
檢索增強生成 (Retrieval Augmented Generation,RAG) 可將存儲在外部數據庫中的新鮮領域知識納入大語言模型以增強其文本生成能力。其提供了一種將公司數據與訓練期間語言模型學到的知識分開的方式,有助于我們在性能、準確性及安全隱私之間進行有效折衷。
通過本文,你將了解到英特爾如何通過企業 AI 開放平臺 OPEA 開源項目幫助你開發和部署 RAG 應用。你還將通過真實的 RAG 使用案例了解英特爾 Gaudi 2 AI 加速器和至強 CPU 如何助力企業級應用性能的顯著飛躍。
OPEAhttps://opea.dev
導入
在深入了解細節之前,我們先要獲取硬件。英特爾 Gaudi 2 專為加速數據中心和云上的深度學習訓練和推理而設計。你可在 英特爾開發者云 (IDC) 上獲取其公開實例,也可在本地部署它。IDC 是嘗試 Gaudi 2 的最簡單方法,如果你尚沒有帳戶,可以考慮注冊一個帳戶,訂閱 “Premium”,然后申請相應的訪問權限。
英特爾 Gaudi 2https://habana.ai/products/gaudi2/
英特爾開發者云 (IDC)https://www.intel.com/content/www/us/en/developer/tools/devcloud/overview.html
在軟件方面,我們主要使用 LangChain 來構建我們的應用。LangChain 是一個開源框架,旨在簡化 LLM AI 應用的構建流程。其提供了基于模板的解決方案,允許開發人員使用自定義嵌入模型、向量數據庫和 LLM 構建 RAG 應用,用戶可通過 LangChain 文檔獲取其更多信息。英特爾一直積極為 LangChain 貢獻多項優化,以助力開發者在英特爾平臺上高效部署 GenAI 應用。
在 LangChain 中,我們將使用 rag-redis 模板來創建我們的 RAG 應用。選型上,我們使用 BAAI/bge-base-en-v1.5 作為嵌入模型,并使用 Redis 作為默認向量數據庫。下圖展示了該應用的高層架構圖。
BAAI/bge-base-en-v1.5https://hf.co/BAAI/bge-base-en-v1.5
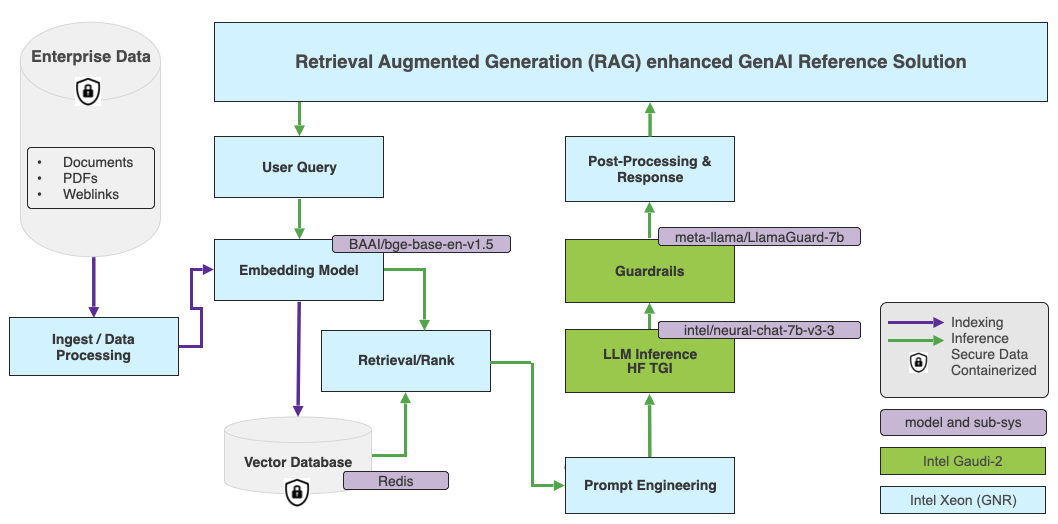
在我們的應用中,嵌入模型跑在 英特爾 Granite Rapids CPU 上。英特爾 Granite Rapids 架構專為高核數、性能敏感型工作負載以及通用計算工作負載而優化,并為此類工作負載提供最低的總擁有成本 (Cost Of Ownership,TCO)。GNR 還支持 AMX-FP16 指令集,這會為混合 AI 工作負載帶來 2-3 倍的性能提升。
英特爾 Granite Rapidshttps://www.intel.com/content/www/us/en/newsroom/news/intel-unveils-future-generation-xeon.html#gs.6t3deu
