Agent本身的定義也不是絕對的,從LLM到最高等級的Agent,中間是有大量灰度地帶的,在Anthropic看來,Agent可以以多種方式定義,有些人將完全自主系統定義為Agent,而另一些團隊則將預定義的工作流程定義為Agent。在Anthropic,所有這些變種都定義為Agent系統(Agentic System)。
Workflow和Agents的區別:
- Workflow:LLMs和工具通過預定義的代碼路徑編排的系統,也就是用戶輸入后,它的執行路徑,是能夠提前預料的,是有人工構建的,像基于Coze、Dify、n8n等平臺搭建的應用,絕大多數屬于這一類
- Agents:LLMs動態指導自己的流程和工具使用,典型的,比如Cursor、Windsur、Claude Code這種編程智能體,你發送指令后,后續它會先向你做一些澄清、幫你開始編寫一份技術文檔還是調用MCP工具來獲取一些API使用說明等,沒人能確切地知道其執行路徑
為什么上一篇介紹完“正統”的Agent設計模式后,這一篇還要介紹一些Workflow呢?這是因為當前落地的絕大多數Agent仍以Workflow形式為主,它有三大顯著的優勢:
- 上手很快,門檻比較低,即使沒有學過編程,也能拖拽出一個可以用的應用
- 不同場景有自己固定的成熟流程,使用Workflow是將這些流程融入AI非常低成本的方式
- 試錯成本低,熟悉基本概念后,對于一個不太復雜的場景,一兩天就能用Coze、Dify之類的搭建出看起來像樣的應用,而構建高度自主化的Agent,則周期長、成本高
Anthropic在原文的多個地方強調尋找盡可能簡單的解決方案,這也確實是一個非常務實的建議,畢竟,在沒有清晰實現路徑的情況下,小步快跑才是更優選擇。
1 何時該使用與不該使用Agents
使用LLMs構建應用程序時,建議盡可能找簡單的解決方案,僅在需要時增加復雜性。這意味著可能根本不需要構建Agent。Agent系統通常以高延遲和高成本為代價來獲得更好的任務性能。
