
本篇文章深入分析了大型模型微調的基本理念和多樣化技術,細致介紹了LoRA、適配器調整(Adapter Tuning)、前綴調整(Prefix Tuning)等多個微調方法。詳細討論了每一種策略的基本原則、主要優點以及適宜應用場景,使得讀者可以依據特定的應用要求和計算資源限制,挑選最適合的微調方案。
一、大型模型微調的基礎理論
大型語言模型(LLM)的訓練過程通常分為兩大階段:
階段一:預訓練階段
在這個階段,大型模型會在大規模的無標簽數據集上接受訓練,目標是使模型掌握語言的統計特征和基礎知識。此期間,模型將掌握詞匯的含義、句子的構造規則以及文本的基本信息和上下文。
需特別指出,預訓練實質上是一種無監督學習過程。完成預訓練的模型,亦即基座模型(Base Model),擁有了普遍適用的預測能力。例如,GLM-130B模型、OpenAI的四個主要模型均屬于基座模型。
階段二:微調階段
預訓練完成的模型接下來會在針對性的任務數據集上接受更進一步的訓練。這一階段主要涉及對模型權重的細微調整,使其更好地適配具體任務。最終形成的模型將具備不同的能力,如gpt code系列、gpt text系列、ChatGLM-6B等。
那么,何為大型模型微調?
直觀上,大型模型微調即是向模型“輸入”更多信息,對模型的特定功能進行“優化”,通過輸入特定領域的數據集,使模型學習該領域知識,從而優化大模型在特定領域的NLP任務中的表現,如情感分析、實體識別、文本分類、對話生成等。
為何微調至關重要?
其核心理由是,微調能夠“裝備”大模型以更精細化的功能,例如整合本地知識庫進行搜索、針對特定領域問題構建問答系統等。
以VisualGLM為例,作為一個通用多模態模型,當應用于醫學影像判別時,就需要輸入醫學影像領域的數據集以進行微調,以此提升模型在醫學影像圖像識別方面的表現。
這與機器學習模型的超參數優化類似,只有在調整超參數后,模型才能更好地適應當前數據集;同時,大型模型可以經歷多輪微調,每次微調都是對模型能力的優化,即我們可以在現有的、已經具備一定能力的大模型基礎上進一步進行微調。
二、大型模型的經典網絡結構
以GPT系列中的Transformer為例,這種深度學習模型結構通過自注意力機制等技巧解決了相關問題。正是得益于Transformer架構,基于GPT的大型語言模型取得了顯著的進展。
Transformer模型架構包含了眾多模塊,而我們討論的各種微調技術通常是對這些模塊中的特定部分進行優化,以實現微調目的。
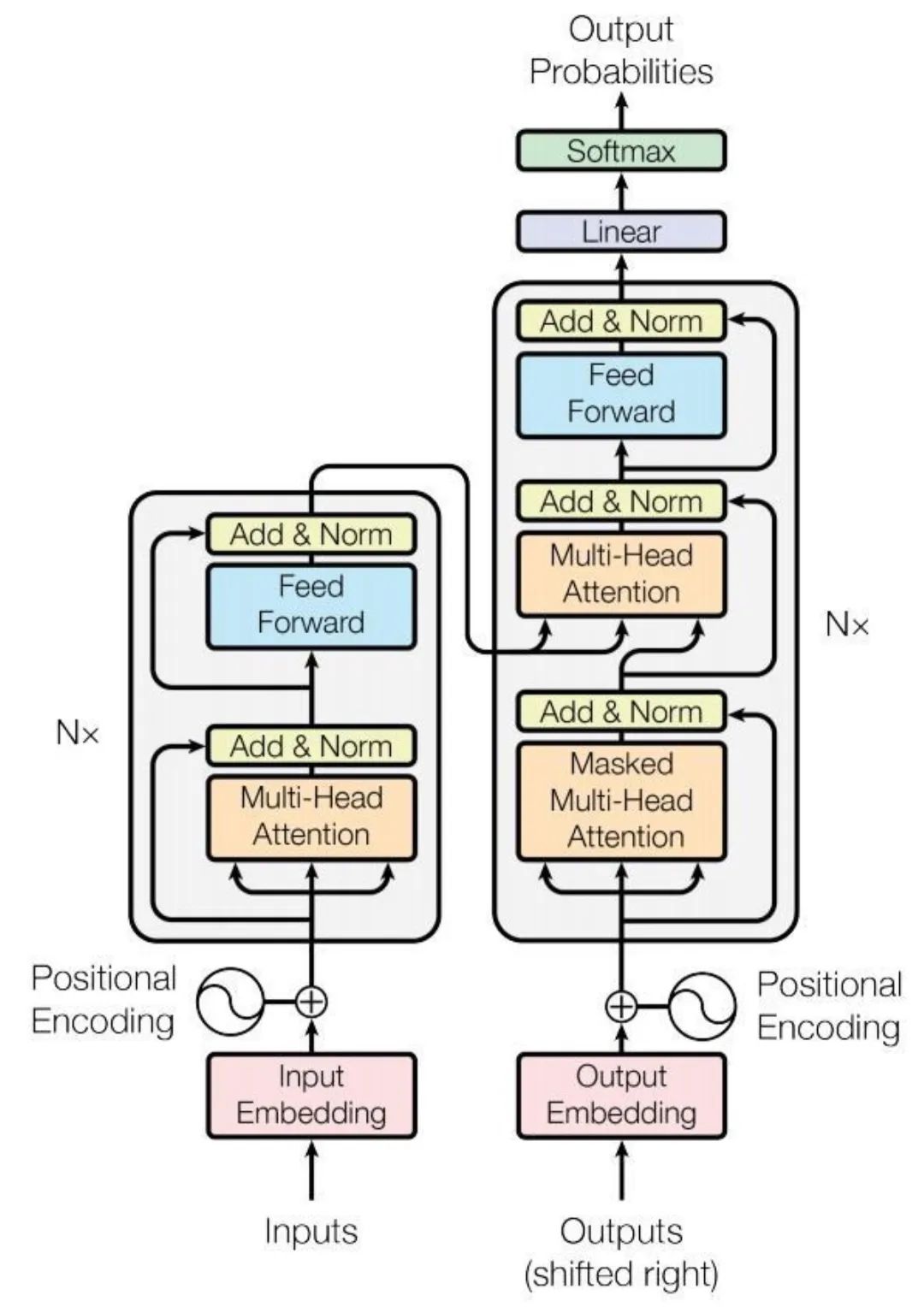
要深入理解各類微調手段,首先需要對網絡架構有一個基本的認識。以下以Transformer為例,闡述各個模塊的作用:
-
