DEADiff: An Efficient Stylization Diffusion Model with Disentangled Representations
代碼:https://tianhao-qi.github.io/DEADiff/
論文:https://arxiv.org/pdf/2403.06951

本文介紹了一種名為DEADiff的方法,旨在解決基于擴散的文本到圖像模型在風格遷移時遇到的問題。解決當前的基于編碼器的方法顯著影響了文本到圖像模型在風格遷移時的文本可控性問題。為了解決這個問題,DEADiff采用了以下兩種策略:
- 解耦風格和語義的機制。通過Q-Formers首先提取解耦的特征表示,這些特征表示受不同的文本描述指導。然后將它們注入到互斥的交叉注意力層的子集中,以更好地解耦風格和語義。
- 非重構性學習方法。Q-Formers使用成對圖像進行訓練,而不是相同的目標圖像。在這種情況下,參考圖像和真值圖像具有相同的風格或語義。
MOTIVATION
附加編碼器為中心(center around an additional encoder)
風格轉移的流行方法是以附加編碼器為中心的方法。基于編碼器的方法通常訓練編碼器將參考圖像編碼為信息特征,然后將其注入擴散模型作為其引導條件。通過這樣的編碼器,可以提取高度抽象的特征,以有效地描述參考圖像的風格。T2I-Adapter)可以自然地生成忠實的參考樣式。 然而,這種方法也引入了一個特別令人煩惱的問題:雖然它允許模型遵循參考圖像的風格,但它顯著降低了模型在理解文本條件的語義上下文方面的性能。
文本可控性的喪失(The loss of text controllability)
- 編碼器提取的信息將風格與語耦合在一起,而不僅僅是純粹的風格特征。具體來說,先前的方法在其編碼器中缺乏有效的機制來區分圖像風格和圖像語義。因此,提取的圖像特征不可避免地包含了風格和語義信息。這種圖像語義與文本條件中的語義沖突,導致對基于文本的條件的控制力降低。
- 先前的方法將編碼器的學習過程視為一種重構任務(reconstruction),其中參考圖像的gournd-truth是圖像本身與訓練文本到圖像模型遵循文本描述相比,從參考圖像的重構中學習通常更容易。因此,在重構任務下,模型傾向于關注參考圖像,而忽視文本到圖像模型中的原始文本條件。
CONTRIBUTION
- 提出了一種雙解耦表示提取機制,分別獲取參考圖像的風格和語義表示,從學習任務的角度緩解文本和參考圖像之間的語義沖突問題。
- 引入了一種解耦的調節機制,允許交叉注意力層的不同部分分別負責圖像風格/語義表示的注入,從模型結構的角度進一步減少語義沖突。
- 構建了兩個配對數據集,以使用非重建訓練范例來輔助 DDRE 機制。
RELATED WORK
T2I
基于文本反演的方法(Textual inversion-based meth-ods)將風格圖像投影到可學習的文本token空間的embedding中。不幸的是,由于從視覺到文本模態的映射導致的信息丟失問題,使得學習的embedding無法準確地渲染參考圖像的風格與用戶定義的提示。
DreamBooth和Custom Diffusion通過優化擴散模型的全部或部分參數,可以合成更能捕捉參考圖像風格的圖像。然而,這種方法的代價是由于嚴重過擬合導致的對文本提示的準確度降低。
目前,參數有效的微調提供了一種更有效的方法來進行風格化圖像生成,而不影響擴散模型對文本提示的忠實度,如InST,LoRA和StyleDrop。然而,盡管這些基于優化的方法可以定制風格,但它們都需要數分鐘到數小時來微調每個輸入參考圖像的模型。額外的計算和存儲開銷阻礙可行性。
因此,一些無優化方法被提出來通過設計的圖像編碼器從參考圖像中提取風格特征。
- T2I-Adapter-Style和IP-Adapter使用Transformer作為圖像編碼器,以CLIP圖像embedding作為輸入,并利用通過UNet交叉注意力層提取的圖像特征。
- BLIP-Diffusion構建了一個Q-Former,將圖像embedding轉換為文本embedding空間,并將其輸入到擴散模型的文本編碼器中。
這些方法使用整個圖像重建或對象重建作為訓練目標,導致從參考圖像中提取了內容和風格信息。為了使圖像編碼器專注于提取風格特征,StyleAdapter和ControlNet-shuffle對參考圖像的塊或像素進行了重排,并且可以生成具有目標風格的各種內容。
Q-Former
Q-Former是一個基于Transformer的組件,它被用來提取和過濾圖像特征。
METHODS
雙重解耦下的提取-Dual Decoupling Representation Extraction
DDRE(Dual Decoupling Representation Extraction)受到BLIP-Diffusion的啟發,DDRE不是直接訓練一個模型來重建或模仿輸入圖像,而是通過設計2個輔助task來幫助模型學習更深層次的特征表示、DDRE通過分別針對風格和內容的訓練,使得模型能夠獨立地處理這兩類特征。
- 使用Q-Formers作為表示過濾器:Q-Formers在這個中充當風格和內容特征提取的過濾器。利用 QFormer從參考圖像中獲取風格和語義表示。 Q-Former 根據“風格”和“內容”條件來選擇性地提取與給定指令相符的特征。
- 配對合成圖像中學習的非重建訓練范例:使用分別與參考圖像和地面實況圖像具有相同風格的成對圖像來訓練由“Style”條件指示的Q-Former。 同時,“Content”條件指示的QFormer是由具有相同語義但不同風格的圖像訓練的。
- 非重構范式:與直接重建圖像的方法不同,DDRE采用非重構的訓練范式。這意味著模型的目標不是生成與參考圖像完全相同的圖像,而是學習如何提取和利用對生成過程有用的特征表示。

