為了減少數據分布的不平衡,提供高樣本的代表性,可將數據按特征分層一定的層次,在每個層次抽取一定量的樣本,為分層抽樣。分層抽樣的特點是將科學分組法與抽樣法結合在一起,分組減小了各抽樣層變異性的影響,抽樣保證了所抽取的樣本具有足夠的代表性。
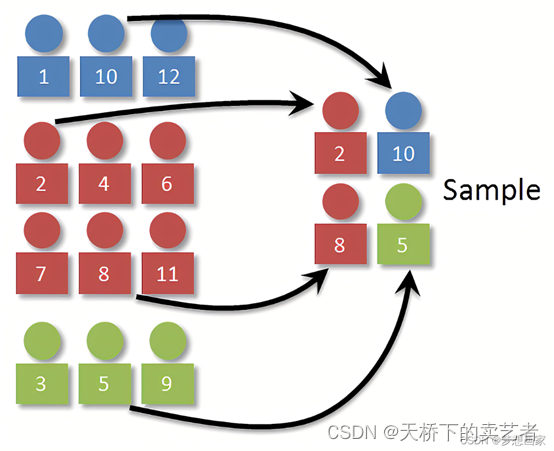
既往咱們已經多篇文章介紹了R語言的隨機抽樣,今天咱們通過R語言的2種方法來介紹隨機分層抽樣。咱們先導入數據和R包,首先介紹的是sampling包,
library(sampling)
bc<-read.csv("E:/r/test/demo.csv",sep=',',header=TRUE)
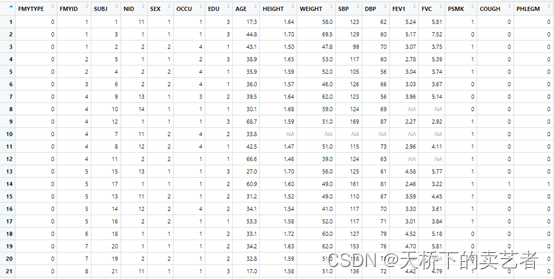
這是個體檢相關的數據,公眾號回復:體檢數據,可以獲得這個數據。這個數據的變量我就不解釋了,SEX:性別,我們等下就根據性別分層來隨機抽樣。用到的是strata函數,我們來看下函數的格式
strata(data, stratanames=NULL, size, method=c("srswor","srswr","poisson",
"systematic"), pik,description=FALSE)
其實用起來非常簡單哈,data就是你的數據,strataname就是你分層的變量名字,我們這里當然是SEX性別啦,size就是你抽取的數量,method是抽取的方法,有不替換的簡單隨機抽樣(srswr)、替換的簡單隨意抽樣(srswr)、泊松抽樣(Poisson)、系統抽樣(systematic sampling);如果缺少“method”,則默認方法為“srswork”。
下面咱們就來實現一下,假設咱們想男女等比例抽取60%的樣本來建模,首先咱們需要小小計算一下
n=round(3/5*nrow(bc)/2)

男女需要分別抽取250例
sub_train=strata(bc,stratanames=("SEX"),size=c(250,250),method="srswor")
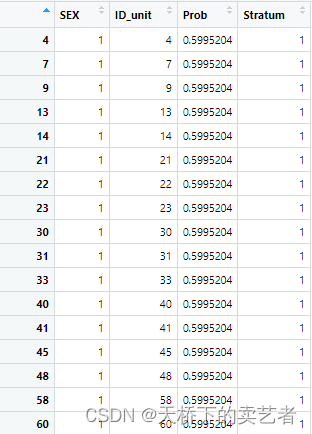
這樣一句話就抽取好啦,咱們來看一下,確實都是抽取了250個
table(sub_train$SEX)

也可以不等比例抽取,假設我想男性抽190個,女性抽100個
sub_train1=strata(bc,stratanames=("SEX"),size=c(190,100),method="srswor")
table(sub_train1$SEX)

如果要提取數據,需要使用ID_unit這個變量,這是數據的標識,咱們通常會把分層抽樣的數據用來建模,其余的數據用來驗證。
data_train=bc[sub_train$ID_unit,]
data_test=bc[-sub_train$ID_unit,]
這樣數據就提取出來啊,非常簡單。
接下來介紹的是dplyr包因為跑的是通道,也是非常簡單
library(dplyr)
每組抽取固定數量250個
strat <- bc %>% group_by(SEX) %>% slice_sample(n = 250)
每組抽取一定比例
strat1 <- bc %>% group_by(SEX) %>% slice_sample(prop = .50)
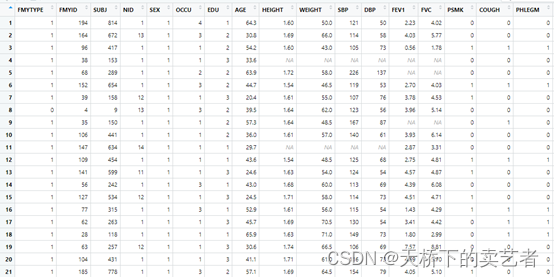
Dplyr包是直接提取出了數據,不用你再提取啦。
本期結束啦,祝大家五一勞動節快樂!
參考文獻:
- sampling包文檔
- dplyr包文檔
- https://blog.csdn.net/neweastsun/article/details/122395968
- https://blog.csdn.net/claroja/article/details/55096431

)
)












與os.scandir())



—封裝頭部導航組件)