論文:Medical Image Segmentation Using Deep Learning: A Survey
參考:[醫學圖像分割綜述] Medical Image Segmentation Using Deep Learning: A Survey-CSDN博客
一、背景
- 特征表示的困難:模糊、噪聲、對比度低--->CNN
- 屬于語義分割(對圖像進行像素分類)的范疇:
-
語義分割(Semantic Segmentation):語義分割的目標是將圖像中的每個像素分配到一個類別。它關注的是類別,而不區分同一類別中的不同個體。例如,在一幅街景圖像中,語義分割會將所有的“車”像素標注為“車”類別,而不區分這些車是不同的個體。
-
實例分割(Instance Segmentation):實例分割不僅將每個像素分配到一個類別,還要區分同一類別中的不同個體。它結合了目標檢測和語義分割的特點。例如,在一幅街景圖像中,實例分割不僅會標注出所有的“車”,還會區分這些車是不同的個體,給每輛車一個唯一的標識。
-
二、監督學習?
1.網絡骨干
1)U-Net
參考:U-Net網絡結構講解(語義分割)_嗶哩嗶哩_bilibili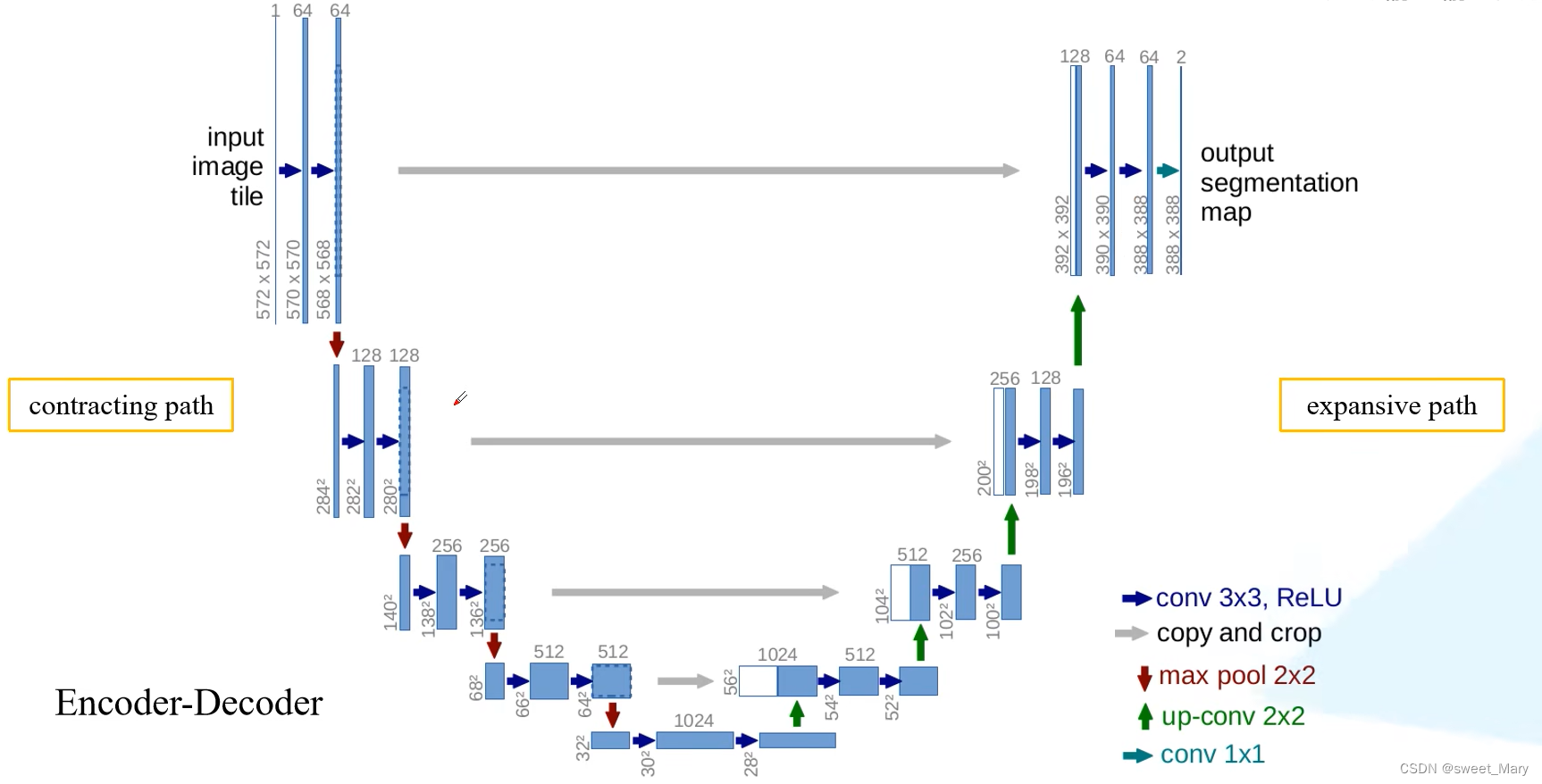
通過跳躍連接,將低分辨率和高分辨率的特征圖結合起來,有效地融合了低分辨率和高分辨率的圖像特征。
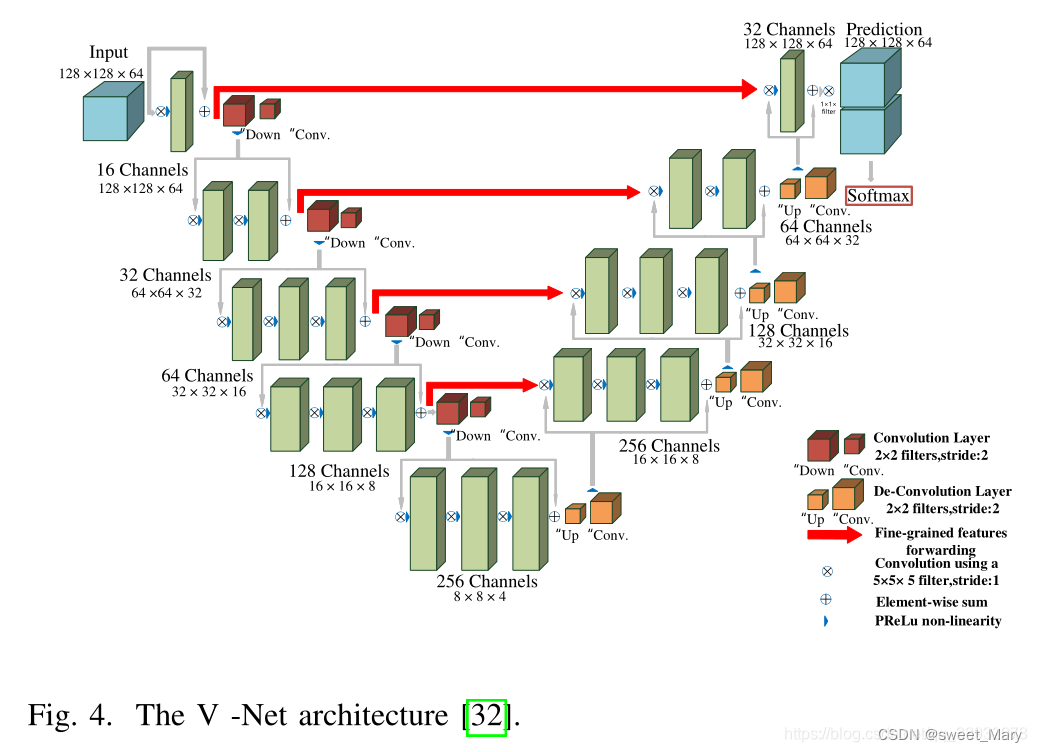
2)3D-Net
全篇為[醫學圖像分割綜述] Medical Image Segmentation Using Deep Learning: A Survey-CSDN博客的筆記~
3D U-Net僅包含3次下采樣,不能有效提取深層圖像特征,導致醫學圖像分割精度有限。與3D-UNet相比,V-Net利用殘差連接設計更深層次的網絡(4次下采樣),從而獲得更高的性能。
3)RNN?
