?1.bert訓練的方法
????????為了訓練BERT模型,主要采用了兩種方法:掩碼語言模型(Masked Language Model, MLM)和下一個句子預測(Next Sentence Prediction, NSP)。
方法一:掩碼語言模型(Masked Language Model, MLM)
-
掩碼處理:
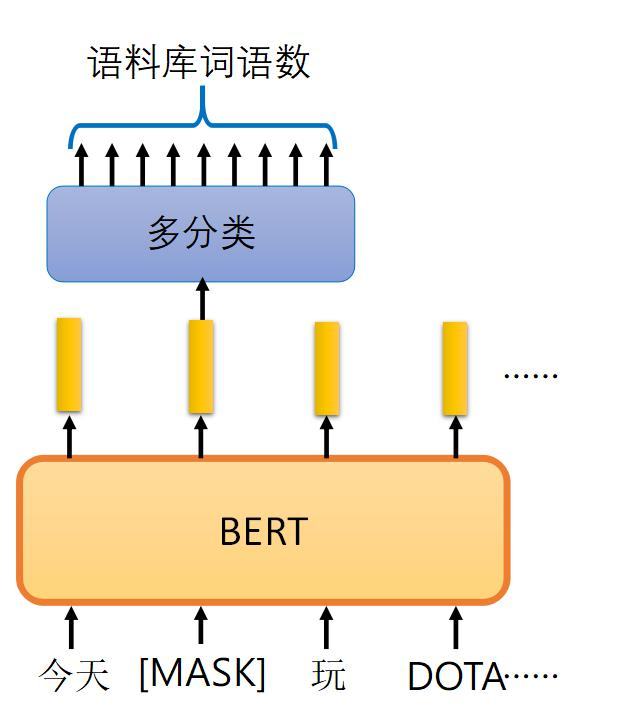
- 在訓練過程中,隨機選擇輸入句子中15%的詞匯,并將它們用特殊標記[MASK]替換。
- 例如,句子“今天我玩DOTA”可能被處理成“今天[MASK]玩DOTA”。
-
預測被掩碼的詞匯:
- 模型需要根據上下文預測被掩碼的詞匯是什么。
- 圖中展示了BERT模型如何處理輸入序列,嘗試預測被掩碼的詞匯,最終通過多分類層輸出預測結果。
-
目標:
- 通過這種方式,模型可以學習到每個詞匯在不同上下文中的表示,提高對詞匯語義的理解。
方法二:下一個句子預測(Next Sentence Prediction, NSP)
-
句子對構建:
- 在訓練數據中,構建句子對,其中一部分句子對是連續的(即前后兩句在原文本中是連續的),另一部分是隨機組合的(即前后兩句在原文本中并不連續)。
-
輸入處理:
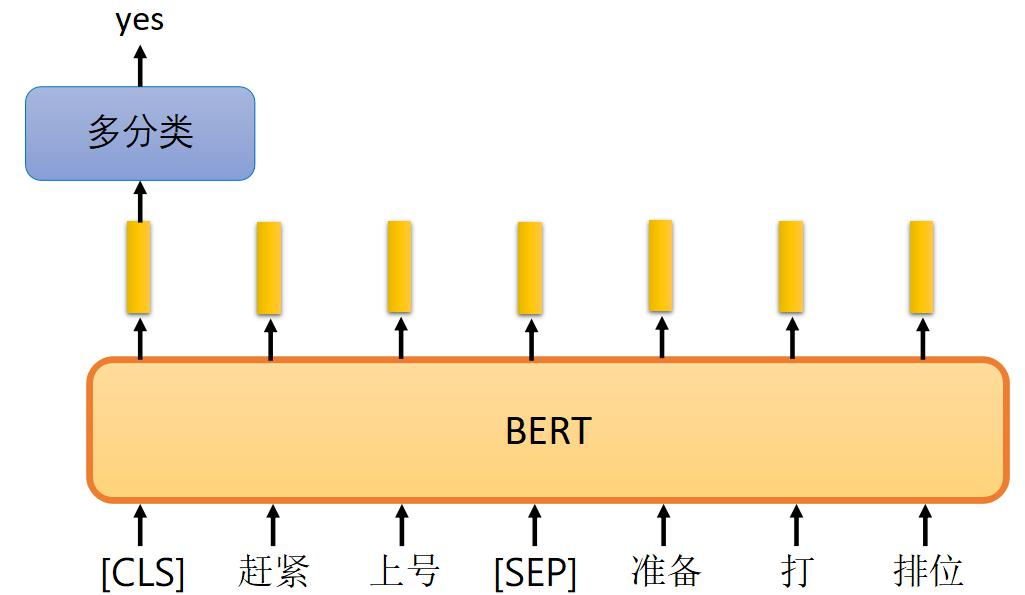
- 對每對句子添加特殊標記[CLS]和[SEP],其中[CLS]標記句子的開始,[SEP]標記句子的分隔。
- 例如,句子對“趙緊上號準備打排位”和“老師馬上點名”會被處理成“[CLS] 趙緊上號準備打排位 [SEP] 老師馬上點名 [SEP]”。
-
預測句子連貫性:
- 模型需要預測兩個句子是否應該連在一起。
- 圖中展示了BERT如何處理句子對,通過多分類層輸出預測結果,是或否。
-
目標:
- 通過預測句子對的連貫性,模型能夠學習到句子級別的上下文關系,增強對文本的理解能力。
2.ALBERT
論文地址:https://arxiv.org/abs/1909.11942v1
