????????說明 :經過多次交互,前后花了幾個小時,總算完成了基本功能。如果做到按不同層次分配考場,一鍵出打印結果就完美了。如果不想看中間“艱苦”的過程,請直接跳到“最后結果”及“食用方法”。中間過程還省略了一部分交互,gpt-4o一個線程限制了會話的次數(100),大概開了三個線程完成了任務。在此過程中自己可能提示詞描述不夠準確。以后在描述問題時還需要改進,后續添加交互,打包為exe
????????在日常的教務活動中,考場安裝很費時的事。學校平時考場安排,不像大型考試每考室人數固定,有時還會按不同層次的學生安排考場,要求比較多,排定后還需手工調整。
第一次給的提示語:
?電子表格”考場安排demo.xlsx“的字段為:班級、準考證號、學生姓名、考場、考號。其中考場、考號需要程序來安排的,請按以下要求給出python程序。1、總考場數為24個2、請平均分配每考場人數3、每個考場的座位號從1開始編號,依次為2, 3, 4,...。4、隨機安排學生,注意是隨機,但要保證在一個考場中相鄰兩條記錄,它們班級字段的值不相等。5、將安排好的結果以“考場安排結果.xlsx"保存經過了幾次迭代:
?上面的程序執行了很長時間,即沒有結果,也沒有出錯提示錯誤仍然存在如果每考場的學生班號隨機一點就更好了
此時出現警告
?A value is trying to be set on a copy of a slice from a DataFrame
直接將警告提交給gpt
?當我重新運行以上程序時,雖然沒有了警告提示,運行很長時間沒有結果
這時給出了正確的結果
?import pandas as pdimport randomfrom openpyxl import Workbookimport numpy as np??def load_data(filename):return pd.read_excel(filename)??def save_data(df, filename):df.to_excel(filename, index=False)??def assign_seats(df, total_halls):# 按班級分組并隨機打亂每個班級內部的順序grouped = df.groupby('班級')groups = [group.sample(frac=1).reset_index(drop=True) for _, group in grouped]?# 創建調度器隊列,初始化為每個班級的iteratoriterators = [iter(group.iterrows()) for group in groups]?arranged_data = []hall_number = 1seat_number = 1?total_students = len(df)students_per_hall = total_students // total_hallsextra_students = total_students % total_halls?while iterators:random.shuffle(iterators)for it in iterators[:]: ?# 遍歷每個迭代器try:_, student = next(it)student_data = student.to_dict()student_data["考場"] = hall_numberstudent_data["考號"] = seat_numberarranged_data.append(student_data)?seat_number += 1?if seat_number > students_per_hall + (1 if hall_number <= extra_students else 0):hall_number += 1seat_number = 1?if hall_number > total_halls:hall_number = 1except StopIteration:iterators.remove(it) ?# 當前iterator已遍歷完全,移除它?return arranged_data??def main():input_filename = "考場安排demo.xlsx"output_filename = "考場安排結果.xlsx"?total_halls = 24?df = load_data(input_filename)arranged_students = assign_seats(df, total_halls)arranged_df = pd.DataFrame(arranged_students)?save_data(arranged_df, output_filename)??if __name__ == "__main__":main()重新給了提示語:座位號改為01、02、03...,添加了時間戳。
?電子表格”考場安排demo.xlsx“的字段為:班級、準考證號、學生姓名、考場、考號。其中考場、考號需要程序來安排的,請按以下要求給出python程序。1、總考場數為24個2、請平均分配每考場人數3、每個考場的座位號從01開始編號,依次為02, 03, 04,...。4、隨機安排學生,注意是隨機,但要保證在一個考場中相鄰兩條記錄,它們班級字段的值不相等。5、將安排好的結果以“考場安排結果+時間戳.xlsx"保存
很高興聽到程序已經很好地滿足了你的要求。為了確保最終程序完善且清晰,我將提供最終版本的Python代碼,該代碼完整處理各項要求,并生成考場安排結果文件:
-
總考場數為24個。
-
平均分配每考場人數。
-
每個考場的座位號從01開始編號,依次為02, 03, 04,...。
-
隨機安排學生,保證在一個考場中,相鄰兩條記錄的班級字段的值不相等。
-
將安排好的結果以“考場安排結果+時間戳.xlsx”保存。
代碼如下:?
