本文來源公眾號“DeepDriving”,僅用于學術分享,侵權刪,干貨滿滿。
原文鏈接:CUDA編程-03:線程層級
DeepDriving | CUDA編程-01: 搭建CUDA編程環境-CSDN博客
DeepDriving | CUDA編程-02: 初識CUDA編程-CSDN博客
1 GPU架構概述
英偉達GPU的架構是圍繞一個流式多處理器(Streaming Multiprocessors,SM)的可擴展陣列構建的,通過復制這種架構的構建來實現GPU的硬件并行。一個典型的SM包括以下幾個組件:
-
核心
-
共享內存/一級緩存
-
寄存器文件
-
加載/存儲單元
-
特殊功能單元
-
線程束調度器

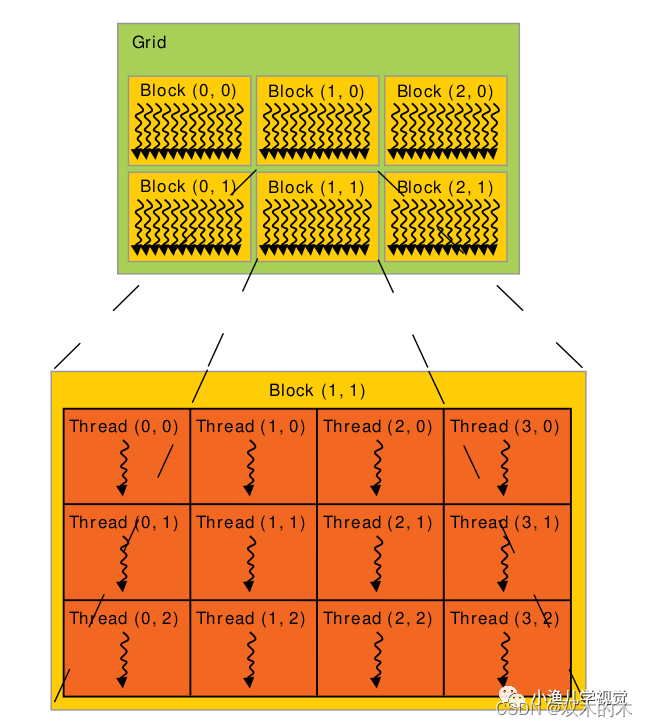
一個GPU中通常有多個SM,每個SM上支持許多個線程并發地執行,CUDA采用單指令多線程(Single-Instruction Multiple-Thread,SIMT)來管理和執行GPU上的眾多線程,并提出一個兩級的線程層級結構的概念以便組織線程。由一個內核啟動所產生的所有線程統稱為一個線程網格,同一網格中的所有線程共享全局內存空間,一個網格由多個線程塊組成,一個線程塊包含一組線程,同一線程塊內的線程通過同步和共享內存的方式實現協作,不同塊內的線程不能協作。當host通過內核函數啟動一個內核網格時,這個內核網格的線程塊就被分配到可用的SM上來執行,一個線程塊內的多個線程在SM上并發執行,多個線程塊可以并發地在一個SM上執行,當線程塊終止時,新的線程塊又可以在騰出的SM上啟動執行。
2 線程
線程是并行程序的基礎,并行化的方式一般有兩種:任務并行和數據并行。任務并行是將一個計算任務分解為幾個子任務,通過不同的線程分別執行各個子任務,最后匯總結果;數據并行是將一個總任務在數據粒度上進行劃分,然后每個線程處理一份數據,每個線程上執行的計算任務是一樣的。
舉個搬磚的例子:
假設我們的任務是將100個磚從A點搬到B點,搬磚的任務分為3個子任務:把磚從A點裝車、從A點運送到B點、在B點把磚從車上卸下來。如果采用任務并行方式,那么可以請多個工人,然后把他們分為3個組,每個組負責一個子任務 ;如果是采用數據并行,那么可以請100個工人,每個人負責1個磚,每個人的任務都是把磚從A點搬到B點。
GPU采用數據并行的模式,它可以運行成千上萬的線程用于運行大量邏輯比較簡單的計算任務以實現高效的并行化計算。在上一篇文章中,我介紹了一個數組相加的例子,本文繼續以這個例子來介紹GPU中以多線程實現并行化的方式。
先來看一下CPU實現數組相加的方式:
void?VectorAddCPU(const?float?*const?a,?const?float?*const?b,?float?*const?c,const?int?n)?{for?(int?i?=?0;?i?<?n;?++i)?{c[i]?=?a[i]?+?b[i];}
}
CPU的代碼默認是單線程執行模式,要想實現含多個數據的數組相加任務,就必須以循環的方式實現(相當于一個人要把所有的磚搬完)。
再來看GPU的實現方式:
__global__?void?VectorAddGPU(const?float?*const?a,?const?float?*const?b,float?*const?c,?const?int?n)?{int?i?=?blockDim.x?*?blockIdx.x?+?threadIdx.x;?//?線程IDif?(i?<?n)?{c[i]?=?a[i]?+?b[i];?//每個線程需要做的事情}
}
可以看到,GPU代碼中并不需要循環,只是需要一個線程ID來進行索引,并告訴每個線程需要做的事情。線程依靠兩個內置變量來進行區分:
-
blockIdx: 線程塊在線程網格中的索引 -
threadIdx: 線程塊內的線程索引
這兩個CUDA內置變量是基于uint3定義的向量類型,是一個包含x,y,z三個無符號整數字段的結構。
在調用內核函數的時候,會在<<< >>>內設置兩個參數,分別代表線程網格的維度和線程塊的維度。CUDA可以組織三維的線程網格和線程塊,它們的維度由下列兩個內置變量來決定:
-
blockDim: 線程塊的維度,用每個線程塊中的線程數量來表示 -
gridDim: 線程網格的維度,用每個線程網格中的線程塊數量來表示
它們是基于uint3定義的dim3結構類型的變量,用于表示維度,每個維度可通過x,y,z字段獲得,未被初始化的字段會被初始化為1且忽略不計。通常情況下,一個線程網格會被組織成線程塊的二維數組形式,一個線程塊會被組織成線程的三維數組形式。
const?size_t?size?=?1024;
dim3?thread_per_block(256);
dim3?block_per_grid((size?+?thread_per_block.x?-?1)?/?thread_per_block.x);
printf("thread_per_block:?%d,?block_per_grid:?%d?\n",?thread_per_block.x,block_per_grid.x);
VectorAddGPU<<<block_per_grid,?thread_per_block>>>(da,?db,?dc,?size);