風格圖像提取STRE:
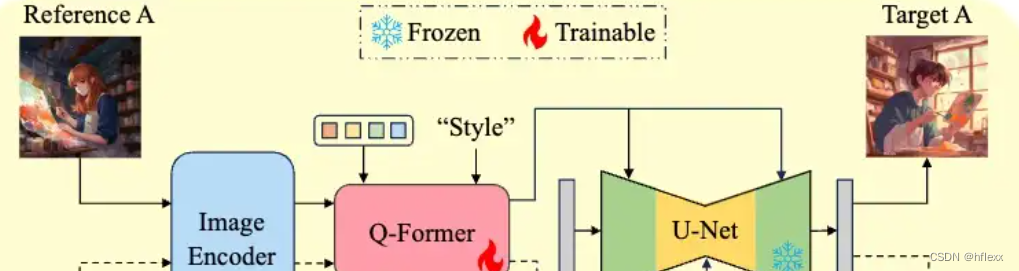
- 選擇一對風格相同但內容不同的圖像(對應圖中reference A和target A),兩者都保持相同的風格,它們分別作為Stable Diffusion(SD)生成過程的參考圖像(reference )和目標圖像(target )。(使用兩個具有相同提示的不同圖像)
- 參考圖像輸入到CLIP圖像編碼器,其輸出(該編碼器會輸出一個向量表示或特征向量)與Q-Former的learnable query tokens以及其輸入文本(inputs)通過交叉注意力機制相互作用。
- Q-Former的輸入文本(inputs)被設定為“style”,目的是生成與文本對齊的圖像特征作為輸出。(條件化輸入),對應的輸出封裝了風格信息,然后與目標圖像內容的詳細描述相結合,并提供給去噪U-Net進行條件控制.
這種prompt構成策略的動力在于更好地解開風格和內容描述之間的糾纏,使Q-Former更加專注于提取以風格為中心的表示
內容表示提取SERE
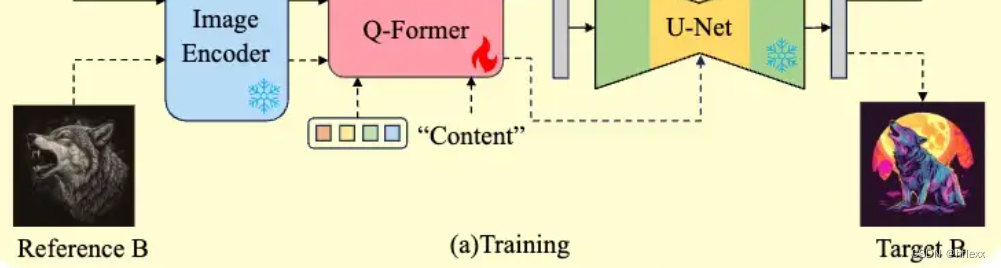
- 選擇一對主題相同但風格不同的圖像((對應圖中reference B和target B)),分別作為參考圖像和目標圖像。
- 與STRE不同,Q-Former的輸入文本被替換為“content”,以提取與內容相關的特定表示。
- 為了獲取純凈的內容表示,Q-Former的query token輸出和目標圖像的文本風格詞同時作為去噪U-Net的條件。在這種方法中,Q-Former在生成目標圖像時將篩選出CLIP圖像嵌入中與內容無關的信息。
同時,將重構任務整合到整個流程中。這個學習任務的條件提示由“風格”Q-Former和“內容”Q-Former處理的 query token組成。通過這種方式,可以確保Q-Formers不會忽視關鍵的圖像信息,考慮到內容和風格之間的互補關系。
解耦條件機制-Disentangled Conditioning Mechanism
DCM
受先前工作的啟發(去噪 U-Net 中的不同交叉注意層主導合成圖像的不同屬性,不同的交叉注意力層對風格和語義的不同響應),引入了一種創新的Disentangled Conditioning Mechanism(DCM)。
- DCM采用的策略是,空間分辨率較低的粗層以語義為條件,而空間分辨率較高的精細層以風格為條件。
- 我們僅將帶有“Style”條件的 Q-Former 的輸出 query 注入到細層(fine layers),這些層響應局部區域特征而不是全局語義。這種結構性的調整促使Q-Former在輸入“風格”條件時提取更多的風格導向特征,例如圖像的筆觸、紋理和顏色,同時減弱了其對全局語義的關注。
a joint text-image cross-attention layer
為了使去噪U-Net支持圖像特征作為條件,設計了一個聯合文本-圖像交叉注意力層,類似于IP-Adapter:
IP-adapter可以跳轉到這篇博客:IP-adapter