當需要更高的復雜性時,Workflow為定義明確的任務提供可預測性和一致性,當需要大規模的靈活性和模型驅動的決策時,Agents是更好的選擇。但是,對于大多數應用,使用檢索和In-Context樣例優化單個LLM就足夠了。
2 代理系統的常見模式
這部分從基礎構建塊——增強LLM開始,逐步增加復雜性,從簡單組合的工作流到自主代理。
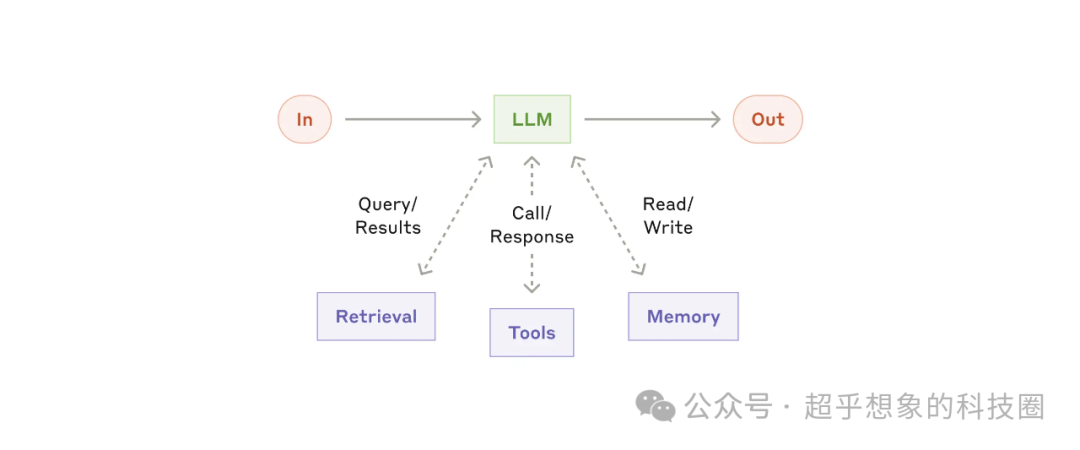
2.1 增強LLM
通過檢索、工具、記憶等模塊來增強LLM

2.2 鏈式調用
這種模式由一系列Prompt + LLM串聯成鏈式結構組成,鏈可以將任務分解為一系列步驟,每個LLM調用都會處理前一個調用的輸出,可以對任何中間步驟添加檢查(下圖中的Gate)
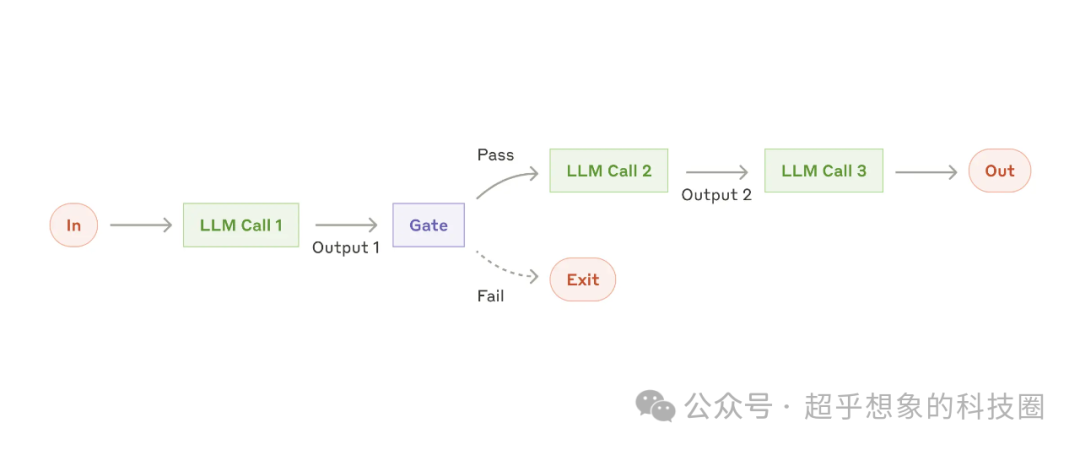
適用模式的樣例:
- 生成營銷副本,然后將其翻譯為不同的語言
- 編寫文檔的大綱,檢查大綱是否滿足特定條件,然后根據大綱編寫文檔
2.3 路由模式
將輸入分類,然后將其定向到后續的任務。
對于有些輸入,優化一種類型的輸入可能會損害其他輸入的性能(蹺蹺板),這種情況適合使用這種模式。
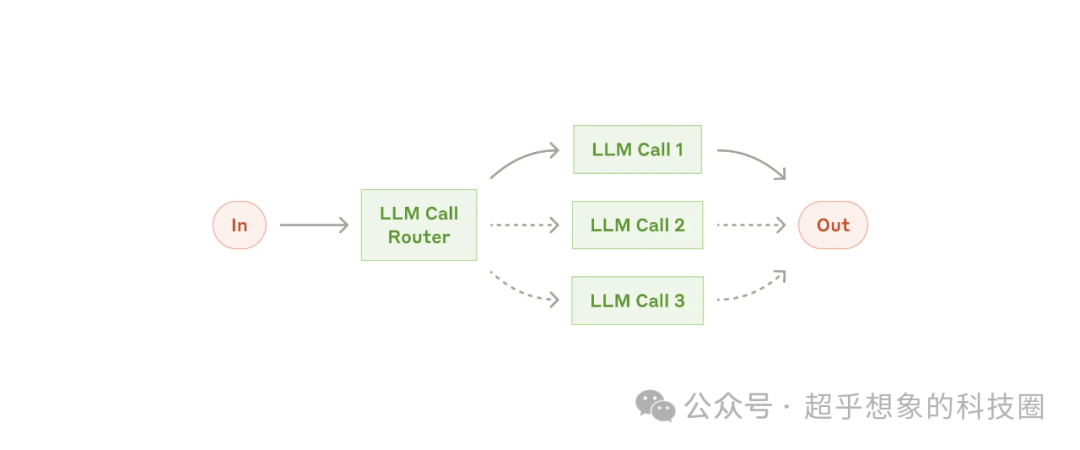
適用這種模式的樣例:
- 將不同類型的客戶服務查詢(一般問題、退款請求、技術支持)引導到不同的下游流程、提示和工具中
- 將簡單/常見問題路由到較小的模型,將困難/不尋常的問題路由到更強大的模型,以優化成本和速度
2.4 并行化
這種模式適合同時處理多個任務,并以編程方式聚合其輸出。
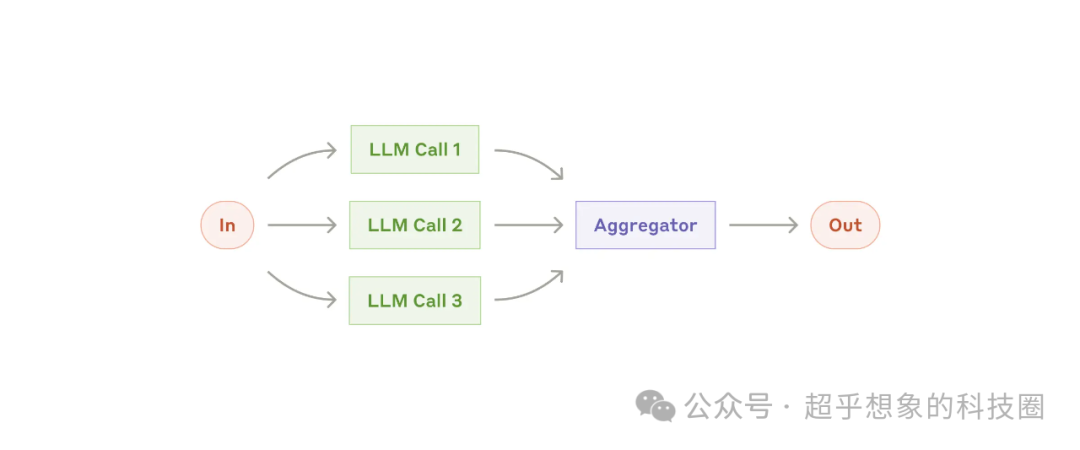
當任務可以并行以提高速度時,或者需要多個視角或嘗試以更高的置信度結果時,這種方式比較有效。
對于有多個考慮因素的復雜任務,將每個考慮因素都由單獨的LLM處理時,通常效果會更好。
適用這種模式的樣例:
-
聚合
-
- 實施查詢護欄,其中一個模型實例處理用戶查詢,另一個檢查用戶輸入是否存在不當內容
