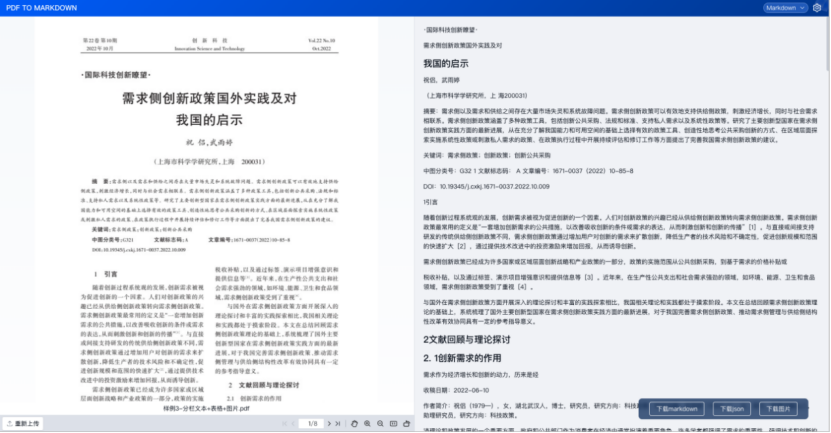
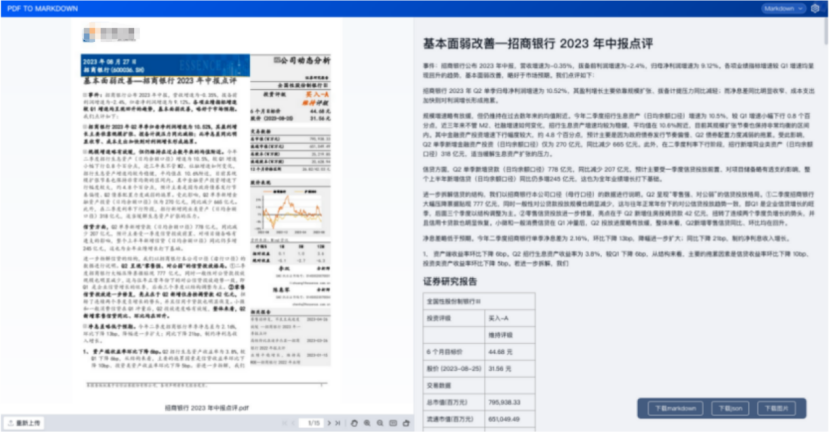
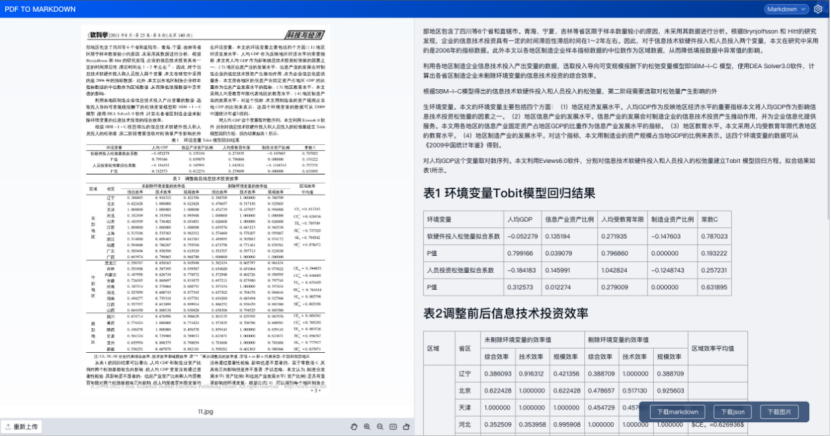
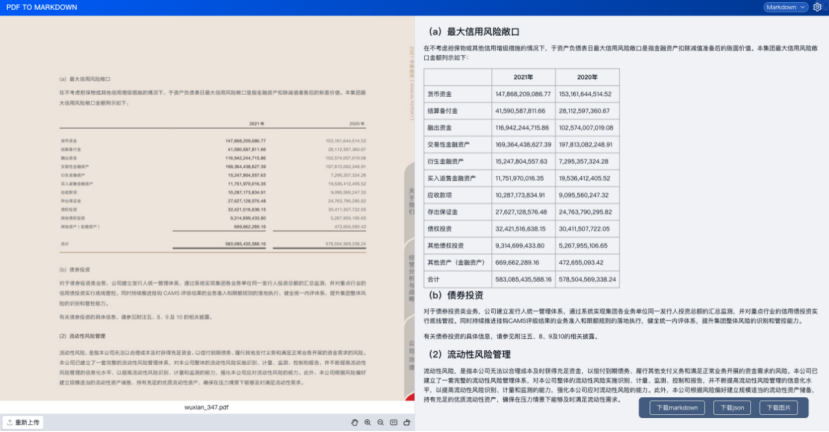
目錄
- 前言
- 1、TextIn文檔解析技術
- 1.1、文檔解析技術
- 1.2、目前存在的問題
- 1.2.1、不規則的文檔信息示例
- 1.3、合合信息的文檔解析
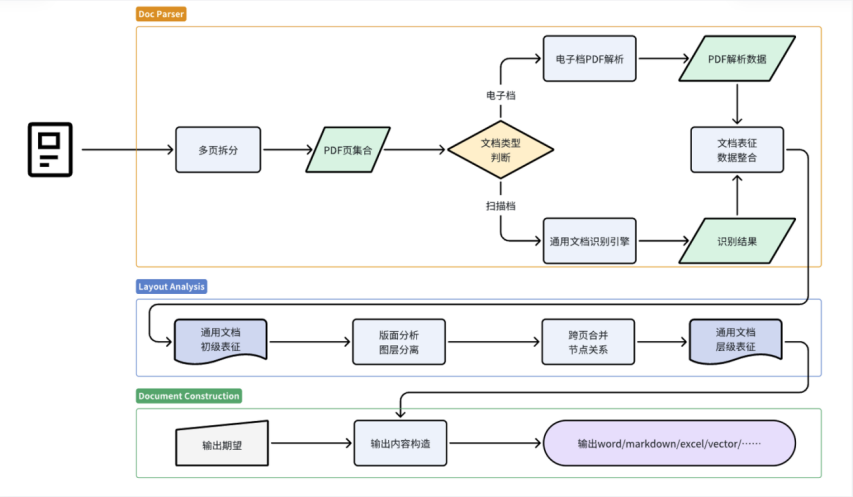
- 1.3.1、合合信息的TextIn文檔解析技術架構
- 1.3.2、版面分析關鍵技術 Layout-engine
- 1.3.3、文檔樹提取關鍵技術 Catalog-engine
- 1.3.4、雙欄
- 1.3.5、非對稱雙欄
- 1.3.6、雙欄+表格
- 1.3.7、無線表格