(1)解決的問題
????????在自然語言處理(NLP)領域,BERT(Bidirectional Encoder Representations from Transformers)模型的出現標志著預訓練技術的革命,極大地推動了該領域的發展。BERT憑借其強大的語言理解能力,在多項任務中取得了前所未有的成績,確立了“模型越大,效果越好”的普遍認知。然而,這一規律伴隨著顯著的挑戰:大規模模型意味著龐大的權重參數量,不僅對硬件資源,尤其是顯存,提出了極高的要求,還導致訓練過程異常緩慢,有時甚至需要數月之久,這對于快速迭代和實際應用構成了巨大障礙。
????????為了解決上述難題,研究者們開始探索如何在不犧牲過多性能的前提下,打造更為輕量級的BERT模型,即A Lite BERT。這類模型旨在通過優化結構和算法,減少模型的復雜度和參數量,同時保持其強大的表達能力。一個關鍵的觀察是,BERT模型中的Transformer架構中,Embedding層約占總參數的20%,而Attention機制則占據了剩余的80%。這意味著,通過精簡或優化這些部分,可以有效減小模型體積。
????????ALBERT(A Lite BERT)正是在此背景下應運而生的一個代表。它通過參數共享、跨層權重綁定等技巧大幅減少了模型的參數量,同時保持了競爭力的表現。例如,與原始BERT相比,ALBERT在保持相似性能的同時,顯著降低了對計算資源的需求,加快了訓練速度,使得模型能夠在更短的時間內完成訓練,降低了部署門檻,使得更多研究者和開發者能夠受益。
????????此外,隨著技術的進步,如優化器的創新、并行計算技術的發展以及分布式訓練策略的優化,即使是大型模型的訓練時間也得到了大幅縮減。從過去需要數月的訓練周期,到現在某些情況下僅需幾分鐘,這些進步充分體現了技術革新對于加速NLP模型訓練的顯著影響。因此,通過不斷的模型優化與算法創新,實現更快速、更高效的BERT模型訓練已經成為可能,為推動NLP技術的廣泛應用奠定了堅實基礎。
(2)隱層特征越多,效果一定越好嗎?
