需求:為了利用elasticsearch實現高效搜索,需要將mysql中的數據查出來,再定時同步到es里,同時在同步過程中通過分片廣播+多線程提高同步數據的效率。
1. 添加映射
- 使用kibana添加映射
PUT /app_info_article
{"mappings":{"properties":{"id":{"type":"long"},"publishTime":{"type":"date"},"layout":{"type":"integer"},"images":{"type":"keyword","index": false},"staticUrl":{"type":"keyword","index": false},"authorId": {"type": "long"},"authorName": {"type": "keyword"},"title":{"type":"text","analyzer":"ik_max_word","copy_to": "all"},"content":{"type":"text","analyzer":"ik_max_word","copy_to": "all"},"all":{"type": "text","analyzer": "ik_max_word"}}}
}
- 使用http請求
PUT請求添加映射:http://192.168.200.130:9200/app_info_article
GET請求查詢映射:http://192.168.200.130:9200/app_info_article
DELETE請求,刪除索引及映射:http://192.168.200.130:9200/app_info_article
GET請求,查詢所有文檔:http://192.168.200.130:9200/app_info_article/_search

2. springboot測試
引入依賴
<!--elasticsearch--><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.12.1</version></dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-client</artifactId><version>7.12.1</version></dependency><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.12.1</version><exclusions><exclusion><groupId>com.fasterxml.jackson.dataformat</groupId><artifactId>jackson-dataformat-smile</artifactId></exclusion><exclusion><groupId>com.fasterxml.jackson.dataformat</groupId><artifactId>jackson-dataformat-yaml</artifactId></exclusion></exclusions></dependency>
elasticsearch配置
#自定義elasticsearch連接配置
elasticsearch:host: 192.168.200.131port: 9200
elasticsearch配置類
@Getter
@Setter
@Configuration
@ConfigurationProperties(prefix = "elasticsearch")
public class ElasticSearchConfig {private String host;private int port;@Beanpublic RestHighLevelClient client(){return new RestHighLevelClient(RestClient.builder(new HttpHost(host,port,"http")));}
}
實體類
@Data