- 自動化評估,每個LLM調用評估模型在給定Prompt下性能的區別
-
投票
-
- 使用不同的Prompt檢查代碼是否存在漏洞
- 評估給定的內容是否不合適,不同的Prompt評估不同的方面或者要求不同的投票閾值來平衡誤報和漏報
2.5 編排器-Worker
在這種模式下,中央LLM會動態分解任務,然后將其委派給worker LLMs,并合并結果。
這種Workflow適合無法預測所需子任務的復雜任務(例如,在編碼過程中,需要修改的文件數量和每個文件要修改的內容很可能依賴于任務)。
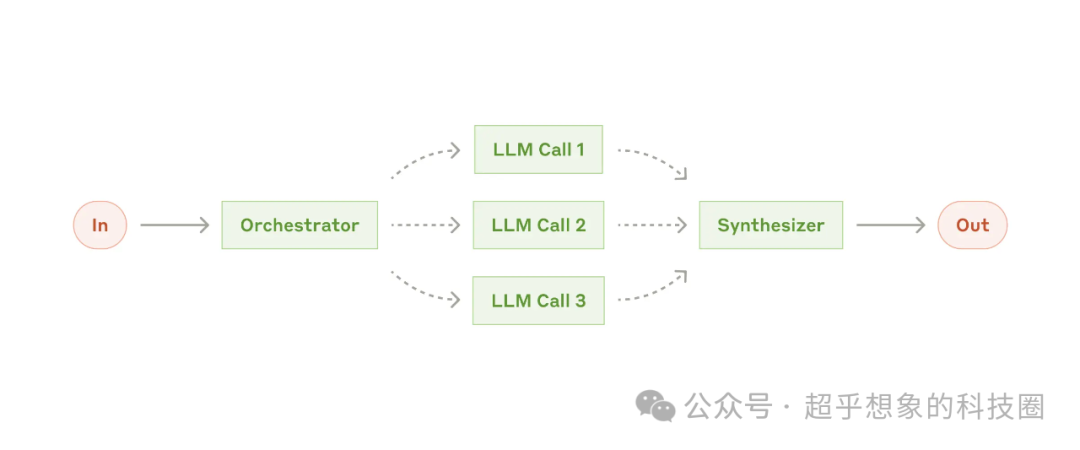
它和并行模式雖然在拓撲結構上類似,但主要的區別是靈活性——子任務不是預定義的,而是編排模塊根據特定輸入確定的。
適用這種模式的樣例:
- 每次對多個文件進行復雜更改的編碼產品
- 涉及從多個來源收集和分析信息以查找可能的相關信息的搜索任務
2.6 評估-優化模式
在這種工作流中,一個LLM調用負責生成,而另一個LLM調用在循環中提供評估和反饋。
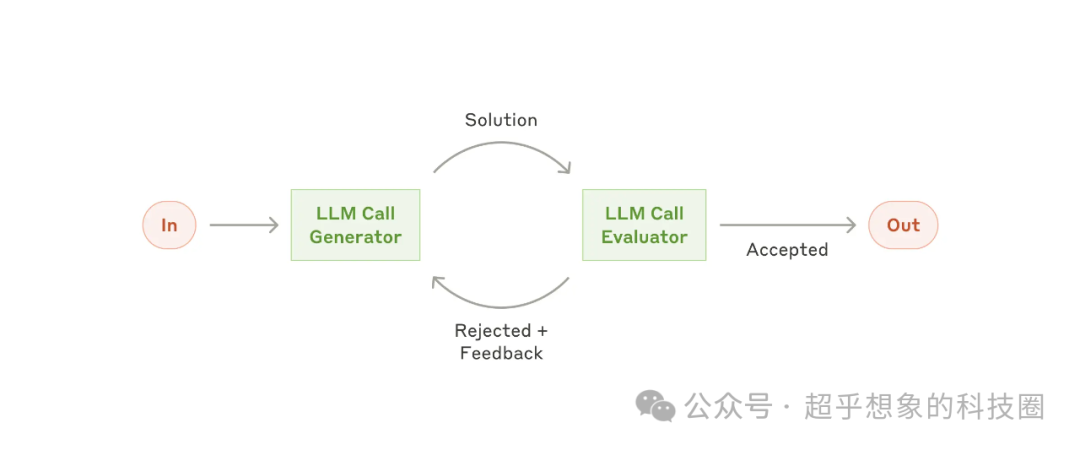
當有明確的評估標準,并且迭代優化提供可衡量的價值時,此工作流特別有效,這種模式已經有自主Agent的雛形了,把Evaluator部分加上環境反饋,這基本上就跟上篇文章介紹的ReAct很像了。
適用這種模式有兩個判斷標準:
- 反饋可以由人類清晰表述時,LLM的輸出根據反饋可以明顯得到改善
- LLM可以提供這樣的反饋
這類似人類作家在制作精美的文檔時可能經歷的迭代協作過程。
適用這種模式的樣例:
- 文學翻譯,其中有細微的差別,翻譯LLM最初可能無法捕獲到,但評估LLM可以提供有用的批評
- 復雜的搜索任務,需要多輪搜索和分析以收集全面的信息,評估LLM可以決定是否需要進一步搜索
下面是使用Dify搭建的一個反思翻譯的流程,也就是吳恩達之前開源的反思翻譯項目的Dify實現:

下面是實際翻譯效果,從翻譯結果來看,反思翻譯質量明顯是高于初始翻譯的。

2.7 Agents
隨著 LLM 在關鍵能力(理解復雜輸入、參與推理和規劃、可靠地使用工具以及從錯誤中恢復)方面的成熟,人工智能正在生產中嶄露頭角。Agents通過人類用戶的命令或與人類用戶的互動討論開始工作。一旦任務明確,Agents就會獨立進行規劃和操作,并有可能返回人類獲取進一步的信息或判斷。在執行過程中,Agents從環境中獲取每一步的 “基本事實”(如工具調用結果或代碼執行情況)以評估其進度至關重要。然后,代理可以在檢查點或遇到阻礙時暫停,以獲得人工反饋。任務通常會在完成后終止,但通常也會包含停止條件(如迭代的最大次數)以保持控制。
代理可以處理復雜的任務,但它們的實現通常很簡單。它們通常只是基于環境反饋循環使用工具的 LLM。因此,清晰周到地設計工具集及其文檔至關重要。
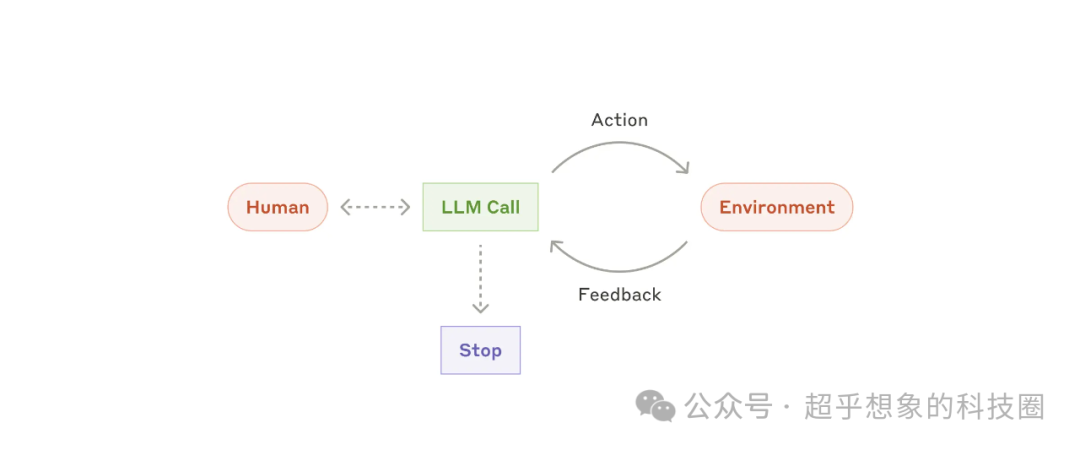
何時使用Agents:agents通常用于難以或不可能預測所需步驟以及無法固定路徑進行硬編碼的開放問題。LLM可能會運行多個回合,并且用戶需要對其決策有一定程度的信任。Agents的自主性使得它成為可信環境中擴展任務的理想選擇。
agents的自主性意味著更高的成本,并且可能會使錯誤復雜化。建議在沙盒環境中進行廣泛測試,并使用適當的防護機制。
適用這種模式的樣例:
(例來自Anthropic)
- 解決SWE-bench任務,該任務涉及根據任務描述對許多文件進行編輯
- computer use參考實現,其中Claude使用計算機完成任務
3 模式的組合
上面這7種模式可以看作是原子模塊,可以根據實際情況修改和組合以適應不同場景。
和任何LLM功能一樣,成功的關鍵是衡量在實際場景中的效果,并要切記:只有在能夠明顯改善結果時才應考慮增加復雜性。
最后
選擇AI大模型就是選擇未來!最近兩年,大家都可以看到AI的發展有多快,我國超10億參數的大模型,在短短一年之內,已經超過了100個,現在還在不斷的發掘中,時代在瞬息萬變,我們又為何不給自己多一個選擇,多一個出路,多一個可能呢?
