
【摘要】根據觀察數據估計個體治療效果(ITE)是一項至關重要但具有挑戰性的任務。解纏結表示已用于將代理變量分為混雜變量、工具變量和調整變量。然而,根據觀測數據準確地進行反事實推理來識別 ITE 仍然是一個懸而未決的問題。在本文中,我們從數據和模型的角度重新審視 ITE 估計問題,揭示了以前未充分探索的方面。具體來說,我們研究了不平衡數據對 ITE 估計的影響,強調了假設兼容和方法簡單性在處理不平衡數據中的重要性。從模型的角度來看,我們從信息論的角度重新審視了解纏結的表示學習,并提供了支持變分自動編碼器(VAE)框架實現解纏結的有效性的理論證據。利用這些見解,我們提出了 EDVAE,這是一種用于解開潛在因素的數據驅動模型。 EDVAE 包含三個可擴展組件:用于不平衡數據的過采樣層、用于分離潛在因子的表示層以及結果預測層。合成數據集和真實數據集的實驗結果強調了我們提出的方法的有效性,展示了其解決根據觀測數據估計 ITE 的復雜問題的潛力。
原文:EDVAE: Disentangled latent factors models in counterfactual reasoning for individual treatment effects estimation
地址:https://www.sciencedirect.com/science/article/abs/pii/S0020025523011635
出版:Information Sciences
機構: Wuhan University; Hubei Luojia Laboratory
解析人:公眾號“碼農的科研筆記”
1 研究問題
本文研究的核心問題是: 如何設計一個數據驅動的解耦隱變量模型,用于從觀察數據中估計個體治療效應(ITE)。
在醫療領域,醫生常常需要根據病人的個人特征,來決定是否給予某種治療(如化療)。這里的關鍵是要估計出每個病人在接受和不接受治療情況下的預后差異,即個體治療效應(ITE)。但現實中我們只能觀察到病人實際接受的治療結果,而無法知道反事實情況下的結果。
本文研究問題的特點和現有方法面臨的挑戰主要體現在以下幾個方面:
-
觀察數據中存在混淆偏差,即治療分配與治療結果之間存在共同的影響因素。傳統的回歸方法無法很好地消除這種偏差。
-
治療組和對照組的樣本分布不平衡,治療組的樣本量通常遠小于對照組。現有的ITE估計方法大多忽略了這一問題。
-
從高維觀察數據中準確識別出僅影響治療、僅影響結果、同時影響治療和結果的潛在因素,對于減少ITE估計偏差至關重要,但現有方法還不夠理想。
針對這些挑戰,本文提出了一種基于變分自編碼器(VAE)框架的"EDVAE"方法:
EDVAE巧妙地將ITE估計問題分解為三個模塊:過采樣層、表示層和預測層。過采樣層通過復制少數類(治療組)樣本來平衡數據分布。表示層利用VAE的解耦能力,從高維觀察數據中提取出獨立的工具變量、混淆變量和調整變量。預測層則基于治療和潛在因素來預測反事實結果。 這種模塊化設計就像一個齒輪傳動裝置,通過將復雜任務分解為幾個簡單步驟,最終實現了從觀察數據到因果推理的無縫銜接。其中VAE框架起到了至關重要的作用,猶如變速箱中的"離合器",將原始數據壓縮到低維隱空間,并實現了關鍵因素的解耦。實驗表明,與現有方法相比,EDVAE在合成和真實數據集上都取得了優異的ITE估計性能,體現了其在因果推理領域的前景和潛力。