我們將 LLM 跑在英特爾 Gaudi 2 加速器上。至于如何使用 Hugging Face 模型,Optimum Habana 庫可將 Hugging Face Transformers 和 Diffusers 庫橋接至 Gaudi 加速器。因此,用戶可以用它針對各種下游任務在單卡和多卡場景下輕松進行模型加載、訓練及推理。
Optimum Habanahttps://hf.co/docs/optimum/en/habana/index
Transformershttps://hf.co/docs/transformers/index
Diffusershttps://hf.co/docs/diffusers/index
我們提供了一個 Dockerfile 以簡化 LangChain 開發環境的配置。啟動 Docker 容器后,你就可以開始在 Docker 環境中構建向量數據庫、RAG 流水線以及 LangChain 應用。詳細的分步說明,請參照 ChatQnA 示例。
Dockerfilehttps://github.com/opea-project/GenAIExamples/tree/main/ChatQnA/langchain/docker
ChatQnAhttps://github.com/opea-project/GenAIExamples/tree/main/ChatQnA
創建向量數據庫
我們用耐克的公開財務文件創建一個向量數據庫,示例代碼如下:
#?Ingest?PDF?files?that?contain?Edgar?10k?filings?data?for?Nike.
company_name?=?"Nike"
data_path?=?"data"
doc_path?=?[os.path.join(data_path,?file)?for?file?in?os.listdir(data_path)][0]
content?=?pdf_loader(doc_path)
chunks?=?text_splitter.split_text(content)#?Create?vectorstore
embedder?=?HuggingFaceEmbeddings(model_name=EMBED_MODEL)_?=?Redis.from_texts(texts=[f"Company:?{company_name}.?"?+?chunk?for?chunk?in?chunks],embedding=embedder,index_name=INDEX_NAME,index_schema=INDEX_SCHEMA,redis_url=REDIS_URL,
)定義 RAG 流水線
在 LangChain 中,我們使用 Chain API 來連接提示、向量數據庫以及嵌入模型。
你可在 該代碼庫 中找到完整代碼。
