說起迭代器(Iterator),相信你并不會陌生,因為我們幾乎每天都在使用JDK中自帶的各種迭代器。那么,這些迭代器是如何構建出來的呢?就需要用到了今天內容要介紹的迭代器設計模式。在日常開發過程中,我們可能很少會自己去實現一個迭代器,但掌握迭代器設計模式對于我們學習一些開源框架的源碼還是很有幫助的,因為在像Mybatis等主流開發框架中都用到了迭代器模式。
迭代器設計模式的概念和簡單示例
在對迭代器模式的應用場景和方式進行展開之前,讓我們先來對它的基本結構做一些展開。迭代器是這樣一種結構:它提供一種方法,可以順序訪問聚合對象中的各個元素,但又不暴露該對象的內部表示。
想要構建這樣一個迭代器,我們就可以引入迭代器設計模式。迭代器模式的基本結構如下圖所示。
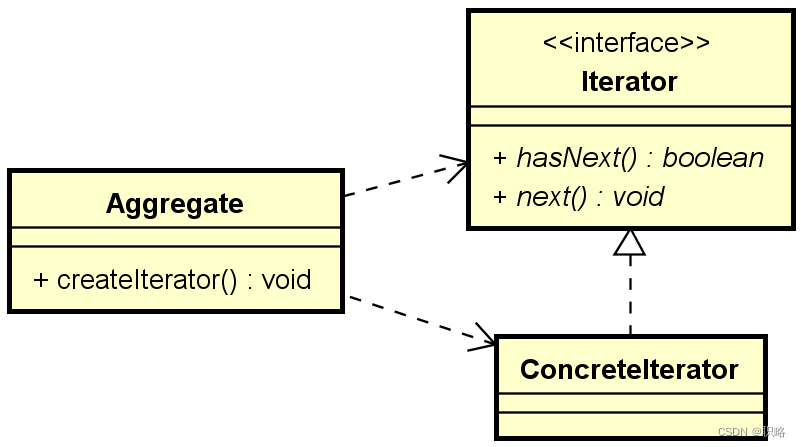
上圖中的Aggregate相當于是一個容器,致力于提供符合Iterator實現的數據格式。當我們訪問容器時,則是使用Iterator提供的數據遍歷方法進行數據訪問,這樣處理容器數據的邏輯就和容器本身的實現了解耦,因為我們只需要使用Iterator接口就行了,完全不用關心容器怎么實現、底層數據如何訪問之類的問題。而且更換容器的時候也不需要修改數據處理邏輯。
明白了迭代器模式的基本結構,接下來我們來給出對應的案例代碼。首當其沖的,我們需要實現一個Iterator接口,如下所示。
public?interface?Iterator<T> {
//是否存在下一個元素
??boolean?hasNext();
//獲取下一個元素
??T next();
}
注意到這里使用的泛型結構,意味著這個迭代器接口可以應用到各種數據結構上。而這里的hasNext和next方法分別用來判斷迭代器中是否存在下一個元素,以及下一個元素具體是什么。
然后,我們可以創建一個代表元素的數據結構,例如像這樣的Item類。
public?class?Item {
??private?ItemType type;
??private?final?String name;
??public?Item(ItemType type, String name) {
????this.setType(type);
????this.name?= name;
??}
…
}
注意到這里包含了兩個參數,一個是ItemType枚舉,代表Item的類型,另一個則指定Item的名稱。
如果我們把Item看做是一個個寶物,那么我們就可以構建一個寶箱(TreasureChest)類,
public?class?TreasureChest?{
??private?final?List<Item> items;
??
