K8s 是一種強大的容器編排和管理平臺,能夠高效地調度、管理和監控容器化應用程序;其本身使用聲明式語義管理著集群內所有資源模型、應用程序、存儲、網絡等多種資源,Node 本身又屬于 K8s 計算資源,上面承載運行著各種類型的應用程序,當Node NotReady 后運行在其上面各種 Workload 類型的 Pod 都會受到影響,脫離了 K8s 生命周期的管理后將會變的不可控無法提供服務,為保障該 Node 上 Pod 的可用性及可控性,K8s 會對這個 Node 上的 Pod 進行網絡、存儲、副本保持等控制;因 K8s 自身 controller manager 較多加上集群管理及運維的復雜度,增加了 Node NotReady 后的理解與學習成本;本文將基于 K8s 1.24 版本對 Node NotReady 后會觸發哪些行為進行詳細描述。
1. 控制器探索
1.1. Node Controller
默認情況下,Kubelet 每隔 10s (--node-status-update-frequency=10s) 更新 Node 的狀態(我們稱之為心跳),而 kube-controller-manager 每隔 5s 檢查一次 Node 的狀態 (--node-monitor-period=5s)。kube-controller-manager 會在 Node 未更新狀態超過 40s (--node-monitor-grace-period=40s)時 ,將其標記為 NotReady (Node Ready Condition: True on healthy, False on unhealthy and not accepting pods, Unknown on no heartbeat)。當 Node 超過 5m 未更新狀態,則 kube-controller-manager 會驅逐該 Node 上的所有 Pod。
Kubernetes 會自動給 Pod 添加針對 node.kubernetes.io/not-ready 和 node.kubernetes.io/unreachable 的容忍度,且配置 tolerationSeconds=300。這里需要注意的是當 Pod 對應容忍沒有配置tolerationSeconds時,該容忍生效后 K8s 不會對 Pod 進行驅逐,可以通過 tolerations 配置 Pod 的容忍度,來覆蓋默認的配置:
tolerations:
- key: "node.kubernetes.io/unreachable"operator: "Exists"effect: "NoExecute"tolerationSeconds: 300
- key: "node.kubernetes.io/not-ready"operator: "Exists"effect: "NoExecute"tolerationSeconds: 300Node 控制器在節點異常后,會按照默認的速率(--node-eviction-rate=0.1,即每10秒一個節點的速率)進行 Node 的驅逐。Node 控制器按照 Zone 將節點劃分為不同的組,再跟進 Zone 的狀態進行速率調整:
-
Normal:所有節點都 Ready,默認速率驅逐。
-
PartialDisruption:即超過33% 的節點 NotReady 的狀態。當異常節點比例大于 --unhealthy-zone-threshold=0.55 時開始減慢速率:
-
小集群(即節點數量小于 --large-cluster-size-threshold=50):停止驅逐
-
大集群:減慢速率為 --secondary-node-eviction-rate=0.01
-
-
FullDisruption:所有節點都 NotReady,返回使用默認速率驅逐。但當所有 Zone 都處在 FullDisruption 時,停止驅逐。
K8s 此后的所有行為將會圍繞著 Pod NotReady 和被驅逐的 Pod 進行展開;從下圖中我們可以看到牽涉的組件及功能較多讓人感覺著實復雜,但各個功能相互獨立,管理邏輯有跡可循,以下根據各個組件功能進行詳細探索,為減少本文篇幅,從總體邏輯上說明白 K8s 管理 Node 及 Pod 功能,本文只做功能描述,具體代碼不再詳細介紹。
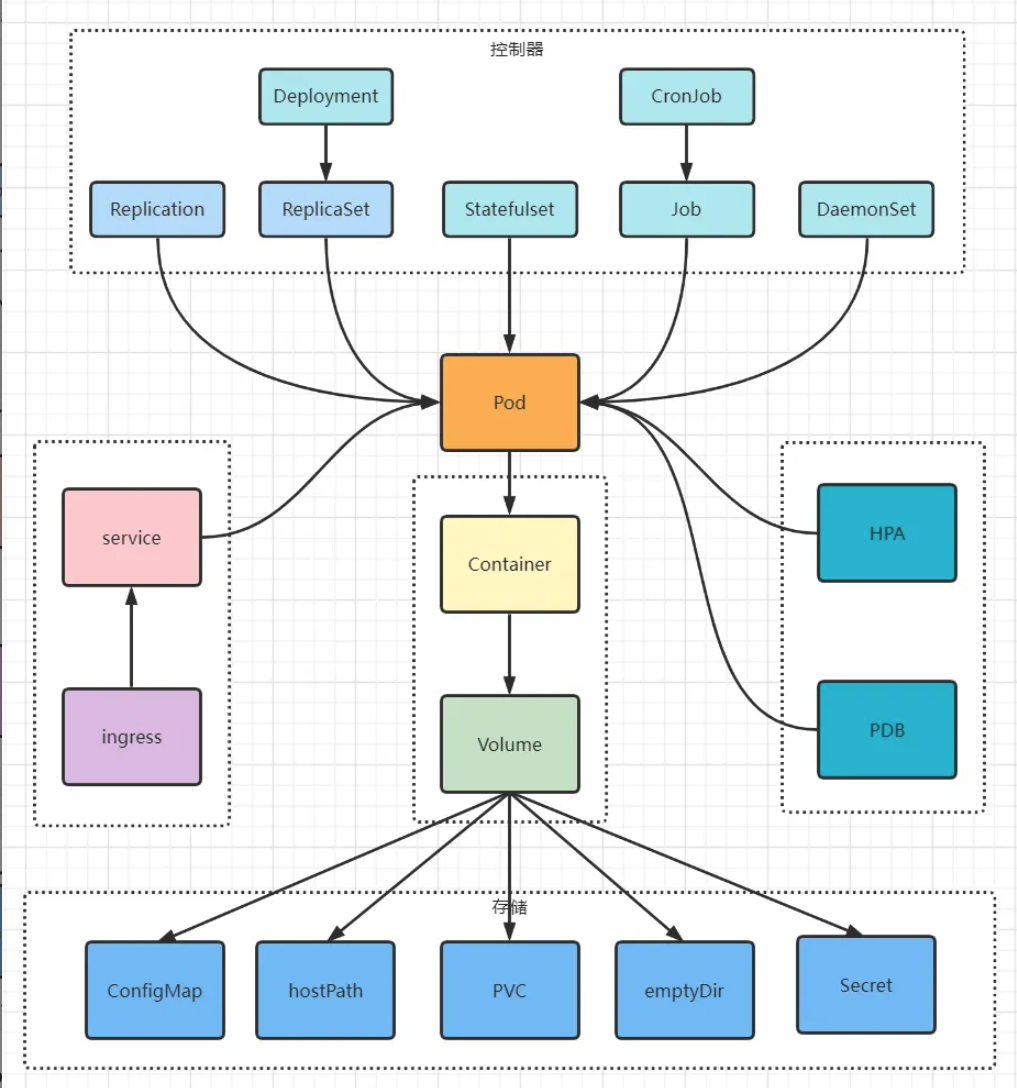
1.2. Deployment Controller
Deployment 通過管理 ReplicaSet 來完成 K8s 中微服務的版本更新、擴容縮容、滾動更新、回滾等高級功能,當 Pod NotReady 后會觸發對應 ReplicaSet 的副本數保持功能;而 Deployment 只會更新自身 status 相關內容。
1.3. ReplicaSet Controller
Replicaset Controller的主要功能是確保期望的 Pod 副本數量與實際運行的 Pod 副本數量一致。因此,Replicaset Controller 會重建該 Node 上 相關的 Not Ready 的 Pod 副本以替換NotReady節點上的失效副本。Node NotReady 的 Pod 仍然會保留處于 Terminating 狀態,Node 恢復后 kubelet 會執行優雅刪除并強制刪除該 Pod。
1.4. StatefulSet Controller
Node NotReady 同樣會對 StatefulSet Pod 觸發 eviction 操作,用戶看到的 Pod 會一直處于 Terminating 狀態。此時 StatefulSet Controller 并不會創建新的 Pod;Node 恢復后 kubelet 會執行優雅刪除,detach PV,然后會重建該Pod。
1.4.1. 為什么沒有重建
往往應用中有一些 Pod 沒法實現多副本,但是又要保證集群能夠自愈,那么這種某個節點 Down 掉或者網卡壞掉等情況,就會有很大影響,要如何能夠實現自愈呢?