- 1.3.8、合并單元格表格
- 1.3.9、層級目錄
- 1.3.10、更高的文檔問答精度
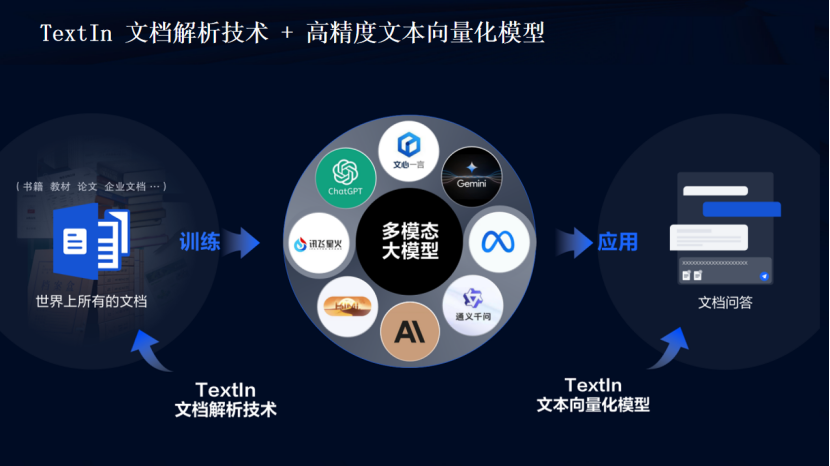
- 2、向量化技術
- 2.1、文本向量化模型
- 總結
前言

在人工智能時代,多模態大模型的發展不僅僅是技術創新的產物,它更是對人類交互和信息處理方式的一種模擬。我們的世界是多模態的:我們不僅閱讀文字,還觀察圖像,聆聽聲音,感受觸覺。多模態大模型試圖通過模擬這種豐富的信息處理方式來增強機器的理解能力。
這些模型的核心優勢在于它們的整合能力。傳統的單模態系統在處理單一類型數據時可能表現出色,但它們無法捕捉跨模態的復雜關系。例如,一段視頻內容不僅包含視覺元素,還可能包含重要的音頻信息,甚至是文字信息(如字幕或場景中的文本)。多模態大模型能夠綜合這些信息,提供更為全面的分析和理解。