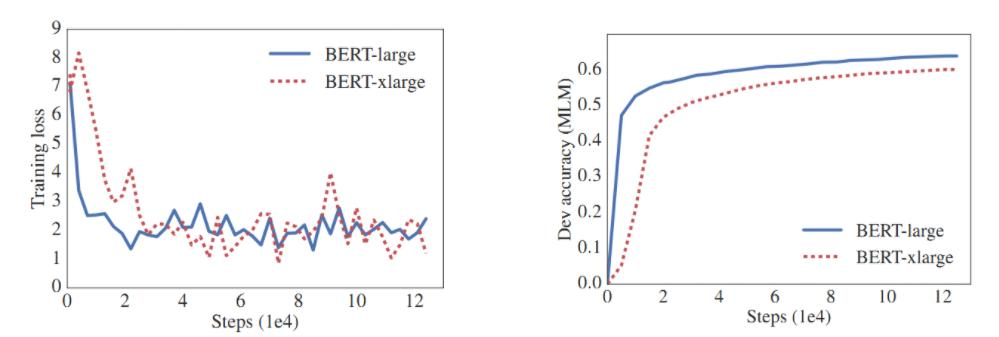
? ? ? ??圖中展示了BERT-large和BERT-xlarge模型在訓練過程中的表現對比。盡管BERT-xlarge的隱藏層特征更多、參數量更大,但其在RACE數據集上的準確率(54.3%)低于BERT-large(73.9%)。這表明,模型效果并不一定隨著隱藏層特征的增加而提高,合適的模型規模和結構更為重要。
 (3)重要參數
(3)重要參數
????????在深入理解自然語言處理(NLP)特別是Transformer模型架構時,幾個核心參數扮演著至關重要的角色,分別是E、H和V:
-
E (Embedding Size): 這表示模型在將文本轉換為機器可理解的形式時,每個詞嵌入向量的維度。換句話說,E定義了詞匯表中每個詞經過詞嵌入層處理后所獲得的向量空間的大小。例如,如果E設置為768,那么每個詞都將被映射到一個768維的向量中。
-
H (Hidden Layer Size): H是指Transformer模型中隱藏層的維度,特別是在多頭自注意力(Multi-Head Attention)和前饋神經網絡(Feed Forward Networks, FFNs)等組件處理后輸出的向量尺寸。同樣地,使用768作為一個常見例子,意味著經過這些層處理后的特征向量也是768維的。這表明,在許多標準Transformer配置中,E和H是相等的,均為768,以此確保模型內部信息傳遞的一致性和高效性。
-
V (Vocabulary Size): V代表了模型訓練所依據的語料庫中不同詞項的數量。例如,如果我們的字典包含20,000個獨特的詞或token,則V即為20,000。這個數值直接影響到詞嵌入層的初始化和大小,每個詞在詞嵌入矩陣中都有一個對應的、獨一無二的向量表示。
(4)嵌入向量參數化的因式分解
????????在自然語言處理(NLP)領域,尤其是在設計高效的Transformer模型時,面對巨大的參數量挑戰,研究者們探索了一種創新策略——嵌入向量參數化的因式分解。這種方法巧妙地通過引入一個中介層,將原本單層高維度的嵌入表示分解為兩個低維度的步驟,從而在不嚴重犧牲模型性能的前提下,大幅度減少所需的參數數量。