2 研究方法

為了從觀察數據中準確估計個體治療效應(ITE),本文提出了一種新的基于解開表示的方法EDVAE。EDVAE考慮了ITE估計中不平衡數據的影響,并從信息論的角度分析了變分自編碼器(VAE)學習解開表示的有效性。如圖3所示,EDVAE主要由三個模塊組成:過采樣層、表示層和預測層。
2.1 不平衡數據處理
在因果推斷中,由于實際治療的約束,治療組的樣本量通常遠小于對照組,導致樣本分布不平衡。不平衡數據會使一組相對另一組過度代表,造成治療效果估計偏差。因此,EDVAE在表示學習前先引入過采樣層來處理不平衡數據。
常見的過采樣方法可分為生成式和非生成式兩類。生成式方法(如SMOTE)通過對少數類樣本插值來合成新樣本。但它們可能破壞治療、結果與協變量間原有的關系,違背因果推斷所需的先驗假設。非生成式方法(如隨機重采樣)通過對少數類樣本復制來平衡數據,保持了原有關系,更適合ITE估計任務。因此,EDVAE采用隨機重采樣對少數的治療組樣本進行過采樣,使治療組和對照組的樣本量接近。
2.2 基于VAE的解開表示學習
從因果圖3(a)可知,研究者通常假設存在三類隱含因子:只影響治療的工具變量 、同時影響治療和結果的混淆變量 、只影響結果的調整變量 。學習相互獨立的隱含因子,有助于從觀察數據中準確估計治療效應。
從信息論角度看,最小化互信息 可以降低隱含因子間的依賴性。本文推導出該互信息的一個上界(公式4),其形式與VAE的ELBO損失非常相似。因此,論文基于VAE框架來學習解開的隱含表示。表示層由一個編碼器 和一個解碼器 組成。其中編碼器通過神經網絡參數化隱變量 的后驗分布,解碼器對 施加先驗。為了平衡治療組和對照組在隱空間的分布差異,論文還引入Wasserstein距離作為正則項(公式13)。最終,表示層的損失由VAE重構誤差、后驗正則和分布差異度量三部分組成(公式6)。
2.3 協變量分解為隱含因子
個體治療效應定義為 ,即在給定協變量 的條件下,個體 接受治療()和未接受治療()的潛在結果之差。為了從可觀測的協變量中識別隱含的因果結構,論文將 分解為工具變量 、混淆變量 和調整變量 。這三類隱變量相互獨立,分別只影響治療、同時影響治療和結果、只影響結果。
EDVAE的表示層負責從協變量中學習這三類相互獨立的隱含因子。編碼器 、、 分別對 、、 的后驗分布進行建模,使其服從各自獨立的高斯分布(公式10-12)。而解碼器 對隱變量的聯合先驗分布進行建模,用于重構原始協變量。通過最小化VAE損失和分布差異度量,表示層可以學習到既能很好重構 、又能保持治療組和對照組分布一致的隱含因子表示。
2.4 基于治療和隱含因子的結果預測
獲得隱含因子后,預測層通過因果圖3(a)所示的因果關系,來預測個體在不同治療條件下的潛在結果。其中工具變量 只影響治療分配 而與結果 無關,因此 可以用混淆變量 和調整變量 在給定治療 的條件下來預測。