該代碼庫https://github.com/opea-project/GenAIExamples/blob/main/ChatQnA/langchain/redis/rag_redis/chain.py
#?Embedding?model?running?on?Xeon?CPU
embedder?=?HuggingFaceEmbeddings(model_name=EMBED_MODEL)#?Redis?vector?database
vectorstore?=?Redis.from_existing_index(embedding=embedder,?index_name=INDEX_NAME,?schema=INDEX_SCHEMA,?redis_url=REDIS_URL
)#?Retriever
retriever?=?vectorstore.as_retriever(search_type="mmr")#?Prompt?template
template?=?"""…"""
prompt?=?ChatPromptTemplate.from_template(template)#?Hugging?Face?LLM?running?on?Gaudi?2
model?=?HuggingFaceEndpoint(endpoint_url=TGI_LLM_ENDPOINT,?…)#?RAG?chain
chain?=?(RunnableParallel({"context":?retriever,?"question":?RunnablePassthrough()})?|?prompt?|?model?|?StrOutputParser()
).with_types(input_type=Question)在 Gaudi 2 上加載 LLM
我們在 Gaudi2 上使用 Hugging Face 文本生成推理 (TGI) 服務運行聊天模型。TGI 讓我們可以在 Gaudi2 硬件上針對流行的開源 LLM (如 MPT、Llama 以及 Mistral) 實現高性能的文本生成。
無需任何配置,我們可以直接使用預先構建的 Docker 映像并把模型名稱 (如 Intel NeuralChat) 傳給它。
model=Intel/neural-chat-7b-v3-3
volume=$PWD/data
docker?run?-p?8080:80?-v?$volume:/data?--runtime=habana?-e?HABANA_VISIBLE_DEVICES=all?-e?OMPI_MCA_btl_vader_single_copy_mechanism=none?--cap-add=sys_nice?--ipc=host?tgi_gaudi?--model-id?$modelTGI 默認使用單張 Gaudi 加速卡。如需使用多張卡以運行更大的模型 (如 70B),可添加相應的參數,如 --sharded true 以及 --num_shard 8 。對于受限訪問的模型,如 Llama 或 StarCoder,你還需要指定 -e HUGGING_FACE_HUB_TOKEN= <kbd> 以使用你自己的 Hugging Face 令牌 獲取模型。
