提示:文章寫完后,目錄可以自動生成,如何生成可參考右邊的幫助文檔
文章目錄
- 摘要
- Abstract
- 文獻閱讀:DEA-Net:基于細節增強卷積和內容引導注意的單圖像去霧
- 1、研究背景
- 2、方法提出
- 3、相關知識
- 3.1、DEConv
- 3.3、多重卷積的計算
- 3.3、FAM
- 3.4、CGA
- 4、實驗
- 4.1、數據集
- 4.2、評價指標
- 4.3、實驗結果
- 5、貢獻
- 二、CGA模塊代碼學習
- 1、空間注意力模塊
- 2、通道注意力模塊
- 3、像素注意力模塊
- 總結
摘要
本周主要閱讀了文章,DEA-Net:基于細節增強卷積和內容引導注意的單圖像去霧。該論文提出了提出了一種細節增強注意力塊(DEAB),該模塊由一個細節增強卷積(DEConv)和一個內容引導的注意力(CGA)機制組成,使得模型能夠更好地保留圖像的細節信息,同時又能關注圖像中的重要信息,從而達到更好的去霧效果。除此之外,還學習學習了CGA模塊的注意力代碼模塊的學習。
Abstract
This week, I mainly read the article DEA-Net: Single Image De-Fogging Based on Detail Enhancement Convolution and Content Guided Attention. This paper proposes a detail enhancement attention block DEAB, which consists of a detail enhancement convolution DEConv and a content guided attention CGA mechanism. This module enables the model to better preserve the details of the image while also focusing on important information in the image, thus achieving better de-fogging effects. In addition, I also learned about the attention code module of the CGA module.
文獻閱讀:DEA-Net:基于細節增強卷積和內容引導注意的單圖像去霧
Title: DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention
Author:Zixuan Chen, Zewei He?, Zhe-Ming Lu
From:JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 1
1、研究背景
單張圖像去霧是一個低級視覺任務,旨在從單張受霧影響的圖像中恢復其清晰的場景。圖像去霧在許多計算機視覺應用中都有需求,例如自動駕駛、無人機、監控系統等。在這些應用中,準確的場景感知和物體識別對于系統的可靠性和安全性至關重要。當然單圖像去霧是一個具有挑戰性的問題,它從觀測到的霧圖像中估計潛在的無霧圖像。一些現有的基于深度學習的方法致力于通過增加卷積的深度或寬度來提高模型性能。卷積神經網絡(CNN)的學習能力仍然沒有得到充分探索。
2、方法提出
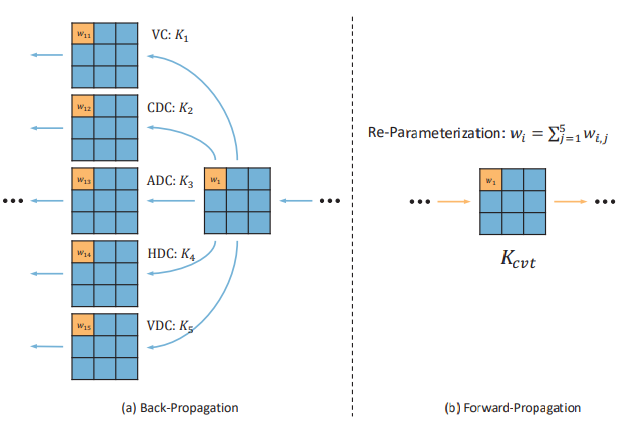
本文提出了一種細節增強注意力塊(DEAB),DEA-Net是一種用于單張圖像去霧的深度學習網絡。它采用類似U-Net的編碼器-解碼器結構,由三部分組成:編碼器部分、特征轉換部分和解碼器部分。在去霧等低級視覺任務中,從編碼器部分融合特征與解碼器部分的特征是一種有效的技巧。該模塊由一個細節增強卷積(DEConv)和一個內容引導的注意力(CGA)機制組成。DEConv包含并行的普通卷積和差異卷積,五個卷積層(四個差異卷積和一個普通卷積),這些卷積層并行部署用于特征提取。 此外,復雜的注意力機制(即CGA)是一個兩步注意力生成器,它可以首先產生粗略的空間注意力圖,然后對其進行細化。

