形式的庫。它支持多種編碼器,包括BERT、GPT-2等,并提供了一些高級對齊方法,可以用于映射原始字符串(字符和單詞)和標記空間之間的關系。
-
Hugging Face Transformer:是一個用于自然語言處理(NLP)任務的庫。它提供了各種預訓練模型,包括BERT、GPT-2等,并提供了一些高級功能,例如控制生成文本的長度、溫度等。
-
Hugging Face Accelerate:是一個用于加速訓練和推理的庫。它支持各種硬件加速器,例如GPU、TPU等,并提供了一些高級功能,例如混合精度訓練、梯度累積等。
3.1 Hugging Face Dataset
Hugging Face Dataset是一個公共數據集倉庫,用于輕松訪問和共享音頻、計算機視覺和自然語言處理(NLP)任務的數據集。只需一行代碼即可加載數據集,并使用強大的數據處理方法快速準備好數據集,以便在深度學習模型中進行訓練。
在Apache Arrow格式的支持下,以零拷貝讀取處理大型數據集,沒有任何內存限制,以實現最佳速度和效率。Hugging Face Dataset還與擁抱面部中心深度集成,使您可以輕松加載數據集并與更廣泛的機器學習社區共享數據集。
在花時間下載數據集之前,快速獲取有關數據集的一些常規信息通常會很有幫助。數據集的信息存儲在 DatasetInfo 中,可以包含數據集描述、要素和數據集大小等信息。
使用 load_dataset_builder() 函數加載數據集構建器并檢查數據集的屬性,而無需提交下載:
>>> from datasets import load_dataset_builder
>>> ds_builder = load_dataset_builder("rotten_tomatoes")# Inspect dataset description
>>> ds_builder.info.description
Movie Review Dataset. This is a dataset of containing 5,331 positive and 5,331 negative processed sentences from Rotten Tomatoes movie reviews. This data was first used in Bo Pang and Lillian Lee, ``Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales.'', Proceedings of the ACL, 2005.# Inspect dataset features
>>> ds_builder.info.features
{'label': ClassLabel(num_classes=2, names=['neg', 'pos'], id=None),'text': Value(dtype='string', id=None)}
如果您對數據集感到滿意,請使用 load_dataset() 加載它:
from datasets import load_datasetdataset = load_dataset("rotten_tomatoes", split="train")
3. 2 Hugging Face Tokenizer
Tokenizers 提供了當今最常用的分詞器的實現,重點是性能和多功能性。這些分詞器也用于Transformers。
Tokenizer 把文本序列輸入到模型之前的預處理,相當于數據預處理的環節,因為模型是不可能直接讀文字信息的,還是需要經過分詞處理,把文本變成一個個token,每個模型比如BERT、GPT需要的Tokenizer都不一樣,它們都有自己的字典,因為每一個模型它的訓練語料庫是不一樣的,所以它的token和它的字典大小、token的格式都會各有不同。整體來講,就是給各種各樣的詞進行分詞,然后編碼,以123456來代表詞的狀態,這個就是Tokenizer的作用。
所以,Tokenizer的任務就是把輸入的文本轉換成一個一個的標記,它還可以負責對文本序列的清洗、截斷、填充進行處理。簡而言之,就是為了滿足具體模型所要求的格式。
主要特點:
- 使用當今最常用的分詞器訓練新的詞匯表并進行標記化。
- 由于Rust實現,因此非常快速(訓練和標記化),在服務器CPU上對1GB文本進行標記化不到20秒。
- 易于使用,但也非常多功能。
- 旨在用于研究和生產。
- 完全對齊跟蹤。即使進行破壞性規范化,也始終可以獲得與任何令牌對應的原始句子部分。
- 執行所有預處理:截斷、填充、添加模型所需的特殊令牌。
這里演示如何使用 BPE 模型實例化一個:classTokenizer
from tokenizers import Tokenizer
from tokenizers.models import BPE
tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
3.3 Hugging Face Transformer
Transformers提供API和工具,可輕松下載和訓練最先進的預訓練模型。使用預訓練模型可以降低計算成本、碳足跡,并節省訓練模型所需的時間和資源。這些模型支持不同模態中的常見任務,例如:
- 自然語言處理:文本分類、命名實體識別、問答、語言建模、摘要、翻譯、多項選擇和文本生成。
- 計算機視覺:圖像分類、目標檢測和分割。
- 音頻:自動語音識別和音頻分類。
- 多模式:表格問答、光學字符識別、從掃描文檔中提取信息、視頻分類和視覺問答。
Transformers支持PyTorch、TensorFlow和JAX之間的框架互操作性。這提供了在模型的每個階段使用不同框架的靈活性;在一個框架中用三行代碼訓練一個模型,在另一個框架中加載它進行推理。模型還可以導出到ONNX和TorchScript等格式,以在生產環境中部署。
# 導入必要的庫
from transformers import AutoModelForSequenceClassification# 初始化分詞器和模型
model_name = "bert-base-cased"
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)# 將文本編碼為模型期望的張量格式
