作者:周弘懿(錦琛)
背景
跟?ChatGPT?對話,比跟真人社交還累!真人好歹能記住你名字吧?
想象一下——你昨天剛把沙發位置、爆米花口味、愛看的電影都告訴了?ChatGPT,而它永遠是那個熱情又健忘的助理,下次再對話還是會問:“哦?是嗎?那太好了!請問您對什么類型的電影感興趣呢?”
受夠了這種單方面的“社牛”表演?Mem0?來了,專治?AI?失憶癥,給你的“金魚腦”助理裝個大容量硬盤,讓你們下次見面,能直接跳過多余的問答,從“好久不見”開始。
Mem0介紹
Mem0是為?AI?智能體開發打造的記憶層。它就像一個持久的“大腦”,能幫助?AI?智能體完成以下內容:
-
隨時調取歷史對話,追溯關鍵信息
-
精準記住用戶的個人偏好與重要事實
-
在實踐中總結經驗,不斷自我完善
git地址:https://github.com/mem0ai/mem0
記憶層的作用
如下圖所示,無記憶層的情況下,即使LLM有超大的上下文窗口的情況下,再開一個新會話后上下文都會被重置。有記憶層Mem0的情況下,將保留上下文,召回需要的內容,并持續優化自身存儲。

記憶層在AI 智能體開發中的作用
如下圖所示,Mem0?會與檢索器(RAG)、LLM?、上下文并肩工作。與傳統的基于檢索的系統(如?RAG)不同,Mem0?會記錄過往交互、保存長期知識,并讓智能體的行為隨時間而進化。僅會將記憶中相關的知識合并到prompt之中,輸入給LLM。
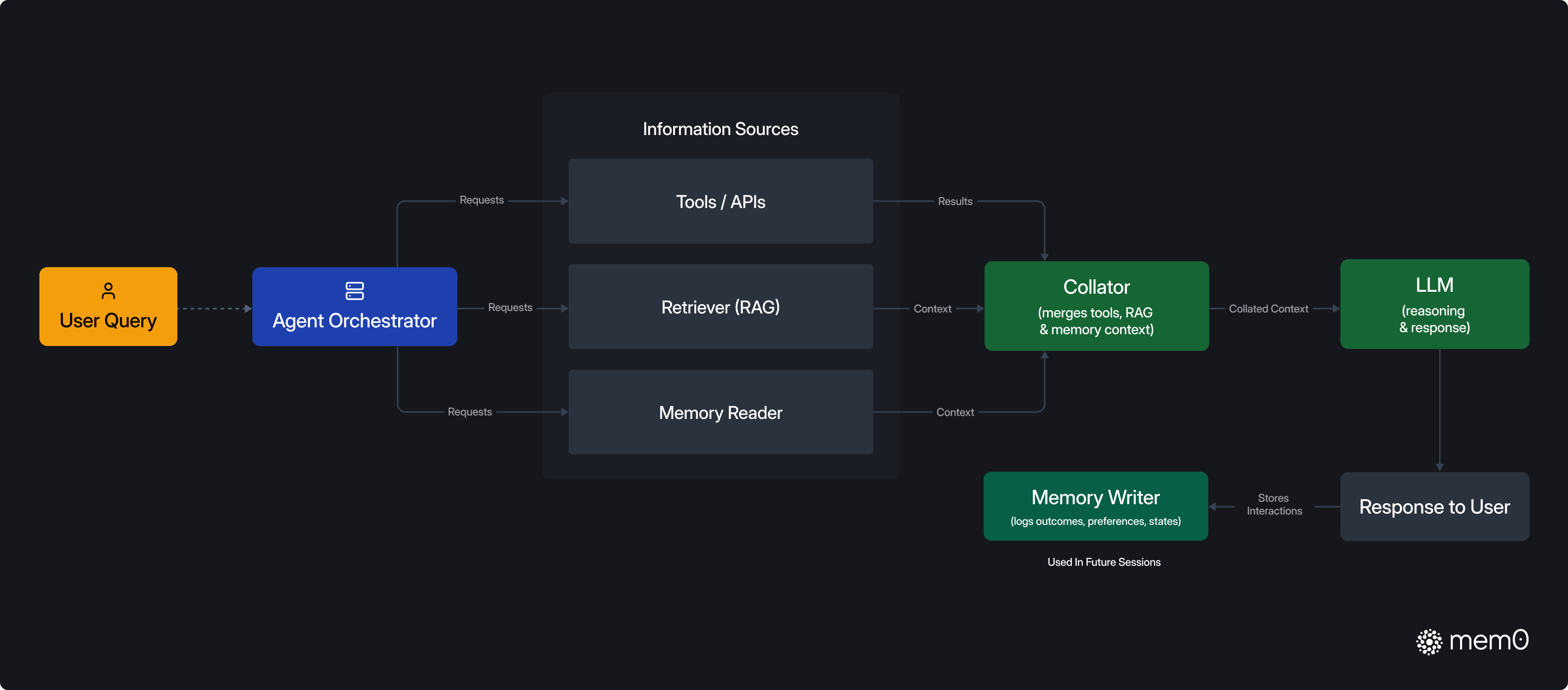
Mem0在AI智能體中的處理方式
下面是Mem0記憶層和使用LLM上下文窗口的主要區別

記憶層和RAG對比
以Mem0為代表的記憶層與傳統RAG對比有以下區別:
-
實體關聯:理解并跨會話關聯人物、主題,而非僅檢索靜態文檔。
-
記憶策略:優先近期、高相關記憶,舊信息自動衰減。
-
會話連續:長期保留上下文,使得虛擬伴侶、學習助手等場景更連貫。
-
持續學習:根據用戶反饋實時微調,個性化隨時間更精準。
-
動態更新:新交互即時寫入記憶,無需重新索引文檔。
Mem0核心流程
Mem0的核心工作流程包括以下步驟:
-
語義捕獲:利用LLM對會話流進行智能解析,自動捕獲并抽象出具備長期價值的核心語義信息。
-
內容向量化:通過嵌入模型將這些語義信息編碼為高維度的向量,為后續的相似度計算和高效檢索奠定基礎。
-
向量存儲:將上一步生成的向量存儲至向量數據庫中,該數據庫需要支持大規模、低延遲的語義搜索,在后面的例子中我們將使用阿里云Milvus。
-
檢索:系統接收到新的用戶輸入后,會立即在向量空間中進行語義相似度匹配,精準地調用出與當前情境最關聯的歷史記憶。
-