3、相關知識
3.1、DEConv
DEConv包含五個卷積層(四個差異卷積和一個普通卷積),這些卷積層并行部署用于特征提取。具體來說,采用中心差分卷積(CDC)、角差分卷積(ADC)、水平差分卷積(HDC)和垂直差分卷積(VDC)將傳統的局部描述符集成到卷積層中,從而可以增強表示能力和泛化能力。在差異卷積中,首先計算圖像中的像素差異,然后與卷積核卷積以生成輸出特征圖。通過設計像素對的差異計算策略,可以將先驗信息顯式編碼到CNN中。這些卷積用于特征提取和學習,可以增強表示能力和泛化能力。
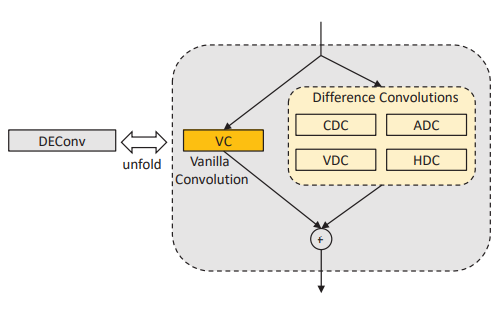
3.3、多重卷積的計算
VC、CDC、ADC、HDC和VDC的核函數,與圖像進行卷積,最后并行卷積結合在一起。
3.3、FAM
FAM(Feature attention module)是一種用于圖像去霧的注意力機制模塊,它包含通道注意力和空間注意力兩部分。FAM通過對不同通道和像素進行不平等處理,提高了去霧性能。然而,FAM的空間注意力只能在圖像級別上解決不均勻的霧分布問題,忽略了其他維度。以此有以下幾個缺點:
- 空間注意力機制:FAM中的空間注意力只能在圖像級別上解決不均勻的霧分布問題,這意味著它無法處理多尺度維度的霧分布問題。在處理具有復雜霧分布的圖像時,這可能會導致去霧效果不佳。
- 通道特異性SIMs(空間注意圖):FAM在計算注意力權重時,只使用了一個單一通道來表示輸入特征的重要區域,而輸入特征的通道數量相對較大。這可能導致注意力權重的計算不夠準確,從而影響去霧效果。
- 兩個注意力權重之間缺乏信息交換:在FAM中,通道注意力和空間注意力是順序計算的,它們之間沒有信息交換。這意味著它們可能無法充分考慮彼此的特點,從而影響去霧效果。
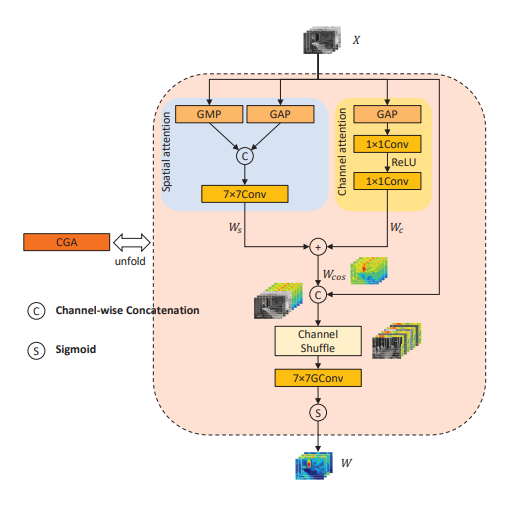
3.4、CGA
CGA(Content-Guided Attention)是一種內容引導注意力機制,用于提高圖像恢復任務中神經網絡的性能。CGA是一種粗細處理過程,首先生成粗略的空間注意力圖,然后根據輸入特征圖的每個通道進行細化,以產生最終的空間注意力圖。CGA通過使用輸入特征的內容來引導注意力圖的生成,從而更加關注每個通道的唯一特征部分,可以更好地重新校準特征,學習通道特定的注意力圖,以關注通道之間的霧霾分布差異。CGA的工作過程分為兩步:
- 生成粗略的空間注意力圖。這是一個粗細處理過程,通過生成一個粗略的注意力圖,可以快速捕捉到圖像中的主要特征。
- 根據輸入特征圖的每個通道對注意力圖進行細化。這一步的目的是使注意力圖更加精確,能夠關注到特征圖中的獨特部分。
4、實驗
4.1、數據集
- SOTS:SOTS是一個包含1000張室內和室外清晰圖像以及對應的帶有不同霧度的模糊圖像的數據集。該數據集分為訓練集、驗證集和測試集。SOTS數據集的圖像具有豐富的場景和復雜的霧度,因此可以有效地評估圖像去霧方法在各種情況下的性能。
- Haze4K:Haze4K數據集包含4000張帶有不同霧度的室內和室外圖像,用于訓練和測試圖像去霧方法。該數據集分為訓練集和測試集。Haze4K數據集的圖像具有較高的分辨率和豐富的場景,可以有效地訓練和評估圖像去霧方法。
4.2、評價指標
- PSNR:峰值信噪比(Peak Signal-to-Noise Ratio)是一種用于衡量圖像質量的評價指標。它通過計算去霧圖像與清晰圖像之間的均方誤差(MSE)來評估圖像去霧方法的性能。PSNR的計算公式為:PSNR = 10 * log10(255^2 / MSE) 。其中,255是像素值的范圍,MSE是去霧圖像與清晰圖像之間的均方誤差。PSNR值越高,說明去霧圖像的質量越好,圖像去霧方法的性能也就越好。