輸入嵌入層(Input Embedding)
-
- 輸入(Inputs):模型的輸入環節,通常為單詞或符號序列。
- 輸入嵌入(Input Embedding):此步驟將輸入序列(例如句中的每個單詞)轉化為嵌入表示,即能夠表征單詞語義信息的高維向量。
- 位置編碼(Positional Encoding):鑒于Transformer不依賴序列,位置編碼旨在提供序列中單詞位置的信息,這些編碼添加到輸入嵌入中,確保模型即便同時處理輸入也能夠利用單詞的順序信息。
-
編碼器層(Encoder,左邊)
-
- Nx:指示有N個相同的編碼器層疊加而成。每個編碼器層包括兩個主要子層:多頭自注意力機制和前饋神經網絡。
- 多頭自注意力(Multi-Head Attention):注意力機制允許模型在處理每個單詞時考慮到輸入序列中的所有單詞。多頭部分表示模型并行學習輸入數據的不同表示。
- 殘差連接和歸一化(Add & Norm):注意力層后面跟著殘差連接和層歸一化,有助于防止深層網絡中的梯度消失問題,并穩定訓練過程。
- 前饋神經網絡(Feed Forward):全連接神經網絡處理自注意力層的輸出,包含兩個線性變換和一個非線性激活函數。
-
解碼器層(Decoder,右側)
-
- 解碼器亦包含多個相同的層,每層包括三個主要子層:掩蔽的多頭自注意力機制、多頭自注意力機制和前饋神經網絡。
- 掩蔽多頭自注意力(Masked Multi-Head Attention):與編碼器的多頭自注意力機制類似,但為確保解碼順序性,掩蔽操作確保預測僅依賴于之前的輸出。
- 前饋神經網絡(Feed Forward):與編碼器相同,每個子層之后也有加法和歸一化步驟。
-
輸出嵌入層和輸出過程
-
- 解碼器端的嵌入層將目標序列轉換為向量形式。
- 線性層(Linear)和Softmax層:解碼器的輸出通過線性層映射到一個更大的詞匯空間,Softmax函數將輸出轉換為概率分布。
三、大型模型微調的技術手段
大型模型的全面微調(Fine-tuning)涉及調整所有層和參數,以適配特定任務。此過程通常采用較小的學習率和特定任務的數據,可以充分利用預訓練模型的通用特征,但可能需要更多計算資源。
參數高效微調(Parameter-Efficient Fine-Tuning,PEFT)旨在通過最小化微調參數數量和計算復雜度,提升預訓練模型在新任務上的表現,從而減輕大型預訓練模型的訓練負擔。
即使在計算資源受限的情況下,PEFT技術也能夠利用預訓練模型的知識快速適應新任務,實現有效的遷移學習。因此,PEFT不僅能提升模型效果,還能顯著縮短訓練時間和計算成本,使更多研究者能夠參與到深度學習的研究中。
