-- 窗口范圍是整個表-- 按照age排序,每階段的age數據進行統計求和.select id,name,age,count()over(orderby age)as n from wt1;
相同字段分區、排序
-- 窗口范圍是表下按照age進行分區-- 在分區里面,再按照age進行排序select id,name,age,count()over(partitionby age orderby age)as n from wt1;-- 若分區和排序是同一字段時,可以省略order by語句.
不同字段分區、排序
-- 窗口范圍是表下按照age進行分區-- 在分區里面,再按照id進行排序select id,name,age,count()over(partitionby age orderby id)as n from wt1;-- 可以根據需要對order by進行asc,desc
序列函數
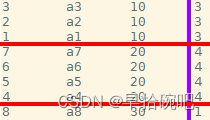
rank
會對相同數值,輸出相同的序號,而且下一個序號間斷, 如:1、1、3、3、5. rank(等級)
dense_rank
會對相同數值,輸出相同的序號,而且下一個序號不間斷,如:1、1、2、2、3. dense(稠密的)
row_number
會對所有數值,輸出不同的序號,序號唯一且連續,如:1、2、3、4、5.
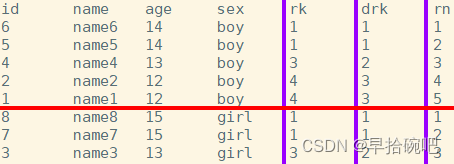
select id,name,age,sex,
rank()over(partitionby sex orderby age desc)as rk,
dense_rank()over(partitionby sex orderby age desc)as drk,
row_number()over(partitionby sex orderby age desc)as rn
from stu;
行選擇函數
-- 語法over(rowsbetween num 函數 and 函數)-- 關鍵詞釋義
:'
following
在后N行; following--(時間上)接著的,下述的,下列的.
preceding
在前N行; preceding--在…之前發生(或出現),先于,走在…前面.
unbounded
不限行數; unbounded--無窮的,無盡的,無限的.
current row
當前行; current--現時發生的,當前的,現在的,通用的,流通的,流行的.
'-- 窗口中的整個范圍rowsbetweenunboundedprecedingand unbouned following-- 從窗口的前無限行到當前行rowsbetweenunboundedprecedingandcurrentrow-- 從窗口的當前行的前2行到當前行rowsbetween2precedingandcurrentrow-- 從窗口的當前行到當前行的后2行rowsbetweencurrentrowand2following
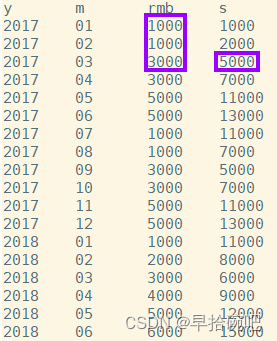
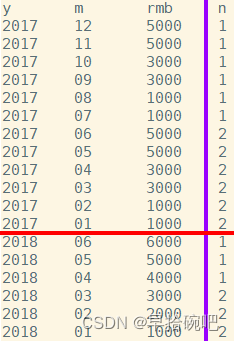
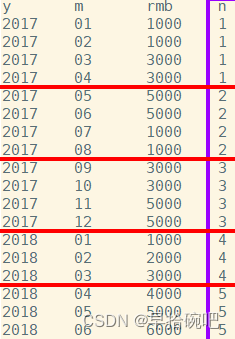
-- 查詢當月銷售額和近三個月的銷售額select y,m,rmb,sum(rmb)over(orderby y,m rowsbetween2precedingandcurrentrow)as s
from sale;-- 從結果可以看出,窗口函數的結果是包括本行在內的前三月的總和.
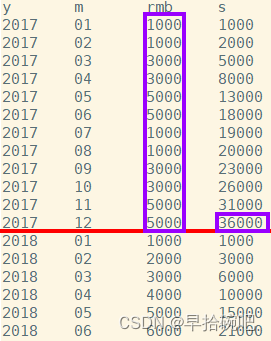
-- 查詢當月銷售額和今年年初到當月的銷售額SELECT y,m,rmb,sum(rmb)over(partitionby y orderby m rowsbetweenunboundedprecedingandcurrentrow)as s
from sale;
值選擇函數
-- 上面知道了行選擇函數的寫法是:sum()over(partitionby xx orderby xx rowsbetween xx and xx)-- 相類似的,值選擇函數的寫法就是:sum()over(partitionby xx orderby xx range between xx and xx)? rows是物理窗口,是哪一行就是哪一行,與當前行的值(orderbykey的key的值)無關,只與排序后的行號相關,就是我們常規理解的那樣。
? range是邏輯窗口,與當前行的值有關(orderbykey的key的值),在key上操作range范圍。
select y,m,rmb,
lag(rmb,1)over(partitionby y orderby m)as lag_rmb,
lead(rmb,1)over(partitionby y orderby m)as lead_rmb
from sale;
first_value()、last_value()取值函數
-- first_value() 的結果容易理解,直接在結果的所有行記錄中輸出同一個滿足條件的首個記錄;-- last_value() 默認統計范圍: rows between unbounded preceding and current row,也就是取當前行數據與當前行之前的數據的比較,如果需要在結果的所有行記錄中輸出同一個滿足條件的最后一個記錄,在order by 條件的后面加上語句:rows between unbounded preceding and unbounded following。
select y,m,rmb,
first_value(rmb)over(partitionby y orderby rmb desc)as rmb_first,
last_value(rmb)over(partitionby y orderby rmb descrowsbetweenunboundedprecedingandunboundedfollowing)as rmb_last
from sale;





















)