上下文增強:將調用出的歷史記憶注入到當前的推理鏈路中,與現有上下文相結合,從而生成邏輯更連貫、內容更具個性化的響應。
阿里云Milvus基本原理介紹
基本原理與架構概述
Milvus?是專為向量相似性搜索設計的分布式數據庫,其核心基于以下關鍵技術:
-
近似最近鄰搜索(ANN):通過HNSW、IVF、PQ等算法實現高效向量檢索,平衡精度與速度。
-
向量索引與查詢分離:支持動態構建多種索引類型(如FLAT、IVF_FLAT、IVF_PQ、HNSW),適配不同場景需求。
-
向量數據分片與分布式計算:數據水平切分(Sharding)并行處理,實現高吞吐與低延遲。
采用云原生和存算分離的微服務架構。該架構分為接入、協調、執行和存儲四層。各組件可獨立擴展,確保了系統的高性能、高可用性和彈性。它依賴成熟的第三方組件(如etcd、對象存儲)進行數據和元數據管理,穩定可靠。
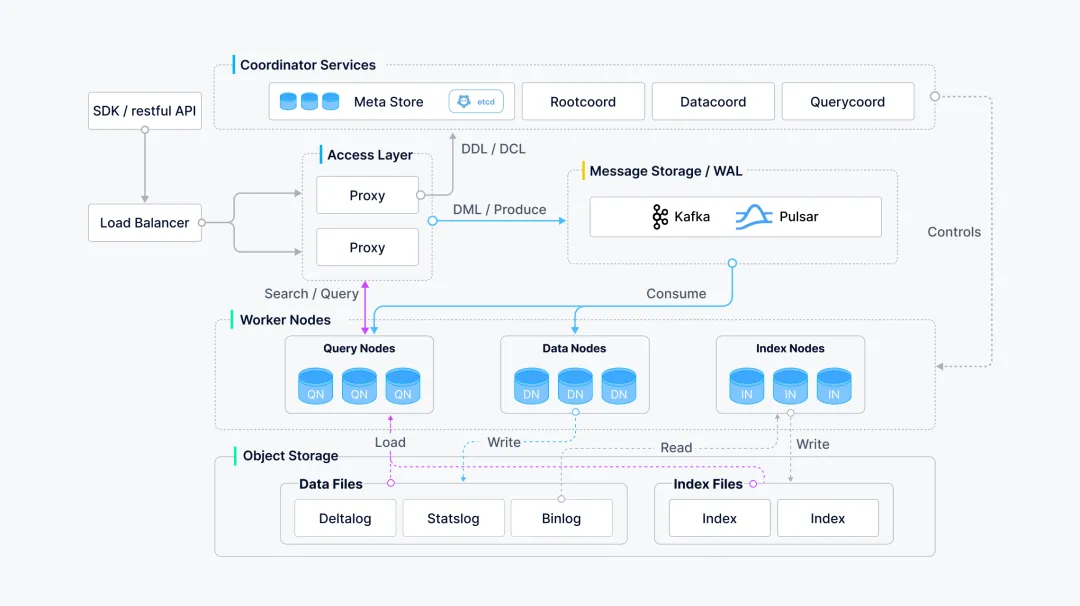
阿里云Milvus系統架構圖
使用場景
阿里云?Milvus?適用于任何需要進行“相似性”匹配的場景。其核心應用包括:
-
圖像視頻搜索:如電商平臺的以圖搜圖、安防領域的人臉識別和視頻軌跡追蹤。
-
文本語義搜索:構建智能客服、企業內部文檔知識庫和代碼搜索引擎,能精準理解用戶意圖,而非簡單的關鍵詞匹配。
-
個性化推薦系統:根據用戶的行為和偏好向量,實時推薦最相似的商品、音樂、新聞或視頻。
-
前沿科學與安全:在生物信息學中加速藥物分子篩選,或在網絡安全領域進行異常流量和欺詐行為檢測。
-
智能駕駛數據準備與挖掘:對點云圖像、車載傳感器收集的音視頻等多模態數據進行向量數據的實時查詢。
更多介紹:https://www.aliyun.com/product/milvus
接下來,本教程將通過兩個示例,帶你實踐如何結合?Mem0?與?Milvus實現:
-
構建具備長期記憶的?AI?Agent
-
利用圖譜引擎與向量引擎協同分析信息間的復雜關聯。
實踐一、有記憶的AI?Agent開發流程
前提條件
-
已創建阿里云Milvus實例。具體操作,請參見快速創建Milvus實例。
-
已開通服務并獲得API-KEY。具體操作,請參見開通DashScope并創建API-KEY。
代碼開發
LangGraph?是一個業界成熟的用于構建有狀態和多角色的Agents?應用的框架。限于篇幅將不對LangGraph過多介紹,可以參考官方文檔。
-
依賴庫安裝
pip install langgraph langchain-openai mem0ai-
核心代碼
包含以下核心步驟:
-
