上一節內容的補充:I/O多路復用是同步的,只有調用某些API才是異步的
Unix/Linux上的五種IO模型
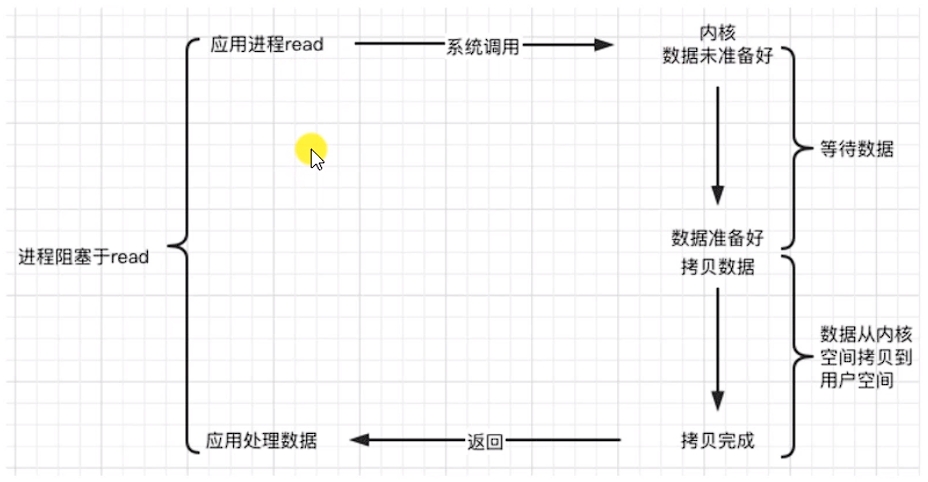
a.阻塞 blocking
調用者調用了某個函數,等待這個函數返回,期間什么也不做,不停地去檢查這個函數有沒有返回,必須等這個函數返回才能進行下一步動作。
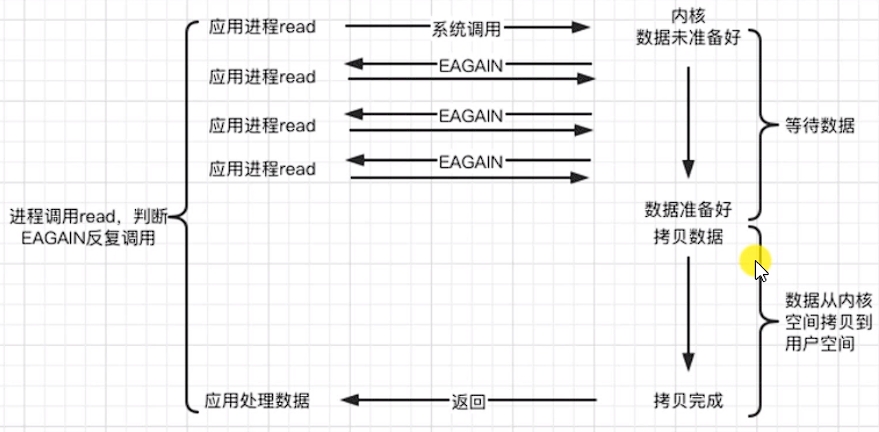
b.非阻塞 non-blocking
非阻塞等待,每隔一段時間就去檢測IO事件是否就緒,沒有就緒時可以去做其他事。非阻塞IO執行系統調用時總是立即返回,不管事件是否已經發生,若事件沒有發生,則返回-1,此時可以根據errno區分這兩種情況,對于 accept, recv, send 這些事件未發生時,errno 通常被設置為 EAGAIN
c. IO復用 IO multiplexing
Linux用 select/poll/epoll 函數實現 IO 復用模型,這些函數也回使進程阻塞,但是和阻塞 IO 所不同的是這些函數可以同時阻塞多個 IO 操作。而且可以同時對多個讀操作、寫操作的 IO 函數進行檢測,直到有數據可讀或可寫時,才真正調用 IO 操作函數。
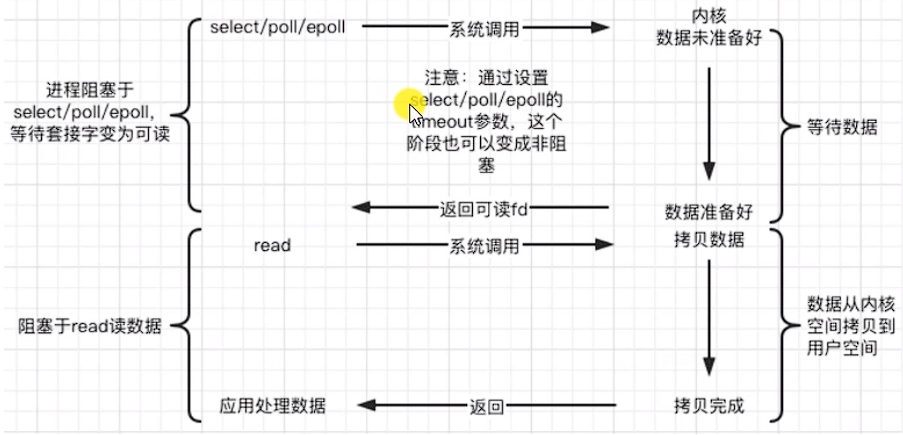