Llamahttps://hf.co/meta-llama
StarCoderhttps://hf.co/bigcode/starcoder
Hugging Face 令牌https://hf.co/docs/hub/en/security-tokens
容器啟動后,我們可以通過向 TGI 終端發送請求以檢查服務是否正常。
curl?localhost:8080/generate?-X?POST?\
-d?'{"inputs":"Which?NFL?team?won?the?Super?Bowl?in?the?2010?season?",?\
"parameters":{"max_new_tokens":128,?"do_sample":?true}}'?\
-H?'Content-Type:?application/json'如果你能收到生成的響應,則 LLM 運行正確。從現在開始,你就可以在 Gaudi2 上盡情享受高性能推理了!
TGI Gaudi 容器默認使用 bfloat16 數據類型。為獲得更高的吞吐量,你可能需要啟用 FP8 量化。根據我們的測試結果,與 BF16 相比,FP8 量化會帶來 1.8 倍的吞吐量提升。FP8 相關說明可在 README 文件中找到。
READMEhttps://github.com/opea-project/GenAIExamples/blob/main/ChatQnA/README.md
最后,你還可以使用 Meta Llama Guard 模型對生成的內容進行審核。OPEA 的 README 文件提供了在 TGI Gaudi 上部署 Llama Guard 的說明。
Llama Guardhttps://hf.co/meta-llama/LlamaGuard-7b
READMEhttps://github.com/opea-project/GenAIExamples/blob/main/ChatQnA/README.md
運行 RAG 服務
我們運行下述命令啟動 RAG 應用后端服務, server.py 腳本是用 fastAPI 實現的服務終端。
docker?exec?-it?qna-rag-redis-server?bash
nohup?python?app/server.py?&默認情況下,TGI Gaudi 終端運行在本地主機的 8080 端口上 (即 http://127.0.0.1:8080 )。如果需將其運行至不同的地址或端口,可通過設置 TGI_ENDPOINT 環境變量來達成。
啟動 RAG GUI
運行以下命令以安裝前端 GUI 組件:
sudo?apt-get?install?npm?&&?\npm?install?-g?n?&&?\n?stable?&&?\hash?-r?&&?\npm?install?-g?npm@latest然后,更新 .env 文件中的 DOC_BASE_URL 環境變量,將本地主機 IP 地址 ( 127.0.0.1 ) 替換為運行 GUI 的服務器的實際 IP 地址。
接著,運行以下命令以安裝所需的軟件依賴:
npm?install最后,使用以下命令啟動 GUI 服務:
nohup?npm?run?dev?&上述命令會運行前端服務并啟動應用。
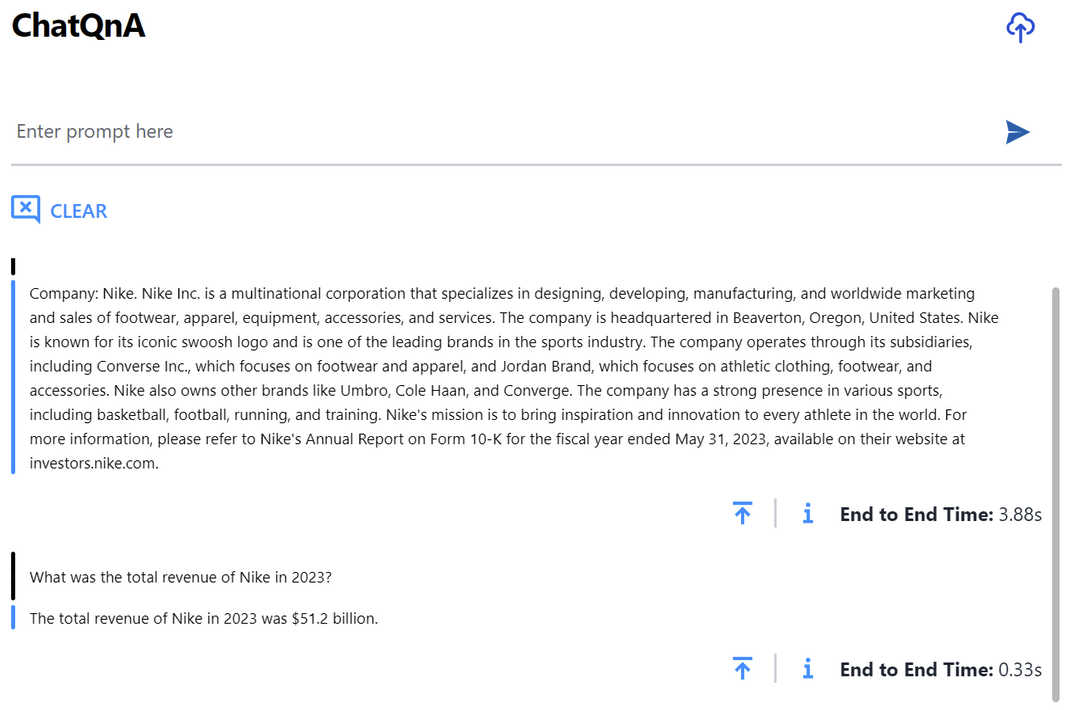
基準測試結果
我們針對不同的模型和配置進行了深入的實驗。下面兩張圖展示了 Llama2-70B 模型在四卡英特爾 Gaudi 2 和四卡英偉達 H100 平臺上,面對 16 個并發用戶時的相對端到端吞吐量和性價比對比。
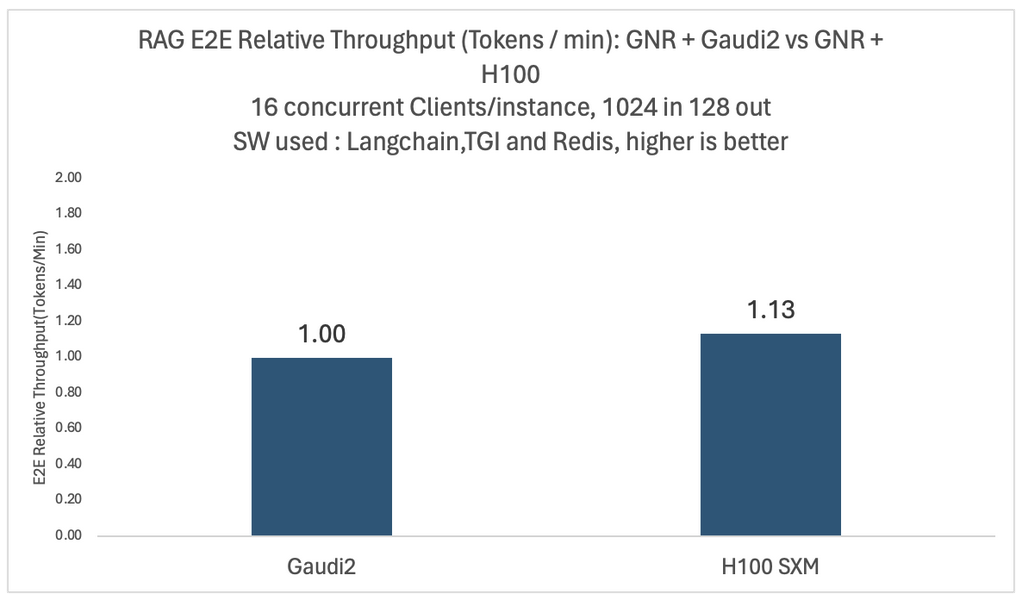
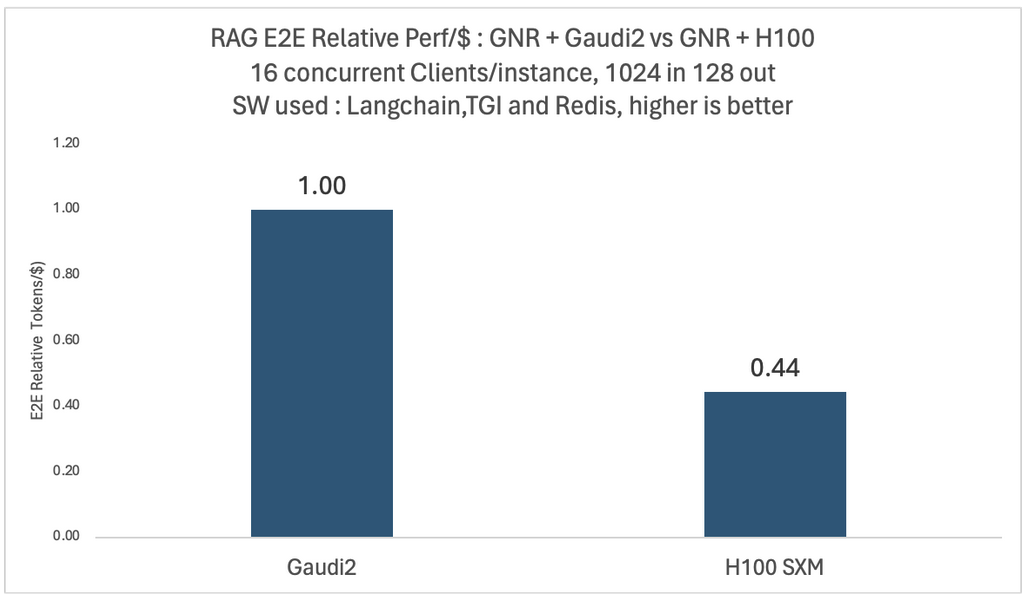
在這兩種測例中,向量數據庫和嵌入模型都運行在相同的英特爾 Granite Rapids CPU 平臺上。為了比較每美元的性能,我們使用了與 MosaicML 團隊于 2024 年 1 月使用的數據相同的公開定價數據來計算每美元的平均訓練性能。
MosaicMLhttps://www.databricks.com/blog/llm-training-and-inference-intel-gaudi2-ai-accelerators
如你所見,與 Gaudi 2 相比,基于 H100 的系統雖然吞吐量提高了 1.13 倍,但每美元性能僅為 0.44 倍。這些比較可能會因云廠商不同以及客戶折扣不同而有所不同,我們在文末列出了詳細的基準配置。
總結
上例成功演示了如何在英特爾平臺上部署基于 RAG 的聊天機器人。此外,英特爾會不斷發布成熟的 GenAI 示例,以期通過這些經過驗證的工具助力開發人員簡化創建、部署流程。這些示例功能多樣且易于定制,非常適合用戶基于其在英特爾平臺上開發各種應用。
運行企業級 AI 應用時,基于英特爾 Granite Rapids CPU 和 Gaudi 2 加速器的系統的總擁有成本更低。另外,還可通過 FP8 優化進一步優化成本。
以下開發者資源應該可以幫助大家更平滑地啟動 GenAI 項目。
OPEA GenAI 示例https://github.com/opea-project/GenAIExamples
基于 Gaudi 2 的 TGIhttps://github.com/huggingface/tgi-gaudi
英特爾 AI 生態之 Hugging Facehttps://www.intel.com/content/www/us/en/developer/ecosystem/hugging-face.html
Hugging Face hub 英特爾頁https://hf.co/Intel
如果你有任何問題或反饋,我們很樂意在 Hugging Face 論壇 上與你互動。感謝垂閱!