import pandas as pdimport randomfrom openpyxl import Workbookfrom datetime import datetimeimport numpy as np?def load_data(filename):return pd.read_excel(filename)?def save_data(df, filename):df.to_excel(filename, index=False)?def assign_seats(df, total_halls):# 按班級分組并隨機打亂每個班級內部的順序grouped = df.groupby('班級')groups = [group.sample(frac=1).reset_index(drop=True) for _, group in grouped]# 創建調度器隊列,初始化為每個班級的iteratoriterators = [iter(group.iterrows()) for group in groups]?arranged_data = []hall_number = 1seat_number = 1total_students = len(df)students_per_hall = total_students // total_hallsextra_students = total_students % total_hallswhile iterators:random.shuffle(iterators)for it in iterators[:]:try:_, student = next(it)student_data = student.to_dict()student_data["考場"] = hall_numberstudent_data["考號"] = f"{seat_number:02d}" ?# 格式化為兩位字符arranged_data.append(student_data)seat_number += 1if seat_number > students_per_hall + (1 if hall_number <= extra_students else 0):hall_number += 1seat_number = 1if hall_number > total_halls:hall_number = 1except StopIteration:iterators.remove(it)return arranged_data?def main():input_filename = "考場安排demo.xlsx"total_halls = 24?df = load_data(input_filename)arranged_students = assign_seats(df, total_halls)arranged_df = pd.DataFrame(arranged_students)current_time = datetime.now().strftime("%Y%m%d_%H%M%S")output_filename = f"考場安排結果_{current_time}.xlsx"save_data(arranged_df, output_filename)print(f"已成功生成文件:{output_filename}")?if __name__ == "__main__":main()讓gpt-4o進行了美化:
為了對導出的電子表格進行格式化美化,我們可以使用 pandas 和 openpyxl 模塊來提升電子表格的可讀性和視覺效果。這可能包括:
-
設置標題行的樣式(如背景顏色、字體加粗等)。
-
自動調整列寬。
-
為整個表格設置邊框。
-
設置單元格對齊方式。
以下是如何實現這些功能的代碼示例:?
import pandas as pdimport openpyxlfrom openpyxl.styles import Font, Alignment, PatternFill, Border, Sidefrom openpyxl.utils import get_column_letterfrom openpyxl.worksheet.worksheet import Worksheetimport randomfrom datetime import datetime?def load_data(filename):return pd.read_excel(filename)?def save_data(df, filename):df.to_excel(filename, index=False)format_excel(filename)?def assign_seats(df, total_halls):grouped = df.groupby('班級')groups = [group.sample(frac=1).reset_index(drop=True) for _, group in grouped]iterators = [iter(group.iterrows()) for group in groups]?arranged_data = []hall_number = 1seat_number = 1total_students = len(df)students_per_hall = total_students // total_hallsextra_students = total_students % total_hallswhile iterators:random.shuffle(iterators)for it in iterators[:]:try:_, student = next(it)student_data = student.to_dict()student_data["考場"] = hall_numberstudent_data["考號"] = f"{seat_number:02d}"arranged_data.append(student_data)seat_number += 1if seat_number > students_per_hall + (1 if hall_number <= extra_students else 0):hall_number += 1seat_number = 1if hall_number > total_halls:hall_number = 1except StopIteration:iterators.remove(it)return arranged_data?def format_excel(filename):wb = openpyxl.load_workbook(filename)ws = wb.active# 設置標題行的樣式for cell in ws[1]:cell.font = Font(bold=True, color="FFFFFF")cell.fill = PatternFill(start_color="4F81BD", end_color="4F81BD", fill_type="solid")cell.alignment = Alignment(horizontal="center", vertical="center")# 自動調整列寬for col in ws.columns:max_length = 0column = col[0].column_letter ?# 獲取列的字母for cell in col:try:if len(str(cell.value)) > max_length:max_length = len(str(cell.value))except:passadjusted_width = (max_length + 2)ws.column_dimensions[column].width = adjusted_width# 設置單元格邊框和對齊方式thin_border = Border(left=Side(style='thin'), right=Side(style='thin'), top=Side(style='thin'), bottom=Side(style='thin'))for row in ws.iter_rows(min_row=2, max_row=ws.max_row, min_col=1, max_col=ws.max_column):for cell in row:cell.border = thin_bordercell.alignment = Alignment(horizontal="center", vertical="center")wb.save(filename)?def main():input_filename = "考場安排demo.xlsx"total_halls = 24?df = load_data(input_filename)arranged_students = assign_seats(df, total_halls)arranged_df = pd.DataFrame(arranged_students)current_time = datetime.now().strftime("%Y%m%d_%H%M%S")output_filename = f"考場安排結果_{current_time}.xlsx"save_data(arranged_df, output_filename)print(f"已成功生成文件:{output_filename}")?if __name__ == "__main__":main()美化步驟:
-
設置標題行樣式:
-
使用
Font來設定字體加粗和顏色。 -
使用
PatternFill來設定標題行的背景顏色。 -
使用
Alignment來設置標題單元格內容居中。
-
-
自動調整列寬:
-
遍歷每一列,計算列中最長的單元格內容長度,并據此設置列寬,使得內容完整顯示。
-
-
設置單元格邊框和對齊方式:
-
使用
Border和Side來為每個單元格加上細邊框。 -
對每個單元格設置居中對齊
Alignment。
-
????????這樣設置后,生成的Excel文件在視覺上會更加整潔和美觀,并且更符合傳統表格的排版格式。可以在正式運行前用少量數據進行測試。
完整示例代碼如下:
-
引入
openpyxl:添加import openpyxl。 -
設置適當的頁邊距、行高和打印設置。
-
在代碼最后保存并提示用戶文件已生成。
?import pandas as pdimport randomimport openpyxlfrom openpyxl.styles import Font, Alignment, PatternFill, Border, Sidefrom openpyxl.utils import get_column_letterfrom openpyxl.worksheet.page import PageMarginsfrom datetime import datetime?def load_data(filename):return pd.read_excel(filename)?def save_data(df, filename):df.to_excel(filename, index=False)format_excel(filename)?def assign_seats(df, total_halls):grouped = df.groupby('班級')groups = [group.sample(frac=1).reset_index(drop=True) for _, group in grouped]iterators = [iter(group.iterrows()) for group in groups]?arranged_data = []hall_number = 1seat_number = 1total_students = len(df)students_per_hall = total_students // total_hallsextra_students = total_students % total_hallswhile iterators:random.shuffle(iterators)for it in iterators[:]:try:_, student = next(it)student_data = student.to_dict()student_data["考場"] = hall_numberstudent_data["考號"] = f"{seat_number:02d}"arranged_data.append(student_data)seat_number += 1if seat_number > students_per_hall + (1 if hall_number <= extra_students else 0):hall_number += 1seat_number = 1if hall_number > total_halls:hall_number = 1except StopIteration:iterators.remove(it)return arranged_data?def format_excel(filename):wb = openpyxl.load_workbook(filename)ws = wb.active# 設置標題行的樣式for cell in ws[1]:cell.font = Font(bold=True, color="FFFFFF")cell.fill = PatternFill(start_color="4F81BD", end_color="4F81BD", fill_type="solid")cell.alignment = Alignment(horizontal="center", vertical="center")# 自動調整列寬for col in ws.columns:max_length = 0column = col[0].column_letterfor cell in col:try:if len(str(cell.value)) > max_length:max_length = len(str(cell.value))except:passadjusted_width = (max_length + 2)ws.column_dimensions[column].width = adjusted_width# 設置行高(適當調整以適應A4紙)for row in range(1, ws.max_row + 1):ws.row_dimensions[row].height = 18 ?# 行高設置為18像素# 設置單元格邊框和對齊方式thin_border = Border(left=Side(style='thin'), right=Side(style='thin'), top=Side(style='thin'), bottom=Side(style='thin'))for row in ws.iter_rows(min_row=2, max_row=ws.max_row, min_col=1, max_col=ws.max_column):for cell in row:cell.border = thin_bordercell.alignment = Alignment(horizontal="center", vertical="center")# 設置頁邊距ws.page_margins = PageMargins(left=0.5, right=0.5, top=0.5, bottom=0.5)# 設置打印區域(每張A4紙顯示一個考場)total_halls = 24total_students = ws.max_row - 1 ?# 排除標題行students_per_hall = total_students // total_hallsextra_students = total_students % total_halls?for hall_number in range(1, total_halls + 1):min_row = 2 + (hall_number - 1) * (students_per_hall + (1 if hall_number <= extra_students else 0))max_row = min_row + students_per_hall + (1 if hall_number <= extra_students else 0) - 1?ws.print_area = f"A1:E{max_row}"?# 配置頁面設置ws.page_setup.orientation = 'portrait'ws.page_setup.paperSize = ws.PAPERSIZE_A4ws.page_setup.fitToWidth = Truews.page_setup.fitToHeight = False?wb.save(filename)?def main():input_filename = "考場安排demo.xlsx"total_halls = 24?df = load_data(input_filename)arranged_students = assign_seats(df, total_halls)arranged_df = pd.DataFrame(arranged_students)current_time = datetime.now().strftime("%Y%m%d_%H%M%S")output_filename = f"考場安排結果_{current_time}.xlsx"save_data(arranged_df, output_filename)print(f"已成功生成文件:{output_filename}")?if __name__ == "__main__":main()關鍵美化與打印設置說明:
-
自動調整列寬:根據單元格內容自動調整列寬,以適應打印輸出。
-
設置標題行的樣式:加粗并設置標題行字體顏色和背景顏色,使其與數據行區別開來。
-
設置行高:設置統一的行高(18像素)以適應A4紙打印要求。
-
設置單元格邊框和對齊方式:所有單元格增加邊框和居中對齊。
-
設置頁邊距:為頁面設置合適的頁邊距(0.5英寸)。
-
設置打印區域:每個考場的安排顯示在一張A4紙上。
????????現在,運行程序將生成已格式化和打印優化的Excel文件,包含每個考場的安排,并輸出為設置在A4紙上的頁邊距和打印區域。
運行后的結果:

????????這里展示了兩個考場,相鄰的兩個考生看上去來至于不同的班級。由于各班級人數不等,有的班級人數過多,最后一個考場有幾個相同班的學生連在一起。

如何解決這個問題??
請通過一個函數檢查最后輸出的結果,如果有相鄰的考生來至于同一個班級,請參照前面的安排,適當的調整,全部安排,保證相鄰的考生來至于不同的班級?要確保沒有相鄰的考生來自同一個班級,我們需要一個后處理函數來檢查最終的座位安排,并在發現問題時進行調整。以下是一個改進方案,它在安排考位之后,通過檢查并調整相鄰考生的班級來防止同一班級的考生相鄰:?“將相鄰的學生和隨后找到的另一個班級的學生交換位置”, 這個算法不完全正確。隨后仍然可能是一個班級,應該是從前面已排的學生中尋找滿足以下條件的記錄進行調換:這個學生前后都與調整的學生班級不一樣?現在給出的結果,沒有連續幾個來至同一個班級的考生了,但還是有相鄰兩個來至于同一個班,請調整后,重新調用檢查函數,直到不再有相鄰學生來至于一個班級?為了確保相鄰的學生不來自同一個班級,我們可以用一個循環不斷地檢查并調整座位安排,直到沒有相鄰考生來自同一個班級為止。我們可以在`check_and_adjust_seating`函數中用一個布爾值標記調整是否完成,如果發現有相鄰的學生來自同一個班級,則進行調整并再次檢查。?### 改進內容:1. 修改了`check_and_adjust_seating`函數,確保在調整座位后再一次檢查是否有相鄰的考生來自同一個班級。如果有相鄰的考生來自同一個班級,則繼續調整,直到沒有相鄰的考生來自同一個班級。2. 用一個布爾值`adjusted`跟蹤是否進行了調整,如果進行了調整則繼續檢查,否則結束循環。?這樣可以確保最終輸出的結果中沒有相鄰兩個考生來自同一個班級。?調整后,應該反復從開始驗證,最終確保最終輸出的結果中沒有相鄰兩個考生來自同一個班級,只給出調整函數最后結果
????????看上去已經沒有相鄰兩個考生來自同一個班級,實際上gpt只是調整記錄位置,考場號和座位號還是原來的值,讓gpt從新分配考場號和座位號
?import pandas as pdimport randomimport openpyxlfrom openpyxl.styles import Font, Alignment, PatternFill, Border, Sidefrom openpyxl.worksheet.page import PageMarginsfrom datetime import datetime??def load_data(filename):return pd.read_excel(filename)??def save_data(df, filename):df.to_excel(filename, index=False)format_excel(filename, df)??def assign_seats(df, total_halls):grouped = df.groupby('班級')groups = [group.sample(frac=1).reset_index(drop=True) for _, group in grouped]?# Sort groups by size (descending)groups.sort(key=lambda x: len(x), reverse=True)?iterators = [iter(group.iterrows()) for group in groups]arranged_data = []hall_number = 1seat_number = 1?total_students = len(df)students_per_hall = total_students // total_hallsextra_students = total_students % total_halls?while iterators:# Shuffle iterators to ensure randomnessrandom.shuffle(iterators)for it in iterators[:]:try:_, student = next(it)student_data = student.to_dict()student_data["考場"] = hall_numberstudent_data["考號"] = f"{seat_number:02d}"arranged_data.append(student_data)seat_number += 1?