指數分布的定義
在浙大版的教材中,指數分布的定義如下:
若連續型的隨機變量 X X X的概率密度為:
f ( x ) = { 1 θ e ? x θ , x>0 0 , 其他 f(x) = \begin{cases} \frac{1}{\theta} e^{-\frac{x}{\theta}}, & \text{x>0}\\ 0, & \text{其他} \end{cases} f(x)={θ1?e?θx?,0,?x>0其他?
其中 θ > 0 \theta>0 θ>0為常數,則稱 X X X服從參數為 θ \theta θ的指數分布,其中 θ \theta θ的含義是事件發生的時間間隔
需要特別注意的是在考研大綱中的形式如下:
f ( x ) = { λ e ? λ x , x ≥ 0 0 , 其他 f(x) = \begin{cases} \lambda e^{-\lambda{x}}, & x \geq 0\\ 0, & \text{其他} \end{cases} f(x)={λe?λx,0,?x≥0其他?
其中 λ \lambda λ為每單位時間發生該事件的次數,這種形式更加常見,服從的是參數為 1 λ \frac{1}{\lambda} λ1?的指數分布
指數分布分布的理解與公式推導
在之前的文章中我們說過泊松分布https://blog.csdn.net/qq_42692386/article/details/125916391,可以知道泊松分布其實是描述一段時間內事情發生了多少次(例子中就是營業時間內賣了多少個饅頭)的概率分布,而現在我們想研究一下事件與事件之間間隔時間(賣兩個饅頭之間的間隔時間)的服從什么分布呢?
假如某一天沒有賣出饅頭,比如說周三吧,這意味著,周二最后賣出的饅頭,和周四最早賣出的饅頭中間至少間隔了一天:
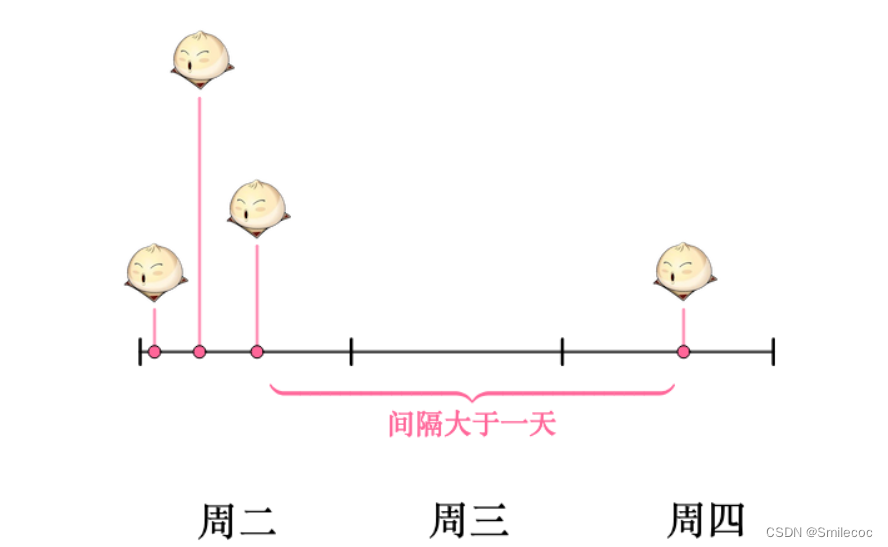
當然也可能運氣不好,周二也沒有賣出饅頭。那么賣出兩個饅頭的時間間隔就隔了兩天,但無論如何時間間隔都是大于一天的:
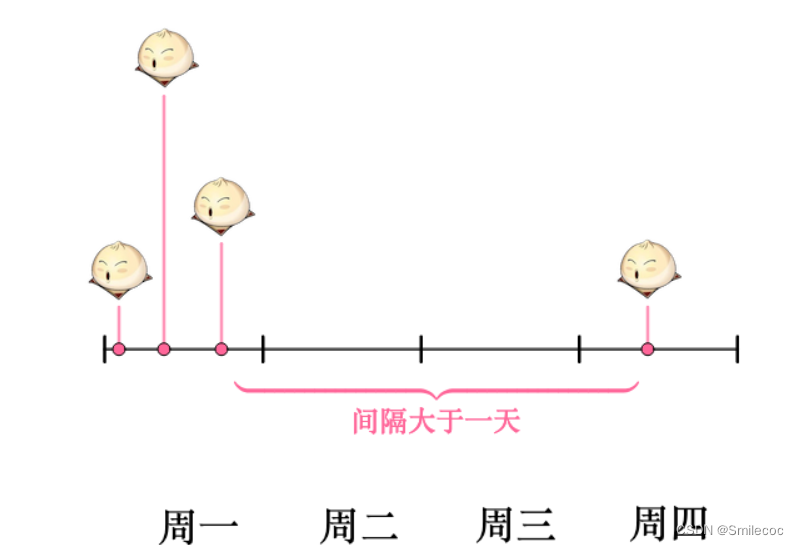
而某一天沒有賣出饅頭的概率可以由泊松分布得出:
P ( X = 0 ) = λ 0 0 ! e ? λ = e ? λ P(X=0)=\frac{\lambda^0}{0!}e^{-\lambda}=e^{-\lambda} P(X=0)=0!λ0?e?λ=e?λ
根據上面的分析,賣出兩個饅頭之間的時間間隔要大于一天,那么必然要包含沒有賣出饅頭的這天,所以兩者的概率是相等的。如果假設隨機變量為:
Y = 賣出兩個饅頭之間的時間間隔 Y=賣出兩個饅頭之間的時間間隔 Y=賣出兩個饅頭之間的時間間隔