PEFT包括LoRA、QLoRA、適配器調整(Adapter Tuning)、前綴調整(Prefix Tuning)、提示調整(Prompt Tuning)、P-Tuning及P-Tuning v2等多種方法。
以下圖表示了7種主流微調方法在Transformer網絡架構中的作用位置及其簡要說明,接下來將詳細介紹每一種方法。
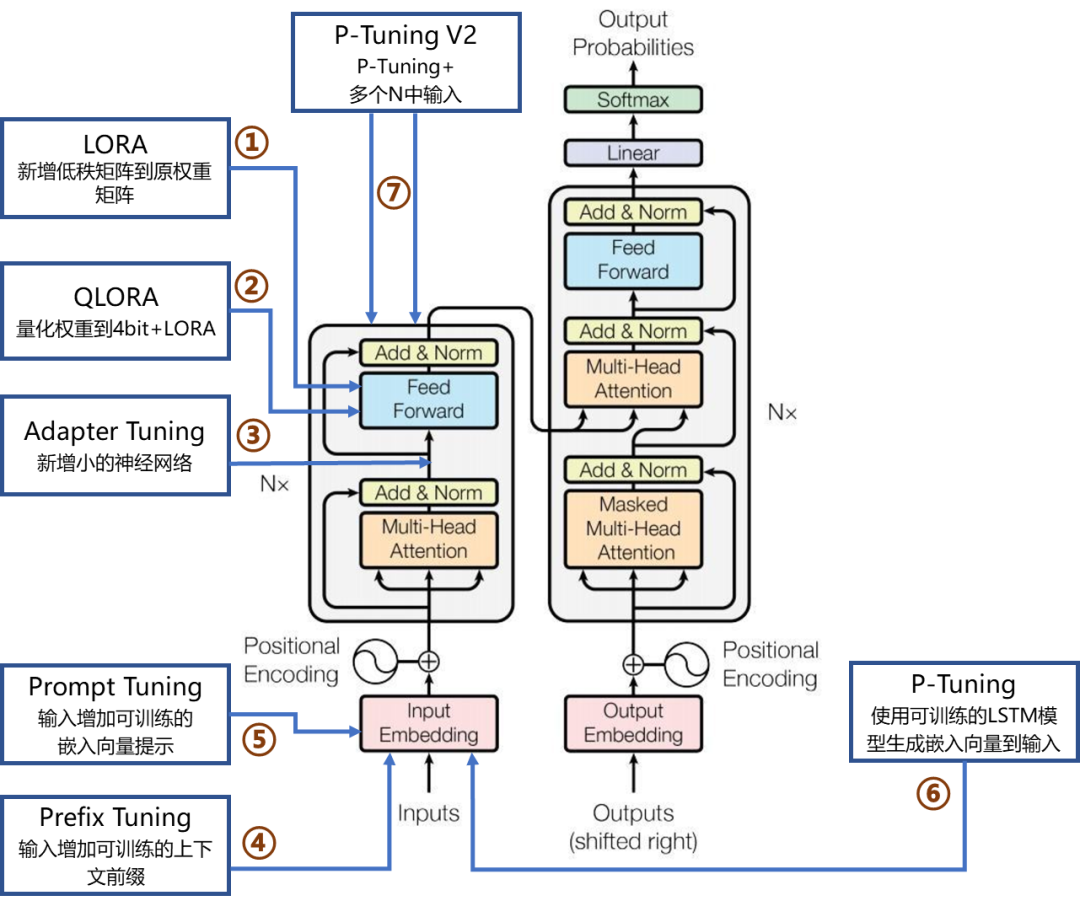
1、LoRA
LoRA(Low-Rank Adaptation)是一種旨在微調大型預訓練語言模型(如GPT-3或BERT)的技術。其核心理念在于,在模型的決定性層次中引入小型、低秩的矩陣來實現模型行為的微調,而無需對整個模型結構進行大幅度修改。
這種方法的優勢在于,在不顯著增加額外計算負擔的前提下,能夠有效地微調模型,同時保留模型原有的性能水準。
LoRA的操作流程如下:
- 確定微調目標權重矩陣:首先在大型模型(例如GPT)中識別出需要微調的權重矩陣,這些矩陣一般位于模型的多頭自注意力和前饋神經網絡部分。
- 引入兩個低秩矩陣:然后,引入兩個維度較小的低秩矩陣A和B。假設原始權重矩陣的尺寸為dd,則A和B的尺寸可能為dr和r*d,其中r遠小于d。
- 計算低秩更新:通過這兩個低秩矩陣的乘積AB來生成一個新矩陣,其秩(即r)遠小于原始權重矩陣的秩。這個乘積實際上是對原始權重矩陣的一種低秩近似調整。
- 結合原始權重:最終,新生成的低秩矩陣AB被疊加到原始權重矩陣上。因此,原始權重經過了微調,但大部分權重維持不變。這個過程可以用數學表達式描述為:新權重 = 原始權重 + AB。
以一個具體實例來說,假設我們手頭有一個大型語言模型,它通常用于執行廣泛的自然語言處理任務。現在,我們打算將其微調,使其在處理醫療健康相關的文本上更為擅長。
采用LoRA方法,我們無需直接修改模型現有的大量權重。相反,只需在模型的關鍵部位引入低秩矩陣,并通過這些矩陣的乘積來進行有效的權重調整。這樣一來,模型就能更好地適應醫療健康領域的專業語言和術語,同時也避免了大規模權重調整和重新訓練的必要。
2、QLoRA
QLoRA(Quantized Low-Rank Adaptation)是一種結合了LoRA(Low-Rank Adaptation)方法與深度量化技術的高效模型微調手段。QLoRA的核心在于:
- 量化技術:QLoRA采用創新的技術將預訓練模型量化為4位。這一技術包括低精度存儲數據類型(4-bit NormalFloat,簡稱NF4)和計算數據類型(16-bit BrainFloat)。這種做法極大地減少了模型存儲需求,同時保持了模型精度的最小損失。
- 量化操作:在4位量化中,每個權重由4個比特表示,量化過程中需選擇最重要的值并將它們映射到16個可能的值之一。首先確定量化范圍(例如-1到1),然后將這個范圍分成16個區間,每個區間對應一個4-bit值。然后,原始的32位浮點數值將映射到最近的量化區間值上。