public class SearchArticleVo {// 文章idprivate Long id;// 文章標題private String title;// 文章發布時間private Date publishTime;// 文章布局private Integer layout;// 封面private String images;// 作者idprivate Long authorId;// 作者名詞private String authorName;//靜態urlprivate String staticUrl;//文章內容private String content;}
測試。測試成功后別忘了刪除app_info_article的所有文檔
@SpringBootTest
@RunWith(SpringRunner.class)
public class ApArticleTest {@Autowiredprivate ApArticleMapper apArticleMapper;@Autowiredprivate RestHighLevelClient restHighLevelClient;/*** 注意:數據量的導入,如果數據量過大,需要分頁導入* 1)查詢數據庫數據* 2)將數據寫入到ES中即可* 創建BulkRequest* ================================* ||A:創建XxxRequest* ||B:向XxxRequest封裝DSL語句數據* || X C:使用RestHighLevelClient執行遠程請求* ================================* 將XxxRequest添加到BulkRequest* 使用RestHighLevelClient將BulkRequest添加到索引庫* @throws Exception*/@Testpublic void init() throws Exception {//1)查詢數據庫數據List<SearchArticleVo> searchArticleVos = apArticleMapper.loadArticleList();//2)創建BulkRequest - 刷新策略BulkRequest bulkRequest = new BulkRequest()//刷新策略-立即刷新.setRefreshPolicy(WriteRequest.RefreshPolicy.IMMEDIATE);for (SearchArticleVo searchArticleVo : searchArticleVos) {//A:創建XxxRequestIndexRequest indexRequest = new IndexRequest("app_info_article")//B:向XxxRequest封裝DSL語句數據.id(searchArticleVo.getId().toString()).source(JSON.toJSONString(searchArticleVo), XContentType.JSON);//3)將XxxRequest添加到BulkRequestbulkRequest.add(indexRequest);}//4)使用RestHighLevelClient將BulkRequest添加到索引庫restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);}}
3. 核心代碼
3.1 xxljob配置
xxl:job:accessToken: default_tokenadmin:addresses: http://127.0.0.1:8080/xxl-job-adminexecutor:address: ''appname: hmttip: ''logpath: /data/applogs/xxl-job/jobhandlerlogretentiondays: 30port: 9998
@Configuration