- SSIM:結構相似度指數(Structural Similarity Index)是一種用于衡量圖像結構信息的評價指標。它通過比較去霧圖像與清晰圖像之間的亮度、對比度和結構信息來評估圖像去霧方法的性能。SSIM的計算公式為:SSIM = (2 * μx * μy + C1) * (2 * σxy + C2) / ((μx^2 + μy^2 + C1) * (σx^2 + σy^2 + C2))。其中,μx和μy分別是去霧圖像和清晰圖像的平均灰度值,σx2和σy2分別是去霧圖像和清晰圖像的方差,σxy是去霧圖像和清晰圖像的協方差,C1和C2是常數。SSIM值越高,說明去霧圖像的結構信息與清晰圖像越相似,圖像去霧方法的性能也就越好。
4.3、實驗結果

5、貢獻
-
Detail-Enhanced Convolution (DEConv)
作者提出了Detail-Enhanced Convolution (DEConv),這是一種包含并行的vanilla和difference卷積的新型卷積方式。DEConv第一次引入差分卷積來解決圖像去噪問題。傳統的卷積操作主要是通過滑動窗口在輸入圖像上進行操作,而差分卷積則是在卷積操作中引入了差分的思想,使得卷積核在不同的位置具有不同的權重,這樣可以更好地捕捉圖像中的細節信息,提高去噪效果。DEConv的引入,使得模型能夠更好地保留圖像的細節信息,提高圖像去霧的性能。 -
Content-Guided Attention (CGA)
作者還提出了Content-Guided Attention (CGA),這是一種創新的注意力機制。CGA為每個通道分配唯一的SIM,引導模型關注每個通道的重要區域。這樣可以強調編碼在特征中的更多有用信息,以有效提高去霧性能。CGA的引入,使得模型能夠更加關注圖像中的重要信息,忽略無關的信息,從而提高圖像去霧的效果。此外,作者還將DEConv與CGA相結合,提出了DEA-Net的主要模塊,即細節增強注意模塊 (DEAB)。DEAB的引入,使得模型能夠更好地保留圖像的細節信息,同時又能關注圖像中的重要信息,從而達到更好的去霧效果 。
二、CGA模塊代碼學習
1、空間注意力模塊
class SpatialAttention(nn.Module):def __init__(self):super(SpatialAttention, self).__init__()self.sa = nn.Conv2d(2, 1, 7, padding=3, padding_mode='reflect', bias=True)# 定義一個二維卷積層self.sa,輸入通道數為2,輸出通道數為1,卷積核大小為7x7 # padding=3表示在輸入數據的周圍填充3個像素,保持空間尺寸不變 # padding_mode='reflect'表示使用反射填充方式 # bias=True表示卷積層使用偏置項 def forward(self, x): x_avg = torch.mean(x, dim=1, keepdim=True) # 計算輸入x在通道維度(dim=1)上的平均值,并保持輸出的維度與輸入相同 x_max, _ = torch.max(x, dim=1, keepdim=True) # 找到輸入x在通道維度上的最大值,并忽略最大值的索引(用_表示) # 同樣保持輸出的維度與輸入相同 x2 = torch.cat([x_avg, x_max], dim=1) # 將x_avg和x_max沿著通道維度(dim=1)拼接起來,得到新的張量x2 # 此時x2的通道數是x的兩倍 sattn = self.sa(x2) # 將x2作為輸入傳遞給之前定義的卷積層self.sa,得到輸出sattn return sattn # 返回計算得到的空間注意力圖sattn
2、通道注意力模塊