- 微調階段:在訓練期間,QLoRA先以4-bit格式加載模型,訓練時將數值反量化到bf16進行訓練,這樣大幅減少了訓練所需的顯存。例如,33B的LLaMA模型可以在24 GB的顯卡上進行訓練。
量化過程的挑戰在于設計合適的映射和量化策略,以最小化精度損失對性能的影響。在大型模型中,這種方法可以顯著減少內存和計算需求,使得在資源有限的環境下部署和訓練成為可能。
3、適配器調整(Adapter Tuning)
與LoRA技術類似,適配器調整的目標是在保留預訓練模型原始參數不變的前提下,使模型能夠適應新的任務。適配器調整的方法是在模型的每個層或選定層之間插入小型神經網絡模塊,稱為“適配器”。這些適配器是可訓練的,而原始模型的參數則保持不變。
適配器調整的關鍵步驟包括:
- 以預訓練模型為基礎:初始階段,我們擁有一個已經經過預訓練的大型模型,如BERT或GPT,該模型已經學習了豐富的語言特征和模式。
- 插入適配器:在預訓練模型的每個層或指定層中,我們插入適配器。適配器是小型的神經網絡,一般包含少量層次,并且參數規模相對較小。
- 維持預訓練參數不變:在微調過程中,原有的預訓練模型參數保持不變。我們不直接調整這些參數,而是專注于適配器的參數訓練。
- 訓練適配器:適配器的參數會根據特定任務的數據進行訓練,使適配器能夠學習如何根據任務調整模型的行為。
- 針對任務的調整:通過這種方式,模型能夠對每個特定任務進行微調,同時不影響模型其他部分的通用性能。適配器有助于模型更好地理解和處理與特定任務相關的特殊模式和數據。
- 高效與靈活:由于只有部分參數被調整,適配器調整方法相比于全模型微調更為高效,并且允許模型迅速適應新任務。
例如,如果我們有一個大型文本生成模型,它通常用于執行廣泛的文本生成任務。若要將其微調以生成專業的金融報告,我們可以在模型的關鍵層中加入適配器。在微調過程中,僅有適配器的參數會根據金融領域的數據進行更新,使得模型更好地適應金融報告的寫作風格和術語,同時避免對整個模型架構進行大幅度調整。
LoRA與適配器調整的主要區別在于:
- LoRA:在模型的權重矩陣中引入低秩矩陣來實現微調。這些低秩矩陣作為原有權重矩陣的修改項,在實際計算時對原有權重矩陣進行調整。
- 適配器調整:通過在模型各層中添加小型神經網絡模塊,即“適配器”,來實現微調。適配器獨立于模型的主體結構,僅適配器的參數在微調過程中更新,而模型的其他預訓練參數保持不變。
4、前綴調整(Prefix Tuning)