# Check if seat number exceeds the allowed number of students per hallif seat_number > students_per_hall + (1 if hall_number <= extra_students else 0):hall_number += 1seat_number = 1# Reset hall number if it exceeds total hallsif hall_number > total_halls:hall_number = 1except StopIteration:iterators.remove(it)?return arranged_data??def check_and_adjust_seating(arranged_data):def has_adjacent_same_class(data):# Check if there are any adjacent students from the same classfor i in range(len(data) - 1):if data[i]['班級'] == data[i + 1]['班級']:return ireturn -1?def find_valid_swap(index, data):# Find a valid swap by checking front part of the list before the indexcurrent_class = data[index]['班級']for j in range(len(data)):if j != index and data[j]['班級'] != current_class:# Ensure new surrounding are validif (j == 0 or data[j - 1]['班級'] != current_class) and (j == len(data) - 1 or data[j + 1]['班級'] != current_class):return jreturn -1?swap_operations = []while True:index = has_adjacent_same_class(arranged_data)if index == -1:break # No adjacent students from the same classswap_index = find_valid_swap(index + 1, arranged_data)if swap_index == -1:raise ValueError("Cannot find a valid swap to adjust the seating arrangement.")# Record the swap operationswap_operations.append((index + 1, swap_index))# Swap the adjacent student with the valid studentarranged_data[index + 1], arranged_data[swap_index] = arranged_data[swap_index], arranged_data[index + 1]?# Additional check and swap if any, continue from the startwhile has_adjacent_same_class(arranged_data) != -1:index = has_adjacent_same_class(arranged_data)if index != -1:swap_index = find_valid_swap(index, arranged_data)if swap_index != -1:# Record the swap operationswap_operations.append((index, swap_index))arranged_data[index], arranged_data[swap_index] = arranged_data[swap_index], arranged_data[index]?return arranged_data, swap_operations??def reassign_seats(arranged_data, total_halls):hall_number = 1seat_number = 1total_students = len(arranged_data)students_per_hall = total_students // total_hallsextra_students = total_students % total_halls?for i, student in enumerate(arranged_data):student['考場'] = hall_numberstudent['考號'] = f"{seat_number:02d}"seat_number += 1?if seat_number > students_per_hall + (1 if hall_number <= extra_students else 0):hall_number += 1seat_number = 1if hall_number > total_halls:hall_number = 1?return arranged_data??def format_excel(filename, df):wb = openpyxl.load_workbook(filename)ws = wb.active?# 設置標題行的樣式for cell in ws[1]:cell.font = Font(bold=True, color="FFFFFF")cell.fill = PatternFill(start_color="4F81BD", end_color="4F81BD", fill_type="solid")cell.alignment = Alignment(horizontal="center", vertical="center")?