- 包含了兩個可訓練的線性投影層 W I k , W I V W_I^k,W_I^V WIk?,WIV?來處理圖像特征 c i c_i ci?
- 還包含了凍結的線性投影層 W T k , W T V W_T^k,W_T^V WTk?,WTV?,用于處理文本特征 c t c_t ct?
- 不是獨立地對圖像和文本特征執行交叉注意力,而是分別從文本和圖像特征中連接鍵和值矩陣,隨后使用U-Net query 特征Z進行單個交叉注意力操作
Q = Z W Q , K = C o n c a t ( c t W T K , c i W I K ) , V = C o n c a t ( c t W T V , c i W I V ) , Z n e w = S o f t m a x ( Q K T d ) V . \begin{aligned} \text{Q}& =ZW^{Q}, \\ \text{K}& =Concat(c_{t}W_{T}^{K},c_{i}W_{I}^{K}), \\ \text{V}& =Concat(c_{t}W_{T}^{V},c_{i}W_{I}^{V}), \\ Z^{new}& =Softmax(\frac{QK^{T}}{\sqrt{d}})V. \end{aligned} QKVZnew?=ZWQ,=Concat(ct?WTK?,ci?WIK?),=Concat(ct?WTV?,ci?WIV?),=Softmax(d?QKT?)V.?
配對數據集構建
通過組合主題詞和風格詞手動創建文本提示列表,并利用預先訓練的模型構建兩個配對圖像數據集
- 具有相同風格的sample
- 具有相同主題的sample。
具體而言,構建配對數據集包括以下三個步驟:
- 步驟1:文本提示組合。 列出了近12,000個主題詞,涵蓋了四個主要類別:人物、動物、物體和場景。此外,還記錄了近700個風格詞,包括藝術風格、藝術家、筆觸、陰影、鏡頭、分辨率和視角等屬性。然后,平均每個主題詞分配了大約14個來自所有風格詞的風格詞,這些組合形成了用于文本到圖像模型的最終文本提示。
- 步驟2:圖像生成和收集。 將文本提示與主題詞和風格詞結合后,得到了超過160,000個文本提示。隨后,將所有文本提示發送到Midjourney,這是一個領先的文本到圖像生成產品,用于合成相應的圖像。作為Midjourney的特點,給定提示的直接輸出包括4張分辨率為512×512的圖像。將每個圖像上采樣到分辨率為1024×1024,并與給定的提示一起存儲。由于數據收集中的冗余性,最終收集了共計106萬個圖像-文本對。
- 步驟3:**配對圖像選擇。**至于描述的內容表示學習任務,將具有相同主題詞但不同風格詞的圖像配對為一個單獨的項目。 我們觀察到,即使具有相同的風格詞(style words),使用不同的subject詞生成的圖像也存在顯著差異。
- 考慮到這一點,在風格表示學習任務中,使用兩個具有相同提示的不同圖像。
- 將具有相同提示的圖像存儲為單個項目,并在每次迭代中隨機選擇兩個圖像。
Training and Inference
采用SD對應的損失函數來監督上述三個學習任務。在訓練過程中,只有Q-Former和新添加的線性投影層被優化
L = E z , c , ? ~ N ( 0 , 1 ) , t [ ∥ ? ? ? θ ( z t , t , c ) ∥ 2 2 ] L=\mathbb{E}_{z,c,\epsilon\sim\mathcal{N}(0,1),t}\left[\left\|\epsilon-\epsilon_{\theta}\left(z_{t},t,c\right)\right\|_{2}^{2}\right] L=Ez,c,?~N(0,1),t?[∥???θ?(zt?,t,c)∥22?]

