文章目錄
- 前言
- 一、字節流
- 1.1 讀文件
- 1.2 寫文件
- 二、字符流
- 2.1 讀文件
- 2.2 寫文件
- 三、文件IO三道例題
前言
在這里對Java標準庫中對文件內容的操作進行總結,總體上分為兩部分,字節流和字符流,就是以字節為單位讀取文件和以字符為單位讀取文件內容。
一、字節流
1.1 讀文件
字節流在Java中的類就是InputStream,他是一個抽象類,我們在這里操作的文件所以就需要通過它的子類FileInputStream向上轉型的方式,因為InputStream不能初始化。后面如果我們要進行網絡IO,就也是使用相對應的子類來進行實現。
代碼示例1:
package io;import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;public class Demo6 {public static void main(String[] args) throws IOException {
// 讀文件的兩種不同參數的read方法的使用
// InputStream inputStream = new FileInputStream("F:/test.txt");
// while (true) {
// int b = inputStream.read();
// if (b == -1) {
// break;
// }
// System.out.printf("0x%x ", b);
// }
// System.out.println();// while (true) {
// byte[] arrB = new byte[1024];
// int n = inputStream.read(arrB);
// System.out.println("n = " + n);
// if(n==-1) {
// //讀畢 n就會返回-1
// // 在這里首先第一次會把數組填滿 后面第二次循環文件內沒字節了就返回-1
// break;
// }
// for (int i = 0; i < n; i++) {
// System.out.printf("0x%x ", arrB[i]);
//
// }
// System.out.println();
// }
//
// } }}這段代碼是使用字節流來讀取文件內容的一個簡單過程,因為我們讀取硬盤中的文件內容給內存中的變量去接受,顯然數據是往cpu的方向流動的,因此是一個輸入的過程,我們使用InputStream抽象類以及FileInputStream類進行向上轉型來構造這樣的一個字節流對象。我們想要讀取哪個文件中的信息就可以將文件的路徑或者File類對象用以初始化字節流對象,如下。
InputStream inputStream = new FileInputStream("F:/test.txt");
FileInputStream這樣的字節流對象提供了一些讀取文件數據的方法如下圖。
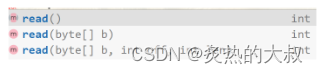
這三種方法有些許的不同,首先read方法,它每次讀取一個字節,然后返回值就是就是這個字節的相應的ASCII值,如果說讀到文件末尾那么此時就會返回-1。那么既然每次都是讀一個字節,返回的就是一個字節的范圍,那么返回值類型直接設為byte即可,那么為什么會設為int類型的返回呢?
有以下幾點原因:
(1)確保每次返回的數都是正數,因為從原則上說字節這樣的概念本身是無符號的但是byte類型本身是有符號的,如果說你拿byte來返回無符號數,那么范圍是0~255,此時就無法表示-1。只有你使用int類型,才能夠返回值是正數,還能使用-1來表示文件結尾。
(2)這時我們又會想到,那么我們直接用short不就行了,這樣也就可以包含-1以及0到255的整數。但是這里就涉及到計算機發展的問題了,因為計算機發展到現在存儲空間不再是核心矛盾了,存儲設備的成本是越來越便宜了,此時隨著cpu越來越牛,它單次處理數據的長度也越來越長。對于32位cpu,一次就能夠處理四個字節的數據,此時要是使用short還要將其轉成int再按int進行處理,顯然64位cpu也是類似的,此時的short就更沒意義了,我們學過的c語言中的整形提升也是類似的道理。因此在我們使用short的場景換成int,在我們使用float的場景我們換成double。
這里補充一下,為什么說字節數據從原則上是無符號的,因為字節數據不是用來進行算數運算的,例如一張圖片就是由很多字節數據構成的,如果對其字節進行加一或者減一操作,那么這張圖像很可能直接崩掉
第二個read方法和第一個read方法不同的點在于它的參數是一個字節數組,這個數組是一個空數組,讀文件數據的時候就會把讀到的數據全放到這個數組當中,去把這個字節數組給填滿,能填多少填多少。返回值也是類似,你讀到多少個字節就返回多少,讀到文件尾就返回-1。
第三個read方法其實和第二個read方法就很類似了,也是建立一個空數組來作為參數,然后指定一個區間,讀到的文件數據只放到這個空數組的對應區間當中。返回值就和第二個read方法一樣了,讀到多少字節就返回多少,讀到文件尾就返回-1。
這里提一嘴,read()和read(byte[] b)這兩種方法誰的效率比較高?