??public?TreasureChest() {
????items?= List.of(
????????new?Item(ItemType.POTION, "勇氣藥劑"),
????????new?Item(ItemType.RING, "陰影之環"),
????????new?Item(ItemType.POTION, "智慧藥劑"),
????????new?Item(ItemType.WEAPON, "銀色之劍"),
????????new?Item(ItemType.POTION, "腐蝕藥劑"),
????????new?Item(ItemType.RING, "盔甲之環"),
????????new?Item(ItemType.WEAPON, "毒之匕首"));
??}
??public?Iterator<Item> iterator(ItemType itemType) {
????return?new?TreasureChestItemIterator(this, itemType);
??}
??public?List<Item> getItems() {
????return?new?ArrayList<>(items);
??}
}
結合迭代器模式的基本結構,這個TreasureChest類相當于就是代表容器的Aggregate類,該類依賴于Iterator接口,同時又負責創建一個迭代器組件TreasureChestItemIterator。TreasureChestItemIterator類如下所示。
public?class?TreasureChestItemIterator?implements?Iterator<Item> {
//當前項索引
??private?int?idx;
??private?final?TreasureChest chest;
??private?final?ItemType type;
??public?TreasureChestItemIterator(TreasureChest chest, ItemType type) {
????this.chest?= chest;
????this.type?= type;
????this.idx?= -1;
??}
??@Override
??public?boolean?hasNext()?{
????return?findNextIdx() != -1;
??}
??@Override
??public?Item next()?{
????idx?= findNextIdx();
????if?(idx?!= -1) {
??????return?chest.getItems().get(idx);
????}
????return?null;
??}
//尋找下一個Idx
??private?int?findNextIdx() {
????var?items?= chest.getItems();
????var?tempIdx?= idx;
????while?(true) {
??????tempIdx++;
??????if?(tempIdx?>= items.size()) {
????????tempIdx?= -1;
????????break;
??????}
??????if?(type.equals(ItemType.ANY) || items.get(tempIdx).getType().equals(type)) {
????????break;
??????}
????}
????return?tempIdx;
??}
}
TreasureChestItemIterator的實現主要就是基于當前項索引對Item進行動態遍歷和判斷。
案例的最后,我們可以構建一段測試代碼完成對TreasureChest和TreasureChestItemIterator功能的驗證,如下所示。
??private?static?final?TreasureChest TREASURE_CHEST?= new?TreasureChest();
var?itemIterator?= TREASURE_CHEST.iterator(ItemType.RING);
????while?(itemIterator.hasNext()) {
??????LOGGER.info(itemIterator.next().toString());
}
執行這段代碼,不難想象我們可以得到如下所示的結果。
陰影之環
盔甲之環
顯然,我們獲取了對應類型的Item數據,而這個過程對于測試代碼而言是完全解耦的,我們不需要知道迭代器內部的運行原理,而只需要關注所返回的結果。
迭代器設計模式在Mybatis中的應用
介紹完迭代器模式的基本概念和代碼示例,我們進一步來看看它是如何在主流開源框架中進行應用的。在Mybatis中,針對SQL中配置項語句的解析,專門設計并實現了一套迭代器組件。
Mybatis中存在兩個類,通過了對迭代器模式的具體實現,分別是PropertyTokenizer和CursorIterator。我們先來看PropertyTokenizer的實現方法。
PropertyTokenizer
在Mybatis中,存在一個非常常用的工具類PropertyTokenizer,該類主要用于解析諸如“order[0].address.contactinfo.name”類型的屬性表達式,在這個例子中,我們可以看到系統是在處理訂單實體的地址信息,Mybatis支持使用這種形式的表達式來獲取最終的“name”屬性。我們可以想象一下,當我們想要解析“order[0].address.contactinfo.name”字符串時,我們勢必需要先對其進行分段處理以分別獲取各個層級的對象屬性名稱,如果遇到“[]”符號表示說明要處理的是一個對象數組。這種分層級的處理方式可以認為是一種迭代處理方式,作為迭代器模式的實現,PropertyTokenizer對這種處理方式提供了支持,該類代碼如下所示。
public class PropertyTokenizer implements Iterator<PropertyTokenizer> {
??private String name;
??private final String indexedName;
??private String index;
??private final String children;
??public PropertyTokenizer(String fullname) {
????int delim = fullname.indexOf('.');
????if (delim > -1) {
??????name = fullname.substring(0, delim);
??????children = fullname.substring(delim + 1);
????} else {
??????name = fullname;
??????children = null;
????}
????indexedName = name;
????delim = name.indexOf('[');
????if (delim > -1) {
??????index = name.substring(delim + 1, name.length() - 1);
??????name = name.substring(0, delim);
????}
??}
?…
??@Override
??public boolean hasNext() {
