名詞解釋
1.特征重建
特征重建是一種機器學習中常用的技術,通常用于自監督學習或無監督學習任務。在特征重建中,模型被要求將輸入數據經過編碼器(encoder)轉換成某種表示,然后再經過解碼器(decoder)將這種表示轉換回原始的輸入數據。
具體來說,特征重建的過程通常分為以下幾個步驟:
1.編碼(Encoding): 輸入數據經過編碼器,被映射到一個低維度的表示空間中,這個表示通常稱為特征向量或隱藏表示。
2.重建(Reconstruction): 編碼后的特征向量再經過解碼器,被映射回原始的輸入空間,嘗試重建原始輸入數據。
3.損失計算(Loss Computation): 通過比較重建數據與原始數據之間的差異,計算出重建誤差或損失值。
4.優化(Optimization): 模型被訓練以最小化重建誤差,通過調整編碼器和解碼器的參數來提高重建的準確性。
在自監督學習中,通常使用無標簽的數據來進行特征重建,因此模型必須依靠數據本身來學習如何有效地表示和重建輸入。這樣做的好處在于可以在本身是無監督的任務中,圖片本身自己去學習自己的有用表示,有助于提取圖片中的關鍵信息,從而提高后續任務的性能。因為往常的視頻分割任務通常都會有人工標注的昂貴的注釋集,而本文應用特征重建是由于語義的異質性,邊界處的幀很難重建(通常具有較大的重建誤差),這有利于事件邊界檢測(這樣就能很容易檢測出邊界)。
2.語義視覺表示
語義視覺表示是指通過計算機視覺技術將圖像或視頻數據轉換為具有語義含義的向量或特征表示。這種表示捕捉了圖像或視頻中物體、場景和動作等高級概念的語義信息,而不僅僅是低級的像素值或幾何特征。
在語義視覺表示中,模型通常會學習到與物體類別、場景描述或動作等相關的特征,這些特征具有更高層次的抽象性,能夠更好地反映數據的語義內容。這種表示有助于計算機理解圖像或視頻,并支持各種計算機視覺任務,如物體識別、場景理解、行為分析等。
語義視覺表示的生成可以通過多種方式實現,包括傳統的手工設計特征提取器、基于深度學習的端到端表示學習方法以及結合語義信息的生成式模型等。隨著深度學習技術的發展,基于深度神經網絡的方法已經成為生成語義視覺表示的主流方法之一,這些方法可以在大規模數據集上進行端到端的訓練,從而學習到更加豐富和高效的語義表示。
總的來說,語義視覺表示是計算機視覺領域中一種重要的數據表示形式,它將圖像或視頻轉換為具有語義含義的向量表示,為各種視覺任務提供了有力支持。
3.特征空間和像素空間
特征空間和像素空間是在計算機視覺和機器學習中經常提到的兩個概念,它們描述了數據在不同層次上的表示方式和表達內容的不同。
1.像素空間:
在像素空間中,圖像被表示為一個由像素組成的矩陣,每個像素包含有關圖像中某個位置的顏色或灰度信息。像素空間是圖像的原始表示形式,它反映了圖像中每個位置的具體像素值,通常是RGB顏色空間中的值或灰度值。像素空間中的操作通常是基于像素級別的,例如圖像增強、濾波、邊緣檢測等處理都是直接在像素空間上進行的。
2.特征空間:
在特征空間中,圖像被表示為一組抽象的特征向量或特征表示,這些特征捕捉了圖像中的語義信息和高級結構。特征空間中的特征通常是通過特征提取器或深度神經網絡從原始圖像中學習得到的,它們可能表示物體、場景、紋理等高級概念。特征空間的表示更加抽象和語義化,它能夠更好地捕捉到圖像的語義內容,而不僅僅是像素級別的細節。在特征空間中進行的操作通常是基于特征級別的,例如特征重建、特征匹配、語義分割等處理都是在特征空間上進行的。
總的來說,像素空間和特征空間代表了數據在不同層次上的表達方式,像素空間更接近于原始數據的表示,而特征空間則更加抽象和語義化,能夠捕捉到數據的高級結構和語義信息。個人理解就是,像素空間就是一張圖片的原始矩陣,原始矩陣經過卷積等操作后被轉為特征圖,特征圖代表的語義信息 更豐富更抽象,之后特征重建是在特征圖上重建的。
