前言
對于ai訓練來說,處理訓練集是模型訓練的重要環節。訓練集的質量對最終模型的質量影響巨大。這里以二次元角色為例,記錄下訓練集處理的流程和一些心得。
素材準備
素材準備有以下幾個需要注意的點:
- 通常訓練二次元角色需要30張以上的圖片,訓練三次元角色需要50張以上的圖片。原因是三次元圖像里面包含的細節更多。
- 訓練集最關鍵的是“質”而不是“量”。單純堆圖片數量并不能保證好的訓練效果。
- 訓練集圖片需要保證圖片中僅包含訓練角色一個人物,其他人物需要裁剪掉。
- 訓練集圖片中人物盡可能包含不同的角度,動作,服飾,風格。
- 訓練集圖片中一些有負面影響的元素需要適當刪改掉,比如文字,水印等。不好處理可以涂抹掉。
素材裁剪
stable diffusion常用的模型是基于SD1.5的,建議尺寸不要高于768,不小于512。尺寸過大對于顯存的要求會很高。

素材裁剪可以使用【分割過大的圖像】,重疊比例可以適當調高,這樣裁剪出來的圖像更多,更適合挑選。
素材打標
素材打標通常是先自動打標,再根據一定的規則進行手動刪改。
自動打標
自動打標可以使用WD1.4反推工具。
簡單介紹WD1.4的用法
