大家好,隨著人工智能(AI)的蓬勃發展,一個新興領域語言模型運維(LLMOps)正逐漸成為關注的焦點。LLMOps專注于對大型語言模型(LLMs),例如OpenAI的GPT系列,進行全生命周期的管理,確保高效運作和持續優化。
本文將介紹LLMOps的核心理念,包括其重要性、構成要素、挑戰和未來前景,并分析其在AI快速發展的大背景下所扮演的關鍵角色。
1.LLMOps簡介
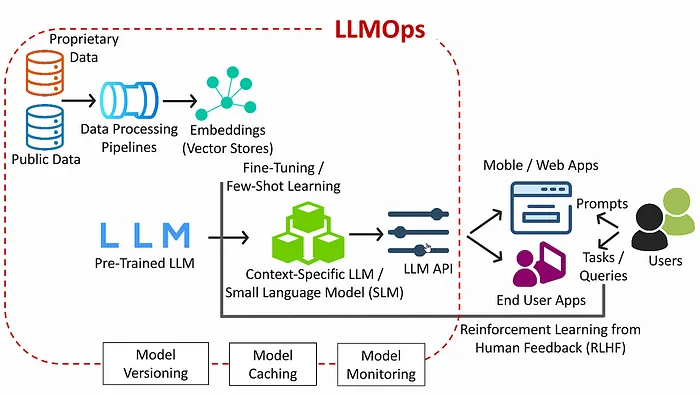
LLMOps,即語言模型運維,指的是管理和部署像OpenAI的GPT系列這樣的大型語言模型(LLMs)所涉及的實踐和流程。LLMOps包含一系列活動,包括:
-
模型訓練和開發:包括收集和準備數據集,在這些數據集上訓練模型,并根據性能指標迭代改進模型。
-
模型部署:將LLMs部署到生產環境中,用戶可以訪問或集成到應用程序中。
-
監控和維護:持續監控生產中LLMs的性能,確保它們按預期運行,并根據需要進行維護。
-
擴展和優化:擴展基礎設施以支持LLMs的使用,并優化模型和基礎設施以提高性能和成本效率。
-
倫理和法律合規:確保LLMs的使用遵守倫理標準并符合法律規范,特別是在隱私、偏見和公平性等方面。
-
版本控制和模型管理:管理不同版本的語言模型,包括用新數據或改進更新模型和管理每個模型版本的生命周期。
總的來說,LLMOps是一個端到端的過程,涵蓋了語言模型從開發初期到部署階段,再到生產環境中的運維管理,貫穿了整個生命周期的每一個環節。
2.重要性
LLMOps之所以至關重要,是因為關系到大型語言模型(LLMs)在技術、醫療保健、金融和教育等多個領域的迅猛增長和廣泛應用。LLMs已經成為推動自然語言處理(NLP)能力發展的核心力量,為會話AI、情感分析、內容生成和語言翻譯等提供了創新的解決方案。隨著這些模型規模的不斷擴大和復雜度的日益增加,如何高效管理它們的生命周期變得尤為關鍵。這不僅能夠充分發揮LLMs的巨大潛力,同時也能有效降低與模型部署和使用相關的風險。
3.核心要素
3.1 模型開發與訓練
這是構建語言模型的基石,包括數據的收集、模型架構的設計以及訓練過程的執行。在這一階段,確保訓練數據的高質量和多樣性是關鍵,有助于減少偏見,提升模型的準確性和公平性。
3.2 部署與集成
將語言模型(LLMs)通過API接口或嵌入應用程序的方式,使其對最終用戶開放使用。這一步驟要求有堅實的基礎設施支撐,以應對計算需求,同時保證模型的高效集成,為用戶提供無縫體驗。
3.3 監控與維護
在生產環境中對LLMs進行持續監控,對于及時發現并解決性能問題、異常情況以及倫理問題(如偏見和濫用)非常重要。維護工作包括模型的更新、微調和軟件依賴的修復。
3.4 擴展與優化
隨著AI服務需求的增加,擴展基礎設施和優化性能成為必要。這不僅有助于控制成本,還能提升服務效率,需要在計算資源、降低延遲和算法優化之間找到平衡。
3.5 倫理與合規管理
遵循倫理準則和法律標準是LLMOps不可或缺的一部分。這涉及到確保模型的操作和決策過程在隱私保護、公平性、透明度和可問責性方面都符合要求。
3.6 版本控制與生命周期管理
對不同版本的LLMs及其生命周期進行有效管理,對于保持系統的穩定性和實現持續改進至關重要。這包括對模型版本的控制、模型的退役以及向新模型過渡的平滑處理。
4.挑戰
LLMOps在實踐中面臨著眾多挑戰,主要歸因于大型語言模型(LLMs)本身的復雜性以及人工智能(AI)技術的快速進步。其中一些挑戰包括:
-
數據隱私與安全:在管理海量數據的同時,確保隱私和安全是一大難題,尤其是需要面對GDPR、CCPA等嚴格的數據保護法規。
-
偏見與公平性:要打造無偏見、公平的模型,需要持續不斷地進行監控、評估,并利用多樣化的數據集對模型進行再訓練。
-
資源管理:隨著大型語言模型規模的不斷擴大,如何有效管理計算資源,以平衡性能和成本,成為一個持續的挑戰。
-
人工智能技術的迅速發展要求LLMOps必須保持高度警覺,快速適應新技術,以確保運維實踐的時效性和有效性。
5.前景展望
語言模型運維(LLMOps)的未來發展前景樂觀,其發展特點預計將集中在三個方面:對自動化技術的進一步應用,對人工智能倫理問題的持續關注,促進不同學科領域間更緊密的合作。
自動化技術的融入將極大簡化語言模型從訓練到部署的流程,提升效率并降低人為錯誤。同時,AI倫理將持續成為焦點,推動開發更多保障語言模型負責任使用的框架和工具。此外,數據科學、軟件工程、倫理學等不同領域的專家需要緊密合作,這對于塑造LLMOps的未來具有重大意義,這種跨界合作能夠促進技術合理性與倫理責任感的增強,推動創新的同時確保技術的健康發展。簡言之,LLMOps的未來將是技術與倫理并重,自動化與合作共進的時代。