在上面的例子中,我只初始化了線程網格和線程塊的第一維x,相當于設定線程網格中的線程塊是以一維的形式排列,每個線程塊中的線程也是以一維的形式排列,在內核函數中每個線程的ID可以這樣得到:
const?unsigned?int?id?=?blockDim.x?*?blockIdx.x?+?threadIdx.x;?
我們可以在內核函數中打印gridDim,blockDim,blockIdx,threadIdx這些信息看一下:
......
gridDim:(4 1 1), blockDim:(256 1 1), blockIdx:(1 0 0), threadIdx:(29 0 0)
gridDim:(4 1 1), blockDim:(256 1 1), blockIdx:(1 0 0), threadIdx:(30 0 0)
gridDim:(4 1 1), blockDim:(256 1 1), blockIdx:(1 0 0), threadIdx:(31 0 0)
gridDim:(4 1 1), blockDim:(256 1 1), blockIdx:(0 0 0), threadIdx:(0 0 0)
gridDim:(4 1 1), blockDim:(256 1 1), blockIdx:(0 0 0), threadIdx:(1 0 0)
gridDim:(4 1 1), blockDim:(256 1 1), blockIdx:(0 0 0), threadIdx:(2 0 0)
......
把thread_per_block設置為512再看一下:
......
gridDim:(2 1 1), blockDim:(512 1 1), blockIdx:(1 0 0), threadIdx:(93 0 0)
gridDim:(2 1 1), blockDim:(512 1 1), blockIdx:(1 0 0), threadIdx:(94 0 0)
gridDim:(2 1 1), blockDim:(512 1 1), blockIdx:(1 0 0), threadIdx:(95 0 0)
gridDim:(2 1 1), blockDim:(512 1 1), blockIdx:(0 0 0), threadIdx:(416 0 0)
gridDim:(2 1 1), blockDim:(512 1 1), blockIdx:(0 0 0), threadIdx:(417 0 0)
gridDim:(2 1 1), blockDim:(512 1 1), blockIdx:(0 0 0), threadIdx:(418 0 0)
......
可以看到,啟動內核函數的時候在<<< >>>內設置不同的執行參數,內核中線程的布局是不一樣的。
3 線程束
CUDA采用SIMT架構來管理和執行線程,將線程塊中的線程每32個(記住這個神奇的數字)為一組進行劃分,每一組被稱為一個線程束(warp)。線程束的大小warpSize是CUDA中的一個內部屬性,可以通過以下方式獲得:
cudaDeviceProp?prop;
cudaGetDeviceProperties(&prop,?0);
printf("warpSize:?%d\n",?prop.warpSize);
線程束是GPU的基本執行單元,當線程網格啟動后,網格中的線程塊被分配到SM中執行,一旦線程塊被調度到一個SM上,線程塊中的線程就會被進一步劃分為線程束,每個線程束中的所有線程執行相同的命令,每個線程擁有自己的指令地址計數器和寄存器狀態,利用自己的私有數據執行當前的指令。線程塊的邏輯視圖和硬件視圖之間的關系如下:
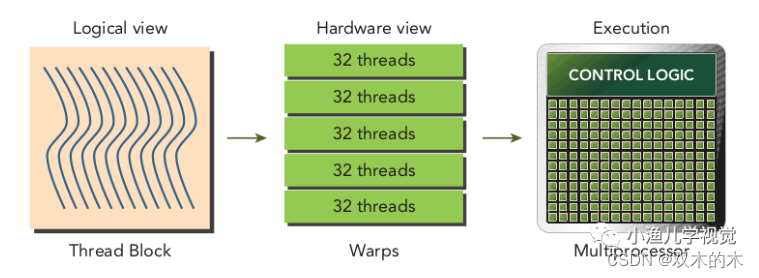
從邏輯角度看,線程塊是線程的集合,它們可以被組織成一維、二維或者三維的布局形式;從硬件角度來看,線程塊是一維線程束的集合,線程塊中的線程被組織成一維布局,每32個連續的線程組成了一個線程束。
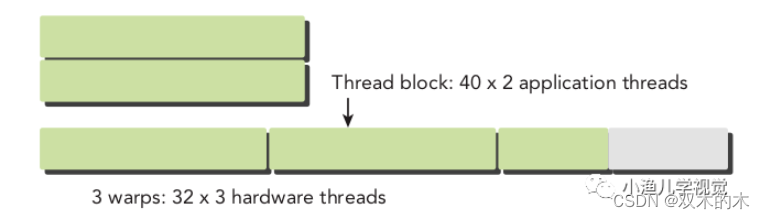
由于在硬件上線程塊中的線程會被劃分為線程束,而線程束不會在不同線程塊之間分離,也就是說同一個線程束中的線程不會同屬于兩個線程塊。如果線程塊的大小不是線程束大小的偶數倍,那么最后一個線程束里就會有些線程沒有用,但是它們依然會消耗SM的資源,所以在設置線程塊大小的時候,最好設置為32的倍數。下圖展示了一個線程塊中包含80個線程時的情況,硬件為這些線程分配了3個線程束,最后一個線程束中有些線程是沒有用的。
4 線程塊
對于一份給定的數據,確定網格和塊的維度的一般步驟為:
-
確定塊的維度大小;
-
在已知數據大小和塊大小的基礎上計算網格的維度。
如何確定一個塊的維度大小,通常需要考慮內核的性能特性和GPU的資源限制,比如寄存器和共享內存的大小,使用合適的網格和塊大小來組織線程可以對內核性能產生較大的影響。在程序中,應該盡量避免使用小的線程塊,因為這樣無法充分利用硬件資源。為了防止不合理的內存合并,我們需要盡量做到數據內存的分布與線程的分布達到一一映射的關系。CUDA的設計思想是將數據分解到并行的線程和線程塊中,使得程序結構與內存數據的分布能夠建立一一映射的關系。假如我們需要計算二維數組的相加,那么可以將線程網格和線程塊劃分為二維:

這種情況下計算線程的ID會稍微復雜一點,首先計算當前的行索引,然后乘以每一行的線程總數,最后加上X軸方向上的偏移,這樣就能計算出線程相對于整個線程網格的絕對線程索引:
const?unsigned?int?idx?=?blockDim.x?*?blockIdx.x?+?threadIdx.x;
const?unsigned?int?idy?=?blockDim.y?*?blockIdx.y?+?threadIdx.y;
const?unsigned?int?thread_id?=?(gridDim.x?*?blockDim.x)?*?idy?+?idx;
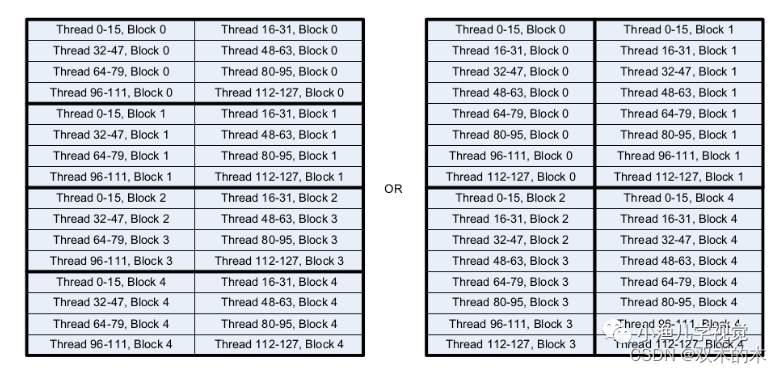
當然,二維線程塊的布局方式也有多種,比如下面這兩種,它們的線程總數是一樣的,但左圖的布局要比右圖的更高效。因為無論是在CPU還是在GPU中都是以行的方式進行內存訪問,以右圖的布局方式,同一行的數據需要被2個線程塊訪問2次,而左圖的布局同一行的數據只需要訪問1次即可。
5 參考資料
-
《
Professional CUDA C Programming》 -
《
CUDA C Programming Guide》 -
《
CUDA Programming:A Developer's Guide to Parallel Computing with GPUs》
THE END !
文章結束,感謝閱讀。您的點贊,收藏,評論是我繼續更新的動力。大家有推薦的公眾號可以評論區留言,共同學習,一起進步。
)

 函數)
安裝 Docker)



)


)