多模態大模型在文檔處理平臺的應用實現了對復雜文檔內容的深層次理解和智能化處理。這些模型不僅能夠執行基本的文字識別任務,還能結合上下文信息,識別和解釋圖表、圖像中的數據和關系,甚至從視頻中提取關鍵信息。例如,當處理一個包含圖表和圖像的報告時,多模態模型可以識別圖表中的趨勢,將其與文本中的描述相匹配,從而提供一個綜合的內容概述。
1、TextIn文檔解析技術
1.1、文檔解析技術
文檔解析技術,主要是指提取非結構化的文檔內容中的關鍵信息,解析成結構化的數據。在多模態訓練中,不僅能提取文字信息,也能對視頻、音頻、表格等信息進行處理,同時還能結合上下文,識別和解析文字、圖片、音視頻等數據中的信息和關系。
1.2、目前存在的問題
目前多模態大模型賽道上有眾多著名公司在耕耘,普遍都存在一些問題。
- 速度慢,用戶在Gpt里提交一個200頁的文檔,結果需要等3-5分鐘,才能看到進度條走到底,這種體驗猶如手機開機要等5分鐘一樣恐怖和難受。
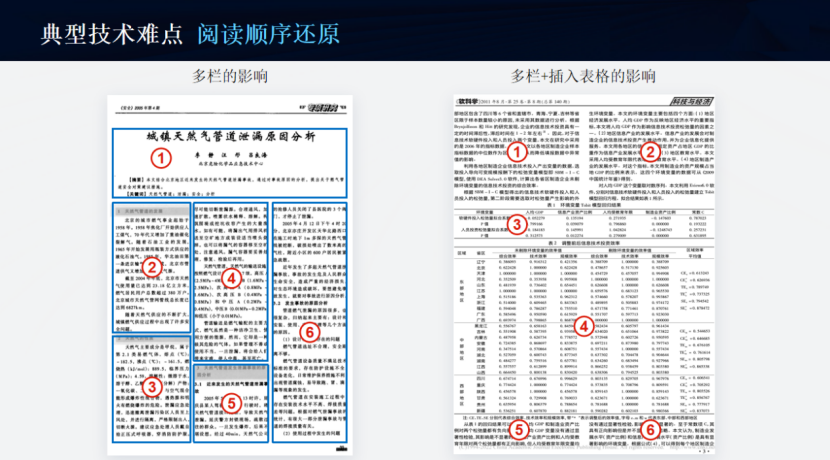
- 精度低,對于各種不規則表格、不規則排版版面、公式、圖像里文字識別不佳,最終出來的結果,與預期的相差甚遠。