# 自動調整列寬for col in ws.columns:max_length = 0column = col[0].column_letterfor cell in col:try:if len(str(cell.value)) > max_length:max_length = len(str(cell.value))except:passadjusted_width = (max_length + 20)ws.column_dimensions[column].width = adjusted_width?# 設置行高(適當調整以適應A4紙)for row in range(1, ws.max_row + 1):ws.row_dimensions[row].height = 23 # 行高設置為23像素?# 設置單元格邊框和對齊方式thin_border = Border(left=Side(style='thin'), right=Side(style='thin'), top=Side(style='thin'),bottom=Side(style='thin'))for row in ws.iter_rows(min_row=2, max_row=ws.max_row, min_col=1, max_col=ws.max_column):for cell in row:cell.border = thin_bordercell.alignment = Alignment(horizontal="center", vertical="center")?# 設置頁邊距ws.page_margins = PageMargins(left=0.5, right=0.5, top=0.5, bottom=0.5)?hall_groups = df.groupby('考場')?# 設置重復打印標題行ws.print_title_rows = '1:1'ws.print_title_cols = None?# 逐個考場設置打印區域for hall_number, hall_df in hall_groups:min_row = hall_df.index[0] + 2 # 加2以跳過標題行和數據框索引偏移max_row = hall_df.index[-1] + 2 # 加2以跳過標題行和數據框索引偏移?# 初始化 print area, configuration of page settings for each hallws.print_area = f"A1:E{max_row}"?# 配置頁面設置ws.page_setup.orientation = 'portrait'ws.page_setup.paperSize = ws.PAPERSIZE_A4ws.page_setup.fitToPage = Truews.page_setup.fitToWidth = 1ws.page_setup.fitToHeight = False # 允許縱向頁面數自動擴展?wb.save(filename)??def main():input_filename = "11-15.xlsx" # 修改為學生信息的電子表格名total_halls = 9 # 修改為考場數df = load_data(input_filename)arranged_students = assign_seats(df, total_halls)adjusted_students, swap_operations = check_and_adjust_seating(arranged_students)final_students = reassign_seats(adjusted_students, total_halls)arranged_df = pd.DataFrame(final_students)current_time = datetime.now().strftime("%Y%m%d_%H%M%S")output_filename = f"考場安排結果_{current_time}.xlsx"save_data(arranged_df, output_filename)print(f"已成功生成文件:{output_filename}")??if __name__ == "__main__":main()??最后在Microsoft Excel 中檢測相鄰單元格值是否相等
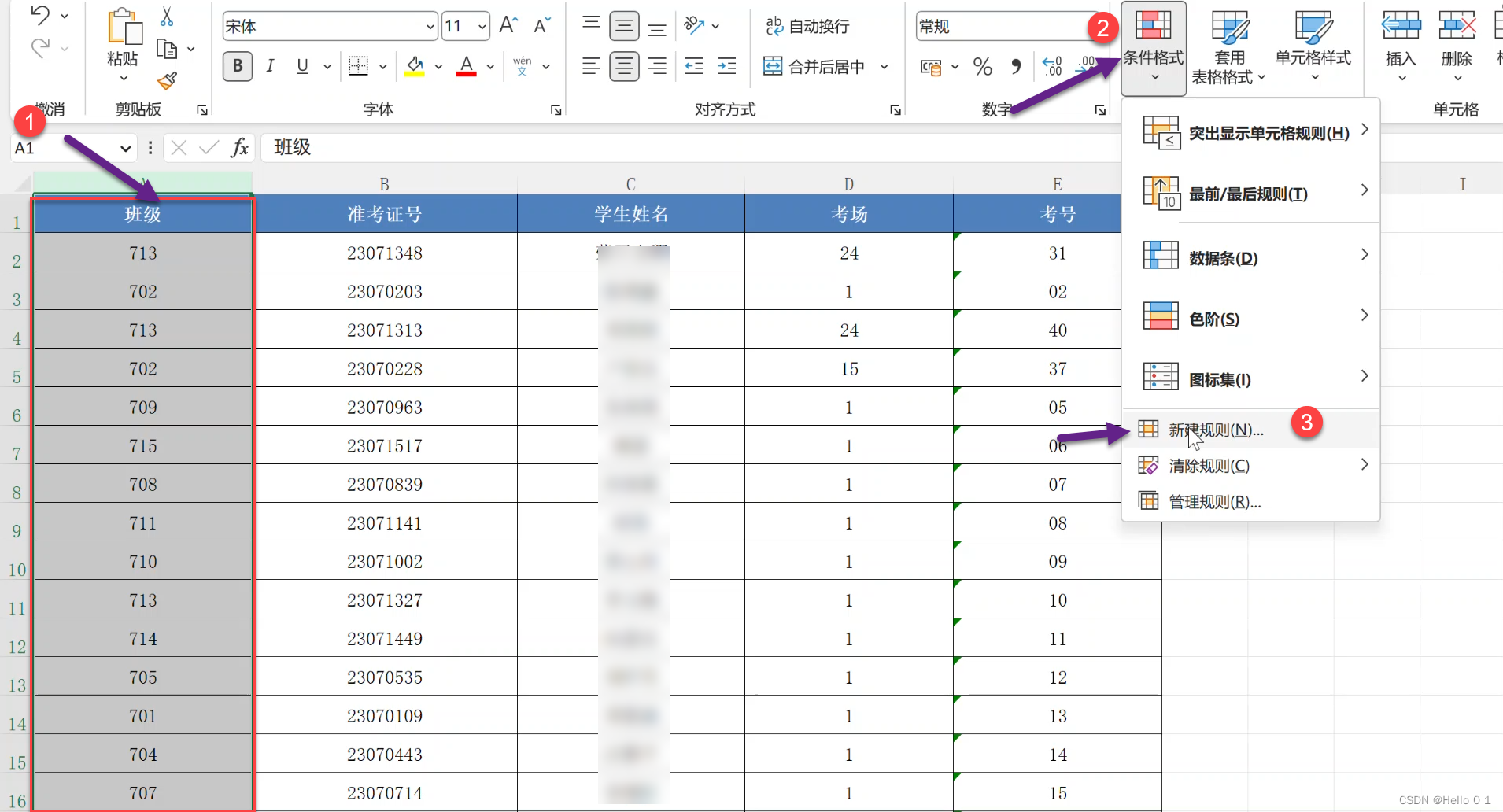
-
選擇數據區域:
-
選擇你想要檢查的單元格區域。例如,假設你要檢查從A2到A100的單元格。
-
-
打開條件格式:
-
在Excel的“開始”選項卡上,點擊“條件格式”。
-
-
創建新的規則:
-
在“條件格式”下拉菜單中,選擇“新建規則”。
-
-
使用公式來檢測:
-
在“選擇規則類型”窗口,選擇“使用公式確定要設置格式的單元格”。
-
在“為符合此公式的值設置格式”框中輸入適當的公式。例如,如果你檢查A列中的相鄰單元格,可以使用公式:
?=A2=A1
-
然后你可以設置條件匹配時應用的格式,如填充顏色或字體顏色等。
-
-
應用條件格式:
-
設置好格式后,點擊“確定”。這個操作將會在指定區域內自動應用條件格式。如果兩個相鄰單元格的值相同,它們將會被醒目地突出顯示。
-
程序已完全符合要求。
食用方法
確保你安裝了所需庫:
?pip install pandas openpyxl numpy1、表結構

2、修改input_filename的值 ,此變量存儲的是學生信息的電子表格名,擴展名為.xlsx
3、修改total_halls的值,此變量存儲的是考場個數
4、如果要分類安排考場,可將各層次學生分別建立對應的電子表格文件。
運行程序后,將生成一個已經格式化美化好的Excel文件。
如果有好的建議歡迎交流!!!,食用過程中錯誤請評論區給出!!!
?
?
![Android-多個tv_item_[i] 點擊事件簡寫](http://pic.xiahunao.cn/Android-多個tv_item_[i] 點擊事件簡寫)













)
)

)