????return children != null;
??}
??@Override
??public PropertyTokenizer next() {
????return new PropertyTokenizer(children);
??}
??@Override
??public void remove() {
????throw new UnsupportedOperationException("Remove is not supported, as it has no meaning in the context of properties.");
??}
}
針對“order[0].address.contactinfo.name”字符串,當啟動解析時,PropertyTokenizer類的name字段指的就是“order”,indexedName字段指的就是“order[0]”,index字段指的就是“0”,而children字段指的就是“address.contactinfo.name”。在構造函數中,當對傳入的字符串進行處理時,通過“.”分隔符將其分作兩部分。然后在對獲取的name字段提取“[”,把中括號里的數字給解析出來,如果name段子你中包含“[]”的話,分別獲取index字段并更新name字段。
通過構造函數對輸入字符串進行處理之后,PropertyTokenizer的next()方法非常簡單,直接再通過children字段再來創建一個新的PropertyTokenizer實例即可。而經常使用的hasNext()方法實現也很簡單,就是判斷children屬性是否為空。
我們再來看PropertyTokenizer類的使用方法,我們在org.apache.ibatis.reflection包的MetaObject類中找到了它的一種常見使用方法,代碼如下所示。
public Object getValue(String name) {
????PropertyTokenizer prop = new PropertyTokenizer(name);
????if (prop.hasNext()) {
??????MetaObject metaValue = metaObjectForProperty(prop.getIndexedName());
??????if (metaValue == SystemMetaObject.NULL_META_OBJECT) {
????????return null;
??????} else {
????????return metaValue.getValue(prop.getChildren());
??????}
????} else {
??????return objectWrapper.get(prop);
????}
??}
這里可以明顯看到通過PropertyTokenizer 的prop.hasNext()方法進行遞歸調用的代碼處理流程。
CursorIterator
其實,迭代器模式有時還被稱為是游標(Cursor)模式,所以通常可以使用該模式構建一個基于游標機制的組件。我們數據庫訪問領域中恰恰就有一個游標的概念,當查詢數據庫返回大量的數據項時可以使用游標Cursor,利用其中的迭代器可以懶加載數據,避免因為一次性加載所有數據導致內存奔潰。而Mybatis又是一個數據庫訪問框架,那么在這個框架中是否存在一個基于迭代器模式的游標組件呢?答案是肯定的,讓我們來看一下。
Mybatis提供了Cursor接口用于表示游標操作,該接口位于org.apache.ibatis.cursor包中,定義如下所示。
public interface Cursor<T> extends Closeable, Iterable<T> {
??boolean isOpen();
??boolean isConsumed();
??int getCurrentIndex();
}
同時,Mybatis為Cursor接口提供了一個默認實現類DefaultCursor,核心代碼如下。
public class DefaultCursor<T> implements Cursor<T> {
??private final CursorIterator cursorIterator = new CursorIterator();
??@Override
??public boolean isOpen() {
????return status == CursorStatus.OPEN;
??}
??@Override
??public boolean isConsumed() {
????return status == CursorStatus.CONSUMED;
??}
??@Override
??public int getCurrentIndex() {
????return rowBounds.getOffset() + cursorIterator.iteratorIndex;
??}
// 省略其他方法 ???
}
我們看到這里引用了CursorIterator,從命名上就可以看出這是一個迭代器,其代碼如下所示。
private class CursorIterator implements Iterator<T> {
????T object;
????int iteratorIndex = -1;
????@Override
????public boolean hasNext() {
??????if (object == null) {
????????object = fetchNextUsingRowBound();
??????}
??????return object != null;
????}
????@Override
????public T next() {
??????// Fill next with object fetched from hasNext()
??????T next = object;
??????if (next == null) {
????????next = fetchNextUsingRowBound();
??????}
??????if (next != null) {
????????object = null;
????????iteratorIndex++;
????????return next;
??????}
??????throw new NoSuchElementException();
????}
????@Override
????public void remove() {
??????throw new UnsupportedOperationException("Cannot remove element from Cursor");
????}
}
上述游標迭代器CursorIterator實現了java.util.Iterator 迭代器接口,這里的迭代器模式實現方法實際上跟 ArrayList 中的迭代器幾乎一樣。
對于系統中具有對元素進行迭代訪問的應用場景而言,迭代器設計模式能夠幫助我們構建優雅的迭代操作。現實中有數據訪問方式都與迭代器相關,通過迭代器模式可以構建出靈活而高效的迭代器組件。在今天的內容中,我們通過詳細的示例代碼對這一設計模式的基本結構進行了展開,并分析了它在Mybatis框架中的兩處具有代表性的應用場景以及實現方式。
)
)
:Nginx核心原理)



)






)


)