- 圖像序列時間依賴性
- 通過將輸入特征圖直接添加到經過卷積和激活函數處理后的特征圖中,模型可以更有效地傳遞信息,避免梯度消失問題。
- 從圖中可以看到,卷積層和激活函數的輸出會回饋到自身,并且重復進行多次。這種循環結構使得模型可以通過多次迭代來逐步精煉特征,從而提高分割的精度和效果。
- 殘差連接通過直接將輸入特征圖添加到經過多次卷積和激活后的特征圖中,使得梯度在反向傳播過程中能夠更有效地傳遞,減輕梯度消失問題,提升深層網絡的訓練效果。
- 梯度消失問題會導致在反向傳播過程中,梯度變得非常小,以至于模型無法有效地學習和更新參數。
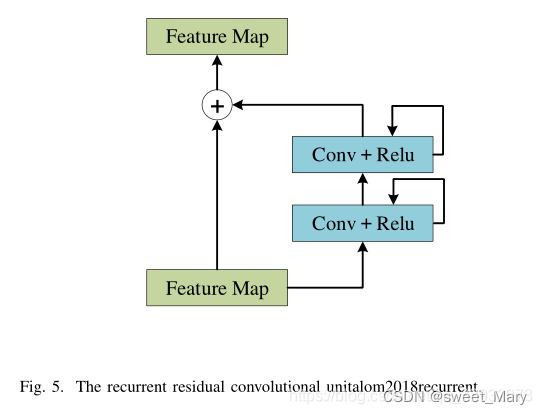
- RNN可以通過考慮上下文信息關系來捕獲圖像的局部和全局空間特征。?
4)SKip Connection?
- 跳躍連接:低分辨率和高分辨率特征之間語義鴻溝較大的問題,導致特征映射模糊
- MultiResUNet:使編碼器特征在與解碼器中相應特征融合之前執行一些額外的卷積操作
5)Cascade of 2D and 3D?(級聯模型)
- 訓練兩個或多個模型來提高分割精度
- 粗-細分割:使用兩個2D網絡的級聯進行分割,其中第一個網絡進行粗分割,然后使用另一個網絡模型在之前的粗分割結果的基礎上實現細分割,這種級聯網絡利用第一個網絡產生的后驗概率比普通級聯網絡能有效地提取更豐富的多尺度上下文信息。
- 混合分割(H-DenseUNet):首先利用簡單的ResNet獲得粗略的肝臟分割結果,利用二維DenseUNet有效提取二維圖像特征,然后利用三維DenseUNet提取三維圖像特征,最后設計一種混合特征融合層,對二維和三維特征進行聯合優化。
- 處理模糊噪聲邊界(Ki-Net):通過在編碼器的每一轉換層之后加上上采樣層來實現。利用Ki-Net的低層精細邊緣特征圖和U-Net的高層形狀特征圖,不僅提高了分割精度,而且對小解剖標志和模糊的噪聲邊界實現了快速收斂。
2.網絡塊
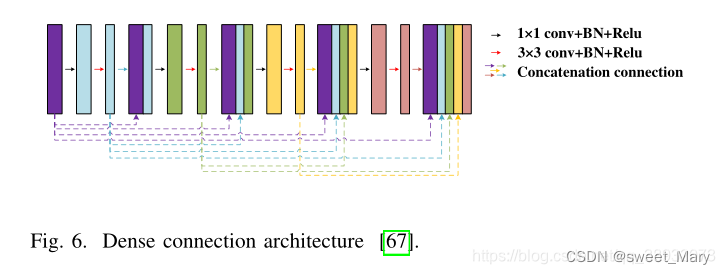
1)Dense Connection(密集連接)
- 改進一
- 每一層的輸入來自前面所有層的輸出
- 用密集連接的形式來代替U-Net的每個子塊
- 低了特征表示的魯棒性,增加了參數的數量
- 改進二?