對于這種 Unknown 狀態的 Stateful Pod ,可以通過 force delete 方式去刪除。關于 ForceDelete,社區是不推薦的,因為可能會對唯一的標志符(單調遞增的序列號)產生影響,如果發生,對 StatefulSet 是致命的,可能會導致數據丟失(可能是應用集群腦裂,也可能是對 PV 多寫導致)。
kubectl delete pods <pod> --grace-period=0 --force但是這樣刪除仍然需要一些保護措施,以 Ceph RBD 存儲插件為例,當執行force delete 前,根據經驗,用戶應該先設置 ceph osd blacklist,防止當遷移過程中網絡恢復后,容器繼續向 PV 寫入數據將文件系統弄壞。因為 force delete 是將 PodObj 直接從 ETCD 強制清理,這樣 StatefulSet Controller 將會新建新的 Pod 在其他節點, 但是故障節點的 Kubelet 清理這個舊容器需要時間,此時勢必存在 2 個容器mount 了同一塊 PV(故障節點Pod 對應的容器與新遷移Pod 創建的容器),但是如果此時網絡恢復,那么2 個容器可能同時寫入數據,后果將是嚴重的。
1.4.2. 社區推薦的做法
先恢復故障機器,自行完成優雅刪除操作、detach PV、強制保障進程完全退出后,再由 kubuelet 將Pod進行徹底刪除,最后觸發 StatefulSet Controller 副本數保持功能,重建該Pod。
1.5. DaemonSet Controller
Node NotReady 對 DaemonSet 不會有影響,查詢 Pod 處于 NodeLost 狀態并一直保持。當 Node 恢復后該類型的Pod 會從 NodeLost 狀態直接變成 Running 狀態,不涉及重建。
1.6. Job Controller
Job Controller負責管理批處理任務。當NotReady節點上的Pod不可用時,Job Controller會在其他可用節點上創建新的Pod副本以完成任務。Job Controller會監控任務的進度,并確保任務在成功完成或達到重試次數限制后結束。
在 Node 重新變為 Ready 狀態時,Job Controller會根據需要對Pod進行重新調度,以確保任務能夠在可用資源的情況下繼續執行。同時,Job Controller還會處理并發限制和任務完成后的清理工作。
2. 網絡
Pod之間的網絡通信在Kubernetes集群中至關重要。當 Node 變為NotReady狀態時,位于該節點上的Pod可能無法與其他Pod進行通信。這可能是由于網絡插件故障、網絡策略限制或底層網絡問題導致的。在 Node 重新變為Ready狀態時,網絡問題可能會得到解決,從而恢復Pod之間的通信。然而,這還取決于網絡插件、配置和底層網絡設施的具體情況。
2.1. Endpoints Controller
Endpoints Controller的主要職責是確保 Endpoints 對象始終與 Service 和 Pod 對象的當前狀態保持一致。這是 K8s 服務發現和負載均衡功能的基礎。其核心工作原理如下:
-
獲取 Service 對象,當查詢不到該 Service 對象時,刪除同名 Endpoints 對象;
-
根據 Service 對象的.Spec.Selector,查詢與 Service 對象匹配的 Pod 列表;
-
查詢 Service 的 annotations 中是否配置了TolerateUnreadyEndpoints,代表允許為 unready 的 Pod 也創建 Endpoints,該配置將會影響 Endpoints 對象的 subsets 信息的計算;
-
遍歷 Service 對象匹配的 Pod 列表,找出處于 Ready 狀態的 Pod,并計算 Endpoints 的 subsets 信息;
-
獲取 Service 同名 Endpoints 對象,沒有則創建新的 Endpoints;將該Service匹配的Pod的 IP 地址和端口信息添加到 Endpoints 對象中。當一個 Service 的選擇器發生變化,或與該 Service 關聯的 Pod 的數量或狀態發生變化時,Endpoints Controller會更新相應的Endpoints對象,以反映當前的 Pod IP 地址和端口信息。