- 兼容性差,對于繁雜的PDF編碼格式識別不佳,出現亂碼、丟字等情況。
1.2.1、不規則的文檔信息示例
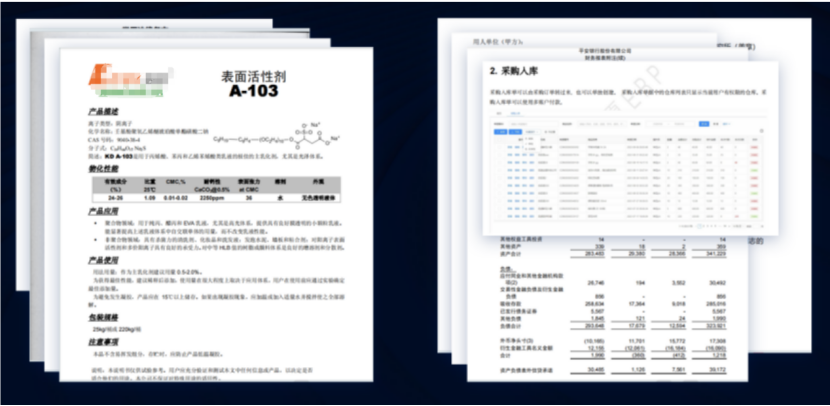

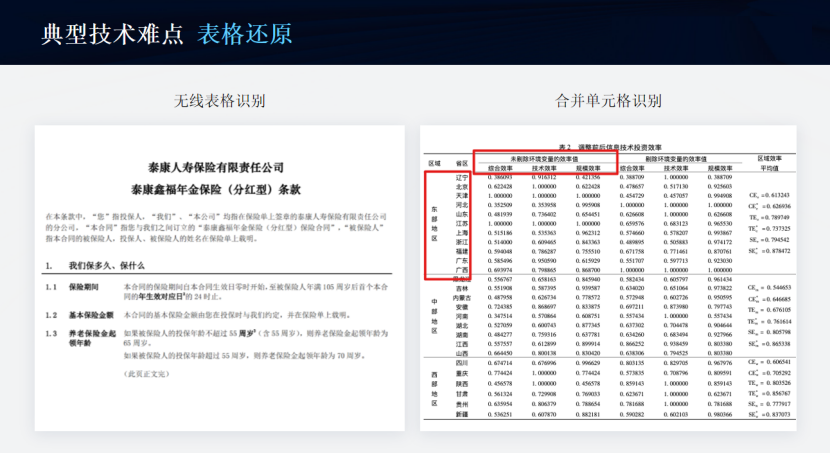

1.3、合合信息的文檔解析
最近也使用了一些PDF解析工具,其中合合信息在PDF文檔解析方面表現非常不錯。合合信息在智能文字處理領域積累了十幾年的經驗,可以說是文檔解析領域的先驅者和佼佼者。對比上述的一些問題,有了顯著的提升。
1.3.1、合合信息的TextIn文檔解析技術架構
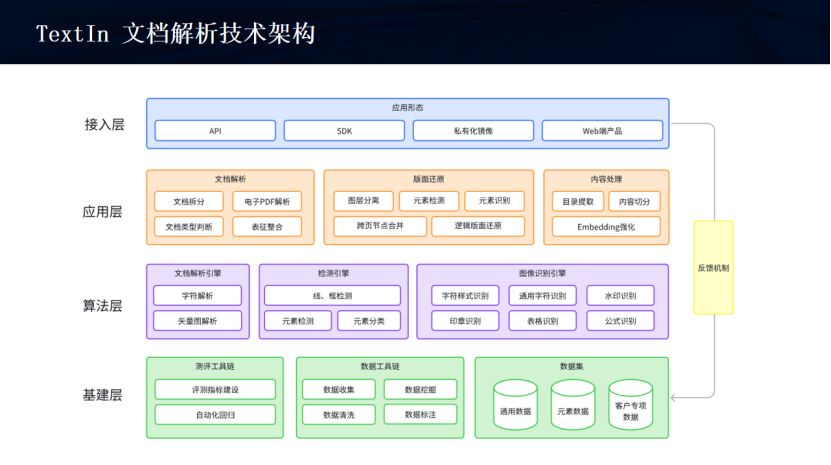
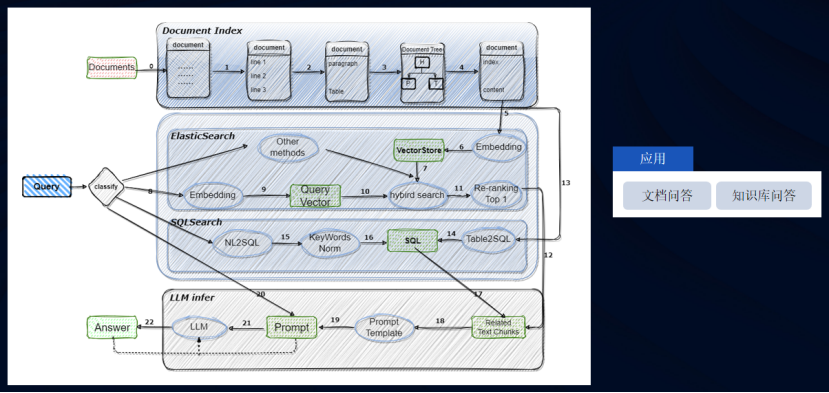
合合信息的TextIn文檔解析技術架構非常清晰完整,總體分為四層:接入層、應用層、算法層、基建層。