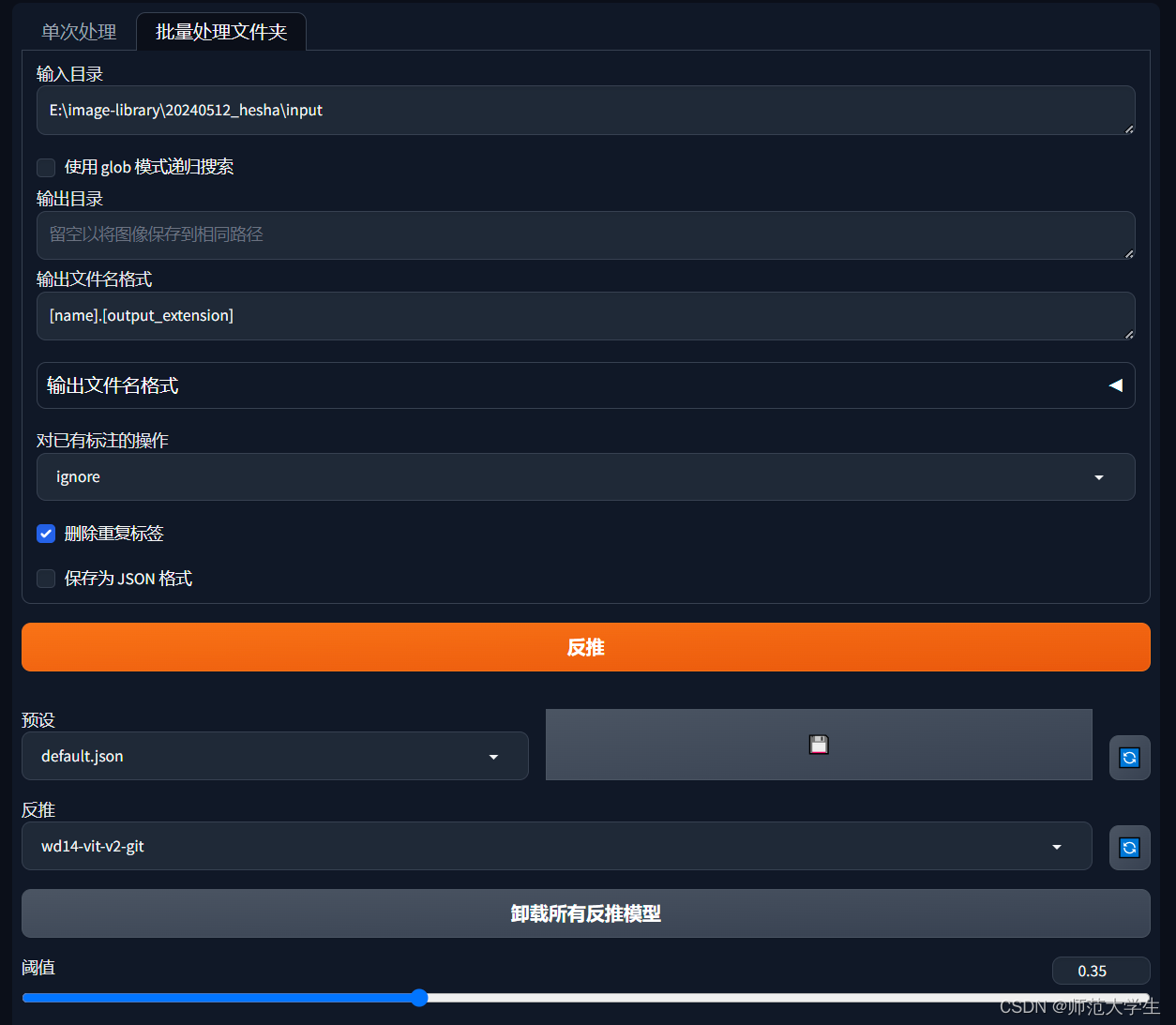
單次處理和批量處理的原理是一樣的。這里主要涉及兩個概念,反推模型與閾值。
反推模型:反推模型的作用是將一幅圖片的提示詞推理出來,推薦反推模型中的wd14-vit-v2-git、wd14-convnextv2-v2-git和wd14-swinv2-v2-git,其中wd14-vit-v2-git最快,wd14-swinv2-v2-git最準確。
閾值:低于閾值則刪除這個關鍵詞,三次元建議0.35,二次元動漫人物建議0.5。
標簽修改
自動打標的標簽可以直接使用,但是通常我們會基于自身需求對TAG做一些刪改。刪改的原則如下:
- 自動打標識別出的角色詞要刪除,比如“野比大雄”這種。保留自動打標的角色詞會導致生成圖片的時候,會觸發大模型(底模型)里的提示詞,進而調用大模型里面的特征。
- 不想讓模型訓練到的特征建議保留。比如一個角色在很多圖片里面都握著一把劍,但是我不想生成圖片時該角色默認擁有“持劍”的特征,所以,類似于“holding weapon”,“sword”這種提示詞建議保留。