與傳統的微調范式不同,前綴調整提出了一種新的策略,即在預訓練的語言模型(LM)輸入序列前添加可訓練、任務特定的前綴,從而實現針對不同任務的微調。這意味著我們可以為不同任務保存不同的前綴,而不是為每個任務保存一整套微調后的模型權重,從而節省了大量的存儲空間和微調成本。
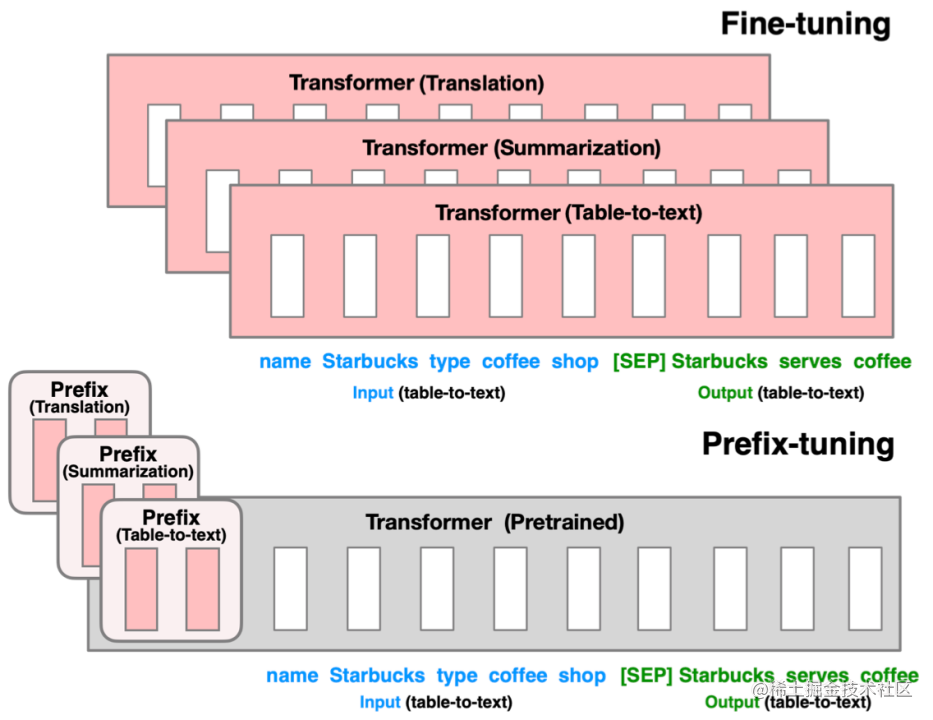
前綴實際上是一種連續可微的虛擬標記(Soft Prompt/Continuous Prompt),與離散的Token相比,它們更易于優化并且效果更佳。這種方法的優勢在于不需要調整模型的所有權重,而是通過在輸入中添加前綴來調整模型的行為,從而節省大量的計算資源,同時使得單一模型能夠適應多種不同的任務。前綴可以是固定的(即手動設計的靜態提示)或可訓練的(即模型在訓練過程中學習的動態提示)。
5、提示調整(Prompt Tuning)
提示調整是一種在預訓練語言模型輸入中引入可學習嵌入向量作為提示的微調方法。這些可訓練的提示向量在訓練過程中更新,以指導模型輸出更適合特定任務的響應。
提示調整與前綴調整都涉及在輸入數據中添加可學習的向量,這些向量是在輸入層添加的,但兩者的策略和目的不同:
- 提示調整:旨在模仿自然語言中的提示形式,將可學習向量(通常稱為提示標記)設計為模型針對特定任務生成特定類型輸出的引導。這些向量通常被視為任務指導信息的一部分,傾向于使用較少的向量來模仿傳統的自然語言提示。
- 前綴調整:可學習前綴更多地用于提供輸入數據的直接上下文信息,作為模型內部表示的一部分,可以影響整個模型的行為。
以下是兩者的訓練示例,以說明它們的不同:
- 提示調整示例:
輸入序列: [Prompt1][Prompt2] “這部電影令人振奮。”
問題: 評價這部電影的情感傾向。
答案: 模型需要預測情感傾向(例如“積極”)
提示: 沒有明確的外部提示,[Prompt1][Prompt2]作為引導模型的內部提示,這里的問題是隱含的,即判斷文本中表達的情感傾向。 - 前綴調整示例:
輸入序列: [Prefix1][Prefix2][Prefix3] “I want to watch a movie.”
問題: 根據前綴生成后續的自然語言文本。
答案: 模型生成的文本,如“that is exciting and fun.”
提示: 前綴本身提供上下文信息,沒有單獨的外部提示。
6、P-Tuning
P-Tuning(基于提示的微調)和提示調整都是為了調整大型預訓練語言模型(如GPT系列)以適應特定任務而設計的技術。兩者都利用預訓練的語言模型執行特定的下游任務,如文本分類、情感分析等,并使用某種形式的“提示”或“指導”來引導模型輸出,以更好地適應特定任務。
提示調整與P-Tuning的主要區別在于:
- 提示調整:使用靜態的、可訓練的虛擬標記嵌入,在初始化后保持固定,除非在訓練過程中更新。這種方法相對簡單,因為它只涉及調整一組固定的嵌入參數,在處理多種任務時表現良好,但可能在處理特別復雜或需要細粒度控制的任務時受限。
- P-Tuning:使用一個可訓練的LSTM模型(稱為提示編碼器prompt_encoder)來動態生成虛擬標記嵌入,允許根據輸入數據的不同生成不同的嵌入,提供更高的靈活性和適應性,適合需要精細控制和理解復雜上下文的任務。這種方法相對復雜,因為它涉及一個額外的LSTM模型來生成虛擬標記嵌入。
P-Tuning中使用LSTM(長短期記憶網絡)作為生成虛擬標記嵌入的工具,利用了LSTM的以下優勢:
- 更好的適應性和靈活性:LSTM可以捕捉輸入數據中的時間序列特征,更好地理解和適應復雜的、順序依賴的任務,如文本生成或序列標注。
- 改進的上下文理解:LSTM因其循環結構,擅長處理和理解長期依賴關系和復雜的上下文信息。
- 參數共享和泛化能力:在P-Tuning中,LSTM模型的參數可以在多個任務之間共享,這提高了模型的泛化能力,并減少了針對每個單獨任務的訓練需求。而在提示調整中,每個任務通常都有其獨立的虛擬標記嵌入,這可能限制了跨任務泛化的能力。
這些特性使得LSTM特別適合處理復雜任務和需要細粒度控制的應用場景。然而,這些優勢也伴隨著更高的計算復雜度和資源需求,因此在實際應用中需要根據具體需求和資源限制來權衡使用LSTM的決策。
7、P-Tuning v2
P-Tuning v2是P-Tuning的進一步改進版,在P-Tuning中,連續提示被插入到輸入序列的嵌入層中,除了語言模型的輸入層,其他層的提示嵌入都來自于上一層。這種設計存在兩個問題:
- 第一,它限制了優化參數的數量。由于模型的輸入文本長度是固定的,通常為512,因此提示的長度不能過長。
- 第二,當模型層數很深時,微調時模型的穩定性難以保證;模型層數越深,第一層輸入的提示對后面層的影響難以預測,這會影響模型的穩定性。
P-Tuning v2的改進在于,不僅在第一層插入連續提示,而是在多層都插入連續提示,且層與層之間的連續提示是相互獨立的。這樣,在模型微調時,可訓練的參數量增加了,P-Tuning v2在應對復雜的自然語言理解(NLU)任務和小型模型方面,相比原始P-Tuning具有更出色的效能。
除了以上PEFT,當前還存在PILL(Pluggable Instruction Language Learning)、SSF(Scaling & Shifting Your Features)等其他類型的微調方法。
PILL是PEFT的一個特定實現,特別關注于如何通過插入可訓練的模塊或插件來提升模型的任務適應性。這些插件被設計為與原始模型協同工作,以提高模型在處理特定任務時的效率和效果。
