自然語言處理 (Natural Language Processing):
NLP四大基本任務
序列標注: 分詞、詞性標注
分類任務: 文本分類、情感分析
句子關系:問答系統、對話系統
生成任務:機器翻譯、文章摘要
機器閱讀理解的定義
Machine Reading Comprehension(MRC)機器閱讀理解任務
QA問題的一個子集,含有contexts
通過交互從書面文字中提取與構造文章語義的過程
機器閱讀理解場景
搜索引擎
機器回答&智能客服
垂直:醫療、法律、金融、教育等領域
MRC四大任務
完形填空
原文中除去若干關鍵詞,需要模型填入正確的單詞或者短語
多項選擇
模型需要從給定的若干選項中給出正確答案
答案抽取
回答限定是文章中的一個子句,需要模型在文章中標注正確答案的起始和終止位置。
自由回答
不限制模型生成答案形式,允許模型自由產生數據
機器閱讀理解方法
特征+傳統機器學習
BERT以前:各種神奇的QA架構
BERT之后:預訓練+微調+trick
機器學習總體架構
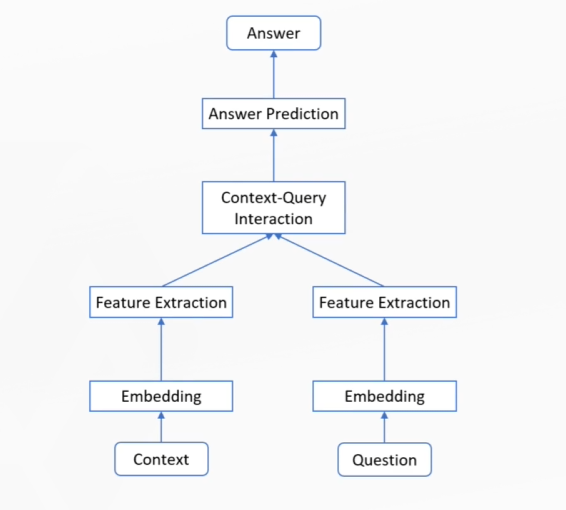
NLP相關任務的基本流程
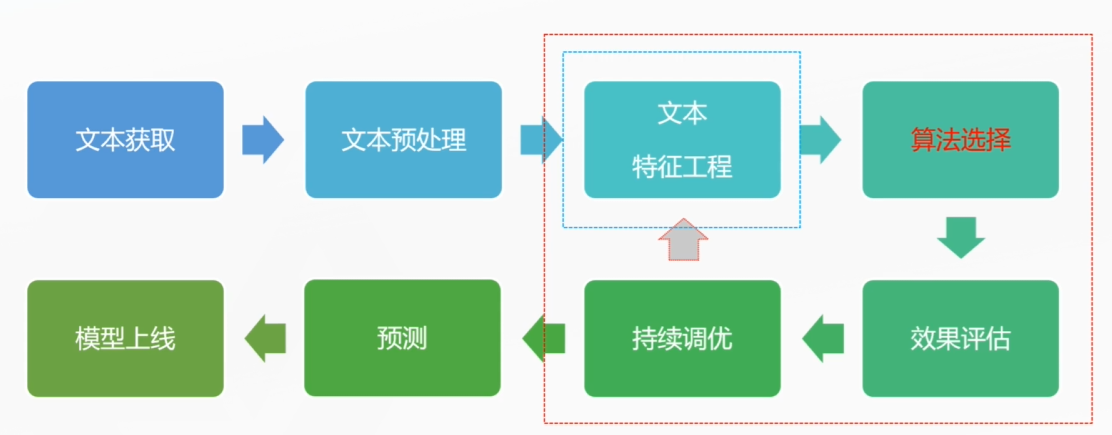
文本預處理:構造訓練語料
算法選擇:輸出數據-》規則
文本獲取:
1、人工標注
2、用戶標注
3、互聯網收集后清洗
文本預處理:
1、去除冗余字符標記
2、分詞(jieba/中文)
3、單詞處理(英文:大寫->小寫,單詞還原,同義詞擴展)
4、去除停用詞
總結:
在訓練之前,要針對對應的模型:
1、確定目標大模型的訓練語料格式
2、針對龐雜的文本文件進行去除標記、分詞、單詞處理、去除停用詞。這些操作
3、得到的文件就可以用來預訓練啦!


)
