inputs = tokenizer(dataset["train"]["text"][:10], padding=True, truncation=True, return_tensors="pt")# 將編碼后的張量輸入模型進行預測
outputs = model(**inputs)# 獲取預測結果和標簽
predictions = outputs.logits.argmax(dim=-1)
3.4 Hugging Face Accelerate
Accelerate 是一個庫,只需添加四行代碼,即可在任何分布式配置中運行相同的 PyTorch 代碼!簡而言之,大規模的訓練和推理變得簡單、高效和適應性強。
from accelerate import Acceleratoraccelerator = Accelerator()model, optimizer, training_dataloader, scheduler = accelerator.prepare(model, optimizer, training_dataloader, scheduler
)
四、基于Hugging Face調用模型
首先需要安裝Hugging Face必要的庫:
pip install transformers
4.1 調用示例
首先安裝 transformers 依賴包:
pip install transformers
from transformers import pipeline#用人家設計好的流程完成一些簡單的任務
classifier = pipeline("sentiment-analysis")
classifier(["I've been waiting for a HuggingFace course my whole life.","I hate this so much!",]
)
這里重點講講pipeline,它是hugging face的基本工具,可以理解為一個端到端(end-to-end)的一鍵調用Transformer模型的工具。它具備了數據預處理、模型處理、模型輸出后處理等步驟,可以直接輸入原始數據,然后給出預測結果,十分方便,在第三部分調用流程中再詳細說明。通過pipeline,可以很方便地調用預訓練模型!
- 符合預期的正常結果,輸出情感分類的結果:
[{'label': 'POSITIVE', 'score': 0.9598049521446228},{'label': 'NEGATIVE', 'score': 0.9994558691978455}]
- 不符合預期的異常結果,輸出報錯信息:
OSError: We couldn't connect to 'https://huggingface.co' to load this file, couldn't find it in the cached files and it looks like google/mt5-small is not the path to a directory containing a file named config.json. Checkout your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/transformers/installation#offline-mode'.
【報錯原因】:Hugging Face模型在國外,國內服務器無法訪問到國外的模型,需要將模型下載到本地來加載。
【解決步驟】:
在HuggingFace官方找到對應的model:
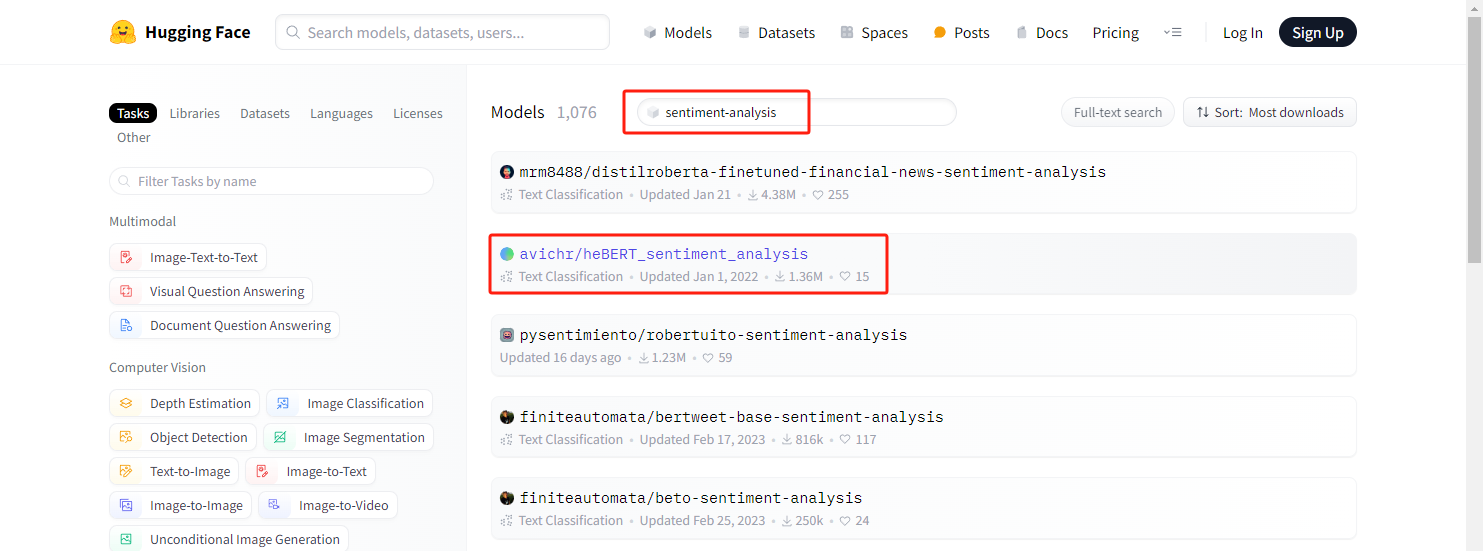
可以看到有非常多 sentiment-analysis 相關的模型,這里我們下載 avichr/heBERT_sentiment_analysis 這個model的相關文件:
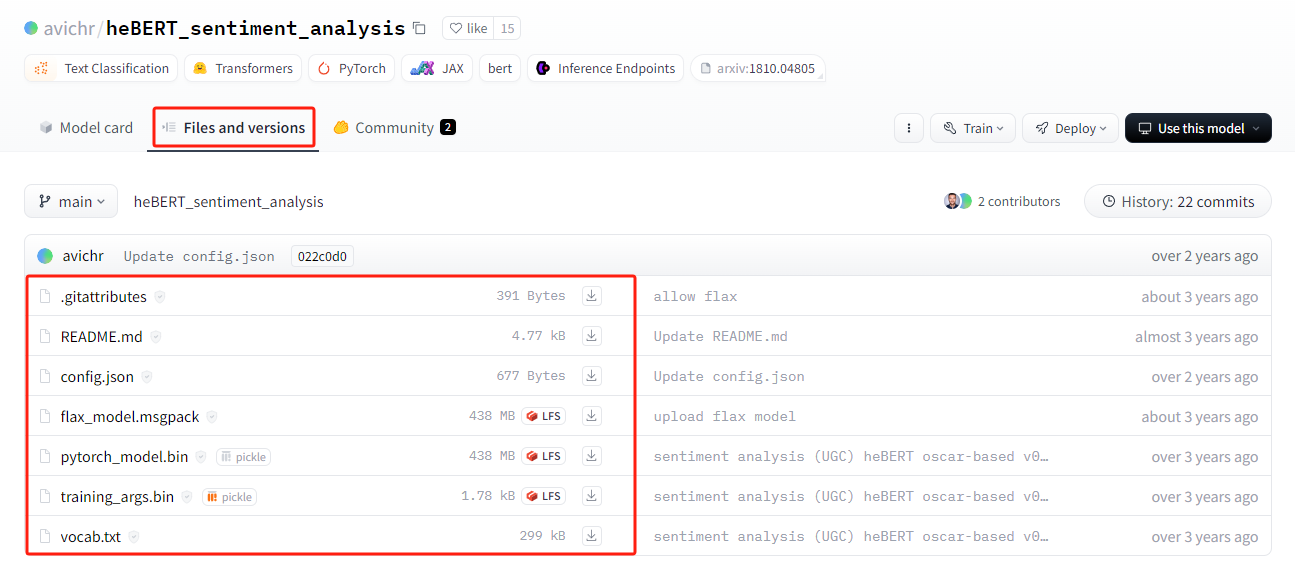
將下載的文件放到本地"./models/sentiment_analysis" 目錄下,并將代碼修改為:
from transformers import pipeline
model_path = "./models/sentiment_analysis"
classifier = pipeline("sentiment-analysis", model=model_path) # 通過本地路徑加載模型
classifier(["I've been waiting for a HuggingFace course my whole life.","I hate this so much!",]
)
4.2 調用流程概述
首先原始文本用Tokenizer進行分詞處理得到輸入的文本,然后通過模型進行學習,學習之后進行處理、預測分析。huggingface有個好處,分詞器、數據集、模型都封裝好了!很方便。

4.2.1 Tokenizer
Tokenizer會做3件事:
- 分詞,分字以及特殊字符(起始,終止,間隔,分類等特殊字符可以自己設計的)
- 對每一個token映射得到一個ID(每個詞都會對應一個唯一的ID)
- 還有一些輔助信息也可以得到,比如當前詞屬于哪個句子(還有一些MASK,表示是否是原來的詞還是特殊字符等)
Hugging Face中自帶AutoTokenizer工具,可以自動根據模型來判斷采用哪個分詞器:
from transformers import AutoTokenizer#自動判斷checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"#根據這個模型所對應的來加載
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
輸入文本:
raw_inputs = ["I've been waiting for a this course my whole life.","I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
打印結果(得到兩個字典映射,‘input_ids’,一個tensor集合,每個詞所對應的ID集合;attention_mask,一個tensor集合,表示是否是原來的詞還是特殊字符等):