事實上是第二個方法的效率高,我們都知道第一個方法是一次讀取一個字節,第二個方法是一次讀一個數組的字節,對于固定的文件內容,肯定是第二個方法讀取的次數比較少,文件的IO在我們的代碼中是一個比較低效的操作,每次讀取都要進行一次IO,顯然IO次數少的方法效率就更高。
此時我們把視角轉回上面的代碼示例1,我們分別使用方法1和方法2來讀取文件數據,然后在外面套一個死循環,當read方法返回-1代表讀到文件尾此時跳出循環,邏輯還是比較簡單的。
代碼示例2:
package io;import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;public class Demo6 {public static void main(String[] args) throws IOException {// 但是每當建立一個線程或進程 建立的PCB中的文件描述符表這個順序表它的長度是有限的// 每當打開一個文件 它的長度就要加一、// 所以打開文件后要及時關閉// 所以這里聯想到處理unlock()的方法 即使用try finally語句
// InputStream inputStream = new FileInputStream("F:/test.txt");
// try {
// while (true) {
// byte[] arrB = new byte[1024];
// int n = inputStream.read(arrB);
// System.out.println("n = " + n);
// if (n == -1) {
// //讀畢 n就會返回-1
// // 在這里首先第一次會把數組填滿 后面第二次循環文件內沒字節了就返回-1
// break;
// }
// for (int i = 0; i < n; i++) {
// System.out.printf("0x%x ", arrB[i]);
// }
// System.out.println();
// }
// } finally {
// inputStream.close();
// }}}}上述代碼相對于代碼示例1加入了try-finally這樣的代碼,因為如同代碼中注釋所描述的每次你打開一個文件,就會在PCB當中的文件描述符表當中添加一個元素,這個元素當中就是文件的相關信息,文件描述符表類似于一個順序表,它總會有上限當這樣不關閉文件的操作多了,會占滿文件描述符表,此時若是再想打開文件就不行了。因此每次我們使用FileInputStream構造流對象打開文件讀取文件內容等一系列操作之后就要關閉文件,使用try-finally就可以保證每次使用完文件之后能夠關閉文件的流對象,此時文件描述符表中的對應元素就會被釋放。
代碼示例3:
package io;import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;public class Demo6 {public static void main(String[] args) throws IOException {// 使用try finally確實可以 但是作為一個程序員要追求去寫優雅的代碼// 上述代碼修改如下// 直接將流對象的創建放到try右邊的括號中 這樣java會自動幫你調用close()// 注意不是什么對象都可以這樣 必須要實現Closeable接口的類才可以try (InputStream inputStream = new FileInputStream("F:/test.txt");){while (true) {byte[] arrB = new byte[1024];int n = inputStream.read(arrB);System.out.println("n = " + n);if (n == -1) {//讀畢 n就會返回-1// 在這里首先第一次會把數組填滿 后面第二次循環文件內沒字節了就返回-1break;}for (int i = 0; i < n; i++) {System.out.printf("0x%x ", arrB[i]);}System.out.println();}}}}代碼示例2我們解決了關閉文件流對象釋放文件描述符表中元素的問題,但是使用try-catch好像不夠優雅,于是我們將InputStream流對象構造的這條語句放入try,這樣java會在文件操作完成之后自動給我們的流對象調用close方法,但是要注意的一點就是這種編寫方式的前提是放入try后的括號的對象對應的類必須實現了Closeable接口。
另外在我們使用FileInputStream類對象時可以配合Scanner對象來進行使用,代碼示例如下:
package io;import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
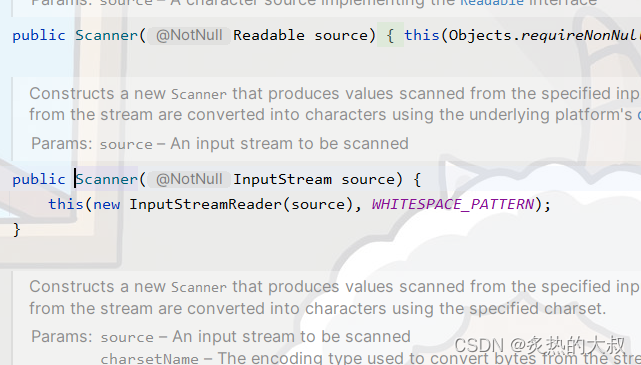
import java.util.Scanner;public class Demo10 {public static void main(String[] args) {try (InputStream inputStream = new FileInputStream("F:/test.txt")) {Scanner sc = new Scanner(inputStream);// 本來這里要在控制臺輸入 但是現在直接將文件中的數據讀走了sc.next();} catch (IOException e) {throw new RuntimeException(e);}}}以前我們使Scanner對象都是在終端輸入數據,這樣寫代碼就是將我們從終端輸入的數據換成了文件中的數據。另外能這么寫的原因看下圖Scanner類的構造函數的參數就不難理解了,本來就是InputStream類型的,另外我們在之前寫入Scanner對象的System.in也是InputStream類型的。
1.2 寫文件
寫文件的流程和讀文件的流程類似的,需要使用OutputStream抽象類以及其子類FileOutputStream。寫文件也要通過FileOutputStream對象的write方法來實現,FileOutputStream對象的write也是要分為三個版本,如下圖。