SSF核心思想是對模型的特征(即模型層的輸出)進行縮放(Scaling)和位移(Shifting)。簡單來說,就是通過調整特征的比例和偏移量來優化模型的性能。
這種方法可以在改善模型對特定任務的響應時,不需要調整或重新訓練模型中的所有參數,從而在節省計算資源的同時保持或提升模型性能。這對于處理大規模模型特別有效,因為它減少了訓練和調整所需的資源和時間。
四、大模型的微調策略
綜上所述,微調是一種強大的工具,它能夠使大型預訓練模型適應于特定的任務和應用場景。正確選擇和應用微調策略對于實現高效且有效的模型性能至關重要。
1、微調與遷移學習:微調實際上是遷移學習的一個實例,其中預訓練的模型(通常在大型通用數據集上訓練)被用作特定任務的起點。這種方法使得即使是對于小數據集的任務,也可以實現高效的學習
2、選擇微調策略:選擇哪種微調方法取決于多個因素,包括任務的復雜性、可用的數據量、計算資源和期望的性能。
例如,對于需要細粒度控制的復雜任務,P-Tuning v2或LSTM基礎的P-Tuning可能更適合。而對于計算資源有限的情況,可以選擇LoRA或Adapter Tuning等方法。
3、微調與模型泛化能力:微調時需要注意的一個關鍵問題是保持模型的泛化能力。過度的微調可能會導致模型對特定訓練數據過擬合,而忽略了其在實際應用中的泛化能力。
?
如何學習AI大模型?
作為一名熱心腸的互聯網老兵,我決定把寶貴的AI知識分享給大家。 至于能學習到多少就看你的學習毅力和能力了 。我已將重要的AI大模型資料包括AI大模型入門學習思維導圖、精品AI大模型學習書籍手冊、視頻教程、實戰學習等錄播視頻免費分享出來。
這份完整版的大模型 AI 學習資料已經上傳CSDN,朋友們如果需要可以微信掃描下方CSDN官方認證二維碼免費領取【保證100%免費】

一、全套AGI大模型學習路線
AI大模型時代的學習之旅:從基礎到前沿,掌握人工智能的核心技能!

二、640套AI大模型報告合集
這套包含640份報告的合集,涵蓋了AI大模型的理論研究、技術實現、行業應用等多個方面。無論您是科研人員、工程師,還是對AI大模型感興趣的愛好者,這套報告合集都將為您提供寶貴的信息和啟示。

三、AI大模型經典PDF籍
隨著人工智能技術的飛速發展,AI大模型已經成為了當今科技領域的一大熱點。這些大型預訓練模型,如GPT-3、BERT、XLNet等,以其強大的語言理解和生成能力,正在改變我們對人工智能的認識。 那以下這些PDF籍就是非常不錯的學習資源。

四、AI大模型商業化落地方案

作為普通人,入局大模型時代需要持續學習和實踐,不斷提高自己的技能和認知水平,同時也需要有責任感和倫理意識,為人工智能的健康發展貢獻力量。
)





)
)
)

)


)