上文已分析到 Node 變為 NotReady 后,Node Controller會更新該 Node 上的 Pod 為NotReady 狀態,更新后 Endpoints Controller 會第一時刻感知到該變化,會把該 Pod 從對應的 Endpoints 的 IP list中摘除,以保證該 Pod 不會被其他 Pod 訪問。
2.2. CoreDNS
CoreDNS就是DNS服務的一種,它會監視Kubernetes集群中的各種對象,包括Service、Endpoint、Pod等等。通過這些對象的更新,CoreDNS可以持續更新DNS記錄,從而保證集群內的服務發現的正確性和實時性。
簡單來說,當Service對象發生變化(例如,新創建了一個Service或者Service的端口、IP等發生了變化)時,CoreDNS就會根據這些變化更新相關的DNS記錄。如果一個Pod被創建、刪除或NotReady,CoreDNS也會及時地更新對應的DNS記錄。
3. 存儲
3.1. 本地存儲
如果PV使用的是本地存儲(例如,節點上的磁盤或目錄),那么當節點變為NotReady狀態時,位于該節點上的存儲卷將無法訪問。這可能導致使用這些存儲卷的Pod無法正常運行。在這種情況下,Kubernetes不會對PV執行任何操作,因為本地存儲卷與特定節點緊密相關。當節點重新變為Ready狀態時,存儲卷的訪問可能會恢復正常。
3.2. 網絡存儲
對于網絡存儲(如NFS、iSCSI、Ceph等),當節點變為NotReady狀態時,位于該節點上的Pod可能無法訪問其存儲卷。這可能是由于網絡問題或者存儲配置問題導致的。在這種情況下,Kubernetes不會對PV執行任何操作。當節點重新變為Ready狀態并且網絡問題得到解決時,Pod可能會重新獲得對存儲卷的訪問。
3.3. 云存儲
對于云存儲(如AWS EBS、GCE PD、Azure Disk等),當節點變為NotReady狀態時,Kubernetes可能會根據存儲類(StorageClass)的配置自動將存儲卷從不可用節點分離并附加到其他可用節點。這樣,重新調度到其他節點的Pod可以繼續訪問其存儲卷。請注意,這種行為取決于存儲類的配置和云提供商的支持。
當Kubernetes集群中的節點變為NotReady狀態時,對PV和PVC的影響主要取決于存儲類型和配置。Kubernetes對PV的操作也因存儲類型而異。在節點重新變為Ready狀態時,存儲訪問可能會恢復正常,但這取決于具體情況。為了確保應用程序的高可用性,建議使用支持動態遷移和故障轉移的存儲解決方案。
3.4. 其他組件和功能
除了上述組件外,Kubernetes還有其他組件和功能可能會在節點變為NotReady狀態時發生變化。例如:
Horizontal Pod Autoscaler(HPA):HPA負責根據資源利用率自動調整Pod副本數量。在節點變為NotReady狀態時,HPA可能會在其他可用節點上創建新的Pod副本以滿足負載需求。
Ingress Controller:Ingress Controller負責管理集群的入口流量。當節點變為NotReady狀態時,Ingress Controller可能需要重新調度Ingress資源以確保流量能夠正確路由到其他可用節點上的Pod。
Persistent Volumes(PV)和Persistent Volume Claims(PVC):當節點變為NotReady狀態時,位于該節點上的存儲卷可能會受到影響。這可能導致Pod無法訪問其持久化存儲。在節點重新變為Ready狀態時,存儲卷的訪問可能會恢復正常。
總之,當Kubernetes集群中的節點變為NotReady狀態時,各個組件會采取一系列行動來確保集群的穩定性和應用的正常運行。這包括重新調度Pod、確保服務可用性、維護網絡通信和存儲訪問等。在節點重新變為Ready狀態時,這些組件會根據需要進行相應的調整,以恢復正常運行。




)






 v1.30.1 創建本地鏡像倉庫 使用本地docker鏡像倉庫部署服務 Discuz X3.5 容器搭建論壇)


)