6.構建LLMOps流程
在Python中創建一個完整的LLMOps流程涉及多個步驟,首先要生成合成數據集,然后訓練模型,接著用相關指標對模型進行評估,之后繪制評估結果,最后對這些結果進行解釋。下面逐一解析這些步驟,用一個簡化的示例以展示整個過程。
6.1 創建合成數據集
在本示例中,將生成一個文本分類任務的合成數據集。
import?pandas?as?pd
import?numpy?as?np#?生成合成數據
np.random.seed(42)
data_size?=?1000
text_data?=?['Sentence?'?+?str(i)?for?i?in?range(data_size)]
labels?=?np.random.randint(0,?2,?size=data_size)#?創建一個DataFrame
df?=?pd.DataFrame({'text':?text_data,?'label':?labels})
6.2 預處理與模型訓練
為了演示,使用一個簡單的模型,如邏輯回歸分類器。
from?sklearn.model_selection?import?train_test_split
from?sklearn.feature_extraction.text?import?CountVectorizer
from?sklearn.linear_model?import?LogisticRegression#?分割數據
X_train,?X_test,?y_train,?y_test?=?train_test_split(df['text'],?df['label'],?test_size=0.2,?random_state=42)#?向量化文本數據
vectorizer?=?CountVectorizer()
X_train_vec?=?vectorizer.fit_transform(X_train)
X_test_vec?=?vectorizer.transform(X_test)#?訓練模型
model?=?LogisticRegression(random_state=42)
model.fit(X_train_vec,?y_train)
6.3 評估模型
使用準確率和混淆矩陣作為評估模型的指標。
from?sklearn.metrics?import?accuracy_score,?confusion_matrix#?預測和評估
predictions?=?model.predict(X_test_vec)
accuracy?=?accuracy_score(y_test,?predictions)
conf_matrix?=?confusion_matrix(y_test,?predictions)print(f"準確率:{accuracy}")
print(f"混淆矩陣:\n{conf_matrix}")
6.4 結果可視化
可以通過繪制混淆矩陣來直觀地表示模型的性能。
import?matplotlib.pyplot?as?plt
import?seaborn?as?snssns.heatmap(conf_matrix,?annot=True,?fmt='g')
plt.xlabel('預測標簽')
plt.ylabel('真實標簽')
plt.title('混淆矩陣')
plt.show()
6.5 結果解讀
解釋將取決于模型的性能指標。具體來說:
-
準確率表明了模型的整體正確性。
-
混淆矩陣顯示了真正例、真負例、假正例和假負例的預測數量,為深入理解模型的分類行為提供了直觀的視角。
在實際LLMOps應用場景中,模型的解釋與評估僅是整個流程的一部分。這個完整的流程還涵蓋模型版本控制、持續集成與持續部署(CI/CD)的實踐、以及對模型進行持續監控和根據新數據或性能指標進行更新等環節。
本示例只是提供了一個簡化的視角,而在實際生產環境中,LLMOps的實施需要更復雜的數據處理、模型訓練、評估和運維策略,以確保系統的穩定性和高效性。

在圖像識別中的革命性應用:自動駕駛的崛起)












![[AutoSar]lauterbach_001_ORTI_CPUload_Trace](http://pic.xiahunao.cn/[AutoSar]lauterbach_001_ORTI_CPUload_Trace)




)