那么就有:
P ( Y > 1 ) = P ( X = 0 ) = e ? λ P(Y > 1)=P(X=0)=e^{-\lambda} P(Y>1)=P(X=0)=e?λ
但是現在問題出現了:之前求出的泊松分布實在限制太大,只告訴了我們每天賣出的饅頭數。而兩個饅頭賣出的事件間隔可能是大于一天,也有可能只間隔了幾分鐘,所以我們想知道任意的事件間隔里賣出的饅頭數量的概率分布,比如半天賣出的饅頭數的分布,一小時賣出的饅頭數的分布。
稍微擴展下可以得到新的函數:
P ( X = k , t ) = ( λ t ) k k ! e ? λ t P(X=k,t)=\frac{({\lambda}{t})^k}{k!}e^{-\lambda{t}} P(X=k,t)=k!(λt)k?e?λt
擴展后得到的這個函數稱為泊松過程,具體的推導過程比較復雜,可以自行搜索學習,這里不再贅述。
通過新的這個函數就可知不同的時間段 t t t內賣出的饅頭數的分布了( t = 1 t=1 t=1時就是泊松分布):
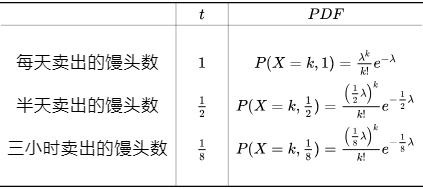
根據之前的分析,兩次賣出饅頭之間的時間間隔大于 t t t的概率,等同于 t t t時間內沒有賣出一個饅頭的概率,而后者的概率可以由泊松過程給出。還是一樣假設隨機變量 Y = 賣出兩個饅頭之間的時間間隔 Y=賣出兩個饅頭之間的時間間隔 Y=賣出兩個饅頭之間的時間間隔
則隨機變量 Y Y Y的概率:
P ( Y > t ) = P ( X = 0 , t ) = ( λ t ) 0 0 ! e ? λ t = e ? λ t , t ≥ 0 P(Y > t)=P(X=0,t)=\frac{({\lambda}{t})^0}{0!}e^{-\lambda{t}}=e^{-\lambda{t}},t \geq 0 P(Y>t)=P(X=0,t)=0!(λt)0?e?λt=e?λt,t≥0
進而有:
P ( Y ≤ t ) = 1 ? P ( Y > t ) = 1 ? e ? λ t P(Y \leq t)=1-P(Y > t)=1-e^{-\lambda{t}} P(Y≤t)=1?P(Y>t)=1?e?λt
這其實已經得到了 的累積分布函數了:
F ( y ) = P ( Y ≤ y ) = { 1 ? e ? λ y , y ≥ 0 0 , y < 0 F(y)=P(Y \leq y)= \begin{cases} 1-e^{-\lambda{y}}, & y\geq 0 \\ 0, & y<0 \end{cases} F(y)=P(Y≤y)={1?e?λy,0,?y≥0y<0?