*注意:IO 復用的目的并不是提高程序處理多個客戶端的能力,單線程、單進程同時檢測多個文件描述符是否可以執行 IO 操作的能力
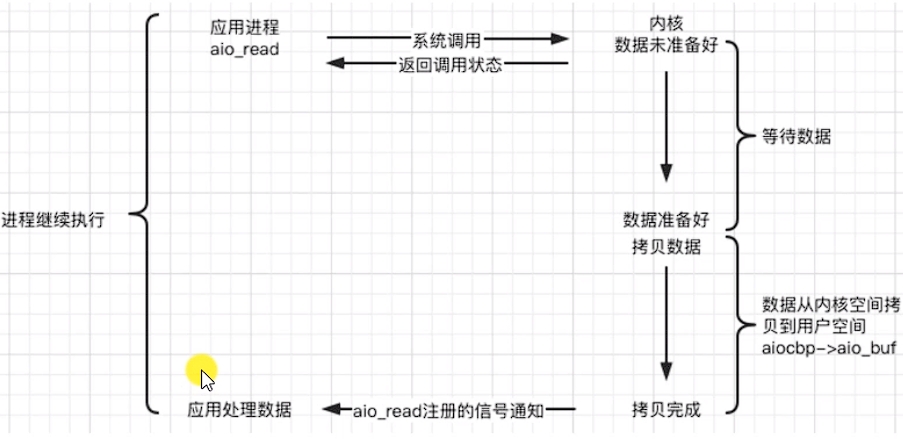
d.信號驅動 signal-driven
Linux用套接口進行信號驅動 IO ,安裝一個信號處理函數,進程繼續運行并不阻塞,當 IO 事件就緒,進程收到 SIGIO 信號,然后處理 IO 事件。
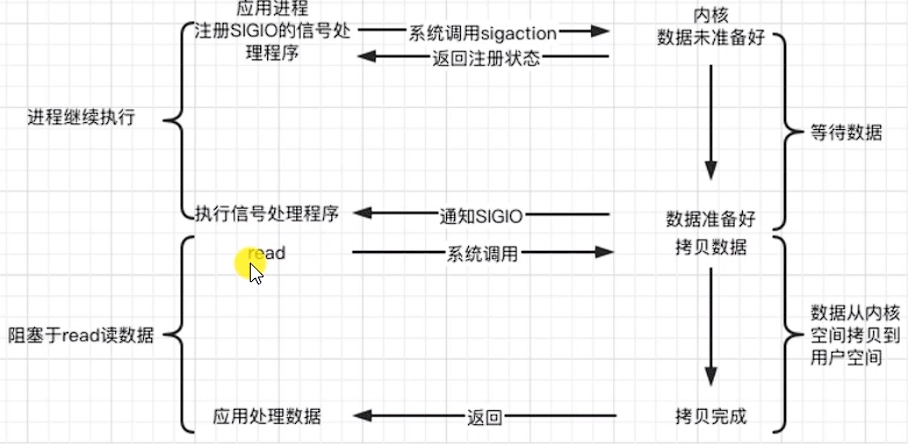
在上圖中,“等待數據”為階段一,“數據從內核空間拷貝到用戶空間”為階段二。內核在階段一是異步的,在階段二是同步的;與非阻塞 IO 的區別在于它提供了消息通過機制,不需要用戶進程不斷地輪詢檢查,減少了系統 API? 的調用次數,提高了效率。
e.異步 asynchronous
Linux中,可以調用 aio_read 函數告訴內核文件描述符緩沖區指針和大小、文件偏移量及通知的方式,然后立即返回,此時用戶進程可以去做自己的事情。當內核將數據拷貝到緩沖區后,再通知應用程序。
以上五種 IO 模型,在實際應用中,最常用的是非阻塞模型和 IO 復用模型。









:ISBN號碼+kotori和迷宮+矩陣最長遞增路徑)







修改好了可以持久保存的vue3留言板)