預測層采用前饋神經網絡來擬合 關于 的條件分布。它包含兩個分支,分別預測個體 在治療()和對照()條件下的潛在結果(公式9)。損失函數為預測值與觀測值的對數似然(公式15)。為了估計ITE,需要對治療前的協變量 分別假設施加治療()和不施加治療()兩種干預,計算相應的潛在結果,再取其差值。這一過程要求隱含因子 滿足可忽略性假設,即給定 的情況下,治療分配與潛在結果相互獨立。
2.5 EDVAE算法流程總結
EDVAE通過過采樣層、表示層和預測層三個模塊,實現端到端的個體治療效應估計:
-
過采樣層利用隨機重采樣平衡治療組和對照組的樣本分布;
-
表示層基于VAE框架,從平衡后的協變量中解開三個相互獨立的隱含因子;
-
預測層在給定治療和隱含因子的條件下,估計個體的潛在結果。
在訓練階段,三個模塊的損失函數聯合優化,使表示層學習到既滿足因果假設、又與預測任務相關的隱含因子。在推理階段,對于新的個體,表示層將其協變量映射到隱空間,預測層再估計其在不同治療條件下的潛在結果,由此得到個體治療效應。
總的來說,EDVAE在ITE估計中考慮了不平衡數據的影響,并利用VAE從信息論角度學習解開表示,以提高估計的準確性。同時該方法的三個模塊可靈活拓展,增強了框架的通用性。 第四步、實驗部分詳細撰寫:
5 實驗
5.1 實驗場景介紹
該論文提出了一個用于個體治療效應(ITE)估計的可分離潛在因子模型EDVAE。論文實驗主要在合成數據和真實數據上驗證EDVAE模型的有效性,以及與其他模型的對比效果。
5.2 實驗設置
-
Datasets:
-
合成數據集:通過不同的實驗組比例設置生成,每個數據集包含2000個樣本,25個特征
-
ACIC 2016:由4802個樣本和58個變量組成
-
IHDP:一項隨機臨床試驗數據,通過消除treated subjects的非隨機子集來模擬選擇偏差
-
-
Baseline:
-
TARNet
-
TEDVAE
-
CEVAE
-
DML4CATE
-
X-learner
-
DragonNet
-
-
metric:
-
PEHE:衡量估計的ITE與真實ITE之間的均方根距離
-
-
消融實驗變體:
-
EDVAE-WR:不包含過采樣層的EDVAE模型
-
5.3 實驗結果
5.3.1 實驗一、合成數據集上算法性能對比
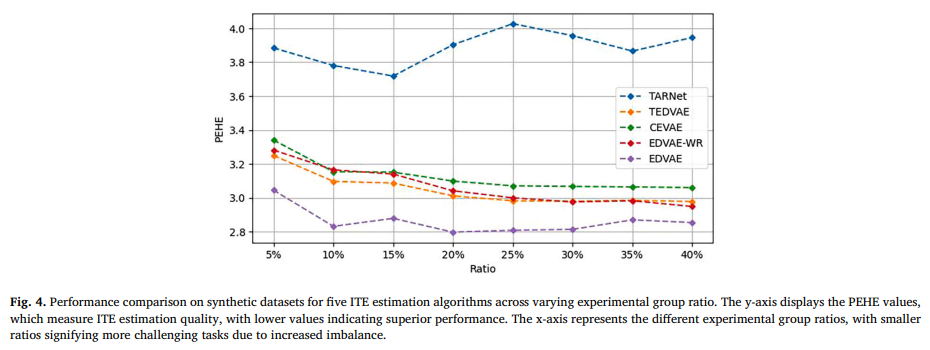
目的:驗證不平衡數據對ITE估計的影響,并比較不同算法在不同程度不平衡數據下的性能
涉及圖表:圖4
實驗細節概述:在具有不同實驗組比例(5%到40%)的合成數據集上,比較TARNet、TEDVAE、CEVAE、DML4CATE、X-learner、DragonNet和EDVAE的PEHE性能
結果:
-
大多數方法在比例小于20%時性能較差
-
EDVAE在比例超過10%時表現相對穩定,在估計ITE方面具有優勢
5.3.2 實驗二、可分離模型性能的回歸可視化
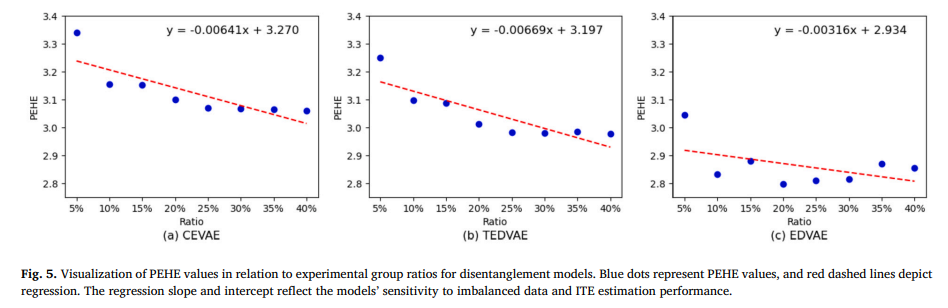
目的:直觀展示EDVAE等可分離表示學習模型處理不平衡數據的優勢
涉及圖表:圖5
實驗細節概述:對CEVAE、TEDVAE和EDVAE模型的ITE估計結果進行回歸擬合,并給出回歸線方程
結果:
-
與CEVAE和TEDVAE相比,EDVAE的回歸線斜率和截距更好