public class XxlJobConfig {private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);@Value("${xxl.job.admin.addresses}")private String adminAddresses;@Value("${xxl.job.accessToken}")private String accessToken;@Value("${xxl.job.executor.appname}")private String appname;@Value("${xxl.job.executor.address}")private String address;@Value("${xxl.job.executor.ip}")private String ip;@Value("${xxl.job.executor.port}")private int port;@Value("${xxl.job.executor.logpath}")private String logPath;@Value("${xxl.job.executor.logretentiondays}")private int logRetentionDays;@Beanpublic XxlJobSpringExecutor xxlJobExecutor() {XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(adminAddresses);xxlJobSpringExecutor.setAppname(appname);xxlJobSpringExecutor.setAddress(address);xxlJobSpringExecutor.setIp(ip);xxlJobSpringExecutor.setPort(port);xxlJobSpringExecutor.setAccessToken(accessToken);xxlJobSpringExecutor.setLogPath(logPath);xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);return xxlJobSpringExecutor;}
}
3.2 elasticsearch配置
和前面一樣
3.3 任務編寫
@Component
public class SyncIndexTask {@Autowiredprivate IArticleClient articleClient;@Autowiredprivate RestHighLevelClient restHighLevelClient;//線程池public static ExecutorService pool = Executors.newFixedThreadPool(10);/**** 同步索引任務* 1)當數量大于100條的時候,才做分片導入,否則只讓第1個導入即可* A:查詢所有數據量 ->searchTotal total>100 [判斷當前分片不是第1個分片]* 第N個分片執行數據處理范圍-要計算 確定當前分片處理的數據范圍 limit #{index},#{size}* [index-范圍]** B:執行分頁查詢-需要根據index判斷是否超過界限,如果沒有超過界限,則并開啟多線程,分頁查詢,將當前分頁數據批量導入到ES** C:在xxl-job中配置作業-策略:分片策略**/@XxlJob("syncIndex")public void syncIndex() {//1、獲取任務傳入的參數 {"minSize":100,"size":10}String jobParam = XxlJobHelper.getJobParam();Map<String,Integer> jobData = JSON.parseObject(jobParam,Map.class);int minSize = jobData.get("minSize"); //分片處理的最小總數據條數int size = jobData.get("size"); //分頁查詢的每頁條數 小分頁//2、查詢需要處理的總數據量 total=IArticleClient.searchTotal()Long total = articleClient.searchTotal();//3、判斷當前分片是否屬于第1片,不屬于,則需要判斷總數量是否大于指定的數據量[minSize],大于,則執行任務處理,小于或等于,則直接結束任務int cn = XxlJobHelper.getShardIndex(); //當前節點的下標if(total<=minSize && cn!