接入層面向不同的受眾,比如有技術在身的工程師通過API、SDK接入,提供HTTPS協議的API,也提供Java、go、nodejs等語言的SDK包。還有面向普通C端用戶的Web端產品,用戶可以在瀏覽器里使用合合信息的TextIn文檔解析工具。
應用層可以歸納為文檔解析、版面還原、內容處理三大類。
算法層可以歸納為文檔解析引擎、檢測引擎、圖像識別引擎。
基建層是上面的基石,包括有測評工具鏈、數據工具鏈、數據集等。同時接入層也提供反饋機制,可以反饋修改意見給數據集。
下面讓我們來看下合合信息的文檔解析表現。
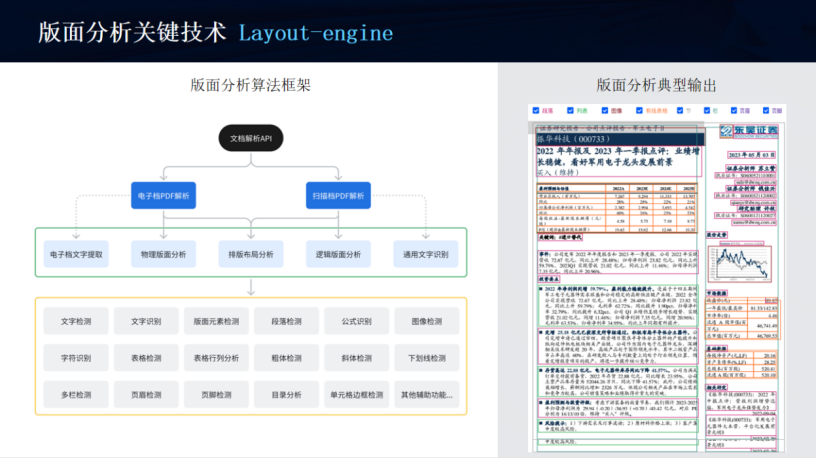
1.3.2、版面分析關鍵技術 Layout-engine
1.3.3、文檔樹提取關鍵技術 Catalog-engine

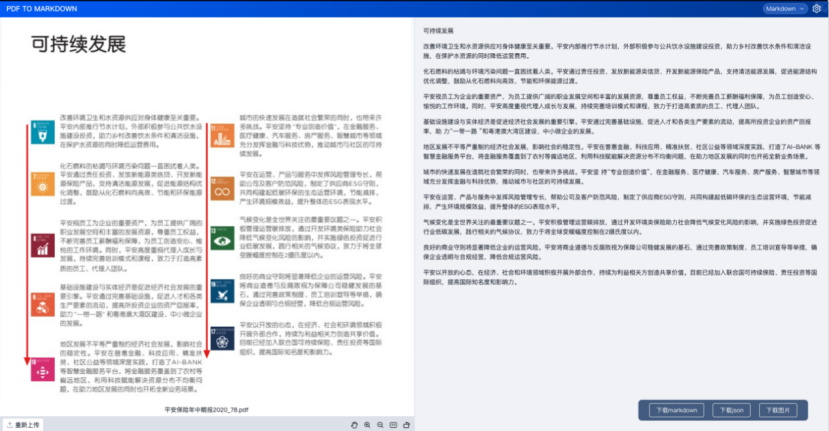
1.3.4、雙欄
1.3.5、非對稱雙欄
1.3.6、雙欄+表格
1.3.7、無線表格
1.3.8、合并單元格表格