????????具體來說,傳統的Transformer模型中,嵌入層直接將詞匯表(V)中的每個詞映射到一個高維空間(H),導致參數量為V×H。而采用因式分解技術后,這一過程被重構為先通過一個較低維度的嵌入(E)表示每個詞,隨后再將此低維表示映射至最終的高維空間(H)。這樣一來,參數總量從V×H減少到了V×E+E×H。當目標是構建輕量化模型且H遠大于E時,這種方法尤其有效,能夠在保持模型相對性能的同時,顯著減輕硬件負擔,加快訓練和推理速度。
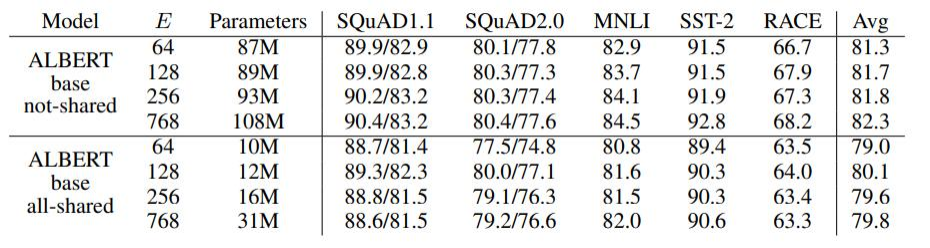
? ? ? ? ?上圖中展示了嵌入向量參數化對模型性能的影響。結果表明,嵌入向量維度 𝐸的變化對性能有一定影響,但并不顯著。在所有參數共享的情況下,盡管參數量減少,模型的平均性能僅略微下降,這表明模型在保持較少參數量的情況下仍能保持較好的性能。
(5)跨層參數共享
? ? ? ?參數共享的方法有很多,ALBERT選擇了全部共享,FFN和ATTENTION的都共享。
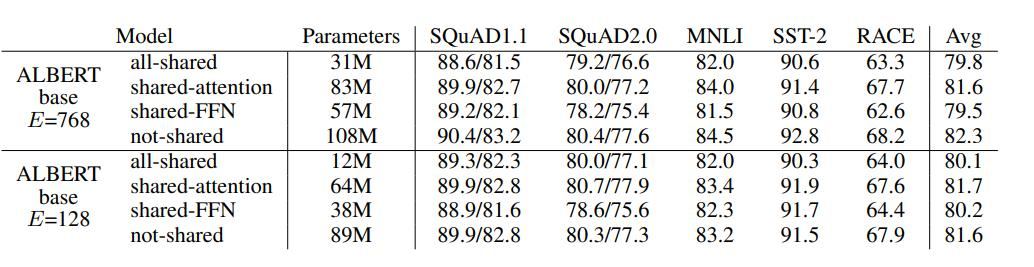
?????????結果顯示,全部共享(all-shared)的方法在減少參數數量的同時,依然保持了較高的性能。例如,對于嵌入維度為768的ALBERT模型,全部共享方法的平均性能(Avg)為79.8,而未共享的性能為82.3。盡管未共享的方法性能稍高,但參數量顯著增加(108M vs. 31M)。這表明參數共享方法,尤其是全部共享方法,可以在保持模型性能的前提下顯著減少參數量。
? ? ? ? 論文還展示了模型層數和隱藏層特征大小對性能的影響。結果表明,層數和隱藏層特征越多,模型性能越好。例如,層數為24時,模型在多個數據集上的平均性能最高(82.1)。同時,隱藏層特征從1024增加到4096時,模型性能也顯著提升。這說明增加層數和隱藏層特征可以有效提高模型性能。


3.Robustly optimized BERT approach
https://arxiv.org/pdf/1907.11692v1
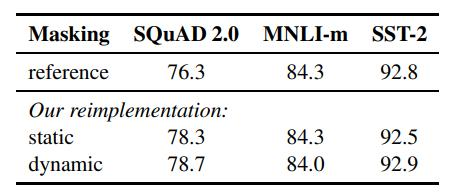