和前面的read參數很類似,第一個版本就是一次在文件中寫入一個字節,寫入的字節由b指定。第二個版本就是一次寫入文件一整個數組,第三個版本也是往文件中寫入一個數組,只是只寫入數組在區間內的部分。
代碼示例如下:
package io;import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;public class Demo7 {public static void main(String[] args) {try (OutputStream outputStream = new FileOutputStream("F:/test.txt",true)) {// 注意這里打開文件會發現文件內原本的內容被清空 里面全是新添加的內容// 這里的清空操作是打開文件時清空的,即構造對象時清空的// 要是想在文件內追加即append內容 只需在構造對象時將第二個參數設為trueoutputStream.write(97);outputStream.write(98);outputStream.write(98);outputStream.write(99);} catch (IOException e) {throw new RuntimeException(e);}}}這里寫入文件的代碼需要注意一點就是構造FileOutputStream對象時會直接將對應路徑上的文件內容給清空,如果想要實現寫入文件是一種append的效果,就要在構造流對象時將第二個參數設為true。示例代碼中的注釋也說明了。
二、字符流
使用字符流和字節流操作文件內容基本的流程是類似的,但是字符流讀取和寫入文件內容的基本單位是字符,字節流是字節。
2.1 讀文件
使用字符流讀文件過程和使用字節流讀文件的流程是相似的,只有很少的差別。
代碼示例如下:
package io;import java.io.FileReader;
import java.io.IOException;
import java.io.Reader;public class Demo8 {public static void main(String[] args) {try (Reader reader = new FileReader("./testDir/test2.txt")) {// 讀入字符的時候要思考一個問題// 文件中的字符編碼集用的是utf8 一個中文字是三個字節// java中的一個中文字是兩個字節// 為什么java中的char還能接收并且打印中文字// 原因:因為在java中的char類型在接收字符時會自動將utf8轉換為unicode編碼集// 實際上java中很多類型在接收數據時都會進行字符集的轉換while (true) {int n = reader.read();if(n==-1) {break;}System.out.printf("%c ",n);}} catch (IOException e) {throw new RuntimeException(e);}}}如以上的示例代碼,與字節流的FileinputStream不同這里讀文件內容使用的是FileReader類,過程還是類似的,外面套個循環,每次讀取一個字符,直到讀取操作返回值為-1代表文件讀完此時跳出循環。
但是這里會有一個疑問,在windows下文件中的字符是采用utf8的編碼集,在這個編碼集當中單個漢字的字節數是三個,為什么在java中還能使用char類型接收漢字并且打印,char類型在java中只有兩個字節。這個問題的答案就是說java中讀取到文件中內容時會自動轉換編碼集,對于char類型java中使用的時unicode編碼集,讀到的文件中漢字會自動轉為char類型,也就會經過utf8到unicode這個過程,在unicode當中漢字占兩個字節。
在java中不同的類型實際上用的編碼集都是不同的,比如說String類型內部是使用utf8,char類型使用的是unicode。使用String類型變量保存你好就需要6個字節,當使用字符串s.charAt()這種方法將字符賦給char類型變量時,就會將編碼集從utf8轉為unicode,此時一個字就從三個字節轉為了兩個字節。
2.2 寫文件
流程都是類似的,寫文件的操作主要是通過Writer類中的write方法來實現的。
代碼示例如下:
package io;import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;public class Demo9 {public static void main(String[] args) {try (Writer writer = new FileWriter("F:/test.txt")) {// 字符流寫文件和字節流一樣 都是要加上一個true這個參數才能實現append這樣的效果writer.write("你好世界");} catch (IOException e) {throw new RuntimeException(e);}}
}和字節流的write一樣,要想在寫文件時實現append的效果就需要在構建FileWriter對象時將第二個參數設為true,否則寫文件時都會先清空路徑上的文件內容。
三、文件IO三道例題
(1)掃描指定目錄,并找到名稱中包含指定字符的所有普通文件(包含目錄)。
package io;import java.io.File;