Hugging Face 論壇https://discuss.huggingface.co/
致謝:
我們要感謝 Chaitanya Khened、Suyue Chen、Mikolaj Zyczynski、Wenjiao Yue、Wenxin Zhu、Letong Han、Sihan Chen、Hanwen Cheng、Yuan Wu 和 Yi Wang 對在英特爾 Gaudi 2 上構建企業級 RAG 系統做出的杰出貢獻。
基準測試配置
Gaudi2 配置: HLS-Gaudi2 配備 8 張 Habana Gaudi2 HL-225H 夾層卡及 2 個英特爾至強鉑金 8380 CPU@2.30GHz,以及 1TB 系統內存; 操作系統: Ubuntu 22.04.03,5.15.0 內核
H100 SXM 配置: Lambda labs 實例 gpu_8x_h100_sxm5; 8 張 H100 SXM 及 2 個英特爾至強鉑金 8480 CPU@2 GHz,以及 1.8TB 系統內存; 操作系統 ubuntu 20.04.6 LTS,5.15.0 內核
Llama2 70B 部署至 4 張卡 (查詢歸一化至 8 卡)。Gaudi2 使用 BF16,H100 使用 FP16
嵌入模型為
BAAI/bge-base v1.5。測試環境: TGI-gaudi 1.2.1、TGI-GPU 1.4.5、Python 3.11.7、Langchain 0.1.11、sentence-transformers 2.5.1、langchain benchmarks 0.0.10、redis 5.0.2、cuda 12.2.r12.2/compiler.32965470_0, TEI 1.2.0RAG 查詢最大輸入長度 1024,最大輸出長度 128。測試數據集: langsmith Q&A。并發客戶端數 16
Gaudi2 (70B) 的 TGI 參數:
batch_bucket_size=22,prefill_batch_bucket_size=4,max_batch_prefill_tokens=5102,max_batch_total_tokens=32256,max_waiting_tokens=5,streaming=falseH100 (70B) 的 TGI 參數:
batch_bucket_size=8,prefill_batch_bucket_size=4,max_batch_prefill_tokens=4096,max_batch_total_tokens=131072,max_waiting_tokens=20,max_batch_size=128,streaming=falseTCO 參考:https://www.databricks.com/blog/llm-training-and-inference-intel-gaudi2-ai-accelerators
英文原文:?https://hf.co/blog/cost-efficient-rag-applications-with-intel
原文作者: Julien Simon,Haihao Shen,Antony Vance Jeyaraj,Matrix Yao,Leon Lv,Greg Serochi,Deb Bharadwaj,Ke Ding
譯者: Matrix Yao (姚偉峰),英特爾深度學習工程師,工作方向為 transformer-family 模型在各模態數據上的應用及大規模模型的訓練推理。



)


—— 按鈕控件)



ALGO-934 序列)


-查詢優化(23)-避免全表掃描)

:Linux 系統上的庫文件生成與使用)