????????在持續探索提升自然語言處理(NLP)模型訓練效率的過程中,優化訓練策略尤其是設計更有效的masking機制成為了研究的焦點。傳統上,BERT等模型采用靜態masking策略,在輸入序列中隨機掩蓋部分詞匯,促使模型學習預測這些缺失部分,以此增強語言理解能力。然而,這種方法存在局限性,其生成的mask模式固定且與真實應用場景可能存在偏差。
????????近期的研究工作則聚焦于動態masking技術,這正是某篇論文探討的核心創新點。與靜態masking相比,動態masking在每次訓練迭代時依據特定策略靈活調整掩蓋模式,旨在模擬更加多樣和貼近實際的語言情境。這一變化直覺上看似簡單,實則蘊含深刻:通過引入動態性,模型被鼓勵學習更廣泛和復雜的上下文依賴,從而可能在語言建模能力上實現更顯著的提升。
????????此外,該研究還揭示了一個有趣的發現:取消BERT原始訓練目標之一的**Next Sentence Prediction (NSP)**任務,即判斷兩個句子是否連續,竟然能帶來意想不到的效果提升。NSP任務本意是為了增強模型對句子間關系的理解,但在實際操作中,它的貢獻似乎不如預期,并可能引入不必要的復雜性。移除NSP后,模型能夠更加專注于核心的語言建模任務,這不僅簡化了訓練流程,還可能促進了模型性能的優化。
(1)優化點
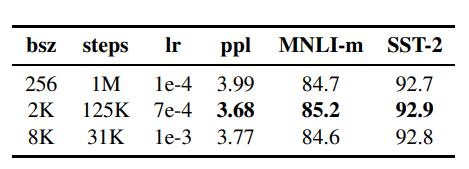
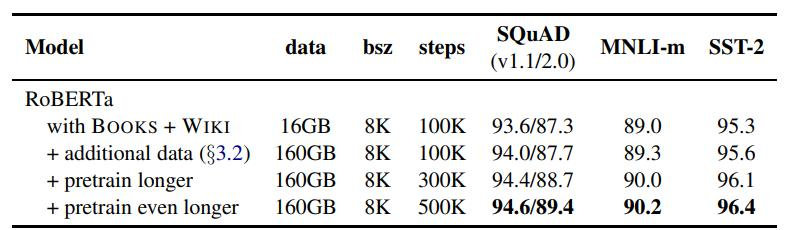
????????首先,增加BatchSize(批處理大小)被認為是提高模型性能的有效方法。其次,使用更多的數據集并延長訓練時間也能提升效果。最后,對分詞方式進行改進,使英文拆分更細致,從而提高模型在SQuAD、MNLI和SST-2數據集上的性能。總的來看,這些優化措施顯著增強了模型的表現。
(2)?RoBERTa-wwm
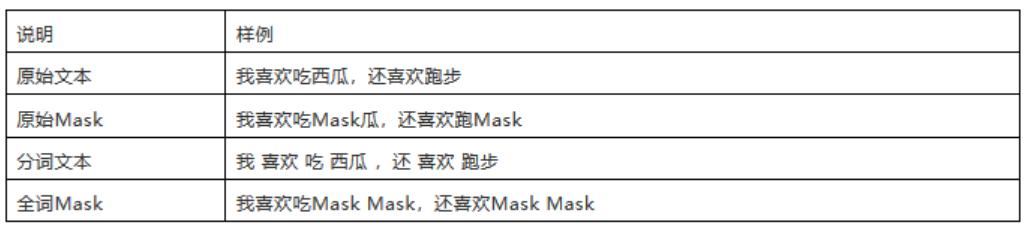