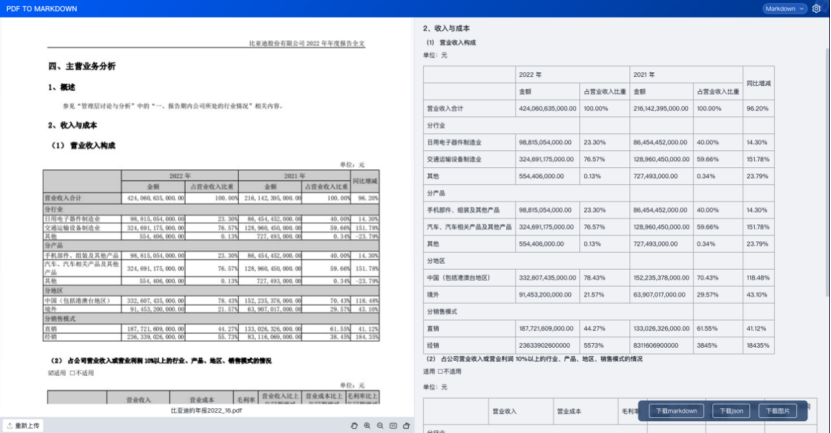
1.3.9、層級目錄
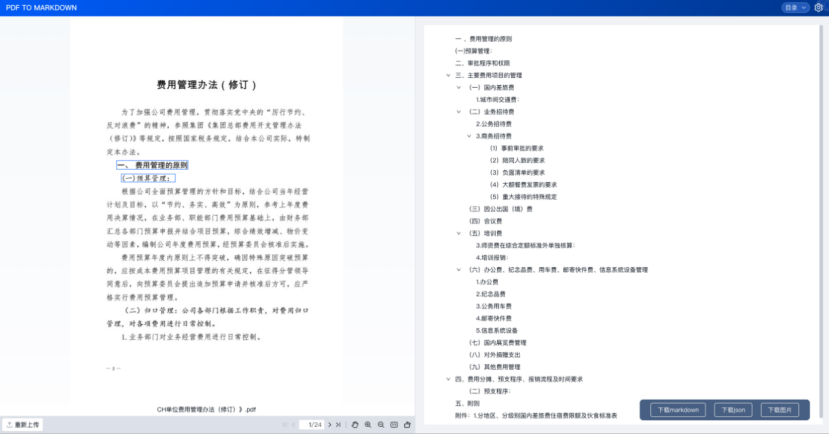
1.3.10、更高的文檔問答精度
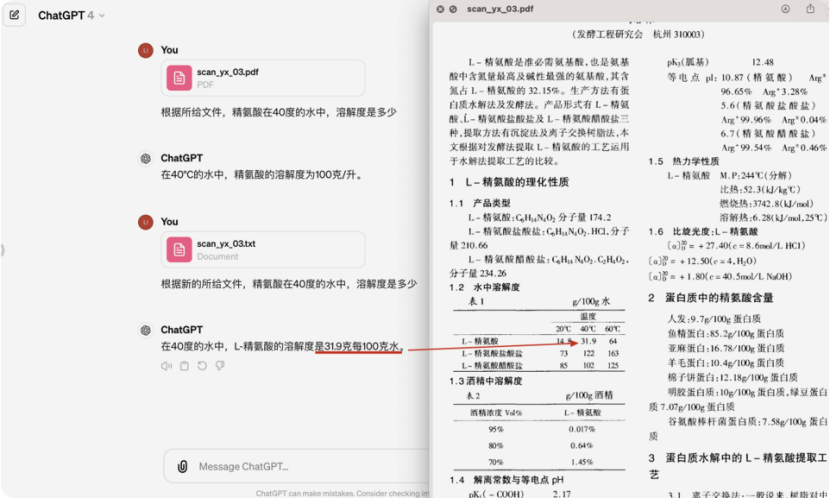
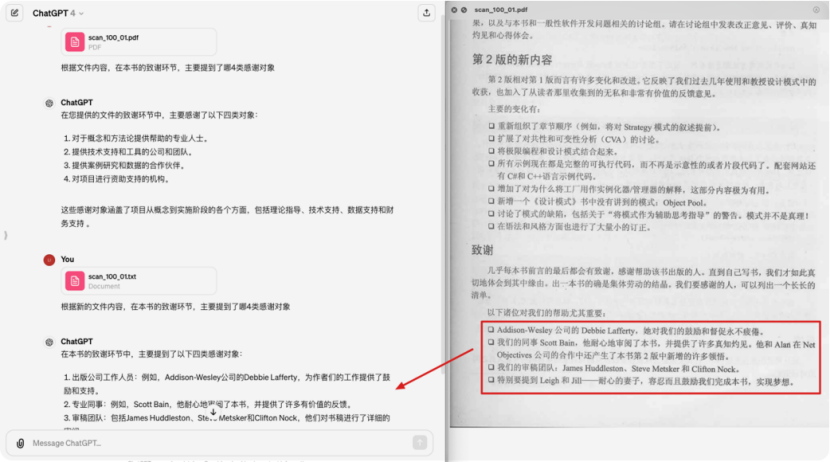
2、向量化技術
文本向量化是自然語言處理的基石,它涉及將文本數據轉換為數值向量的過程,以便計算機能夠處理。如詞袋模型和TF-IDF、詞嵌入技術如Word2Vec和GloVe、ELMo、BERT和GPT等模型,都能將文本數據轉換為數值向量。
在大模型中,文本向量化變得更加復雜和強大。這些模型通常通過大規模預訓練,學習豐富的語言表示,然后可以通過微調(fine-tuning)來適應特定的任務。尤其是基于Transformer的模型,它們通過自注意力機制處理文本,能夠捕捉長距離的依賴關系,為文本提供動態的上下文相關表示。