對其求導就可以得到概率密度函數:
f ( y ) = { λ e ? λ y , y ≥ 0 0 , y < 0 f(y)= \begin{cases} \lambda e^{-\lambda{y}}, & y\geq 0 \\ 0, & y<0 \end{cases} f(y)={λe?λy,0,?y≥0y<0?
這就是賣出饅頭的時間間隔 的概率密度函數,也就是指數分布 。
對應參數的含義辨析
和教科書中的定義比較,可以看到對應的形式稍微不一樣,但是實際上 λ = 1 θ \lambda=\frac{1}{\theta} λ=θ1?,這里 θ \theta θ的含義是事件發生的事件間隔。根據之前的泊松分布定義和推導過程我們知道這里的 λ \lambda λ是對應隨機事件在對應時間內的數學期望。在泊松分布中是對應的單位時間內賣出的饅頭數量的總和,而在指數分布中,由于我們要研究的是隨機事件是對應的隨機事件發生間隔,所以對應隨機事件的期望(也就是賣出兩個饅頭的時間間隔的期望)是單位時間發生次數(賣出的饅頭數量)的倒數。所以可以將參數 λ \lambda λ改為 1 θ \frac{1}{\theta} θ1?,即可得到教科書中參數為 1 θ \frac{1}{\theta} θ1?的公式:
舉個例子:如果您每天賣了3個饅頭( λ = 3 \lambda=3 λ=3),則意味著每賣出2個饅頭的間隔期望為 1 3 \frac{1}{3} 31?( θ = 1 λ = 1 3 \theta=\frac{1}{\lambda}=\frac{1}{3} θ=λ1?=31?)。在有的參考書中, θ \theta θ被稱為“衰減率”*
指數分布的圖像
指數分布中的 λ \lambda λ是每日平均賣出的饅頭數,如果 λ \lambda λ越大,也就是說每日賣出的饅頭越多,那么兩個饅頭之間的時間間隔必然越短,這點從圖像上也可以看出。
當 λ \lambda λ較小的時候,比如說 λ = 1 \lambda=1 λ=1吧,也就是說一天只賣出一個饅頭,那么饅頭賣出間隔時間大于1的可能性就很大(下圖是指數分布的概率密度函數的圖像,對應的概率是曲線下面積):
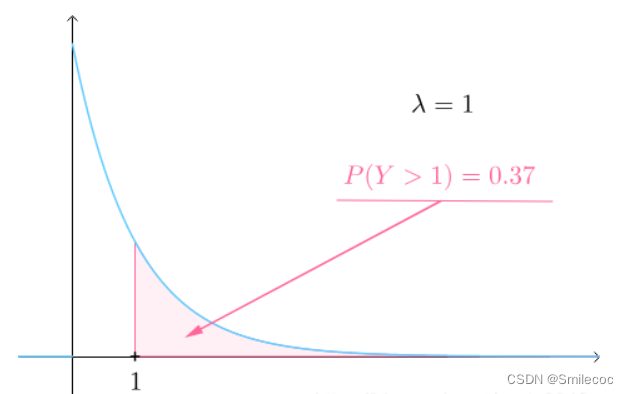
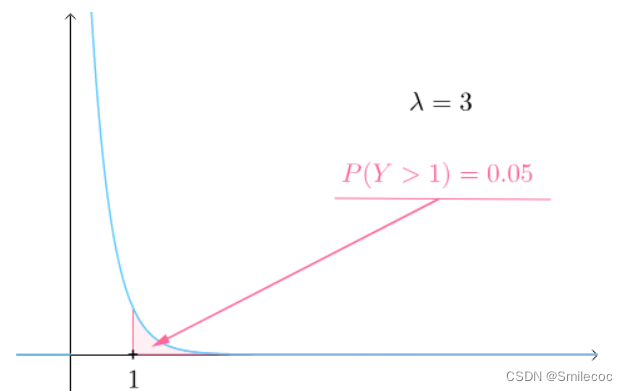
而如果 λ \lambda λ較大的時候,比如說 λ = 3 \lambda=3 λ=3,也就是說一天賣出三個饅頭,那么饅頭賣出間隔時間大于1的可能性已經變得很小了:
指數分布期望與方差
指數分布的期望值是:
E ( X ) = 1 λ {E} (X)={\frac {1}{\lambda }} E(X)=λ1?
