? ? ? YOLOv8論文尚未發布,YOLOv8由Ultralytics公司推出并維護,源碼見:https://github.com/ultralytics/ultralytics ,于2024年1月發布v8.1.0版本,最新發布版本為v8.2.0,License為AGPL-3.0。
? ? ? 以下內容主要來自:
? ? ? 1.?https://docs.ultralytics.com/
? ? ? 2.?https://github.com/ultralytics/ultralytics/issues/189
? ? ? 3.?https://viso.ai/deep-learning/yolov8-guide/
? ? ? Ultralytics YOLOv8是一種尖端、最先進(state-of-the-art, SOTA)的模型,它建立在先前YOLO版本成功的基礎上,并引入了新功能和改進,以進一步提高性能和靈活性。YOLOv8的設計目標是快速、準確且易于使用,使其成為各種目標檢測和跟蹤、實例分割、圖像分類和姿態估計任務的絕佳選擇。
? ? ? 向YOLOv5一樣,根據參數數量,YOLOv8有5種不同類型的模型:nano(n), small(s), medium(m), large(l), and extra large(x),如下圖所示:

? ? ? YOLOv8檢測模型結構如下所示:來源:https://github.com/ultralytics/ultralytics/issues/189 ,與?YOLOv5 相比,改變如下:
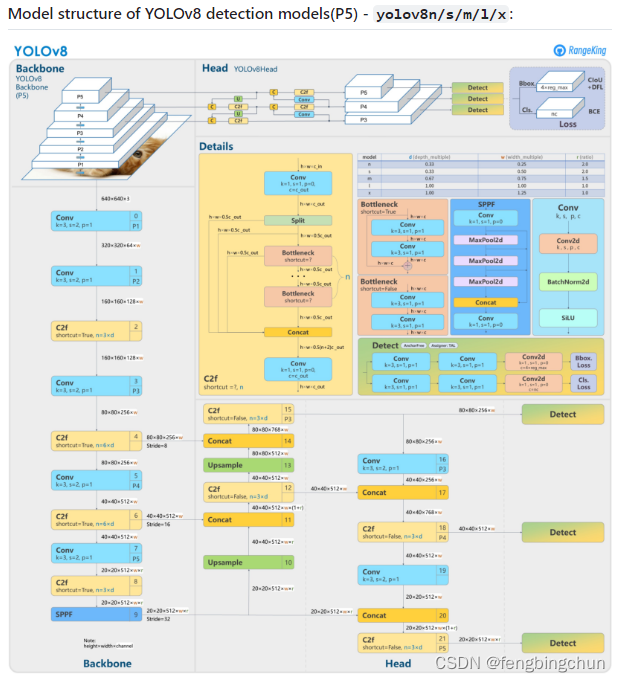
? ? ? (1).將C3模塊替換為C2f模塊;
? ? ? (2).將Backbone中的第一個6*6 Conv替換為3*3 Conv;
? ? ? (3).刪除兩個Conv(YOLOv5配置中的No.10和No.14);
? ? ? (4).將Bottleneck中的第一個1*1 Conv替換為3*3 Conv;
? ? ? (5).使用解耦頭(decoupled head)并刪除objectness分支.
? ? ? YOLOv8架構利用幾個關鍵組件來執行目標檢測任務:
? ? ? (1).Backbone是一系列卷積層,用于從輸入圖像中提取相關特征。SPPF層和后續的卷積層處理各種尺度的特征,而上采樣層則提高特征圖的分辨率。C2f模塊將高級特征(high-level features)與上下文信息相結合,以提高檢測精度。最后,檢測模塊使用一系列卷積層和線性層將高維特征(high-dimensional features)映射到輸出邊界框和目標類別。
? ? ? (2).Head負責獲取Backbone生成的特征圖并進一步處理它們,以邊界框和目標類別的形式生成模型的最終輸出。在YOLOv8中,Head被設計為解耦,這意味著它獨立處理對象性(objectness)、分類和回歸任務。這種設計使得每個分支能夠專注于各自的任務,并提高了模型的整體準確性。為了處理特征圖,Head使用一系列卷積層,然后是線性層來預測邊界框和類別概率。Head的設計針對速度和精度進行了優化,特別關注每層的通道數量和kernel大小,以最大限度地提高性能。注:新版本中objectness head已被刪除
? ? ? (3).YOLOv8中使用的框回歸損失基于Smooth L1損失函數,該函數常用于目標檢測任務。該損失函數平衡了L1和L2損失函數,并且對訓練數據中的異常值不太敏感。它用于計算預測的邊界框坐標與ground truth坐標之間的差異。然后使用損失函數在訓練過程中更新網絡的權重。注:早期版本使用的是Smooth L1,新版本是CIoU、DFL、BCE.
? ? ? (4).在YOLOv8的輸出層中,我們使用sigmoid函數作為objectness分數的激活函數,它表示邊界框包含目標的概率。對于類別概率,我們使用softmax函數,它表示目標屬于每個可能類別的概率。
? ? ? (5).YOLOv8中的Neck結構,它是一個新穎的C2f模塊,與YOLOv5中使用的PANet結構不同。C2f模塊取代了傳統的YOLO Neck結構,并改進了網絡中的特征提取。
? ? ? (6).YOLOv8中使用的網格單元的大小取決于圖像的輸入大小。具體來說,網格單元的大小是通過將輸入圖像劃分為具有一定數量單元的網格來確定的,其中每個單元對應于輸出特征圖的一個區域。在YOLOv8中,這個網格大小由Backbone中最終卷積層的步長決定。例如,如果最終卷積層的步長(Stride)為32,則輸入圖像將被劃分為32*32單元的網格,網格中的每個單元格將對應于輸出特征圖的大小為80*80的區域。類似地,如果最終的卷積層的步長為16,那么輸入圖像將被劃分為16*16單元的網格,網格中的每個單元將對應于輸出特征圖的大小為40*40的區域。YOLOv8中的Stride參數是指輸入圖像在Backbone中下采樣的像素數。
? ? ? YOLOv8主要features:
? ? ? (1).Mosaic數據增強:YOLOv8的變化是在最后10個epoch停止Mosaic增強操作以提高性能;
? ? ? (2).Anchor-Free Detection:YOLOv8改用無錨(anchor-free)檢測來提高泛化能力,基于錨點(anchor-based)的檢測的問題是預定義的錨點框降低了自定義數據集的學習速度。通過無錨檢測,模型直接預測目標的中心點并減少邊界框預測的數量,這有助于加速非最大值抑制(Non-maximum Suppression,NMS),用于消除冗余的檢測框;
? ? ? (3).C2f Module:YOLOv8模型的Backbone現在由C2f模塊而不是C3模塊組成。兩者的區別在于,在C2f中,模型連接了所有Bottleneck模塊的輸出。相反,在C3中,模型使用最后一個Bottleneck模塊的輸出。Bottleneck模塊由bottleneck殘差塊組成,可減少深度學習網絡中的計算成本。這加快了訓練過程并改善了梯度流(gradient flow)。
? ? ? (4).Decoupled Head:Head部不再一起執行分類和回歸。相反,它單獨執行task,這提高了模型性能。
? ? ? (5).Loss:使用BCE(Binary Cross-entropy)計算分類損失;使用CIoU(Complete IoU)和DFL(Distributional Focal Loss)計算回歸損失。DFL背后的主要思想是解決訓練數據中類別不平衡的問題。
? ? ? GitHub:https://github.com/fengbingchun/NN_Test




)






)