環境變量設置OpenAI方式訪問百煉qwen大模型;LLM設置qwen-plus作為語言大模型;Mem0配置qwen-plus作為語義識別和處理大模型、使用text-embedding-v3作為embedding模型、使用Milvus作為向量存儲數據庫。
-
設置LangGraph會話狀態,用于獲取對話上下文。
-
對話Agent開發,使用Mem0的search接口獲取相關的記憶、使用Mem0的add接口存儲相關記憶到向量庫Milvus中。
-
編排LangGraph,設置節點和邊。
-
設置LangGraph流式輸出。
-
入口main函數進行人機交互。
from typing import Annotated, TypedDict, List
from langgraph.graph import StateGraph, START
from langgraph.graph.message import add_messages
from langchain_openai import ChatOpenAI
from mem0 import Memory
import os
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage# 設置環境變量,百煉平臺qwen模型的key和baseurl
os.environ["OPENAI_API_KEY"] = "sk-xx"
os.environ["OPENAI_BASE_URL"] = "https://dashscope.aliyuncs.com/compatible-mode/v1"# LLM設置
llm = ChatOpenAI(model="qwen-plus", temperature=0.2, max_tokens=2000)
# Mem0設置,LLM、embedding和向量庫
config = {"llm": {"provider": "openai","config": {"model": "qwen-plus","temperature": 0.2,"max_tokens": 2000,}},"embedder": {"provider": "openai","config": {"model": "text-embedding-v3","embedding_dims": 128,}},"vector_store": {"provider": "milvus","config": {"collection_name": "mem0_test1","embedding_model_dims": "128","url": "http://c-xxx.milvus.aliyuncs.com:19530","token": "root:xxx","db_name": "default",},},"version": "v1.1",