這個很好理解:如果你平均每天賣兩個饅頭,那么你預期每賣一個饅頭的時間是半天。
指數分布的方差:
D ( X ) = 1 λ 2 {D} (X)={\frac {1}{\lambda^2 }} D(X)=λ21?
嚴格的推導過程如下:
首先,指數分布屬于連續型隨機分布,因此,其期望E(X)為:
E ( X ) = ∫ ? ∞ + ∞ ∣ x ∣ f ( x ) d x = ∫ 0 + ∞ x f ( x ) d x = ∫ 0 + ∞ x λ e ? λ x d x = 1 λ ∫ 0 + ∞ λ x e ? λ x d λ x E(X)=\int_{-\infty}^{+\infty} |x|f(x)dx=\int_{0}^{+\infty}xf(x)dx=\int_{0}^{+\infty}x \lambda e^{-\lambda{x}}dx= \frac{1}{\lambda}\int_{0}^{+\infty} {\lambda}x e^{-\lambda{x}}d{\lambda}x E(X)=∫?∞+∞?∣x∣f(x)dx=∫0+∞?xf(x)dx=∫0+∞?xλe?λxdx=λ1?∫0+∞?λxe?λxdλx
令 u = λ x u=λx u=λx,并使用分步積分法積分,則:
E ( X ) = 1 λ ∫ 0 + ∞ u e ? u d u = 1 λ [ ( ? e ? u ? u e ? u ) ∣ 0 + ∞ = 1 λ E(X)=\frac{1}{\lambda}\int_{0}^{+\infty}ue^{?u}du=\frac{1}{\lambda}[(?e^{?u}?ue^{?u})\big|_{0}^{+\infty}=\frac{1}{\lambda} E(X)=λ1?∫0+∞?ue?udu=λ1?[(?e?u?ue?u) ?0+∞?=λ1?
對于指數分布的方差D(X)有:
D ( X ) = E ( X 2 ) ? ( E ( X ) ) 2 D(X)=E(X^2)-(E(X))^2 D(X)=E(X2)?(E(X))2
其中
E ( X 2 ) = ∫ ? ∞ ∞ ∣ x 2 ∣ f ( x ) d x = ∫ 0 ∞ x 2 f ( x ) d x = ∫ 0 ∞ x 2 ? λ e ? λ x d x E(X^2)=\int_{-\infty }^{\infty }|x^2|f(x)dx=\int_{0}^{\infty }x^2f(x)dx=\int_{0}^{\infty }x^2\cdot\lambda e^{-\lambda x}dx E(X2)=∫?∞∞?∣x2∣f(x)dx=∫0∞?x2f(x)dx=∫0∞?x2?λe?λxdx
E ( X 2 ) = 1 λ 2 ∫ 0 ∞ λ x λ x e ? λ x d λ x E(X^2)=\frac {1} {\lambda^2}\int_{0}^{\infty }\lambda x \lambda xe^{-\lambda x}d\lambda x E(X2)=λ21?∫0∞?λxλxe?λxdλx
同樣令 u = λ x u=λx u=λx,并使用分步積分法積分,則:
E ( X 2 ) = 1 λ 2 ∫ 0 ∞ u 2 e ? u d u = 1 λ 2 [ ( ? 2 e ? u ? 2 u e ? u ? u 2 e ? u ) ∣ ( ∞ , 0 ) ] = 1 λ 2 ? 2 = 2 λ 2 E(X^2)=\frac {1} {\lambda^2}\int_{0}^{\infty }u^2e^{-u}du=\frac {1} {\lambda^2}[(-2e^{-u}-2ue^{-u}-u^2e^{-u})|(\infty,0)]=\frac {1} {\lambda^2}\cdot 2=\frac {2} {\lambda^2} E(X2)=λ21?∫0∞?u2e?udu=λ21?[(?2e?u?2ue?u?u2e?u)∣(∞,0)]=λ21??2=λ22?