框架
1.Contrastive Temporal Feature Embedding(CTFE)
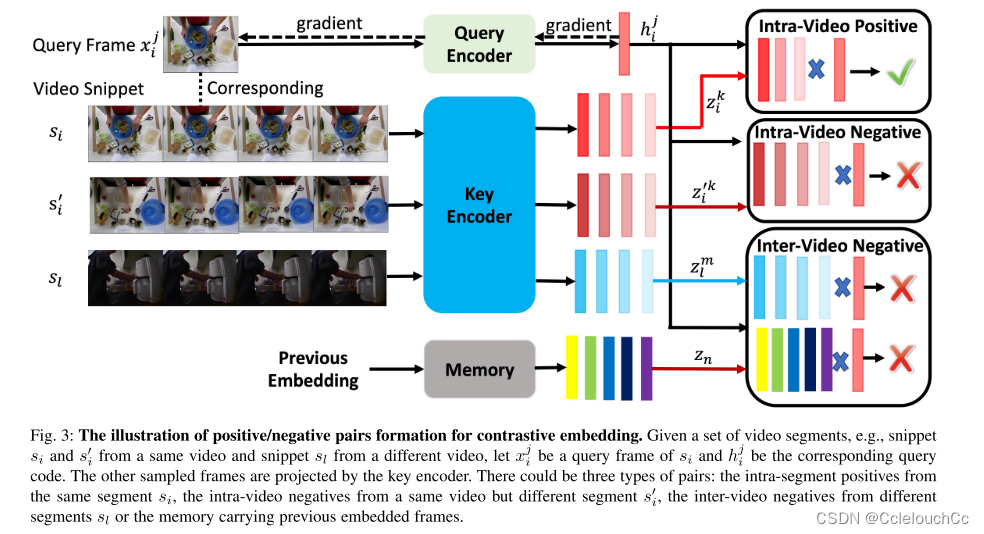
通常,視頻事件由語義相關的幀的序列組成。也就是說,相鄰幀比以長時間間隔采樣的幀更可能在語義上相似。根據這一觀察,我們提出了一個對比時間特征嵌入方案來學習一個有區別的幀表示。從本質上講,它將語義相似的框架投射得更近,而將不相似的框架推開。通過比較,利用這種學習,我們的框架將幀轉換為一種新的表示,在語義上更容易區分。如圖3所示,對比學習的正對由段內幀組成,而負對來自來自相同或其他視頻的其他片段的段間幀,或存儲器中的幀。
總體思路為選取B個視頻,在每個視頻里選擇X個片段(片段幀數為T)。以圖3為例:共選取了視頻的三個片段,S(i)、S’(j)是同一個視頻的不同片段,S(l)是別的視頻的一個片段。首先,取S(i)中的一幀作為查詢鍵Q,其他片段的一幀作為被查詢鍵K,接下來,我們形成與查詢xj i相關聯的三種類型的否定對:1)視頻內否定對:否定幀來自相同的視頻,但來自不同的片段,即X’(j)的幀。2)視頻間負對:負幀選自從不同視頻提取的任何片段,即X(l)的幀。3)存儲器負對:負幀來自在先前迭代期間嵌入在存儲器中的幀。然后,將兩幀進行對比學習,來判斷它們是正樣本還是負樣本,圖3表示的是Q與K來自于同一個視頻的正樣本。
利用這種學習,我們的框架將幀轉換為一種新的表示,在語義上更容易區分。這對本質上是二分類的任務是友好的。
Frame Feature Reconstruction (FFR)
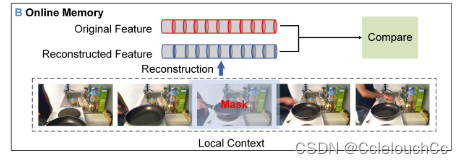
如我們所知,視頻事件之間的過渡幀通常是不一致的,因此較難預測。因此,我們開發了一種無監督的特征重建方法來檢測這些事件的邊界,因為我們推測,邊界幀通常比非邊界幀具有更高的重建誤差。然而,與之前的像素級圖像重建不同,我們的幀重建是在高級語義特征空間中進行的。也就是說,我們的方法旨在重建由CTFE訓練的框架的語義表示。
為了從H0(t)重構掩蔽的特征向量,我們修改了Transformer編碼器的多頭注意部分。具體來說,我們采用2層多頭自注意(MSA)和多層感知器(MLP)塊來處理H0,同時隨機將掩碼M(t)應用于第t個特征嵌入。重構模塊的第l層的輸出被定義為
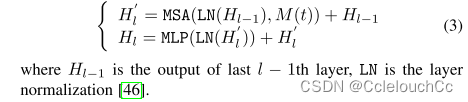
重構模塊的第l層的輸出可以用如下方式定義:已知l層的輸入來自于l-1層的輸出
參數為掩掉的某一幀M(t)和l-1層的輸出H(l-1),首先對M(t)和H(l-1)進行層歸一化,保證訓練穩定,再經過多頭注意力機制計算得到具有時間上下文的語義信息,再和上一層輸出相加后經過多層感知機輸出。
整體框架
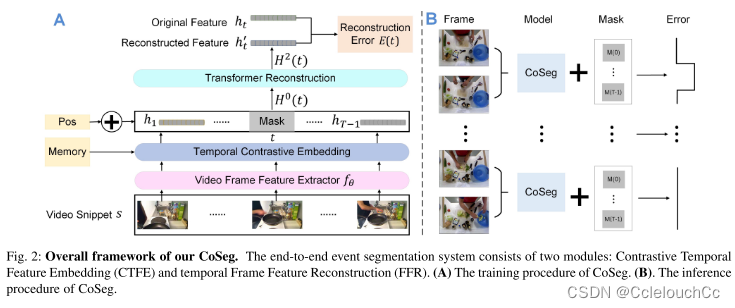
A:train
1.視頻片段經過特征提取網絡變成特征圖。
2.CTFE模塊對特征圖進行處理,得到更高級的表示。
3.經過CTFE得到的表示送入FFR模塊,進行特征重建,得到重建后的特征。
4.重建后的特征圖與原特征圖進行比較,特征重建是由于語義的異質性,邊界處的幀很難重建(通常具有較大的重建誤差),這有利于事件邊界檢測(這樣就能很容易檢測出邊界)。
B:test
將視頻幀送入模型,再逐個地對每一幀進行掩碼,從而重建所有幀的特征,與原特征進行比較后有兩種結果,一種是上半部構建錯誤,即檢測到邊界幀,另一種是下半部構建成功,即無邊界幀。
)











)

)


)