class ChannelAttention(nn.Module): def __init__(self, dim, reduction=8): # 初始化方法,接收輸入特征的通道數dim和一個可選的通道數減少比例reduction(默認為8) super(ChannelAttention, self).__init__() # 定義了一個自適應平均池化層,輸出大小為1x1,用于對每個通道內的所有元素進行平均 self.gap = nn.AdaptiveAvgPool2d(1) # 定義了一個順序模型self.ca,包含兩個卷積層和一個ReLU激活函數 self.ca = nn.Sequential( # 第一個卷積層將輸入特征的通道數從dim減少到dim // reduction,使用1x1的卷積核,無填充,并使用偏置 nn.Conv2d(dim, dim // reduction, 1, padding=0, bias=True), # ReLU激活函數對第一個卷積層的輸出進行非線性變換,inplace=True表示直接在輸入數據上進行修改 nn.ReLU(inplace=True), # 第二個卷積層將通道數從dim // reduction恢復到原始的dim,同樣使用1x1的卷積核和無填充 nn.Conv2d(dim // reduction, dim, 1, padding=0, bias=True), ) def forward(self, x): # 對輸入x進行自適應平均池化操作,得到每個通道的平均值 x_gap = self.gap(x) # 將池化后的結果x_gap傳遞給self.ca順序模型,計算通道注意力權重 cattn = self.ca(x_gap) # 返回計算得到的通道注意力權重 return cattn
3、像素注意力模塊
class PixelAttention(nn.Module): def __init__(self, dim): super(PixelAttention, self).__init__() # 定義一個二維卷積層,輸入通道數為2*dim,輸出通道數為dim, # 卷積核大小為7x7,填充大小為3(使用reflect模式),分組數為dim,并使用偏置項。 self.pa2 = nn.Conv2d(2 * dim, dim, 7, padding=3, padding_mode='reflect', groups=dim, bias=True) # 定義一個Sigmoid激活函數 self.sigmoid = nn.Sigmoid() def forward(self, x, pattn1): """ 前向傳播方法,接收兩個輸入:特征圖x和另一個注意力圖pattn1。 """ # 獲取輸入x的形狀 B, C, H, W = x.shape # 在x的通道維度之后增加一個新的維度,大小為1 x = x.unsqueeze(dim=2) # 在pattn1的通道維度之后增加一個新的維度,大小為1 pattn1 = pattn1.unsqueeze(dim=2) # 將x和pattn1在第二個維度(現在的大小為2)上進行拼接 x2 = torch.cat([x, pattn1], dim=2) # 使用Rearrange函數對x2的形狀進行重排,將通道數和第二個維度的大小合并成一個維度 x2 = Rearrange('b c t h w -> b (c t) h w')(x2) # 將重排后的x2輸入到卷積層self.pa2中 pattn2 = self.pa2(x2) # 對卷積層的輸出應用Sigmoid激活函數 pattn2 = self.sigmoid(pattn2) # 返回計算得到的像素注意力權重pattn2 return pattn2 總結
本周主要閱讀了文章,DEA-Net:基于細節增強卷積和內容引導注意的單圖像去霧。該論文提出了提出了一種細節增強注意力塊(DEAB),該模塊由一個細節增強卷積(DEConv)和一個內容引導的注意力(CGA)機制組成,使得模型能夠更好地保留圖像的細節信息,同時又能關注圖像中的重要信息,從而達到更好的去霧效果。除此之外,我還學習學習了CGA模塊的注意力代碼模塊的學習。下周再接再厲

 -- 將一天的時間進行等步長分割)

+聯合體(union))
)
無類別域間路由)






:Kubernetes 控制器之 Job)


——多表關系介紹)