}mem0 = Memory.from_config(config)# 設置LangGraph對話狀態
class State(TypedDict):messages: Annotated[List[HumanMessage | AIMessage], add_messages]mem0_user_id: strgraph = StateGraph(State)# 對話Agent開發,包含Mem0記憶讀取和記憶存儲
def chatbot(state: State):messages = state["messages"]user_id = state["mem0_user_id"]try:# Retrieve relevant memoriesmemories = mem0.search(messages[-1].content, user_id=user_id,)# Handle dict response formatmemory_list = memories['results']context = "Relevant information from previous conversations:\n"for memory in memory_list:context += f"- {memory['memory']}\n"system_message = SystemMessage(content=f"""You are a helpful customer support assistant. Use the provided context to personalize your responses and remember user preferences and past interactions.
{context}""")full_messages = [system_message] + messagesprint(full_messages)response = llm.invoke(full_messages)# Store the interaction in Mem0try:interaction = [{"role": "user","content": messages[-1].content},{"role": "assistant", "content": response.content}]result = mem0.add(interaction, user_id=user_id,)print(f"Memory saved: {len(result.get('results', []))} memories added")except Exception as e:print(f"Error saving memory: {e}")return {"messages": [response]}except Exception as e:print(f"Error in chatbot: {e}")# Fallback response without memory contextresponse = llm.invoke(messages)return {"messages": [response]}# 設置LangGraph調度節點和邊
graph.add_node("chatbot", chatbot)
graph.add_edge(START, "chatbot")
graph.add_edge("chatbot", "chatbot")compiled_graph = graph.compile()# 設置LangGraph流式輸出
def run_conversation(user_input: str, mem0_user_id: str):config = {"configurable": {"thread_id": mem0_user_id}}state = {"messages": [HumanMessage(content=user_input)], "mem0_user_id": mem0_user_id}for event in compiled_graph.stream(state, config):for value in event.values():if value.get("messages"):print("Customer Support:", value["messages"][-1].content)return# 入口函數交互入口
if __name__ == "__main__":print("Welcome to Customer Support! How can I assist you today?")mem0_user_id = "alice" # You can generate or retrieve this based on your user management systemwhile True:user_input = input("You: ")if user_input.lower() in ['quit', 'exit', 'bye']:print("Customer Support: Thank you for contacting us. Have a great day!")breakrun_conversation(user_input, mem0_user_id)驗證效果