{'input_ids': tensor([[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 2023, 2607, 2026, 2878,2166, 1012, 102],[ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0, 0, 0,0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0]])}如果想根據id重新獲得原始句子,如下操作:
tokenizer.decode([ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 2023, 2607, 2026, 2878,2166, 1012, 102])
生成的文本會存在特殊字符,這些特殊字符是因為人家模型訓練的時候就加入了這個東西,所以這里默認也加入了(google系的處理)
"[CLS] i've been waiting for a this course my whole life. [SEP]"
4.2.2 模型的加載
模型的加載直接指定好名字即可(先不加輸出層),這里checkpoint相當于一個文本,只是方便引用,checkpoint在hugging face中也是專門用來保留原來模型,然后再來訓練的。
另外AutoModel類也做下說明,AutoModel類及其相關模型類覆蓋了非常多模型。它能夠根據checkpoint名稱分析得到合適的模型架構,并且使用該架構實例化model,方便后續調用。
from transformers import AutoModelcheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
model
打印出來模型架構,就是DistilBertModel(蒸餾后的bert模型,模型參數大約只有原來的60%,訓練更快,但準確率下降不多)的架構了,能看到embeddings層、transformer層,看得還比較清晰:
DistilBertModel((embeddings): Embeddings((word_embeddings): Embedding(30522, 768, padding_idx=0)(position_embeddings): Embedding(512, 768)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False))(transformer): Transformer((layer): ModuleList((0): TransformerBlock((attention): MultiHeadSelfAttention((dropout): Dropout(p=0.1, inplace=False)(q_lin): Linear(in_features=768, out_features=768, bias=True)(k_lin): Linear(in_features=768, out_features=768, bias=True)(v_lin): Linear(in_features=768, out_features=768, bias=True)(out_lin): Linear(in_features=768, out_features=768, bias=True))(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(ffn): FFN((dropout): Dropout(p=0.1, inplace=False)(lin1): Linear(in_features=768, out_features=3072, bias=True)(lin2): Linear(in_features=3072, out_features=768, bias=True))(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True))(1): TransformerBlock((attention): MultiHeadSelfAttention((dropout): Dropout(p=0.1, inplace=False)(q_lin): Linear(in_features=768, out_features=768, bias=True)(k_lin): Linear(in_features=768, out_features=768, bias=True)(v_lin): Linear(in_features=768, out_features=768, bias=True)(out_lin): Linear(in_features=768, out_features=768, bias=True))(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(ffn): FFN((dropout): Dropout(p=0.1, inplace=False)(lin1): Linear(in_features=768, out_features=3072, bias=True)(lin2): Linear(in_features=3072, out_features=768, bias=True))(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True))(2): TransformerBlock((attention): MultiHeadSelfAttention((dropout): Dropout(p=0.1, inplace=False)(q_lin): Linear(in_features=768, out_features=768, bias=True)(k_lin): Linear(in_features=768, out_features=768, bias=True)(v_lin): Linear(in_features=768, out_features=768, bias=True