即可利用公式解得
D ( X ) = E ( X 2 ) ? ( E ( X ) ) 2 = 2 λ 2 ? ( 1 λ ) 2 = 1 λ 2 D(X)=E(X^2)-(E(X))^2=\frac {2} {\lambda^2}-(\frac {1} {\lambda})^2=\frac {1} {\lambda^2} D(X)=E(X2)?(E(X))2=λ22??(λ1?)2=λ21?
指數分布的無記憶性
無記憶性是指經過一定的試驗次數或時間后,隨機變量的條件概率仍服從相同的分布,形象化地說計算后續的分布時可以把過去的經歷完全忽略忘記,故稱為無記憶性
P ( X > s + t ∣ X > s ) = P ( X > t ) , s , t ≥ 0 P(X>s+t \mid X>s)=P(X>t), \quad \ \ s, t \geq 0 P(X>s+t∣X>s)=P(X>t),??s,t≥0
指數分布的無記憶性證明如下:
P ( X > s + t ∣ X > s ) = P { ( X > s + t ) ∩ ( X > s ) } P ( X > s ) = P ( X > s + t ) P ( X > s ) = 1 ? F ( s + t ) 1 ? F ( s ) = e ? λ ( s + t ) e ? λ ( s ) = e ? λ t = P ( X > t ) P(X>s+t \mid X>s)=\frac{P\{(X>s+t) \cap ( X>s)\}}{ P( X>s)} \\ =\frac{P(X>s+t)}{ P( X>s)} =\frac{1-F(s+t)}{ 1-F(s)} \\ =\frac{e^{-\lambda(s+t)}}{e^{-\lambda(s)}}=e^{-\lambda{t}}=P(X>t) P(X>s+t∣X>s)=P(X>s)P{(X>s+t)∩(X>s)}?=P(X>s)P(X>s+t)?=1?F(s)1?F(s+t)?=e?λ(s)e?λ(s+t)?=e?λt=P(X>t)
在浙大教材中有個例子:如果X是某一個電器的使用壽命,在使用過 s 小時后,它還能再使用 t 小時的概率,和它一開始算壽命就是 t 小時的概率是一樣的。
很多人覺得日常生活中的電子元件用了十年之后不可能還能和新的有一樣的預期壽命,實際上這個例子應該要加上一個條件的:如果將電器考慮作理想的電器,器件不會老化。
此時,電器的壽命是隨機的。可以視為電器內部彷佛每秒鐘都在扔硬幣(扔硬幣很好理解,不管前面扔了多少次,再扔一次硬幣正反面的概率仍是二分之一),扔到了正面,電器就壞了。在這種情況下,我們認為電器的壽命服從指數分布。現實中是不會有理想電器的,但是如果只考慮短時間內的電器壽命,那么就可以將之視作理想電器,認為它的壽命服從指數分布。
指數分布應用實例
假設銀行平均每 10 分鐘接到一個新電話。客戶致電后,確定下一個客戶在之后 10 到 15 分鐘內致電的可能性。
λ = 1 10 = 0.1 λ =\frac{1}{10}=0.1 λ=101?=0.1
則新客戶在 10-15 分鐘內致電的概率:
P ( 10 < X ≤ 15 ) = P ( X ≤ 15 ) ? P ( X ≤ 10 ) = ( 1 – e ? 0.1 × 15 ) – ( 1 – e ? 0.1 × 10 ) = 0.7769 – 0.6321 = 0.1448 P(10 < X ≤ 15) =P( X ≤ 15)-P(X ≤ 10)= (1 – e^{ -0.1\times15} )– (1 – e^{ -0.1\times10 })= 0.7769 – 0.6321= 0.1448 P(10<X≤15)=P(X≤15)?P(X≤10)=(1–e?0.1×15)–(1–e?0.1×10)=0.7769–0.6321=0.1448
所以下一個客戶在之后 10-15 分鐘內致電的可能性是0.1448 。
參考文章:
https://blog.csdn.net/ccnt_2012/article/details/89875865



















:ISBN號碼+kotori和迷宮+矩陣最長遞增路徑)