2.1、文本向量化模型
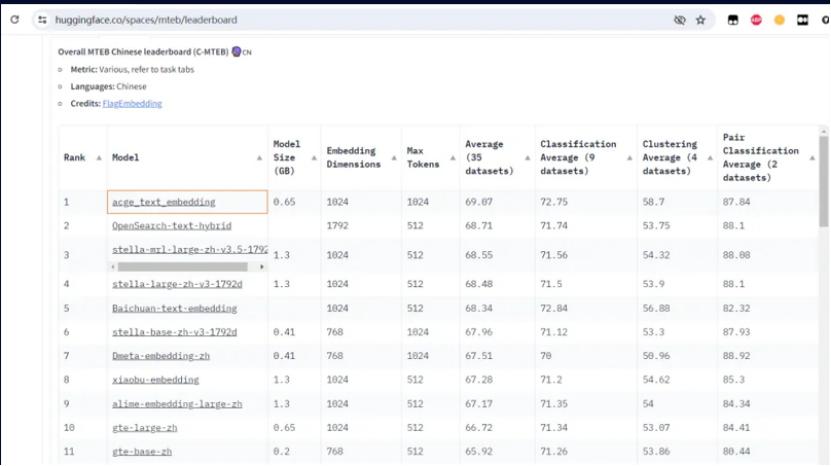
合合信息發布的文本向量化模型acge_text_embedding,簡稱“acge模型”,在MTEB中文榜單(C-MTEB)上取得第一的成績,這一成就標志著在中文文本向量化領域的一個重要突破。MTEB(Multilingual Text Embedding Benchmark)是一個多語言文本嵌入基準測試,旨在評估不同模型在多項語言理解任務上的性能。ACGE模型在C-MTEB榜單上的優異表現,表明了它在理解中文語義和語用特征方面的強大能力。
總結
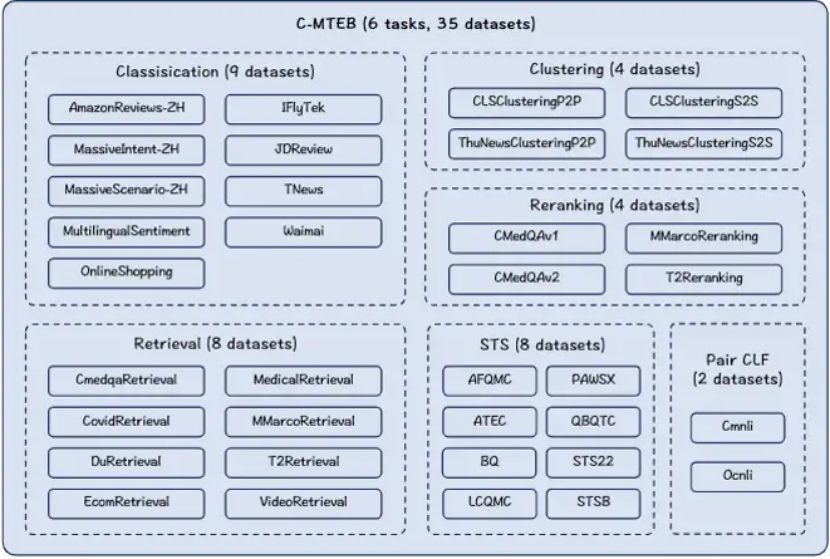
文檔解析與向量化技術加速了多模態大模型訓練與應用,在MTEB(C-MTEB)榜單上我們可以看到各種模型,在分類、聚類、檢索、排序、文本相似度方面的表現都越來越優異。
這些技術的發展,尤其是acge模型在中文領域的優秀變現,使得合合信息在PDF文檔解析方面得到了很好的結果。
- 速度快,合合信息的文檔解析工具在解析一個幾百頁PDF文件的耗時通常都在秒級。對于C端用戶而言,通常都是能夠接受的。
- 【1.3】中我們對于各類版面元素都做了識別,效果還是很不錯的。不管是公式、表格、還是相對復雜的排版,都能正確理解并準確還原。
- 兼容性好,我們在演示的各種繁雜文檔時,都沒有出現亂碼、大量丟字等現象。
合合信息是一家深耕智能文字識別、商業大數據領域的老牌公司,他們有在C端深受全球用戶喜愛的效率工具產品:掃描全能王、名片全能王、啟信寶。在B端也有AI+大數據賦能數字化轉型服務:TextIn智能文字識別產品、“啟信慧眼”風控營銷SaaS、“啟信天元”大數據應用平臺。
朋友們可以通過訪問合合信息旗下的TextIn的官方網站來親自體驗一下哦。歡迎來探秘,更有驚喜【免費使用】等著你,https://www.textin.com/?from=qinghuasuo





】)
:連接使用攝像頭)












