代碼原理及流程
基于灰狼優化算法優化支持向量機(GWO-SVM)的時序預測代碼的原理和流程如下:
1. **數據準備**:準備時序預測的數據集,將數據集按照時間順序劃分為訓練集和測試集。
2. **初始化灰狼群體和SVM模型參數**:隨機生成一定數量的灰狼,并初始化它們的位置和速度。同時,根據問題要求,初始化支持向量機模型的參數,如懲罰系數C、核函數類型、核函數參數等。
3. **計算適應度**:根據灰狼的位置和速度以及SVM模型參數,計算每個灰狼的適應度,即將其作為SVM回歸模型的參數,評估其在訓練集上的擬合性能,通常使用均方誤差(Mean Squared Error,MSE)來評價預測模型的好壞。
4. **更新灰狼位置**:根據灰狼的適應度,更新每個灰狼的位置,以求得更好的適應度。灰狼在搜索空間中的位置更新受到個體的位置、領袖灰狼的位置和群體的位置的綜合影響。
5. **重復迭代**:重復步驟3和4,直到達到預設的停止條件(如迭代次數達到一定次數或適應度滿足一定條件)。
6. **選擇最佳灰狼**:根據最終的適應度,選擇表現最好的灰狼作為最優解,即作為SVM回歸模型的參數。
7. **使用最優參數進行時序預測**:利用選定的最優參數構建SVM回歸模型,并使用該模型對時序數據進行未來的預測。
通過這個過程,GWO-SVM算法能夠在時序預測問題中自適應地優化SVM的參數,從而提高預測的準確性和性能。在實際實現中,需要根據具體問題對參數進行調優,并結合模型評價指標評估預測效果。
代碼效果圖

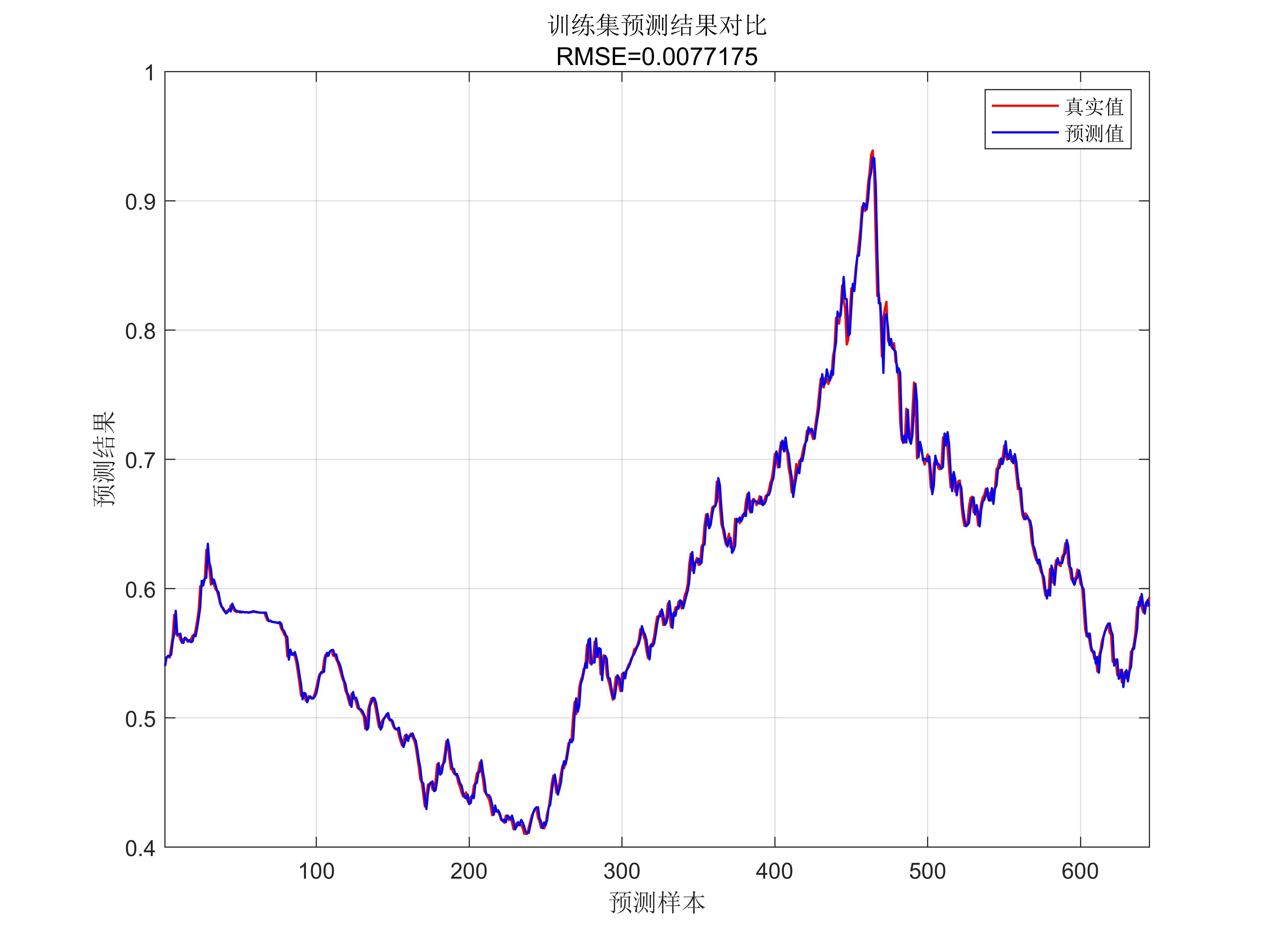

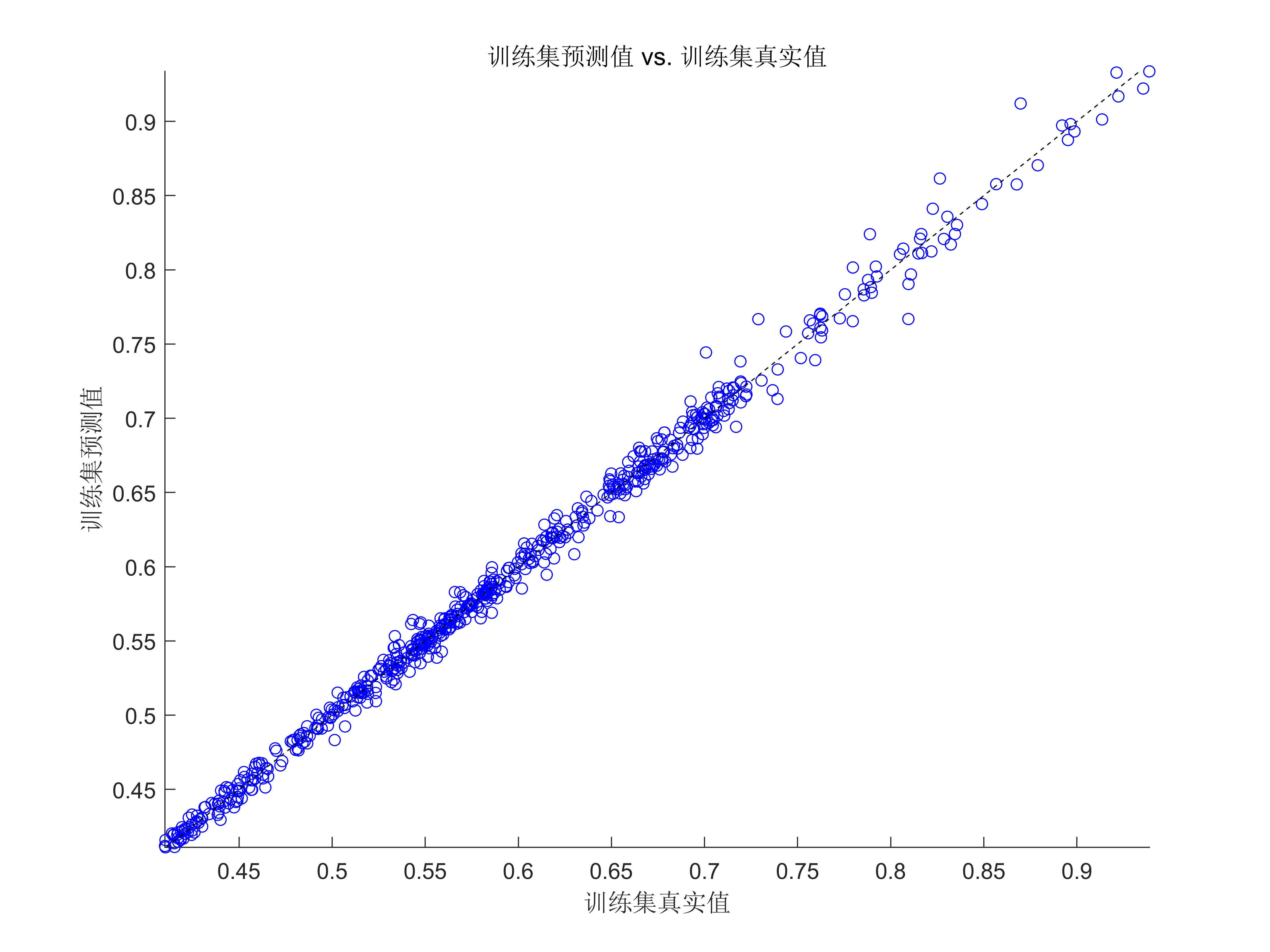