)(out_lin): Linear(in_features=768, out_features=768, bias=True))(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(ffn): FFN((dropout): Dropout(p=0.1, inplace=False)(lin1): Linear(in_features=768, out_features=3072, bias=True)(lin2): Linear(in_features=3072, out_features=768, bias=True))(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True))(3): TransformerBlock((attention): MultiHeadSelfAttention((dropout): Dropout(p=0.1, inplace=False)(q_lin): Linear(in_features=768, out_features=768, bias=True)(k_lin): Linear(in_features=768, out_features=768, bias=True)(v_lin): Linear(in_features=768, out_features=768, bias=True)(out_lin): Linear(in_features=768, out_features=768, bias=True))(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(ffn): FFN((dropout): Dropout(p=0.1, inplace=False)(lin1): Linear(in_features=768, out_features=3072, bias=True)(lin2): Linear(in_features=3072, out_features=768, bias=True))(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True))(4): TransformerBlock((attention): MultiHeadSelfAttention((dropout): Dropout(p=0.1, inplace=False)(q_lin): Linear(in_features=768, out_features=768, bias=True)(k_lin): Linear(in_features=768, out_features=768, bias=True)(v_lin): Linear(in_features=768, out_features=768, bias=True)(out_lin): Linear(in_features=768, out_features=768, bias=True))(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(ffn): FFN((dropout): Dropout(p=0.1, inplace=False)(lin1): Linear(in_features=768, out_features=3072, bias=True)(lin2): Linear(in_features=3072, out_features=768, bias=True))(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True))(5): TransformerBlock((attention): MultiHeadSelfAttention((dropout): Dropout(p=0.1, inplace=False)(q_lin): Linear(in_features=768, out_features=768, bias=True)(k_lin): Linear(in_features=768, out_features=768, bias=True)(v_lin): Linear(in_features=768, out_features=768, bias=True)(out_lin): Linear(in_features=768, out_features=768, bias=True))(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(ffn): FFN((dropout): Dropout(p=0.1, inplace=False)(lin1): Linear(in_features=768, out_features=3072, bias=True)(lin2): Linear(in_features=3072, out_features=768, bias=True))(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True))))
)
從里面取一個TransformerBlock進行分析,如下所示,可以看出由 注意力層+標準化層+前饋神經網絡(全連接)層+標準化層 組成,可以看到每一層的邏輯,然后由多個TransformerBlock堆疊。哈哈,有這個東東要想改某一層只需要動動手調一調就行了!
TransformerBlock((attention): MultiHeadSelfAttention((dropout): Dropout(p=0.1, inplace=False)(q_lin): Linear(in_features=768, out_features=768, bias=True)(k_lin): Linear(in_features=768, out_features=768, bias=True)(v_lin): Linear(in_features=768, out_features=768, bias=True)(out_lin): Linear(in_features=768, out_features=768, bias=True))(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(ffn): FFN((dropout): Dropout(p=0.1, inplace=False)(lin1): Linear(in_features=768, out_features=3072, bias=True)(lin2): Linear(in_features=3072, out_features=768, bias=True))(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True))