EXPERIMENT
實驗設置
采用Stable Diffusion v1.5 作為我們的基礎文本到圖像模型,該模型包括總共 16 個交叉注意力層。按照從輸入到輸出的順序對它們進行編號,定義層 4-8 為粗層,用于注入圖像內容表示。因此,其他層被定義為用于注入圖像風格表示的細層。使用來自 CLIP 的 ViT-L/14 作為圖像編碼器,并保持 Q-Former 的可學習 query token數量與 BLIP-Diffusion 一致,即為 16。采用兩個 Q-Formers 分別提取語義和風格表示,以鼓勵它們專注于自己的任務。
為了快速收斂,使用 HuggingFace 中由 BLIP-Diffusion 提供的預訓練模型初始化 Q-Former。至于額外的投影層 W I k , W I V W_I^k,W_I^V WIk?,WIV?,我們將它們的參數初始化為 W T k , W T V W_T^k,W_T^V WTk?,WTV?的參數。在訓練期間,我們根據前面中所述的三個學習任務的采樣比率設置為1:1:1,以同等地訓練風格 Q-Former 和內容 Q-Former。我們固定圖像編碼器、文本編碼器和原始 U-Net的參數,僅更新 Q-Former、16 個可學習 query 和額外的投影層 W I k , W I V W_I^k,W_I^V WIk?,WIV?的參數。模型在 16 個 A100-80G GPU 上以總batch大小為 512 進行訓練。采用 AdamW 作為優化器,學習率為 1 e ? 4 1e^{-4} 1e?4訓練 100000 次迭代。至于推理階段,采用 DDIM采樣器進行 50 步采樣。無分類器指導的指導尺度為 8。
評估指標
在缺乏準確和合適的評估風格相似度(SS)的度量標準的情況下,我們提出了一個更合理的方法。此外,在 CLIP 文本-圖像embedding空間內確定文本提示與其對應的合成圖像之間的余弦相似度,這表明了文本對齊能力(TA)。還報告了每種方法的圖像質量(IQ)的結果。最后,為了消除客觀度指標計算中隨機性帶來的干擾,進行了用戶研究,反映了結果的主觀偏好(SP)。
Style Similarity: 具體來說,該過程首先使用 CLIP Interrogator 生成與參考圖像對齊的最佳文本提示。 隨后,我們過濾掉與參考圖像內容相關的提示,并計算剩余提示與 CLIP 文本圖像嵌入空間內生成的圖像之間的余弦相似度。 計算結果表示風格相似度,有效減輕參考圖像內容的干擾。
Image Quality:采用名為 LAION-Aesthetics Predictor V2 的預測模型來評估每種方法生成的圖像的質量。
Text Alignment: 確定 CLIP 文本圖像嵌入空間內文本提示與其相應的合成圖像之間的余弦相似度,表明文本對齊能力。
實驗效果
定性分析:
與最先進的方法進行比較,包括無優化方法,如CAST、StyleTr2、T2I-Adapter、IP-Adapter和StyleAdapter,以及基于優化的方法,如InST。