- 優點:允許網絡自動學習不同層次特征的重要性
- 具有不同語義尺度的特征可以在譯碼器中聚合
- 增加了參數的數量(剪枝方法)
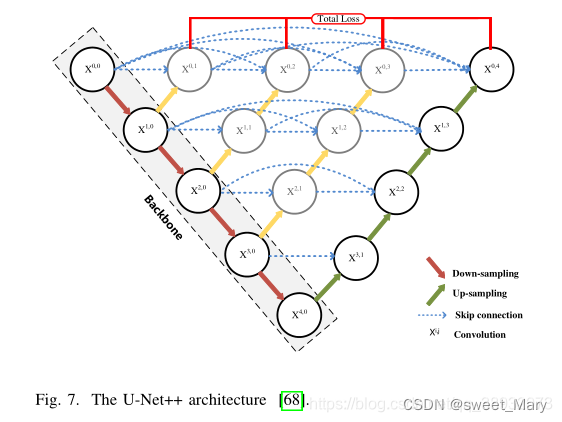
2)Inception(多種卷積核大小的并行路徑)
- 深度網絡:梯度消失、網絡收斂困難、內存占用大等
- 不增加網絡深度的情況下并行地合并卷積核,從而獲得更好的性能
- 利用多尺度卷積核提取更豐富的圖像特征,并進行特征融合,獲得更好的特征表示
- 比較復雜,導致模型修改困難
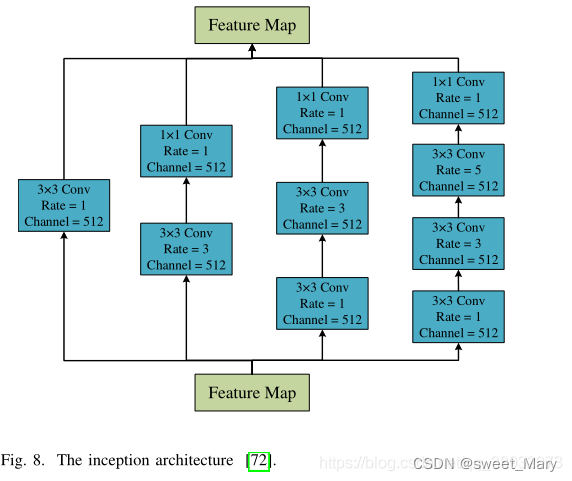
3)Depth Separability?(深度可分離)
- 減少對內存的使用需求--->輕量級網絡
- 普通卷積的參數:
,其中
為卷積核大小,
為輸入特征的維數,
為輸出特征的維數:
- 逐通道卷積、逐點卷積
- 逐通道卷積:
- 逐點卷積:
- 逐通道卷積:
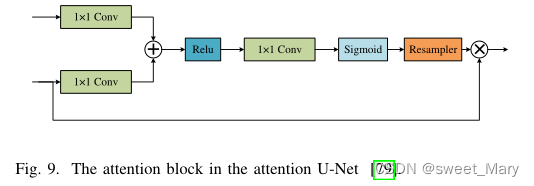
4)Attention Mechanism(注意力機制)
- 掩碼:設計一個新的層,通過訓練和學習,可以從圖像中識別關鍵特征
- 局部空間注意力(Local Spatial Attention):計算每個像素在空間域中的特征重要性,提取圖像的關鍵信息
- 通過1 × 1卷積結合Relu和Sigmoid函數,生成一個權值映射,并通過與編碼器的輸出特征相乘進行校正
- 個人理解:Q:輸入編碼器的內容,K/V:編碼器的輸出特征
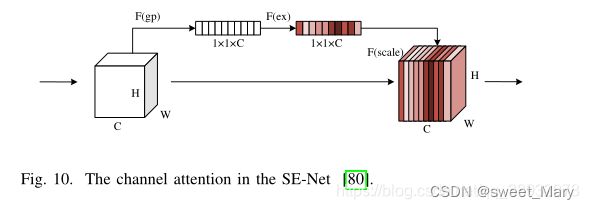
- 通道注意力(Channel Attention):利用學習到的全局信息,選擇性地強調有用的特征
- 壓縮操作,對輸入特征進行全局平均池化,得到1 × 1 × channel的特征映射
- 激勵操作,通過通道特征的相互作用來減少通道數量,然后將減少的通道特征重構回信道數量
- 使用sigmoid函數生成[0,1]的特征權重映射,將比例乘回到原始輸入特征
- 混合注意力(Mixture Attention):
- 空間注意力忽略了不同通道信息的差異,對每個通道都一視同仁
- 通道注意力直接集中全局信息,而忽略每個通道的局部信息
- 多種基于混合注意力塊的模型
- 以通道為中心的注意力是提高圖像分割性能最有效的方法
- 非局部注意力(Non-local Attention):
- 等于自注意力機制
- 與非局部注意相比,傳統的注意力機制缺乏挖掘不同目標和特征之間關聯的能力