-
證實了不平衡數據對可分離潛在因子模型結果的重要影響
5.3.3 實驗三、EDVAE消融實驗
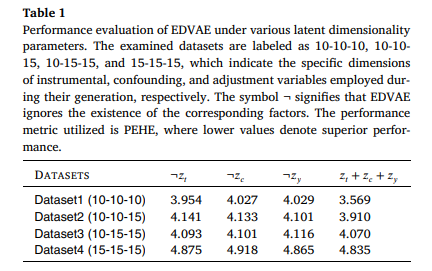
目的:研究EDVAE模型中關鍵組件(過采樣層、不同潛在因子維度等)對模型性能的影響
涉及圖表:圖4,表1
實驗細節概述:
-
比較包含和不包含過采樣層的EDVAE模型性能
-
探究不同維度的混淆、工具和調整變量對EDVAE性能的影響
結果:
-
EDVAE整體優于EDVAE-WR,證實了過采樣層在ITE估計中的有效性
-
當潛在維度參數非零時,EDVAE性能顯著提升,驗證了其成功識別潛在因子的能力
5.3.4 實驗四、ACIC 2016數據集性能對比

目的:在ACIC 2016數據集上評估EDVAE相比其他方法的優勢
涉及圖表:表2
實驗細節概述:使用訓練集和測試集的PEHE指標比較DML4CATE、X-learner、DragonNet、CEVAE、TEDVAE、EDVAE-WR和EDVAE
結果:
-
學習可分離表示的方法(如EDVAE和TEDVAE)取得了更好的結果
-
EDVAE在平均值和方差方面實現了最佳性能
5.3.5 實驗五、IHDP數據集性能對比
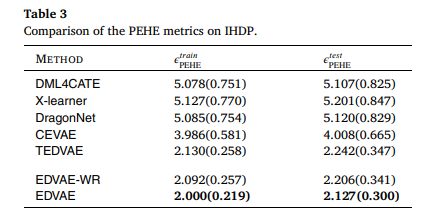
目的:在IHDP半合成數據集上評估EDVAE相比其他方法的優勢
涉及圖表:表3
實驗細節概述:使用訓練集和測試集的PEHE指標比較DML4CATE、X-learner、DragonNet、CEVAE、TEDVAE、EDVAE-WR和EDVAE
結果:
-
EDVAE的PEHE錯誤率在訓練集和測試集上分別比TEDVAE低6.10%和5.12%
-
EDVAE的標準差較小,表明其在真實數據集上表現更穩定
4 總結后記
本論文針對從觀察數據估計個體治療效應(ITE)的問題,提出了一種新的數據驅動的解耦隱變量模型EDVAE。該模型包含三個可擴展的組件:用于不平衡數據的過采樣層、用于解耦隱變量表示的表示層以及結果預測層。在合成數據和真實數據上的實驗結果表明,所提出的方法在ITE估計任務上優于現有方法,展現了從觀察數據估計ITE的潛力。
疑惑和想法:
-
EDVAE目前只考慮了二元治療,如何擴展到多元治療的場景?
-
除了VAE框架,是否可以探索其他形式的生成模型來學習解耦表示,如GAN、Flow等?
-
如何將EDVAE與其他減少選擇偏差的技術(如匹配、重加權等)相結合,進一步提升ITE估計的性能?(聚焦數據挑戰)
-
EDVAE能否擴展到估計其他形式的因果效應,如平均治療效應(ATE)、條件平均治療效應(CATE)等?
可借鑒的方法點:
-
在表示學習中引入VAE框架和互信息最小化準則來實現解耦表示,這一思想可以推廣到其他領域,如視覺、語音等。
-
采用過采樣層來處理不平衡數據問題的方法簡單有效,可以應用于其他對不平衡數據敏感的機器學習任務。
-
將因果推斷問題轉化為表示學習和預測問題的思路值得借鑒,為因果效應估計提供了新的視角。
-
利用輔助損失函數來平衡治療組和對照組在隱空間的分布差異,這一技巧可用于改進其他領域的域適應問題。




)









)