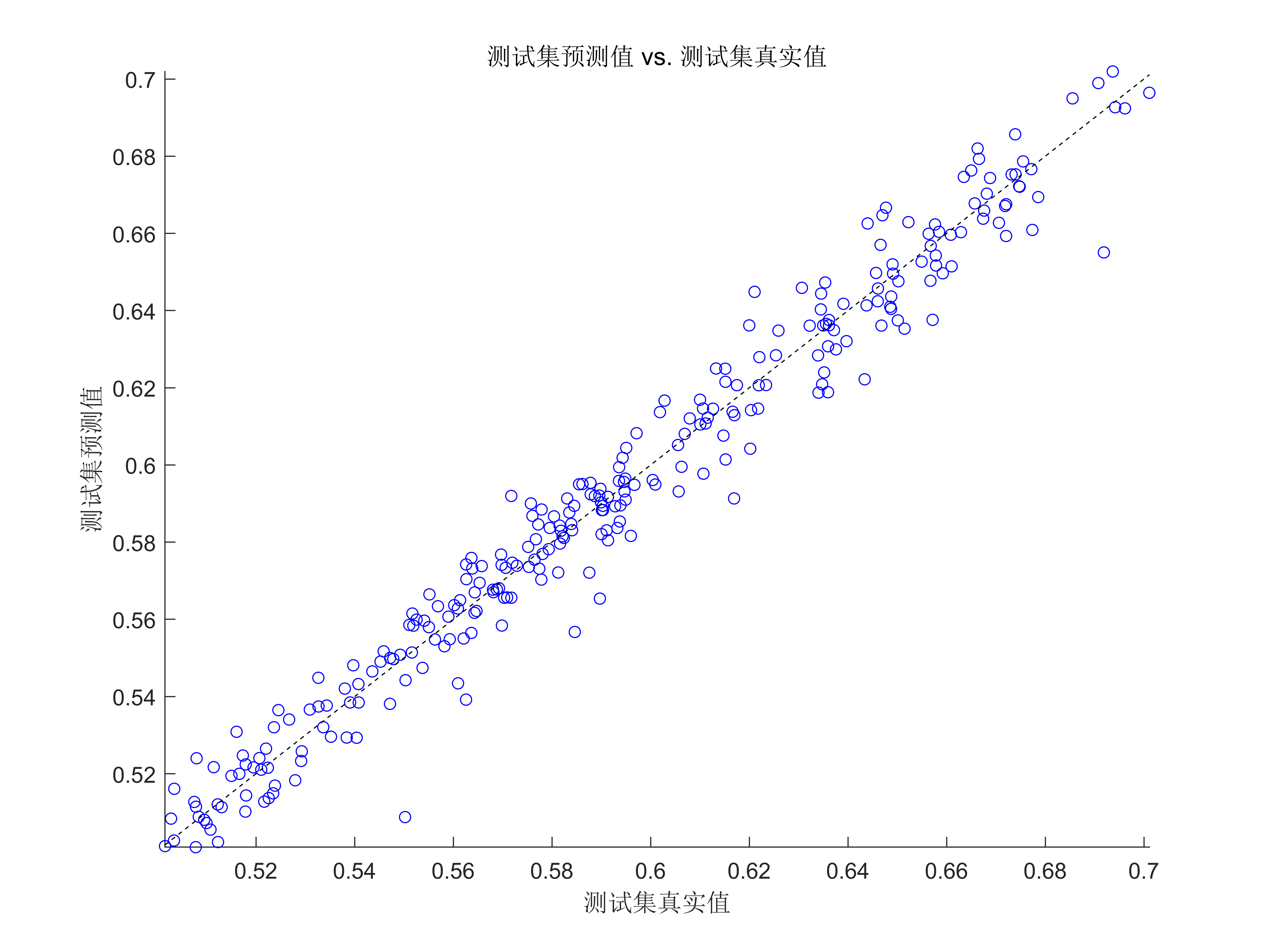
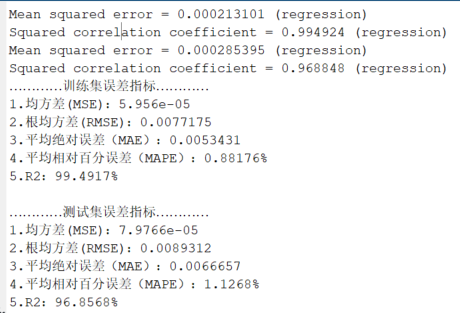
獲取代碼請關注MATLAB科研小白的個人公眾號(即文章下方二維碼),并回復智能優化算法優化SVM本公眾號致力于解決找代碼難,寫代碼怵。各位有什么急需的代碼,歡迎后臺留言~不定時更新科研技巧類推文,可以一起探討科研,寫作,文獻,代碼等諸多學術問題,我們一起進步。













)

![[Algorithm][動態規劃][路徑問題][下降路徑最小和][最小路徑和][地下城游戲]詳細講解](http://pic.xiahunao.cn/[Algorithm][動態規劃][路徑問題][下降路徑最小和][最小路徑和][地下城游戲]詳細講解)