????????RoBERTa-wwm是一種針對中文場景優化的預訓練語言模型,其中的"wwm"代表"whole word mask",即全詞掩碼策略。這一策略特別關鍵,因為它考慮到了中文詞語不像英語那樣由空格分隔的特點,往往一個詞匯由多個字符組成。在預訓練過程中,全詞掩碼會將整個詞匯作為一個單位進行掩蓋,而非單獨遮蔽單個字符,這樣能更準確地保留和學習中文詞匯的完整性及上下文語境,對于提升模型在中文自然語言處理任務上的性能至關重要。因此,對于面向中文場景的訓練任務,采用如RoBERTa-wwm這樣的全詞掩碼模型是極為重要的優化措施。
4.A distilled version of BERT: smaller,faster, cheaper and lighter
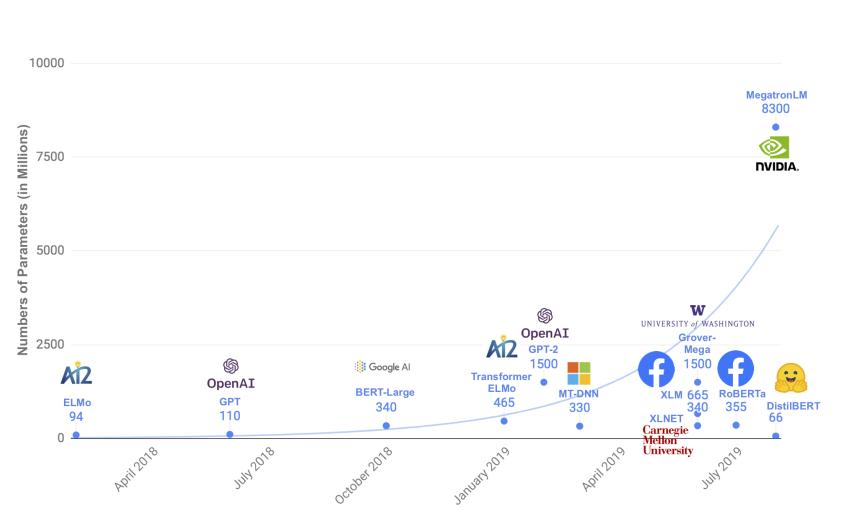
????????2019年,自然語言處理(NLP)領域見證了模型規模不斷膨脹的趨勢,學界普遍認同“越大越強”的理念,認為通過增加模型容量可以獲得更優的性能表現,體現了一種“大力出奇跡”的學術探索精神。然而,在實際應用層面,這引發了對計算資源、存儲需求以及能源消耗的深切關注。工程實踐迫切需要找到平衡點:如何在保持模型相對小巧的同時,確保其具備強大的語言處理能力。
? ? ? ?DistilBERT是BERT的一個蒸餾版本,具有更小的模型尺寸、更快的推理速度和更低的成本。
-
參數減少:
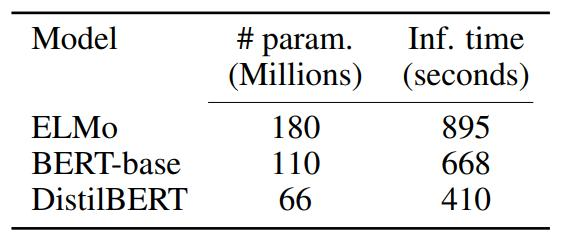
- DistilBERT的參數數量減少了大約40%,主要是為了提高預測速度。
- 具體參數數量對比:
- ELMo:180百萬參數,推理時間895秒。
- BERT-base:110百萬參數,推理時間668秒。
- DistilBERT:66百萬參數,推理時間410秒。
-
性能保留:
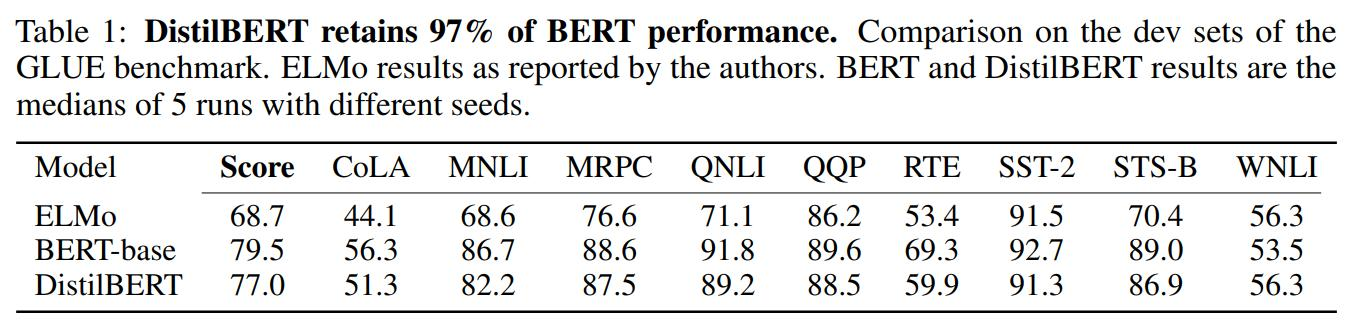
- 盡管DistilBERT進行了大幅度的模型精簡,它仍能保留97%的BERT性能。
- 在GLUE基準測試中的表現(表1所示):
- 總體得分:DistilBERT為77.0,BERT-base為79.5。
- 各子任務得分接近,如MNLI、MRPC、QNLI等任務上DistilBERT表現均較好。
 ?
?
?










)


設計模式?)
)
)
:Nginx核心原理)