- 希望讓模型訓練到的特征建議刪除。比如一個角色是黑頭發,戴著眼鏡。我希望生成圖片時該角色默認就是黑頭發和戴眼鏡,我不會調整他的發色或者不戴眼鏡。所以,“black hair”,“wearing glasses”這種提示詞建議刪除。當然這樣的操作有優點也有缺點。優點是減少了必要的提示詞數量;缺點是降低了模型的泛化性,在上文提到的場景中,如果我在生成圖片時額外設置提示詞“green hair”,可能效果不明顯,因為“黑頭發”這個特征已經被該模型學習到了。
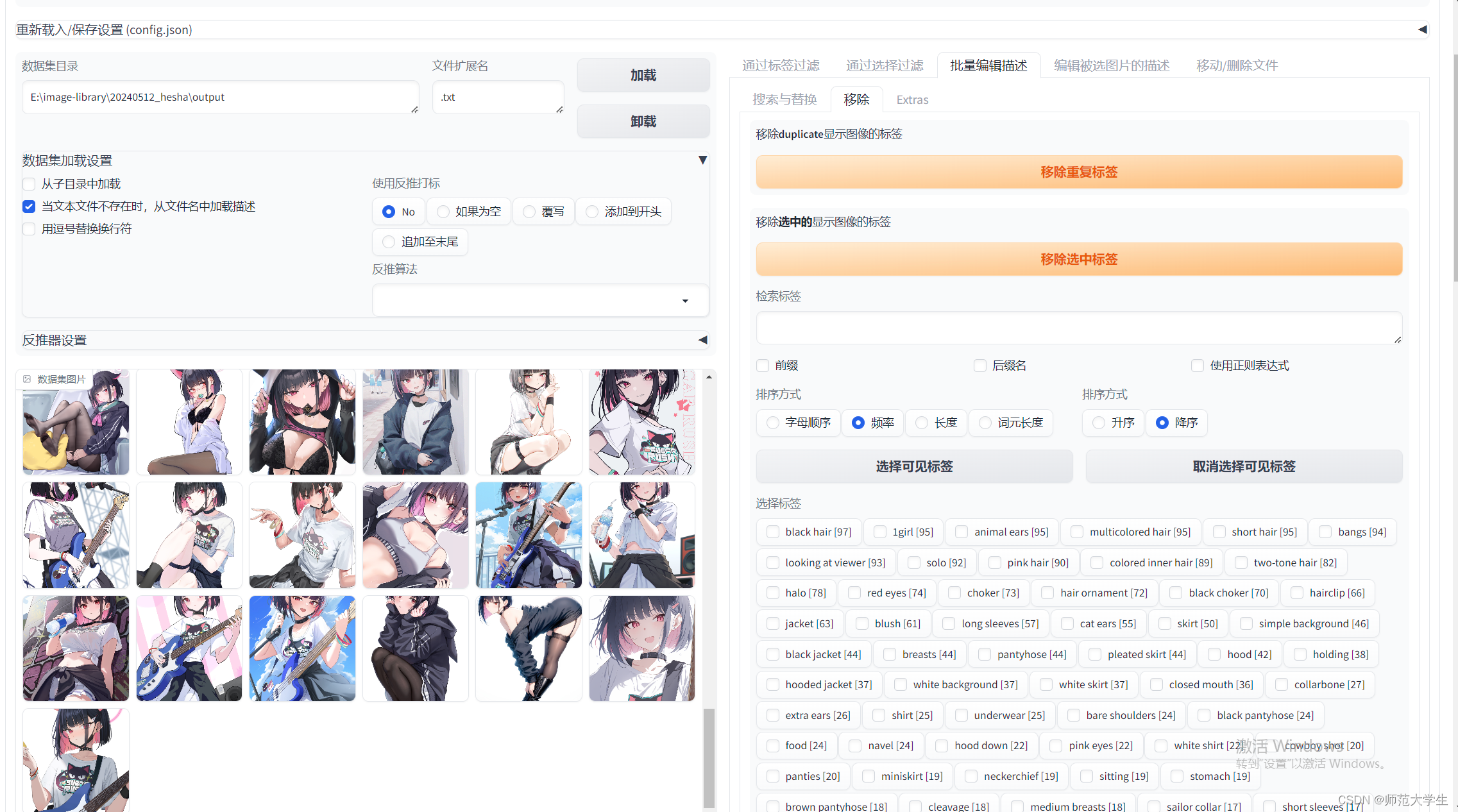
標簽編輯器如上圖所示。在批量編輯描述中,可以選擇特定的TAG進行刪除。
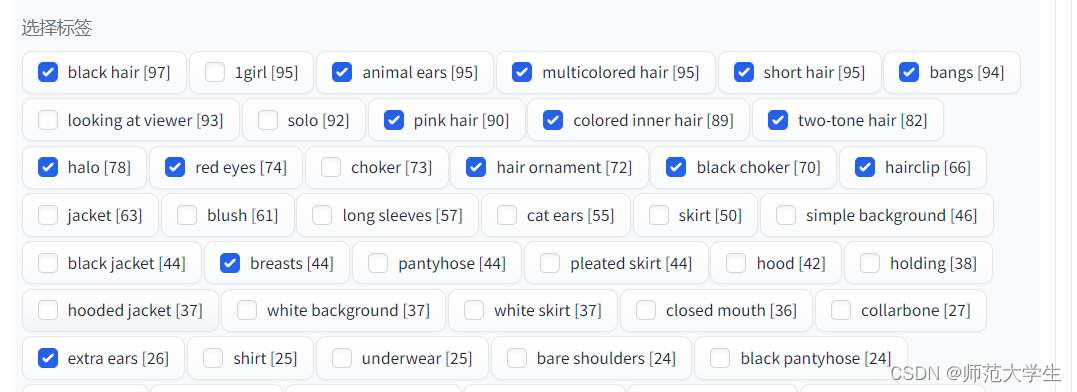
比如這次訓練的一個角色,我將她的固有特征TAG進行刪除,這樣就可以讓模型學習到這些特征,比如“短發”,“獸耳”,“紅眼”。因為這些特征希望生成圖片時默認存在。
衣服,動作,表情之類的TAG全部進行了保留,這樣用提示詞為人物更換衣服,動作,表情效果會更明顯。
修改完后點擊保存所有更改,并在文件夾中刪除所有的過程文件即可。

8*8點陣屏)







:is out of date)

)
QUERY EXECUTION)
)
)

)


)