=0){//結束return;}//4、執行任務 [index-范圍] 大的分片分頁處理//4.1:節點個數int n = XxlJobHelper.getShardTotal();//4.2:當前節點處理的數據量int count = (int) (total % n==0? total/n : (total/n)+1);//4.3:確定當前節點處理的數據范圍//從下標為index的數據開始處理 limit #{index},#{count}int indexStart = cn*count;int indexEnd = cn*count+count-1; //最大的范圍的最后一個數據的下標//5.小的分頁查詢和批量處理int index =indexStart; //第1頁的indexSystem.out.println("分片個數是【"+n+"】,當前分片下標【"+cn+"】,處理的數據下標范圍【"+indexStart+"-"+indexEnd+"】");do {//=============================================小分頁================================//5.1:分頁查詢//5.2:將數據導入ESpush(index,size,indexEnd);//5.3:是否要查詢下一頁 index+sizeindex = index+size;}while (index<=indexEnd);}/*** 數據批量導入* @param index* @param size* @param indexEnd* @throws IOException*/public void push(int index,int size,int indexEnd) {pool.execute(()->{System.out.println("當前線程處理的分頁數據是【index="+index+",size="+(index+size>indexEnd? indexEnd-index+1 : size)+"】");//1)查詢數據庫數據List<SearchArticleVo> searchArticleVos = articleClient.searchPage(index, index+size>indexEnd? indexEnd-index+1 : size); //size可能越界//2)創建BulkRequest - 刷新策略BulkRequest bulkRequest = new BulkRequest()//刷新策略-立即刷新.setRefreshPolicy(WriteRequest.RefreshPolicy.IMMEDIATE);for (SearchArticleVo searchArticleVo : searchArticleVos) {//A:創建XxxRequestIndexRequest indexRequest = new IndexRequest("app_info_article")//B:向XxxRequest封裝DSL語句數據.id(searchArticleVo.getId().toString()).source(com.alibaba.fastjson.JSON.toJSONString(searchArticleVo), XContentType.JSON);//3)將XxxRequest添加到BulkRequestbulkRequest.add(indexRequest);}//4)使用RestHighLevelClient將BulkRequest添加到索引庫if(searchArticleVos!=null && searchArticleVos.size()>0){try {restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);} catch (IOException e) {e.printStackTrace();}}});}