如下圖所示,第一次執行代碼我們沒有任何上下文,我們提問和電影相關的問題并且和LLM說了不喜歡驚悚片,LLM最終根據我們的要求推薦了一些合適的影片。
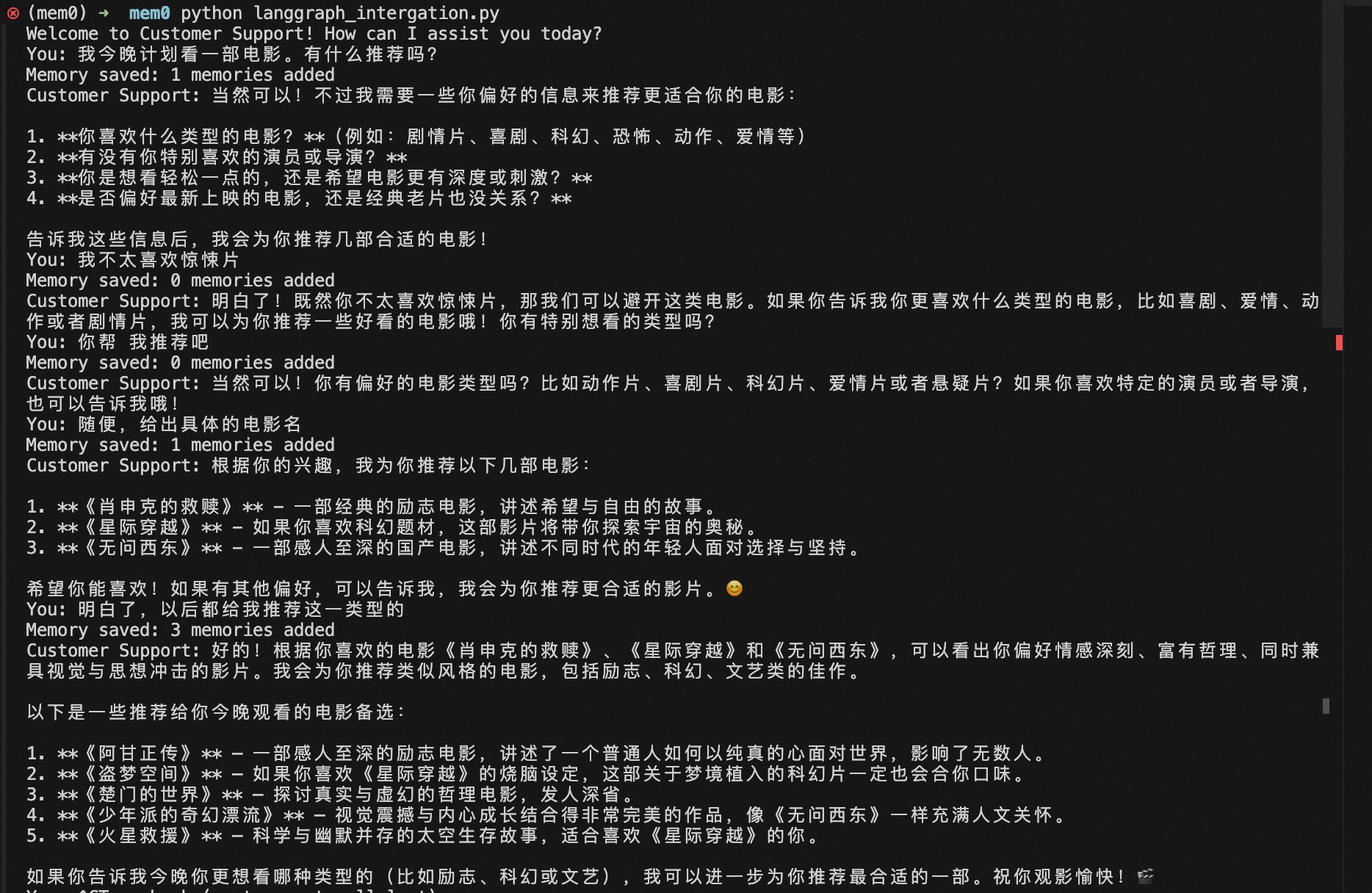
可以看到了一些Memory?saved的打印,查看Milvus向量庫,可以看到對應的collection已經有了幾個Entity。
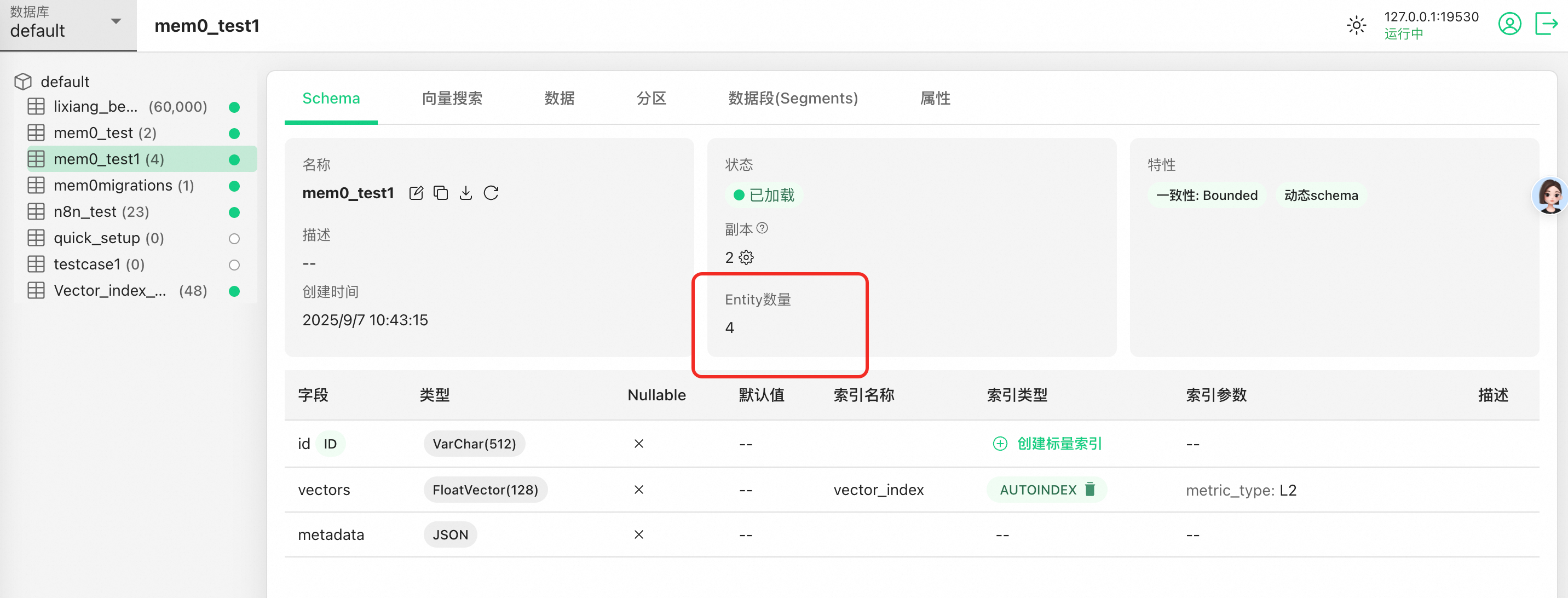
點開數據頁面,可以看到Mem0已將上下文經過LLM處理概括地保存到metadata字段中,并且對應的用戶是alice,數據為了可以被檢索也已經被向量化存儲到vectors字段中。
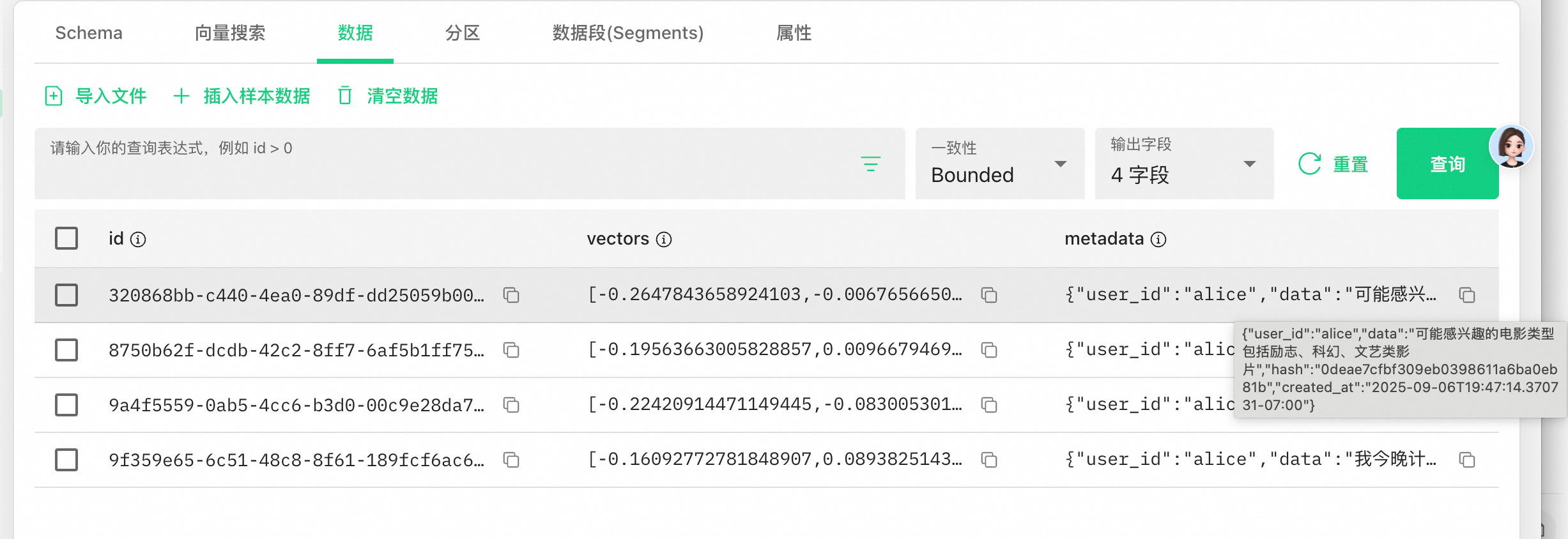
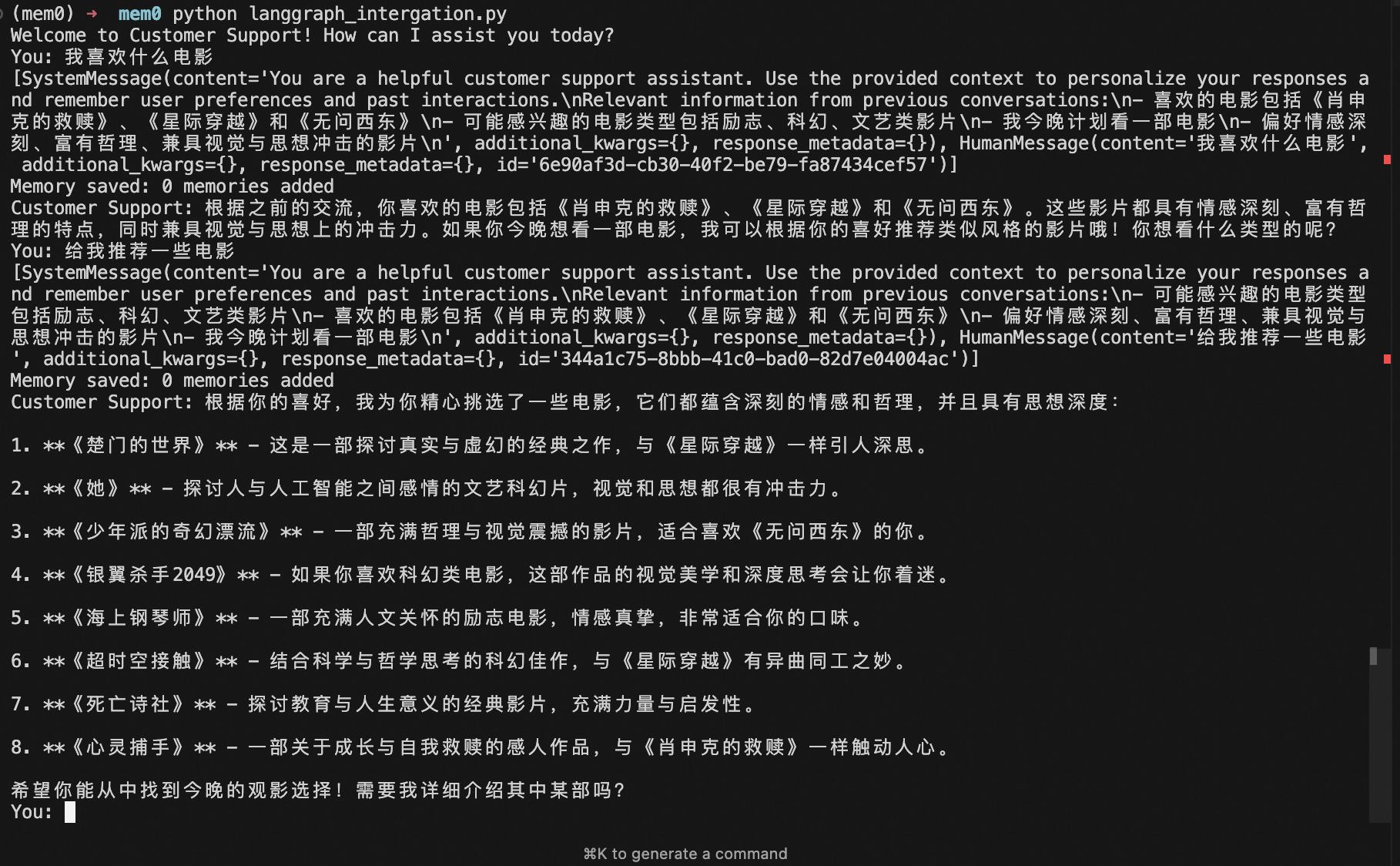
重新執行代碼,因為我們已經有了記憶的存在,再問一下“我喜歡什么電影”,可以看到Mem0從Milvus中召回了相關的內容,并將內容合并到了prompt中發送給LLM,我們得到了相關的電影推薦而不需要再和LLM重復介紹我們的喜好。
實踐二:通過圖譜引擎+向量引擎解析信息之間復雜關系
方案概述
Mem0?支持圖譜記憶(Graph?Memory)。借助圖譜記憶,用戶可以創建并利用信息之間的復雜關系,從而生成更細致、更具上下文感知能力的響應。這一融合使用戶能夠同時發揮向量檢索與圖譜技術的優勢,實現更準確、更全面的信息檢索與內容生成。
記憶層添加記錄的方式如下圖所示,Mem0通過LLM提取內容后,通過添加或者更新的方式,同時將內容embedding到向量庫和提取實體&關系到圖譜數據庫中。
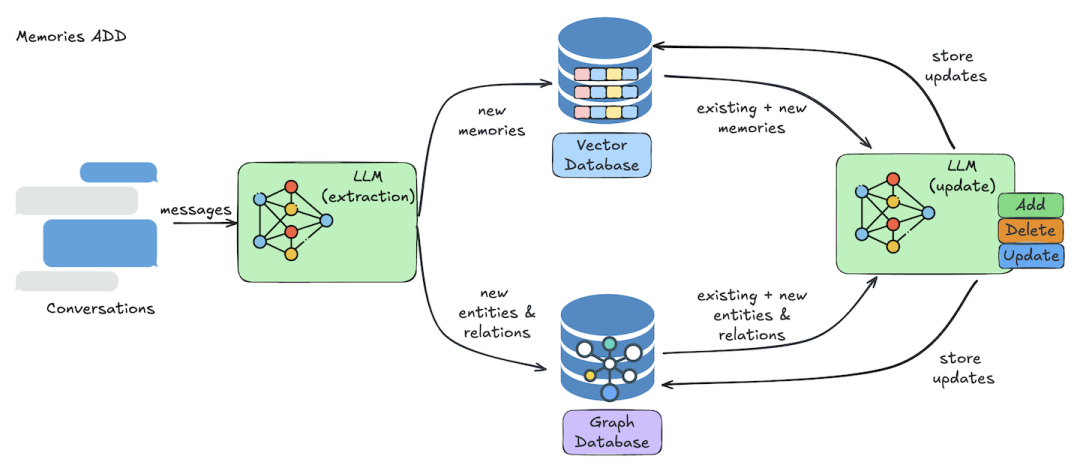
記憶層添加記錄
記憶層檢索記錄的方式如下圖所示,Mem0通過LLM提取內容后,同時將內容embedding到向量庫檢索和提取實體&關系到圖譜數據庫中檢索,雙路檢索后將結果合并輸出。
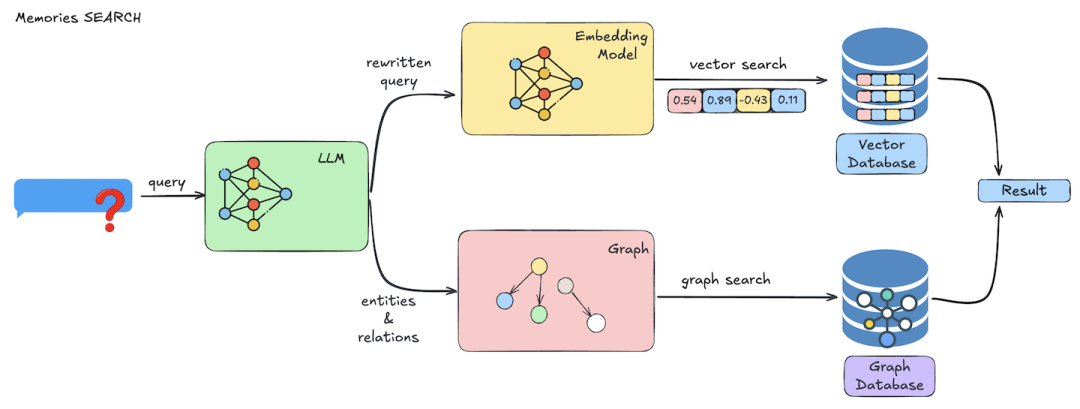
記憶層檢索記錄
前提條件
-
已創建阿里云Milvus實例。具體操作,請參見快速創建Milvus實例。
-
已開通服務并獲得API-KEY。具體操作,請參見開通DashScope并創建API-KEY。
代碼開發
-
依賴庫安裝
pip install kuzu rank-bm25 mem0ai
-
核心代碼
包含以下核心步驟:
-