與其在傳統行業里停滯不前,不如嘗試一下新興行業,而AI大模型恰恰是這兩年的大風口,整體AI領域2025年預計缺口1000萬人,人才需求急為緊迫!
由于文章篇幅有限,在這里我就不一一向大家展示了,學習AI大模型是一項系統工程,需要時間和持續的努力。但隨著技術的發展和在線資源的豐富,零基礎的小白也有很好的機會逐步學習和掌握。
【2025最新】AI大模型全套學習籽料(可白嫖):LLM面試題+AI大模型學習路線+大模型PDF書籍+640套AI大模型報告等等,從入門到進階再到精通,超全面存下吧!
獲取方式:有需要的小伙伴,可以微信掃描下方CSDN官方認證二維碼免費領取【保證100%免費】
包括:AI大模型學習路線、LLM面試寶典、0基礎教學視頻、大模型PDF書籍/筆記、大模型實戰案例合集、AI產品經理合集等等
大模型學習之路,道阻且長,但只要你堅持下去,一定會有收獲。本學習路線圖為你提供了學習大模型的全面指南,從入門到進階,涵蓋理論到應用。
L1階段:啟航篇|大語言模型的基礎認知與核心原理
L2階段:攻堅篇|高頻場景:RAG認知與項目實踐
L3階段:躍迀篇|Agent智能體架構設計
L4階段:精進篇|模型微調與私有化部署
L5階段:專題篇|特訓集:A2A與MCP綜合應用 追蹤行業熱點(全新升級板塊)





AI大模型全套學習資料【獲取方式】

![[BX]和loop指令,debug和masm匯編編譯器對指令的不同處理,循環,大小寄存器的包含關系,操作數據長度與寄存器的關系,段前綴](http://pic.xiahunao.cn/[BX]和loop指令,debug和masm匯編編譯器對指令的不同處理,循環,大小寄存器的包含關系,操作數據長度與寄存器的關系,段前綴)



:如何直接拉起騰訊/百度/高德地圖進行導航)




)





 :Transformer在computer vision領域的應用(三))