}
3.4 xxl-admin新增任務
- 新增執行器 這里的appName要和XxlJobConfig 中的appname保持一致。也可以不用新增執行器,執行器就相當于一個分組的作用。

- 新增任務

4. 模擬集群,運行項目
- 運行3個SearchApplication項目,設置xxl.job.executor.port分別為9998,9997,9996
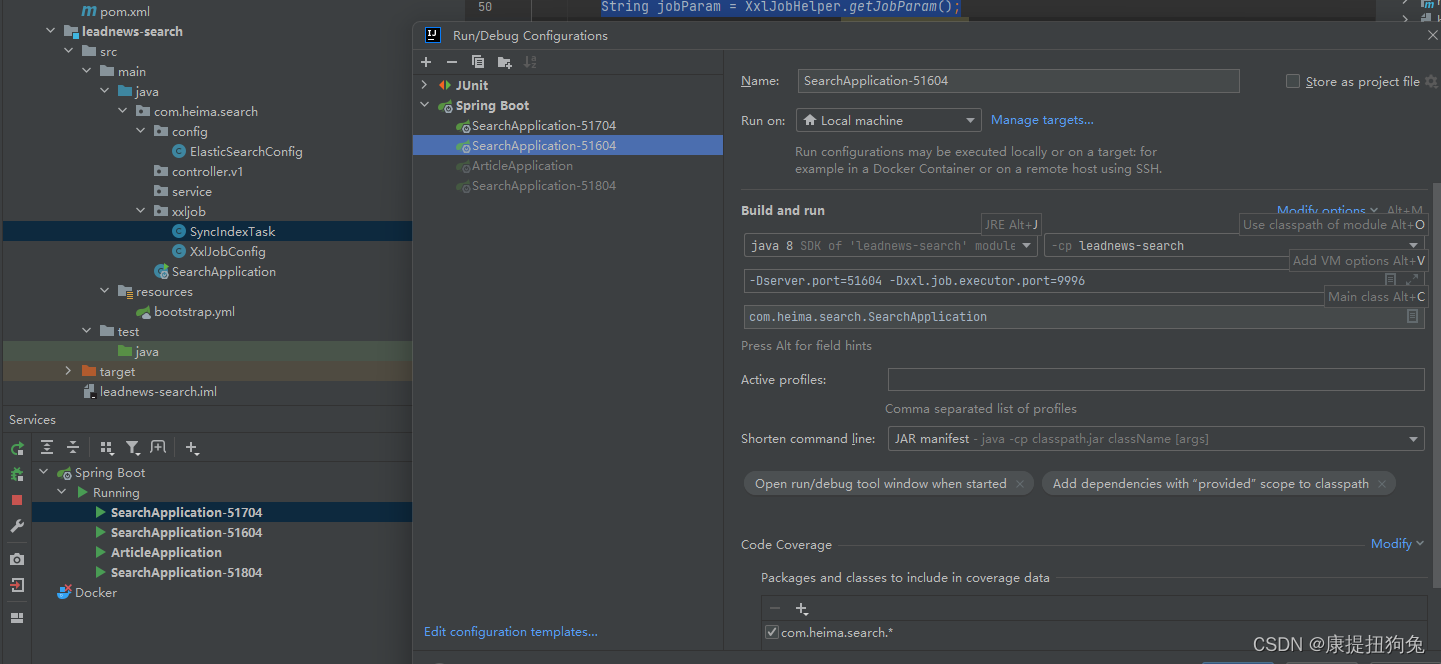
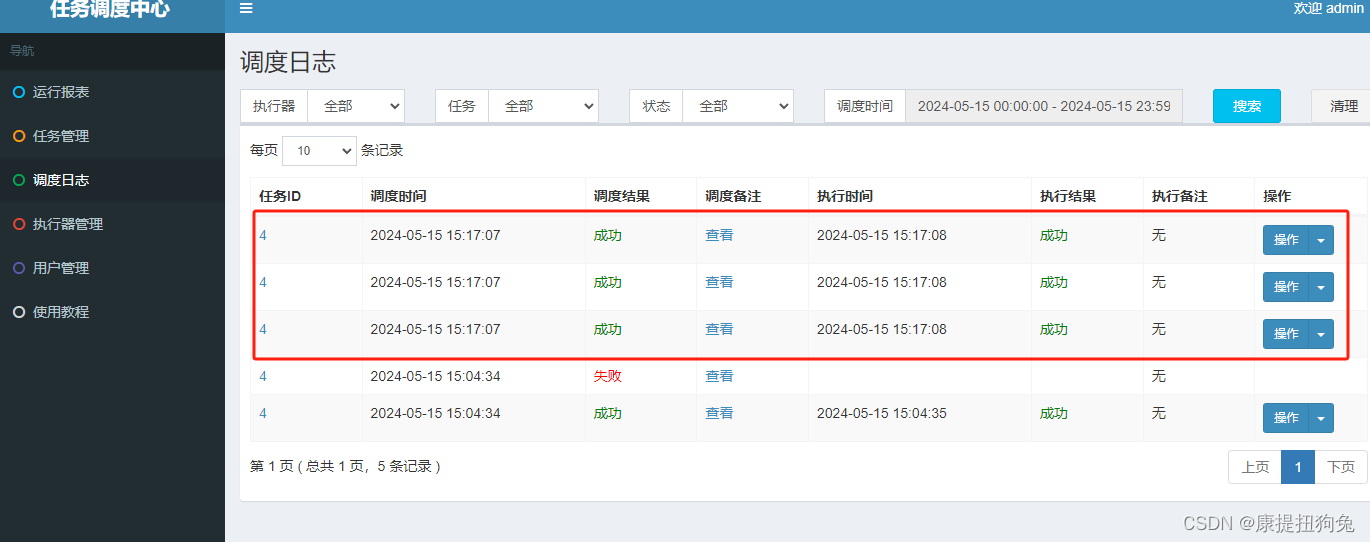
- 執行一次任務

- 查看結果,3個application都成功了
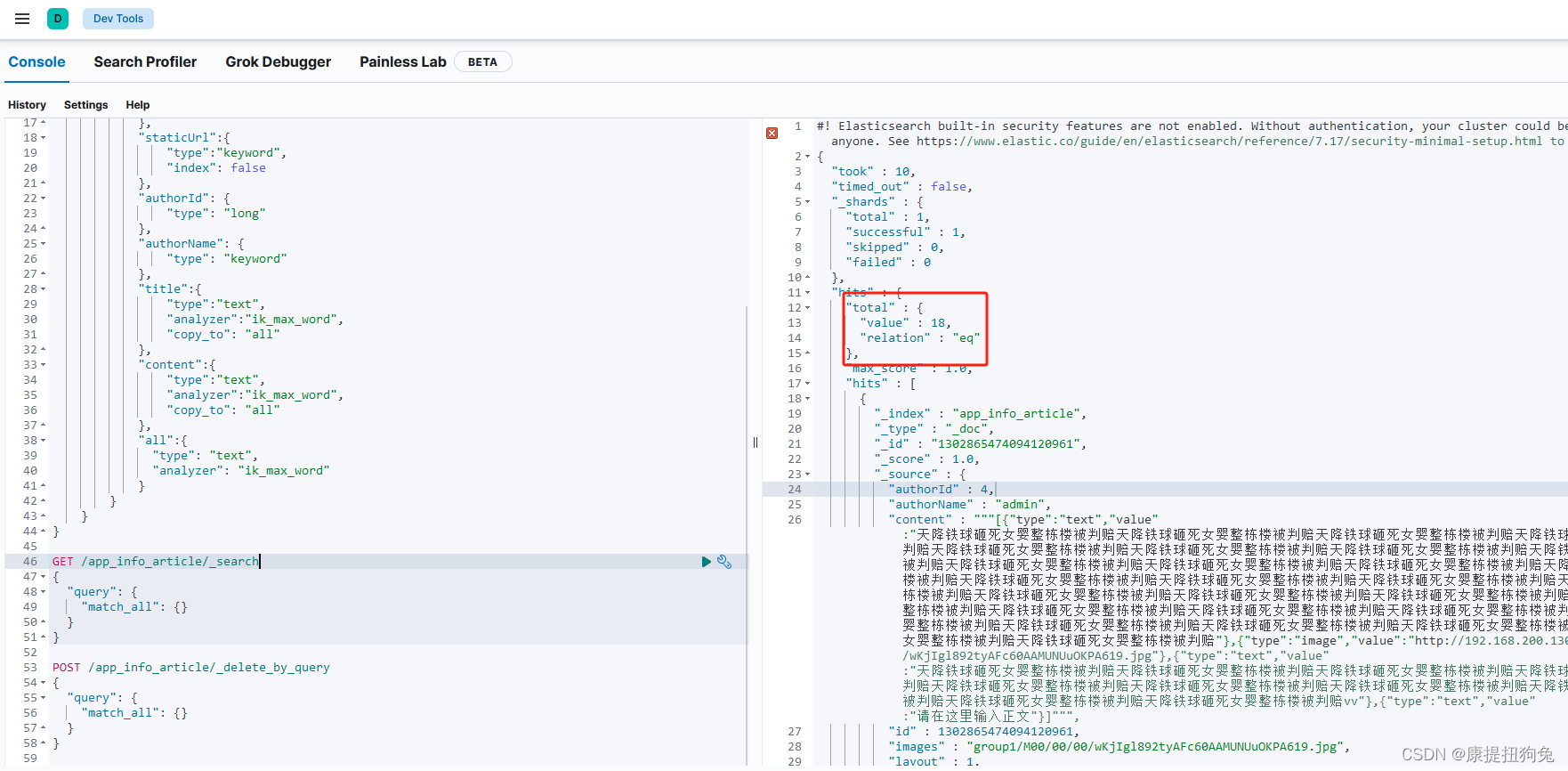
- kibana查看是否有數據,發現有18條,mysql的數據全部被導入了
5. 總結
-
xxljob分片廣播:假如一共有1000條數據,有3個節點上運行著SearchApplication服務。那么每個節點需要同步的數據總條數為334,334,332條。
-
分頁查詢:節點0的任務總條數為334條,那么需要做分頁(假設分頁size為20)查詢的次數為17次,每查1次后,將查到的數據通過restHighLevelClient發送到es中。
do {//5.1:分頁查詢//5.2:將數據導入ESpush(index,size,indexEnd); //分頁查詢+導入es的操作//5.3:是否要查詢下一頁 index+sizeindex = index+size;
}while (index<=indexEnd);
- 多線程:上述代碼,push方法包括了分頁查詢+導入es的操作,是低效的。并且push方法不結束的話,下一頁的操作不會開始。這里可以用多線程,每次push的時候都開啟一個新線程,這樣每一頁的操作都是獨立的,可以同時查詢,同時導入到es,不會互相影響。這里使用了線程池。
public static ExecutorService pool = Executors.newFixedThreadPool(10);
......
public void push(int index,int size,int indexEnd) {pool.execute(()->{//分頁查詢+導入到es});}
- elasticsearch的相關api:參考我另一篇博客 項目中使用Elasticsearch的API相關介紹
//2)創建BulkRequest - 刷新策略BulkRequest bulkRequest = new BulkRequest()//刷新策略-立即刷新.setRefreshPolicy(WriteRequest.RefreshPolicy.IMMEDIATE);for (SearchArticleVo searchArticleVo : searchArticleVos) {//A:創建XxxRequestIndexRequest indexRequest = new IndexRequest("app_info_article")//B:向XxxRequest封裝DSL語句數據.id(searchArticleVo.getId().toString()).source(com.alibaba.fastjson.JSON.toJSONString(searchArticleVo), XContentType.JSON);//3)將XxxRequest添加到BulkRequestbulkRequest.add(indexRequest);}//4)使用RestHighLevelClient將BulkRequest添加到索引庫if(searchArticleVos!=null && searchArticleVos.size()>0){try {restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);} catch (IOException e) {e.printStackTrace();}}








】)
:連接使用攝像頭)