import java.util.Scanner;public class Demo11 {public static void main(String[] args) {Scanner sc = new Scanner(System.in);System.out.println("輸入要查找文件的目錄:");String dirPath = sc.nextLine();System.out.println("輸入要查找文件的關鍵詞:");String keyWord = sc.nextLine();// 根據輸入的路徑構造file對象File dir = new File(dirPath);// 如果輸入的路徑不是目錄則直接返回并報錯if (!dir.isDirectory()) {System.out.println("輸入路徑非法!");return;}// 關鍵詞和目錄都是正確的那么就開始查找文件searchFile(dir, keyWord);}private static void searchFile(File dir, String keyWord) {// 將目錄下的所有文件輸出成數組File[] files = dir.listFiles();// 如果數組為空直接返回 這也是遞歸結束的條件if (files == null) {return;}// 遍歷數組for (File file : files) {// 如果文件是文件 那么判斷是否包含關鍵詞if (file.isFile()) {// 包含則匹配成功if (file.getName().contains(keyWord)) {System.out.println("匹配成功:" + file.getAbsoluteFile());}// 如果是目錄則進行遞歸 在下一級目錄進行查找} else if (file.isDirectory()) {searchFile(file, keyWord);}}}
}(2)復制文件,輸入一個路徑,表示要被復制的文件,輸入另一個路徑,表示要復制到的目標路徑。
package io;import java.io.*;
import java.util.Scanner;public class Demo12 {public static void main(String[] args) throws IOException {Scanner sc = new Scanner(System.in);System.out.println("輸入要復制的文件路徑:");String srcPath = sc.nextLine();System.out.println("輸入要復制到的文件路徑");String destPath = sc.nextLine();File fileSrc = new File(srcPath);File fileDest = new File(destPath);if (!fileSrc.isFile()) {System.out.println("輸入的要復制的文件路徑不合法!");return;}if (!fileDest.getParentFile().isDirectory()) {System.out.println("輸入的復制到的文件路徑不合法!");return;}byte[] bytes = new byte[1024];// OutPutStream會自動創建文件try (InputStream inputStream = new FileInputStream(fileSrc);OutputStream outputStream = new FileOutputStream(fileDest)) {while (true) {int n = inputStream.read(bytes);if (n == -1) {break;}outputStream.write(bytes, 0, n);}} catch (IOException e) {throw new RuntimeException(e);}}
}(3)輸入一個路徑再輸入一個查詢詞,搜索這個路徑中文件內容包含這個查詢次的文件。
package io;import java.io.*;
import java.util.Scanner;public class Demo13 {public static void main(String[] args) {Scanner sc = new Scanner(System.in);System.out.println("請輸入目標目錄:");String dirPath = sc.nextLine();System.out.println("請輸入要匹配的關鍵詞:");String keyWord = sc.nextLine();File dirFile = new File(dirPath);if (!dirFile.isDirectory()) {System.out.println("輸入路徑不合法!!");return;}search(dirFile, keyWord);}private static void search(File dirFile, String keyWord) {File[] files = dirFile.listFiles();if (files == null) {return;}for (File f :files) {if (f.isFile()) {match(f, keyWord);} else if (f.isDirectory()) {search(f, keyWord);}}}private static void match(File f, String keyWord) {StringBuilder stringBuilder = new StringBuilder();try (Reader reader = new FileReader(f)) {while (true) {int b = reader.read();if (b == -1) {break;}stringBuilder.append((char) b);}} catch (IOException e) {throw new RuntimeException(e);}if (stringBuilder.indexOf(keyWord) >= 0) {System.out.println("匹配成功:" + f.getAbsolutePath());}}}![[AI Google] 介紹 VideoFX,以及 ImageFX 和 MusicFX 的新功能](http://pic.xiahunao.cn/[AI Google] 介紹 VideoFX,以及 ImageFX 和 MusicFX 的新功能)




)






)




)