環境變量設置OpenAI方式訪問百煉qwen大模型;LLM設置qwen-plus作為語言大模型;Mem0配置qwen-plus作為語義識別和處理大模型、使用text-embedding-v3作為embedding模型、使用Milvus作為向量存儲數據庫、使用kuzu作為圖譜數據庫。
-
初始化Mem0,添加數據,將同時添加內容到向量庫和圖譜庫中。
-
提問測試。
from langchain_openai import ChatOpenAI
from mem0 import Memory# 設置環境變量,百煉平臺qwen模型的key和baseurl
os.environ["OPENAI_API_KEY"] = "sk-xx"
os.environ["OPENAI_BASE_URL"] = "https://dashscope.aliyuncs.com/compatible-mode/v1"# LLM設置
llm = ChatOpenAI(model="qwen-plus", temperature=0.2, max_tokens=2000)
# Mem0設置,LLM、embedding和向量庫
config = {"llm": {"provider": "openai","config": {"model": "qwen-plus","temperature": 0.2,"max_tokens": 2000,}},"embedder": {"provider": "openai","config": {"model": "text-embedding-v3","embedding_dims": 128,}},"vector_store": {"provider": "milvus","config": {"collection_name": "mem0_test3","embedding_model_dims": "128","url": "http://c-xxx.milvus.aliyuncs.com:19530","token": "root:xxx","db_name": "default",},},"graph_store": {"provider": "kuzu","config": {"db": "./mem0-example.kuzu"}},"version": "v1.1",
}# 初始化Mem0,添加數據,將同時添加內容到向量庫和圖譜庫中
m = Memory.from_config(config)
m.add("我喜歡去徒步旅行", user_id="alice123")
m.add("我喜歡打羽毛球", user_id="alice123")
m.add("我討厭打羽毛球", user_id="alice123")