?5)Multi-scale Information Fusion(多尺度信息融合)
- 目標尺度的大范圍變化:中晚期的腫瘤可能比早期的大得多
- 金字塔池化(Pyramid Pooling)
- 多尺度池化的并行操作
- 殘差多核池化(RMP):使用四個不同大小的池化核來編碼全局上下文信息
- 上采樣操作不能恢復細節信息的丟失,因為池化通常擴大了感受野,但降低了圖像分辨率。
- 空洞空間金字塔池化(Atrous Spatial Pyramid Pooling)
- ???????用空洞卷積
- 兩個問題:局部信息的丟失;這些信息在遠距離傳播后可能是不相關的
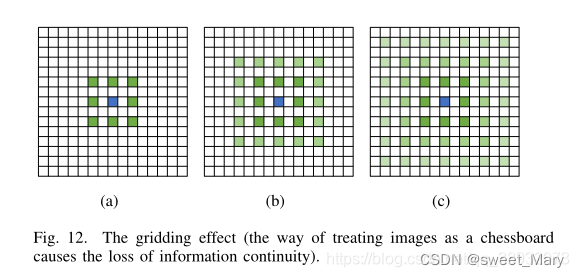
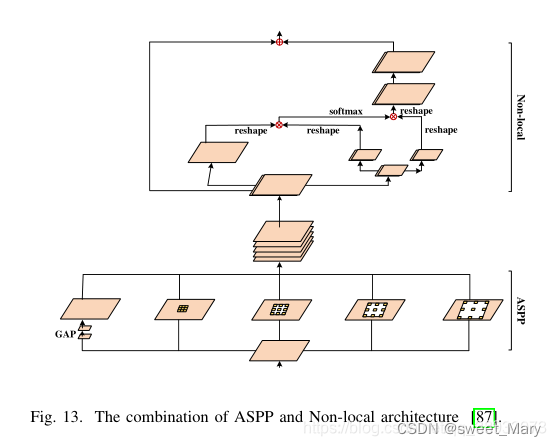
- 非局部和ASPP(Non-local and ASPP)
- ??????????????不同尺度的多個并行空洞卷積來捕獲更豐富的信息
- 非局部操作捕獲廣泛的依賴關系?
三、損失函數的設計
1.Cross Entropy Loss(交叉熵)
- 將預測的分類向量與實際的分割結果向量進行像素級的比較
-
第一項
:
- 當真實標簽 Y 為1時(即 p=1),這項起作用。如果預測概率
也接近1,這項的值會很小。
- 如果
- 當真實標簽 Y 為1時(即 p=1),這項起作用。如果預測概率
-
第二項
:
- 當真實標簽 Y 為0時(即 p=0),這項起作用。如果預測概率
- 如果
- 當真實標簽 Y 為0時(即 p=0),這項起作用。如果預測概率
- 公式:
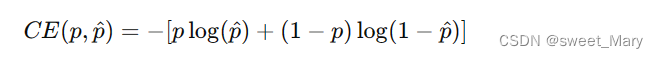
2.Weighted Cross Entropy Loss
- 交叉熵損失對圖像的每個像素都進行同等處理,從而輸出一個平均值,忽略了類的不平衡
-
β用于調整正樣本和負樣本的比例,它是一個經驗值,如果β > 1,假陰性數量減少;反之如果β<1,假陽性數量減少
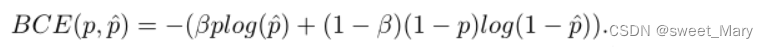
- 添加距離函數改進交叉熵損失函數的U-Net,改進后的損失函數可以提升類間距離的學習能力
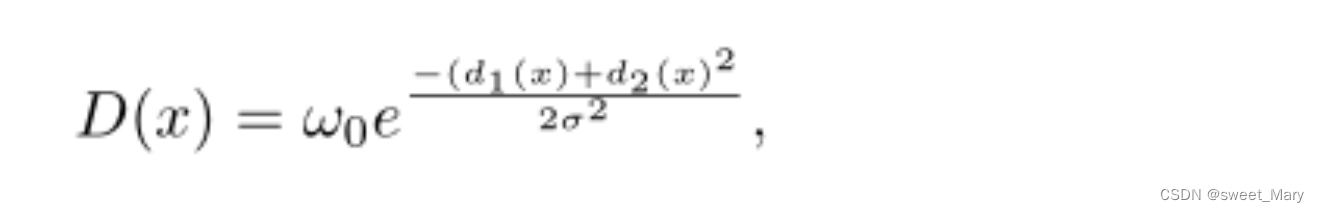
-
其中?
和
代表了像素
和前兩個最近單元格邊界之間的距離
-
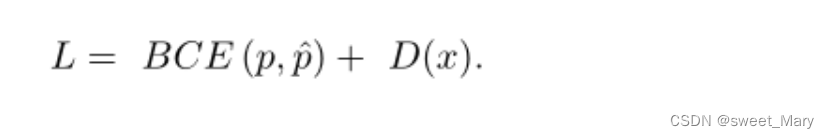










:ISBN號碼+kotori和迷宮+矩陣最長遞增路徑)







修改好了可以持久保存的vue3留言板)