首先,基于內容圖像的風格遷移方法,如CAST和StyleTr2,它們不使用擴散模型,從而避免了文本控制減少的問題。然而,它們僅執行直接的顏色遷移,沒有從參考圖像中提取更獨特的特征,如筆觸和紋理,導致每個合成結果中都存在明顯的偽影。因此,當這些方法遇到具有復雜風格參考和大量內容圖像結構復雜性的情況時,它們的風格轉移能力明顯降低。
另外,對于使用擴散模型進行重建目標訓練的方法,無論是基于優化的(InST)還是無優化的(T2I-Adapter),它們通常都會在生成的結果中受到來自參考圖像的語義干擾,如圖4的第一行和第四行所示。這與我們之前的語義沖突問題的分析相一致。
第三,雖然隨后改進的工作StyleAdapter有效地解決了語義沖突的問題,但它學習到的風格并不理想。它失去了參考圖像的細節筆觸和紋理,顏色也有明顯的差異。
最后,IP-Adapter通過對每個參考圖像進行精細的權重調整,可以實現不錯的結果,但其合成輸出要么引入了一些來自參考圖像的語義,要么風格退化。相反,我們的方法不僅更好地遵循了文本提示,而且顯著保留了參考圖像的整體風格和詳細紋理,顏色色調之間的差異非常小。
定量分析:

在文本對齊方面與生成內容圖像的兩種基于SD的方法CAST和StyleTr2相當,這表明在學習參考圖像的風格時并沒有犧牲SD的原始文本控制能力。
與StyleDrop的比較:

盡管DEADiff在顏色準確性方面略遜于基于優化的StyleDrop,但在藝術風格和對文本的忠實度方面,它取得了相當甚至更好的結果。DEADiff生成的小屋、帽子和機器人更加合適,并且不會遭受參考圖像中固有的語義干擾。這證明了從參考圖像中解耦語義的關鍵作用
應用
應用:與ControlNet的結合
DEADiff支持所有原生于SD v1.5的ControlNet類型。以深度ControlNet為例

應用:風格混合

應用:參考語義的風格化

應用:切換基礎T2I模型
由于DEADiff不對基礎T2I模型進行優化,因此可以直接在不同基礎模型之間切換,生成不同的風格化結果,如下圖10所示





01)



技術詳解)
)