m.add("我的朋友叫約翰,約翰有一只叫湯米的狗", user_id="alice123")
m.add("我的名字是愛麗絲", user_id="alice123")
m.add("約翰喜歡徒步旅行,哈利也喜歡徒步旅行", user_id="alice123")
m.add("我的朋友彼得是蜘蛛俠", user_id="alice123")# 按照score分數倒序排列,輸出結果
def get_res(res):sorted_results = sorted(res['results'], key=lambda x: x['score'], reverse=True)res['results'] = sorted_resultsprint(json.dumps(res, ensure_ascii=False, indent=2))# 提問測試
get_res(m.search("我的名字是什么?", user_id="alice123"))
get_res(m.search("誰是蜘蛛俠?", user_id="alice123"))驗證效果
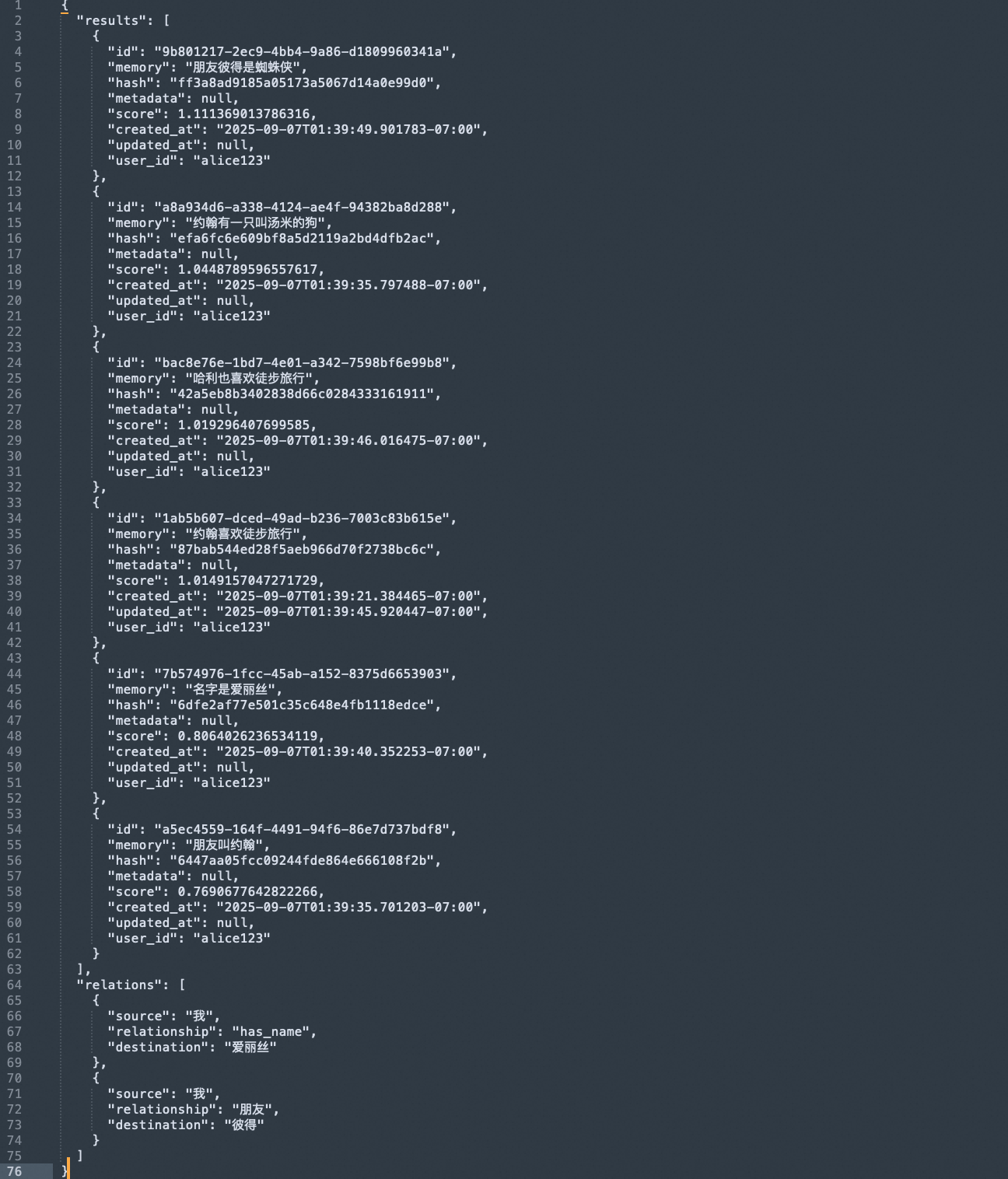
如下圖所示,是“我的名字是什么?”的返回,可以看到results中是向量返回,返回的“名字是愛麗絲”得分并不高,relations中是圖譜返回,解析出了我的名字是“愛麗絲”,關系為has_name。
如下圖所示,是“誰是蜘蛛俠?”的返回,可以看到results中是向量返回,返回的“朋友彼得是蜘蛛俠”得分最低,relations中是圖譜返回,解析出了蜘蛛俠的名字是“彼得”,關系為是。
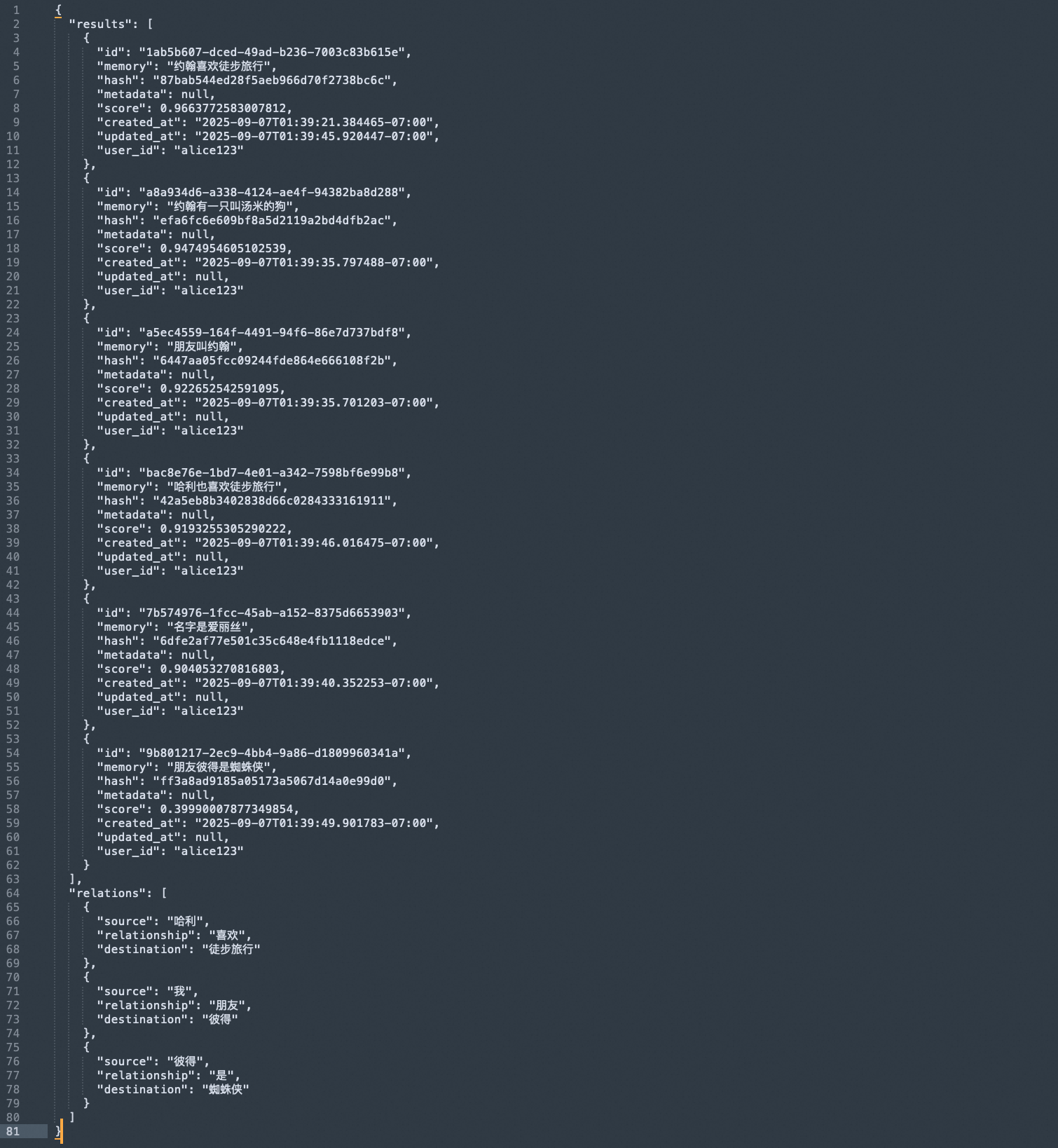
通過以上兩個例子,可以發現,有圖譜能力的加持,可以補齊向量庫缺失信息之間深層分析的短板。
隨著AI應用越來越深入日常生活,系統對用戶上下文和歷史信息的理解變得尤為重要。Mem0?與?Milvus?的結合,為人工智能提供了一套高效、可擴展的長時記憶解決方案。通過向量數據庫持久化存儲語義記憶,AI?不僅能記住過去的交互,還能在后續對話中持續調用和更新這些信息。這一能力讓智能助手、客服機器人等應用更加連貫、個性化和實用。


所需的數學基礎)






,鏈路聚合(兩個交換機配置)以及常用命令)

)



![P2678 [NOIP 2015 提高組] 跳石頭](http://pic.xiahunao.cn/P2678 [NOIP 2015 提高組] 跳石頭)

)

![[優選算法專題二——NO.16最小覆蓋子串]](http://pic.xiahunao.cn/[優選算法專題二——NO.16最小覆蓋子串])