看下輸出層的結構,這里**表示分配字典,按照參數順序依次賦值:
outputs = model(**inputs)
print(outputs.last_hidden_state.shape)
輸出:
torch.Size([2, 15, 768])
4.2.3 模型基本邏輯
根據上面代碼總結模型的邏輯:input—>詞嵌入—>Transformer—>隱藏層—>Head層。
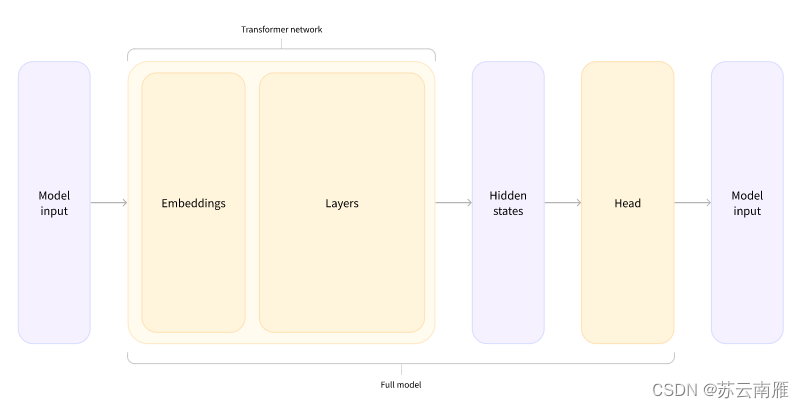
4.2.4 加入輸出頭
from transformers import AutoModelForSequenceClassificationcheckpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
print(outputs.logits.shape)
這里就得到分類后的結果:
torch.Size([2, 2])
再來看看模型的結構:
model
輸出:
DistilBertForSequenceClassification((distilbert): DistilBertModel((embeddings): Embeddings((word_embeddings): Embedding(30522, 768, padding_idx=0)(position_embeddings): Embedding(512, 768)(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(dropout): Dropout(p=0.1, inplace=False))(transformer): Transformer((layer): ModuleList((0): TransformerBlock((attention): MultiHeadSelfAttention((dropout): Dropout(p=0.1, inplace=False)(q_lin): Linear(in_features=768, out_features=768, bias=True)(k_lin): Linear(in_features=768, out_features=768, bias=True)(v_lin): Linear(in_features=768, out_features=768, bias=True)(out_lin): Linear(in_features=768, out_features=768, bias=True))(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(ffn): FFN((dropout): Dropout(p=0.1, inplace=False)(lin1): Linear(in_features=768, out_features=3072, bias=True)(lin2): Linear(in_features=3072, out_features=768, bias=True))(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True))(1): TransformerBlock((attention): MultiHeadSelfAttention((dropout): Dropout(p=0.1, inplace=False)(q_lin): Linear(in_features=768, out_features=768, bias=True)(k_lin): Linear(in_features=768, out_features=768, bias=True)(v_lin): Linear(in_features=768, out_features=768, bias=True)(out_lin): Linear(in_features=768, out_features=768, bias=True))(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(ffn): FFN((dropout): Dropout(p=0.1, inplace=False)(lin1): Linear(in_features=768, out_features=3072, bias=True)(lin2): Linear(in_features=3072, out_features=768, bias=True))(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True))(2): TransformerBlock((attention): MultiHeadSelfAttention((dropout): Dropout(p=0.1, inplace=False)(q_lin): Linear(in_features=768, out_features=768, bias=True)(k_lin): Linear(in_features=768, out_features=768, bias=True)(v_lin): Linear(in_features=768, out_features=768, bias=True)(out_lin): Linear(in_features=768, out_features=768, bias=True))(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(ffn): FFN((dropout): Dropout(p=0.1, inplace=False)(lin1): Linear(in_features=768, out_features=3072, bias=True)(lin2): Linear(in_features=3072, out_features=768, bias=True))(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True))(3): TransformerBlock((attention): MultiHeadSelfAttention((dropout): Dropout(p=0.1, inplace=False)(q_lin): Linear(in_features=768, out_features=768, bias=True)(k_lin): Linear(in_features=768, out_features=768, bias=True)(v_lin): Linear(in_features=768, out_features=768, bias=True)(out_lin): Linear(in_features=768, out_features=768, bias=True))(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(ffn): FFN((dropout): Dropout(p=0.1, inplace=False)(lin1): Linear(in_features=768, out_features=3072, bias=True)(lin2): Linear(in_features=3072, out_features=768, bias=True))(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True))(4): TransformerBlock((attention): MultiHeadSelfAttention((dropout): Dropout(p=0.1, inplace=False)(q_lin): Linear(in_features=768, out_features=768, bias=True)(k_lin): Linear(in_features=768, out_features=768, bias=True)(v_lin): Linear(in_features=768, out_features=768, bias=True)(out_lin): Linear(in_features=768, out_features=768, bias=True))(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(ffn): FFN((dropout): Dropout(p=0.1, inplace=False)(lin1): Linear(in_features=768, out_features=3072, bias=True)(lin2): Linear(in_features=3072, out_features=768, bias=True))(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True))(5): TransformerBlock((attention): MultiHeadSelfAttention((dropout): Dropout(p=0.1, inplace=False)(q_lin): Linear(in_features=768, out_features=768, bias=True)(k_lin): Linear(in_features=768, out_features=768, bias=True)(v_lin): Linear(in_features=768, out_features=768, bias=True)(out_lin): Linear(in_features=768, out_features=768, bias=True))(sa_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)(ffn): FFN((dropout): Dropout(p=0.1, inplace=False)(lin1): Linear(in_features=768, out_features=3072, bias=True)(lin2): Linear(in_features=3072, out_features=768, bias=True))(output_layer_norm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)))))(pre_classifier): Linear(in_features=768, out_features=768, bias=True)(classifier): Linear(in_features=768, out_features=2, bias=True)(dropout): Dropout(p=0.2, inplace=False)
)
之后采用softmax進行預測:
import torchpredictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
輸出:
tensor([[1.5446e-02, 9.8455e-01],[9.9946e-01, 5.4418e-04]], grad_fn=<SoftmaxBackward0>)
id2label這個我們后續可以自己設計,標簽名字對應都可以自己指定:
model.config.id2label
輸出:
{0: 'NEGATIVE', 1: 'POSITIVE'}
參考資料
- Hugging Face Transformer:從原理到實戰的全面指南
- Huggingface中Transformer模型使用












)






